从初始对齐到精细配准
摘要:在医学图像处理中,配准(Registration)是核心步骤之一。本文基于 SimpleITK (sitk) 框架,详细拆解了从"基于几何中心的初始对齐"到"多分辨率刚体配准"的完整代码流程。同时,针对初学者容易困惑的"收敛机制"、"随机采样策略"以及"物理空间与矩阵的区别"进行了深度剖析。
一、 为什么需要初始对齐 (Initial Alignment)?
在使用复杂的优化算法进行配准之前,必须确保两张图像(Fixed Image 和 Moving Image)在空间上有一定的重叠。如果两张图相距太远(例如原点坐标差异巨大),优化算法很容易陷入局部最优或根本无法收敛。
1.1 代码实现
Python
import SimpleITK as sitk
# 计算初始变换
initial_transform = sitk.CenteredTransformInitializer(
fixed_image,
moving_image,
sitk.Euler3DTransform(),
sitk.CenteredTransformInitializerFilter.GEOMETRY
)
# 执行重采样(用于可视化校验)
moving_resampled = sitk.Resample(
moving_image,
fixed_image,
initial_transform,
sitk.sitkLinear,
0.0,
moving_image.GetPixelID()
)1.2 核心参数解析
-
sitk.Euler3DTransform(): 指定变换类型为刚体变换(旋转+平移)。 -
GEOMETRY模式:-
这是最关键的参数。它基于图像的物理坐标元数据(Origin, Spacing, Size)计算几何中心。
-
原理:它假设解剖结构位于图像的几何中心(画框的中心),而不去读取具体的像素值。
-
优点:计算极快,且不受图像噪点影响。
-
对比 :另一种模式是
MOMENTS(基于灰度重心),它通过计算像素值的质心来对齐,但计算较慢且易受背景噪音干扰。
-
1.3 理解重采样 (Resample)
很多初学者不理解 moving_resampled 到底是什么。简单来说,它是一张"伪装"成 Fixed Image 规格的 Moving Image。
-
外壳(几何属性) :它的 Size, Origin, Spacing 与
fixed_image完全一致。 -
内容(像素数据) :它的解剖结构来自
moving_image。 -
位置 :经过
initial_transform变换后,图像内容已被平移到视场中心。
注意 :重采样时,对于灰度图通常使用
sitkLinear(线性插值);如果是 Label/Mask 图像,必须 使用sitkNearestNeighbor(最近邻插值),否则会产生不存在的标签值(如 0.5)。
二、 构建精细配准框架 (The Registration Framework)
完成初始对齐后,我们进入核心的配准迭代过程。SimpleITK 采用面向对象的方式,通过 ImageRegistrationMethod 来管理所有组件。
2.1 完整配置代码
Python
registration_method = sitk.ImageRegistrationMethod()
# --- 1. 相似性度量 (Metric) ---
# 使用 Mattes 互信息,适用于多模态配准(如 CT 配 MRI)
registration_method.SetMetricAsMattesMutualInformation(numberOfHistogramBins=50)
# 随机采样策略:每次迭代只计算 1% 的像素,提升速度
registration_method.SetMetricSamplingStrategy(registration_method.RANDOM)
registration_method.SetMetricSamplingPercentage(0.01)
# --- 2. 插值器 (Interpolator) ---
registration_method.SetInterpolator(sitk.sitkLinear)
# --- 3. 优化器 (Optimizer) ---
# 使用梯度下降法
registration_method.SetOptimizerAsGradientDescent(
learningRate=1.0,
numberOfIterations=100, # 最大迭代次数
convergenceMinimumValue=1e-6,# 收敛阈值
convergenceWindowSize=10, # 收敛窗口
)
# 自动调整参数比例(处理旋转与平移的数量级差异)
registration_method.SetOptimizerScalesFromPhysicalShift()
# --- 4. 多分辨率策略 (Multi-resolution) ---
# 三层金字塔:4倍下采样 -> 2倍下采样 -> 原始分辨率
registration_method.SetShrinkFactorsPerLevel(shrinkFactors=[4, 2, 1])
registration_method.SetSmoothingSigmasPerLevel(smoothingSigmas=[2, 1, 0])
registration_method.SmoothingSigmasAreSpecifiedInPhysicalUnitsOn()
# --- 5. 设置初始状态 ---
registration_method.SetInitialTransform(initial_transform, inPlace=False)
# --- 6. 执行配准 ---
# 关键:必须强制转换为 Float32 类型
final_transform = registration_method.Execute(
sitk.Cast(fixed_image, sitk.sitkFloat32),
sitk.Cast(moving_image, sitk.sitkFloat32)
)三、 深度疑难解答 (Q&A)
在实际运行上述代码时,往往会遇到以下几个令人困惑的现象,这里进行深度原理解析。
Q1: 为什么设置了 200 次迭代,程序跑了 120 次就停了?
A: 这是触发了"早停机制" (Early Stopping),是好事。
代码中设置了 convergenceMinimumValue = 1e-6 和 convergenceWindowSize = 10。
-
优化器会监控最近 10 次迭代的 Metric 变化。
-
如果变化幅度小于
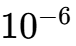 ,说明结果已经稳定(收敛),继续算下去也是浪费时间。
,说明结果已经稳定(收敛),继续算下去也是浪费时间。 -
图示理解:在 Metric 曲线图中,你会看到曲线变平,然后直接跳到下一层分辨率,这说明算法认为当前解已经是该分辨率下的最优解。
Q2: 为什么我每次运行代码,画出来的 Metric 曲线都不一样?
A: 因为使用了随机采样 (Random Sampling)。
Python
registration_method.SetMetricSamplingStrategy(registration_method.RANDOM)
registration_method.SetMetricSamplingPercentage(0.01)为了加速,算法每次只随机抽取 1% 的像素点来计算梯度。
-
每次抽取的点不一样,计算出的"下山路径"就会有微小差别。
-
结果:虽然路径不同,但只要参数合理,最终都会收敛到同一个解(final_transform 是基本一致的)。如果需要完全复现,需要设置 Random Seed。
Q3: 为什么要用 sitk.Cast(..., sitk.sitkFloat32) 转换类型?
A: 为了保证梯度计算的连续性和精度。
-
Int (整数):图像数据像"楼梯"。在台阶之间导数为 0,优化器无法计算梯度,不知道该往哪里走。
-
Float (浮点):图像数据像"平滑的坡道"。优化器可以计算出微小的斜率,进行亚像素级别的精确调整。
-
此外,SimpleITK 底层 C++ 库的许多配准算法强制要求输入为 Float 类型,否则会报错。
Q4: 为什么处理的是 3D Image 而不是 3D 矩阵 (Numpy Array)?
这是医学图像处理与计算机视觉(CV)最大的不同点。
-
矩阵 (Matrix) :只有
[i, j, k]索引,没有物理概念。直接操作矩阵容易导致"由于像素间距 (Spacing) 不同而造成的变形"或"由于原点 (Origin) 不同而造成的位置错位"。 -
图像 (Image) :包含 元数据 (Origin, Spacing, Direction) 。配准是在物理空间 (毫米坐标系) 中进行的。SimpleITK 会自动处理不同分辨率图像之间的坐标映射,确保解剖结构正确对齐。
四、 总结
SimpleITK 的配准流程可以归纳为:
-
准备 :使用
CenteredTransformInitializer把图先"摆正"。 -
配置:告诉机器用什么标准评价(Metric)、怎么走(Optimizer)、怎么看图(Interpolator)。
-
加速:利用多分辨率金字塔(由粗到细)和随机采样。
-
执行 :传入 Float32 数据,获取最终的变换矩阵
final_transform。
希望这篇总结能帮你理清 SimpleITK 配准的代码逻辑!如有疑问,欢迎在评论区交流。