一、目标文件
运行这个命令,会生成main.o的目标文件
bash
gcc -c main.c用file查看目标文件的格式,会发现是ELF文件
目标文件是一个二进制的文件,文件的格式是ELF ,是对二进制代码的一种封装。
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ file main.o
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped二、ELF文件
要理解编译链链接的细节,需先了解 ELF 文件,以下四种文件都属于 ELF 文件:
- 可重定位文件(Relocatable File) :即
xxx.o文件,包含适合与其他目标文件链接,以创建可执行文件或共享目标文件的代码和数据。 - 可执行文件(Executable File):即可执行程序。
- 共享目标文件(Shared Object File) :即
xxx.so文件。 - 内核转储(core dumps):存放当前进程的执行上下文,由 dump 信号触发生成。
ELF文件的格式:
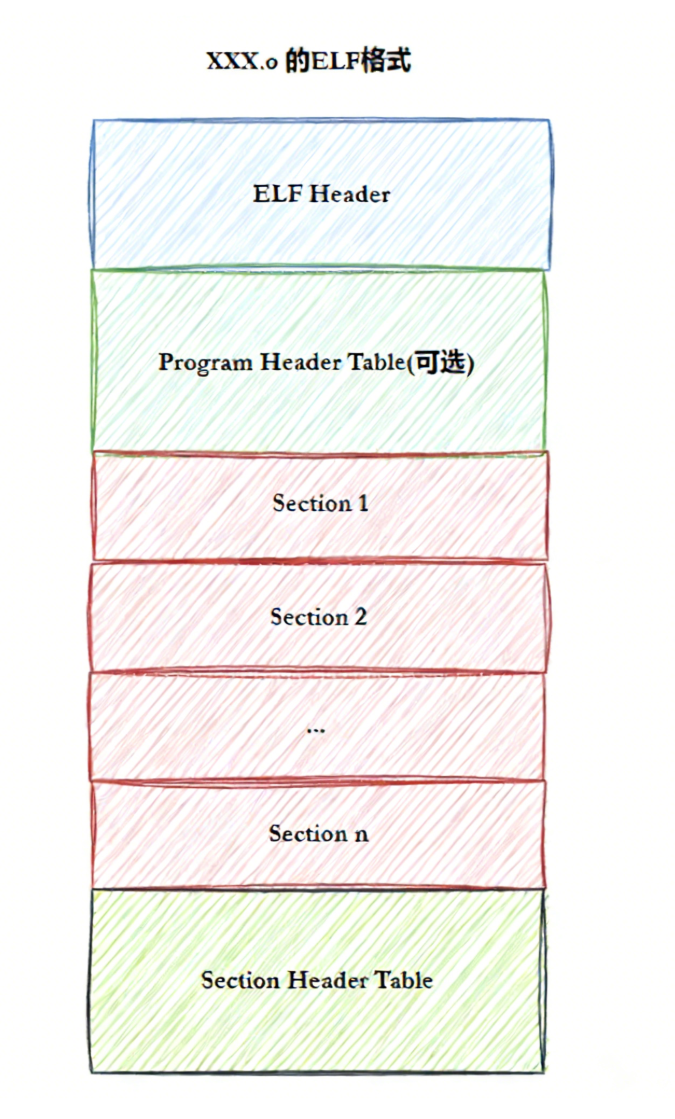
一个 ELF 文件由以下四部分组成:
- ELF 头(ELF header):位于文件起始位置,描述文件主要特性,核心作用是定位文件的其他部分。
- 程序头表(Program header table):列举所有有效段(segments)及其属性,记录每个段的起始位置、偏移量、长度,用于分割二进制文件中紧密排布的各个段。
- 节头表(Section header table):包含对节(sections)的描述信息。
- 节(Section):ELF 文件的基本组成单位,存储特定类型的数据。各类信息与数据分置于不同节中,例如代码节存放可执行代码,数据节存放全局变量和静态数据等。
1.关于查看ELF不同组成部分内容的指令
1.1查看ELF Header
bash
readelf -h main**-h或 --file-header:**显示ELF文件的文件头信息。文件头包含了ELF文件的基本信息,比如文件类 型、机器类型、版本、入口点地址、程序头表和节头表的位置和大小等
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ readelf -h main
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
# 程序的入口
Entry point address: 0x1060
Start of program headers: 64 (bytes into file)
Start of section headers: 13976 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 13
Size of section headers: 64 (bytes)
Number of section headers: 31
Section header string table index: 30
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ 内核中维护ELF的代码:
bash
// 内核中关于ELF Header相关的数据结构
// 没错,操作系统自己必须能够识别特定格式的可执行程序:/linux/include/elf.h
typedef struct elf32_hdr{
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry; /* Entry point */
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
typedef struct elf64_hdr {
unsigned char e_ident[EI_NIDENT]; /* ELF "magic number" */
Elf64_Half e_type;
Elf64_Half e_machine;
Elf64_Word e_version;
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags;
Elf64_Half e_ehsize;
Elf64_Half e_phentsize;
Elf64_Half e_phnum;
Elf64_Half e_shentsize;
Elf64_Half e_shnum;
Elf64_Half e_shstrndx;
} Elf64_Ehdr;1.2 查看 ELF Program Header Table
显示 ELF 文件的程序头部(也称为段头)信息。该信息对于了解可执行文件在内存中的布局和加载过程至关重要
bash
readelf -l main
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ readelf -l main
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1060
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002d8 0x00000000000002d8 R 0x8
INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000628 0x0000000000000628 R 0x1000
LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000
0x0000000000000175 0x0000000000000175 R E 0x1000
LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000
0x00000000000000f4 0x00000000000000f4 R 0x1000
LOAD 0x0000000000002db8 0x0000000000003db8 0x0000000000003db8
0x0000000000000258 0x0000000000000260 RW 0x1000
DYNAMIC 0x0000000000002dc8 0x0000000000003dc8 0x0000000000003dc8
0x00000000000001f0 0x00000000000001f0 RW 0x8
NOTE 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
NOTE 0x0000000000000368 0x0000000000000368 0x0000000000000368
0x0000000000000044 0x0000000000000044 R 0x4
GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
GNU_EH_FRAME 0x0000000000002010 0x0000000000002010 0x0000000000002010
0x0000000000000034 0x0000000000000034 R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002db8 0x0000000000003db8 0x0000000000003db8
0x0000000000000248 0x0000000000000248 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .plt.got .plt.sec .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id .note.ABI-tag
09 .note.gnu.property
10 .eh_frame_hdr
11
12 .init_array .fini_array .dynamic .got 内核中维护ELF的代码:
bash
// 内核中关于ELF Program Header相关的数据结构
typedef struct elf32_phdr{
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
typedef struct elf64_phdr {
Elf64_Word p_type;
Elf64_Word p_flags;
Elf64_Off p_offset; /* Segment file offset */
Elf64_Addr p_vaddr; /* Segment virtual address */
Elf64_Addr p_paddr; /* Segment physical address */
Elf64_Xword p_filesz; /* Segment size in file */
Elf64_Xword p_memsz; /* Segment size in memory */
Elf64_Xword p_align; /* Segment alignment, file & memory */
} Elf64_Phdr;1.3 查看 ELF SectionHeaderTable
-S 或 --section-headers:显示 ELF 文件的节头信息。节头描述了 ELF 文件的各个节的起始地址、大小、标志等信息。
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ readelf -S main
There are 31 section headers, starting at offset 0x3698:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000318 00000318
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.pr[...] NOTE 0000000000000338 00000338
0000000000000030 0000000000000000 A 0 0 8
[ 3] .note.gnu.bu[...] NOTE 0000000000000368 00000368
0000000000000024 0000000000000000 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000038c 0000038c
0000000000000020 0000000000000000 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003b0 000003b0
0000000000000024 0000000000000000 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003d8 000003d8
00000000000000a8 0000000000000018 A 7 1 8
[ 7] .dynstr STRTAB 0000000000000480 00000480
000000000000008d 0000000000000000 A 0 0 1
[ 8] .gnu.version VERSYM 000000000000050e 0000050e
000000000000000e 0000000000000002 A 6 0 2
[ 9] .gnu.version_r VERNEED 0000000000000520 00000520
0000000000000030 0000000000000000 A 7 1 8
[10] .rela.dyn RELA 0000000000000550 00000550
00000000000000c0 0000000000000018 A 6 0 8
[11] .rela.plt RELA 0000000000000610 00000610
0000000000000018 0000000000000018 AI 6 24 8
[12] .init PROGBITS 0000000000001000 00001000
000000000000001b 0000000000000000 AX 0 0 4
[13] .plt PROGBITS 0000000000001020 00001020
0000000000000020 0000000000000010 AX 0 0 16
[14] .plt.got PROGBITS 0000000000001040 00001040
0000000000000010 0000000000000010 AX 0 0 16
[15] .plt.sec PROGBITS 0000000000001050 00001050
0000000000000010 0000000000000010 AX 0 0 16
[16] .text PROGBITS 0000000000001060 00001060
0000000000000107 0000000000000000 AX 0 0 16
[17] .fini PROGBITS 0000000000001168 00001168
000000000000000d 0000000000000000 AX 0 0 4
[18] .rodata PROGBITS 0000000000002000 00002000
0000000000000010 0000000000000000 A 0 0 4
[19] .eh_frame_hdr PROGBITS 0000000000002010 00002010
0000000000000034 0000000000000000 A 0 0 4
[20] .eh_frame PROGBITS 0000000000002048 00002048
00000000000000ac 0000000000000000 A 0 0 8
[21] .init_array INIT_ARRAY 0000000000003db8 00002db8
0000000000000008 0000000000000008 WA 0 0 8
[22] .fini_array FINI_ARRAY 0000000000003dc0 00002dc0
0000000000000008 0000000000000008 WA 0 0 8
[23] .dynamic DYNAMIC 0000000000003dc8 00002dc8
00000000000001f0 0000000000000010 WA 7 0 8
[24] .got PROGBITS 0000000000003fb8 00002fb8
0000000000000048 0000000000000008 WA 0 0 8
[25] .data PROGBITS 0000000000004000 00003000
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 0000000000004010 00003010
0000000000000008 0000000000000000 WA 0 0 1
[27] .comment PROGBITS 0000000000000000 00003010
000000000000002b 0000000000000001 MS 0 0 1
[28] .symtab SYMTAB 0000000000000000 00003040
0000000000000360 0000000000000018 29 18 8
[29] .strtab STRTAB 0000000000000000 000033a0
00000000000001da 0000000000000000 0 0 1
[30] .shstrtab STRTAB 0000000000000000 0000357a
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)内核中维护ELF的代码:
cpp
// 内核中关于ELF Section Header相关的数据结构
typedef struct {
Elf32_Word sh_name;
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr;
Elf32_Off sh_offset;
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize;
} Elf32_Shdr;
typedef struct elf64_shdr {
Elf64_Word sh_name; /* Section name, index in string tbl */
Elf64_Word sh_type; /* Type of section */
Elf64_Word sh_type; /* Type of section */
Elf64_Xword sh_flags; /* Miscellaneous section attributes */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Size of section in bytes */
Elf64_Word sh_link; /* Index of another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;1.4 查看具体的sections信息
bash
# 通过反汇编来查看
objdump -S main
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ objdump -S main
main: file format elf64-x86-64
Disassembly of section .init:
0000000000001000 <_init>:
1000: f3 0f 1e fa endbr64
1004: 48 83 ec 08 sub $0x8,%rsp
1008: 48 8b 05 d9 2f 00 00 mov 0x2fd9(%rip),%rax # 3fe8 <__gmon_start__@Base>
100f: 48 85 c0 test %rax,%rax
1012: 74 02 je 1016 <_init+0x16>
1014: ff d0 call *%rax
1016: 48 83 c4 08 add $0x8,%rsp
101a: c3 ret
Disassembly of section .plt:
0000000000001020 <.plt>:
1020: ff 35 9a 2f 00 00 push 0x2f9a(%rip) # 3fc0 <_GLOBAL_OFFSET_TABLE_+0x8>
1026: ff 25 9c 2f 00 00 jmp *0x2f9c(%rip) # 3fc8 <_GLOBAL_OFFSET_TABLE_+0x10>
102c: 0f 1f 40 00 nopl 0x0(%rax)
1030: f3 0f 1e fa endbr64
1034: 68 00 00 00 00 push $0x0
1039: e9 e2 ff ff ff jmp 1020 <_init+0x20>
103e: 66 90 xchg %ax,%ax
Disassembly of section .plt.got:
0000000000001040 <__cxa_finalize@plt>:
1040: f3 0f 1e fa endbr64
1044: ff 25 ae 2f 00 00 jmp *0x2fae(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>
104a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
Disassembly of section .plt.sec:
0000000000001050 <puts@plt>:
1050: f3 0f 1e fa endbr64
1054: ff 25 76 2f 00 00 jmp *0x2f76(%rip) # 3fd0 <puts@GLIBC_2.2.5>
105a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
Disassembly of section .text:
0000000000001060 <_start>:
1060: f3 0f 1e fa endbr64
1064: 31 ed xor %ebp,%ebp
1066: 49 89 d1 mov %rdx,%r9
1069: 5e pop %rsi
106a: 48 89 e2 mov %rsp,%rdx
106d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
1071: 50 push %rax
1072: 54 push %rsp
1073: 45 31 c0 xor %r8d,%r8d
1076: 31 c9 xor %ecx,%ecx
1078: 48 8d 3d ca 00 00 00 lea 0xca(%rip),%rdi # 1149 <main>
107f: ff 15 53 2f 00 00 call *0x2f53(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>
1085: f4 hlt
1086: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)
108d: 00 00 00
0000000000001090 <deregister_tm_clones>:
1090: 48 8d 3d 79 2f 00 00 lea 0x2f79(%rip),%rdi # 4010 <__TMC_END__>
1097: 48 8d 05 72 2f 00 00 lea 0x2f72(%rip),%rax # 4010 <__TMC_END__>
109e: 48 39 f8 cmp %rdi,%rax
10a1: 74 15 je 10b8 <deregister_tm_clones+0x28>
10a3: 48 8b 05 36 2f 00 00 mov 0x2f36(%rip),%rax # 3fe0 <_ITM_deregisterTMCloneTable@Base>
10aa: 48 85 c0 test %rax,%rax
10ad: 74 09 je 10b8 <deregister_tm_clones+0x28>
10af: ff e0 jmp *%rax
10b1: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
10b8: c3 ret
10b9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
00000000000010c0 <register_tm_clones>:
10c0: 48 8d 3d 49 2f 00 00 lea 0x2f49(%rip),%rdi # 4010 <__TMC_END__>
10c7: 48 8d 35 42 2f 00 00 lea 0x2f42(%rip),%rsi # 4010 <__TMC_END__>
10ce: 48 29 fe sub %rdi,%rsi
10d1: 48 89 f0 mov %rsi,%rax
10d4: 48 c1 ee 3f shr $0x3f,%rsi
10d8: 48 c1 f8 03 sar $0x3,%rax
10dc: 48 01 c6 add %rax,%rsi
10df: 48 d1 fe sar $1,%rsi
10e2: 74 14 je 10f8 <register_tm_clones+0x38>
10e4: 48 8b 05 05 2f 00 00 mov 0x2f05(%rip),%rax # 3ff0 <_ITM_registerTMCloneTable@Base>
10eb: 48 85 c0 test %rax,%rax
10ee: 74 08 je 10f8 <register_tm_clones+0x38>
10f0: ff e0 jmp *%rax
10f2: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
10f8: c3 ret
10f9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
0000000000001100 <__do_global_dtors_aux>:
1100: f3 0f 1e fa endbr64
1104: 80 3d 05 2f 00 00 00 cmpb $0x0,0x2f05(%rip) # 4010 <__TMC_END__>
110b: 75 2b jne 1138 <__do_global_dtors_aux+0x38>
110d: 55 push %rbp
110e: 48 83 3d e2 2e 00 00 cmpq $0x0,0x2ee2(%rip) # 3ff8 <__cxa_finalize@GLIBC_2.2.5>
1115: 00
1116: 48 89 e5 mov %rsp,%rbp
1119: 74 0c je 1127 <__do_global_dtors_aux+0x27>
111b: 48 8b 3d e6 2e 00 00 mov 0x2ee6(%rip),%rdi # 4008 <__dso_handle>
1122: e8 19 ff ff ff call 1040 <__cxa_finalize@plt>
1127: e8 64 ff ff ff call 1090 <deregister_tm_clones>
112c: c6 05 dd 2e 00 00 01 movb $0x1,0x2edd(%rip) # 4010 <__TMC_END__>
1133: 5d pop %rbp
1134: c3 ret
1135: 0f 1f 00 nopl (%rax)
1138: c3 ret
1139: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
0000000000001140 <frame_dummy>:
1140: f3 0f 1e fa endbr64
1144: e9 77 ff ff ff jmp 10c0 <register_tm_clones>
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: 48 89 c7 mov %rax,%rdi
115b: e8 f0 fe ff ff call 1050 <puts@plt>
1160: b8 00 00 00 00 mov $0x0,%eax
1165: 5d pop %rbp
1166: c3 ret
Disassembly of section .fini:
0000000000001168 <_fini>:
1168: f3 0f 1e fa endbr64
116c: 48 83 ec 08 sub $0x8,%rsp
1170: 48 83 c4 08 add $0x8,%rsp
1174: c3 ret1.5 查看编译后的.o 目标文件
bash
objdump -d 可执行文件 # 反汇编代码段
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ objdump -d main.o
main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <main+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <main+0x17>
17: b8 00 00 00 00 mov $0x0,%eax
1c: 5d pop %rbp
1d: c3 ret2. ELF从形成到加载
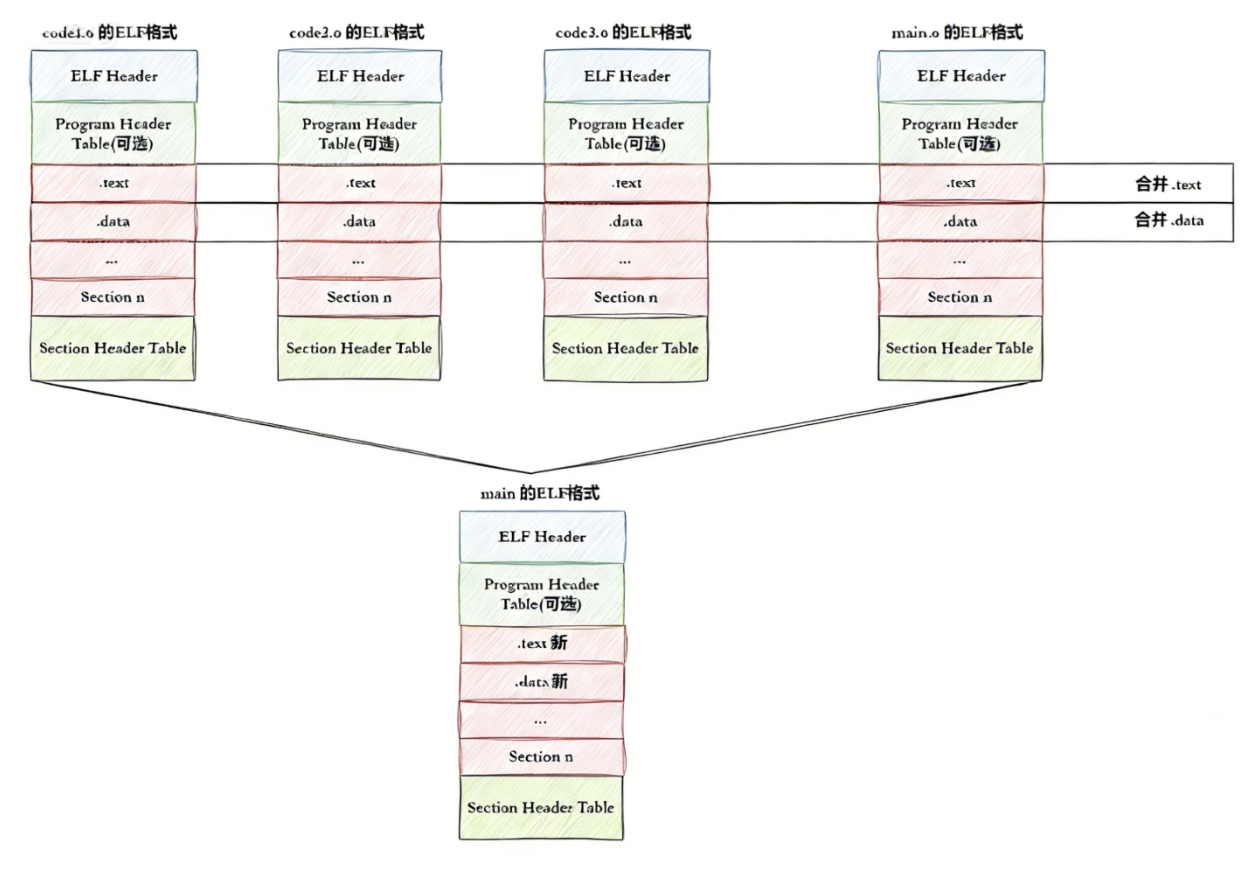
2.1 ELF形成可执行
- step-1: 将多份 C/C++ 源代码,翻译成为的目标 .o 文件 + 动静态库 (ELF)
- step-2: 将多份 .o 文件 section 进行合并
- 说白了就是对应区域进程合并重新排布(按照ELF格式来)
- 实际合并是在链接时进行的,但是并不是这么简单的合并,也会涉及对库合并,此处不做过多追究
2.2 ELF可执行文件加载
- ELF 的 Section 与 Segment 关系:ELF 包含多个不同 Section,加载到内存时会合并这些 Section,形成 Segment。
- Section 合并原则:依据 Section 的属性(如可读、可写、可执行、加载时申请空间等),属性相同的 Section 会被合并。
- 合并的确定性:该合并逻辑在 ELF 文件生成时已确定,具体的合并规则记录在 ELF 的程序头表(Program header table)中。
查看ELF Program Header Table里面有一个对应的节(Section)和段(Segment)的映射表:
bash
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .plt.got .plt.sec .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id .note.ABI-tag
09 .note.gnu.property
10 .eh_frame_hdr
11
12 .init_array .fini_array .dynamic .got 为什么要将 Section 合并成为 Segment
将 Section 合并为 Segment 的核心目的是提升程序加载与运行的效率、适配操作系统的内存管理规则,具体原因包括:
- 适配内存页管理:操作系统以 "内存页" 为基本单位分配 / 管理内存(通常是 4KB 等固定大小),若直接加载单个 Section,会导致内存页的碎片化或浪费;合并为 Segment 后,可一次性加载一组同属性的 Section,匹配内存页的分配逻辑。
- 统一权限控制:操作系统对内存区域的权限(可读 / 可写 / 可执行)是按 "段" 维度设置的,合并同属性 Section 到一个 Segment,能高效地为该内存区域统一配置权限(比如所有代码 Section 合并为 "可读 + 可执行" 的段,避免逐个 Section 设置权限)。
- 减少加载开销:加载一个 Segment 只需一次内存申请 + 权限配置,若加载多个独立 Section 则需要多次操作,合并后能降低操作系统的加载耗时。
- 区分 "加载 / 不加载" 的内容:部分 Section(如调试信息节)不需要加载到内存,合并时会被排除在 Segment 之外,避免不必要的内存占用。
本质是用 "段" 的粗粒度管理,适配操作系统的内存机制,平衡资源利用与执行效率。
对于程序头表 和节头表又有什么用呢,其实 ELF 文件提供 2 个不同的视图 / 视角来让我们理解这两个部分:
- 链接视图 (Linking view) - 对应节头表 Section header table
- 文件结构的粒度更细,将文件按功能模块的差异进行划分,静态链接分析的时候一般关注的是链接视图,能够理解 ELF 文件中包含的各个部分的信息。
- 为了空间布局上的效率,将来在链接目标文件时,链接器会把很多节(section)合并,规整成可执行的段(segments)、可读写的段、只读段等。合并了后,空间利用率就高了,否则,很小的很小的一段,未来物理内存浪费太大(物理内存页分配一般都是整数倍一块给你,比如 4k),所以,链接器趁趁着链接就把小块们都合并了。
- 执行视图 (execution view) - 对应程序头表 Program header table
- 告诉操作系统,如何加载可执行文件,完成进程内存的初始化。一个可执行程序的格式中,一定有 program header table。(重点理解,和PCB的虚拟地址创建有关系,下面会展开说)
- 说白了就是:一个在链接时作用,一个在运行加载时作用。
从链接视图来看:
- 命令
readelf -S main.o可以帮助查看 ELF 文件的节头表。 - .text 节:是保存程序代码指令的代码。
- .data 节:保存了初始化的全局变量和局部静态变量等数据。
- .rodata 节:保存了只读的数据,如一行 C 语言代码中的字符串。由于.rodata 节是只读的,所以只能存在于一个可执行文件的只读段中。因此,只能是在 text 段(不是 data 段)中找到.rodata 节。
- .BSS 节:为未初始化的全局变量和局部静态变量预留位置
- .symtab 节:Symbol Table 符号表,就是源码里面那些函数名、变量名和代码的对应关系。
- .got.plt 节(全局偏移表 - 过程链接表):.got 节保存了全局偏移表。.got 节和.plt 节一起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。使用
readelf命令查看.so 文件可以看到该节。(更多细节:https://www.doubao.com/thread/w92e078e825c6d2fc)
从执行视图来看:
- 告诉操作系统哪些模块可以被加载进内存。
- 加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执行的
我们可以在 ELF 头中找到文件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。
先区分两个易混淆的术语(这是理解偏移关系的关键):
术语 中文名称 核心作用 面向对象 Section 节 编译 / 链接阶段组织数据(如代码、数据、符号表) 链接器(ld) Segment 段(程序头段) 运行阶段加载到内存的最小单位 加载器(操作系统) 简单说:节(Section)是链接视角的划分,段(Segment)是加载视角的划分;一个段通常包含多个节,而文件偏移量是这些 "区域" 在磁盘文件中的物理位置。
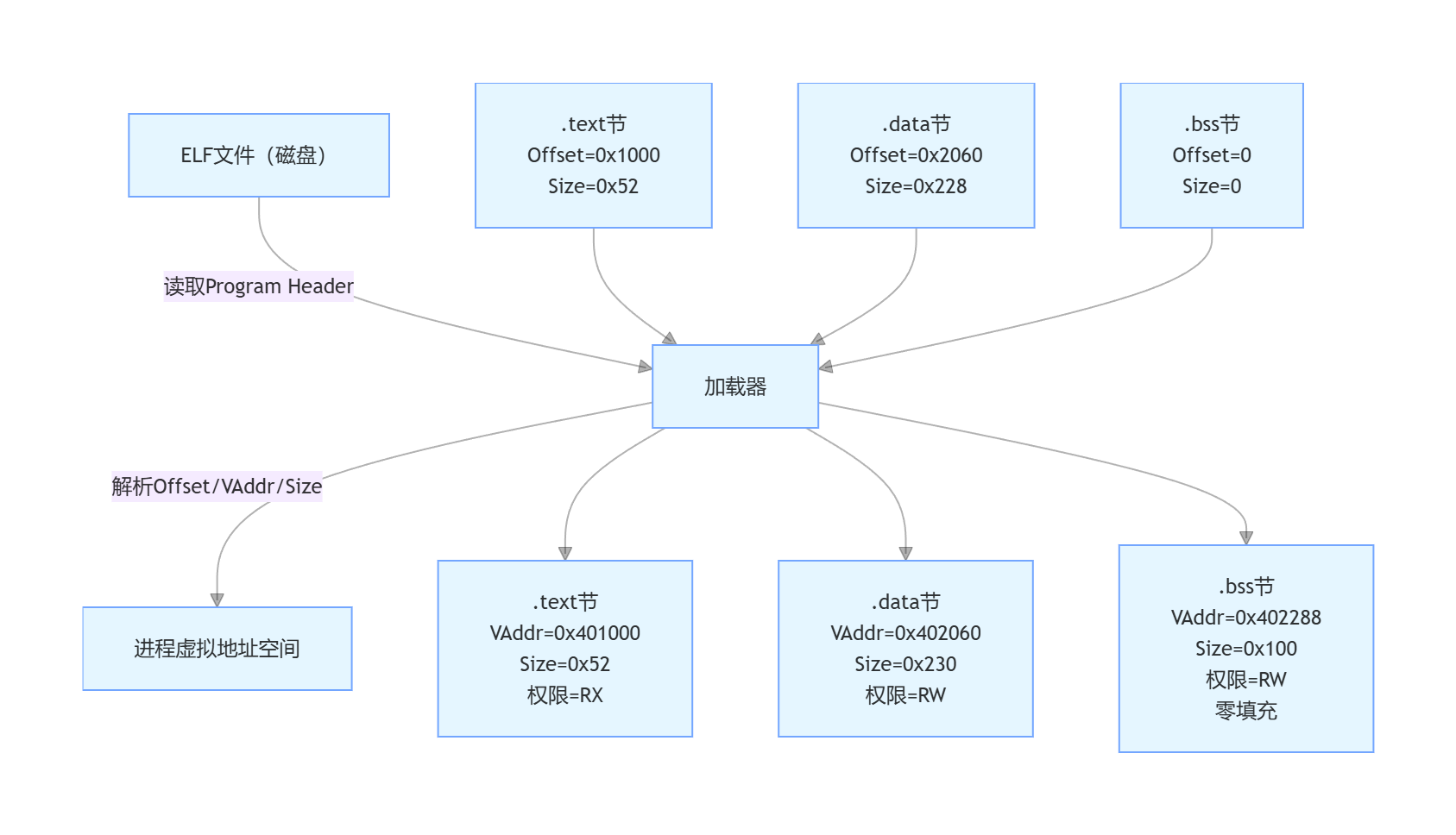
二、核心映射关系:文件偏移 ↔ 虚拟地址
ELF 文件加载到内存的本质,是把磁盘文件中的部分数据,按 "映射规则" 拷贝 / 映射到进程的虚拟地址空间。这个规则由 ELF 的程序头表(Program Header Table) 定义(段的映射规则),而节的偏移关系则由节头表(Section Header Table) 定义。
1. 核心公式(段 / 节的映射核心)
对于可加载的段 / 节,磁盘文件偏移和内存虚拟地址的映射满足:
bash内存虚拟地址 (Virtual Address, VA) = 加载基址 + (文件偏移 - 段偏移) + 段虚拟地址简化理解:
- 磁盘文件中,段 / 节有一个文件偏移(Offset):表示该区域在 ELF 文件中的起始字节位置(相对于文件开头)。
- 内存中,段 / 节有一个虚拟地址(VAddr):表示该区域加载到进程虚拟地址空间的起始地址。
- 加载器会把 "文件中 Offset 开始、大小为 Size 的数据",映射到 "内存中 VAddr 开始、大小为 Size 的区域"。
细节:
- 核心对应关系 :ELF 的段 / 节在磁盘中有文件偏移(Offset) ,加载到内存后对应虚拟地址(VAddr),加载器按 Program Header 的规则将二者映射,本质是 "磁盘字节位置 → 内存地址位置" 的一一对应(零填充区域除外)。
- 视角区分:节(Section)是链接器的划分,其偏移由节头表定义;段(Segment)是加载器的划分,其偏移由程序头表定义,一个段可包含多个节。
到这里要理解一个东西:PCB中虚拟内存中的数据是谁给初始化的呢?(ELF方面理解)答:是加载程序ELF文件时,加载器会用ELF文件中的属性和数据来初始化虚拟内存各段中的数据。(ELF文件中各区域的分布与虚拟内存中的分布大致一样。) LF 文件的可加载段(LOAD 段) 在虚拟内存中的布局,会保持段内相对偏移 的一致性,但整体基址、未加载区域、对齐填充、ASLR 等因素会导致分布存在差异。
三、ELF 加载与进程地址空间
虚拟地址 / 逻辑地址
问题:
- 一个 ELF 程序,在没有被加载到内存的时候,有没有地址呢?
- 进程 mm_struct、vm_area_struct 在进程刚刚创建的时候,初始化数据从哪里来的?
答案:
- 一个 ELF 程序,在没有被加载到内存的时候,本来就有地址,当代计算机工作的时候,都采用 "平坦模式" 进行工作。所以也要求 ELF 对自己的代码和数据进行统一编址,下面是
objdump -S反汇编之后的代码 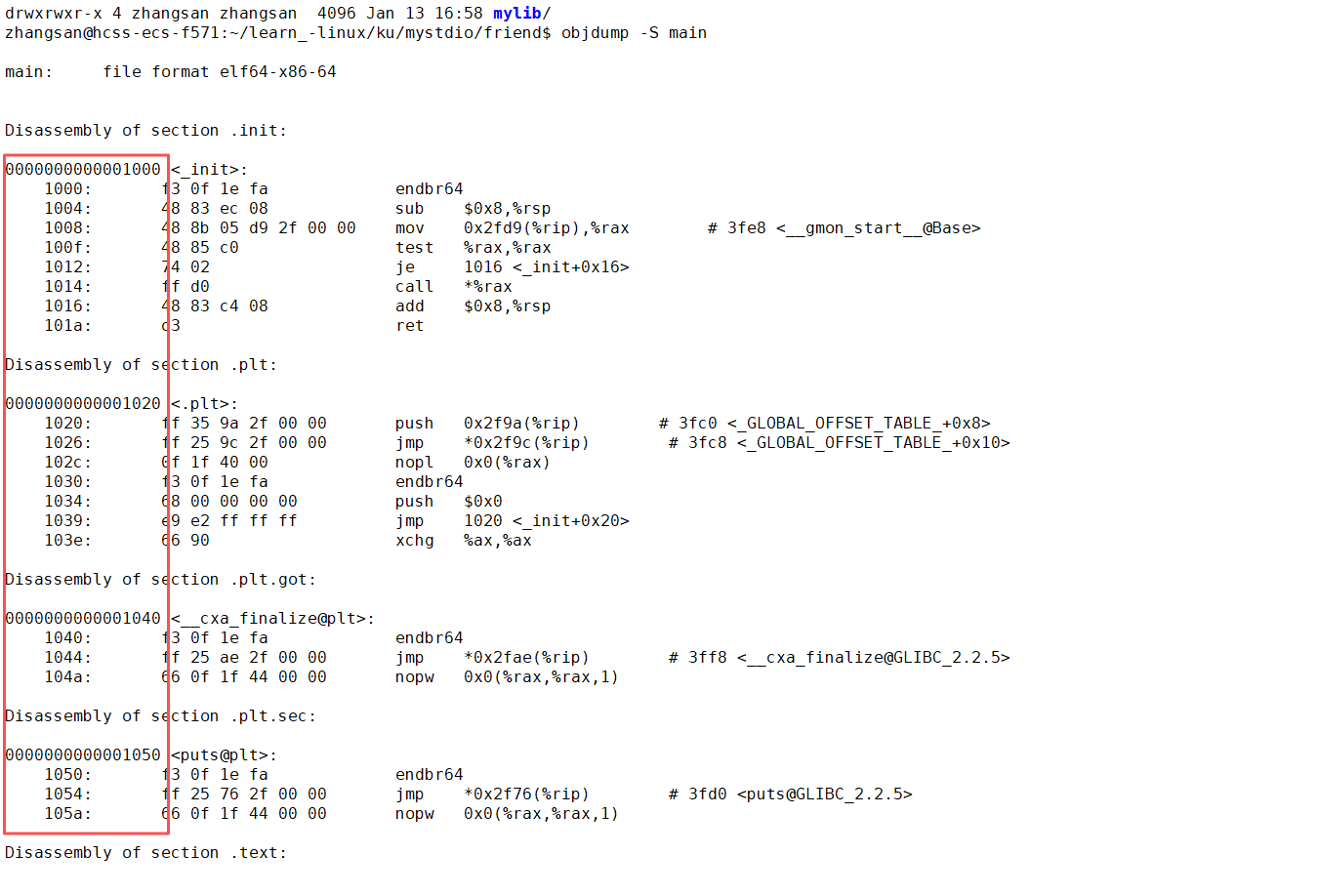
左侧的就是 ELF 的虚拟地址,其实,严格意义上应该叫做逻辑地址(起始地址 + 偏移量),但是我们认为起始地址是 0. 也就是说,其实虚拟地址在我们的程序还没有加载到内存的时候,就已经把可执行程序进行统一编址了.
- 进程 mm_struct、vm_area_struct 在进程刚刚创建的时候,初始化数据从哪里来的?从 ELF 各个 segment 来,每个 segment 有自己的起始地址和自己的长度,用来初始化内核结构中的 start, end 等范围数据,另外在用详细地址,填充页表.
所以:虚拟地址机制,不光 OS 要支持,编译器也要支持.
四、静态链接
静态链接就是把库中的.o 进行合并, 所以链接其实就是将编译之后的所有目标文件连同用到的一些静态库运行时库组合,拼装成一个独立的可执行文件。(其中就包括地址修正 )当所有模块组合在一起之后,链接器会根据我们的.o 文件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从而修正它们的地址。这就是静态链接的过程。
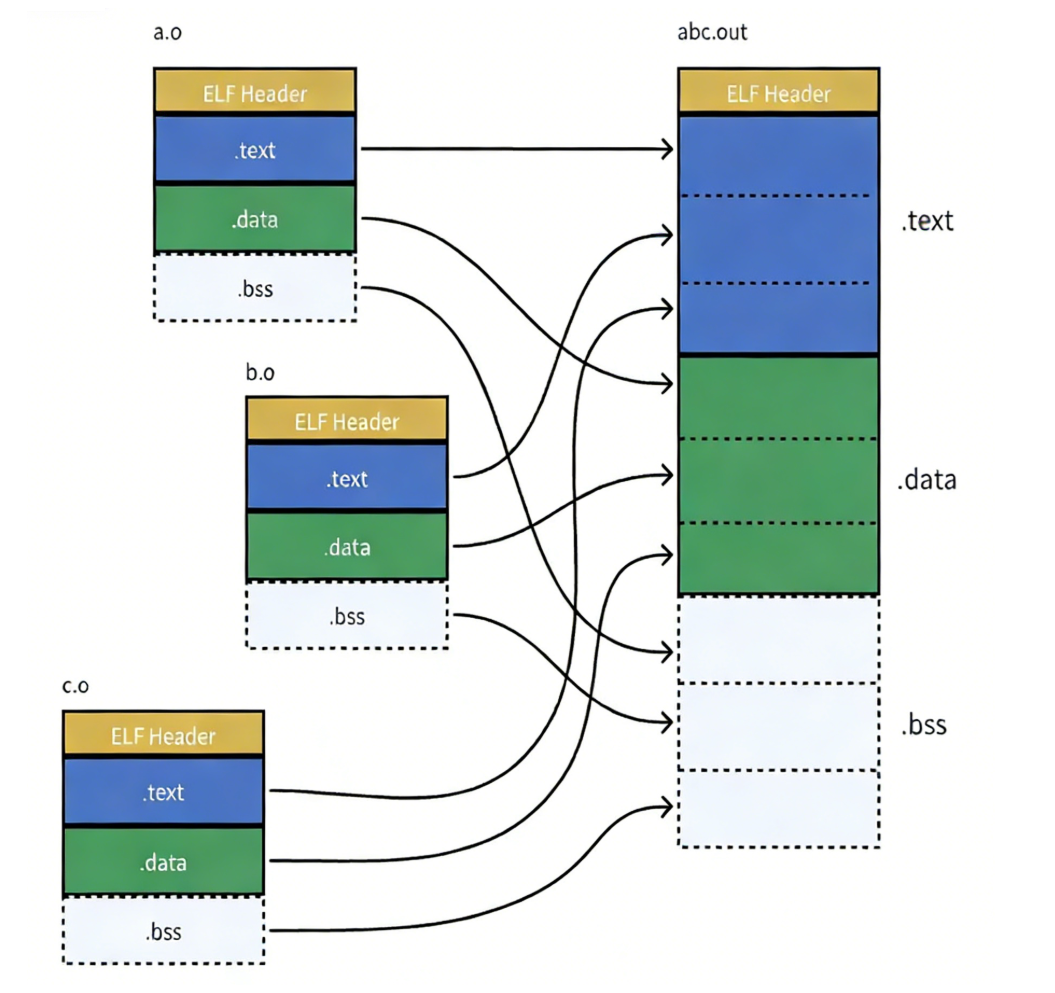
五、动态链接与动态库加载
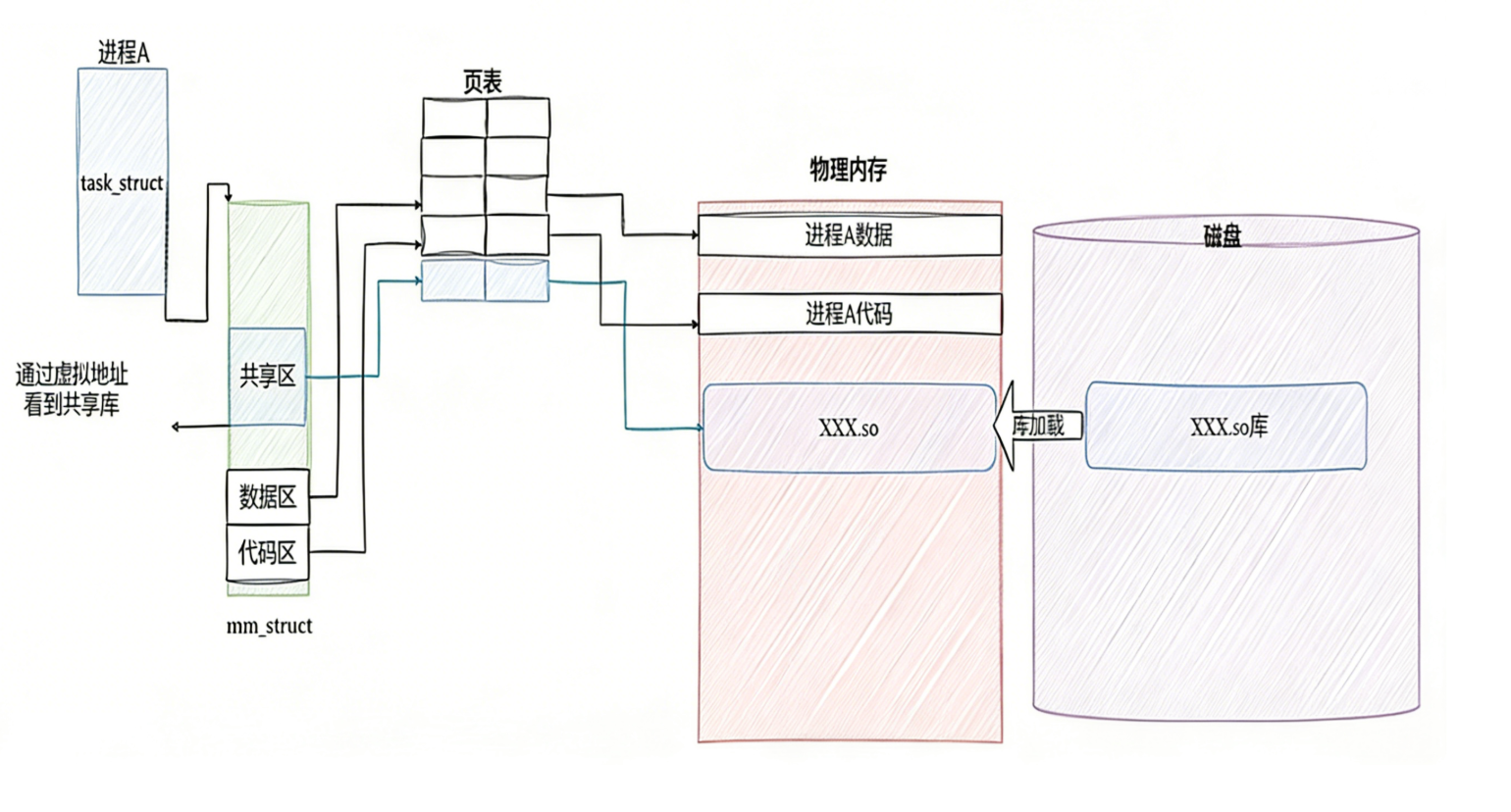
1.进程如何看到动态库的
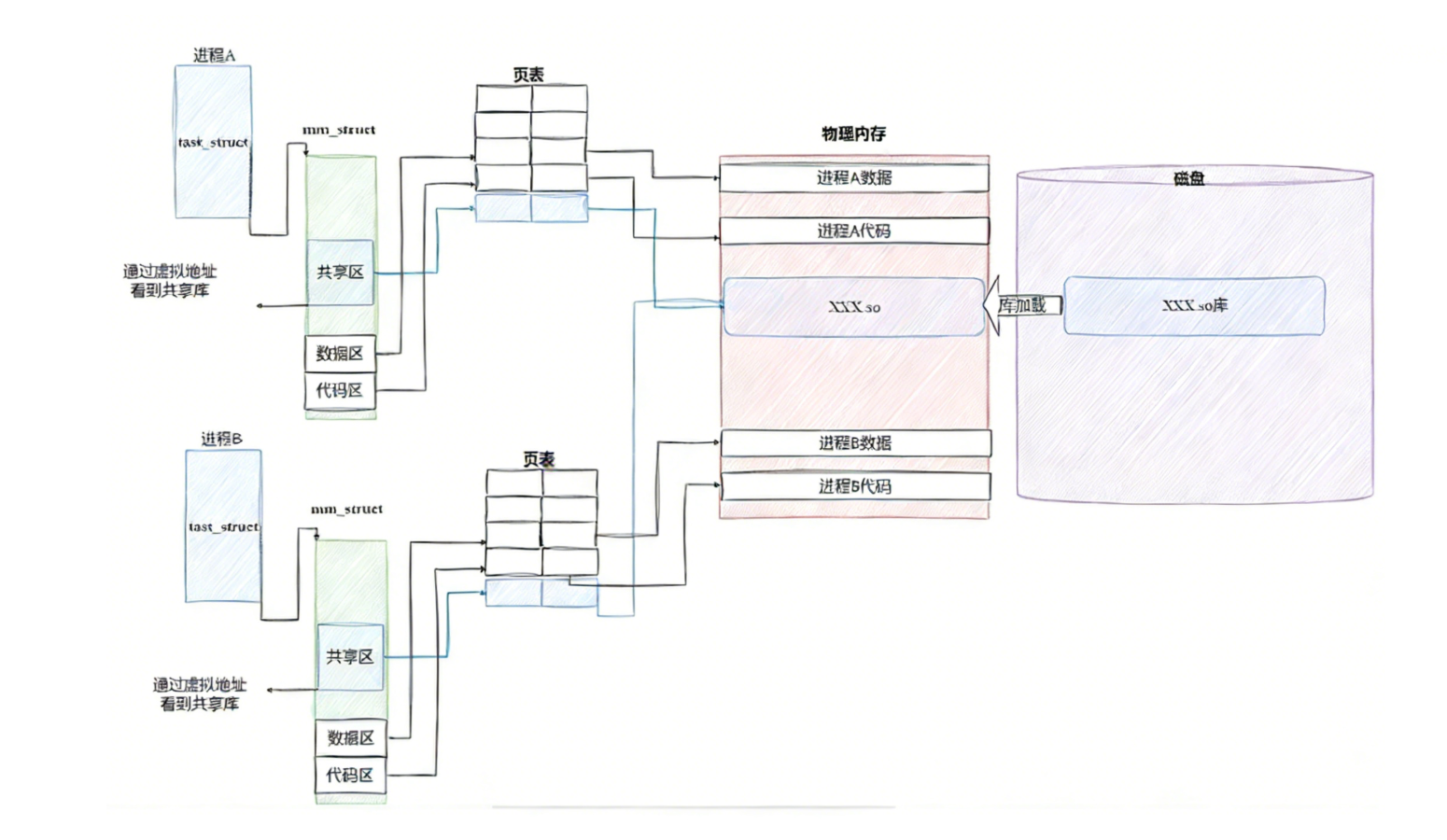
2.进程之间如何共享库的
3.动态链接
动态链接其实远比静态链接要常用得多。比如我们查看下hello这个可执行程序依赖的动态库,会发现它就用到了一个 c 动态链接库:
bash
zhangsan@hcss-ecs-f571:~/learn_-linux/ku/mystdio/friend$ ldd main
linux-vdso.so.1 (0x00007ffdcb56f000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ded44800000)
/lib64/ld-linux-x86-64.so.2 (0x00007ded44b17000)
# ldd命令用于打印程序或者库文件所依赖的共享库列表。这里的libc.so是 C 语言的运行时库,里面提供了常用的标准输入输出文件字符串处理等等这些功能。
**那为什么编译器默认不使用静态链接呢?**静态链接会将编译产生的所有目标文件,连同用到的各种库,合并形成一个独立的可执行文件,它不需要额外的依赖就可以运行。照理来说应该更加方便才对是吧?
静态链接最大的问题在于生成的文件体积大,并且相当耗费内存资源。随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费大量的硬盘空间。
**这个时候,动态链接的优势就体现出来了,**我们可以将需要共享的代码单独提取出来,保存成一个独立的动态链接库,等到程序运行的时候再将它们加载到内存,这样不但可以节省空间,因为同一个模块在内存中只需要保留一份副本,可以被不同的进程所共享。
动态链接到底是如何工作的?
首先要交代一个结论,动态链接实际上将链接的整个过程推迟到了程序加载的时候。 比如我们去运行一个程序,操作系统会首先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使用情况为它们动态分配一段内存。当动态库被加载到内存以后,一旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
也就是说:我们的可执行程序被编译器动了手脚
在 C/C++ 程序中,当程序开始执行时,它首先并不会直接跳转到main函数。实际上,程序的入口点是_start,这是一个由 C 运行时库(通常是 libc)或链接器(如 ld)提供的特殊函数。
在_start函数中,会执行一系列初始化操作,这些操作包括:
1.设置堆栈:为程序创建一个初始的堆栈环境。
2.初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
3.动态链接 :这是关键的一步,_start函数会调用动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地址。
动态链接器:
- 动态链接器(如
ld-linux.so)负责在程序运行时加载动态库。- 当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。
环境变量和配置文件:
- Linux 系统通过环境变量(如
LD_LIBRARY_PATH)和配置文件(如/etc/ld.so.conf及其子配置文件)来指定动态库的搜索路径。- 这些路径会被动态链接器在加载动态库时搜索。
缓存文件:
- 为了提高动态库的加载效率,Linux 系统会维护一个名为
/etc/ld.so.cache的缓存文件。- 该文件包含了系统中所有已知动态库的路径和相关信息,动态链接器在加载动态库时会首先搜索这个缓存文件。
4.调用__libc_start_main :一旦动态链接完成,_start函数会调用__libc_start_main(这是 glibc 提供的一个函数)。__libc_start_main函数负责执行一些额外的初始化工作,比如设置信号处理函数、初始化线程库(如果使用了线程)等。
5.调用main函数 :最后,__libc_start_main函数会调用程序的main函数,此时程序的执行控制权才正式交用户编写的代码。
6.处理main函数的返回值 :当main函数返回时,__libc_start_main会负责处理这个返回值,并最终调用_exit函数来终止程序。
上述过程描述了 C/C++ 程序在main函数之前执行的一系列操作,但这些操作对于大多数程序员来说是一个黑盒子的。程序员通常只需要关注main函数中的代码,而不需要关心底层的初始化过程。然而,了解这些底层细节有助于更好地理解程序的执行流程和调试问题
4.动态库中的相对地址
动态库为了随时进行加载,为了支持并映射到任意进程的任意位置,对动态库中的方法,统一编址,采用相对编址的方案进行编制的(其实可执行程序也一样,都要遵守平坦模式,只不过 exe 是直接加载的)。
5.我们的程序,怎么和库具体映射起来的
⚠️ 注意:
- 动态库也是一个文件,要访问也是要被先加载,要加载也是要被打开的
- 让我们的进程找到动态库的本质:也是文件操作,不过我们访问函数,通过虚拟地址进行跳转访问的,所以需要把动态库映射到进程的地址空间中。
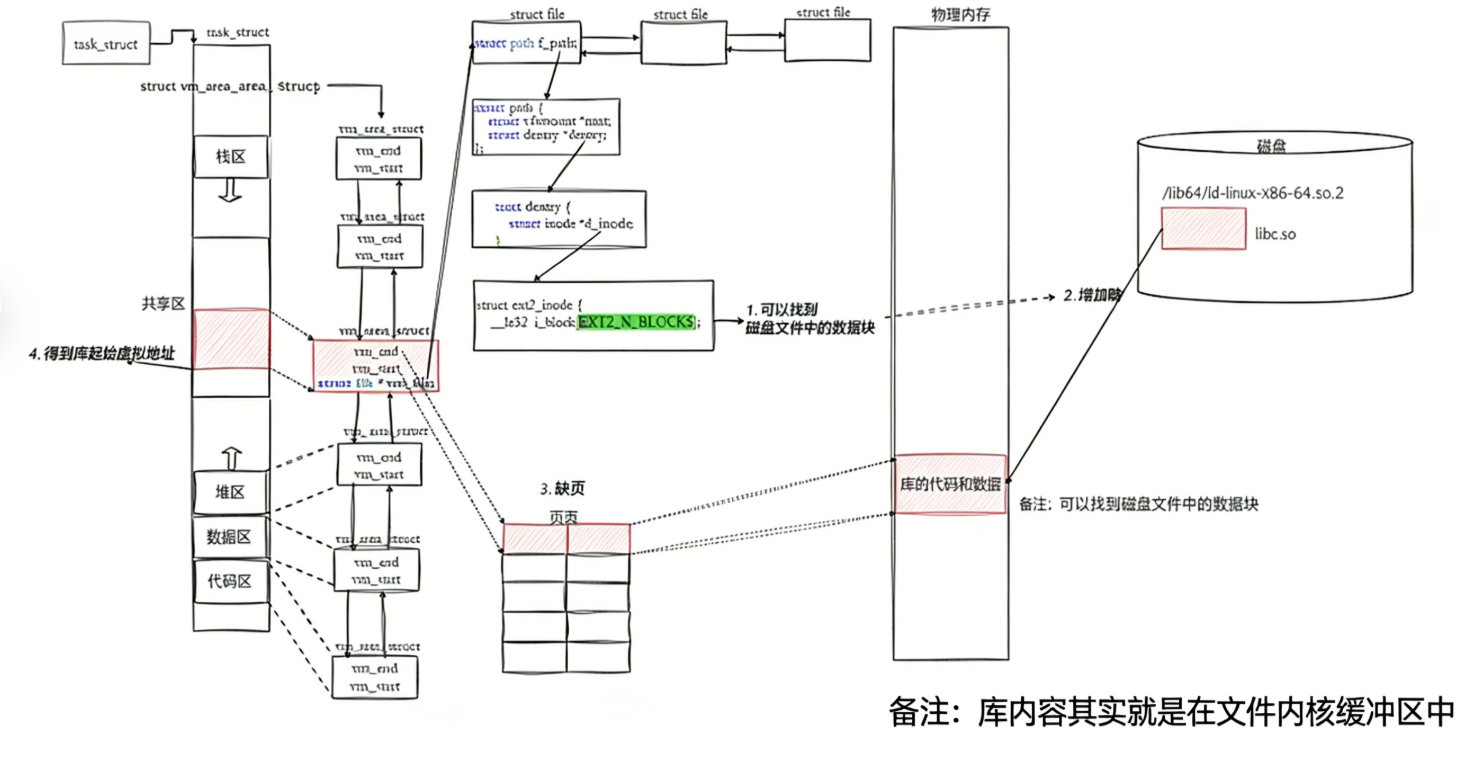
6.我们的程序,怎么进行库函数调用
⚠️ 注意:
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每一个方法的偏移量地址我们也知道
- 所以:访问库中任意方法,只需要知道库的起始虚拟地址 + 方法偏移量即可定位库中的方法
- 而且:整个调用过程,是从代码区跳转到共享区,调用完毕在返回到代码区,整个过程完全在进程地址空间中进行的.
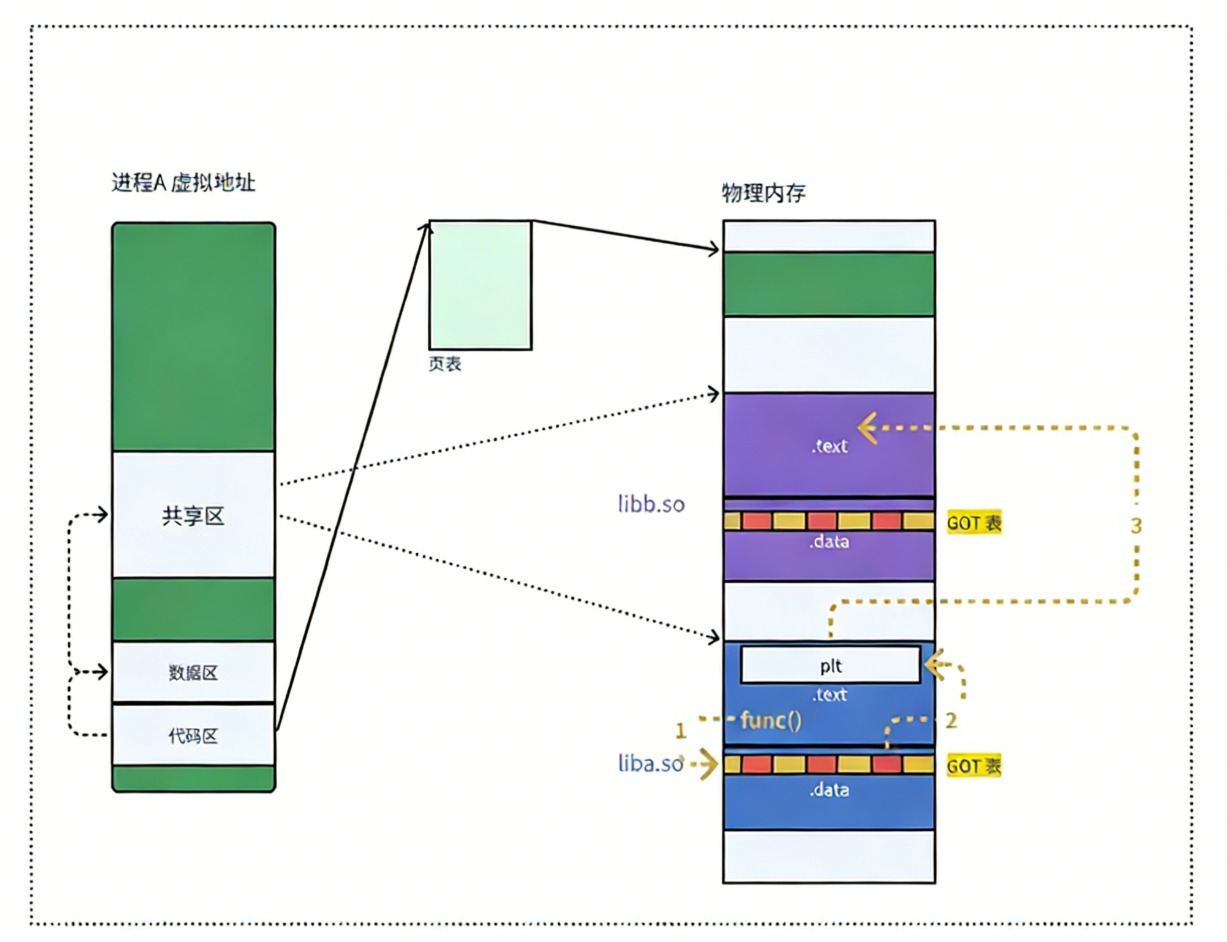
7.全局偏移量表 GOT (global offset table)
⚠️ 注意:
- 也就是说,我们的程序运行之前,先把所有库加载并映射,所有库的起始虚拟地址应该提前知道
- 然后对我们加载到内存中的程序的库函数调用进行地址修改,在内存中二次完成地址设置(这个叫做加载地址重定位)
- 等等,修改的是代码区?不是说代码区在进程中是只读的吗?怎么修改?能修改吗?
所以:动态链接采用的做法是在.data(可执行程序或者库自己)中专门预留一片区域用来存放函数的跳转地址,它也被叫做全局偏移表 GOT,表中每一项都是本运行模块要引用的一个全局变量或函数的地址。
- 因为
.data区域是可读写的,所以可以支持动态进行修改
bash
$ readelf -S main
...
[24] .got PROGBITS 0000000000003fb8 00002fb8
0000000000000048 0000000000000000 WA 0 0 8
...
$ readelf -l a.out # .got在加载的时候,会和.data合并成为一个segment,然后加载在一起
...
05 .init_array .fini_array .dynamic .got .data .bss
...关于 GOT 的补充说明:
- 由于代码段只读,我们不能直接修改代码段。但有了 GOT 表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到 GOT 表上,就是每个进程的每个动态库都有独立的 GOT 表,所以进程间不能共享 GOT 表。
- 在单个.so 下,由于 GOT 表与
.text的相对位置是固定的,我们完全可以利用 CPU 的相对寻址来找到 GOT 表。 - 在调用函数的时候会首先查表,然后根据表中的地址来进行跳转,这些地址在动态库加载的时候会被修改为真正的地址。
- 这种方式实现的动态链接就被叫做 PIC(地址无关代码)。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运行,并且能够被所有进程共享,这也是为什么之前我们给编译器指定 - fPIC 参数的原因,PIC = 相对编址 + GOT。
9.库间依赖 (了解)
注意:
- 不仅仅有可执行程序调用库
- 库也会调用其他库!库之间是有依赖的,如何做到库和库之间互相调用也是与地址无关的呢?
- 库中也有 GOT, 和可执行一样!这也就是为什么大家为什么都是 ELF 的格式!
由于 GOT 表中的映射地址会在运行时去修改,我们可以通过 gdb 调试去观察 GOT 表的地址变化。在这里我们只需要知道原理即可,有兴趣的可以参考:使用 gdb 调试 GOT
- 由于动态链接在程序加载的时候需要对大量函数进行重定位,这一步显然是非常耗时的。为了进一步降低开销,我们的操作系统还做了一些其他的优化,比如延迟绑定 ,或者也叫 PLT(过程链接表(Procedure Linkage Table))。与其在程序一开始就对所有函数进行重定位,不如将这个过程推迟到函数第一次被调用的时候,因为绝大多数动态库中的函数可能在程序运行期间一次都不会被使用到。
- 思路是:GOT 中的跳转地址默认会指向一段辅助代码,它也被叫做桩代码 /stub。在我们第一次调用函数的时候,这段代码会负责查询真正函数的跳转地址,并且去更新 GOT 表。于是我们再次调用函数的时候,就会直接跳转到动态库中真正的函数实现。
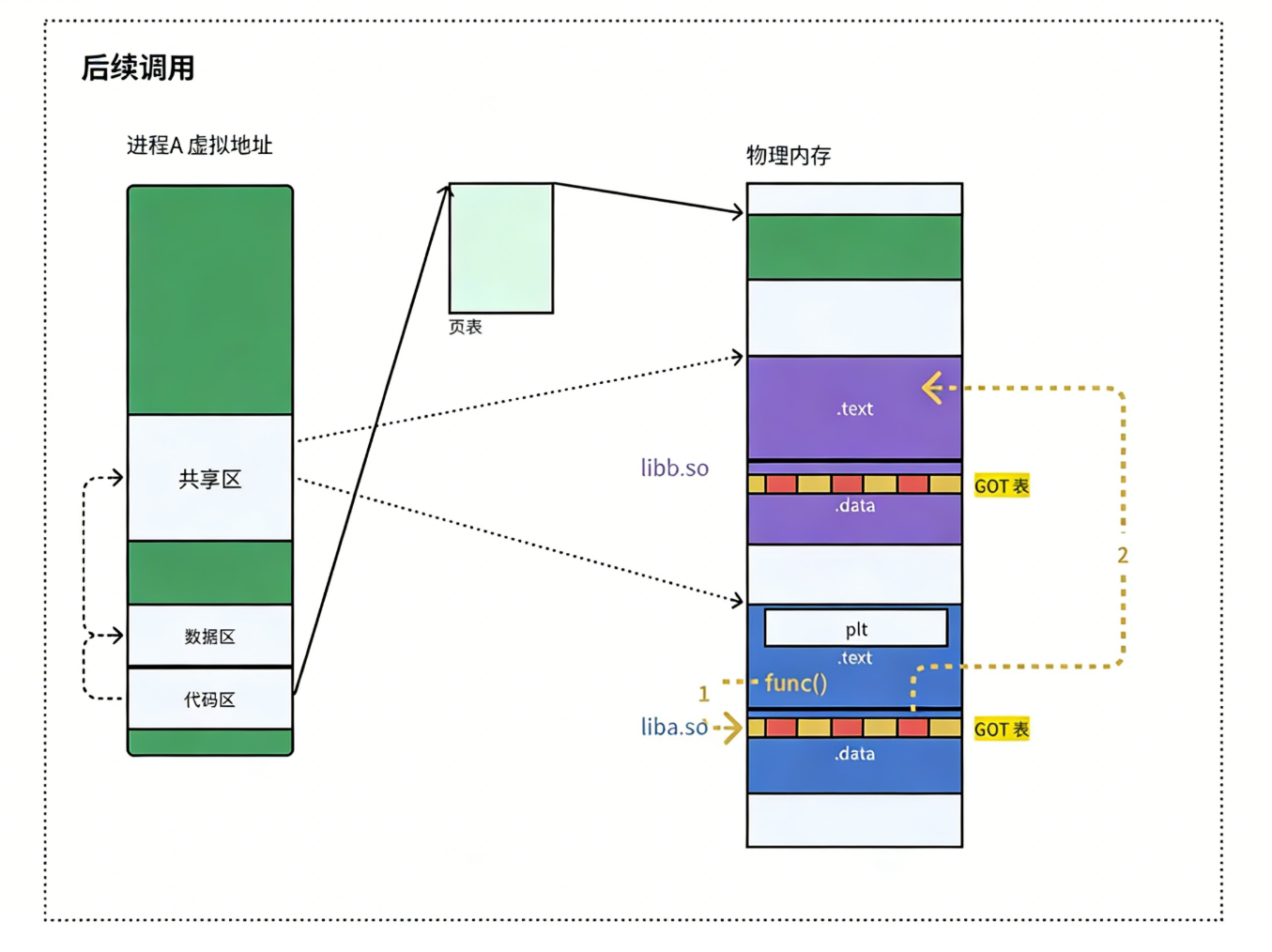
总而言之,动态链接实际上将链接的整个过程,比如符号查询、地址的重定位从编译时推迟到了程序的运行时,它虽然牺牲了一定的性能和程序加载时间,但绝对是物有所值的。因为动态链接能够更有效的利用磁盘空间和内存资源,以极大方便了代码的更新和维护,更关键的是,它实现了二进制级别的代码复用。
⚠️ 解析依赖关系的时候,就是加载并完善互相之间的 GOT 表的过程.
总结
- 静态链接的出现,提高了程序的模块化水平。对于一个大的项目,不同的人可以独立地测试和开发自己的模块。通过静态链接,生成最终的可执行文件。
- 我们知道静态链接会将编译产生的所有目标文件,和用到的各种库合并成一个独立的可执行文件,其中我们会去修正模块间函数的跳转地址,也被叫做编译重定位 (也叫做静态重定位)。
- 而动态链接实际上将链接的整个过程推迟到了程序加载的时候。比如我们去运行一个程序,操作系统会首先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,但是无论加载到什么地方,都要映射到进程对应的地址空间,然后通过.GOT 方式进行调用 (运行重定位,也叫做动态地址重定位)。