通过可扩展查找的条件记忆:大型语言模型稀疏性的新维度
摘要
Engram 是一个对经典 N-gram 嵌入进行现代化的模块,用于 O(1) 查找。通过构建稀疏性分配问题,我们发现了一个 U 形缩放定律,该定律优化了神经计算 (MoE) 和静态记忆 (Engram) 之间的权衡。我们将 Engram 扩展到 270 亿参数,与严格的同参数和同 FLOPs 的 MoE 基线相比,实现了卓越的性能。最值得注意的是,虽然记忆模块有望帮助知识检索(例如,MMLU +3.4;CMMLU +4.0),但我们观察到在一般推理(例如,BBH +5.0;ARC-Challenge +3.7)和代码/数学领域(HumanEval +3.0;MATH +2.4)中,增益甚至更大。机制分析表明,Engram 解除了骨干网络早期层对静态重建的负担,有效地加深了网络以进行复杂的推理。此外,通过将局部依赖关系委托给查找,它可以释放注意力容量以用于全局上下文,从而大大提高了长上下文检索能力(例如,MultiQuery NIAH:84.2 → 97.0)。最后,Engram 建立了感知基础设施的效率:其确定性寻址能够从主机内存中进行运行时预取,从而产生可忽略不计的开销。我们设想条件记忆是下一代稀疏模型不可或缺的建模原语。
1. 介绍
稀疏性是智能系统的一个反复出现的设计原则,主要通过混合专家(MoE)实现。
尽管这种条件计算范式取得了成功,但语言信号固有的异质性表明在结构优化方面仍有很大的空间。具体而言,语言建模包含两个性质上不同的子任务:组合推理和知识检索。虽然前者需要深入的动态计算,但文本的很大一部分------例如命名实体和公式化模式------是局部的、静态的和高度刻板的。经典 N-gram 模型(Brants et al., 2007; Liu et al., 2024b; Nguyen, 2024)在捕获此类局部依赖关系方面的有效性表明,这些规律自然地表示为计算成本低廉的查找。
由于标准 Transformer(Vaswani et al., 2017)缺乏原生的知识查找原语,因此当前的 LLM 不得不通过计算来模拟检索。例如,解析一个常见的由多个 token 组成的实体需要消耗多个注意力机制的早期层和前馈网络(Ghandeharioun et al., 2024; Jin et al., 2025)(见表NT83)。这个过程本质上相当于对静态查找表进行昂贵的运行时重建,将宝贵的序列深度浪费在琐碎的操作上,而这些深度原本可以分配给更高层次的推理。
为了使模型架构与这种语言二元性对齐,我们提倡一种互补的稀疏性轴:条件记忆。条件计算稀疏地激活参数以处理动态逻辑。而条件记忆则依赖于稀疏的查找操作来检索固定知识的静态嵌入。作为对这种范式的一个初步探索,我们重新审视 N-gram 嵌入(Bojanowski et al., 2017)作为一个规范的实例化:局部上下文充当一个键,通过常数时间 O (1) 查找来索引一个巨大的嵌入表。
我们的研究表明,也许令人惊讶的是,这种静态检索机制可以作为现代 MoE 架构的理想补充------但前提是它经过适当的设计。在本文中,我们提出了 Engram,一个基于经典 N-gram 结构的条件记忆模块 ,但配备了现代化的适配,例如分词器压缩、多头哈希、上下文门控和多分支集成(详见第 2 节)。
备注:上下文作为一个key,是将哪些作为上下文?
为了量化这两种原语之间的协同作用,我们提出了稀疏性分配问题:在给定的固定总参数预算下,应该如何在 MoE 专家和 Engram 内存之间分配容量?我们的实验揭示了一个独特的 U 形缩放规律,表明即使是简单的查找机制,当被视为一流的建模原语时,也可以作为神经计算的重要补充。在这一分配规律的指导下,我们将 Engram 扩展到 270 亿参数的模型。与严格的等参数和等 FLOPs 的 MoE 基线相比,Engram-27B 在不同的领域都实现了卓越的效率。
备注:比直接将参数增加到MOE上要好
通过 LogitLens(nostalgebraist,2020)和 CKA(Hendrycks et al., 2021a)进行的机制分析揭示了这些收益的来源:Engram 减轻了早期层中主干网络重建静态知识的负担,从而增加了可用于复杂推理的有效深度。此外,通过将局部依赖关系委托给查找,Engram 释放了注意力容量,使其能够专注于全局上下文,从而在长上下文场景中实现卓越的性能------在 LongPPL(Fang et al.)和 RULER(Hsieh et al.)上大大优于基线(例如,Multi-Query NIAH:97.0 vs. 84.2;Variable Tracking:89.0 vs. 77.0)。
备注:LogitLens和 CKA是什么?
最后,我们将感知基础设施的效率确立为首要原则。与MoE的动态路由不同,Engram采用确定性ID来实现运行时预取,使通信与计算重叠。经验结果表明,将一个1000亿参数的表卸载到主机内存所产生的开销可忽略不计(< 3%)。这表明Engram有效地绕过了GPU内存的限制,从而促进了积极的参数扩展。
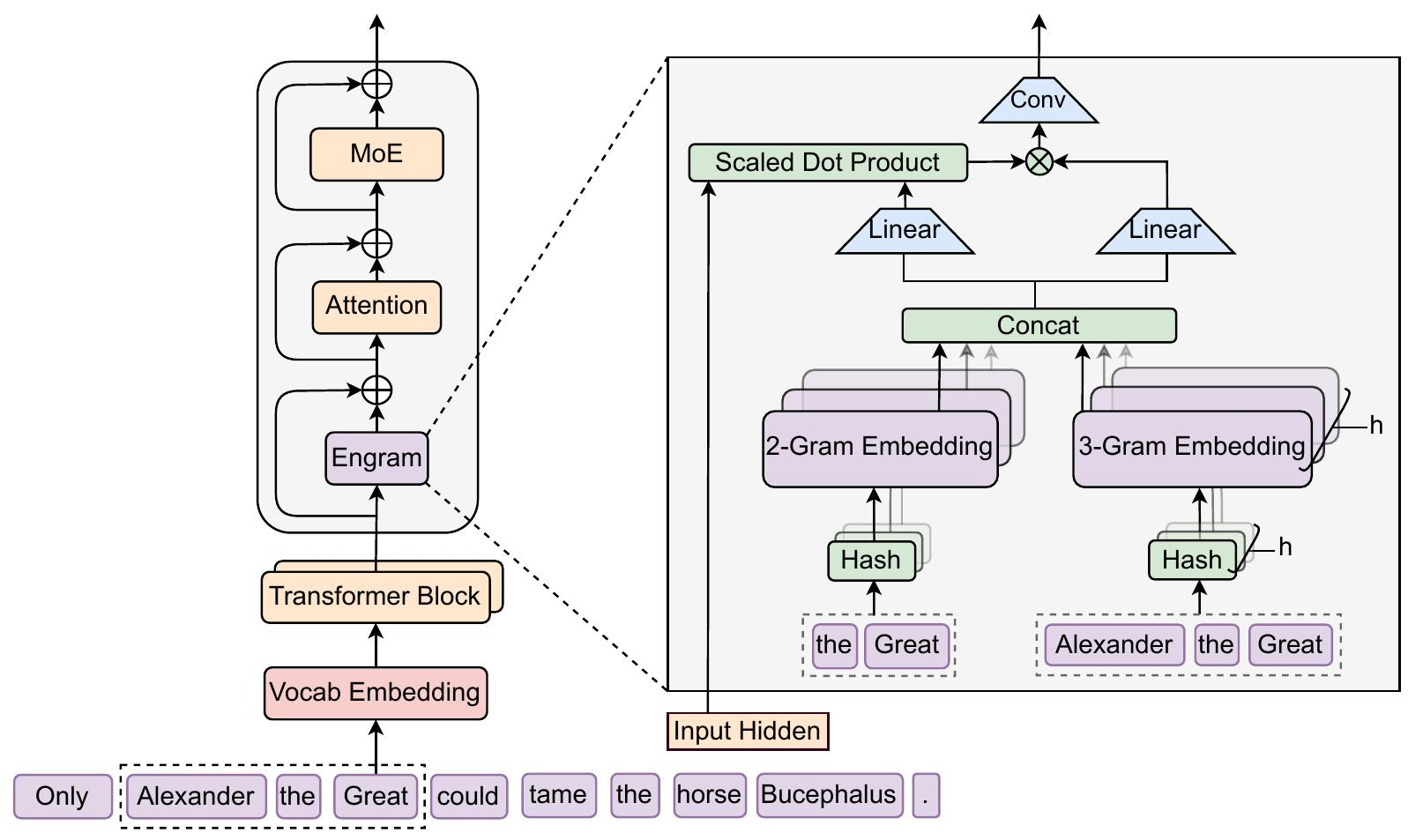

2. 架构
2.1. 概述

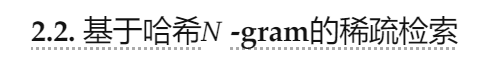
第一阶段将局部上下文映射到静态内存条目,涉及分词器压缩和通过确定性哈希检索嵌入。


补充: ngram介绍(来自元宝)
N-GRAM是一种基于统计的语言模型,它通过统计文本中连续N个词(或字符)出现的频率来预测下一个词的概率。N表示连续词序列的长度,当N=1时称为unigram(单字),N=2时称为bigram(双字),N=3时称为trigram(三字),以此类推。
核心原理
N-GRAM模型基于马尔可夫假设,即当前词的出现只依赖于前面N-1个词。例如,在bigram模型中,一个词的出现只依赖于前一个词,概率公式为:
P(wₙ|w₁, w₂, ..., wₙ₋₁) ≈ P(wₙ|wₙ₋₁)
概率预测应用示例
假设我们有一个小型语料库:
"我喜欢吃苹果"
"我喜欢吃香蕉"
"我喜欢喝牛奶"
1. 计算词频统计:
-
我:3次
-
喜欢:3次
-
吃:2次
-
喝:1次
-
苹果:1次
-
香蕉:1次
-
牛奶:1次
2. 预测下一个词:
场景1:预测"我喜欢"后面接什么词?
使用bigram模型:
-
P(吃|喜欢) = count(喜欢 吃) / count(喜欢) = 2/3 ≈ 0.667
-
P(喝|喜欢) = count(喜欢 喝) / count(喜欢) = 1/3 ≈ 0.333
结论:最可能接"吃"(概率66.7%)
场景2:预测"我喜欢吃"后面接什么词?
使用trigram模型:
-
P(苹果|喜欢 吃) = count(喜欢 吃 苹果) / count(喜欢 吃) = 1/2 = 0.5
-
P(香蕉|喜欢 吃) = count(喜欢 吃 香蕉) / count(喜欢 吃) = 1/2 = 0.5
结论:可能接"苹果"或"香蕉"(各50%概率)
实际应用领域
1. 输入法预测:根据用户已输入的前几个字,预测下一个最可能输入的字或词。
2. 拼写纠错:当用户输入"我喜欢迟苹果"时,系统通过N-GRAM模型发现"迟"与"吃"发音相似,且"喜欢 吃"的共现概率远高于"喜欢 迟",从而建议纠正为"吃"。
3. 机器翻译:在翻译过程中,使用N-GRAM模型确保目标语言生成流畅、自然的句子。
4. 语音识别:结合声学模型,通过语言模型(N-GRAM)提高识别准确率,区分同音词。
优缺点
优点:
-
计算简单,易于实现
-
在数据充足时效果较好
-
可处理大规模语料
缺点:
-
数据稀疏问题(很多N元组在训练语料中未出现)
-
无法捕捉长距离依赖关系
-
需要大量训练数据
N-GRAM模型虽然简单,但在自然语言处理领域有着广泛的应用,是许多复杂模型的基础组件。
2.3. 上下文感知门控


备注:检索到的知识可能是无关的,需要参考注意力机制筛选相关的知识。增加Wk和Wv投影后就相当于k和v。


备注:主要是为了扩大感受野和增加模型的非线性,相当于能够捕捉到更丰富的信息,之前有做过将注意力替换为卷积的实验,是有效的。

备注:并不是应用于每一层
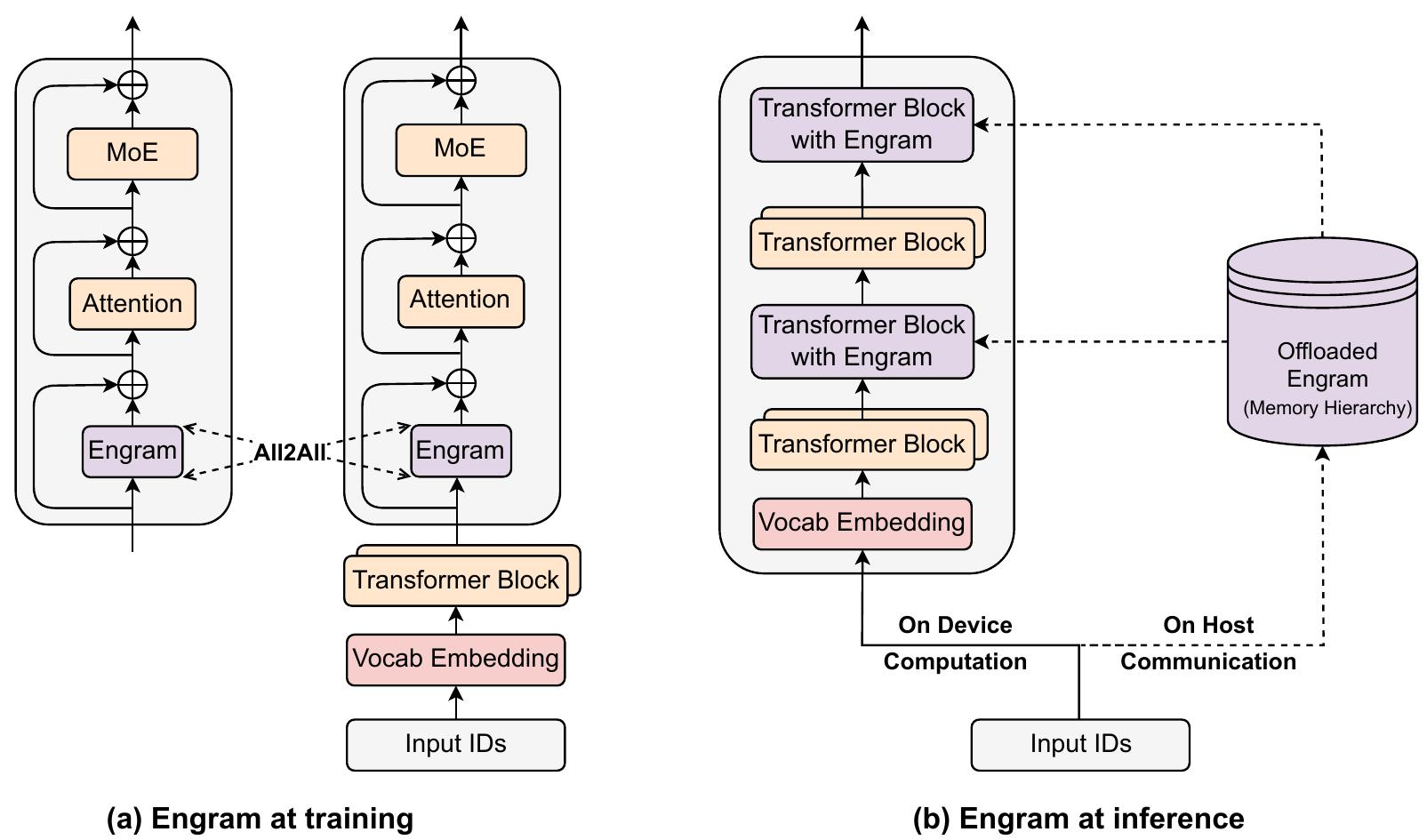

备注:训练时在GPU中,推理时在主机内存中,实际场景需要配置这么大的内存,是比较恐怖的
2.4. 与多分支架构的集成



2.5. 系统效率:解耦计算与内存
扩展内存增强模型通常受到GPU高带宽内存(HBM)有限容量的制约。然而,Engram的确定性检索机制自然支持参数存储与计算资源的分离。与MoE不同,MoE依赖于运行时隐藏状态进行动态路由,而Engram的检索索引仅依赖于输入token序列。正如Figure 2所示,这种可预测性有助于训练和推理的专门优化策略。
在训练期间,为了适应大规模嵌入表,我们采用标准模型并行策略,通过在可用的GPU上对表进行分片 。使用All-to-All通信原语在前向传播中收集活动行,并在反向传播中分派梯度,从而使总内存容量能够随着加速器的数量线性扩展。
在推理过程中,这种确定性使得预取和重叠策略成为可能。由于内存索引在正向传递之前已知,系统可以通过PCIe从丰富的host内存中异步检索嵌入 。为了有效地掩盖通信延迟,Engram模块被放置在backbone中的特定层,利用前置层的计算作为缓冲区,以防止GPU停顿。这需要一种硬件-算法协同设计策略:虽然将Engram放置得更深可以扩展可用于隐藏延迟的计算窗口,但我们在第6.2节中的消融实验表明,建模性能更倾向于早期干预以卸载局部模式重建。因此,最佳放置必须同时满足建模和系统延迟约束。
此外,自然语言N元语法本质上遵循齐夫分布(Chao and Zipf, 1950; Piantadosi, 2014),其中一小部分模式占据了绝大多数的内存访问。这种统计特性促使我们采用多级缓存体系结构:频繁访问的嵌入可以缓存在更快的存储层(例如,GPU HBM或Host DRAM )中,而罕见模式的长尾则驻留在速度较慢、容量较大的介质(例如,NVMe SSD)中。这种分层结构使得Engram能够扩展到海量内存容量,同时对有效延迟的影响最小。
3. 缩放定律与稀疏性分配
记忆痕迹,作为条件记忆的实例化,在结构上与MoE专家提供的条件计算形成互补。本节研究这种对偶性的缩放特性,以及如何优化分配稀疏容量。具体来说,以下两个关键问题驱动着我们的研究:
-
有限约束下的分配。当总参数和训练计算量固定时(等参数和等 FLOPs),我们应该如何在 MoE 专家和 Engram 嵌入之间分配稀疏容量?
-
无限内存机制。考虑到 Engram 的非规模化 O(1) 开销,如果内存预算放宽或积极扩展,Engram 本身会表现出什么样的扩展行为?
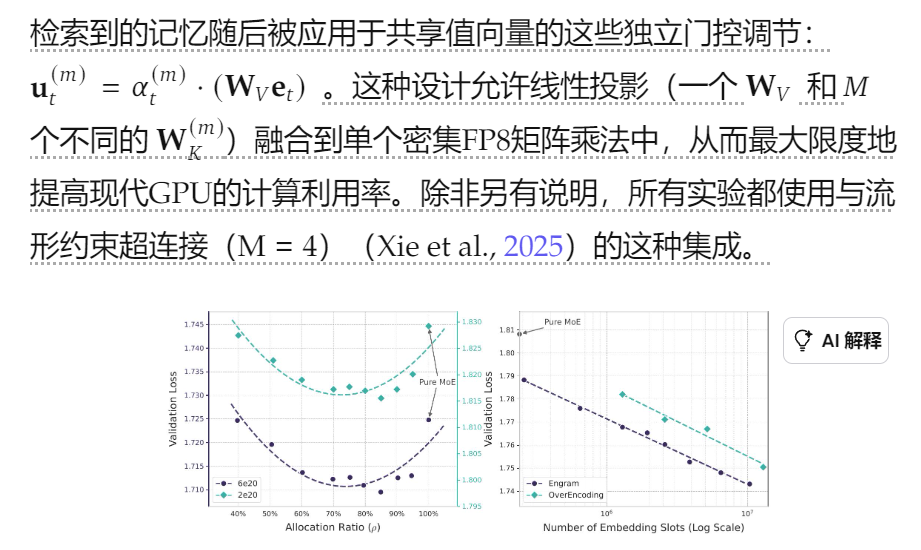
3.1. MoE与Engram之间的最佳分配比例

3.2. 无限记忆机制下的印迹
4. 大规模预训练
训练数据和模型配置 所有模型均在包含2620亿个token的语料库上进行预训练,我们使用DeepSeek-v3 (Liu et al., 2024a) 中的tokenizer,词汇量大小为128k。对于建模,为了确保受控比较,除非另有明确说明,否则我们坚持所有模型采用一致的默认设置。我们使用一个30块的Transformer,隐藏层大小为2560。每个块集成了一个多头潜在注意力(MLA)(DeepSeek-AI et al., 2024),具有32个头,通过mHC(Xie et al., 2025)连接到FFN,扩展率为4。所有模型均使用Muon进行优化(Jordan et al., 2024; Team et al., 2025);详细的超参数列于附录A中。我们实例化了四个不同的模型:
备注:这里使用了mHC和Muon
5. 长文本训练
通过将局部依赖建模卸载到静态查找,Engram架构保留了宝贵的注意力容量,用于管理全局上下文。在本节中,我们通过进行长上下文扩展训练(Gao et al., 2025; Peng et al., 2024)来实证验证这种结构优势。通过严格的评估协议,将架构贡献与基础模型能力隔离开来,我们证明Engram在远距离检索和推理任务中产生了显著的收益。