

在当今数据驱动的时代,网页数据采集是获取行业洞察、支撑业务决策的核心手段。但随着网站IP限制机制升级,IP固定、访问限制等问题频繁出现,导致采集任务中断、数据获取不完整。IPIDEA作为全球领先的企业级代理服务提供商,凭借99.9%可用率的纯净IP资源、亿级并发承载能力及多场景适配优势,成为解决采集难题的关键工具。本文将从环境搭建到实战案例,带您掌握Python+IPIDEA的高效数据采集方案。

一、IPIDEA代理:数据采集的"加速器"与"防护盾"
在开始Python实战前,先了解IPIDEA为何能成为企业级数据采集的首选代理服务------其核心优势完美匹配采集场景的核心需求:
| 核心优势 | 对数据采集的价值 |
|---|---|
| 全球1亿级+纯净住宅IP | 模拟真实用户访问,规避网站对"非住宅IP"的拦截,适用于电商、社媒等场景 |
| 99.9%IP可用率 | 减少因IP失效导致的采集中断,保障任务连续性,尤其适合大规模、长时间采集任务 |
| 无限并发请求 | 支持亿级并发承载,可同时发起多线程/多进程采集,大幅提升数据获取效率 |
| 多类型代理全覆盖 | 动态住宅(自动变更)、静态住宅(长效稳定)、数据中心(高速低延迟)等,适配不同场景 |
| 安全合规认证 | 通过ISO9001&ISO27001认证,IP来源合规,避免因"违规IP"导致业务风险 |
| 1V1定制化服务 | 可根据采集目标地区、频率、业务类型定向优化IP资源,例如"定向提取美国电商IP" |
目前,阿里巴巴、华为、美图、Lazada等企业已将IPIDEA用于数据采集、跨境业务支撑,其稳定性和合规性经过了千万级任务验证。
二、实战准备:3步完成IPIDEA与Python环境配置
2.1 注册IPIDEA账号,获取代理授权
- 访问IPIDEA官网,完成注册并登录(支持手机验证码快速登录);
- 进入【个人中心 】-【代理管理】,根据采集需求选择代理类型(新手推荐"动态住宅代理",适配多数场景);
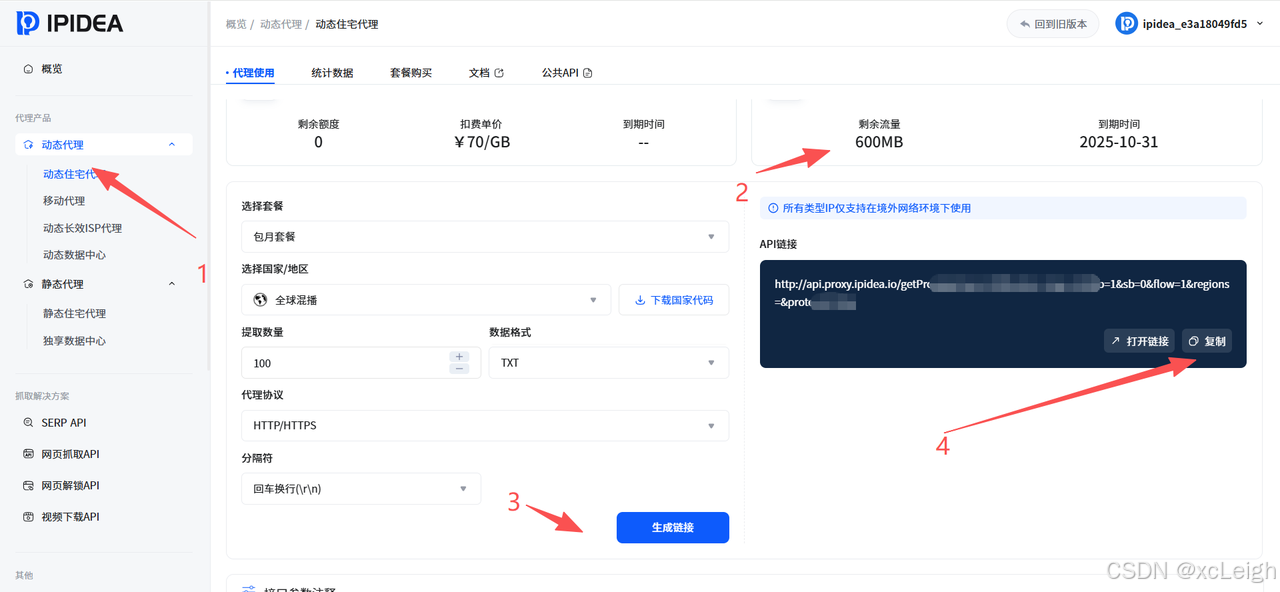
- 充值并获取账密认证信息(用户名+密码,用于自动化获取IP)或API提取链接(用于自动化获取IP),同时记录代理服务器地址(默认:
proxy.ipidea.io:2333); - 添加本地IP到【白名单】:在【安全设置】中添加当前设备的公网IP,避免非授权设备使用代理,提升安全性。
提示:IPIDEA提供免费测试额度,新用户可先试用,验证IP可用性与采集效果后再正式充值。
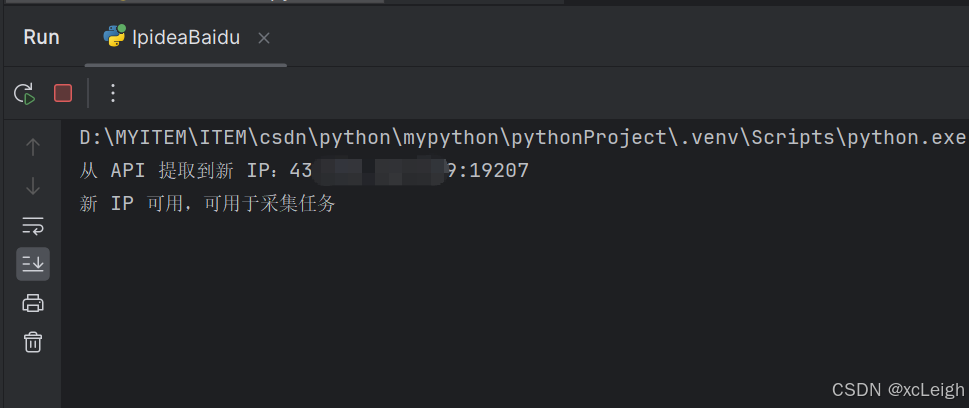
获取动态IP的API
2.2 安装Python采集必备库
数据采集常用Python库包括requests(发起HTTP请求)、BeautifulSoup4(解析HTML数据)、lxml(高效解析器)、threading(多线程加速),通过pip一键安装:
python
# 安装核心库
pip install requests beautifulsoup4 lxmlrequests:负责通过代理向目标网站发起请求,是采集的"通信桥梁";BeautifulSoup4+lxml:配合解析网页HTML结构,提取商品价格、评论、排名等目标数据;- 若需处理JavaScript渲染的动态网页(如淘宝、抖音),可额外安装
selenium或playwright:
python
pip install selenium playwright2.3 核心配置:Python代理连接模板
IPIDEA支持账密认证 和API提取两种代理使用方式,以下是两种方式的基础配置模板,适用于90%以上的采集场景。
方式 1:账密认证(快速上手,适合小规模采集)
直接使用用户名和密码配置代理,无需频繁获取新IP,适合短时间、固定场景采集,完整实现代码如下:
python
import requests
from bs4 import BeautifulSoup
# 1. IPIDEA 代理配置(替换为你的用户名和密码)
IPIDEA_USER = "你的IPIDEA用户名"
IPIDEA_PASS = "你的IPIDEA密码"
PROXY_HOST = "proxy.ipidea.io"
PROXY_PORT = 2333
# 2. 构建代理链接
proxies = {
"http": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@{PROXY_HOST}:{PROXY_PORT}",
"https": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@{PROXY_HOST}:{PROXY_PORT}" # HTTPS 网站必须配置
}
# 3. 测试代理连通性(访问 IP 信息查询网站,验证是否使用代理 IP)
def test_proxy():
try:
response = requests.get(
url="https://ipinfo.ipidea.io", # IPIDEA 官方 IP 验证接口
proxies=proxies,
timeout=10 # 超时时间,避免因 IP 延迟导致卡死
)
if response.status_code == 200:
print("代理连接成功!当前 IP 信息:")
print(response.text) # 输出 IP 地址、地区、运营商等信息
return True
else:
print(f"代理连接失败,状态码:{response.status_code}")
return False
except Exception as e:
print(f"代理连接出错:{str(e)}")
return False
# 执行测试
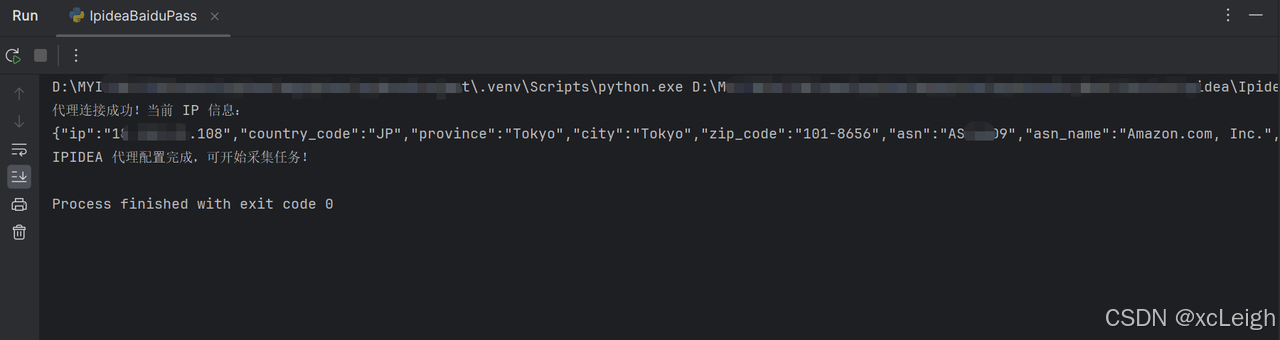
if test_proxy():
print("IPIDEA 代理配置完成,可开始采集任务!")运行成功效果:
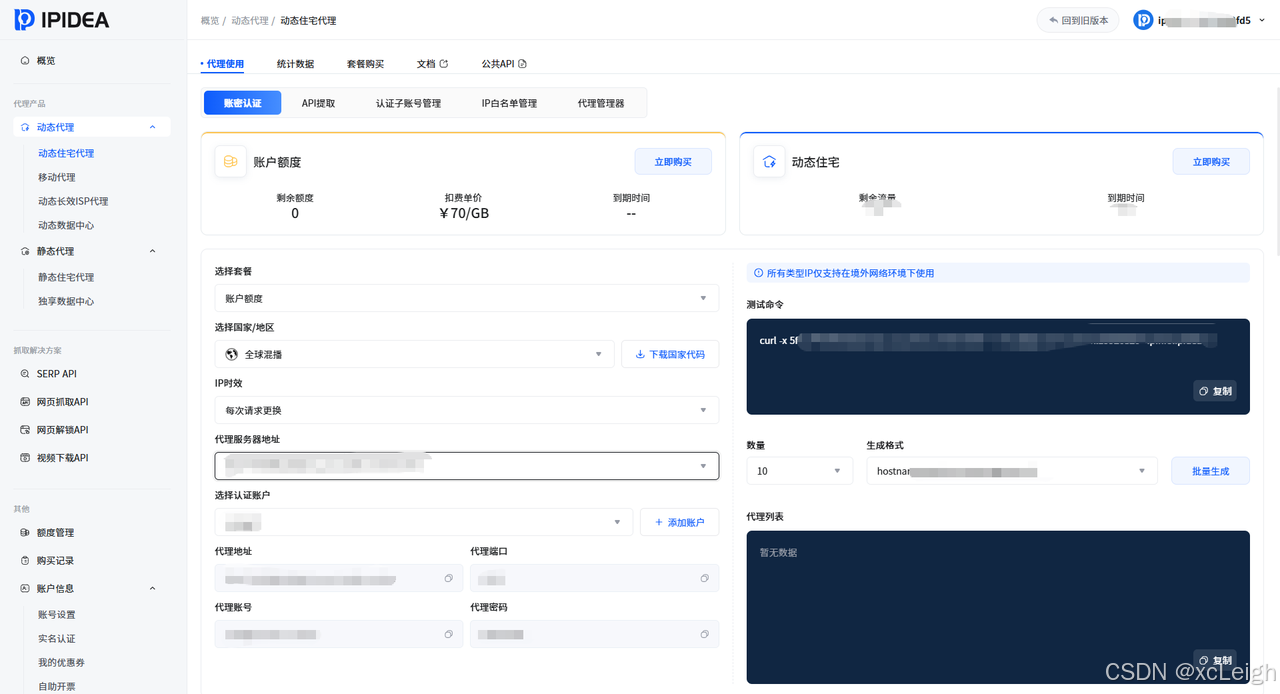
方式 2:API提取(自动化换IP,适合大规模采集)
当需要多IP(如采集IP限制网站)时,通过IPIDEA API动态提取新IP,支持自定义 IP 地区、时效(1-120分钟),完整运行代码如下:
csharp
import requests
import time
# 1. IPIDEA API 配置(从官网【API 管理】获取 API 链接)
IPIDEA_API_URL = "你的IPIDEA API提取链接" # 示例:https://api.ipidea.io/getip?num=1&type=json&lb=1&sb=0&flow=1®ions=us
# 2. 从 API 提取代理 IP
def get_proxy_from_api():
try:
response = requests.get(IPIDEA_API_URL, timeout=10)
if response.status_code == 200:
api_data = response.json()
if api_data["code"] == 0: # API 成功返回标识(具体看官网文档)
proxy_info = api_data["data"][0] # 获取第一个 IP 信息
proxy = {
"http": f"http://{proxy_info['ip']}:{proxy_info['port']}",
"https": f"http://{proxy_info['ip']}:{proxy_info['port']}"
}
print(f"从 API 提取到新 IP:{proxy_info['ip']}:{proxy_info['port']}")
return proxy
else:
print(f"API 提取失败:{api_data['msg']}")
return None
else:
print(f"API 请求失败,状态码:{response.status_code}")
return None
except Exception as e:
print(f"API 提取出错:{str(e)}")
return None
# 3. 循环提取 IP 并测试(模拟每 10 分钟换一次 IP)
while True:
proxy = get_proxy_from_api()
if proxy:
# 测试新 IP 可用性
try:
test_response = requests.get("https://www.baidu.com", proxies=proxy, timeout=5)
if test_response.status_code == 200:
print("新 IP 可用,可用于采集任务\n")
except:
print("新 IP 不可用,重新提取\n")
time.sleep(600) # 10 分钟后再次提取新 IP运行成功效果:
三、实战案例:3个场景掌握Python+IPIDEA采集技巧
以下案例覆盖"静态网页采集""电商数据采集""多线程加速采集",均基于IPIDEA动态住宅代理,规避IP限制。
案例 1:网页数据采集(以"北美票房榜"为例)
目标: 北美票房榜的"电影名称、总票房、上映日期",静态网页无JS渲染,直接用requests+BeautifulSoup即可。
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
# 1. IPIDEA 代理配置(替换为你的信息)
IPIDEA_USER = "你的用户名"
IPIDEA_PASS = "你的密码"
proxies = {
"http": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@proxy.ipidea.io:2333",
"https": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@proxy.ipidea.io:2333"
}
# 2. 采集数据
def crawl_maoyan_na_boxoffice():
"""采集猫眼北美票房榜数据(适配最新页面结构)"""
url = "https://m.maoyan.com/asgard/board/2" # 猫眼北美票房榜页面
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 17_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.2 Mobile/15E148 Safari/604.1",
"Referer": "https://m.maoyan.com/"
}
try:
response = requests.get(url,proxies, headers=headers, timeout=15, verify=False)
response.raise_for_status()
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, "lxml")
# 定位所有电影卡片(核心:class="board-card" 的 div 容器)
movie_cards = soup.find_all("div", class_="board-card")
if not movie_cards:
print("❌ 未找到电影卡片容器,可能页面结构再次更新")
return None
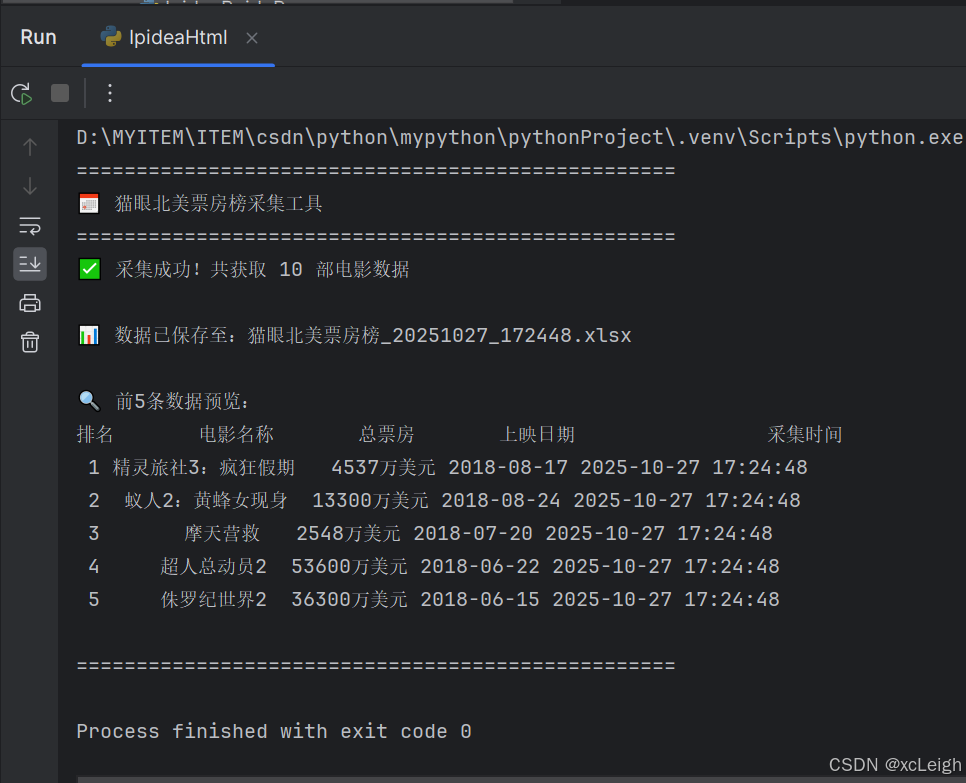
print(f"✅ 采集成功!共获取 {len(movie_cards)} 部电影数据")
return movie_cards
except requests.exceptions.HTTPError as e:
print(f"❌ HTTP错误:{e}")
except Exception as e:
print(f"❌ 未知错误:{e}")
return None
def save_to_excel(movie_cards, excel_path=None):
"""解析电影卡片并保存数据到Excel"""
if not movie_cards:
print("❌ 无有效数据可保存")
return
if not excel_path:
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
excel_path = f"猫眼北美票房榜_{current_time}.xlsx"
parsed_data = []
for card in movie_cards:
try:
# 排名(从rank-number类的i标签提取)
rank = card.find("i", class_="rank-number").get_text(strip=True)
# 电影名称(title类的h3标签)
title = card.find("h3", class_="title").get_text(strip=True)
# 总票房(从包含"总票房"的div中提取数值和单位)
boxoffice_div = card.find("div", string=lambda s: "总票房" in s)
boxoffice_text = boxoffice_div.get_text(strip=True) if boxoffice_div else "未知"
boxoffice = boxoffice_text.replace("总票房:", "")
# 上映日期(date类的div)
release_date = card.find("div", class_="date").get_text(strip=True)
except Exception as e:
print(f"⚠️ 解析单条数据出错:{e},跳过该条")
continue
parsed_data.append({
"排名": rank,
"电影名称": title,
"总票房": boxoffice,
"上映日期": release_date,
"采集时间": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
})
# 保存到Excel
try:
df = pd.DataFrame(parsed_data)
df_sorted = df.sort_values(by="排名", key=lambda x: x.astype(int), ascending=True).reset_index(drop=True)
df_sorted.to_excel(excel_path, index=False, engine="openpyxl")
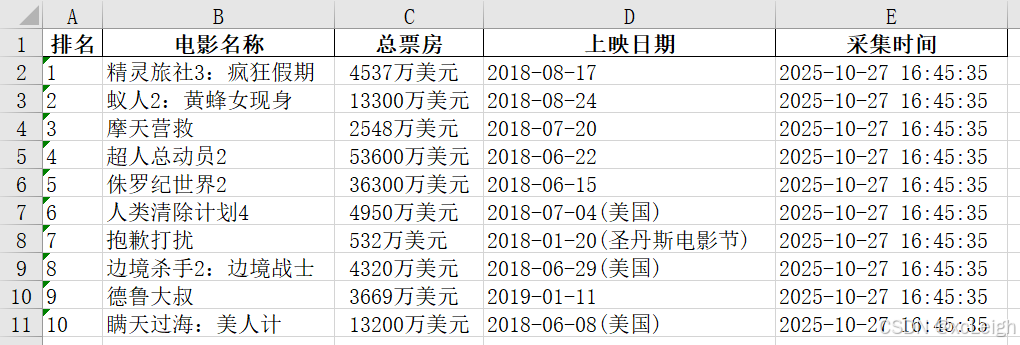
print(f"\n📊 数据已保存至:{excel_path}")
print("\n🔍 前5条数据预览:")
print(df_sorted.head().to_string(index=False))
except ModuleNotFoundError:
print("❌ 缺少依赖库,请执行:pip install pandas openpyxl lxml")
except PermissionError:
print(f"❌ 无法保存文件:{excel_path}")
except Exception as e:
print(f"❌ 保存Excel失败:{e}")
def main():
print("=" * 50)
print("📅 猫眼北美票房榜采集工具")
print("=" * 50)
movie_data = crawl_maoyan_na_boxoffice()
if movie_data:
save_to_excel(movie_data)
print("\n" + "=" * 50)
if __name__ == "__main__":
import warnings
warnings.filterwarnings("ignore", message="Unverified HTTPS request")
main()控制台输出:
导出Excel文件效果:
案例 2:电商数据采集(以"亚马逊商品价格"为例)
目标: 采集亚马逊某商品的"名称、售价、库存状态",电商网站IP限制严格,需用IPIDEA住宅IP模拟真实用户:
python
import requests
from bs4 import BeautifulSoup
# 1. IPIDEA 代理配置(选择"美国地区"IP,因亚马逊海外站限制地区)
IPIDEA_USER = "你的用户名"
IPIDEA_PASS = "你的密码"
# 如需定向美国 IP,可在官网【代理管理】中配置"地区筛选",API 链接添加 regions=us
proxies = {
"https": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@proxy.ipidea.io:2333"
}
# 2. 采集亚马逊商品
def crawl_amazon_product(product_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9" # 亚马逊海外站需英文语言头
}
try:
response = requests.get(product_url, proxies=proxies, headers=headers, timeout=15)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
# 提取商品名称
product_name = soup.find("span", id="productTitle").get_text(strip=True) if soup.find("span", id="productTitle") else "未知名称"
# 提取售价(亚马逊价格标签可能变化,需多节点匹配)
price_whole = soup.find("span", class_="a-price-whole")
price_fraction = soup.find("span", class_="a-price-fraction")
product_price = f"${price_whole.get_text(strip=True)}.{price_fraction.get_text(strip=True)}" if price_whole and price_fraction else "无价格"
# 提取库存状态
stock_status = soup.find("div", id="availability").get_text(strip=True) if soup.find("div", id="availability") else "库存未知"
# 输出结果
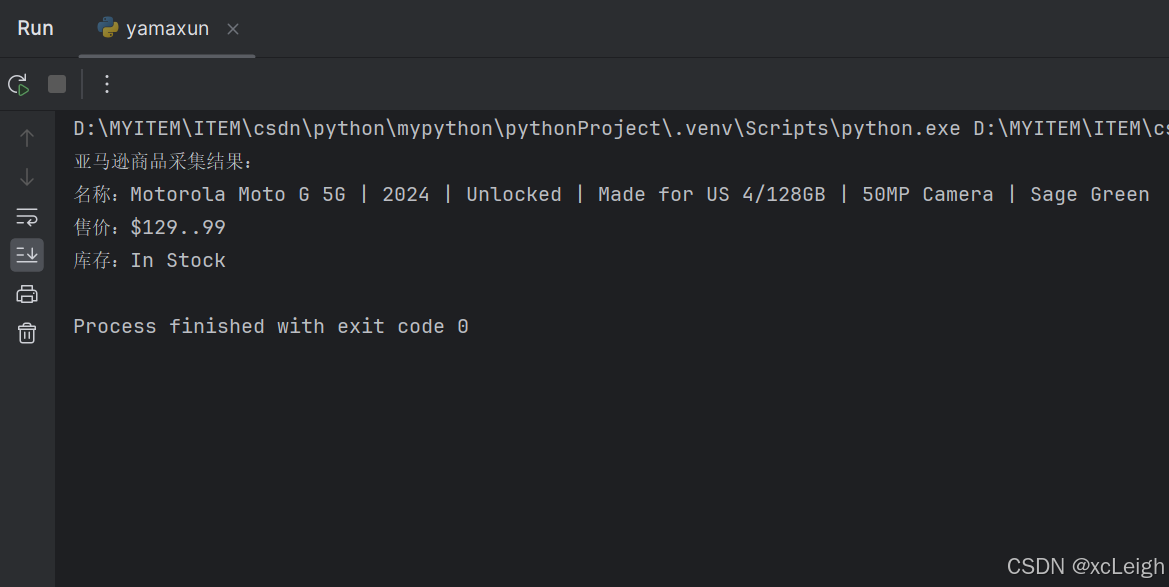
print("亚马逊商品采集结果:")
print(f"名称:{product_name}")
print(f"售价:{product_price}")
print(f"库存:{stock_status}")
elif response.status_code == 503:
print("503 错误:亚马逊识别为爬虫,建议更换 IPIDEA 住宅 IP 或延长 IP 时效(官网可设置 1-120 分钟)")
else:
print(f"采集失败,状态码:{response.status_code}")
except Exception as e:
print(f"采集出错:{str(e)}")
# 执行采集(替换为目标亚马逊商品链接)
if __name__ == "__main__":
amazon_url = "https://www.amazon.com/dp/B07VGRJDFY" # 示例商品链接
crawl_amazon_product(amazon_url)运行效果:
案例 3:多线程加速采集(批量采集多个网页)
当需要采集上百个网页时,单线程效率极低,通过threading实现多线程,并配合IPIDEA无限并发优势,提升10倍+效率:
python
import requests
from bs4 import BeautifulSoup
import threading
import time
# 1. IPIDEA 代理配置
IPIDEA_USER = "你的用户名"
IPIDEA_PASS = "你的密码"
proxies = {
"https": f"http://{IPIDEA_USER}:{IPIDEA_PASS}@proxy.ipidea.io:2333"
}
# 2. 单个网页采集函数
def crawl_single_page(url, thread_name):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
try:
start_time = time.time()
response = requests.get(url, proxies=proxies, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
page_title = soup.title.get_text(strip=True) if soup.title else "无标题"
end_time = time.time()
print(f"【{thread_name}】采集成功:{page_title}(耗时:{end_time - start_time:.2f}s)")
else:
print(f"【{thread_name}】采集失败,状态码:{response.status_code}")
except Exception as e:
print(f"【{thread_name}】采集出错:{str(e)}")
# 3. 多线程批量采集
def multi_thread_crawl(url_list):
threads = []
for i, url in enumerate(url_list):
thread_name = f"线程{i+1}"
# 创建线程,每个线程负责一个网页的采集
t = threading.Thread(target=crawl_single_page, args=(url, thread_name))
threads.append(t)
t.start() # 启动线程
# 等待所有线程完成
for t in threads:
t.join()
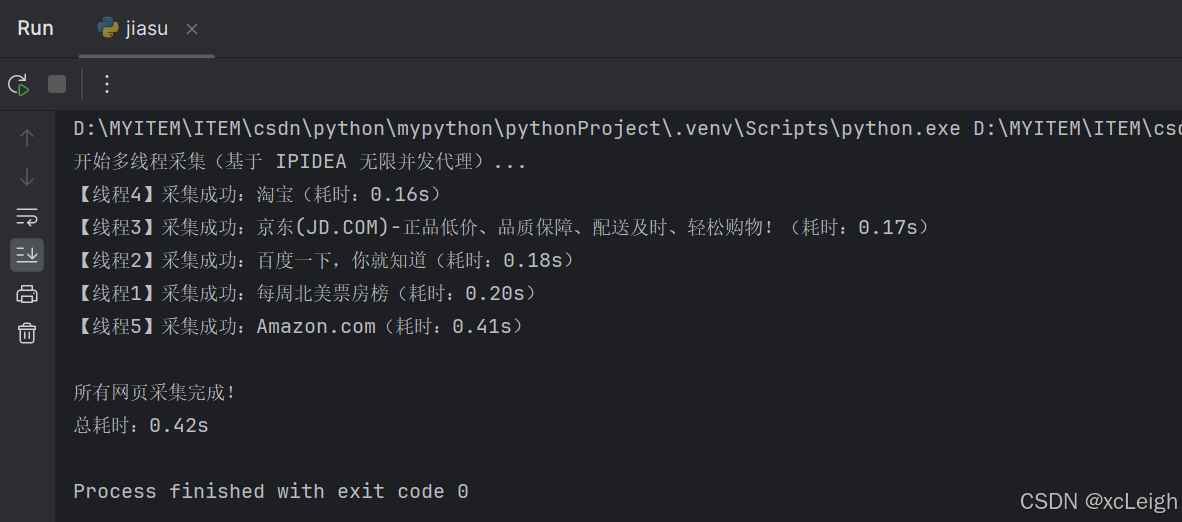
print("\n所有网页采集完成!")
# 执行多线程采集(示例:采集 5 个不同网站)
if __name__ == "__main__":
target_urls = [
"https://m.maoyan.com/asgard/board/2",
"https://www.baidu.com",
"https://www.jd.com",
"https://www.taobao.com",
"https://www.amazon.com"
]
print("开始多线程采集(基于 IPIDEA 无限并发代理)...")
start_total_time = time.time()
multi_thread_crawl(target_urls)
end_total_time = time.time()
print(f"总耗时:{end_total_time - start_total_time:.2f}s")运行效果:
四、IPIDEA进阶技巧:让采集更稳定、更高效
4. 1 动态调整IP时效
在IPIDEA官网【账密认证】中,可将动态IP时效从1分钟调整到120分钟:
- 短时效(1-10分钟):适合高频切换IP的场景(如舆情监控、多账号操作);
- 长时效(30-120分钟):适合需要稳定连接的场景(如大文件下载、长时间登录采集)。
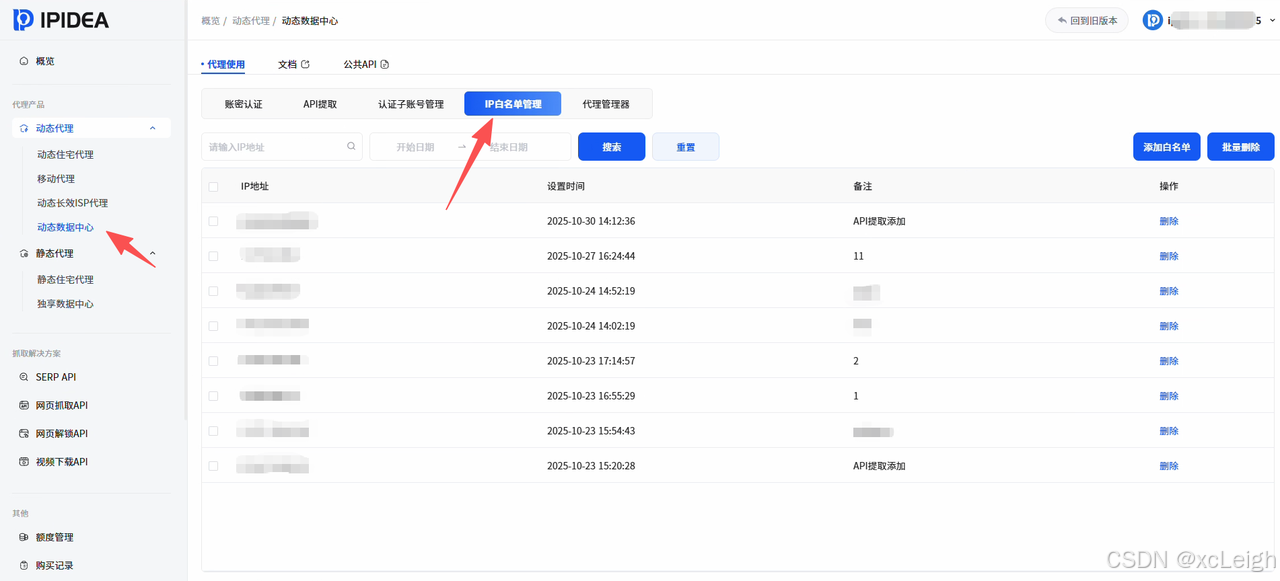
4.2 利用"IP白名单"提升安全性
在【个人中心】-【安全设置】中添加本地/服务器IP到白名单,仅白名单内设备可使用代理,避免账密泄露导致的资源盗用。
4.3 查看代理使用统计
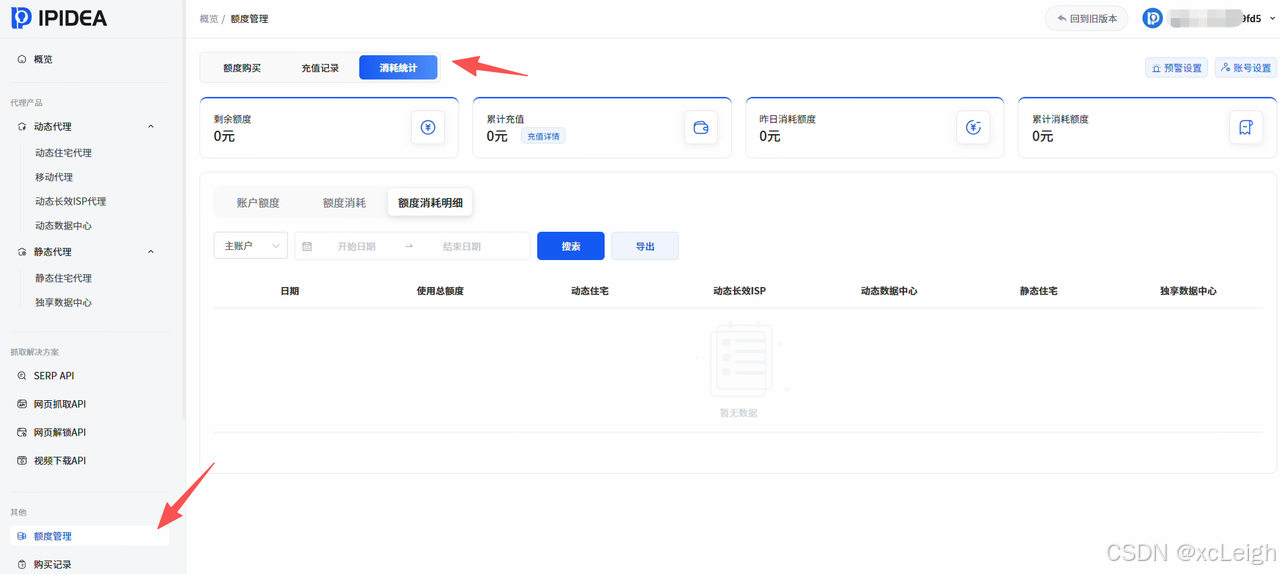
通过【账户后台】-【数据统计】,实时查看流量消耗、IP使用次数、地区分布等数据,合理规划资源(如发现某地区IP使用率低,可调整采集目标地区)。
4.4 自助开票与服务支持
IPIDEA支持订单的自助开票,在【账户信息】-【自助开票】中提交申请,2-3个工作日内即可获取数电发票,企业用户可直接用于报销。
五、为什么选择Python+IPIDEA做数据采集?
- 技术适配性:Python采集库(requests、selenium等)与IPIDEA代理无缝集成,无需复杂开发;
- 稳定性保障:99.9%可用率的IP资源+无限并发,解决采集中断、效率低的核心痛点;
- 场景全覆盖:从静态网页到动态电商,从单人测试到企业级大规模采集,IPIDEA均能适配;
- 合规与安全:ISO认证+白名单机制,避免因代理违规导致的业务风险。
如果您正在被IP固定、采集效率低等问题困扰,不妨立即访问IPIDEA官网,领取免费测试额度,体验企业级代理带来的采集升级!无论是电商分析、市场调查,还是舆情监控、SEO优化,IPIDEA都能成为您数据采集的"最强后盾"。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 人工智能学习合集 🌀 搭配实例教程与实战案例,帮你构建完整 AI 知识体系
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌