在求职和职场数据分析场景中,获取结构化的职位信息能为我们提供极大的便利 ------ 无论是对比薪资水平、分析行业需求,还是研究企业招聘偏好,都需要可靠的数据源支持。本文将手把手教你用 Python 开发一个 Boss 直聘爬虫,通过监听网络请求的方式高效获取职位数据,并将结果保存为 Excel 文件。
一、开发前准备:环境与工具
在开始编码前,我们需要搭建好开发环境并明确核心依赖库的作用,确保后续开发过程顺畅。
1. 环境要求
- Python 3.8 及以上版本(推荐 3.10,兼容性更好)
- 浏览器:Chrome 或 Edge(需与 Chromium 内核驱动版本匹配)
2. 核心依赖库
本文爬虫主要依赖 4 个关键库,可通过pip install 库名命令安装:
- DrissionPage:一款强大的浏览器自动化工具,支持控制浏览器、监听网络请求,无需手动配置 Selenium 驱动,上手门槛极低。
- pandas:数据分析领域的 "瑞士军刀",用于将爬取到的字典数据转换为 DataFrame,并快速导出为 Excel。
- sqlalchemy:(本文未实际使用数据库存储,预留扩展接口)用于数据库连接,方便后续将数据存入 MySQL、PostgreSQL 等数据库。
- json:Python 内置库,用于解析接口返回的 JSON 格式数据。
二、爬虫核心逻辑拆解
本爬虫的核心思路是:模拟浏览器访问 Boss 直聘搜索页 → 监听后端返回职位数据的 API 接口 → 解析 JSON 数据提取关键字段 → 翻页循环采集 → 保存数据到 Excel。相比传统的 "解析网页 HTML" 方式,监听 API 接口能直接获取结构化数据,效率更高且稳定性更强。
下面我们按代码顺序逐步解析每个模块的作用。
1. 初始化与用户输入
首先通过input()函数获取用户想要爬取的职位关键词和页数,让爬虫更具灵活性。
import json
from time import sleep
from sqlalchemy import create_engine
import pandas as pd
from DrissionPage import ChromiumPage
# 接收用户输入:职位关键词和爬取页数
key = input('请输入你想爬取的职位信息')
mun = int(input('请输入你想爬取页数'))
# 实例化Chromium浏览器对象(自动启动浏览器)
dp = ChromiumPage()
2. 监听 API 接口:精准捕获数据来源
Boss 直聘的职位数据是通过异步请求加载的,我们通过 DrissionPage 的listen功能,精准监听返回职位列表的 API 接口,避免解析复杂的网页 DOM 结构。
# 访问Boss直聘搜索页:传入职位关键词,城市默认"全国"(city=100010000)
dp.get(f'https://www.zhipin.com/web/geek/job?query={key}&city=100010000')
# 定义空列表,用于存储爬取到的职位字典数据
ans = []
关键说明:该 API 接口是通过浏览器 F12 开发者工具(Network→XHR/ Fetch)分析发现的,每次翻页都会请求该接口返回 JSON 格式的职位数据。
3. 循环爬取:翻页与数据提取
这是爬虫的核心执行部分,通过循环实现多页爬取,每一页都完成 "下滑加载→等待数据→解析字段→存储数据" 的流程。
# 循环爬取指定页数
for page in range(mun):
print(f'正在采集第{page+1}页数据') # 页码从1开始更符合用户习惯
# 1. 下滑到页面底部:触发下一页数据加载
dp.scroll.to_bottom()
# 2. 等待API响应:最多等待10秒(默认值),获取接口返回数据
resp = dp.listen.wait()
# 3. 解析JSON数据:从响应体中提取职位列表
json_data = resp.response.body # resp.response.body直接返回解析后的字典
jobList = json_data['zpData']['jobList'] # 职位数据存储在zpData→jobList中
# 可选:将原始JSON数据保存到文件,方便调试
with open('boss_raw_data.json', 'w', encoding='utf-8')as file:
file.write(json.dumps(json_data, indent=4, ensure_ascii=False))
# 4. 提取关键字段:遍历职位列表,提取需要的信息
for job in jobList:
# 处理工作地点:城市+区域+商圈(如"北京-朝阳区-望京")
work_location = job['cityName'] + '-' + job['areaDistrict'] + '-' + job['businessDistrict']
# 提取核心字段,存储为字典
job_info = {
'岗位名称': job['jobName'],
'工作地点': work_location,
'学历要求': job['jobDegree'],
'工作经验': job['jobExperience'],
'薪资范围': job['salaryDesc'],
'公司名称': job['brandName'],
'职位标签': ','.join(job['jobLabels']), # 列表转字符串,方便Excel查看
'职位要求': ' '.join(job['skills']), # 技能要求拼接为字符串
'招聘人姓名': job['bossName'],
'招聘人职位': job['bossTitle'],
'公司行业': job['brandIndustry'],
'公司规模': job['brandScaleName']
}
print(job_info) # 打印当前职位信息,方便实时查看
ans.append(job_info) # 将字典添加到列表中
# 5. 翻页与等待:避免请求过于频繁被反爬
print(f'第{page+1}页采集完成,等待3秒后继续...')
sleep(3) # 休眠3秒,降低反爬风险
核心亮点:
- 工作地点字段进行了拼接处理,更符合阅读习惯;
- 职位标签和技能要求将列表转为字符串,避免 Excel 中出现 "\[\]" 符号;
- 每页爬取后休眠 3 秒,降低被 Boss 直聘反爬机制拦截的概率。
4. 数据保存:导出为 Excel 文件
使用 pandas 将列表中的字典数据转换为 DataFrame,然后通过to_excel()方法导出为 Excel 文件,无需手动处理格式。
# 将列表数据转换为DataFrame
df = pd.DataFrame(ans)
# 导出为Excel:index=False表示不保存行索引
df.to_excel(f"boss_{key}_职位数据.xlsx", index=False)
print(f"爬取完成!共采集{len(ans)}条{key}职位数据,已保存为Excel文件。")
三、运行与结果展示
1. 运行步骤
- 安装所有依赖库:pip install drissionpage pandas sqlalchemy;
- 复制代码到 Python 文件(如boss_crawler.py);
- 运行文件,根据提示输入职位关键词(如 "Python 开发")和爬取页数(如 "5");
- 等待爬虫执行完成,当前目录会生成 Excel 文件。
2. 结果展示
Excel 文件包含 12 个字段,数据结构清晰,可直接用于后续分析:
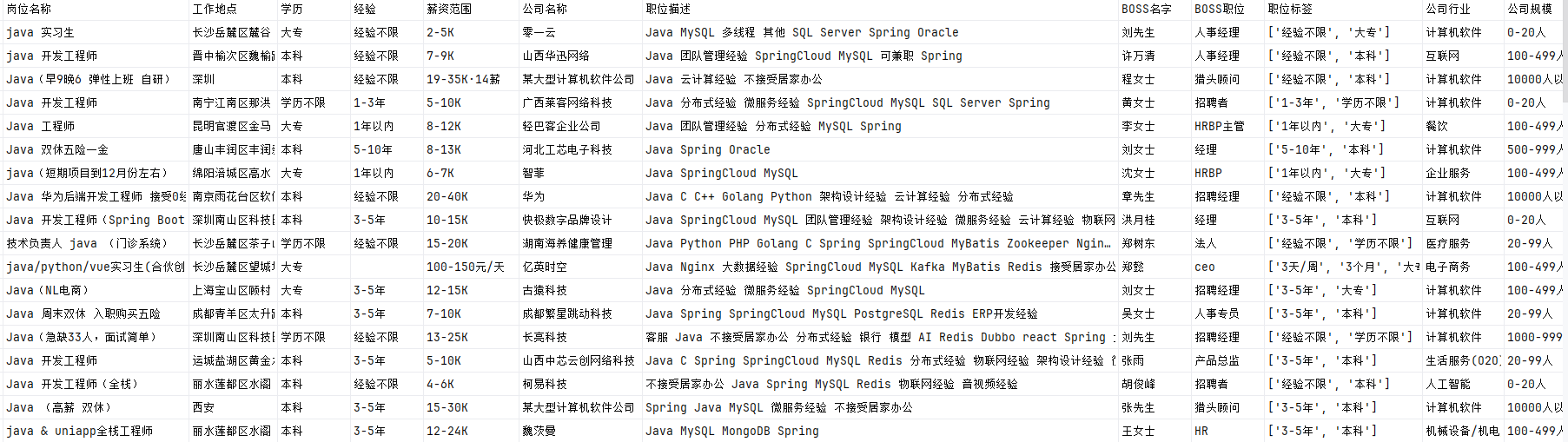
|--------------|----------------|------|--------------|--------|---------------|
| 岗位名称 | 工作地点 | 学历要求 | 薪资范围 | 公司名称 | 职位标签 |
| Python 开发工程师 | 北京 - 朝阳区 - 望京 | 本科 | 25k-35k・14 薪 | 某互联网公司 | 五险一金,弹性工作,年终奖 |
| 全栈开发工程师 | 上海 - 浦东新区 - 张江 | 本科 | 20k-40k・13 薪 | 某科技公司 | 远程办公,股票期权 |
四、反爬与合规注意事项
爬虫开发需遵守法律法规和平台规则,避免触犯风险,以下几点务必注意:
- 控制爬取频率:本文已添加sleep(3),请勿删除或缩短休眠时间,建议单 IP 单日爬取页数不超过 50 页;
- 避免登录爬取:未登录状态下的公开数据爬取风险较低,登录后爬取可能涉及个人信息,存在法律风险;
- 遵守 robots 协议 :访问https://www.zhipin.com/robots.txt查看 Boss 直聘的爬虫限制规则;
- 非商业用途:本爬虫仅用于学习和个人数据分析,禁止用于商业盈利或恶意攻击平台。
如果出现 "无法获取数据" 或 "浏览器被拦截",可能是 IP 被限制,建议更换网络或暂停爬取 1-2 小时后再尝试。
五.资料获取
资料下载地址:项目展示
总结
本文通过 DrissionPage 监听 API 的方式,避开了复杂的网页解析,高效获取了 Boss 直聘的结构化职位数据。整个过程从用户输入到 Excel 导出,逻辑清晰且代码简洁,非常适合 Python 爬虫初学者学习。
需要强调的是,爬虫开发必须以合规为前提,合理控制爬取频率,避免对目标网站造成负担。希望本文能为你的职场数据分析或爬虫学习提供帮助!