个人简介:

孙旭翔,西北工业大学航空学院2019级流体力学专业博士生,研究方向为数据同化与数据驱动湍流建模。在Machine Learning-Science and Technology、Journal of Computational Science、Computers & Fluids发表SCI论文三篇。
论文题目:高雷诺数湍流场数据同化与湍流模型机器学习研究
答辩时间:2025年2月28日
毕业去向:中国飞行试验研究院
论文简介:
航空航天领域的湍流现象是决定关键工程能否成功的核心难题之一,也是当前急需攻克的重要基础科学问题。由于湍流本质上的不确定性、跨尺度特性以及复杂非线性,其数值模拟一直是计算流体力学(Computational Fluid Dynamics, CFD)领域的核心难题之一。传统湍流模拟方法主要基于雷诺平均纳维-斯托克斯(Reynolds-Averaged Navier-Stokes, RANS)方程,这类方法在计算效率和工程适用性方面表现突出,但是对于复杂分离流动(如大迎角失速、激波-边界层干扰等),其预测精度难以满足工程需求。大涡模拟和直接数值模拟方法尽管精度高,但计算成本极为昂贵,难以在工程中大规模应用。
近年来,人工智能技术的快速发展为湍流建模带来了新的机遇。通过挖掘流动数据中的潜在规律,数据驱动方法为湍流建模提供了新的思路,为解决工程高雷诺数复杂湍流模拟问题提供了新的视角。然而,数据驱动方法在实际应用中仍面临诸多挑战。首先,流场数据获取成本高,尤其是高雷诺数复杂流动的高可信度数据极为稀缺;其次,数据驱动模型在不同流动状态和几何形状中的泛化能力不足;此外,数据驱动模型与传统CFD程序的高效集成仍是技术瓶颈。这些问题限制了数据驱动湍流建模在工程实践中的推广与应用。基于此,本文以典型高雷诺数复杂湍流模拟问题为研究背景,结合数据驱动和数据同化方法,开展了数据驱动湍流模型构建与部署、高可信度流场数据反演、数据驱动模型高效集成框架设计等研究,实现了对于高雷诺数复杂流动的精确高效模拟。本文主要的研究内容如下。
(1)针对附着流动下的数据驱动湍流建模问题,提出并实现了从数据驱动湍流模型构建到落地部署的全流程框架。对于二维翼型绕流,以基于Spalart-Allmaras(SA)湍流模型的数值模拟数据为样本,采用全连接神经网络构建湍流模型。引入特征重要性分析优化模型输入,降低复杂度的同时提升了计算稳定性和收敛性。结果表明,数据驱动湍流模型耦合计算得到的摩擦阻力和压力分布预测精度与SA模型接近,并在部分跨声速状态下表现出更优的收敛性。对于三维复杂构型的湍流模拟,进一步研究了数据驱动湍流模型在国产软硬件环境下的编译优化与耦合计算问题,实现了模型在华为昇腾硬件上的半精度部署以及与双精度CFD求解器的混合精度耦合计算,与传统湍流模型相比,计算速度提升3.9倍,集中力系数平均误差小于3%。
(2)针对高雷诺数分离流动中高可信度流场数据稀缺的问题,提出了一种基于集合卡尔曼滤波(Ensemble Kalman Filter, EnKF)的高效湍流场数据同化方法。以稀疏实验数据为观测数据,实现了对SA湍流模型参数和涡粘分布的有效同化,并在此基础上提出了使用EnKF对SA模型生成项空间分布场进行数据同化的方法,拓展了EnKF在湍流同化问题上的应用场景。在SC1095旋翼翼型、DU91-W2-250风力机翼型及ONERA-M6机翼的典型分离流动场景下对比验证了该方法的有效性。结果显示,通过调控局部湍流生成项,能够使得模拟结果更接近实验值,相较传统同化方法,不仅提高了同化精度,还确保了计算稳定性,为分离流动的数据驱动湍流建模研究奠定了高质量数据基础。
(3)针对SA湍流模型在高雷诺数复杂分离流动中模拟精度不足的局限性,提出了一种基于符号回归的湍流模型生成项修正方法。以SC1095和DU91-W2-250翼型典型失速状态下的同化数据为训练样本,采用符号回归方法构建了湍流生成项修正表达式。修正模型能够在壁面附近进行合理地修正,在形式上确保生成项系数非负且对远场无影响。在多个外形、工况上的计算结果表明该模型可以有效提升对分离流动的模拟精度,与标准SA模型相比,对翼型失速迎角下的升力预测平均相对误差降低了50%以上,并具备较强的泛化能力,适用于多种翼型及三维机翼的复杂流动模拟,同时在附着流上与经典模型保持一致。
(4)针对数据驱动模型与CFD程序集成困难的问题,设计开发了一种高效通用的模型集成框架并进一步拓展了其应用范围。基于混合编程方法与动态链接库设计,实现了数据驱动模型与CFD程序之间的高效数据传递,确保了模型在基于Fortran、C++等不同语言开发的CFD程序上的无缝集成和高效运行。框架支持CPU与NPU协同计算及半精度与双精度混合计算,并通过大规模并行计算验证了其高效性和可扩展性,为机器学习算法嵌入CFD程序提供了通用技术方案。
攻读博士期间发表学术成果:
1 Sun X, Liu Y, Zhang W, et al. Development and deployment of data-driven turbulence model for three-dimensional complex configurations J. Machine Learning: Science and Technology, 2024, 5(3): 035085. (SCI: 001324082700001, 二区/JCR Q1, IF: 6.4)
2 Sun X, Cao W, Shan X, et al. A generalized framework for integrating machine learning into computational fluid dynamics J. Journal of Computational Science, 2024, 82: 102404. (SCI: 001295434300001, 三区/JCR Q2, IF: 3.1)
3 Sun X, Cao W, Liu Y, et al. High Reynolds number airfoil turbulence modeling method based on machine learning technique J. Computers & Fluids, 2022, 236: 105298. (SCI:000820618000005, 三区/JCR Q2, IF: 2.5)

博士论文答辩PPT

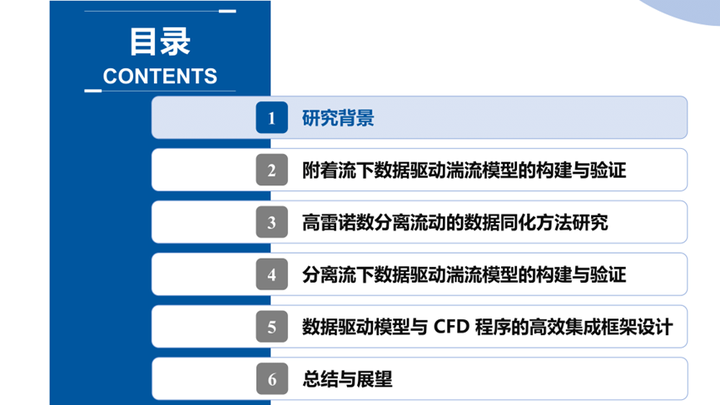
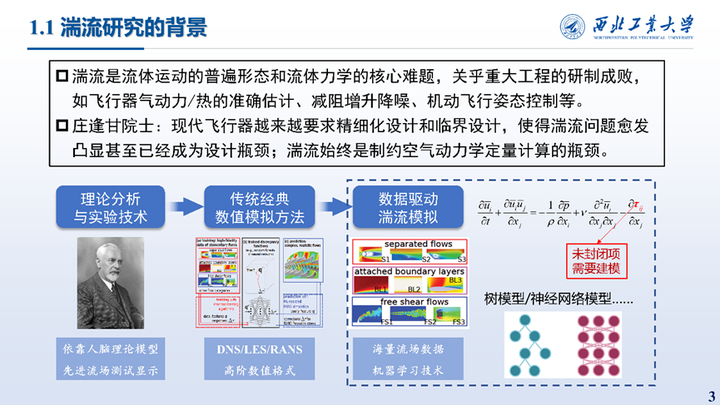
湍流是流体运动的普遍形态,是国家亟需解决的重要基础课题。湍流的研究方法可以分为三个阶段,早期学者建立理论模型或运用实验技术进行流场测量;后期则发展了数值模拟方法,通过不同的数值格式实现DNS/LES或RANS模拟;近年来,随着海量流场数据的累积和机器学习技术的发展,数据驱动方法成为湍流模拟和建模的新途径。
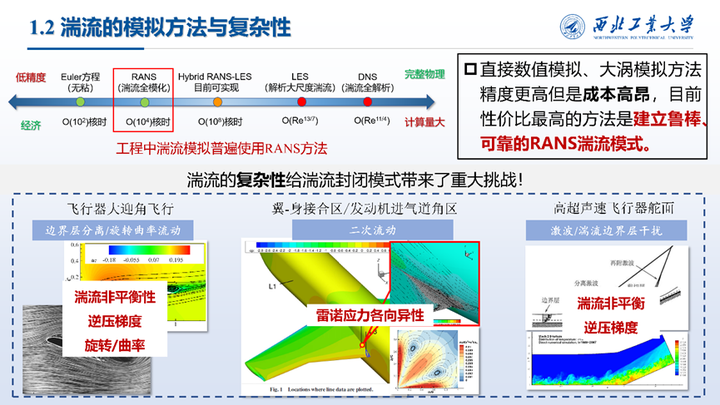
在湍流数值模拟方面,直接数值模拟、大涡模拟方法虽然具有更高的精度但是成本高昂,目前工程中性价比最高的方法是建立鲁棒、可靠的RANS湍流模式。但是湍流的复杂性给湍流封闭模式带来了重大挑战,特别是在分离流动、二次流动等方面的模拟精度还有待提高。
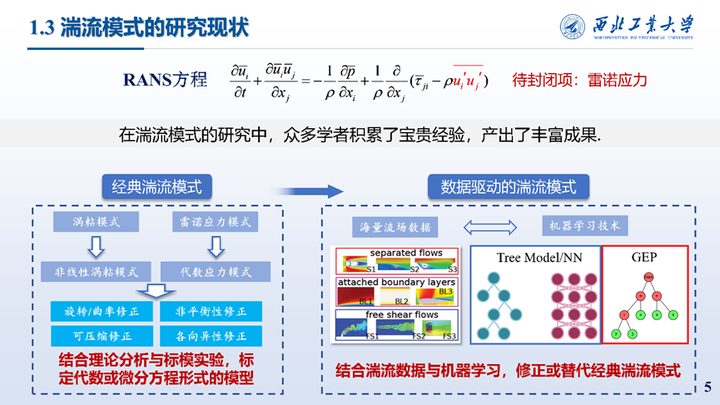
以往的经典湍流模式研究结合理论分析与标模实验,标定代数或微分方程形式的模型。当前在数据驱动的湍流模式研究中,可以结合湍流数据与机器学习方法,修正或替代经典湍流模式。

当前随着人工智能技术的飞速发展,其为科学研究提供了新的范式。逐渐形成了以大数据 + 知识发现 / 提取为特点的数据驱动研究新范式
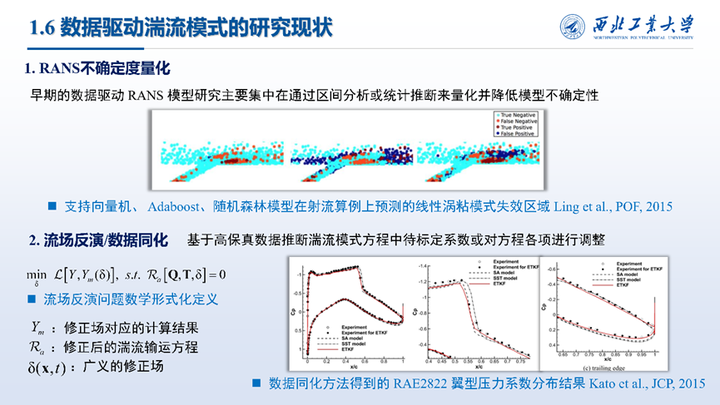
在当前数据驱动湍流模式的研究方面,可分为三个方面。早期的数据驱动 RANS 模型研究主要集中在通过区间分析或统计推断来量化并降低模型不确定性而后开始出现了基于高保真数据推断湍流模式方程中待标定系数或对方程各项进行调整的流场反演或数据同化方法
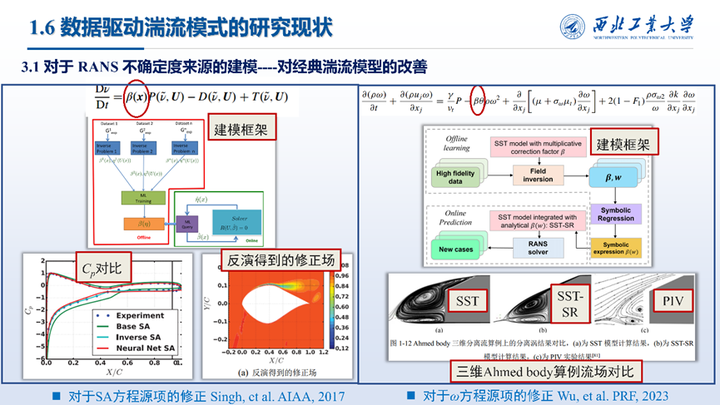
在更进一步的研究中,研究者开始对RANS不确定度来源建模,以期改善RANS模拟精度。这方面的一个代表是对于经典湍流模型的改善,比如对SA模型源项、omega方程破坏项的修正,均取得了较好的结果
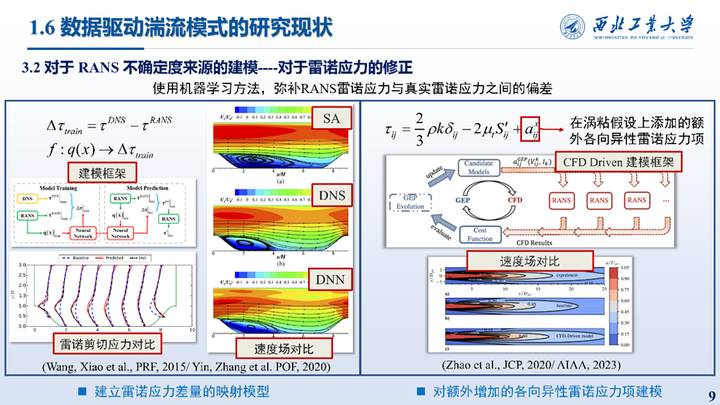
接着是直接对雷诺应力的修正,代表性工作是使用机器学习方法,弥补RANS雷诺应力与真实雷诺应力之间的偏差。
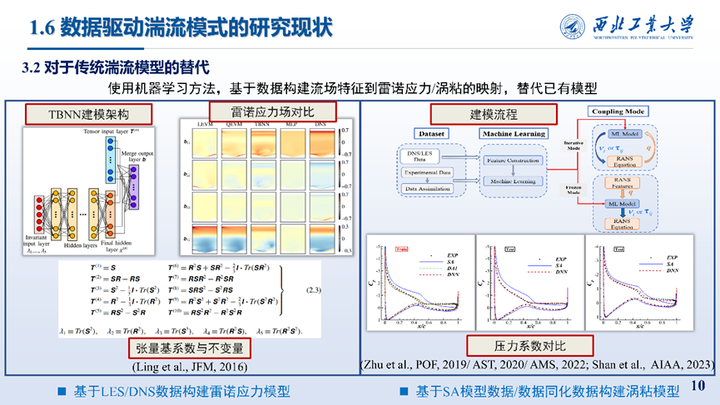
更进一步的,也有研究者使用机器学习方法,基于数据构建流场特征到雷诺应力/涡粘的映射,替代已有模型。
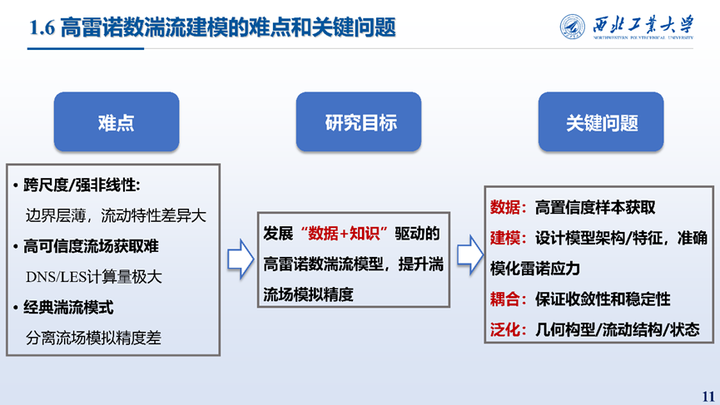
对于工程界高雷诺数的湍流问题,传统模型与数据驱动模型都面临着诸多挑战。例如,尺度跨度巨大,非线性强烈,高精度流场很难获取,传统模型在分离流场中精度不高。因此,我们研究的目标是建立一个适用于复杂工程问题的数据驱动湍流模型,提高湍流场的模拟精度。这一领域中的关键问题是如何获取样本、如何缓解尺度效应,耦合计算的收敛性和稳定性问题以及对于不同构型、流动状态的良好泛化。

附着流下RANS模拟的精度尚可,因此本节先以NACA0012翼型为研究对象,使用CFD模拟数据作为建模样本,优先考虑解决特征构建与选择、耦合求解等问题。根据物理知识与经验,构造了11个输入特征,模型的输出特征是涡粘系数。通过神经网络建立输入输出特征之间的映射关系,实现对于SA模型的代替。
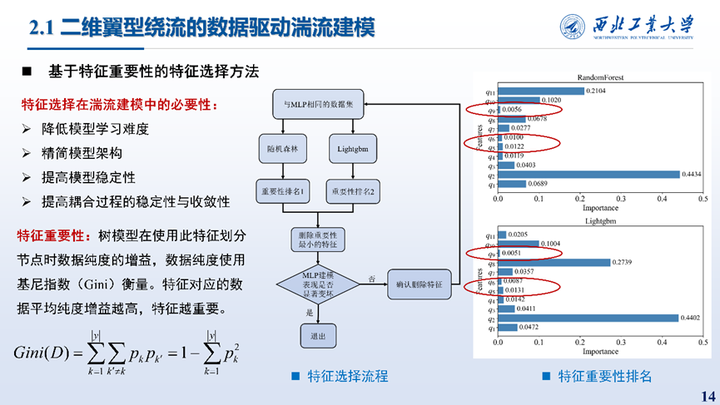
特征选择可以降低模型学习难度,精简模型架构,提高模型稳定性等,本文提出了一种基于特征重要性的特征选择方法,其中特征重要性通过随机森林和Lightgbm给出每一轮删除两个模型都认为不重要的特征,并检测神经网络的训练性能,最终删除了三个特征,特征重要性的排名如右图所示。
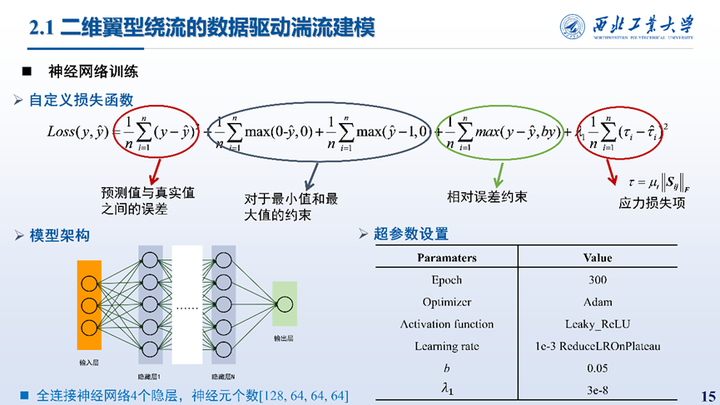
使用全连接神经网络来建立模型,并自定义了损失函数,包括了数据损失、对于极值的约束、相对误差以及应力约束,超参数的设置见右下的表
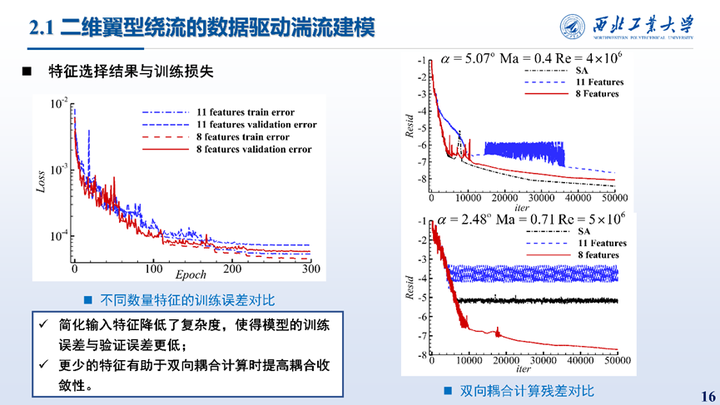
这里左边给出了模型训练过程中11和8个特征对应的训练、验证误差下降曲线,可以看到8输入特征的模型的训练和验证误差都更小,表明了所提出的特征选择方法的有效性。同时8输入特征的模型在于CFD求解器耦合计算时也用于更好的稳定性与收敛性。
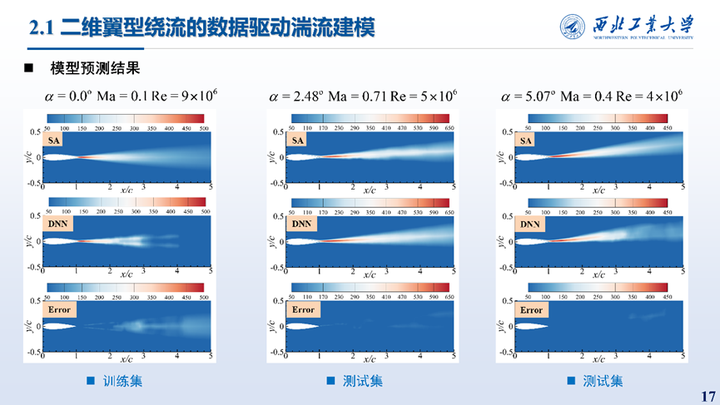
本页展示的模型在训练集与测试集上的预测结果、与真实值的误差统计,可见模型对于不同状态均具有较好的预测精度。
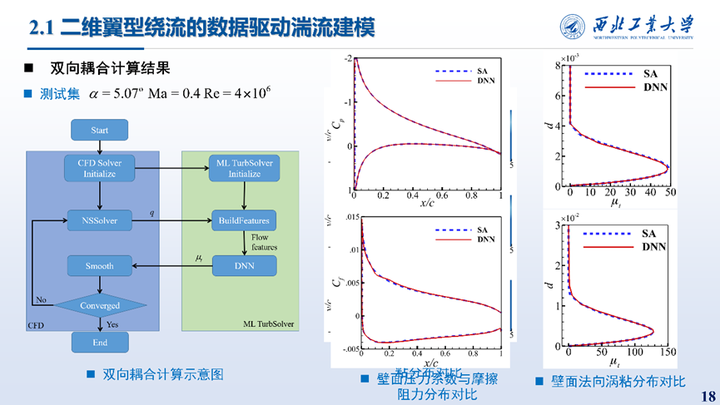
双向耦合计算指的是将训练好的神经网络湍流模型与CFD求解器耦合计算,在每一个迭代步中CFD求解器将流场特征传递给神经网络湍流模型,模型预测得到涡粘系数并返回。耦合得到的涡粘分布以及沿壁面的法向分布如右图所示。
壁面压力系数与摩擦阻力系数的对比如图所示,无论是涡粘分布还是力系数分布结果均与SA模型结果吻合较好。
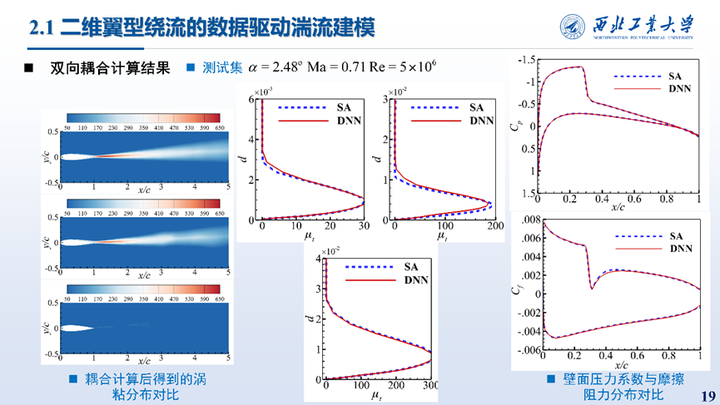
这里给出的是在另一个跨声速测试集上的耦合计算结果,结论与之前一致
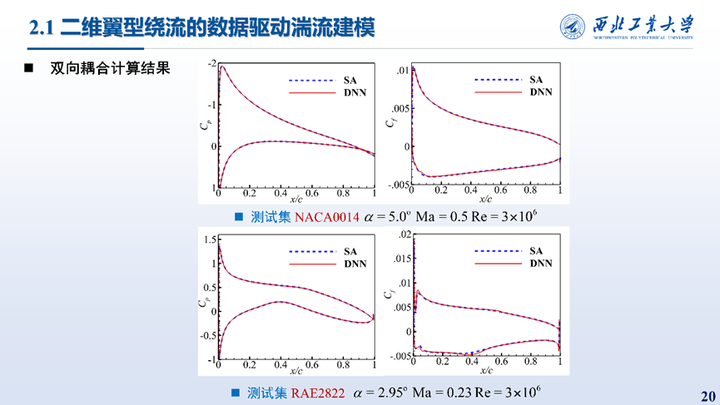
在NACA0014和RAE2822翼型上也进行了测试,结果与SA模型结果吻合较好,说明模型对于不同外形也具有一定的泛化性
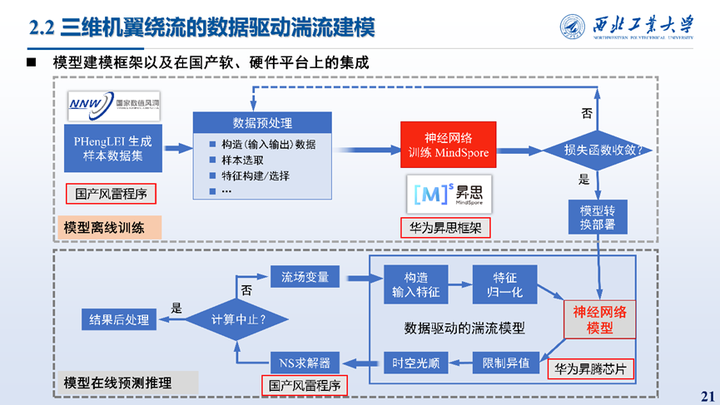
接着是在三维外形上的建模,将前面提出的二维建模框架移植到了华为的软硬件平台上并进行了相应的测试,整个流程包含模型离线训练与在线推理预测两部分。
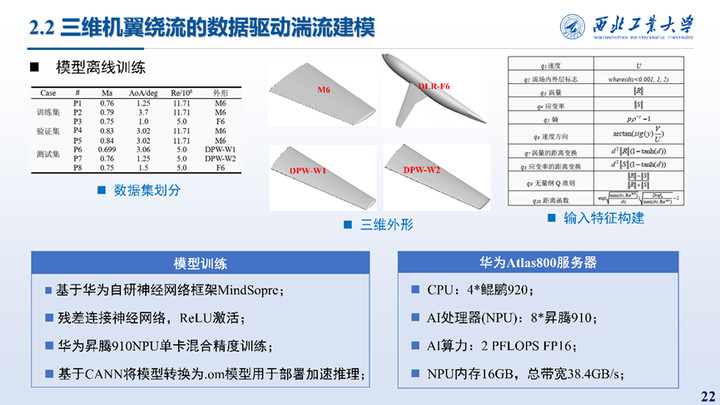
训练数据集的划分、特征构建以及三维外形如图所示,模型的训练基于华为自研的神经网络框架Mindspore,使用残差连接的神经网络,在华为昇腾910NPU单卡上进行了混合精度训练。训练完成后通过CANN将模型转换为更加适合推理的om模型用于加速推理。
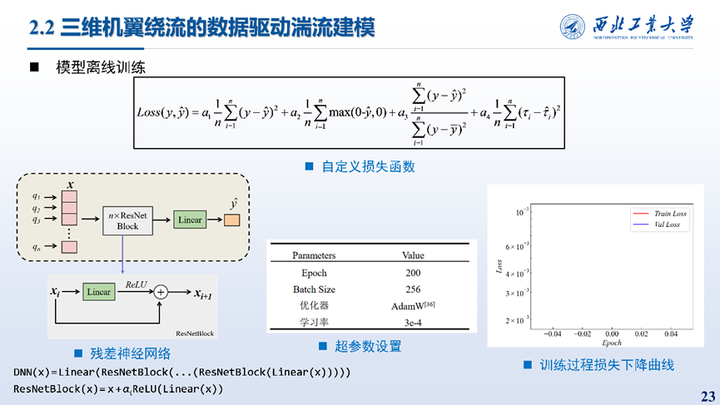
同样在训练过程中自定义了损失函数,残差神经网络的示意图左下角所示。
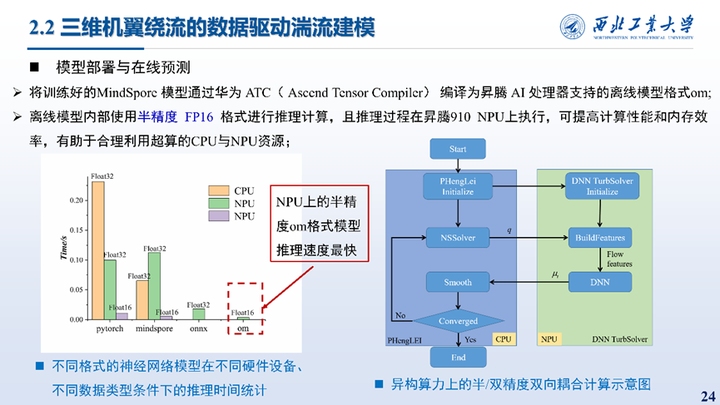
模型的部署指的是将将训练好的MindSpore 模型通过华为ATC编译为昇腾 AI 处理器支持的离线模型格式om。离线模型内部使用半精度 FP16 格式进行推理计算,且推理过程在昇腾910 NPU上执行,可提高计算性能和内存效率,有助于合理利用超算的CPU与NPU资源;左图对比了不同格式神经网络模型在不同硬件设备以及不同数据类型条件下的推理时间统计,可见NPU上半精度的om模型推理速度最快。右图是异构算力上的半/双精度双向耦合计算示意图。
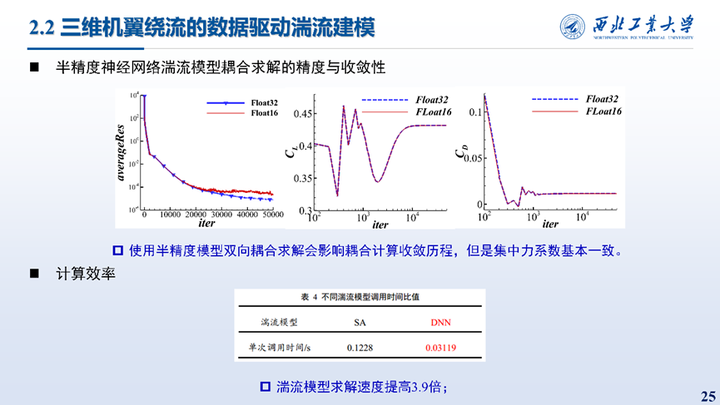
首先对比了半精度神经网络湍流模型耦合求解的精度与收敛性,可见使用半精度模型双向耦合求解会影响耦合计算收敛历程,但是集中力系数基本一致。计算效率方面得益于数据类型以及硬件的支持,湍流模型求解速度提高4倍。
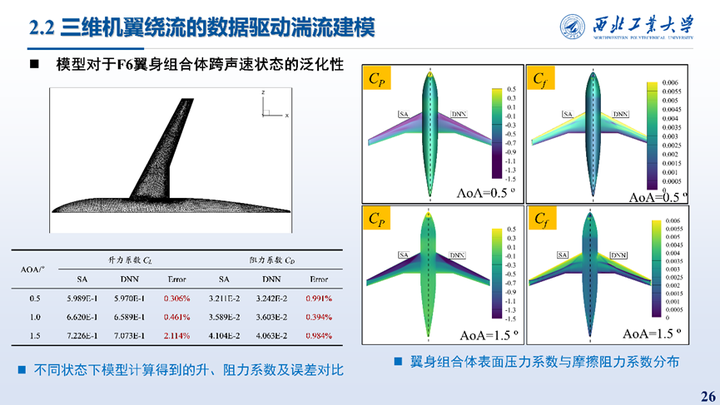
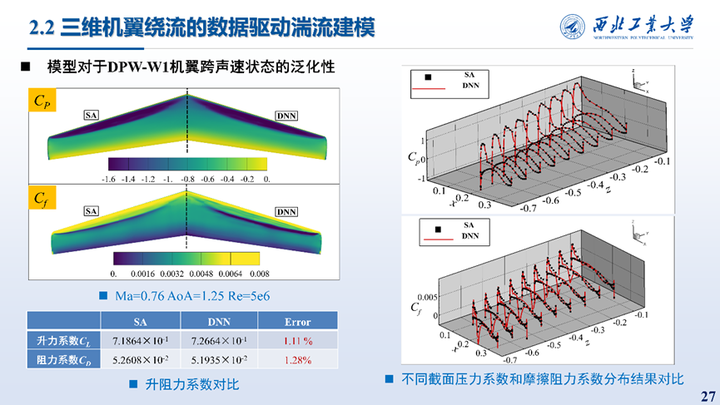
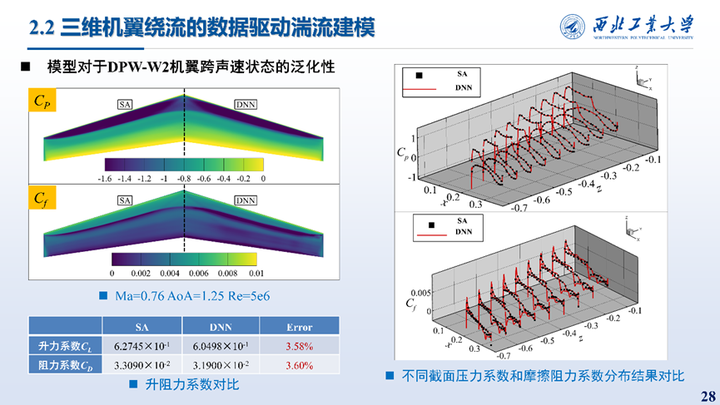
这里展示的F6翼身组合体、DPW-W1/W2外形不同工况下的耦合结果统计与表面压力、摩擦阻力系数分布对比。
面向工程的高雷诺数分离流场,DNS/LES算力不足,传统RANS方法精度不够,而风洞实验则难以获得整个流场数据,这为高雷诺数分离流下的数据驱动湍流建模带来了严重挑战。本文考虑使用数据同化+机器学习的方法来解决这一问题,基于RANS框架与少量实验数据通过数据同化方法得到高可信度流场数据,在此基础上使用机器学习方法构建模型,实现对于不同外形与状态的泛化。本章着重于数据同化部分,实现了三种同化方案,分别为对湍流模型参数、湍流涡粘分布、湍流模型形式的同化。
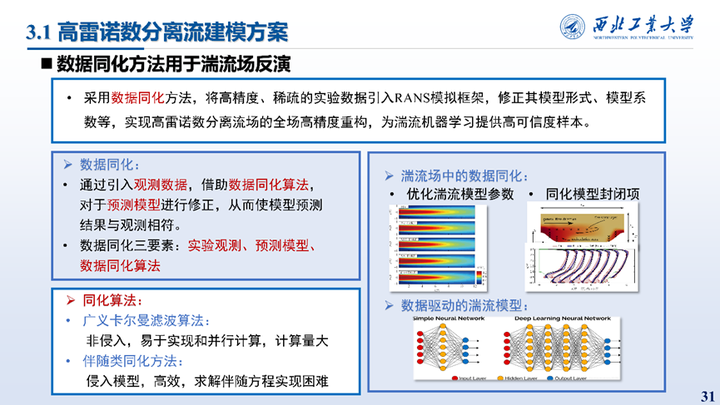
采用数据同化方法,可以将高精度、稀疏的实验数据引入RANS模拟框架,修正其模型形式、模型系数等,实现高雷诺数分离流场的全场高精度重构,为湍流机器学习提供高可信度样本。湍流问题中常用的同化算法有广义卡尔曼滤波和伴随类同化算法。

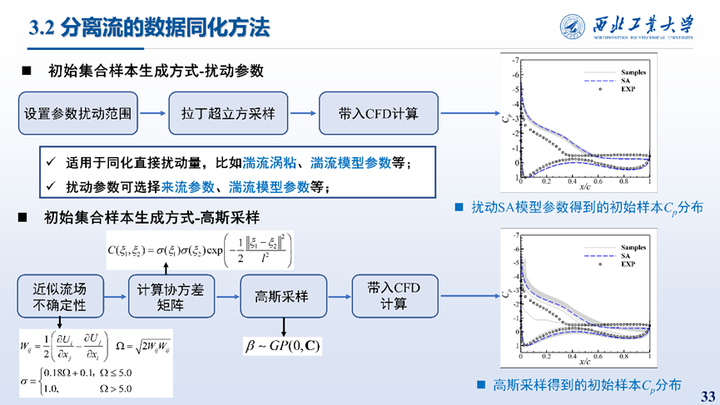
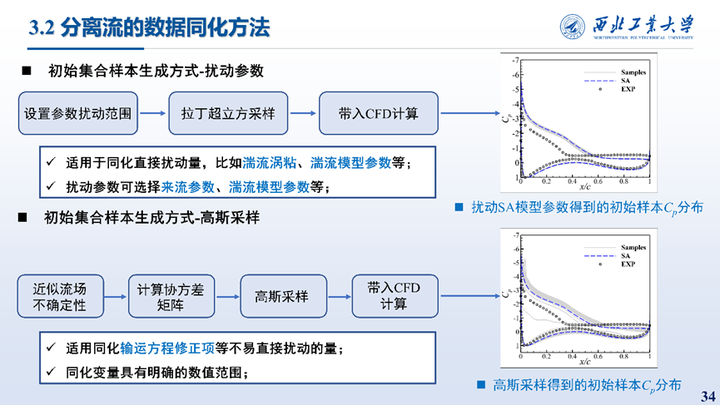
我们考虑使用集合卡尔曼滤波来实现对于相关变量的同化工作。在集合卡尔曼滤波方法中,初始样本的生成至关重要,对于湍流涡粘、模型参数等同化变量使用间接扰动的方法生成初始样本。对于湍流生成项系数的空间分布,其不易扰动,使用高斯采样的方法生成初始集合样本。两种方法生成的初始样本的Cp分布如右图所示。
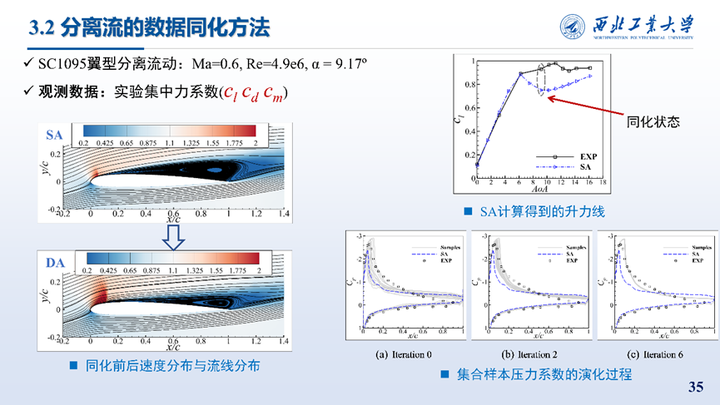
首先是对二维旋翼翼型SC1095翼型跨声速大迎角状态下的同化,所使用的观测数据为集中力系数。右图展示了SA模型计算的升力线与实验值的对比,以及同化过程中集合样本Cp演化过程。同化前流程分离涡较大,同化后分离涡显著减小,且激波位置后移。
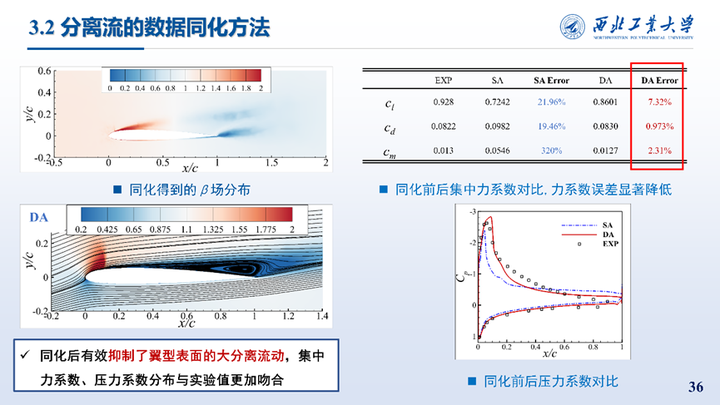
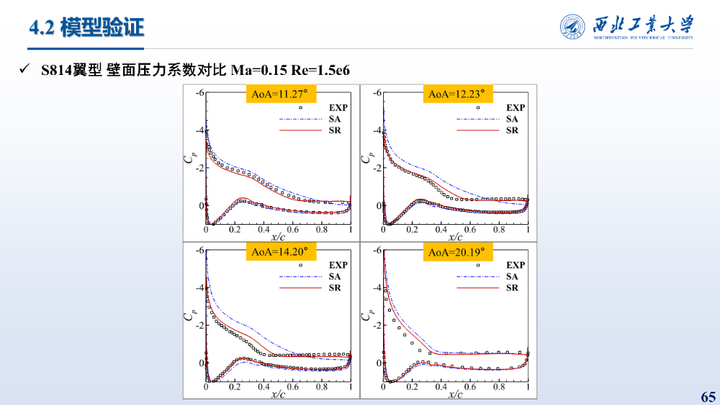
同化前后的集中力系数力系数误差显著降低,压力系数也与实验值更加吻合。同化得到的β场分布如图所示,翼型前缘的生成项显著增加。
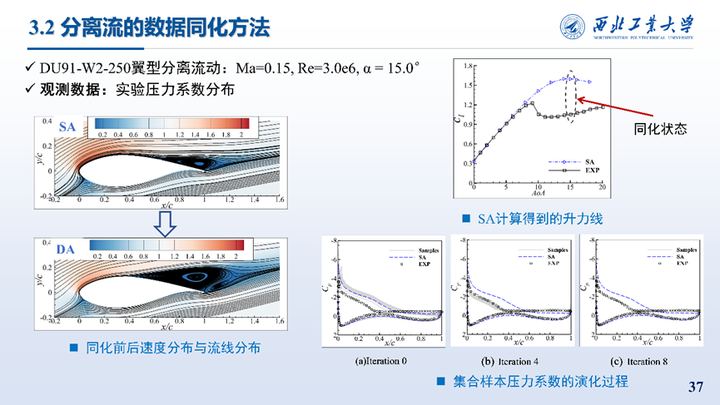
其次是对DU91-W2-250翼型大迎角分离流动的同化,观测数据是实验的压力系数分布。右图给出了SA模型升力线的对比以及对应的同化状态,同化过程中的集合样本Cp演化历程。左图则给出了同化前后流场的速度分布与流线,同化后流动提前分离,分离涡更加饱满。
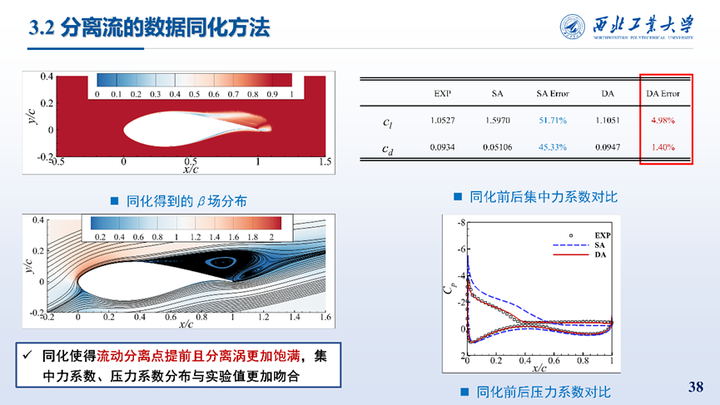
同化前后的集中力系数力系数误差显著降低,压力系数也与实验值更加吻合。同化得到的β场分布如图所示,远场均为1表示不做修正,翼型前缘至50%弦长处的β减小。
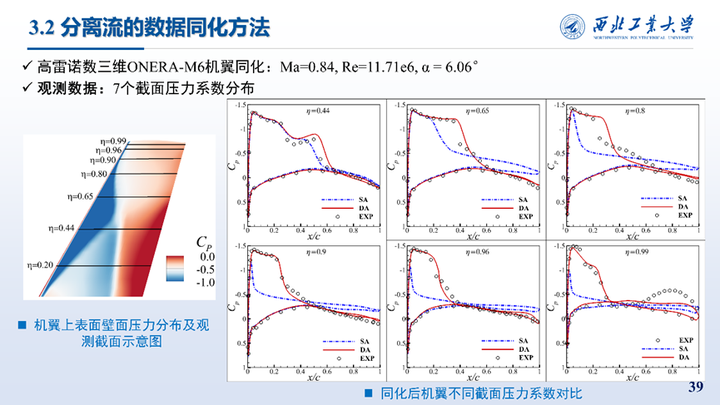
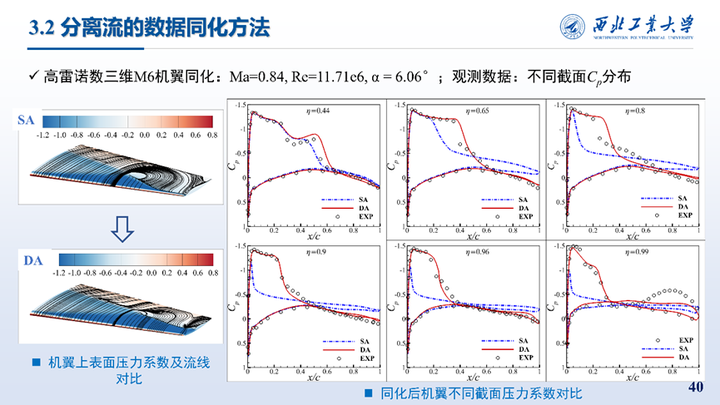
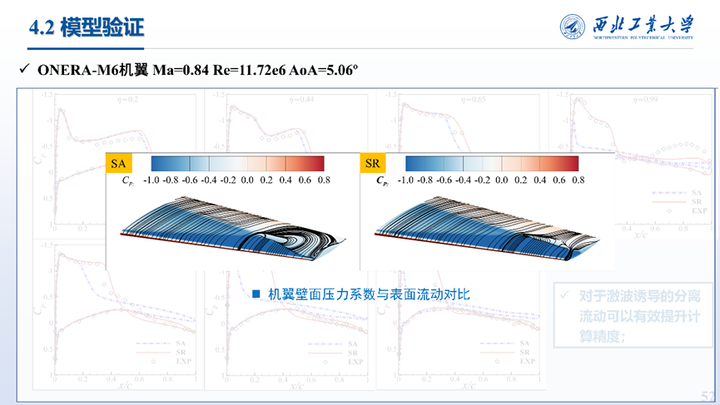
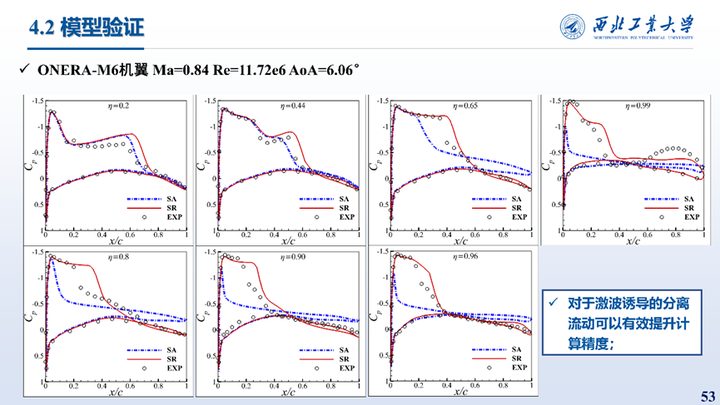
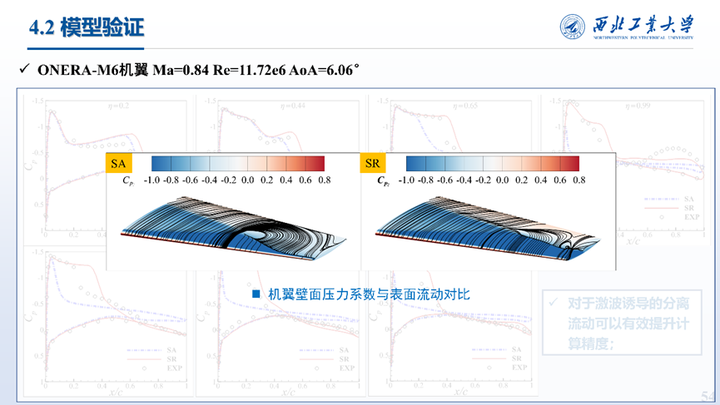
接着我们对三维M6机翼跨声速大迎角状态也进行了同化,该状态下机翼上表面会出现激波边界层干扰问题,形成λ型激波并引起大范围分离。所使用的是观测数据是7个展向截面处实验测得的压力系数。同化结果与实验值的对比如图所示,相比SA模型,同化结果精度显著提高。
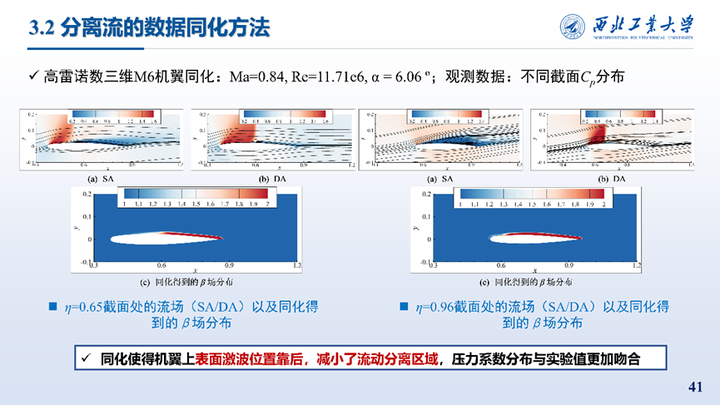
这里展示的η=0.65和0.96两个截面处同化前后的速度分布与流线对比,可以看到同化使得机翼上表面激波位置靠后,减小了流动分离区域,压力系数分布与实验值更加吻合。
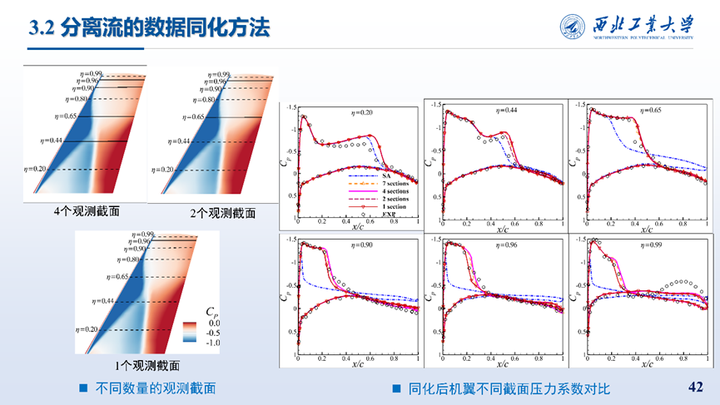
继续在在逐渐减少观测截面的情况下开展了同化工作,不同数量观测截面得到的同化结果如图所示,相比SA均有较大提升。
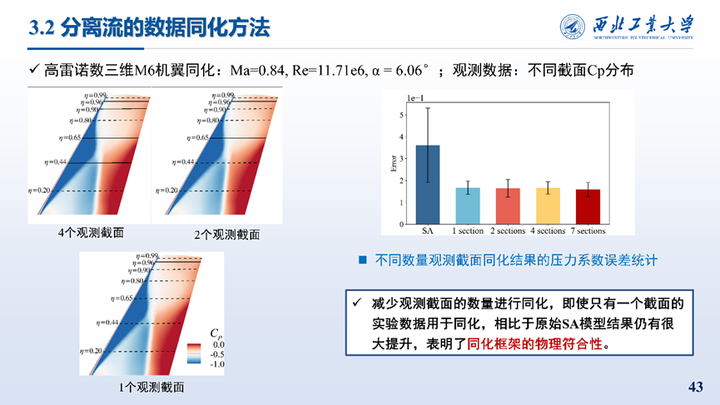
不同数量观测截面同化结果的压力系数误差统计,可以看到减少观测截面的数量进行同化,即使只有一个截面的实验数据用于同化,相比于原始SA模型结果仍有很大提升,表明了同化框架的物理符合性,而不是对观测数据的简单直接拟合。
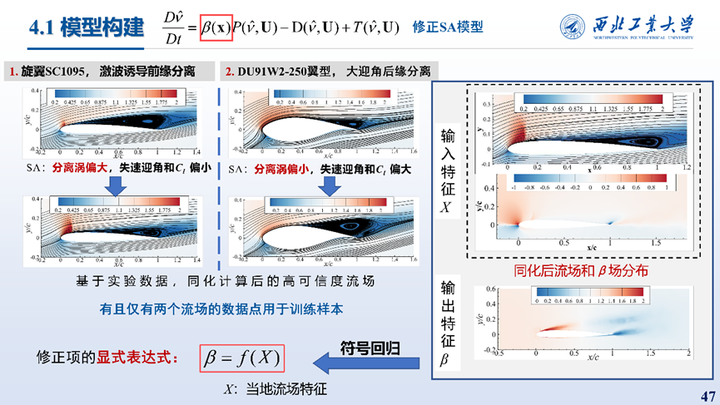
SC1095和DU91W2-250翼型的分离流动是具有代表性的两种翼型分离流动,因此我们选取其同化数据作为数据样本,通过符号回归方法构建当地流场特征到SA模型生成项系数空间分布β场的显式代数模型,实现对于SA模型的修正。

符号回归算法是通过选择(模拟自然选择)、变异(引入新的遗传变异)和交叉(模拟生物繁殖中的基因重组),来不断迭代寻找更优的解决方案。训练得到的符号回归模型表达式的值域为0, 2,形式上满足了湍流生成项非负性;且是显式白箱的代数表达式,易于移植嵌入已有CFD程序、计算代价小、易于调整参数、可解释性强。
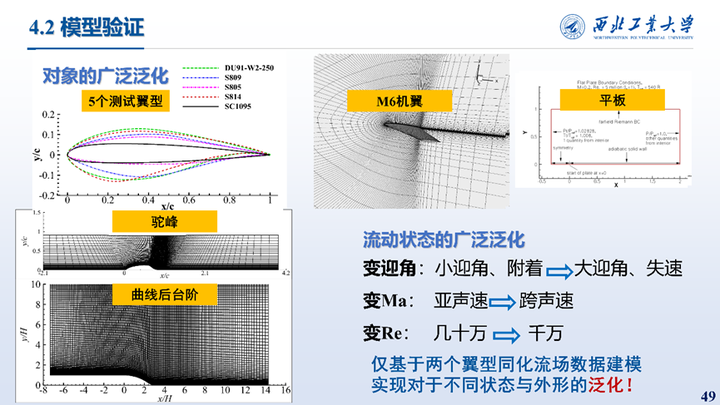
接下来在多个算例上对其进行了测试,外形有5个测试翼型,三维M6机翼,平板,驼峰以及曲线后台阶算例,对于流动状态也进行了广泛的泛化性测试。仅基于两个翼型同化流场数据建模实现对于不同状态与外形的泛化!
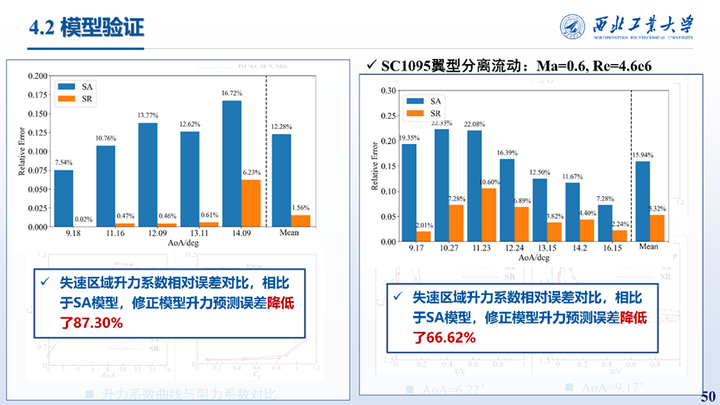
首先是SC1095翼型不同来流状态上的测试结果。使用了Ma0.6一个状态点的建模实现了对于整条升力曲线的泛化,并且对于Ma0.5状态的计算结果也与实验值吻合很好。失速区域升力结果相比于SA模型,相对误差降低了分别降低了87.30%和66.62%
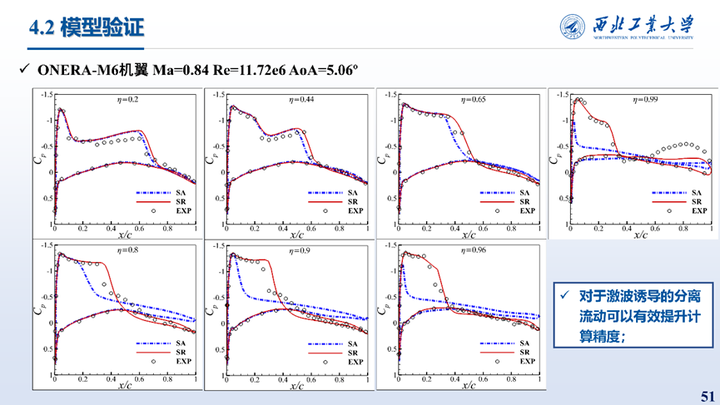
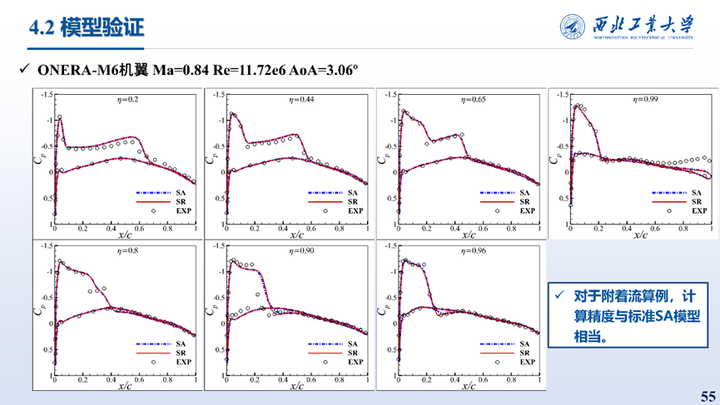
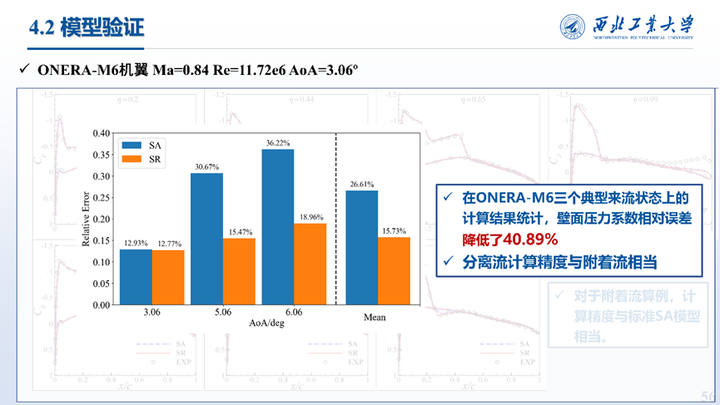
其次是对M6机翼三个不同攻角的计算结果对比,可以看到对于三维激波诱导的分离流动修正模型也可以有效提成计算进度,对于三维附着流动计算结果则与SA模型保持一致。统计了Cp的相对误差,可以看到在M6三个典型来流状态壁面压力系数相对误差降低了40.89%。另一个角度来看修正模型在分离流计算精度与附着流相当。
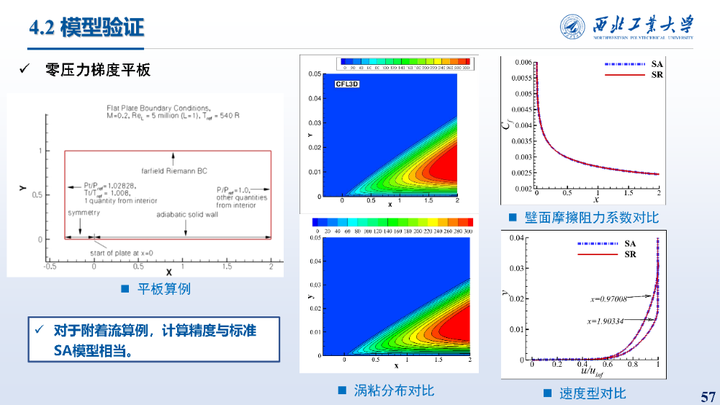
除了三维附着流动之外,还在零压力梯度平板这类简单附着流算例上进行了测试,对于附着流算例,计算精度与标准SA模型相当。
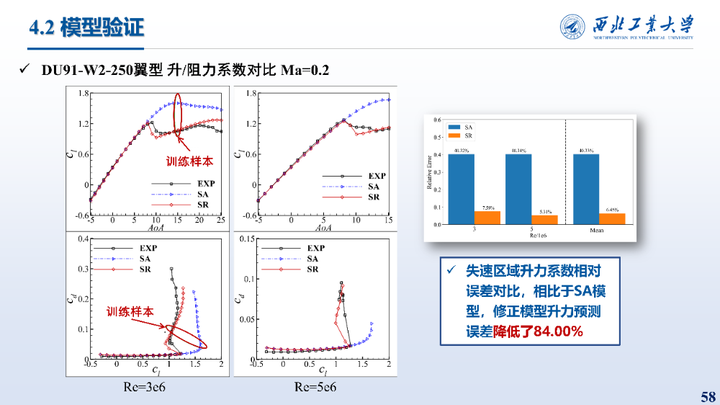
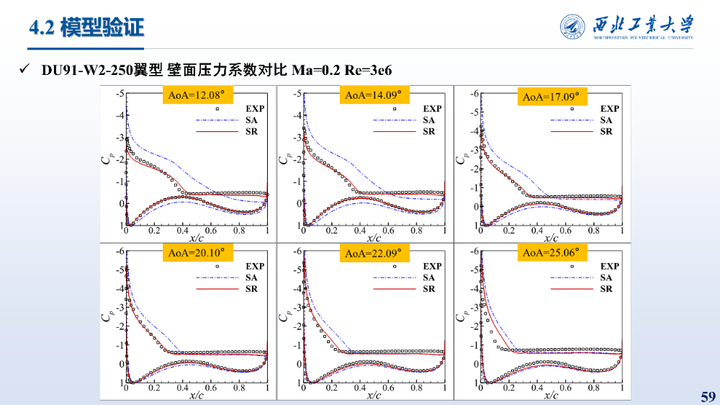
这里给出的是在DU91-W2-250翼型上的测试结果,相比于SA模型,修正模型升力预测误差降低了84.00%
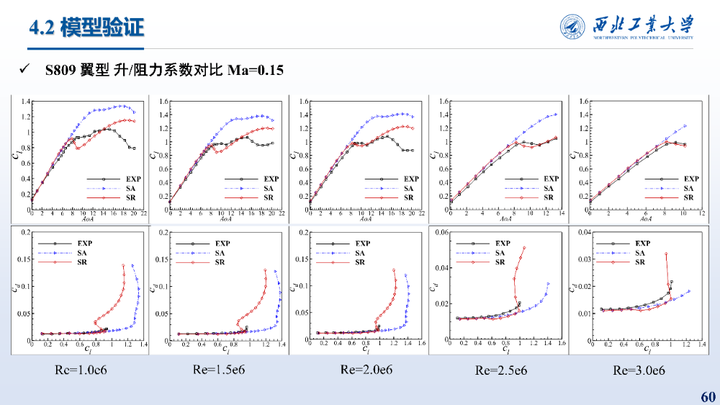
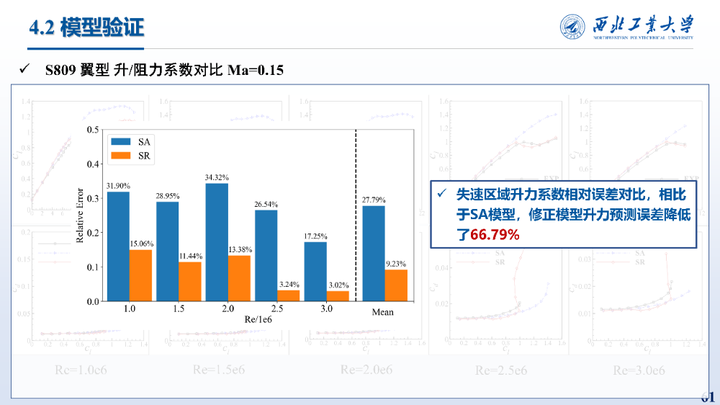
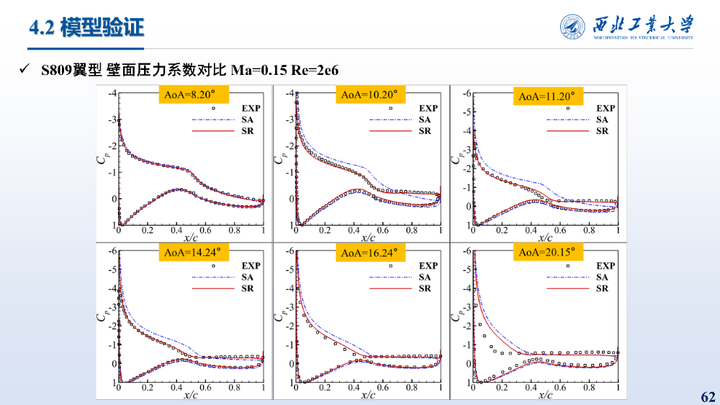
这里给出的是在S809翼型不同雷诺数上的测试结果,相比于SA模型,修正模型升力预测误差降低了66.79%
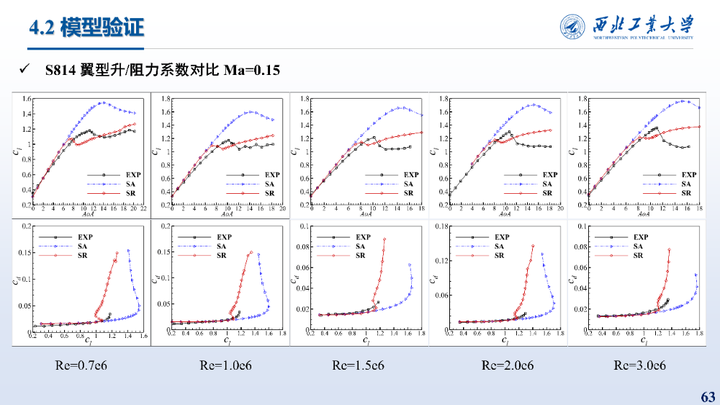
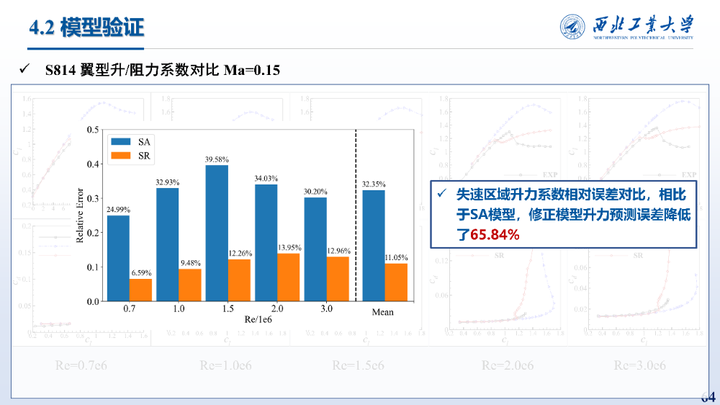
这里给出的是在S814翼型不同雷诺数上的测试结果,相比于SA模型,修正模型升力预测误差降低了65.84%
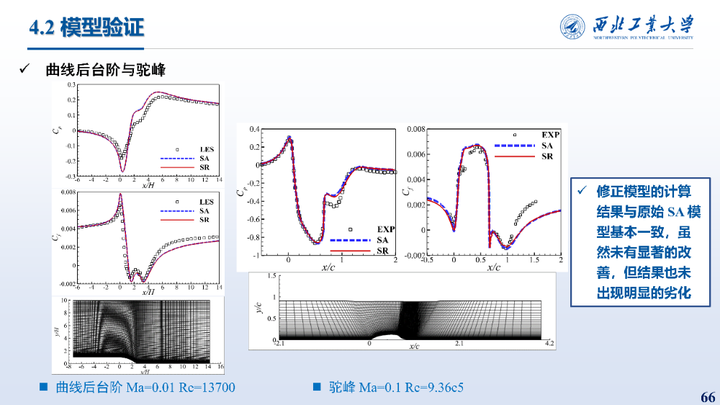
这里展示的是模型在驼峰与曲线后台阶上的结果对比,对于这类流动,修正模型的计算结果与原始 SA 模型基本一致,虽然未有显著的改善,但结果也未出现明显的劣化。这主要归因于这两个算例的流动分离机制与翼型流动存在显著差异,
修正模型的训练数据中未包含此类具有在附着特性流动的数据,导致其难以针对这类流动进行有效修正。这表明,针对不同分离流动类型的统一建模仍有提升空间。未来的研究可尝试将多种分离流动类型纳入训练数据集,以构建具有更强泛化能力的模型,这也是本文工作的重要拓展方向之一。

综上可以看到,我们仅基于两个翼型数据同化流场的数据构建修正模型,实现了对于不同外形不同来流状态的良好泛化,是对SA模型创始人Spalart于2022 NASA湍流建模会议上"calling for universality"的有力回应!
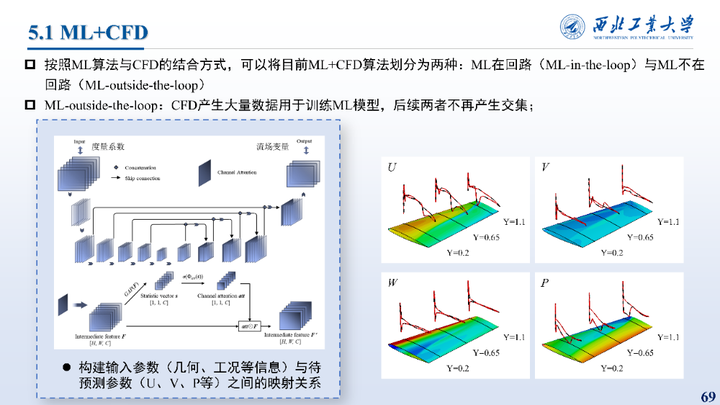
按照ML算法与CFD的结合方式,可以目前ML+CFD算法划分为两种:ML在回路(ML-in-the-loop)与ML不在回路(ML-outside-the-loop)。ML-outside-the-loop:CFD产生大量数据用于训练ML模型,后续两者不再产生交集;
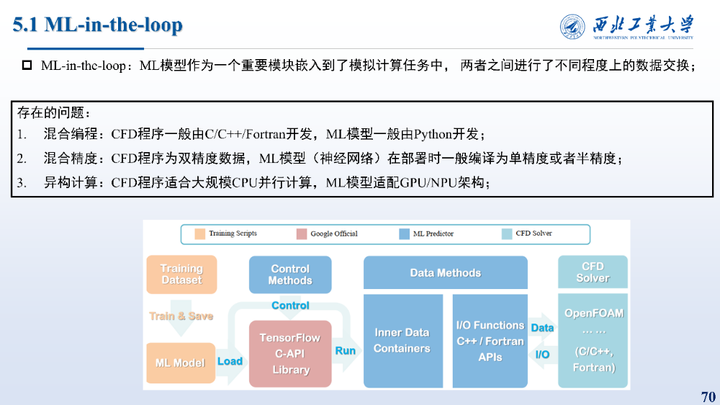
ML-in-the-loop:ML模型作为一个重要模块嵌入到了模拟计算任务中,两者之间进行了不同程度上的数据交换,但是存在这混合编程、混合精度、异构计算等问题。
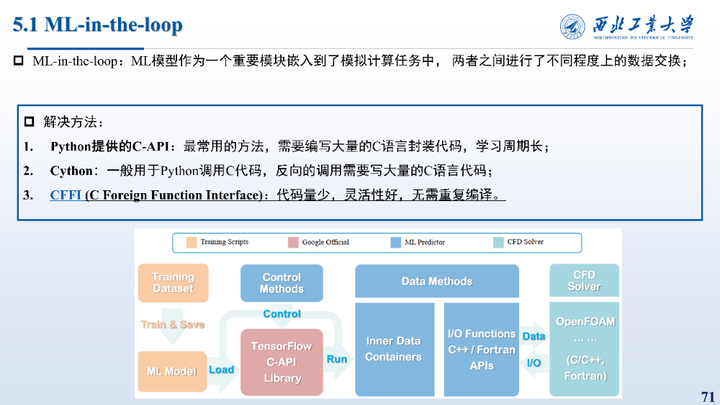
本章通过CFFI来解决上述遇到的问题。
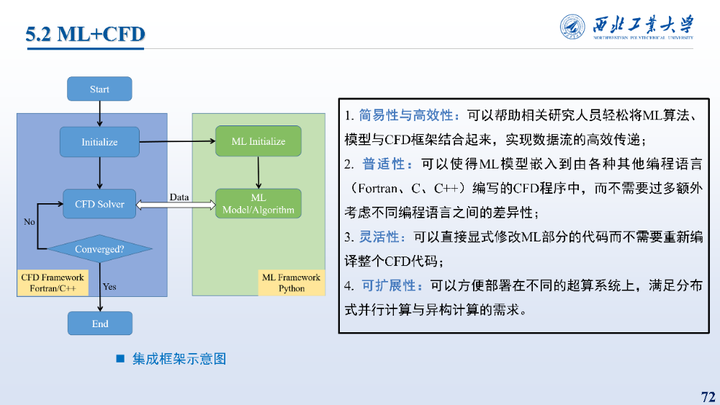
所提出的框架示意图如左图所示,所提出的框架具有简易性与高效性、普适性、灵活性以及可扩展性的特点。
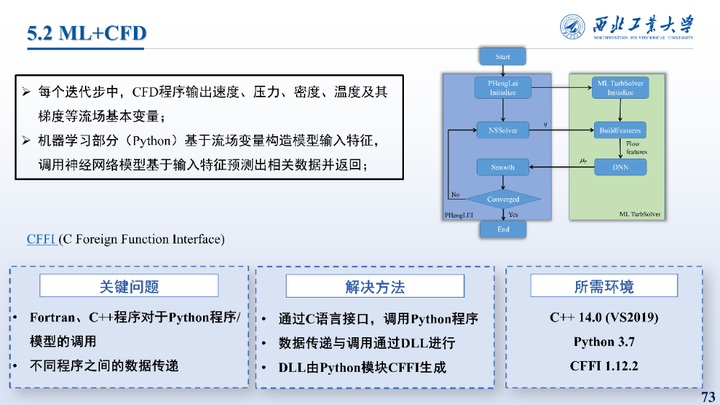
具体而言,本框架所要解决的问题是核心是Fortran、C++程序对于Python程序/模型的调用以及不同程序之间的数据传递,解决的思路是通过通过C语言接口,调用Python程序,数据传递与调用通过DLL进行,DLL由Python模块CFFI生成。
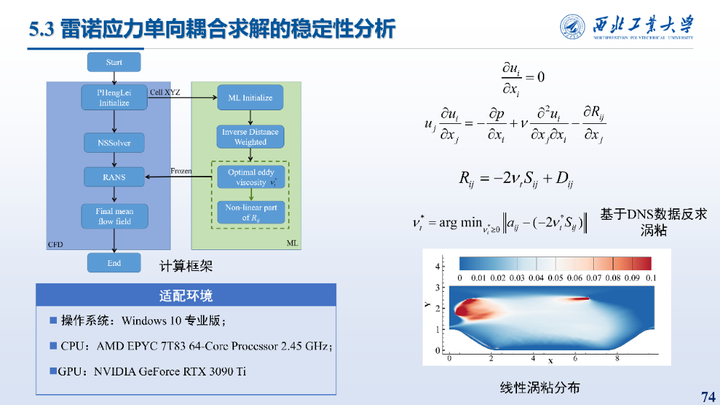
首先以周期山算例中雷诺应力单向耦合求解的稳定性分析为例对框架进行说明,在这个例子中CFD求解器传递格心坐标到Python部分,Python基于DNS数据反求涡粘并插值,然后将插值后的数据返回到CFD中冻结计算。
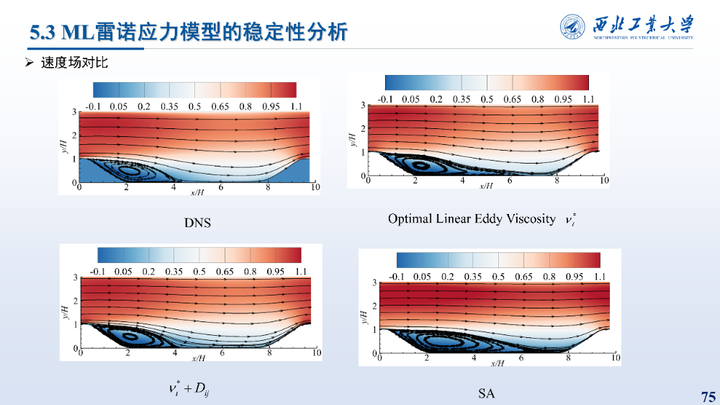
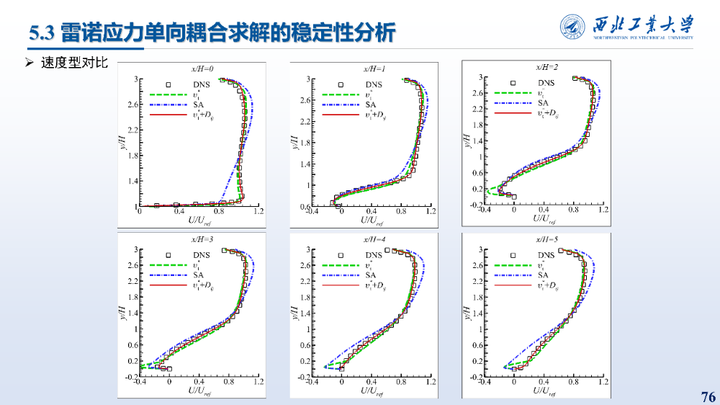
这里对比了不同方法得到的流场以及速度型对比
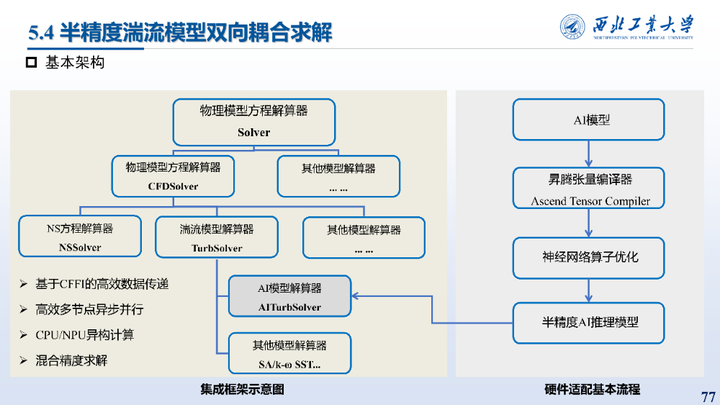
其次是半精度湍流模型双向耦合求解的算例,这部分已经在第二部分进行了说明,这里仅做展示。其集成框架示意图与硬件适配基本流程如图所示。
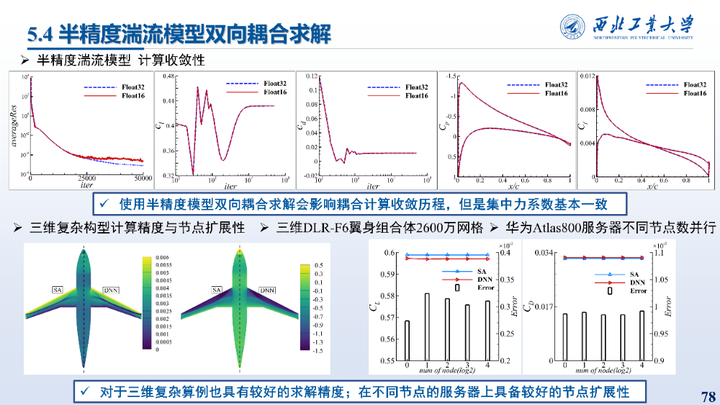
这里对比了半精度湍流模型的计算收敛性以及精度,并在不同节点数量的华为服务器上验证了框架的扩展性。这部分是整个论文的程序基础,为前面各种算法与模型的嵌入提供了重要支撑。




论文下载:
张伟伟教授ReaserchGate可下载