目录
[range optimizer限制](#range optimizer限制)
[Range optimizer跳过index dive*](#Range optimizer跳过index dive*)
[Index Dive](#Index Dive)
[MySQL查询优化分析 - 常见慢查问题与优化方法](#MySQL查询优化分析 - 常见慢查问题与优化方法)
没有将等值条件列用做组合索引前缀
如果查询语句的谓词条件是范围条件与等值条件,存在组合索引,那么当范围条件列作为索引前缀的时候,等值条件是无法被range optimizer用来生成引擎扫描range减少扫描行数的。
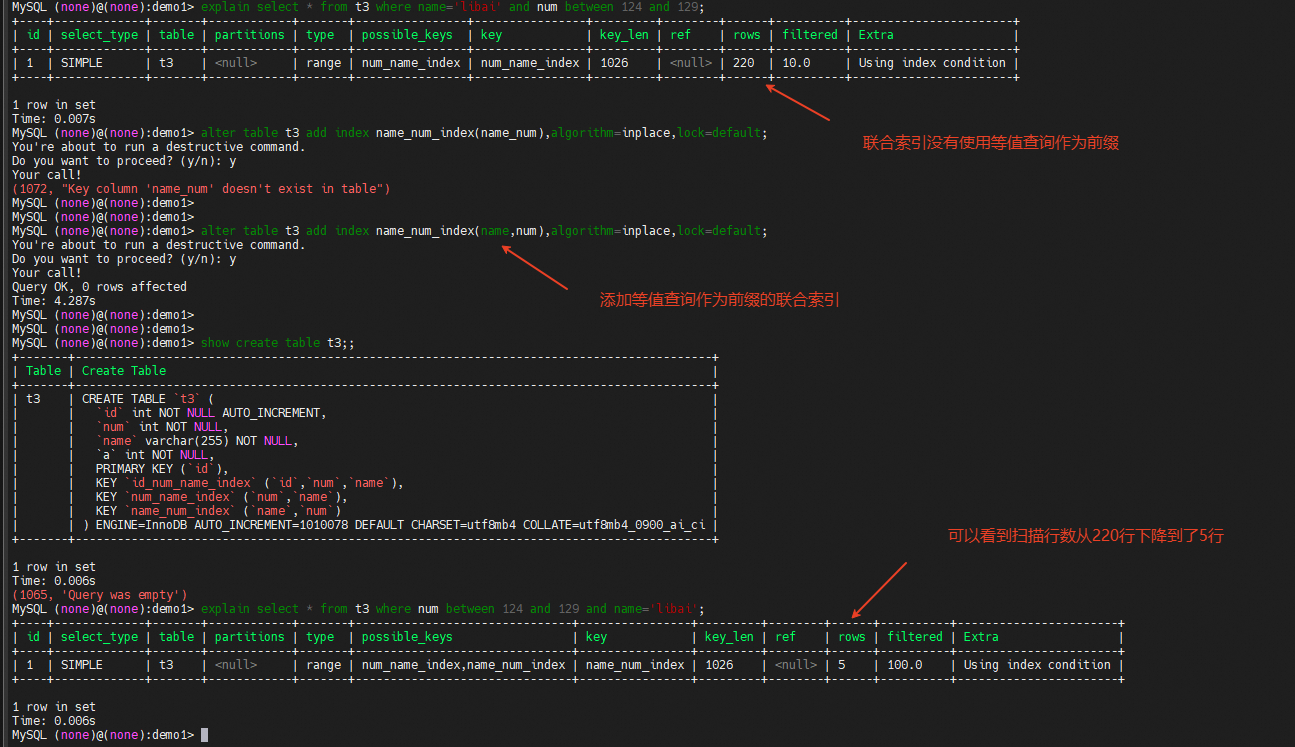
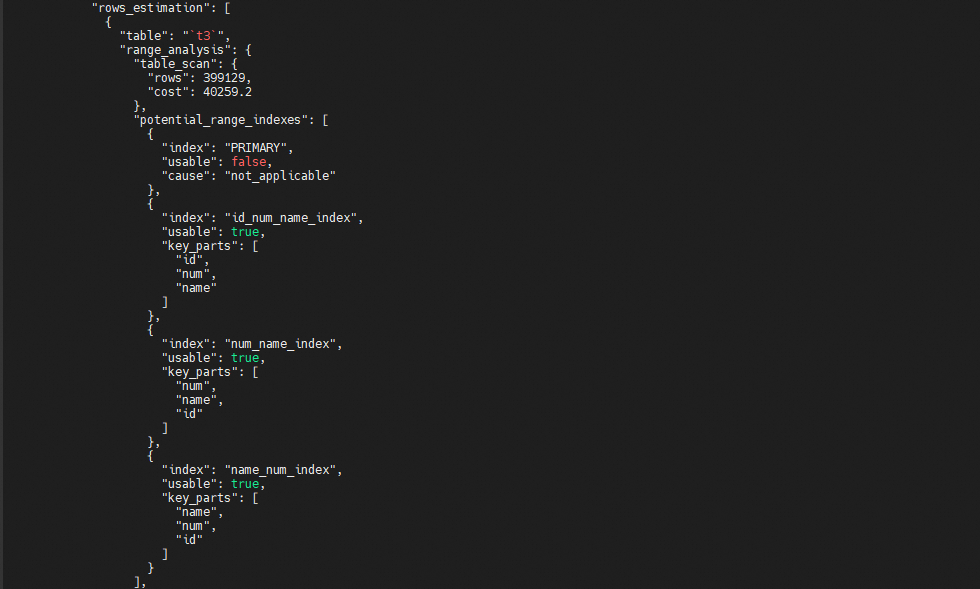
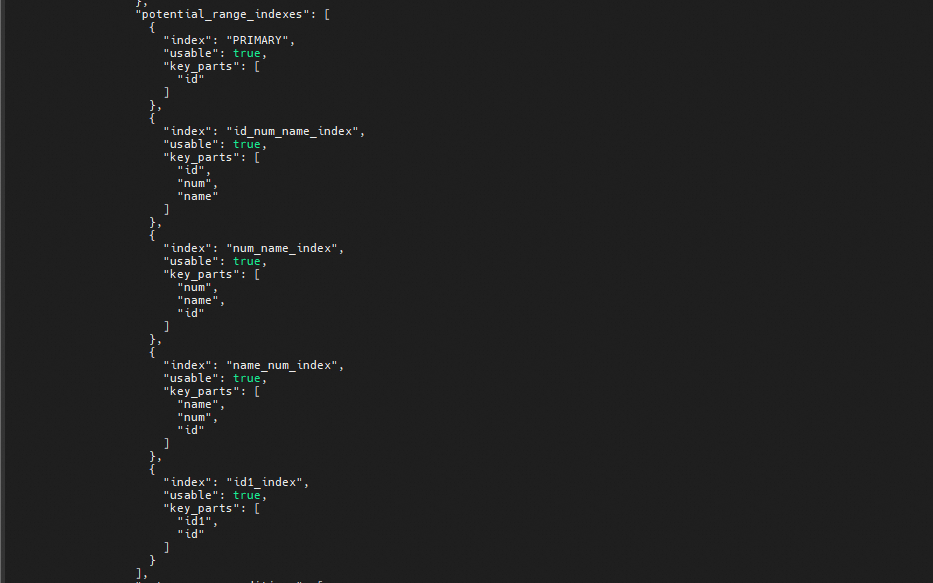
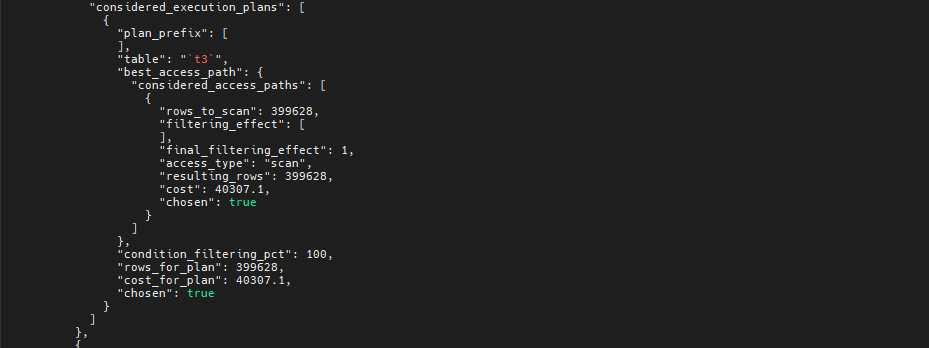
查看optimize trace中的"potential_range_indexes"可以看到表中的三个联合索引都被标记是可用的,排除了主键索引
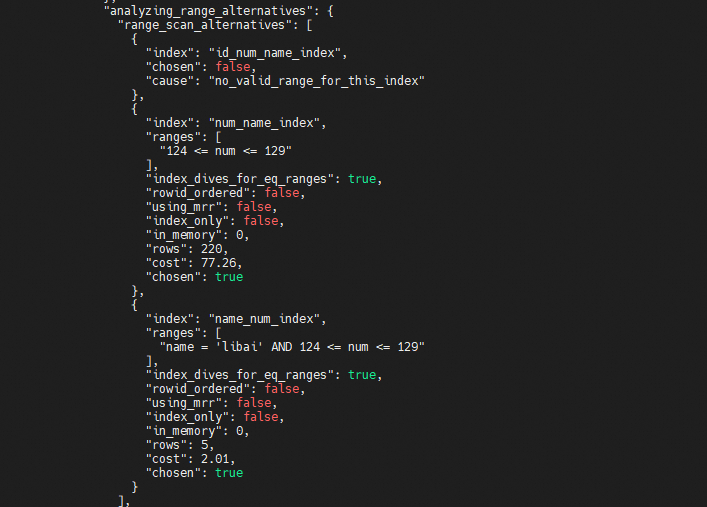
在往下看"analyzing_range_alternatives"中的"range_scan_alternatives"可以看到"index": "id_num_name_index"被淘汰,而"index": "num_name_index"和 "index": "name_num_index"被标记可。,但是"index": "num_name_index"扫描"rows": 220,"cost": 77.26,而"index": "name_num_index"扫描"rows": 5,"cost": 2.01
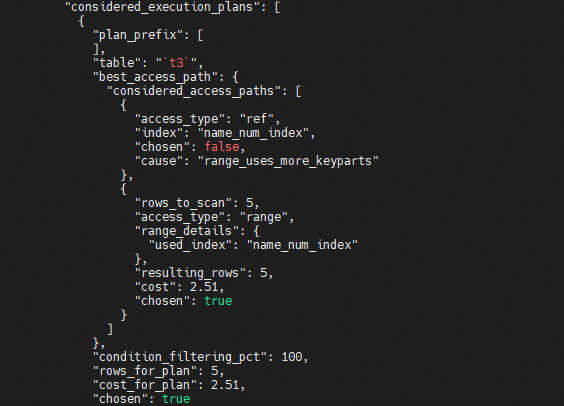
再往下看,可以看到"considered_execution_plans"这里选择了"used_index": "name_num_index"
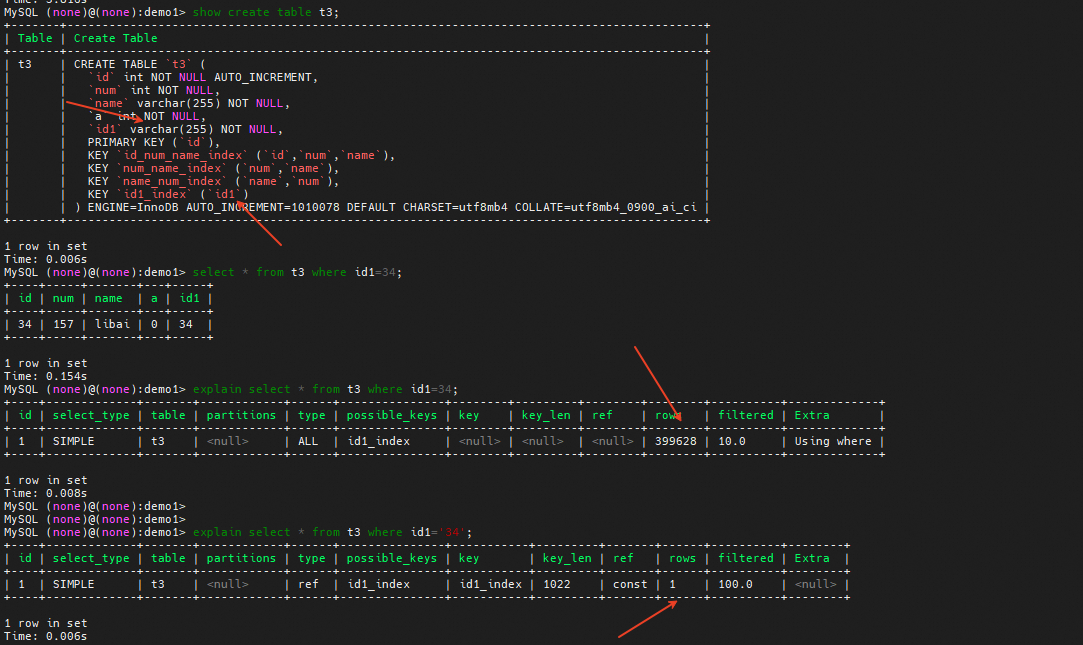
索引列类型和常量类型不一致
当索引列类型和常量类型不一致的时候,可能导致索引无法使用。例如下面的例子,列类型是varchar,而常量类型是Int。在MySQL中varchar类型和int类型比较是会将varchar转换为int类型去比较,这就导致下面语句需要扫描每一行数据将id转换为int类型再做比较。
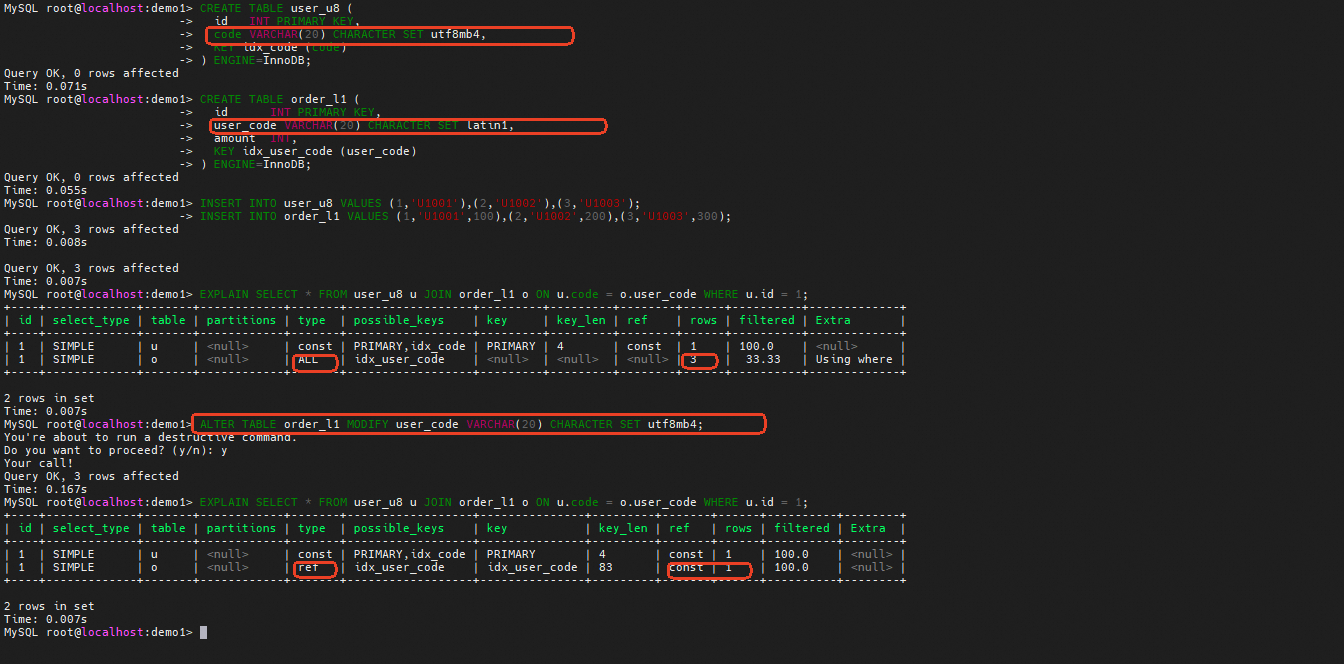
关联字段类型不一致
对于JOIN操作,如果关联字段类型不一样,比如一个是Int,一个是varchar,由于比较类型是Int,那么varchar字段的关联索引就无法用来生成REF访问,减少扫描行数。

关联字段字符集不一致
对于JOIN操作,如果关联字段的字符集不一致,这也会导致索引无法被有效利用,进而导致扫描大量数据,查询执行慢。
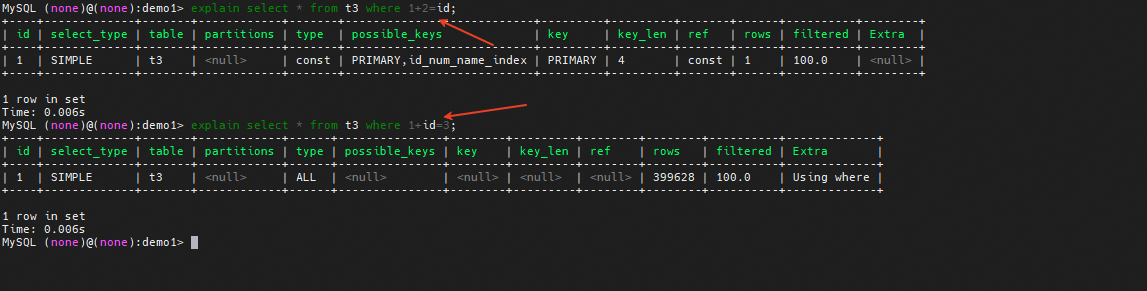
索引列上有表达式计算
当谓词条件中,索引列上有表达式计算的时候,优化器会无法分析抽取range
range optimizer限制
索引的扫描范围分析是由range optimizer处理,一些场景会触发range optimizer的限制。例如in list或者or的条件数太多,在分析扫描范围区间的时候,会消耗大量内存,导致超过range_optimizer_max_mem_size的大小,这类语句EXPLAIN后,在warnings信息中会有提示:
***************************[ 1. row ]***************************
Level | Warning
Code | 3170
Message | Memory capacity of 5 bytes for 'range_optimizer_max_mem_size' exceeded. Range optimization was not done for this query.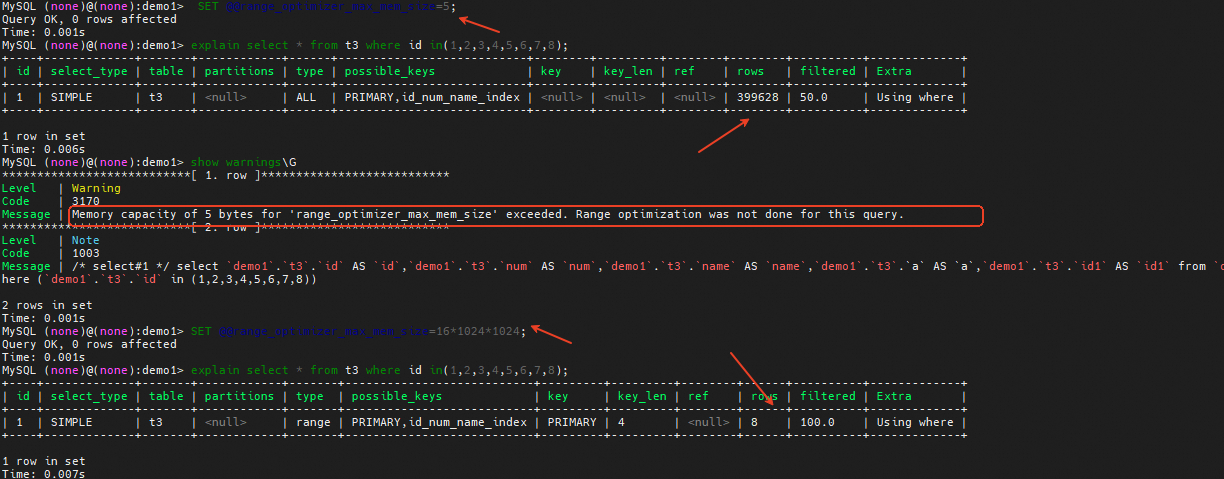
在 MySQL 中,
range_optimizer_max_mem_size是一个系统变量,用于控制查询优化器在执行查询时可以使用的最大内存大小。这个参数影响查询优化器在处理范围查询(如BETWEEN、IN等)时的行为,特别是当这些查询涉及多个表和大量数据时。参数作用
- 内存使用 :
range_optimizer_max_mem_size指定了查询优化器在处理范围查询时可以使用的最大内存量。如果查询的内存需求超过了这个限制,优化器将尝试使用其他方法来处理查询,例如将范围查询转换为全表扫描。参数值
- 默认值:默认值通常为 1MB(1024MB),这意味着查询优化器在处理范围查询时最多可以使用 1MB 的内存。
- 调整:你可以根据服务器的内存大小和查询的复杂性来调整这个值。增加这个值可以让查询优化器在处理更复杂的范围查询时有更多的内存可用,但也可能增加内存消耗。
Range optimizer跳过index dive*
对于索引范围,range optimizer会通过index dive来估算实际扫描行数。由于这会带来实际的数据访问,有一定的代价开销,优化器会限制index dive的场景。对于in list等值条件特别多的场景,当超过eq_range_index_dive_limit的阈值,优化器就不会做index dive,而是基于NDV统计信息去估算扫描行数。如果in list中有倾斜的数据,那么行数估算就会错误。
Index Dive
总结 :拿着每个 IN 值或区间边界去索引根页 → 二分定位 → 读取叶子页中的 记录条数(rec_per_key)。
例如:
拿着一个 IN 值 → 找到它在索引里的 边界页假设表 t 有二级索引 idx(c1),且当前 SQL 是
SELECT * FROM t WHERE c1 IN (17, 29, 53);优化器拿到第一个值 17。
从 索引根页(root page) 开始二分:根页里存的是"子页的最小键值+页号"。
例:根页条目 10→pageA, 20→pageB, 30→pageC
17 落在 10~20 之间 → 指向 pageA。
继续二分直到 叶子页。pageA 不是叶子,再二分 → 找到 叶子页 L17,叶子页里才是真正按顺序排好序的 (c1, row_id) 记录。在叶子页里 统计 17 这个键值出现了多少条,叶子页内部也是有序的,二分即可找到第一条 17。顺序往后扫,直到键值 ≠ 17,统计行数 → 得到 rec_per_key(17)=5 条。把这个行数累加到本次 range 的总扫描行数。对 29、53 重复 1~3 步,就能算出。
total_rows = rec_per_key(17) + rec_per_key(29) + rec_per_key(53)。
基于NDV统计信息去估算扫描行数
总结:
"基于 NDV 统计信息去估算扫描行数" 就是"用总行数 ÷ 列的不同值个数,再乘以查询涉及的不同值个数"
- NDV
Number of Distinct Values------某一列里 有多少个不同的取值。
例:列 status 只有 'OK','FAIL','RUNNING' 3 种值 ⇒ NDV = 3。- 统计信息
MySQL 在执行 ANALYZE TABLE 后,会把- 表总行数 rows
- 该列的 NDV存进 mysql.innodb_index_stats (或 mysql.column_stats 里,8.0 直方图更细)。因此 平均每值出现的行数 = rows / NDV。
- 估算扫描行数
当优化器放弃 "index dive" 时,就直接用上面的平均值乘以 查询里要用到的不同值个数。例子:如果数据倾斜(例如 c1=1 其实有 8 万行,其余值只有 1 行),
估算 100 行 vs 实际 80 004 行,就会出现 "基于 NDV 的估算失真"。
- 表 100 万行,列 c1 NDV = 5 万 ⇒ 平均 20 行/值。
- SQL:WHERE c1 IN (1,2,3,4,5) (5 个值)。
- 估算行数 = 20 × 5 = 100 行。
内容整合于 数据库内核月报 - 2024 / 12