Prometheus+Grafana构建云原生分布式监控系统(一)![]() https://blog.csdn.net/xiaochenXIHUA/article/details/157059743
https://blog.csdn.net/xiaochenXIHUA/article/details/157059743
一、Prometheus是什么?有啥用?适用在哪?
1.1、Prometheus简介
|--------|------------------------------------------------------------------------------|
| Prometheus是一套开源的系统监控报警框架,作为新一代的云原生监控系统,Prometheus既可以实现以主机为中心的监控,也可以完成以服务为导向的动态架构监控。在微服务的世界,它支持多维度的数据集合,查询功能十分强大。 ||
| 序号 | Prometheus的优势 |
| 1 | 【使用简单、部署方便】 prometheus唯一需要的就是一个本地磁盘,因为它的核心部署只有一个单独的二进制文件,没有数据库,缓存等一系列的第三方依赖。 |
| 2 | prometheus可以实现监控服务的内部状态。 |
| 3 | prometheus内置了一个强大的数据查询语言PromQL。通过PromQL可以实现对监控数据的查询、聚合。 |
| 4 | prometheus可以每秒处理数十万的数据。 |
| ||
| 序号 | Prometheus与Zabbix相比,二者的区别如下: |
| 1 | Zabbix更适合【偏向于基础的监控(如:主机、网络这样的场景)】。 |
| 2 | Prometheus【偏向于服务类与容器的监控】。 |
[Prometheus的简介]
1.2、Prometheus架构与工作流程
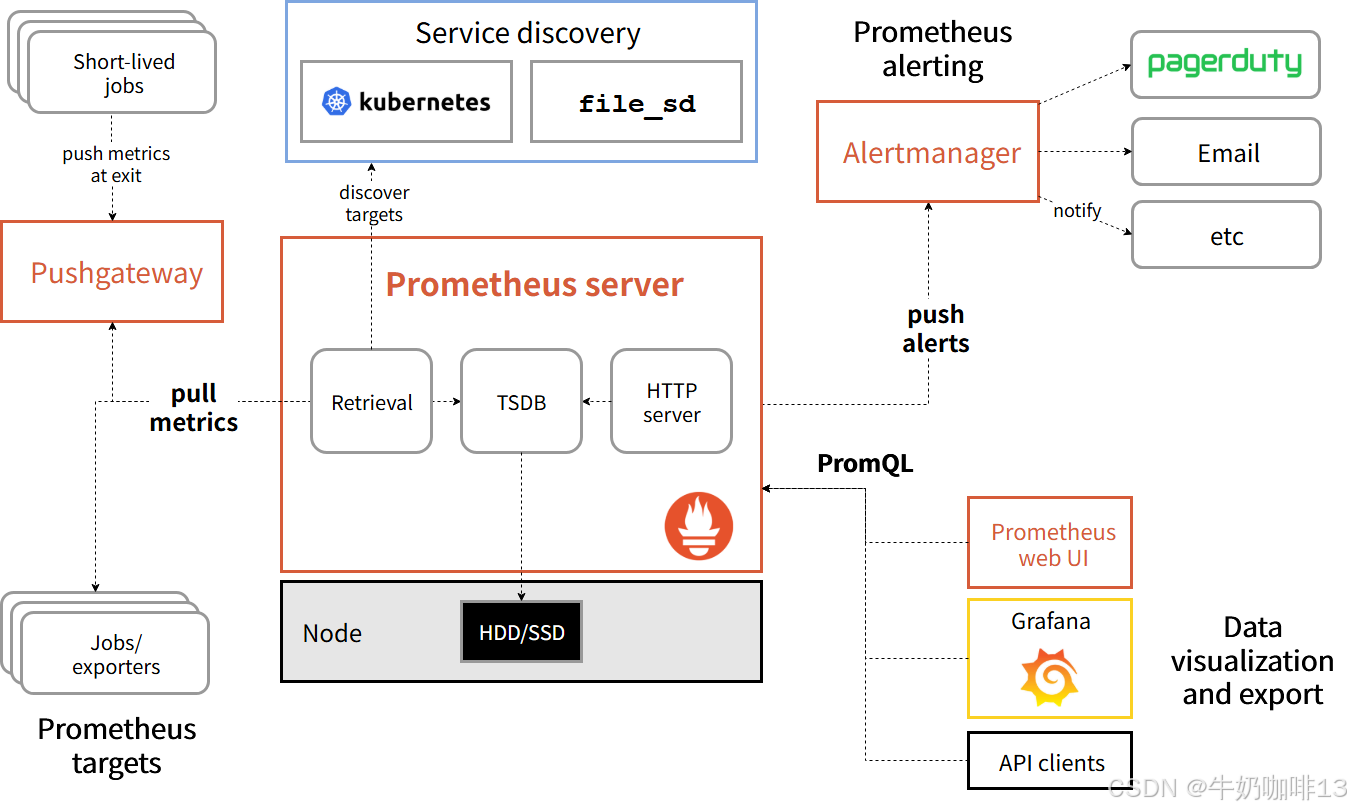
Prometheus的生态系统包括多个组件,大部分的组件是使用Go语言编写的,因此部署十分方便,而这些组件大部分是可选的。Prometheus的基础架构图如下:
|--------|-----------------------|-----------------------------------------------------------------------------------------------------------|
| 序号 | prometheus的组件 | 说明 |
| 1 | Prometheus Server | Prometheus Server是Prometheus组件中的核心,主要负责实现对监控数据的获取,存储及其查询。 |
| 2 | Push Gateway | 推送网关主要是用来接收【客户端(client push)】推送过来的指标数据,在指定的时间间隔由Prometheus Server来抓取。 |
| 3 | Exporter | 主要用来采集数据,并通过HTTP服务的形式暴露给Prometheus Server。Prometheus Server通过访问该Exporter提供的接口,即可获取到需要采集的监控数据。 |
| 4 | Alertmanager | 告警管理器主要是负责监控报警功能,在Prometheus Server中支持PromQL创建告警规则,若满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则是由AlertManager进行管理。 |
[Prometheus的组件介绍]
|--------|--------------------------------------------------------------------------------------------------------|
| 序号 | Prometheus的工作流程 |
| 1 | Prometheus Server 以服务发现(如:Kubernetes、DNS等)方式自动发现或静态配置添加监控目标。 |
| 2 | Prometheus Server 定期从监控目标(Jobs/exporters)或【Push Gateway】中拉取数据指标(metrics),将时间序列数据保存到其自身的时间序列数据库(TSDB)中。 |
| 4 | Prometheus Server 通过HTTP Server 对外开放接口,通过可视化工具(如:prometheus web UI、Grafana或自己开发的工具)以PromQL查询、导出数据。 |
| 5 | 当有告警产生时,Prometheus Server 将告警信息推送到Alertmanager。由Alertmanager根据配置的告警策略发送告警信息到对应的接收端。 |
| 6 | Push Gateway 接收 "Short-lived"类型的 Jobs 推送过来的 metrics 并缓存,等待 Prometheus Server 来抓取。 |
[Prometheus的工作流程]
1.3、pull与push
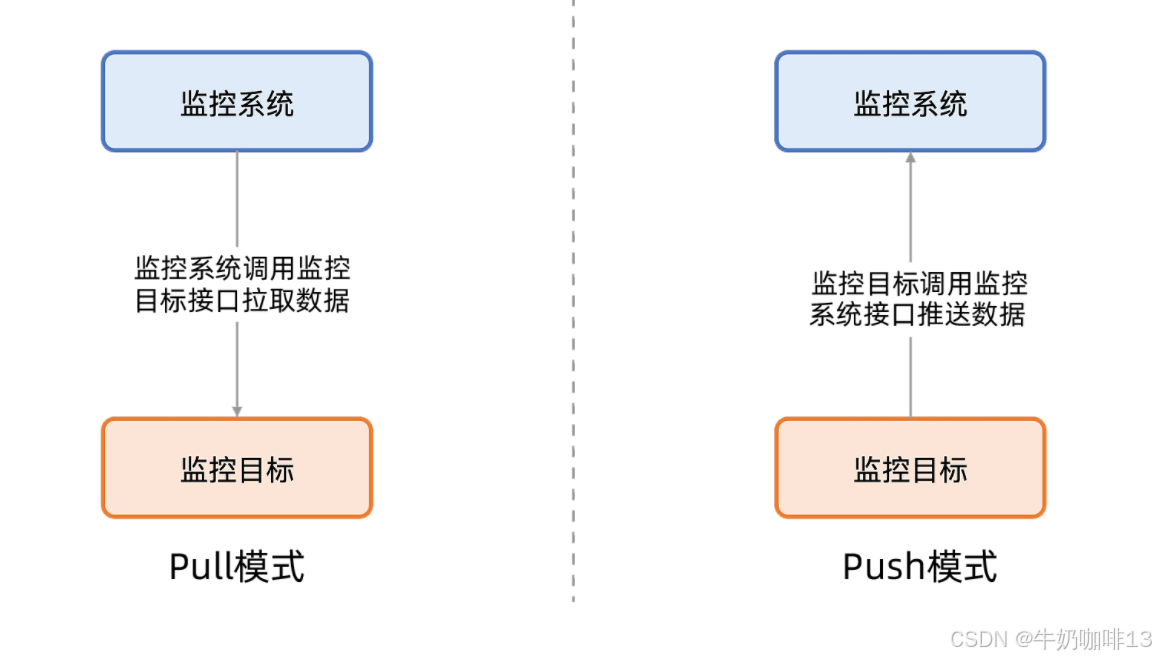
Prometheus是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并符合Prometheus定义的数据格式,就可以接入Prometheus监控。
Prometheus Server负责定时在目标上抓取指标(metrics)数据,每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为拉(pull)模式。拉模式的优势是:
《1》降低耦合(即:已有的系统或应用不用做任何修改,就可以被采集到各种监控数据,被采集端无需感知监控系统的存在,完全独立于监控系统之外);
《2》可控性好(即:拉模式下监控系统是主动的一方,可以控制频率)而推(push)模式则客户端是主动的一方,需要编写配置相关监控内容,若编写配置有问题,就会给监控系统造成一些不必要的压力与故障;
Prometheus是通过pull方式拉取数据的;但对于【网络只能出不能进】或者【瞬时或批量作业】场景使用push模式是最佳的。
1.4、Prometheus的适用与不适用场景
|--------|----------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 序号 | 场景 | 说明 |
| 1 | Prometheus的适用场景 | 《1》非常适合记录任何纯数值时间序列。 《2》如:【以机器为中心的监控】【高度动态的服务导向架构的监控】【微服务领域】。 Prometheus的设计宗旨是可靠性(即:在发生故障时可以依赖的系统,可以快速诊断问题。且每个Prometheus都是独立的,不依赖于网络或其他远程服务。当基础设施的其他部分出现故障时,依然可以依赖它提供的相关统计信息。并且还不需要配置大量的基础设施来使用它)。 |
| 2 | Prometheus的不适用场景 | 需要100%的准确性(如:每次请求计费,因为Prometheus收集到的数据不够详细和完整) |
[Prometheus的适用与不适用场景]
二、Prometheus的安装和配置
2.1、时序数据库
时序数据库全称为时间序列数据库。时间序列数据库是指主要用于处理带时间标签(按照时间的顺序变化【即:时间序列化】)的数据,带时间标签的数据也称为时间序列数据。常适用于物联网设备监控和互联网业务监控场景,提供高性能读写和强聚合计算服务。
时间序列数据库主要按照一定的时间间隔产生一个个数据点,以时间轴为横坐标,序列为纵坐标。如下图所示:

每条时间序列通过指标名称(metrics name)和一组标签集(lableset)命名,示例如下:
bash
#每条时间序列通过指标名称(metrics name)和一组标签集(lableset)命名示例
. . . . . . . . . . . . . . . . . node_cpu_seconds_total{cpu="cpu0",mode="idle"}
. . . . . . . . . . . . . . . . . node_cpu_seconds_total{cpu="cpu0",mode="system"}
. . . . . . . . . . . . . . . . node_load1{}
......|--------|----------------|-------------------------------------------------|
| 每个数据点都代表一条时间序列数据;但同一个时间点可能会产生多条数据,只要指标名称或标签不同,就是不同的数据。另外如果时间点不同,指标名称或标签相同,也会产生一个数据点。 |||
| 序号 | 时序数据库特点 | 说明 |
| 1 | 严重依赖于采集的时间 | 每条数据都有一个时间戳,通常以UNIX时间为单位,可以方便地对数据进行排序和查询。 |
| 2 | 数据产生频率快 | 高并发写入,主要是写入和读取操作,没有更新操作,通常以秒或毫秒为单位,有时甚至会达到微妙级别。 |
| 3 | 存在明显的冷热数据 | 一般只会查询近期数据。对冷数据降低精度存储,对历史数据做聚合,节省存储空间。 |
| 4 | 大量的统计查询要求 | 查询一定时间范围内的计数、最大值、最小值和平均值。 |
| 常见的时序数据库有【InfluxDB】【OpenTSDB】等。 |||
[时序数据库的特点]
2.2、Prometheus指标数据详解
Promethes监控中,对于采集过来的数据统称为指标(metrics)数据,当需要为某个系统、某个服务做监控统计时,就需要用到指标数据。因此,指标是对采样数据的总称。注意:metrics并不代表某种具体的数据格式,它是对于度量计算单位的抽象。
|--------|----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Prometheus将采集的监控数据以指标(metric)的形式保存在内置的【时间序列】数据库当中(TSDB),每一条时间序列都是由 metric 的名字和一系列的标签(key/value键值对)来唯一标识的,不同的标签代表不同的时间序列。 bash #单条时间序列格式 <metric name>{<label name>=<label value>, ...} |||
| 序号 | 单条时间序列 | 说明 |
| 1 | 指标(metric) | 指标的名称可以反映被监控样本的含义,一般用于表示指标的功能。 如:prometheus_http_requests_total, 表示http请求的总数。其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成。 |
| 2 | 标签(lable) | 标签可以使 Prometheus的数据更加丰富,对于相同的指标名称,通过不同标签列表的集合,会形成特定的维度实例。改变任何指标上的任何标签值(包括添加或删除指标),都会创建新的时间序列。 如:prometheus_http_requests_total{code="200"}表示所有http请求中状态码为200的请求。当code="403"时,就变成一个新的指标。标签中的键由ASCII字符,数字,以及下划线组成。其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何 Unicode 编码的字符。 |
[Prometheus的单条指标数据格式解析]
在时间序列中的每一个点称为一个样本(sample),时间序列的样本数据包括一个float64的值和一个毫秒级的unix时间戳,这些数据是按照某个时序以时间维度采集的数据。这样,一个完整的时间序列的组成如下图所示:

bash
#<--------------- metric and lable---------------------><-timestamp -> <-value->
http_request_total{status="200", method="GET"} @1434417560938 => 94355
http_request_total{status="200", method="GET"} @1434417561287 => 94334
http_request_total{status="404", method="GET"} @1434417560938 => 38473
http_request_total{status="404", method="GET"} @1434417561287 => 38544
http_request_total{status="200", method="POST"} @1434417560938 => 4748
http_request_total{status="200", method="POST"} @1434417561287 => 47852.3、Prometheus Server的下载安装
本文接下来都是以【AlmaLinux9】进行演示操作的(你也可以使用红帽系9的其他系统如:RHEL9/RockyLinux9)。
2.3.1、ntp时间同步
在正式安装Prometheus之前必须先进行NTP时间同步(这是因为Prometheus Server对系统时间的准确性要求很高,必须保证本机时间实时同步)。
bash
#Linux服务器进行NTP时间同步操作
#1-设置系统时区为【亚洲/上海】
timedatectl set-timezone Asia/Shanghai
#方法一(centos8及其更高版本已经废弃):配置定时任务实现每小时进行NTP时间同步
contab -e
0 * * * * /usr/sbin/ntpdate -u ntp.ntsc.ac.cn ntp.aliyun.com > /dev/null 2>&1
#方法二(推荐)
yum install chrony -y
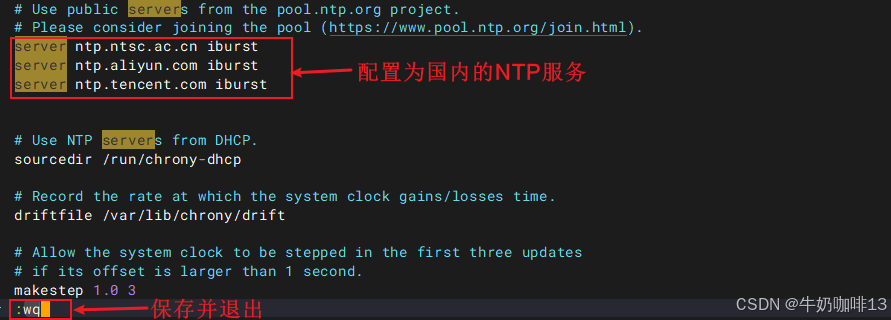
vi /etc/chrony.conf
#【/etc/chrony.conf】文件中第一行中的NTP服务器修改为国内的
server ntp.ntsc.ac.cn iburst
server ntp.aliyun.com iburst
server ntp.tencent.com iburst
#重启服务并设置开机自启
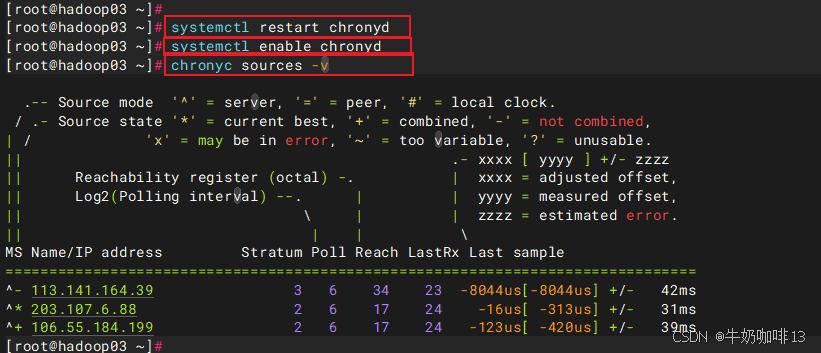
systemctl restart chronyd
systemctl enable chronyd
#验证同步状态
chronyc sources -v
2.3.2、Prometheus的下载安装
首先到Prometheus官网下载适合自己的版本,建议下载长期支持版本(LTS)(如:)
bash
#下载安装Prometheus
#1-下载Prometheus
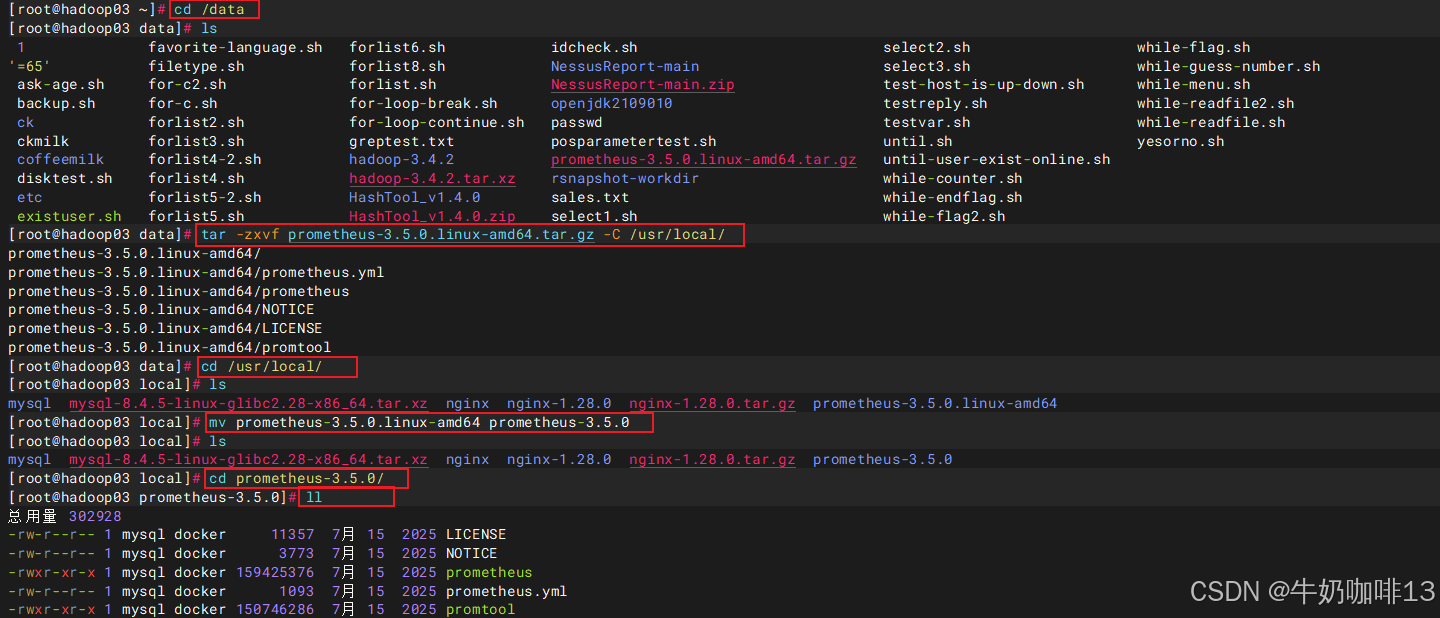
wget https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz -c -P /data
#2-解压下载好的Prometheus
cd /data
tar -zxvf prometheus-3.5.0.linux-amd64.tar.gz -C /usr/local/
cd /usr/local
mv prometheus-3.5.0.linux-amd64 prometheus-3.5.0
cd prometheus-3.5.0/
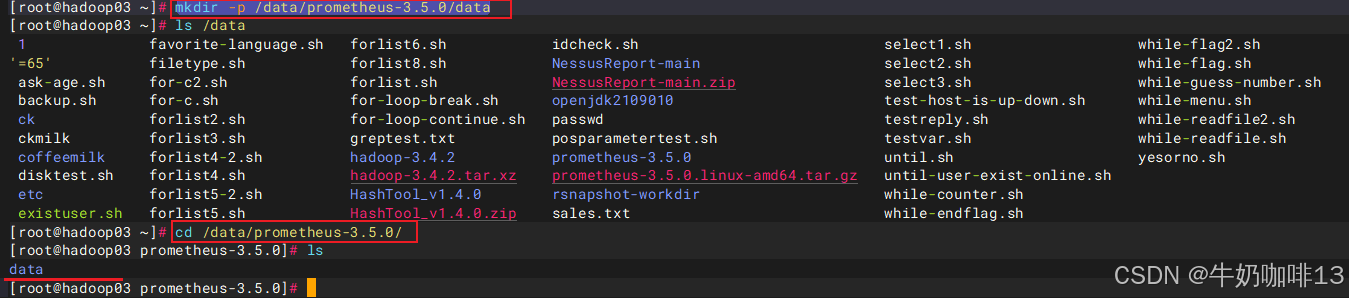
mkdir -p /data/prometheus-3.5.0/data
#3-编写Prometheus的服务方便管理
vi /usr/lib/systemd/system/prometheus.service
#【/usr/lib/systemd/system/prometheus.service】的完整文件
[Unit]
Description=Prometheus: the alerting system
Documentation=http://prometheus.io/docs/
After=prometheus.service
[Service]
ExecStart=/usr/local/prometheus-3.5.0/prometheus --web.enable-lifecycle --storage.tsdb.retention.time=90d --storage.tsdb.path=/data/prometheus-3.5.0/data --config.file=/usr/local/prometheus-3.5.0/prometheus.yml
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
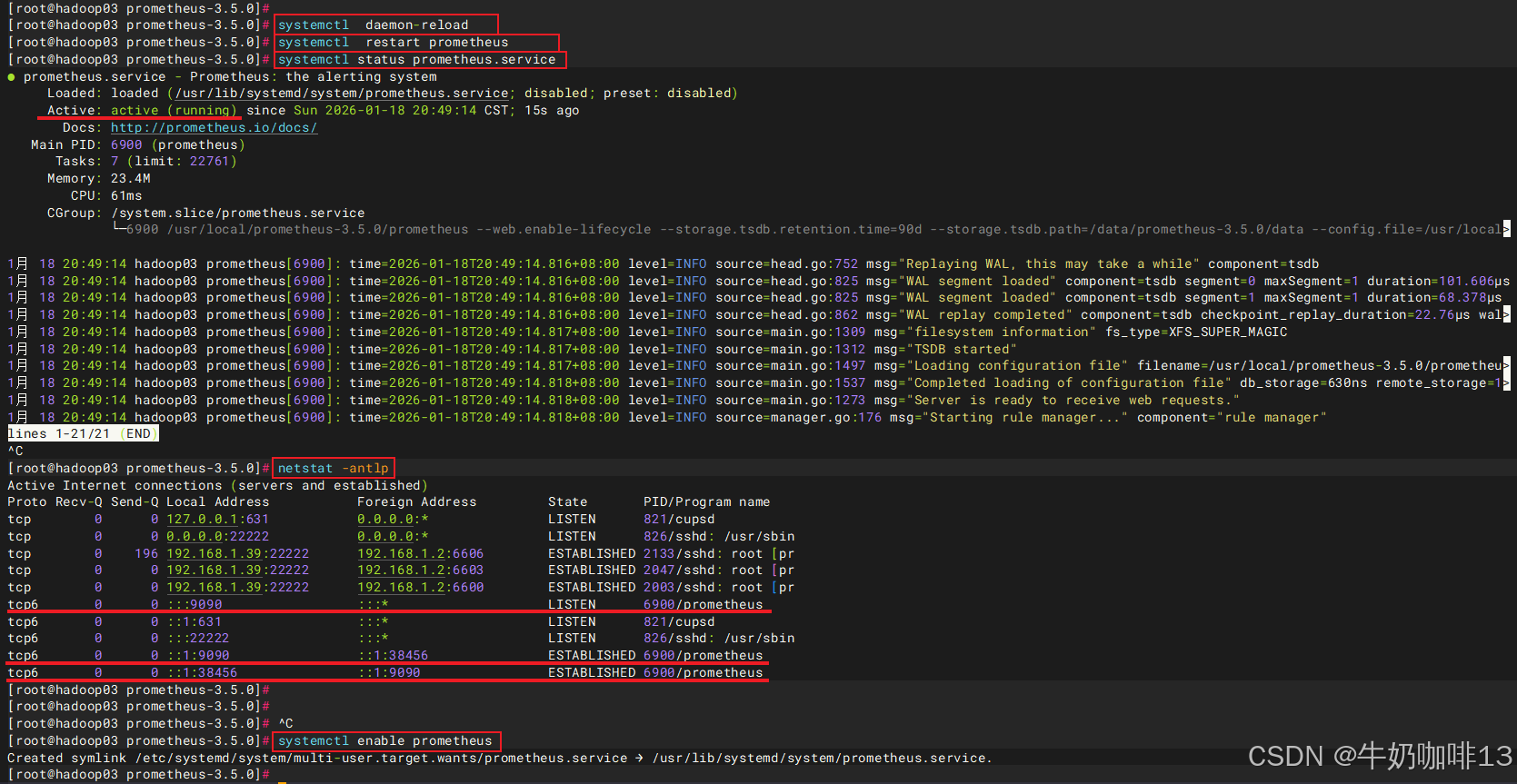
#4-通过systemctl来管理prometheus服务
systemctl daemon-reload
systemctl restart prometheus
systemctl status prometheus.service
netstat -antlp | grep prometheus
systemctl enable prometheus
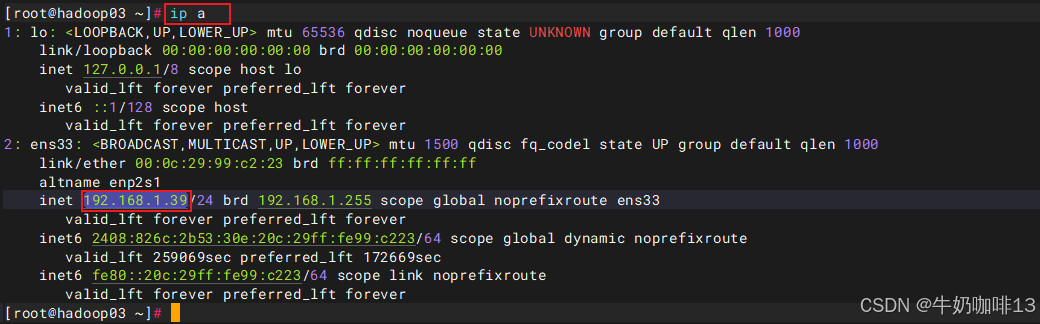
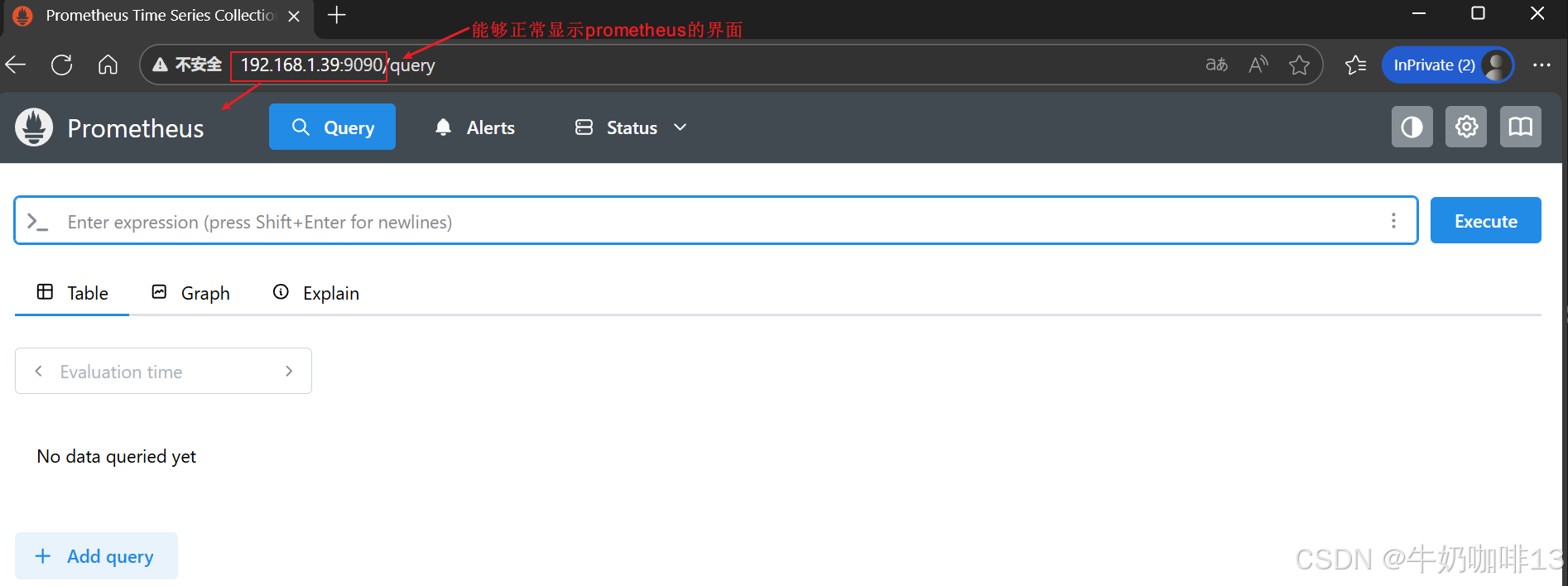
#5-通过【ip:9090】端口即可访问到prometheus的web界面【Prometheus UI】
ip a
#注意:若是启动prometheus报错,则需要【查看系统日志中Prometheus相关的错误信息】后解决
journalctl -u prometheus -f|--------|-----------------------------------|--------------------------------|
| 序号 | prometheus的启动参数 | 说明 |
| 1 | --config.file | 加载prometheus的配置文件 |
| 2 | --web.listen-address | 监听prometheus的web地址和端口,默认是9090。 |
| 3 | --web.enable-lifecycle | 热启动参数,可在不中断服务的情况下重启加载配置文件 |
| 4 | --storage.tsdb.retention.time | 数据持久化的时间(根据业务情况设置) |
| 5 | --storage.tsdb.retention.size | 数据持久化的大小 |
| 6 | --storage.tsdb.path | 数据持久化的保存路径 |
| |||
| 【Prometheus UI】是Prometheus内置的一个可视化web管理界面,通过Prometheus UI,用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。 Promtheus作为一个时间序列数据库,其采集的数据会以文件的形似存储在本地中,默认的存储路径为执行命令的当前data目录下,会自动创建,用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径。 |||
[prometheus的启动参数介绍]


三、Prometheus的配置文件解析
Prometheus的主配置文件【prometheus.yml】该文件存在prometheus解压后的目录下(如:这里是【/usr/local/prometheus-3.5.0/prometheus.yml】)。prometheus.yml文件的内容如下:
bash
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
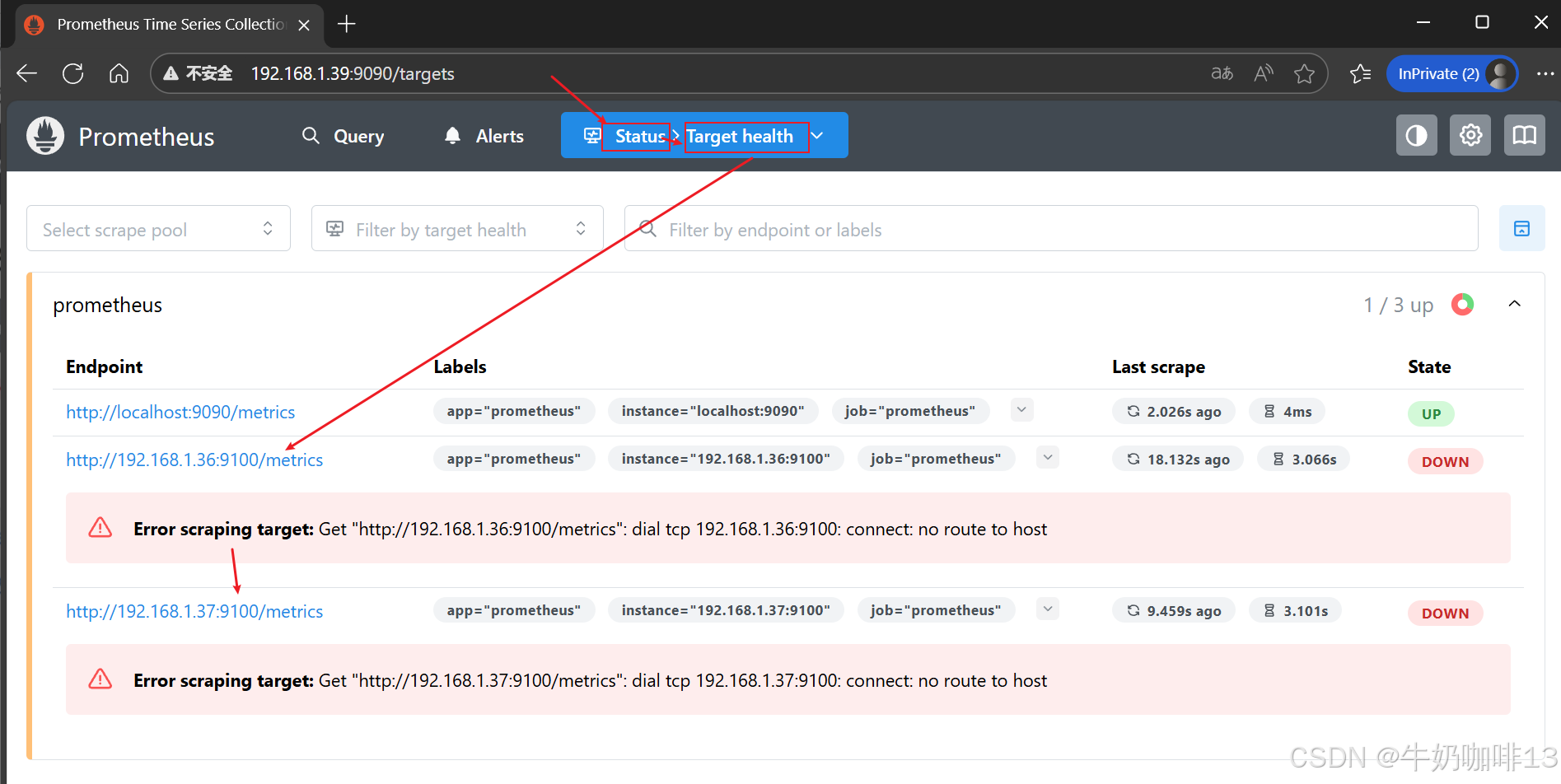
- targets: ["localhost:9090",'192.168.1.36:9100','192.168.1.37:9100']
# The label name is added as a label `label_name=<label_value>` to any timeseries scraped from this config.
labels:
app: "prometheus"|--------|-------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 序号 | prometheus.yml文件的参数 | 说明 |
| 1 | global | global是一些常规的全局配置 bash scrape_interval: 15s #每隔15秒向目标抓取一次数,默认为一分钟 evaluation_interval: 15s #每隔15秒执行一次告警规则检查,默认为一分钟 |
| 2 | alerting | 是报警管理的配置内容,后续会详细配置说明 |
| 3 | rule_files | 指定加载的告警规则文件,后续也会详细配置说明 |
| 4 | scrape_configs | 指定prometheus要监控的目标,是比较复杂的内容。 在scrape_config中每个监控目标是一个job,但job的类型有很多种(可以是最简单的static_config【即:静态地指定每一个目标】;也可以是动态发现的目标)。 bash #静态的指定目标(用逗号隔开,每个目标是IP+端口号(是exporters的端口, #9100是node_exporter的默认端口)) - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090",'192.168.1.36:9100','192.168.1.37:9100'] |
[prometheus.yml文件中的参数解析]
prometheus.yml文件配置完成后,prometheus就可以通过配置文件识别监控的节点,持续开始采集数据,prometheus基础配置也就搭建好了。
bash
#prometheus配置文件编写完成后,还可以通过【promtool】工具进行校验配置是否正确
#结果显示【SUCCESS】字样则表示配置文件正确,否则就是有问题根据提示解决
cd /usr/local/prometheus-3.5.0
./promtool check config prometheus.yml
#【prometheus.yml】文件校验正确后需重启prometheus服务
systemctl restart prometheus.service