学习和适应对于增强人工智能 Agent 的能力至关重要。这些过程使 Agent 能够超越预定义参数进行演化,通 过经验和环境交互实现自主改进。通过学习和适应,Agent 可以有效应对新情况并优化其性能,而无需持续 的人工干预。
本文将深入探讨支撑 Agent 学习和适应的原理与机制。
全局视角
Agent 通过基于新经验和数据改变其思维、行动或知识来实现学习和适应。这使得 Agent 能够从简单地遵循 指令演化为随时间推移变得更加智能。
・ 强化学习: Agent 尝试行动并获得积极结果奖励/消极结果惩罚,在动态环境中学习最优行为。适用于 控制机器人或游戏角色的 Agent。
・ 监督学习: Agent 从标注示例学习输入与期望输出的映射关系,支持决策制定和模式识别任务。适用 于邮件分类或趋势预测的 Agent。
・ 无监督学习: Agent 在未标注数据中发现隐藏模式和关联,构建环境心理模型并获取洞察。适用于无 特定指导的数据探索场景。
・ 基于大语言模型(LLM)的少样本/零样本学习:利用大语言模型的 Agent 通过少量示例或明确指令快 速适应新任务,实现对新命令/情况的即时响应。
・ 在线学习: Agent 持续更新知识库以适应动态环境,对实时响应和持续优化至关重要。适用于处理连 续数据流的 Agent。
・ 基于记忆的学习: Agent 回忆过往经验调整当前行动,增强上下文感知和决策能力。特别适合具备记 忆召回能力的 Agent。
Agent 基于学习结果改变策略、理解或目标来实现适应。这对于在不可预测、变化或新环境中的 Agent 至关 重要。
近端策略优化(PPO)是一种强化学习算法,用于在具有连续动作范围的环境中训练 Agent,例如控制机器 人的关节或游戏中的角色。其主要目标是可靠且稳定地改进 Agent 的决策策略(即其策略)。
PPO 的核心思想是对 Agent 策略进行小幅谨慎更新,避免可能导致性能崩溃的剧烈变化。
其工作流程如下:
**1. 收集数据:**Agent 使用其当前策略与环境交互(例如,玩游戏)并收集一批经验数据(状态、动作、奖 励)。
2. 评估替代目标(Surrogate Goal): PPO 计算策略更新对预期奖励的影响,使用特殊的"裁剪"目标 函数而非单纯奖励最大化。
**3. 裁剪机制:**这是 PPO 稳定性的关键。它在当前策略周围创建一个"信任区域"或安全区,阻止算法进 行与当前策略差异过大的更新。这种裁剪机制就像一个安全刹车,确保 Agent 不会采取巨大而有风险 的步骤来破坏其学习成果。 简而言之,PPO 在改进性能与保持接近已知有效策略之间取得平衡,这可以防止训练期间的灾难性故障并实 现更稳定的学习过程。
**直接偏好优化(DPO)**是一种专门为使大语言模型与人类偏好保持一致而设计的更新方法。它为此任务提供 了比使用 PPO 更简单、更直接的替代方案。 要理解 DPO,首先了解传统的基于 PPO 的对齐方法会有所帮助:
・ PPO 方法(两步过程):
**1. 训练奖励模型:**首先收集人类反馈数据,人们在其中评级或比较不同的 LLM 响应(例如,"响应 A 比响应 B 更好")。这些数据用于训练一个独立的 AI 模型,称为奖励模型,其任务是预测人类会给 任何新响应打什么分数。
**2. 使用 PPO 微调:**接下来使用 PPO 微调 LLM。LLM 的目标是生成能够从奖励模型获得最高分的响 应。奖励模型在训练过程中充当"评判员"。 这个两步过程可能既复杂又不稳定。例如,LLM 可能会找到漏洞并学会"破解"奖
励模型,为质量较差的响 应获得高分。
・ DPO 方法(直接过程): DPO 完全跳过了奖励模型。它不是将人类偏好转换为奖励分数然后优化该分 数,而是直接使用偏好数据来更新 LLM 的策略。
・ 它通过利用直接将偏好数据与最优策略联系起来的数学关系来工作。本质上,它教导模型:"增加生成 类似偏好响应的概率,减少生成类似不受欢迎响应的概率。" 本质上,DPO 通过直接在人类偏好数据上优化语言模型来简化对齐过程。这避免了训练和使用单独奖励模 型的复杂性和潜在不稳定性,使对齐过程更加高效和稳健。
实际应用与用例
自适应 Agent 通过由经验数据驱动的迭代更新,在可变环境中表现出增强的性能。
**・ 个性化助手 Agent:**分析用户行为模式优化交互协议,生成高度定制化响应。
**・ 交易机器人 Agent:**基于实时市场数据动态调整模型参数,优化决策算法并平衡风险收益。 ・ 应用程序 Agent:根据用户行为动态修改界面功能,提升系统直观性和参与度。
**・ 机器人及自动驾驶 Agent:**整合传感器数据和历史行动分析,实现各种环境下的安全高效操作。
**・ 欺诈检测 Agent:**识别新型欺诈模式改进预测模型,增强异常检测能力并降低损失。
**・ 推荐 Agent:**采用用户偏好学习算法,提供高度个性化的上下文相关推荐。
**・ 游戏 AIAgent:**动态调整战略算法增加游戏复杂性和挑战性,提升玩家参与度。
**・ 知识库学习 Agent:**利用检索增强生成(RAG)维护问题与解决方案的动态知识库,通 过成功模式复用和陷阱规避有效适应新情况。
概览
是什么:
AI Agent 通常在动态和不可预测的环境中运行,其中预编程逻辑是不够的。当面对初始设计期间未 预料到的新情况时,它们的性能可能会下降。没有从经验中学习的能力,Agent 无法随时间优化其策略或个 性化其交互。这种刚性限制了它们的有效性,并阻止它们在复杂的现实世界场景中实现真正的自主性。
为什么:
标准化解决方案是集成学习和适应机制,将静态 Agent 转变为动态的、演化的系统。这使 Agent 能 够基于新数据和交互自主改进其知识和行为。Agent 系统可以使用各种方法,从强化学习到更高级的技术, 如自我改进编码 Agent(SICA)中看到的自我修改。像 Google 的 AlphaEvolve 这样的高级系统利用 LLM 和 进化算法来发现全新的、更高效的复杂问题解决方案。通过持续学习,Agent 可以掌握新任务、增强其性能 并适应变化的条件,而无需持续的手动重新编程。
经验法则:
在构建必须在动态、不确定或演化环境中运行的 Agent 时使用此模式。它对于需要个性化、持续 性能改进以及自主处理新情况的能力的应用至关重要。
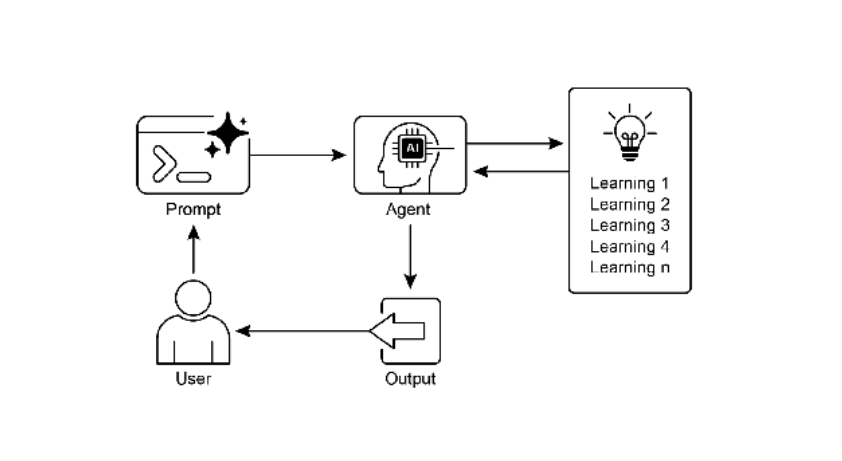
图3:学习和适应模式
关键要点
・ 学习和适应是 Agent 通过经验改进行为并处理新情况的过程
・"适应"是学习导致的 Agent 行为/知识的可见变化
・ 自我改进编码 Agent(SICA)通过修改代码自我演进,产生智能编辑器、AST 符号定位器等工具
・ 专用"子Agent"和"监督者"架构帮助管理系统复杂性
・ 智能设置 LLM 上下文窗口(系统提示/核心提示/助手消息)对运行效率至关重要
・ 本模式对动态/不确定/需个性化环境中的 Agent 必不可少
・ 构建学习型 Agent 需集成机器学习工具并管理数据流
・ 具备基础编码能力的 Agent 系统可自主改进基准任务性能
・ AlphaEvolve 利用大语言模型和进化框架自主发现优化算法,推动科研与工程应用
案例研究
自我改进编码 Agent(SICA) 自我改进编码 Agent(SICA)由 Maxime Robeyns、Laurence Aitchison 和 Martin Szummer 开发,代表了 基于 Agent 的学习的重要进展,展示了 Agent 修改自身源代码的能力。这与传统方法形成鲜明对比,在传统 方法中,一个 Agent 可能训练另一个 Agent;而 SICA 既是修改者又是被修改的实体,通过迭代方式改进其 代码库,以提升在各种编码挑战中的性能。 SICA 的自我改进通过迭代循环实现(见图 1)。Agent 首先审查历史版本在基准测试的表现,选择加权评分 (成功率/时间/计算成本)最高的版本。选定版本分析存档识别改进点,直接修改代码库后重新测试并记录结 果。此循环机制使 Agent 无需传统训练即可持续进化。
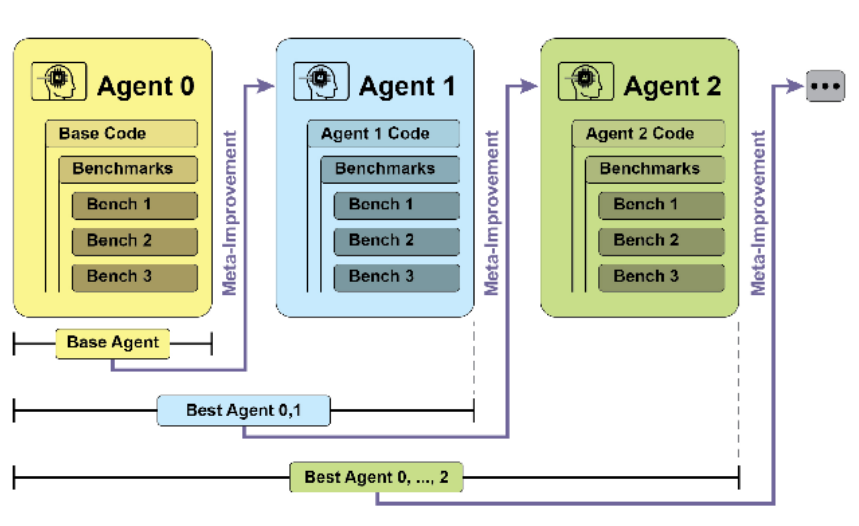
图 1:SICA 的自我改进过程,基于其过去版本进行学习和适应
SICA 经历了显著的自我改进,在代码编辑和导航方面取得了重要进展。最初,SICA 使用基本的文件覆盖方 法进行代码更改。随后,它开发了能够进行更智能和上下文相关编辑的"智能编辑器"。这进一步演变为"差 异增强智能编辑器",结合差异进行有针对性的修改和基于模式的编辑,以及"快速覆盖工具"以减少处理 需求。
SICA 进一步实现了"最小差异输出优化"和"上下文敏感差异最小化",使用抽象语法树(AST)解析来提 高效率。此外,还添加了"智能编辑器输入规范化器"。在导航方面,SICA 独立创建了"AST 符号定位器", 使用代码的结构图(AST)来识别代码库中的定义。后来,开发了"混合符号定位器",将快速搜索与 AST 检 查相结合。这通过"混合符号定位器中的优化 AST 解析"进一步优化,专注于相关代码部分,提高搜索速度 (见图 2)。
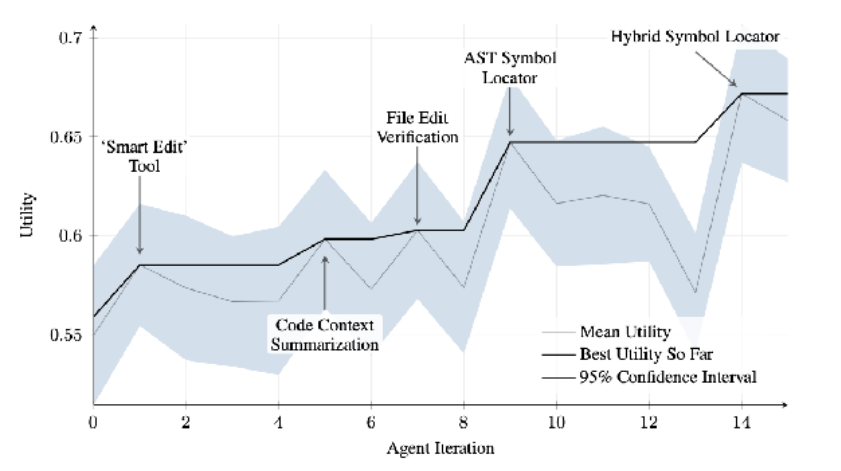
图 2:跨迭代的性能表现。关键改进用其相应的工具或 Agent 修改进行标注。(由 Maxime Robeyns、Martin Szummer、Laurence Aitchison 提供)
SICA 的架构包括用于基本文件操作、命令执行和算术计算的基础工具包。它包含结果提交机制和专门子 Agent(编码、问题解决和推理)的调用功能。这些子 Agent 负责分解复杂任务并管理 LLM 的上下文长度, 特别是在扩展改进周期期间。 异步监督者(另一个 LLM)监控 SICA 的行为,识别潜在问题,如循环或停滞。它与 SICA 进行通信,必要时 可以介入以停止执行。监督者接收 SICA 行动的详细报告,包括调用图和消息及工具操作日志,以识别模式 和低效率。 SICA 的 LLM 在其上下文窗口(其短期内存)中以结构化方式组织信息,这对操作至关重要。此结构包括定 义 Agent 目标的系统提示词、工具和子 Agent 文档以及系统指令。核心提示词包含问题陈述或指令、打开文 件的内容和目录映射。助手消息记录 Agent 的逐步推理、工具和子 Agent 调用记录及结果以及监督者通信。 这种组织方式促进了高效的信息流动,增强了 LLM 操作并减少了处理时间和成本。最初,文件更改记录为 差异,仅显示修改内容并定期合并。
**SICA:代码深度解析:**深入研究 SICA 的实现揭示了支撑其能力的几个关键设计选择。如前所述,该系统采 用模块化架构构建,包含多个子 Agent,如编码 Agent、问题解决 Agent 和推理 Agent。这些子 Agent 由主 Agent 调用,类似于工具调用,用于分解复杂任务并有效管理上下文长度,特别是在这些扩展的元改进迭代 期间。 该项目正在积极开发中,旨在为 LLM 工具使用及 Agent 任务后训练提供强大框架,完整代码参见 GitHub 存 储库。 出于安全考虑,该项目强烈强调 Docker 容器化,这意味着 Agent 在专用 Docker 容器内运行。这是一个关键 措施,因为它提供了与主机的隔离,鉴于 Agent 执行 shell 命令的能力,这减轻了意外文件系统操作等风险。 为确保透明度和控制,系统通过可视化事件总线上的事件和 Agent 调用图的交互式网页提供强大的可观察 性。这提供了对 Agent 行动的全面洞察,允许用户检查单个事件、阅读监督者消息并折叠子 Agent 跟踪以获 得更清晰的理解。 就其核心智能而言,Agent 框架支持来自各种提供商的 LLM 集成,使用户能够尝试不同的模型以找到特定任 务的最佳匹配。最后,一个关键组件是异步监督者,这是一个与主 Agent 并发运行的 LLM。此监督者定期评 估 Agent 的行为是否存在病理性偏差或停滞,必要时可以通过发送通知甚至取消 Agent 的执行来介入。它接收系统状态的详细文本表示,包括调用图和 LLM 消息、工具调用和响应的事件流,这使它能够检测低效模 式或重复工作。 初始 SICA 实现中的一个显著挑战是提示基于 LLM 的 Agent 在每次元改进迭代期间独立提出新颖、创新、可 行且引人入胜的修改。这一限制,特别是在培养 LLM Agent 的开放式学习和真正创造力方面,仍然是当前研 究的关键领域。
用例DEMO
我们将在DEMO中展示一个简单的自适应Agent框架,并实现一个个性化助手Agent的示例。
由于时间限制,我们将构建一个基本的Agent结构,它能够根据用户的历史交互来调整自己的响应。
我们将使用一个简单的记忆机制来存储历史交互,并根据历史数据来生成响应。
注意:这个示例非常简化,实际的自适应Agent会更加复杂,可能会使用机器学习模型来调整行为。
步骤:
-
设计一个Agent基类,包含记忆存储和更新机制。
-
实现一个个性化助手Agent,它根据用户的历史交互来调整响应。
-
演示Agent如何根据交互历史改变自己的响应。
我们将使用一个字典来存储用户的历史交互,并计算用户对某些话题的偏好,然后根据偏好调整响应。
由于我们只是演示,这里不会使用复杂的模型,而是使用基于规则的响应调整。
我们假设助手Agent可以处理两种话题:天气和新闻。根据用户的历史询问次数,Agent会调整对不同话题的响应方式。
例如,如果用户经常问天气,那么当用户问"今天怎么样?"时,Agent会优先回答天气相关;如果用户经常问新闻,则优先提供新闻。
我们使用一个简单的记忆类来存储用户的历史交互,然后Agent根据历史数据做出决策。
代码结构:
-
Memory类:存储用户的历史交互,并可以计算用户对话题的偏好。
-
AdaptiveAgent基类:具有记忆和更新机制。
-
PersonalizedAssistantAgent:继承自AdaptiveAgent,实现具体的响应生成逻辑。
我们将模拟几次交互来展示Agent如何适应。
1. 个性化助手 Agent
python
# personalized_assistant.py
import json
from datetime import datetime
from typing import Dict, List, Any
from dataclasses import dataclass, asdict
from collections import defaultdict
@dataclass
class UserInteraction:
timestamp: str
query_type: str # "weather", "news", "schedule", "shopping", "entertainment"
user_sentiment: float # -1 to 1
response_time: float
user_feedback: float # 0 to 1
class PersonalizedAssistantAgent:
def __init__(self, user_id: str):
self.user_id = user_id
self.interaction_history: List[UserInteraction] = []
self.user_profile = {
"preferred_topics": defaultdict(float),
"response_style": "detailed", # detailed, concise, humorous
"active_hours": {"start": 9, "end": 21},
"communication_preference": "text", # text, voice
}
def learn_from_interaction(self, interaction: UserInteraction):
"""从交互中学习用户偏好"""
self.interaction_history.append(interaction)
# 更新主题偏好
self.user_profile["preferred_topics"][interaction.query_type] += interaction.user_feedback
# 根据情感调整响应风格
if interaction.user_sentiment < -0.5:
self.user_profile["response_style"] = "empathetic"
elif interaction.user_sentiment > 0.5:
self.user_profile["response_style"] = "enthusiastic"
# 学习最佳响应时间
if interaction.response_time < 2.0 and interaction.user_feedback > 0.7:
hour = datetime.now().hour
if hour < self.user_profile["active_hours"]["start"]:
self.user_profile["active_hours"]["start"] = hour
elif hour > self.user_profile["active_hours"]["end"]:
self.user_profile["active_hours"]["end"] = hour
def generate_response(self, query: str, query_type: str) -> str:
"""根据用户偏好生成个性化响应"""
current_hour = datetime.now().hour
active = (self.user_profile["active_hours"]["start"] <= current_hour <=
self.user_profile["active_hours"]["end"])
# 选择响应模板
style = self.user_profile["response_style"]
templates = {
"detailed": "让我为您详细介绍一下...",
"concise": "简要来说...",
"humorous": "哈哈,这个问题问得好!",
"empathetic": "我理解您的心情...",
"enthusiastic": "太棒了!关于这个问题..."
}
# 基于偏好的响应增强
topic_preference = self.user_profile["preferred_topics"].get(query_type, 0.5)
if topic_preference > 0.8:
enthusiasm = "您经常关注这个话题,我来为您深入分析!"
else:
enthusiasm = ""
response = f"{templates.get(style, '')} {enthusiasm}"
# 如果不是活跃时间,添加礼貌说明
if not active:
response += " 现在可能不是您通常的活跃时间,如有打扰请见谅。"
return response
def adapt_protocol(self):
"""自适应调整交互协议"""
recent_interactions = self.interaction_history[-10:] if len(self.interaction_history) > 10 else self.interaction_history
if not recent_interactions:
return
avg_feedback = sum(i.user_feedback for i in recent_interactions) / len(recent_interactions)
# 根据反馈调整协议
if avg_feedback < 0.3:
self.user_profile["response_style"] = "concise"
print(f"为{self.user_id}切换到简洁模式")
elif avg_feedback > 0.8:
self.user_profile["response_style"] = "detailed"
print(f"为{self.user_id}切换到详细模式")
# 使用示例
if __name__ == "__main__":
agent = PersonalizedAssistantAgent("user_001")
# 模拟几次交互
interactions = [
("今天天气怎么样?", "weather", 0.8, 1.5, 0.9),
("有什么新闻?", "news", -0.2, 2.0, 0.3),
("帮我订餐厅", "shopping", 0.5, 1.0, 0.8),
]
for query, qtype, sentiment, resp_time, feedback in interactions:
interaction = UserInteraction(
timestamp=datetime.now().isoformat(),
query_type=qtype,
user_sentiment=sentiment,
response_time=resp_time,
user_feedback=feedback
)
agent.learn_from_interaction(interaction)
response = agent.generate_response(query, qtype)
print(f"Query: {query}")
print(f"Response: {response}")
print(f"User Profile: {agent.user_profile['preferred_topics']}")
print("-" * 50)
agent.adapt_protocol()2. 交易机器人 Agent
python
# trading_agent.py
import numpy as np
from typing import List, Tuple, Optional
from dataclasses import dataclass
from enum import Enum
import random
class MarketCondition(Enum):
BULLISH = "bullish"
BEARISH = "bearish"
VOLATILE = "volatile"
SIDEWAYS = "sideways"
@dataclass
class MarketData:
timestamp: str
price: float
volume: float
rsi: float # 相对强弱指数
macd: float # 异同移动平均线
volatility: float
class AdaptiveTradingAgent:
def __init__(self, initial_capital: float = 10000.0):
self.capital = initial_capital
self.portfolio = {}
self.risk_tolerance = 0.5 # 0-1, 1表示高风险
self.performance_history = []
# 动态参数
self.trading_params = {
"position_size": 0.1, # 仓位大小比例
"stop_loss": 0.02, # 止损比例
"take_profit": 0.05, # 止盈比例
"rsi_threshold": {"buy": 30, "sell": 70},
"macd_sensitivity": 0.001
}
def analyze_market(self, market_data: List[MarketData]) -> MarketCondition:
"""分析市场状况"""
if len(market_data) < 10:
return MarketCondition.SIDEWAYS
prices = [md.price for md in market_data[-10:]]
returns = np.diff(prices) / prices[:-1]
# 计算市场状况
avg_return = np.mean(returns)
volatility = np.std(returns)
if avg_return > 0.005 and volatility < 0.02:
return MarketCondition.BULLISH
elif avg_return < -0.005 and volatility < 0.02:
return MarketCondition.BEARISH
elif volatility > 0.03:
return MarketCondition.VOLATILE
else:
return MarketCondition.SIDEWAYS
def adjust_parameters(self, market_condition: MarketCondition, recent_performance: List[float]):
"""根据市场状况和近期表现调整参数"""
if recent_performance:
avg_performance = np.mean(recent_performance[-5:]) if len(recent_performance) >= 5 else 0
# 根据表现调整风险容忍度
if avg_performance > 0.05: # 表现好,增加风险
self.risk_tolerance = min(1.0, self.risk_tolerance + 0.1)
elif avg_performance < -0.03: # 表现差,降低风险
self.risk_tolerance = max(0.1, self.risk_tolerance - 0.1)
# 根据市场状况调整交易参数
if market_condition == MarketCondition.BULLISH:
self.trading_params["position_size"] = 0.15 * self.risk_tolerance
self.trading_params["take_profit"] = 0.08
self.trading_params["stop_loss"] = 0.03
elif market_condition == MarketCondition.BEARISH:
self.trading_params["position_size"] = 0.05 * self.risk_tolerance
self.trading_params["take_profit"] = 0.03
self.trading_params["stop_loss"] = 0.01
elif market_condition == MarketCondition.VOLATILE:
self.trading_params["position_size"] = 0.08 * self.risk_tolerance
self.trading_params["stop_loss"] = 0.02
self.trading_params["take_profit"] = 0.04
else: # SIDEWAYS
self.trading_params["position_size"] = 0.1 * self.risk_tolerance
self.trading_params["stop_loss"] = 0.015
self.trading_params["take_profit"] = 0.02
def make_decision(self, market_data: MarketData, market_condition: MarketCondition) -> Tuple[str, float]:
"""做出交易决策"""
decision = "HOLD"
amount = 0.0
# RSI指标信号
if market_data.rsi < self.trading_params["rsi_threshold"]["buy"]:
signal_strength = (self.trading_params["rsi_threshold"]["buy"] - market_data.rsi) / 30
if signal_strength > 0.3 and market_condition != MarketCondition.BEARISH:
decision = "BUY"
elif market_data.rsi > self.trading_params["rsi_threshold"]["sell"]:
signal_strength = (market_data.rsi - self.trading_params["rsi_threshold"]["sell"]) / 30
if signal_strength > 0.3:
decision = "SELL"
# MACD信号
if abs(market_data.macd) > self.trading_params["macd_sensitivity"]:
if market_data.macd > 0 and decision == "HOLD":
decision = "BUY"
elif market_data.macd < 0 and decision == "HOLD":
decision = "SELL"
# 确定交易量
if decision != "HOLD":
position_size = self.capital * self.trading_params["position_size"]
amount = position_size / market_data.price
# 根据波动性调整
if market_data.volatility > 0.04:
amount *= 0.7 # 高波动性减少仓位
return decision, amount
def execute_trade(self, symbol: str, decision: str, amount: float, price: float) -> float:
"""执行交易并返回收益"""
if decision == "BUY":
cost = amount * price
if cost <= self.capital:
self.capital -= cost
self.portfolio[symbol] = self.portfolio.get(symbol, 0) + amount
return -cost
elif decision == "SELL":
if symbol in self.portfolio and self.portfolio[symbol] >= amount:
revenue = amount * price
self.capital += revenue
self.portfolio[symbol] -= amount
if self.portfolio[symbol] == 0:
del self.portfolio[symbol]
return revenue
return 0.0
# 模拟交易环境
class MarketSimulator:
def __init__(self, initial_price: float = 100.0):
self.price = initial_price
self.trend = 0.001 # 微小上涨趋势
self.volatility = 0.02
def generate_market_data(self) -> MarketData:
"""生成模拟市场数据"""
# 随机价格变动
price_change = self.trend + random.uniform(-self.volatility, self.volatility)
self.price *= (1 + price_change)
# 模拟技术指标
rsi = random.uniform(20, 80)
macd = random.uniform(-0.005, 0.005)
return MarketData(
timestamp=datetime.now().isoformat(),
price=self.price,
volume=random.uniform(1000, 10000),
rsi=rsi,
macd=macd,
volatility=self.volatility
)
# 使用示例
if __name__ == "__main__":
trader = AdaptiveTradingAgent(initial_capital=10000)
market = MarketSimulator(initial_price=100)
market_data_history = []
print("开始自适应交易...")
print(f"初始资金: ${trader.capital:.2f}")
print("-" * 50)
for day in range(30):
# 生成市场数据
market_data = market.generate_market_data()
market_data_history.append(market_data)
# 分析市场
market_condition = trader.analyze_market(market_data_history)
# 调整参数
trader.adjust_parameters(market_condition, trader.performance_history)
# 做出决策
decision, amount = trader.make_decision(market_data, market_condition)
if decision != "HOLD":
# 执行交易
symbol = "STOCK_A"
pnl = trader.execute_trade(symbol, decision, amount, market_data.price)
trader.performance_history.append(pnl / 10000) # 归一化收益
print(f"Day {day+1}:")
print(f" 价格: ${market_data.price:.2f}")
print(f" 市场状况: {market_condition.value}")
print(f" 决策: {decision} {amount:.2f}股")
print(f" 风险容忍度: {trader.risk_tolerance:.2f}")
print(f" 当前资金: ${trader.capital:.2f}")
print("-" * 30)
total_return = (trader.capital - 10000) / 10000 * 100
print(f"\n最终结果:")
print(f" 最终资金: ${trader.capital:.2f}")
print(f" 总收益率: {total_return:.2f}%")
print(f" 交易次数: {len(trader.performance_history)}")3. RAG 知识库学习 Agent
python
# rag_learning_agent.py
from typing import List, Dict, Any, Tuple
import numpy as np
from dataclasses import dataclass
from sentence_transformers import SentenceTransformer
import faiss
import json
@dataclass
class KnowledgeEntry:
id: str
question: str
answer: str
context: str
embedding: List[float]
success_count: int = 0
failure_count: int = 0
last_used: str = ""
tags: List[str] = None
class RAGLearningAgent:
def __init__(self, model_name: str = "paraphrase-multilingual-MiniLM-L12-v2"):
self.model = SentenceTransformer(model_name)
self.dimension = 384 # 模型嵌入维度
# FAISS向量数据库
self.index = faiss.IndexFlatL2(self.dimension)
self.knowledge_base: List[KnowledgeEntry] = []
# 学习参数
self.success_threshold = 3
self.relevance_threshold = 0.7
def add_knowledge(self, question: str, answer: str, context: str = "", tags: List[str] = None):
"""添加新知识到知识库"""
embedding = self.model.encode(question).tolist()
entry = KnowledgeEntry(
id=f"entry_{len(self.knowledge_base)}",
question=question,
answer=answer,
context=context,
embedding=embedding,
tags=tags or []
)
self.knowledge_base.append(entry)
self.index.add(np.array([embedding]).astype('float32'))
print(f"添加新知识: {question[:50]}...")
def search_similar(self, query: str, top_k: int = 5) -> List[Tuple[KnowledgeEntry, float]]:
"""搜索相似知识"""
query_embedding = self.model.encode(query).reshape(1, -1).astype('float32')
# 在FAISS中搜索
distances, indices = self.index.search(query_embedding, top_k)
results = []
for i, (idx, distance) in enumerate(zip(indices[0], distances[0])):
if idx < len(self.knowledge_base):
similarity = 1 / (1 + distance) # 将距离转换为相似度
results.append((self.knowledge_base[idx], similarity))
return results
def generate_answer(self, query: str, context: str = "") -> Tuple[str, List[Dict]]:
"""生成答案并检索相关知识"""
# 搜索相似问题
similar_knowledge = self.search_similar(query)
if not similar_knowledge:
return "抱歉,我目前还没有这个问题的答案。", []
# 获取最相关的知识
best_entry, best_similarity = similar_knowledge[0]
if best_similarity < self.relevance_threshold:
# 相似度不够,返回通用回答
return "这个问题我不太确定,让我为您查找更多信息。", []
# 更新成功计数
best_entry.success_count += 1
best_entry.last_used = datetime.now().isoformat()
# 构建增强回答
enhanced_answer = f"{best_entry.answer}\n\n"
# 添加上下文相关信息
if best_entry.context:
enhanced_answer += f"相关背景:{best_entry.context}\n\n"
# 添加置信度说明
confidence = min(best_similarity * 100, 99)
enhanced_answer += f"(置信度: {confidence:.1f}%)"
# 返回检索到的相关知识点
retrieved_info = []
for entry, similarity in similar_knowledge[:3]:
retrieved_info.append({
"question": entry.question,
"answer": entry.answer[:100] + "..." if len(entry.answer) > 100 else entry.answer,
"similarity": float(similarity),
"success_rate": entry.success_count / (entry.success_count + entry.failure_count + 1)
})
return enhanced_answer, retrieved_info
def learn_from_feedback(self, query: str, feedback: Dict[str, Any]):
"""从用户反馈中学习"""
was_correct = feedback.get("correct", False)
user_alternative = feedback.get("alternative_answer", "")
user_context = feedback.get("additional_context", "")
# 找到相关的知识条目
similar_knowledge = self.search_similar(query, top_k=1)
if similar_knowledge:
entry, similarity = similar_knowledge[0]
if was_correct:
entry.success_count += 1
print(f"知识 '{entry.question[:30]}...' 被验证正确")
else:
entry.failure_count += 1
# 如果相似度够高但答案错误,需要更新答案
if similarity > 0.8 and user_alternative:
entry.answer = user_alternative
if user_context:
entry.context = user_context
print(f"知识 '{entry.question[:30]}...' 已更新")
# 如果失败次数过多,可能需要标记
failure_ratio = entry.failure_count / (entry.success_count + entry.failure_count)
if failure_ratio > 0.5 and entry.failure_count > 3:
entry.tags.append("needs_review")
print(f"警告: 知识 '{entry.question[:30]}...' 可能需要重新评估")
# 如果没有找到相关知识,添加新知识
elif not was_correct and user_alternative:
self.add_knowledge(
question=query,
answer=user_alternative,
context=user_context,
tags=["user_provided"]
)
def analyze_knowledge_base(self):
"""分析知识库状态"""
print("\n=== 知识库分析 ===")
print(f"总条目数: {len(self.knowledge_base)}")
if not self.knowledge_base:
return
# 计算成功率
total_uses = sum(entry.success_count + entry.failure_count for entry in self.knowledge_base)
successful_uses = sum(entry.success_count for entry in self.knowledge_base)
if total_uses > 0:
success_rate = successful_uses / total_uses * 100
print(f"总体成功率: {success_rate:.1f}%")
# 找出最成功的知识
successful_entries = sorted(
self.knowledge_base,
key=lambda x: x.success_count / (x.success_count + x.failure_count + 1),
reverse=True
)[:5]
print("\n最成功的知识点:")
for i, entry in enumerate(successful_entries, 1):
rate = entry.success_count / (entry.success_count + entry.failure_count + 1) * 100
print(f" {i}. {entry.question[:40]}... (成功率: {rate:.1f}%)")
# 找出需要关注的知识
problematic_entries = [
entry for entry in self.knowledge_base
if entry.failure_count > 2 and
entry.failure_count > entry.success_count
]
if problematic_entries:
print(f"\n需要关注的知识点: {len(problematic_entries)}")
for entry in problematic_entries[:3]:
print(f" - {entry.question[:40]}... (失败: {entry.failure_count})")
# 使用示例
if __name__ == "__main__":
agent = RAGLearningAgent()
# 初始化一些知识
initial_knowledge = [
("如何安装Python?",
"可以从Python官网下载安装包,安装时记得勾选'Add Python to PATH'。",
"Python安装常见问题"),
("什么是机器学习?",
"机器学习是人工智能的一个分支,让计算机从数据中学习模式并做出预测。",
"AI基础知识"),
("如何创建虚拟环境?",
"使用命令 'python -m venv env_name' 创建虚拟环境。",
"Python开发环境")
]
for question, answer, context in initial_knowledge:
agent.add_knowledge(question, answer, context)
print("知识库初始化完成")
print("-" * 50)
# 测试查询
test_queries = [
"怎么安装Python环境?",
"机器学习是什么?",
"如何搭建开发环境?"
]
for query in test_queries:
print(f"\n用户查询: {query}")
answer, retrieved = agent.generate_answer(query)
print(f"回答: {answer}")
if retrieved:
print("相关知识点:")
for info in retrieved:
print(f" - {info['question']} (相似度: {info['similarity']:.2f})")
# 模拟学习过程
print("\n=== 学习过程模拟 ===")
# 用户提供反馈
feedback = {
"correct": False,
"alternative_answer": "更好的方法是使用conda创建环境:conda create -n env_name python=3.9",
"additional_context": "conda环境管理更加强大"
}
agent.learn_from_feedback("如何创建虚拟环境?", feedback)
# 再次查询
print("\n改进后的查询:")
answer, _ = agent.generate_answer("创建Python虚拟环境的方法")
print(f"回答: {answer}")
# 分析知识库
agent.analyze_knowledge_base()4. 推荐 Agent
python
# recommendation_agent.py
import numpy as np
from typing import List, Dict, Any
from collections import defaultdict
from dataclasses import dataclass, field
import json
@dataclass
class UserPreference:
user_id: str
item_preferences: Dict[str, float] = field(default_factory=dict) # item_id -> score
category_weights: Dict[str, float] = field(default_factory=dict) # category -> weight
context_preferences: Dict[str, float] = field(default_factory=dict) # context -> weight
def update_preference(self, item_id: str, rating: float, item_categories: List[str], context: str):
"""更新用户偏好"""
# 更新物品偏好
if item_id in self.item_preferences:
# 平滑更新
self.item_preferences[item_id] = 0.7 * self.item_preferences[item_id] + 0.3 * rating
else:
self.item_preferences[item_id] = rating
# 更新分类权重
for category in item_categories:
if category in self.category_weights:
self.category_weights[category] += rating * 0.1
else:
self.category_weights[category] = rating * 0.1
# 更新上下文偏好
if context in self.context_preferences:
self.context_preferences[context] += rating * 0.05
else:
self.context_preferences[context] = rating * 0.05
# 归一化权重
total = sum(self.category_weights.values())
if total > 0:
for category in self.category_weights:
self.category_weights[category] /= total
class AdaptiveRecommendationAgent:
def __init__(self):
self.user_profiles: Dict[str, UserPreference] = {}
self.item_catalog: Dict[str, Dict] = {}
# 协同过滤矩阵
self.user_item_matrix = {}
self.similarity_cache = {}
def add_item(self, item_id: str, categories: List[str], features: Dict[str, Any]):
"""添加物品到目录"""
self.item_catalog[item_id] = {
"categories": categories,
"features": features,
"popularity": 0,
"avg_rating": 0.0,
"rating_count": 0
}
def record_interaction(self, user_id: str, item_id: str, rating: float, context: str = "default"):
"""记录用户交互"""
if user_id not in self.user_profiles:
self.user_profiles[user_id] = UserPreference(user_id)
user = self.user_profiles[user_id]
item = self.item_catalog.get(item_id, {})
if item:
categories = item.get("categories", [])
user.update_preference(item_id, rating, categories, context)
# 更新物品统计
item["popularity"] += 1
item["rating_count"] += 1
item["avg_rating"] = (
(item["avg_rating"] * (item["rating_count"] - 1) + rating) /
item["rating_count"]
)
def calculate_similarity(self, user1_id: str, user2_id: str) -> float:
"""计算用户相似度"""
user1 = self.user_profiles.get(user1_id)
user2 = self.user_profiles.get(user2_id)
if not user1 or not user2:
return 0.0
# 获取共同评分物品
common_items = set(user1.item_preferences.keys()) & set(user2.item_preferences.keys())
if not common_items:
return 0.0
# 计算余弦相似度
scores1 = [user1.item_preferences[item] for item in common_items]
scores2 = [user2.item_preferences[item] for item in common_items]
dot_product = sum(s1 * s2 for s1, s2 in zip(scores1, scores2))
norm1 = np.sqrt(sum(s * s for s in scores1))
norm2 = np.sqrt(sum(s * s for s in scores2))
if norm1 * norm2 == 0:
return 0.0
return dot_product / (norm1 * norm2)
def get_collaborative_recommendations(self, user_id: str, top_n: int = 10) -> List[str]:
"""基于协同过滤的推荐"""
if user_id not in self.user_profiles:
return []
user = self.user_profiles[user_id]
user_items = set(user.item_preferences.keys())
# 计算与其他用户的相似度
similarities = []
for other_user_id in self.user_profiles:
if other_user_id != user_id:
sim = self.calculate_similarity(user_id, other_user_id)
if sim > 0.3: # 相似度阈值
similarities.append((other_user_id, sim))
# 找出相似用户喜欢的物品
item_scores = defaultdict(float)
item_weights = defaultdict(float)
for other_user_id, similarity in similarities[:20]: # 取前20个相似用户
other_user = self.user_profiles[other_user_id]
for item_id, rating in other_user.item_preferences.items():
if item_id not in user_items: # 用户没看过的
item_scores[item_id] += rating * similarity
item_weights[item_id] += similarity
# 计算加权平均分
for item_id in item_scores:
if item_weights[item_id] > 0:
item_scores[item_id] /= item_weights[item_id]
# 按分数排序
sorted_items = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, _ in sorted_items[:top_n]]
def get_content_based_recommendations(self, user_id: str, context: str = "default", top_n: int = 10) -> List[str]:
"""基于内容的推荐"""
if user_id not in self.user_profiles:
return []
user = self.user_profiles[user_id]
user_items = set(user.item_preferences.keys())
item_scores = {}
for item_id, item_data in self.item_catalog.items():
if item_id in user_items:
continue
score = 0.0
# 基于分类的分数
categories = item_data.get("categories", [])
for category in categories:
score += user.category_weights.get(category, 0.1) * 0.5
# 基于上下文的分数
score += user.context_preferences.get(context, 0.5) * 0.3
# 基于流行度的分数(探索新物品)
popularity = item_data.get("popularity", 0)
if popularity < 10: # 冷启动物品
score += 0.2
# 基于评分的分数
avg_rating = item_data.get("avg_rating", 0.0)
score += avg_rating * 0.4
item_scores[item_id] = score
# 按分数排序
sorted_items = sorted(item_scores.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, _ in sorted_items[:top_n]]
def hybrid_recommendation(self, user_id: str, context: str = "default",
top_n: int = 10, collaborative_weight: float = 0.6) -> List[str]:
"""混合推荐算法"""
# 获取两种推荐结果
collab_recs = self.get_collaborative_recommendations(user_id, top_n * 2)
content_recs = self.get_content_based_recommendations(user_id, context, top_n * 2)
# 合并和去重
all_recs = {}
# 协同过滤结果
for i, item_id in enumerate(collab_recs):
score = (len(collab_recs) - i) / len(collab_recs) * collaborative_weight
all_recs[item_id] = all_recs.get(item_id, 0) + score
# 基于内容的结果
for i, item_id in enumerate(content_recs):
score = (len(content_recs) - i) / len(content_recs) * (1 - collaborative_weight)
all_recs[item_id] = all_recs.get(item_id, 0) + score
# 基于用户偏好调整
user = self.user_profiles.get(user_id)
if user:
for item_id in all_recs:
# 检查物品分类是否符合用户偏好
item = self.item_catalog.get(item_id, {})
categories = item.get("categories", [])
for category in categories:
if category in user.category_weights:
all_recs[item_id] += user.category_weights[category] * 0.1
# 最终排序
sorted_recs = sorted(all_recs.items(), key=lambda x: x[1], reverse=True)
return [item_id for item_id, _ in sorted_recs[:top_n]]
def adapt_to_feedback(self, user_id: str, recommended_items: List[str],
feedback: Dict[str, float]):
"""根据反馈自适应调整"""
if user_id not in self.user_profiles:
return
user = self.user_profiles[user_id]
for item_id, rating in feedback.items():
if item_id in self.item_catalog:
item = self.item_catalog[item_id]
categories = item.get("categories", [])
# 更新偏好
user.update_preference(item_id, rating, categories, "default")
# 如果评分低,降低类似物品的推荐权重
if rating < 0.3:
for category in categories:
if category in user.category_weights:
user.category_weights[category] *= 0.8 # 降低权重
# 调整混合权重
avg_feedback = sum(feedback.values()) / len(feedback) if feedback else 0.5
if avg_feedback > 0.7:
print(f"用户 {user_id} 反馈积极,增加个性化权重")
elif avg_feedback < 0.3:
print(f"用户 {user_id} 反馈消极,增加多样性")
# 使用示例
if __name__ == "__main__":
# 创建推荐系统
recommender = AdaptiveRecommendationAgent()
# 添加一些电影到目录
movies = [
("movie_1", ["Action", "Sci-Fi"], {"year": 2020, "director": "Nolan"}),
("movie_2", ["Comedy", "Romance"], {"year": 2019, "director": "Gerwig"}),
("movie_3", ["Drama", "Biography"], {"year": 2018, "director": "Cuarón"}),
("movie_4", ["Action", "Adventure"], {"year": 2021, "director": "Villeneuve"}),
("movie_5", ["Comedy", "Animation"], {"year": 2022, "director": "Lord"}),
("movie_6", ["Horror", "Thriller"], {"year": 2020, "director": "Peele"}),
("movie_7", ["Action", "Fantasy"], {"year": 2019, "director": "Watiti"}),
("movie_8", ["Drama", "Romance"], {"year": 2021, "director": "Coppola"}),
]
for movie_id, categories, features in movies:
recommender.add_item(movie_id, categories, features)
# 模拟用户交互历史
print("模拟用户交互...")
# 用户1: 喜欢动作片
recommender.record_interaction("user_1", "movie_1", 0.9)
recommender.record_interaction("user_1", "movie_4", 0.8)
recommender.record_interaction("user_1", "movie_7", 0.7)
# 用户2: 喜欢喜剧片
recommender.record_interaction("user_2", "movie_2", 0.9)
recommender.record_interaction("user_2", "movie_5", 0.8)
recommender.record_interaction("user_2", "movie_3", 0.6)
# 用户3: 混合偏好
recommender.record_interaction("user_3", "movie_1", 0.7)
recommender.record_interaction("user_3", "movie_2", 0.8)
recommender.record_interaction("user_3", "movie_6", 0.4) # 不喜欢恐怖片
# 为用户1生成推荐
print("\n为用户1生成推荐:")
recommendations = recommender.hybrid_recommendation("user_1", "weekend", top_n=3)
print("推荐电影:")
for i, movie_id in enumerate(recommendations, 1):
movie = recommender.item_catalog.get(movie_id, {})
categories = movie.get("categories", [])
print(f"{i}. ID: {movie_id}, 分类: {categories}")
# 模拟用户反馈
print("\n模拟用户反馈...")
feedback = {
recommendations[0]: 0.2, # 不喜欢第一个推荐
recommendations[1]: 0.9, # 喜欢第二个推荐
recommendations[2]: 0.6 # 一般般
}
recommender.adapt_to_feedback("user_1", recommendations, feedback)
# 再次生成推荐(应该会调整)
print("\n自适应调整后的推荐:")
new_recommendations = recommender.hybrid_recommendation("user_1", "weekend", top_n=3)
print("新推荐:")
for i, movie_id in enumerate(new_recommendations, 1):
movie = recommender.item_catalog.get(movie_id, {})
categories = movie.get("categories", [])
print(f"{i}. ID: {movie_id}, 分类: {categories}")5. 完整集成示例 - 智能应用 Agent
python
# smart_app_agent.py
import asyncio
from typing import Optional, Dict, Any
from dataclasses import dataclass
from enum import Enum
class UserExpertise(Enum):
BEGINNER = "beginner"
INTERMEDIATE = "intermediate"
EXPERT = "expert"
class TaskComplexity(Enum):
SIMPLE = "simple"
MODERATE = "moderate"
COMPLEX = "complex"
@dataclass
class UserBehavior:
user_id: str
action_sequence: list
time_spent: Dict[str, float] # feature -> seconds
error_count: Dict[str, int]
help_requests: int
success_rate: float
class AdaptiveAppAgent:
def __init__(self):
self.user_behaviors: Dict[str, UserBehavior] = {}
self.interface_configs = {
"beginner": {
"show_tooltips": True,
"simplified_ui": True,
"step_by_step_guide": True,
"advanced_features_hidden": True
},
"intermediate": {
"show_tooltips": False,
"simplified_ui": False,
"step_by_step_guide": False,
"advanced_features_hidden": False
},
"expert": {
"show_tooltips": False,
"simplified_ui": False,
"step_by_step_guide": False,
"advanced_features_hidden": False,
"keyboard_shortcuts": True,
"batch_operations": True
}
}
def analyze_expertise(self, user_id: str) -> UserExpertise:
"""分析用户熟练度"""
if user_id not in self.user_behaviors:
return UserExpertise.BEGINNER
behavior = self.user_behaviors[user_id]
# 基于多个指标评估
score = 0
# 成功率权重
score += behavior.success_rate * 40
# 帮助请求权重(越少越好)
if behavior.help_requests == 0:
score += 30
elif behavior.help_requests < 5:
score += 20
elif behavior.help_requests < 10:
score += 10
# 错误率权重(越少越好)
total_errors = sum(behavior.error_count.values())
if total_errors == 0:
score += 30
elif total_errors < 5:
score += 20
elif total_errors < 10:
score += 10
# 根据分数分类
if score >= 80:
return UserExpertise.EXPERT
elif score >= 50:
return UserExpertise.INTERMEDIATE
else:
return UserExpertise.BEGINNER
def adapt_interface(self, user_id: str, task: TaskComplexity):
"""自适应调整界面"""
expertise = self.analyze_expertise(user_id)
config = self.interface_configs[expertise.value].copy()
# 根据任务复杂度进一步调整
if task == TaskComplexity.COMPLEX and expertise != UserExpertise.EXPERT:
config["show_tooltips"] = True
config["step_by_step_guide"] = True
return config
def record_behavior(self, user_id: str, action: str,
feature: str, success: bool, time_spent: float):
"""记录用户行为"""
if user_id not in self.user_behaviors:
self.user_behaviors[user_id] = UserBehavior(
user_id=user_id,
action_sequence=[],
time_spent={},
error_count={},
help_requests=0,
success_rate=0.0
)
behavior = self.user_behaviors[user_id]
behavior.action_sequence.append(action)
# 记录时间花费
behavior.time_spent[feature] = behavior.time_spent.get(feature, 0) + time_spent
# 记录错误
if not success:
behavior.error_count[feature] = behavior.error_count.get(feature, 0) + 1
# 计算成功率
total_actions = len(behavior.action_sequence)
successful_actions = total_actions - sum(behavior.error_count.values())
behavior.success_rate = successful_actions / total_actions if total_actions > 0 else 0.0
def get_personalized_help(self, user_id: str, feature: str) -> str:
"""提供个性化帮助"""
if user_id not in self.user_behaviors:
return "欢迎使用!这是基础帮助..."
behavior = self.user_behaviors[user_id]
expertise = self.analyze_expertise(user_id)
# 根据熟练度提供不同层次的帮助
if expertise == UserExpertise.BEGINNER:
help_text = f"""
欢迎使用{feature}功能!
1. 首先点击这里
2. 然后选择选项
3. 最后确认完成
提示:完成这个操作通常需要30秒左右。
"""
elif expertise == UserExpertise.INTERMEDIATE:
help_text = f"""
{feature}功能说明:
- 主要用途:数据导入
- 快捷键:Ctrl+I
- 常见问题:确保文件格式正确
您已经使用过这个功能{behavior.time_spent.get(feature, 0):.0f}秒。
"""
else: # EXPERT
help_text = f"""
高级{feature}配置:
- 批量处理:支持最多1000个文件
- API接口:/api/v1/{feature}
- 性能优化:建议使用缓存
统计:平均处理时间 {behavior.time_spent.get(feature, 0)/max(1, len([a for a in behavior.action_sequence if feature in a])):.1f}秒
"""
# 如果用户在这个功能上经常出错,添加特别提示
if feature in behavior.error_count and behavior.error_count[feature] > 2:
help_text += f"\n⚠️ 注意:您在这个功能上遇到了{behavior.error_count[feature]}次错误,建议检查输入格式。"
return help_text
def predict_user_needs(self, user_id: str) -> list:
"""预测用户可能需要什么"""
if user_id not in self.user_behaviors:
return ["完成设置向导", "浏览主要功能"]
behavior = self.user_behaviors[user_id]
expertise = self.analyze_expertise(user_id)
suggestions = []
# 基于行为模式
if len(behavior.action_sequence) < 5:
suggestions.append("尝试数据分析功能")
elif "export" not in behavior.action_sequence:
suggestions.append("学习数据导出")
# 基于时间花费
slowest_feature = max(behavior.time_spent.items(), key=lambda x: x[1], default=(None, 0))[0]
if slowest_feature:
suggestions.append(f"优化{slowest_feature}的使用效率")
# 基于错误
most_error_feature = max(behavior.error_count.items(), key=lambda x: x[1], default=(None, 0))[0]
if most_error_feature:
suggestions.append(f"复习{most_error_feature}的操作")
# 基于熟练度
if expertise == UserExpertise.INTERMEDIATE:
suggestions.append("尝试高级功能")
elif expertise == UserExpertise.EXPERT:
suggestions.append("配置自动化工作流")
return suggestions[:3] # 返回前3个建议
# 模拟应用使用场景
async def simulate_app_usage():
agent = AdaptiveAppAgent()
print("=== 智能应用Agent演示 ===")
# 模拟用户使用应用
user_id = "user_123"
# 第一天:新手用户
print("\n第1天:新手用户学习阶段")
tasks = [
("登录", "auth", True, 5.0),
("创建项目", "project", True, 30.0),
("导入数据", "import", False, 60.0), # 失败了
("寻求帮助", "help", True, 10.0),
("再次导入数据", "import", True, 30.0),
]
for action, feature, success, time_spent in tasks:
agent.record_behavior(user_id, action, feature, success, time_spent)
if action == "寻求帮助":
help_text = agent.get_personalized_help(user_id, "import")
print(f"帮助系统:{help_text[:50]}...")
expertise = agent.analyze_expertise(user_id)
interface_config = agent.adapt_interface(user_id, TaskComplexity.MODERATE)
print(f"用户熟练度:{expertise.value}")
print(f"界面配置:{interface_config}")
# 几天后:用户变得熟练
print("\n第5天:用户变得熟练")
for _ in range(10):
agent.record_behavior(user_id, "数据分析", "analysis", True, 15.0)
agent.record_behavior(user_id, "导出报告", "export", True, 10.0)
expertise = agent.analyze_expertise(user_id)
interface_config = agent.adapt_interface(user_id, TaskComplexity.COMPLEX)
print(f"用户熟练度:{expertise.value}")
print(f"界面配置:{interface_config}")
# 获取个性化建议
suggestions = agent.predict_user_needs(user_id)
print(f"个性化建议:{suggestions}")
# 获取高级帮助
help_text = agent.get_personalized_help(user_id, "analysis")
print(f"\n高级功能帮助:{help_text[:100]}...")
if __name__ == "__main__":
asyncio.run(simulate_app_usage())安装依赖
bash
# 创建虚拟环境(如果还没创建)
python -m venv langchain_env
langchain_env\Scripts\activate
# 安装基础依赖
pip install numpy pandas
# 安装 RAG 相关
pip install sentence-transformers faiss-cpu
# 安装交易相关(可选)
pip install ta-lib # 技术分析库(需要先安装TA-Lib的C库)
# 或者使用纯Python的替代
pip install pandas-ta
# 安装异步支持
pip install asyncio
# 如果遇到问题,先安装这些
pip install --upgrade pip setuptools wheel这些 DEMO 展示了自适应 Agent 的核心概念:
-
个性化学习:从用户交互中学习偏好
-
动态调整:根据反馈和环境变化调整参数
-
记忆与适应:记住成功模式,避免失败陷阱
-
多策略融合:结合多种算法做出更好决策
每个 Agent 都可以进一步扩展:
-
集成 LLM 进行自然语言理解
-
添加更复杂的强化学习算法
-
实现分布式学习和联邦学习
-
增加安全性和隐私保护机制
你可以根据需要选择使用,也可以将这些模式组合起来创建更强大的自适应系统!
结论
本文探讨了学习和适应在人工智能中的关键作用。AI Agent 通过持续的数据获取和经验来增强其性能。自我 改进编码 Agent(SICA)通过代码修改自主改进其能力,很好地例证了这一点。 我们已经回顾了 Agent AI 的基本组成部分,包括架构、应用、规划、多 Agent 协作、内存管理以及学习和适 应。学习原理对于多 Agent 系统中的协调改进特别重要。为了实现这一点,调优数据必须准确反映完整的交互轨迹,捕获每个参与 Agent 的个体输入和输出。 这些元素促成了重大进展,如 Google 的 AlphaEvolve。这个 AI 系统通过 LLM、自动化评估和进化方法 独立发现和改进算法,推动科学研究和计算技术的进步。这些模式可以组合起来构建复杂的 AI 系统。像 AlphaEvolve 这样的发展表明,AI Agent 的自主算法发现和优化是可以实现的。
参考文献
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
-
Mitchell, T. M. (1997). Machine Learning. McGraw‑Hill.
-
Proximal Policy Optimization Algorithms by John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. You can find it on arXiv: https://arxiv.org/abs/1707.06347
-
Robeyns, M., Aitchison, L., & Szummer, M. (2025). A Self‑Improving Coding Agent. arXiv:2504.15228v2. https://arxiv.org/pdf/2504.15228 https://github.com/MaximeRobeyns/self_improving_coding _agent
-
AlphaEvolve blog, https://deepmind.google/discover/blog/alphaevolve‑a‑gemini‑powered‑ coding‑agent‑for‑designing‑advanced‑algorithms/
-
OpenEvolve, https://github.com/codelion/openevolve