欢迎来到C++
1、const引用
学习const引用的时候,我们要知道一点:
权限可以缩小,但不可以放大。
1.1、权限的理解
比如我们用const,修饰变量a;再用变量b,引用a:
c
#include<iostream>
int main()
{
const int a = 10;
int& b = a;
return 0;
}会发现编译器报错:
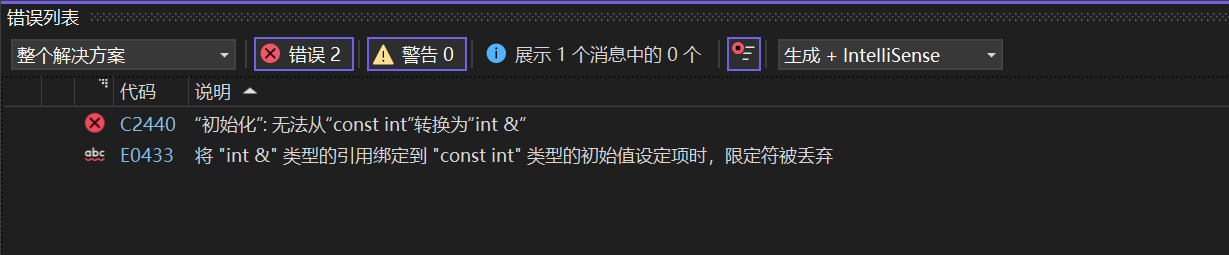
我们可以这么理解:变量a被const修饰,只能读取不能修改 ;而用b引用a,b 可以被读取也可以被修改。所以这里自相矛盾,编译器报错。
这种情况,就是权限放大,b相对于a,权限放大了。
下面这种情况,就是权限不变:
c
#include<iostream>
int main()
{
const int a = 10;
const int& b = a;
return 0;
}此时,a和b都被const修饰,都是只能读取不能修改的状态。
而下面这种情况,就是权限缩小:
c
#include<iostream>
int main()
{
int a = 10;
const int& b = a;
return 0;
}此时,a是可以修改的,而b只能读取,当b引用a,就不会有矛盾。
而这种情况,只是单纯的拷贝赋值,因为新的变量开辟了新的空间:
c
#include<iostream>
int main()
{
const int a = 10;
int e = a;
return 0;
}权限的放大、缩小,只存在指针与const之间、引用与const之间。
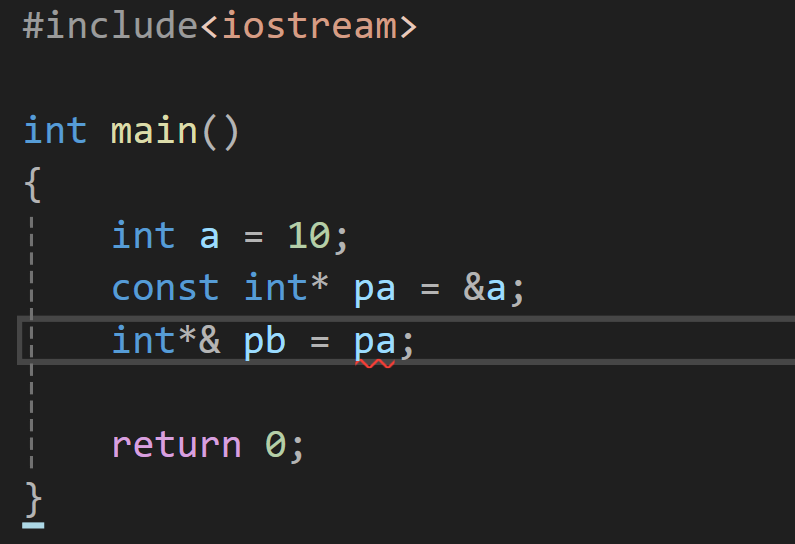
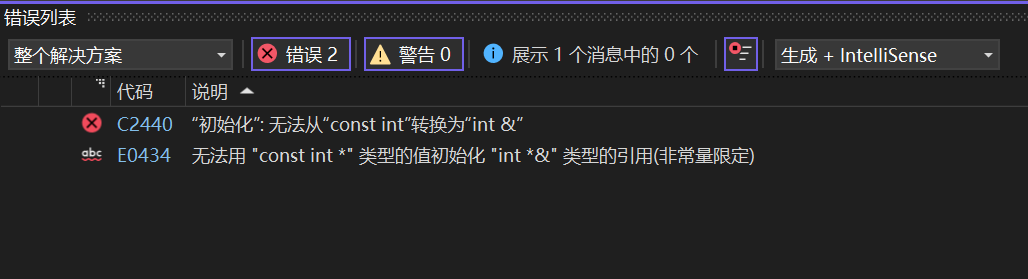
指针的情况,与引用一样。
权限放大:
权限不变:
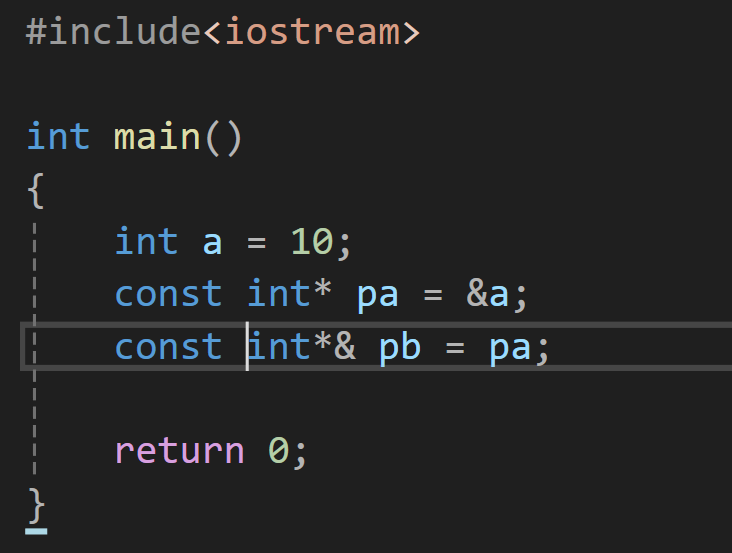
权限缩小:
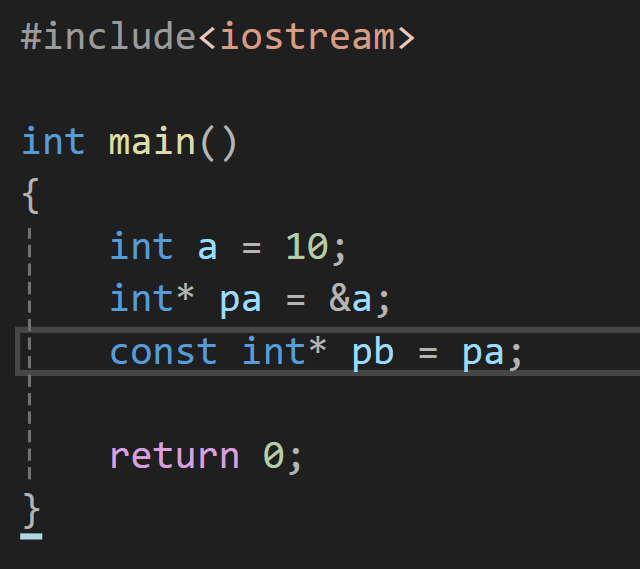
为什么要有权限只能缩小这个规定呢?
首先我们要知道,const是可以引用常量的:
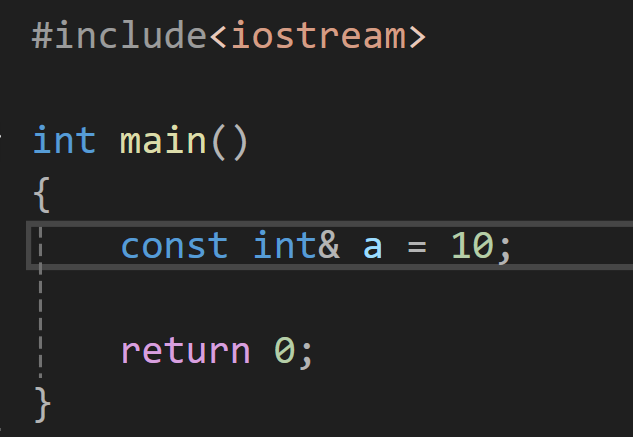
那么,当我们设计函数要使用引用传参 时,会遇到函数调用时,传入常量 和const修饰的变量 ,就会造成权限放大的问题。
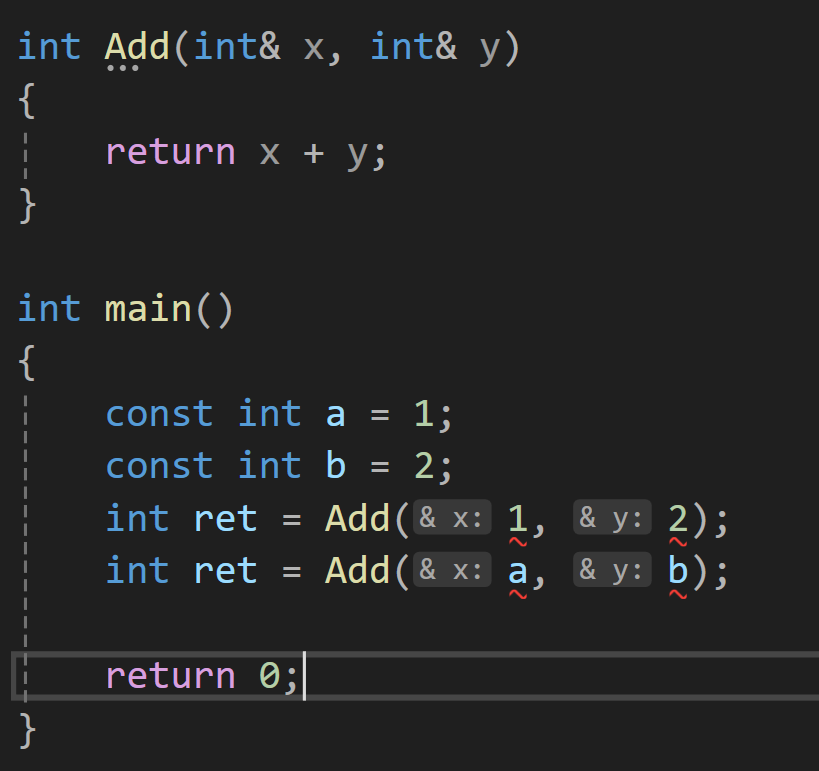
所以,函数要使用引用传参,建议加上const。
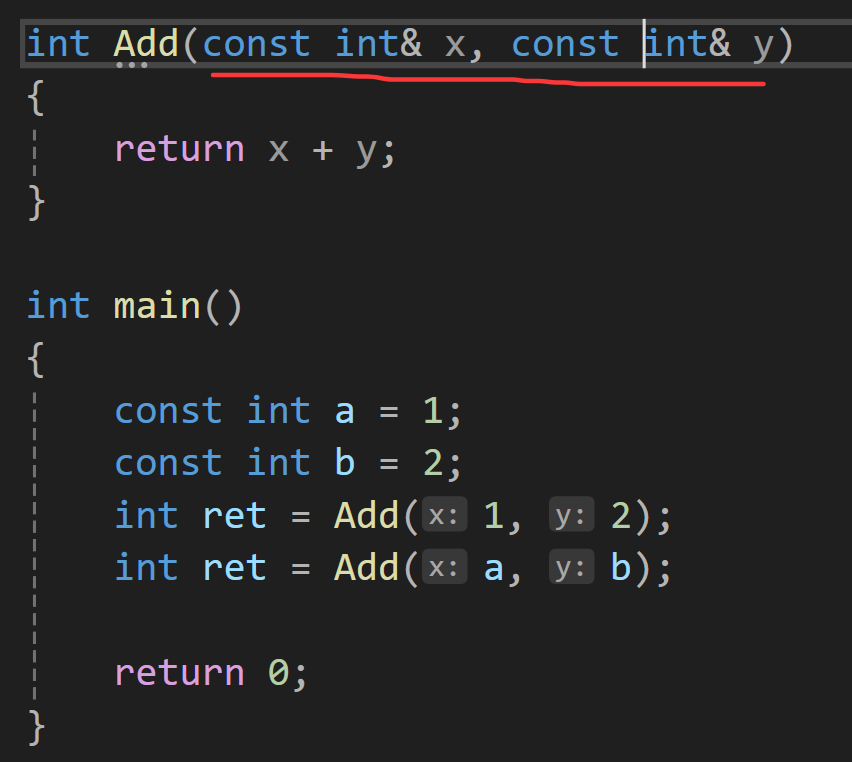
1.2、类型转换的中的const引用
给出这样一段代码:
c
#include<iostream>
int main()
{
int i = 1;
double d = i;
int p = (int)&i;
return 0;
}我们知道,这里的i,隐式转换成了double类型;而&i,强制类型转换成了int类型。
那么问题来了,我们这样写,是不通过的:

为什么呢?
首先,我们要知道,有两个地方,会产生临时变量。
产生临时变量的两个地方:
1、传值返回
2、类型转换
那么,上面代码中的变量d,接收的其实不是i,而是存储i的值的一个临时变量 :
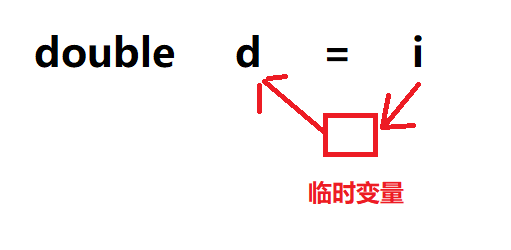
上面的变量p,也是类似的情况。
同时,临时变量具有常性,就像被const修饰了一样。
所以,上面代码的double& rd = i和int& rp = (int)&i,其实就是用一个可以修改的变量,引用另一个不可以修改的变量,本质还是权限放大。
正确写法,就是加上const:

那么,为什么在类型转换中使用引用,也要加上const?
也是为了传参:

补充:指针和引用的区别
首先,不要一上来就说引用的底层实现与指针一样,不要班门弄斧。
| ...... | 引用 | 指针 |
|---|---|---|
| 占用空间 | 引用和实体共用一块空间,不开辟空间 | 指针是定义一个变量存储地址,需要申请一个地址大小的空间 |
| 定义 | 引用必须初始化 | 在语法上,指针不强制初始化(但建议初始化) |
| 问题 | 引用很少出现问题,但是引用被使用在局部变量的返回时,会出问题 | 指针很容易出现空指针、野指针的问题 |
| 指向 | 引用的指向不能改变 | 指针的指向可以随意改变 |
| 访问 | 引用对象可以直接访问被引用对象 | 指针必须解引用访问 |
| sizeof的含义 | 引用对象使用的结果,是被引用对象的大小(字节) | 指针使用的结果,是地址的大小(32位机器下是4字节,64位机器下是8字节) |
2、inline内联函数
C++中inline的引入,是为了解决C语言中宏的问题。
2.1、宏的简单回顾
宏,是一种替换机制。我们可以用一个词来代替一个常量,那么之后的预处理阶段,代码中所有的这个词都会被替换为这个常量。这就是宏定义常量。
宏,也可以定义函数。
我们以使用宏设计加法函数为例,来回顾宏的一些常见问题。
c
#define Add(int x, int y) return x + y;这就是乱写的。
c
#define Add(x, y) x + y;这里犯的其中一个错误是,分号也会被替换进来 。
如果直接调用这个宏函数,编译器不会报错:
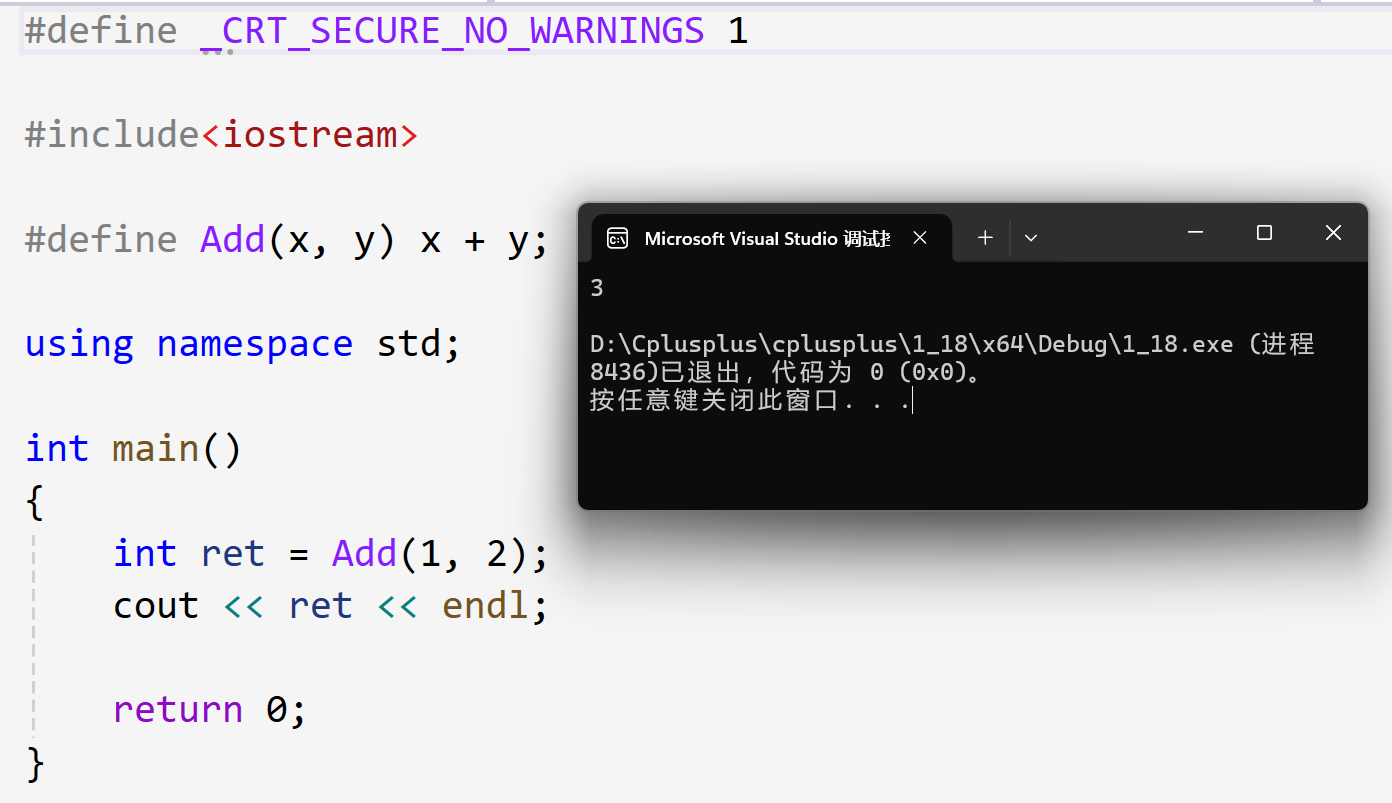
可如果是这样的情况,编译器就会报错:

因为在预处理阶段,宏函数可能被替换成了这样:
c
int ret = 1 + 2;*3;编译器自然报错。
那么下面代码就写对了吗?
c
#define Add(x, y) x + y比如我们再执行Add(1, 2)*3的操作。我们期望得到9,可事实是:
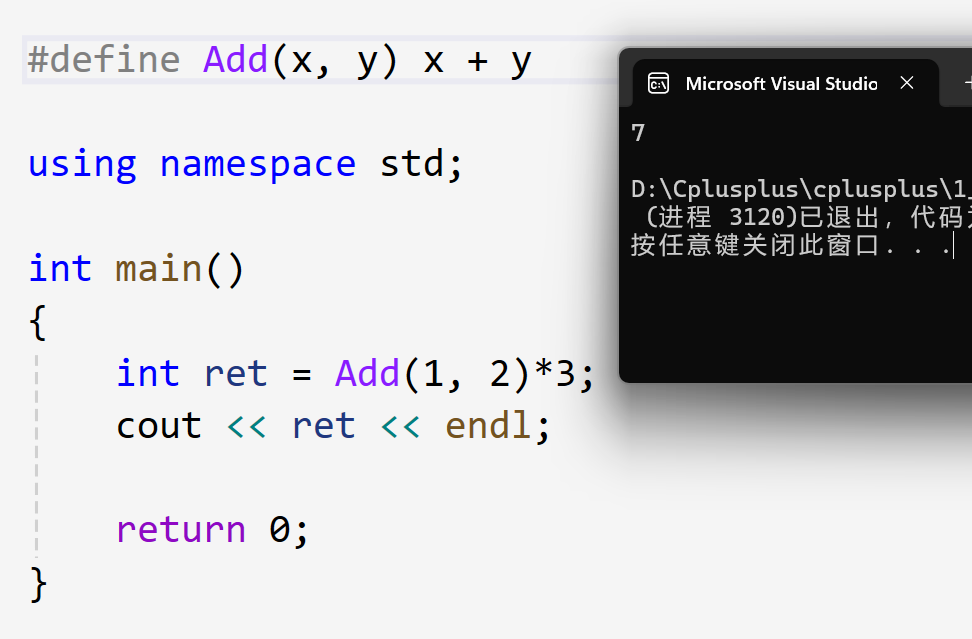
得到7。
宏只是一个替换机制,并不会改变运算符的优先级,所以这段代码中,先算乘法,再算加法。
那么,只加上一对括号就可以了吗?
c
#define Add(x, y) (x + y)还是不行。
如果向宏函数传入的是表达式,且表达式中的运算符的优先级比+低,那么也会发生问题。
正确写法是这样的:
c
#define Add(x, y) ((x) + (y))连x和y,都要用括号括起来。
2.2、inline的引入
虽然宏有很明显的优点:高频调用的短小函数写成宏函数,可以提高效率,因为宏函数在预处理阶段就被替换了,不建立栈帧。宏甚至可以传递类型。
但是,宏、宏函数无法调试,同时,用宏处理较大的函数,很复杂,很容易写出问题。
所以C++引入了inline内联函数。
C++中,内联函数inlne的使用,使得编译器在处理的时候,展开内联函数,从而达到不建立栈帧的效果。
inline同样适用于频繁调用的短小函数。
比如,我们设计一个加法的内联函数:

我们发现,内联函数的写法,只是比一般函数多了一个inline。这使得内联函数的设计,比宏函数更加简单。
但是,我们转到汇编代码,发现加法函数被调用了。也就是说,此时的内联函数并没有被展开:

这与编译器的设置有关。
vs 2022默认的release版本下,inline内联函数是展开的,但是我们观察不到;debug版本下,inline内联函数是不展开的,这是为了方便调试。
我们可以修改设置,使得我们在debug版本下也能观察到inline内联函数的展开:
项目名称右键--->属性--->C/C+±-->常规--->调试信息格式--->程序数据库(/Zi)
C/C+±-->优化--->内联函数扩展--->只适用于_inline(/Ob1)--->应用--->确定
设置完成,反汇编看看:

可以发现,此时内联函数展开了。
但是,我们使用了inline,编译器就一定会把函数展开吗?


比如以上代码,即使使用了inline,编译器也没有展开函数。因为inline对于编译器而言只是一个建议。
inline对于编译器,只是一个建议,代码短小的函数就展开,递归函数和代码多的函数还是会开辟空间。
那为什么编译器本身,要依据实际情况,选择性展开内联函数?
是为了防止代码指令的恶性膨胀。
假设,我们有一个inline Func()函数,展开后大约有20个指令。
在一个项目中,有10000个调用这个代码的位置。
那么,展开,需要指令:大约20 * 10000 == 20万行。
不展开,需要指令:大约20 + 10000(10000行call指令)行。
而这种恶性膨胀,会导致效率的下降。所以,我们建议,大的函数,如果频繁调用,就不要展开,以防止代码指令的恶性膨胀。
inline的使用,还需注意一点:
inline不建议声明和定义分离到不同的文件,否则会报错"错误链接"。因为inline内联函数被展开,展开的是声明,连接时函数的定义就不会被放入符号表,那么链接的时候,就找不到函数定义的地址。
3、nullptr
C++中nullptr的引入,是为了解决C语言中NULL的问题。
C语言中,NULL其实是一个宏。
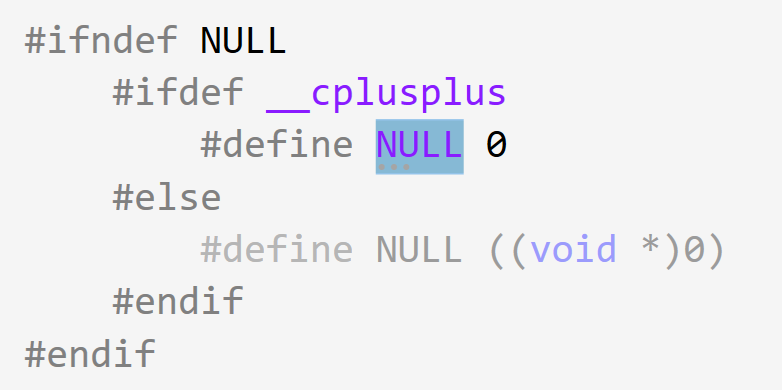
使用NULL,下面一段代码就会出现问题(产生歧义):

传一个指针,怎么编译器当成整型值了?
原来,根据NULL宏的定义,C++中,编译器认为NULL为整型0时更匹配,于是就出现了上面一个问题。
所以,C++11引入了nullptr。
nullptr是一个特殊的关键字,是一个特殊类型的字面量,它可以转换成任意其它类型的指针类型。
nullptr的值为0。
以后在C++中,NULL全部替换成NULL。
