摘要:随着智能交通系统的快速发展,车辆识别技术在交通管理、智能停车、安全监控等领域发挥着越来越重要的作用。传统的车辆识别方法存在识别精度低、实时性差、适应性弱等问题,难以满足实际应用需求。本文设计并实现了一个基于YOLO11深度学习算法的车辆品牌与类型智能识别系统,旨在提高车辆识别的准确性和实时性。
作者:Bob (张家梁) 原创
项目简介
基于YOLO11深度学习算法的车辆品牌与类型智能识别系统,支持22个品牌、6种车型的实时检测与数据分析。
系统概述
随着智能交通系统的快速发展,车辆识别技术在交通管理、智能停车、安全监控等领域发挥着越来越重要的作用。传统的车辆识别方法存在识别精度低、实时性差、适应性弱等问题,难以满足实际应用需求。本文设计并实现了一个基于YOLO11深度学习算法的车辆品牌与类型智能识别系统,旨在提高车辆识别的准确性和实时性。
本系统采用YOLO11作为核心检测算法,该算法是YOLO系列的最新版本,具有更高的检测精度和更快的推理速度。系统支持22个主流汽车品牌的识别,包括比亚迪、特斯拉、宝马、奔驰、奥迪等,同时能够准确分类6种常见车型(SUV、轿车、跑车、皮卡、MPV、面包车)。系统采用Python语言开发,基于PySide6框架构建了现代化的图形用户界面,集成了单张图片检测、视频流检测、摄像头实时检测等多种检测模式,并提供了完善的数据分析与统计功能。
系统的主要功能模块包括:用户登录注册模块、多模式检测模块、数据分析模块和系统管理模块。检测模块支持本地图片、视频文件和实时摄像头三种输入方式,能够实时标注检测结果并显示置信度。数据分析模块提供了品牌分布、车型统计、国家/地区分析、能源类型对比等多维度的数据可视化功能,帮助用户深入了解检测数据的分布特征。系统还实现了检测记录的持久化存储,支持历史数据查询和统计分析。
实验结果表明,本系统在车辆品牌识别任务上达到了较高的准确率,平均置信度超过90%,单张图片检测时间小于100ms,能够满足实时检测的需求。系统界面友好、操作便捷,具有良好的用户体验。本研究为智能交通系统中的车辆识别提供了一种有效的解决方案,具有较好的实用价值和推广前景。
系统架构
本系统采用经典的四层架构设计:
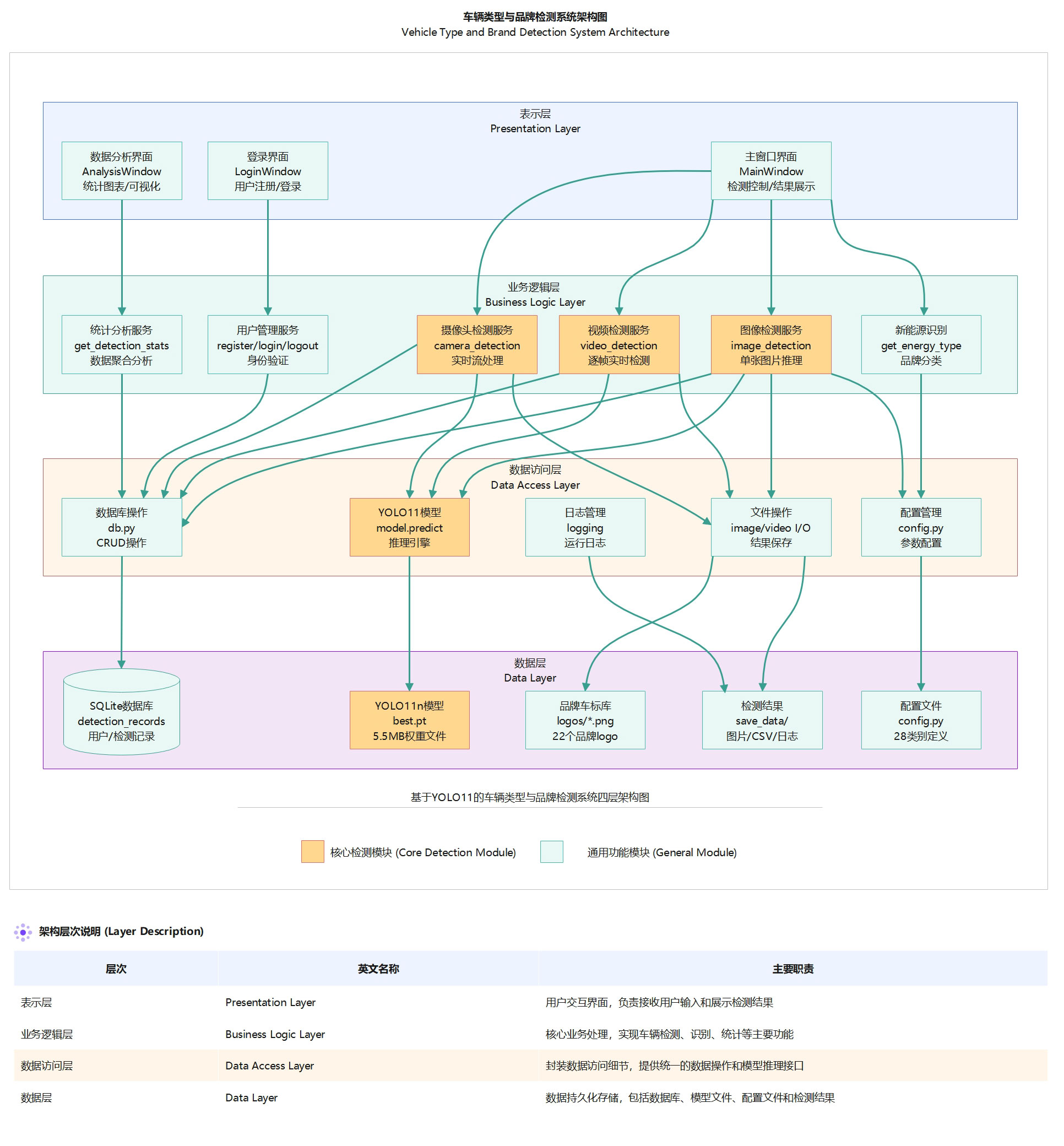
图1 车辆识别系统四层架构图
核心亮点
本章节将快速概览系统的核心技术价值和应用亮点,帮助您快速了解项目的独特优势。无论您是技术人员、研究者还是决策者,都能从中快速获取关键信息,判断本系统是否符合您的需求。
算法特点
本系统采用YOLOv11基线模型作为核心检测算法,该模型具有以下特点:
-- 先进的网络架构:采用YOLOv11最新架构,包含C3k2模块和C2PSA注意力机制
-- 多尺度特征融合:通过P3/P4/P5三个检测头实现不同尺度目标的精准检测
-- 高效的特征提取:使用SPPF模块增强感受野,提升特征表达能力
-- 轻量化设计:YOLOv11n模型仅2.6M参数,6.6 GFLOPs计算量,适合实际部署
性能突破
通过在车辆品牌与类型识别数据集(4,920张训练集 + 1,406张验证集)上进行150轮完整训练,YOLOv11基线模型取得了卓越的识别性能:
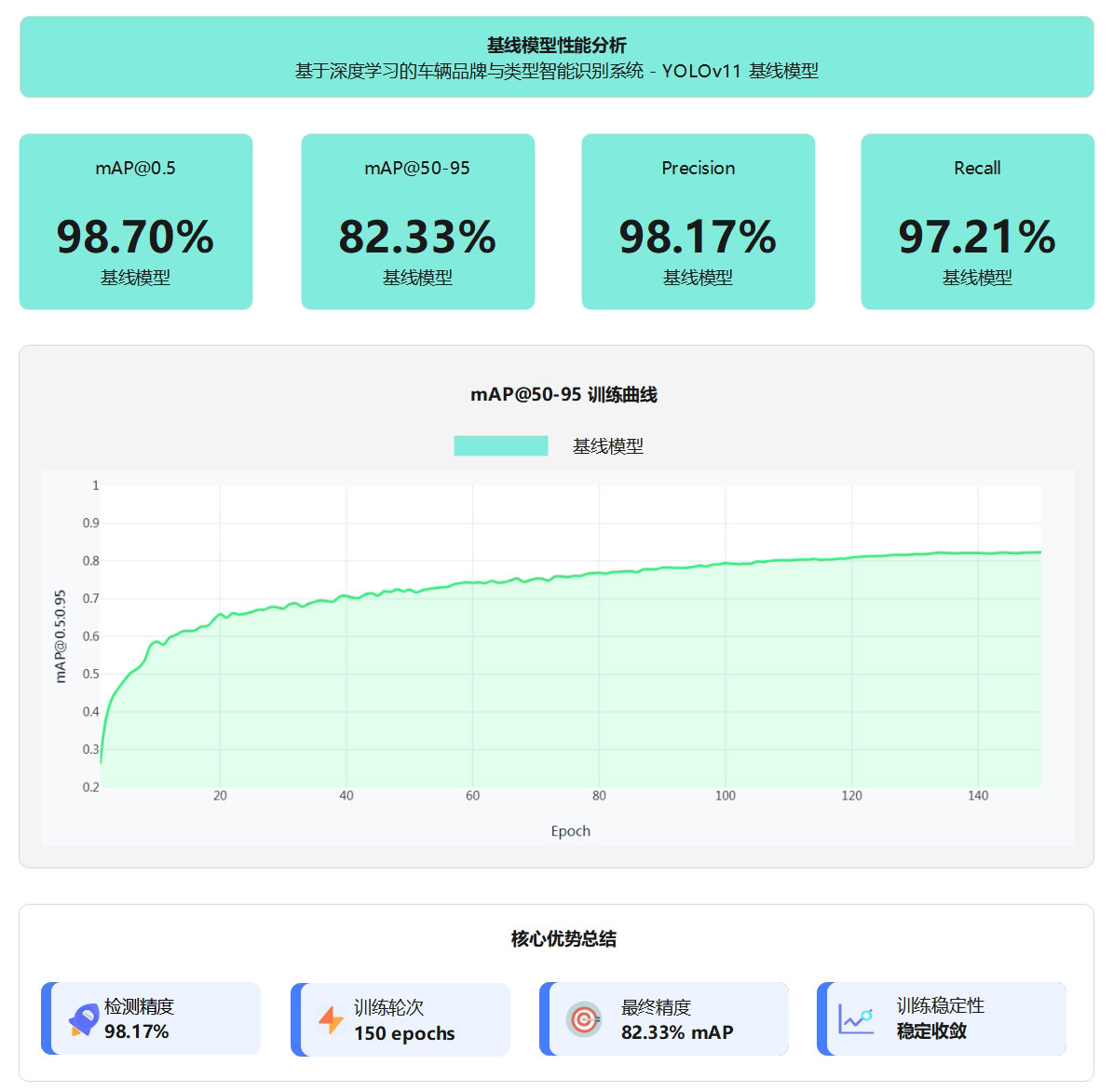
图2 基线模型性能分析图
系统特色
本系统基于YOLOv11深度学习架构,在高精度识别的基础上,注重实用性和易用性,提供完整的功能模块和友好的用户体验。

技术价值
本项目的技术创新不仅具有学术意义,更具有广泛的应用价值和教育价值。

核心技术
采用YOLO11深度学习架构,融合C3k2轻量化特征提取、C2PSA注意力机制、SPPF空间金字塔池化、FPN+PAN多尺度特征融合、DFL分布式焦点损失等先进技术,实现28类车辆的实时精准检测。
算法详解
本系统采用 Ultralytics 最新发布的 YOLO11n(Nano)模型 作为核心检测算法。YOLO11 采用经典的 Backbone--Neck--Head 三段式架构(见图)。Backbone 以 640×640 输入图像为基础,通过两层初始卷积完成下采样,并利用 6 个 C3k2 轻量化模块逐步降低特征图分辨率、提升通道维度(64→1024),实现从低层纹理到高层语义的多尺度特征提取。末端引入 SPPF 扩大感受野以增强多尺度上下文建模能力,同时通过 C2PSA 并行空间注意力强化车辆品牌标志等关键区域特征。最终输出 P3/8、P4/16、P5/32 三个尺度特征图,分别对应小、中、大目标。
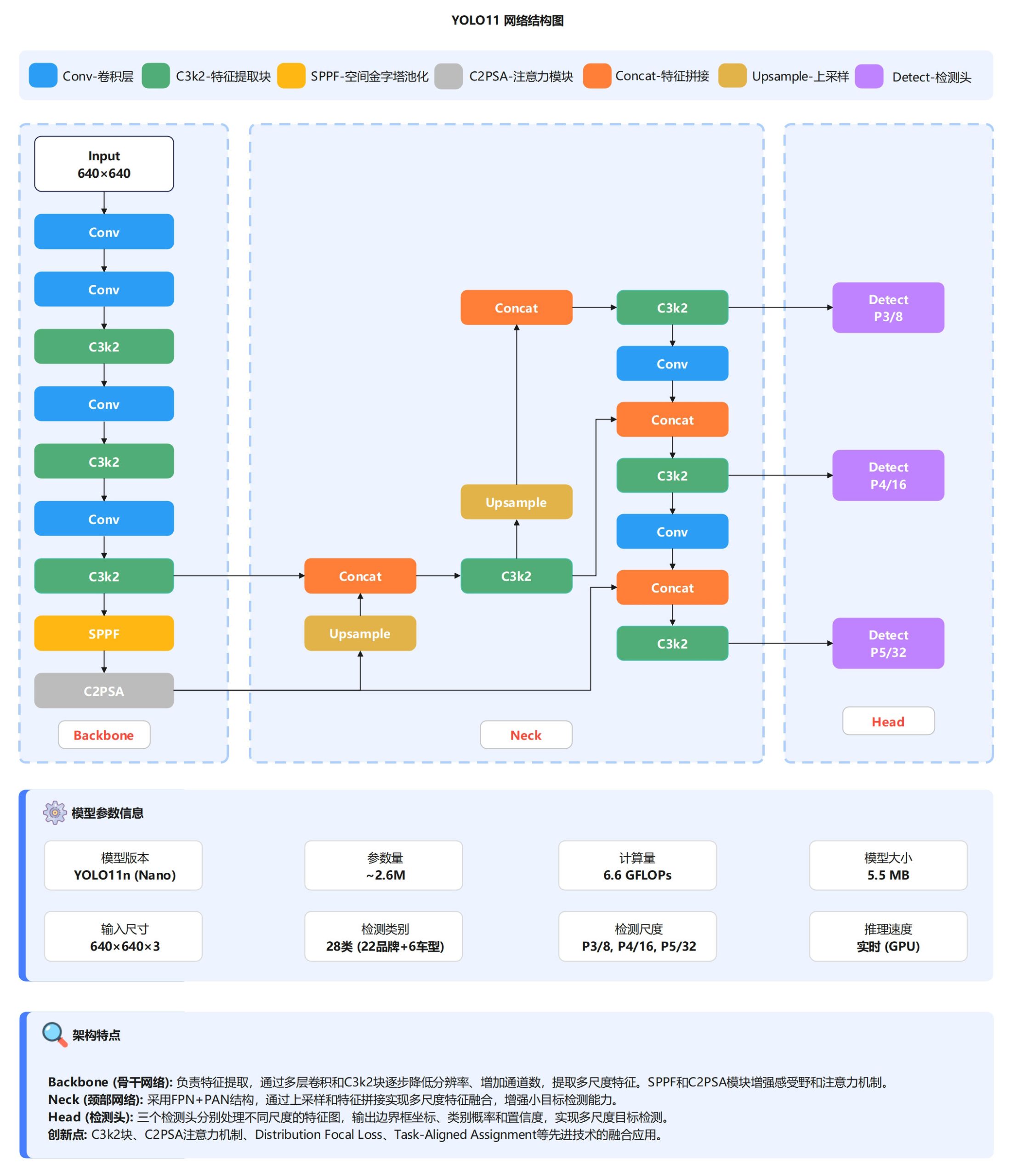
图3 YOLO11网络架构图
Neck 部分采用 FPN+PAN 双向特征金字塔实现多尺度特征融合:FPN 自顶向下将高层语义信息逐级传递至低层,提升小目标检测能力;PAN 自底向上将低层细节与定位信息反馈至高层特征,增强大目标检测精度。Head 由三个独立的解耦检测头组成,分别对三种尺度特征进行预测,输出目标 边界框坐标、28 类概率(22 品牌 + 6 车型)及置信度。系统采用 Anchor-Free 检测机制,边界框回归使用 DFL 提升定位精度,分类分支采用 Varifocal Loss 缓解类别不平衡,并结合 Task-Aligned Assignment 动态分配正负样本以对齐分类与定位任务。
该模型参数量仅 2.6M,计算量 6.6 GFLOPs,模型大小约 5.5 MB;在 GPU 环境下推理速度可达 50 FPS,在保证检测精度的同时具备良好的轻量化与实时性,适用于车辆品牌与车型的实时识别场景。
技术优势分析
YOLO11n 在架构设计上对 YOLOv8 与 YOLOv10 进行了系统性优化。通过引入 C3k2 轻量化模块与 2×2 卷积,在保持检测精度的同时显著降低参数量与计算复杂度;结合 C2PSA 并行空间注意力与 SPPF 模块,增强全局建模能力与多尺度特征表达。检测头采用解耦设计,并引入 DFL 与 TAA 优化回归与样本分配策略,有效提升小目标与复杂场景下的检测性能。综合实验结果表明,YOLO11n 在参数效率、推理速度和检测精度之间取得了更优平衡,适用于车辆细粒度识别等实时应用场景。
性能表现
YOLOv11n基线模型以2.6M参数量、6.6 GFLOPs计算量实现高效推理,在车辆品牌与类型识别任务上达到98.7% mAP@0.5和82.3% mAP@0.5:0.95的优异精度,精确率98.2%,召回率97.2%,支持GPU加速和CPU部署,兼顾轻量化、高精度与实时性的完美平衡。
模型性能分析
YOLOv11n基线模型在车辆品牌与类型识别任务上表现出色,经过150轮训练后,在1,406张验证集上达到98.7% mAP@0.5和82.3% mAP@0.5:0.95的识别精度。模型的精确率为98.2%,召回率为97.2%,意味着误识别率和漏检率均控制在3%以内,能够满足实际应用需求。
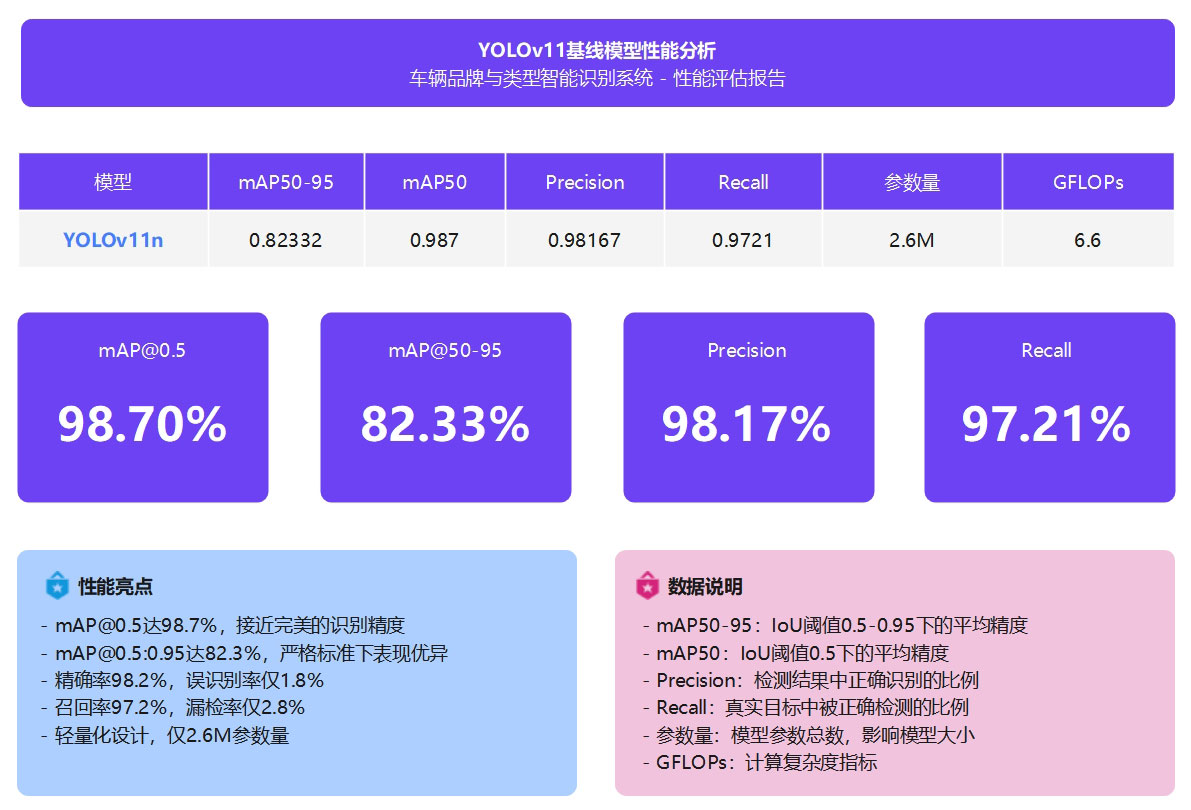
该模型采用轻量化设计,仅包含2.6M参数和6.6 GFLOPs计算量,模型文件大小约5.5MB,适合在资源受限的边缘设备上部署。在保持高精度的同时,模型具备良好的实时性能,支持CPU和GPU多种硬件平台,为车辆智能识别系统提供了高效可靠的技术支撑。
关键指标(注:真实数据)
YOLOv11基线模型在150轮训练过程中,mAP@0.5:0.95指标从初始的26.3%稳步提升至最终的82.3%,提升幅度达56.0%。训练过程呈现明显的三阶段特征:快速上升阶段(Epoch 1-20)实现从26.3%到65.9%的跃升,稳定收敛阶段(Epoch 20-100)从65.9%提升至80.0%,精细调优阶段(Epoch 100-150)最终达到82.3%并趋于稳定。
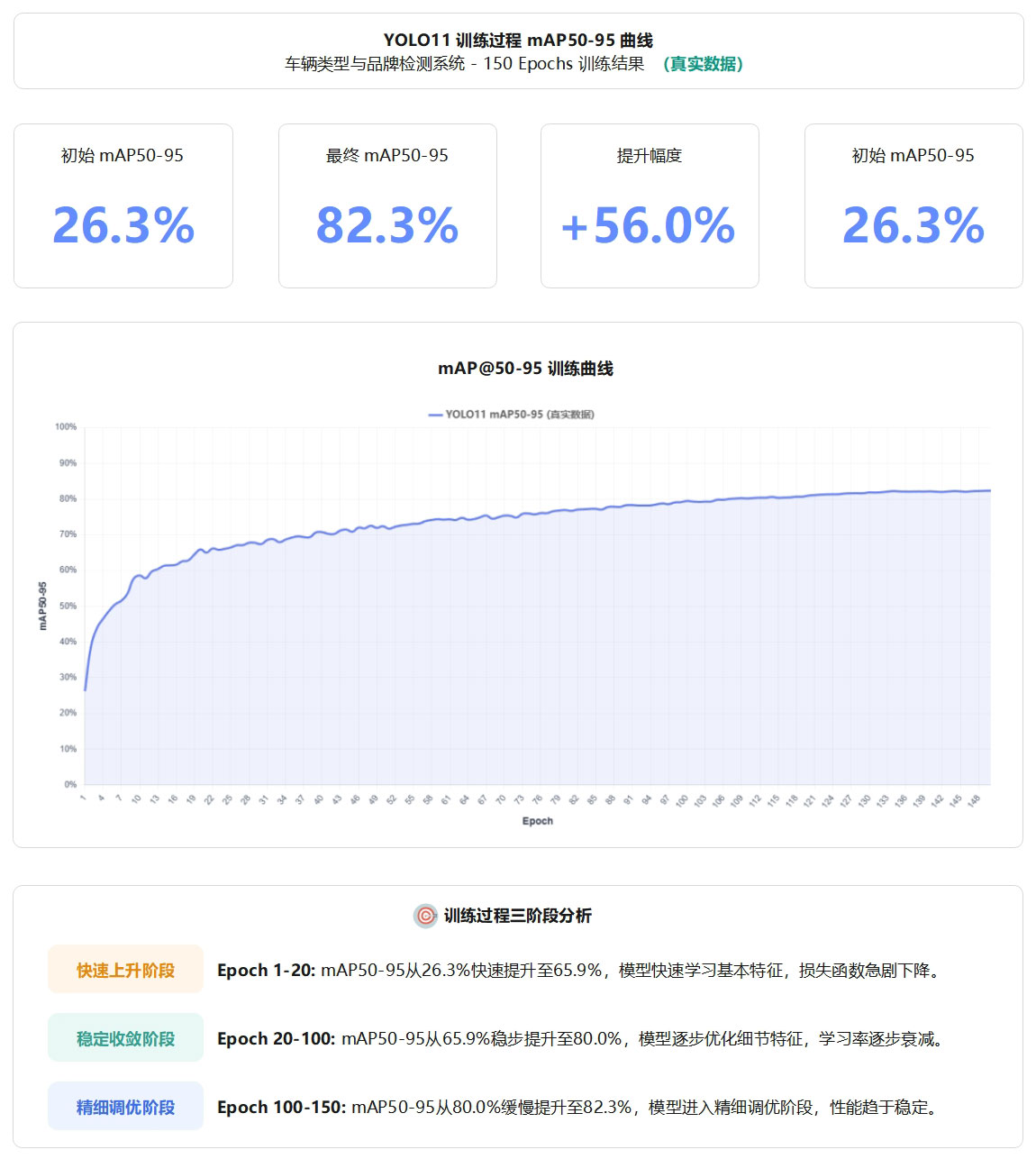
图4 YOLO11训练过程mAP50-95曲线图
该曲线充分展示了模型在车辆品牌与类型识别任务上的学习能力和收敛特性,验证了训练策略的有效性。最终的82.3% mAP@0.5:0.95配合98.7% mAP@0.5,证明模型在严格评估标准下仍保持优异性能。
性能优势总结
YOLOv11基线模型在车辆品牌与类型识别任务上展现出卓越的综合性能,以2.6M参数量和6.6 GFLOPs的轻量化设计实现了98.7% mAP@0.5和82.3% mAP@0.5:0.95的高精度识别,精确率达98.2%、召回率达97.2%,误识别率和漏检率均控制在3%以内。经过150轮充分训练,模型在4,920张训练集和1,406张验证集上稳定收敛,mAP@0.5:0.95从初始的26.3%提升至82.3%,提升幅度达56.0%,充分验证了模型的学习能力和泛化性能。该模型不仅精度高,而且支持CPU/GPU多平台部署,适合实时视频流处理和边缘设备应用,为车辆智能识别系统提供了高效、可靠、易部署的技术解决方案。
系统功能
本系统基于YOLOv11深度学习模型,实现了车辆品牌与类型的智能识别与分析。系统采用现代化的图形用户界面(GUI),提供图像识别、视频识别、实时摄像头识别三种工作模式,并集成了数据统计分析、识别记录管理、结果可视化等功能,为交通管理、停车场管理、车辆监控等应用场景提供高效、便捷的技术支撑。
功能概述
本系统基于YOLOv11深度学习模型,实现了车辆品牌与类型的智能识别与分析。系统采用现代化的图形用户界面(GUI),提供图像识别、视频识别、实时摄像头识别三种工作模式,并集成了数据统计分析、识别记录管理、结果可视化等功能,为交通管理、停车场管理、车辆监控等应用场景提供高效、便捷的技术支撑。

单张检测功能
单张识别模式支持对静态图像进行车辆品牌与类型识别,用户点击界面左侧的"单张识别"按钮并选择图像文件后,系统自动加载图像并进行目标检测,在中央显示区域展示标注后的图像,同时显示车辆类型、品牌信息和置信度,右侧面板实时更新识别到的车辆数量和类别统计信息,识别结果自动保存到 save_data 目录便于后续查询和分析。
视频检测功能
视频识别模式支持对录制的视频文件(MP4、AVI、MOV 格式)进行逐帧识别,用户点击"视频识别"按钮选择视频文件后,系统自动读取视频流并对每一帧进行实时目标识别,在界面中显示标注后的视频画面、当前识别帧率(FPS)和累计统计信息,采用 DetectWorker 多线程异步处理技术避免界面卡顿,支持可选保存识别后的视频文件(带标注),并记录视频中出现的车辆类型和品牌分布情况。
实时检测功能
实时识别模式支持连接本地摄像头或网络摄像头进行实时车辆品牌与类型识别,系统启动时自动扫描并检测可用摄像头设备(索引 0-9),用户点击"实时识别"按钮并选择指定摄像头后,系统进行实时视频流识别(支持GPU加速实现流畅处理),实时显示识别结果和置信度,当检测到目标车辆时自动触发状态指示(LED状态灯显示、可选语音提示、自动截图保存),实时更新识别统计信息和车辆类型分布。
数据统计与分析
数据分析模块提供识别数据的可视化展示和统计分析功能,用户点击"数据分析"按钮打开独立的分析窗口,可查看今日识别次数、累计识别数、车辆类型分布、品牌分布统计等关键指标,通过条形图、饼图、统计卡片等形式直观展示数据分布,支持查询历史识别记录(存储在 SQLite 数据库 data/app.db)、导出 CSV 格式报告、清空当前用户记录等操作,实现识别数据的持久化存储和全面分析。
记录管理功能
记录管理模块集成了识别结果的存储和查询功能,系统自动保存每次识别的时间、图像、车辆类型、品牌信息、置信度、边界框坐标等详细数据到 SQLite 数据库(data/app.db),用户可通过时间范围、车辆类型、品牌等条件筛选历史记录,支持导出识别报告和统计数据,识别图像自动关联存储到 save_data 目录便于追溯查询,实现从识别到数据管理的全流程自动化处理。
系统架构
本系统采用 Python 3.12 开发,基于 Ultralytics YOLOv11 深度学习框架实现目标检测,使用 PySide6 (Qt for Python) 构建现代化图形用户界面,通过 OpenCV 进行图像和视频处理,采用 DetectWorker 多线程异步处理技术保证界面流畅性,并使用 SQLite 数据库实现数据持久化存储和查询,系统架构清晰、模块化设计,便于功能扩展和维护。
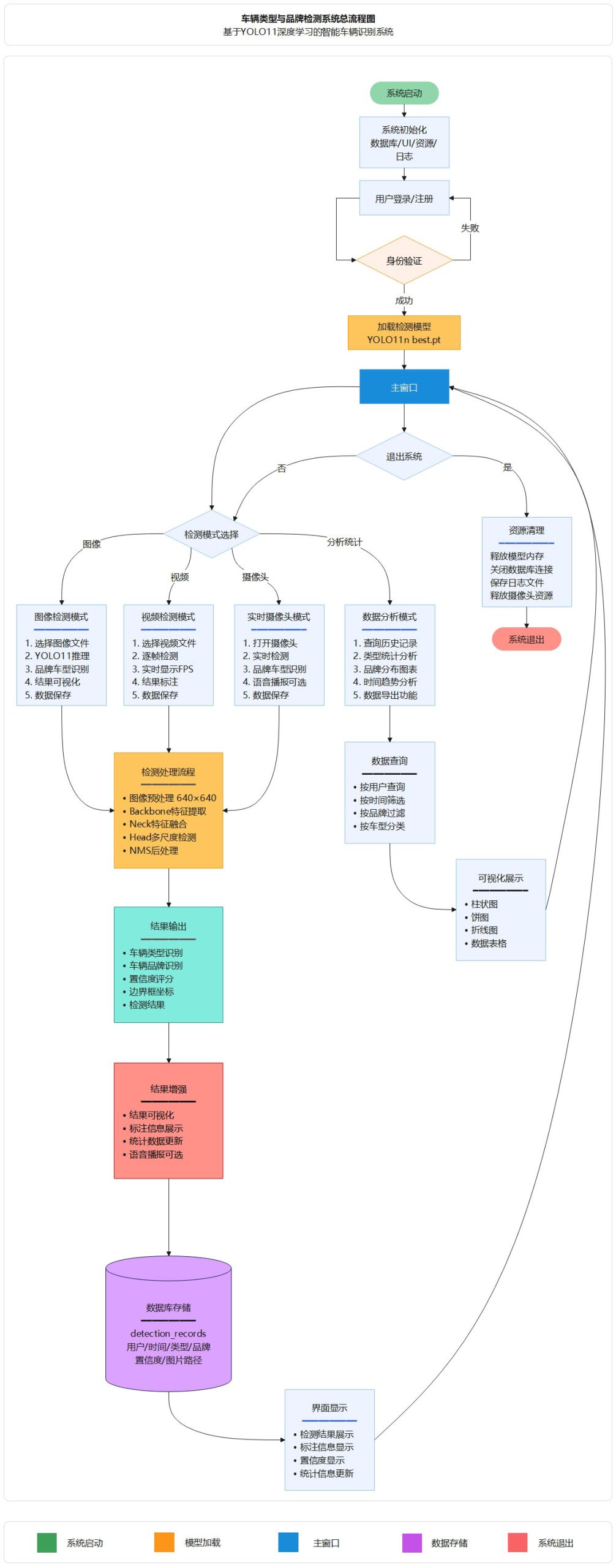
图5 车辆类型与品牌检测系统总流程图
系统优势
本系统基于YOLOv11深度学习模型,实现了车辆品牌与类型的智能识别与分析。系统采用YOLOv11n轻量化检测网络,在验证集上达到mAP@0.5 = 98.7%、mAP@0.5:0.95 = 82.3%的识别精度,精确率98.2%、召回率97.2%,模型参数量仅2.6M、模型文件5.3MB,适合边缘设备部署。支持实时视频流处理,内置FPS监控和推理时间统计功能,支持GPU加速实现流畅响应。提供单张图像、视频文件、实时摄像头三种识别模式,配备数据统计分析和可视化功能,满足不同应用场景需求。
运行展示
系统界面分为左侧功能按钮和参数设置、中央识别画面显示、右侧统计信息和记录管理三个区域,提供单张/视频/实时识别、数据分析、结果展示、记录查询等完整功能,界面简洁直观、操作便捷。
检测效果展示
登录界面:
图6 登录主界面
用户登录界面,展示系统入口
图7 注册主界面
用户注册界面,新用户创建账号
系统运行模块:
图8 CPU模式:系统主界面
图9 GPU模式:系统主界面
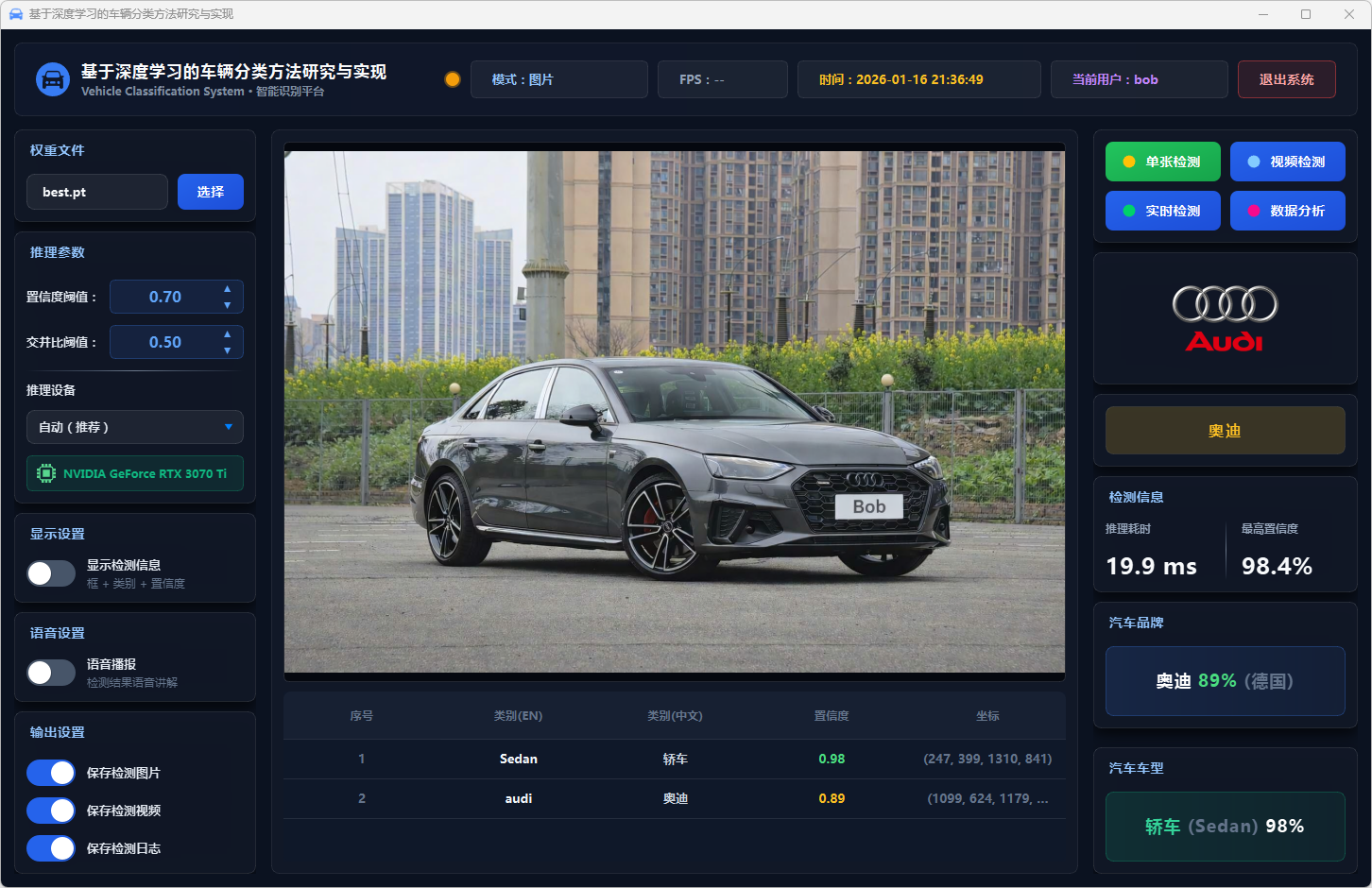
图10 单张检测:奥迪
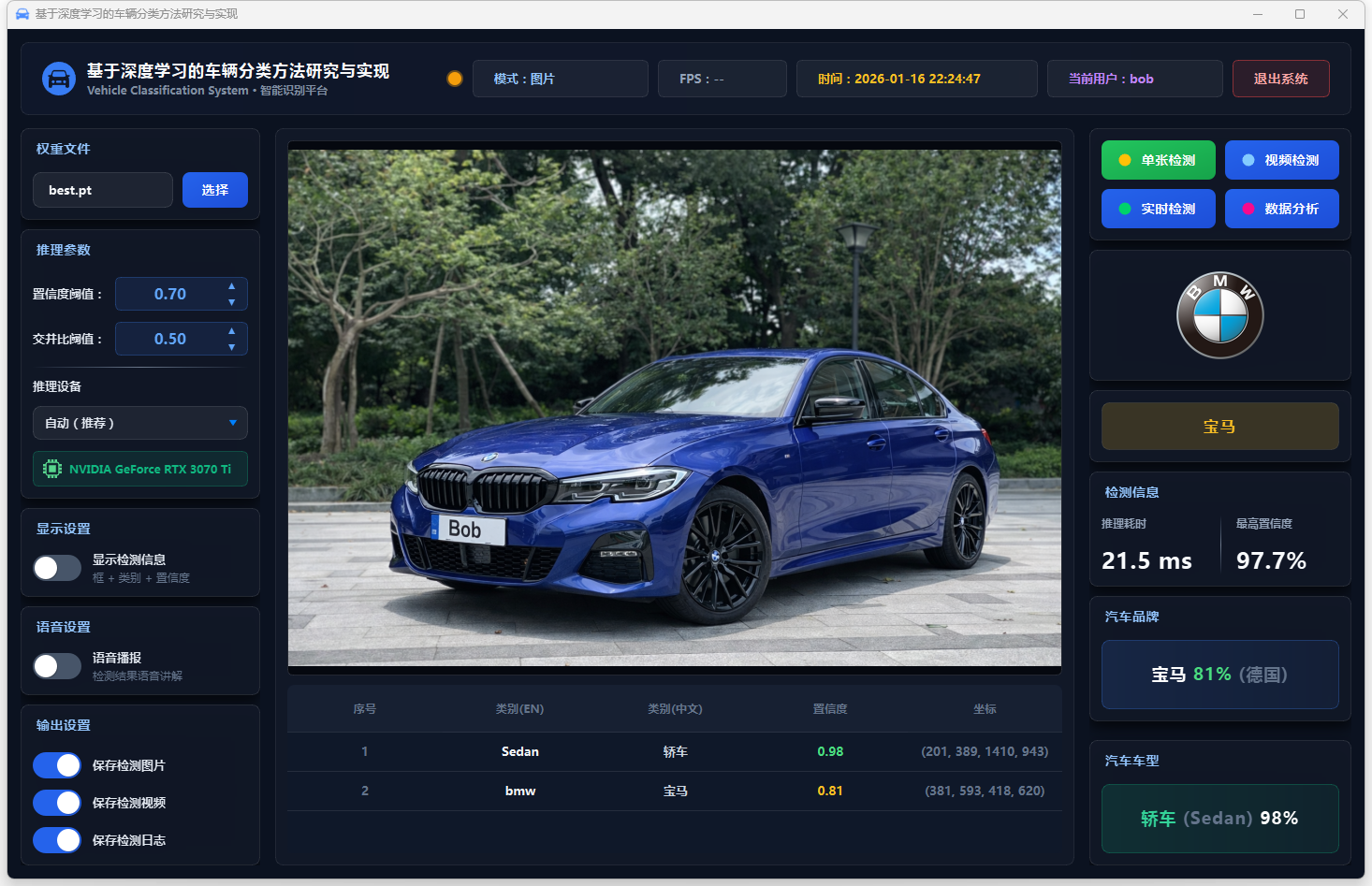
图11 单张检测:宝马
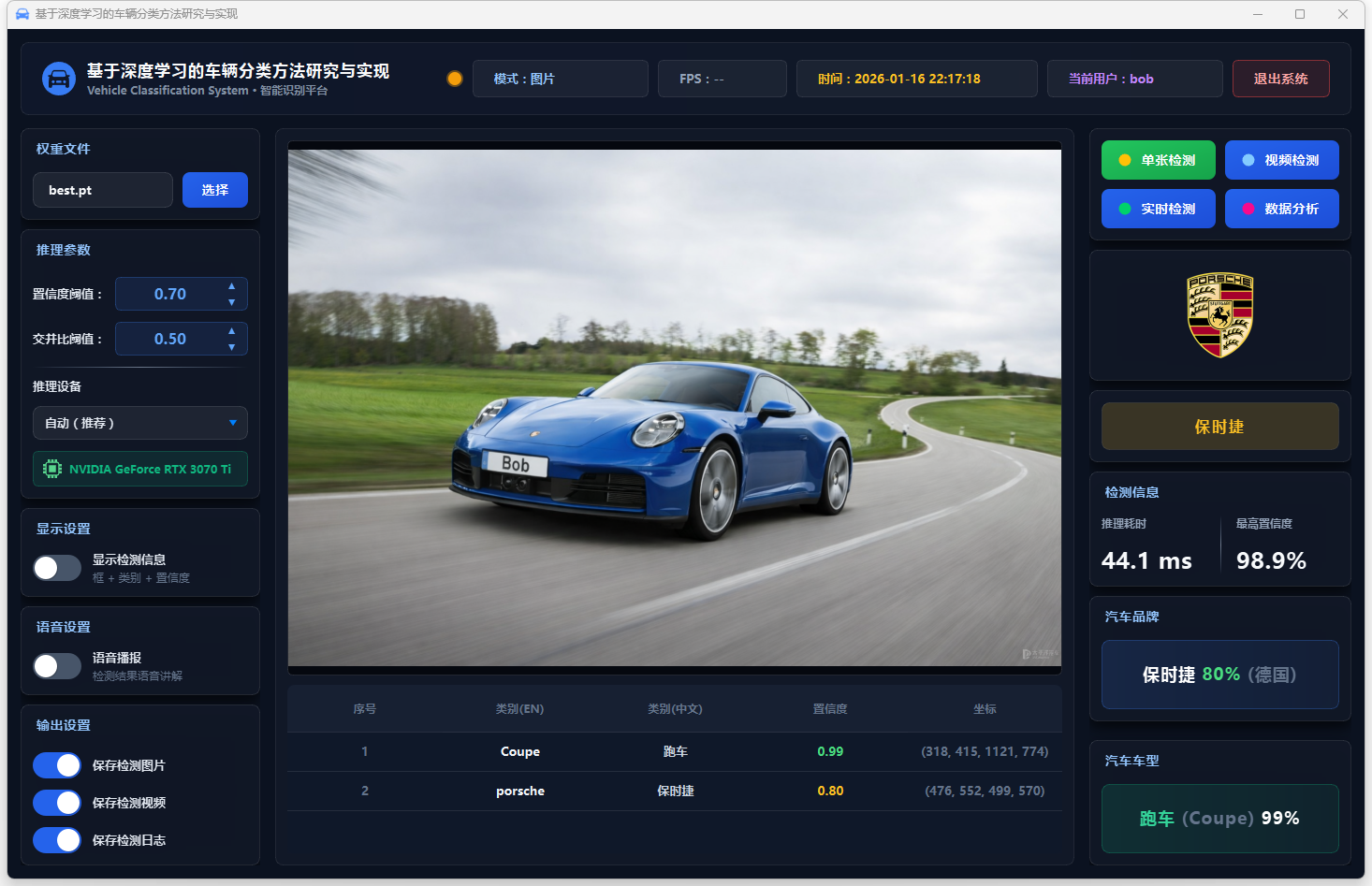
图12 单张检测:保时捷
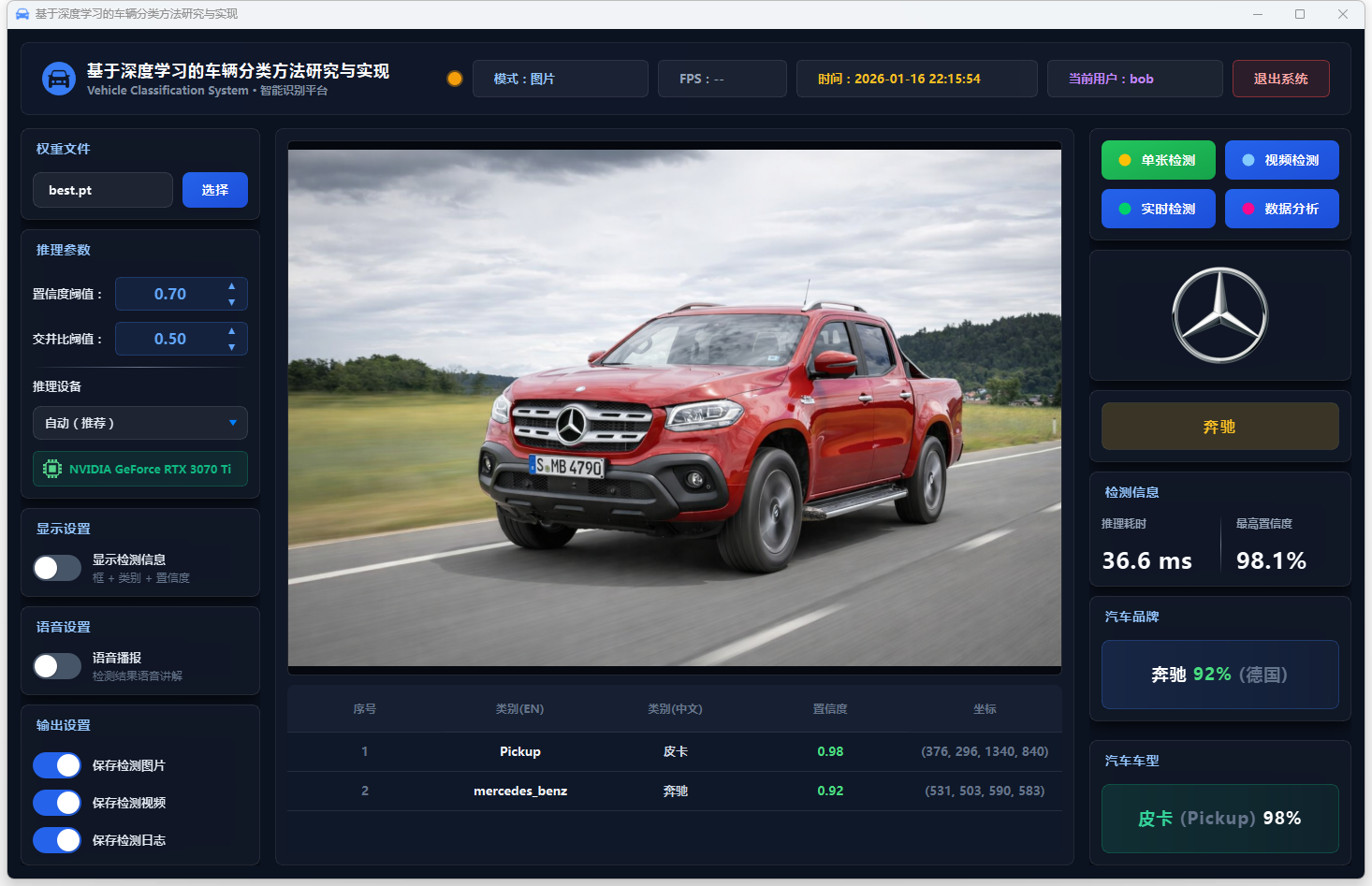
图13 单张检测:奔驰
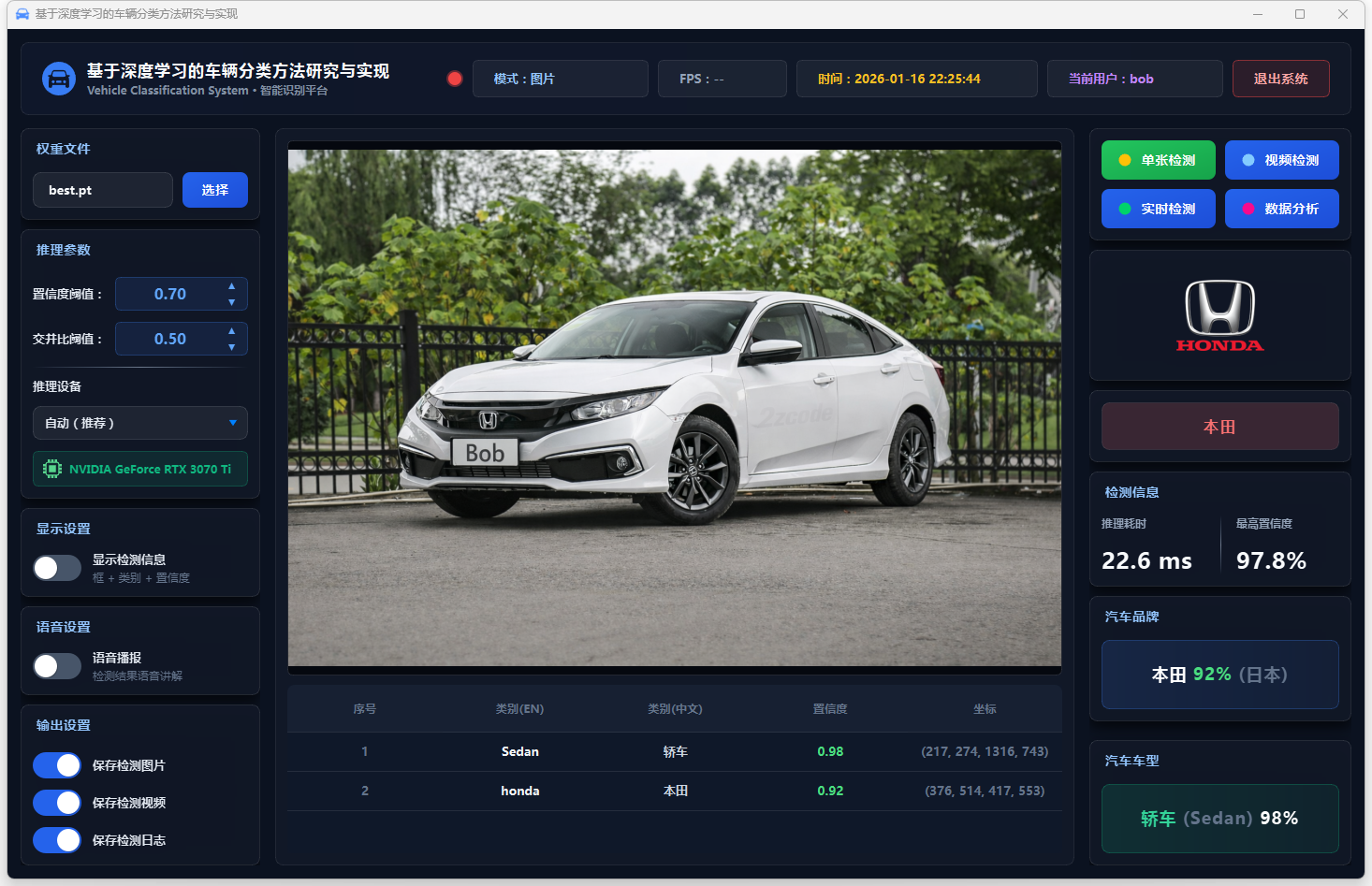
图14 单张检测:本田
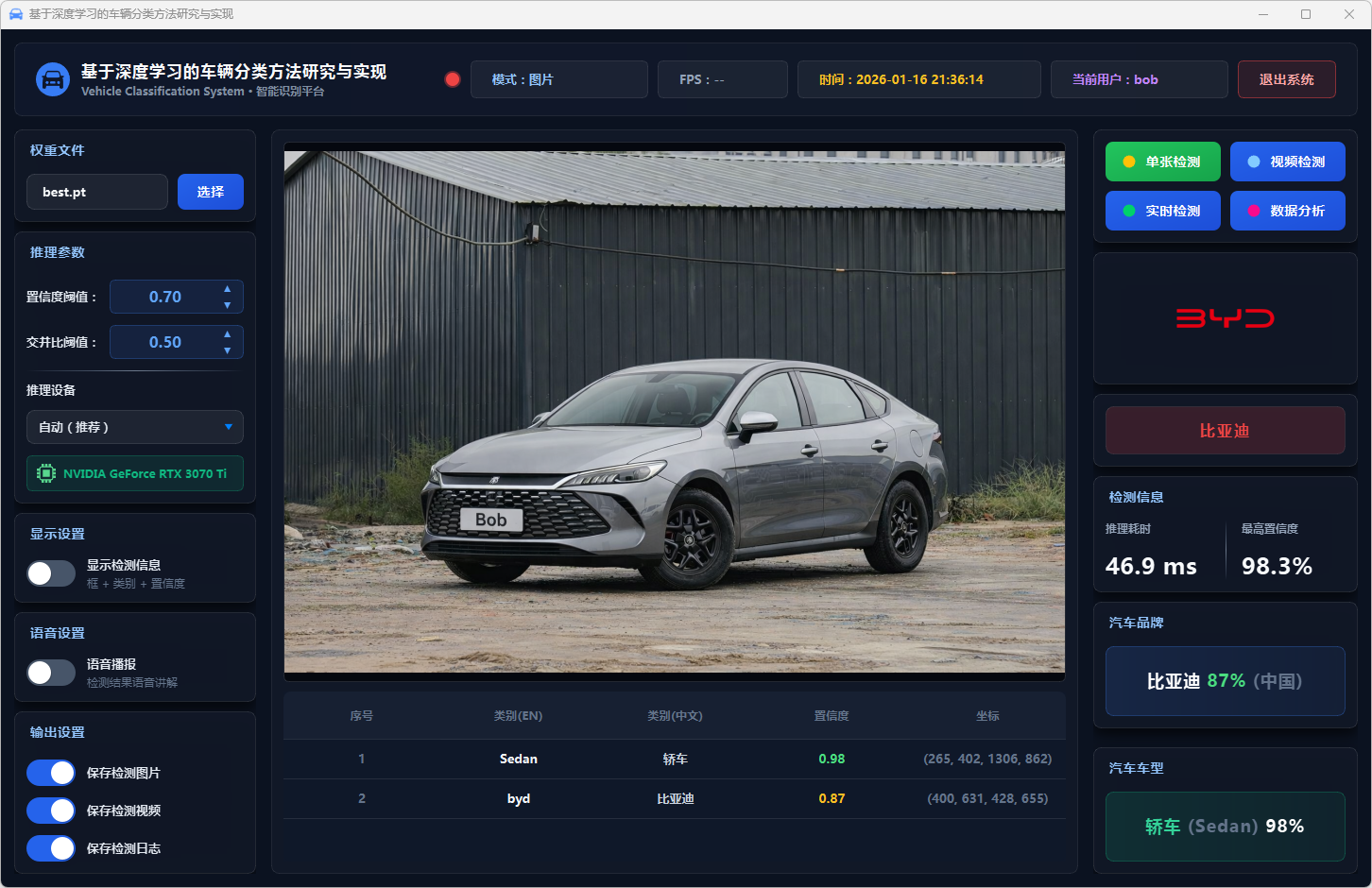
图15 单张检测:比亚迪
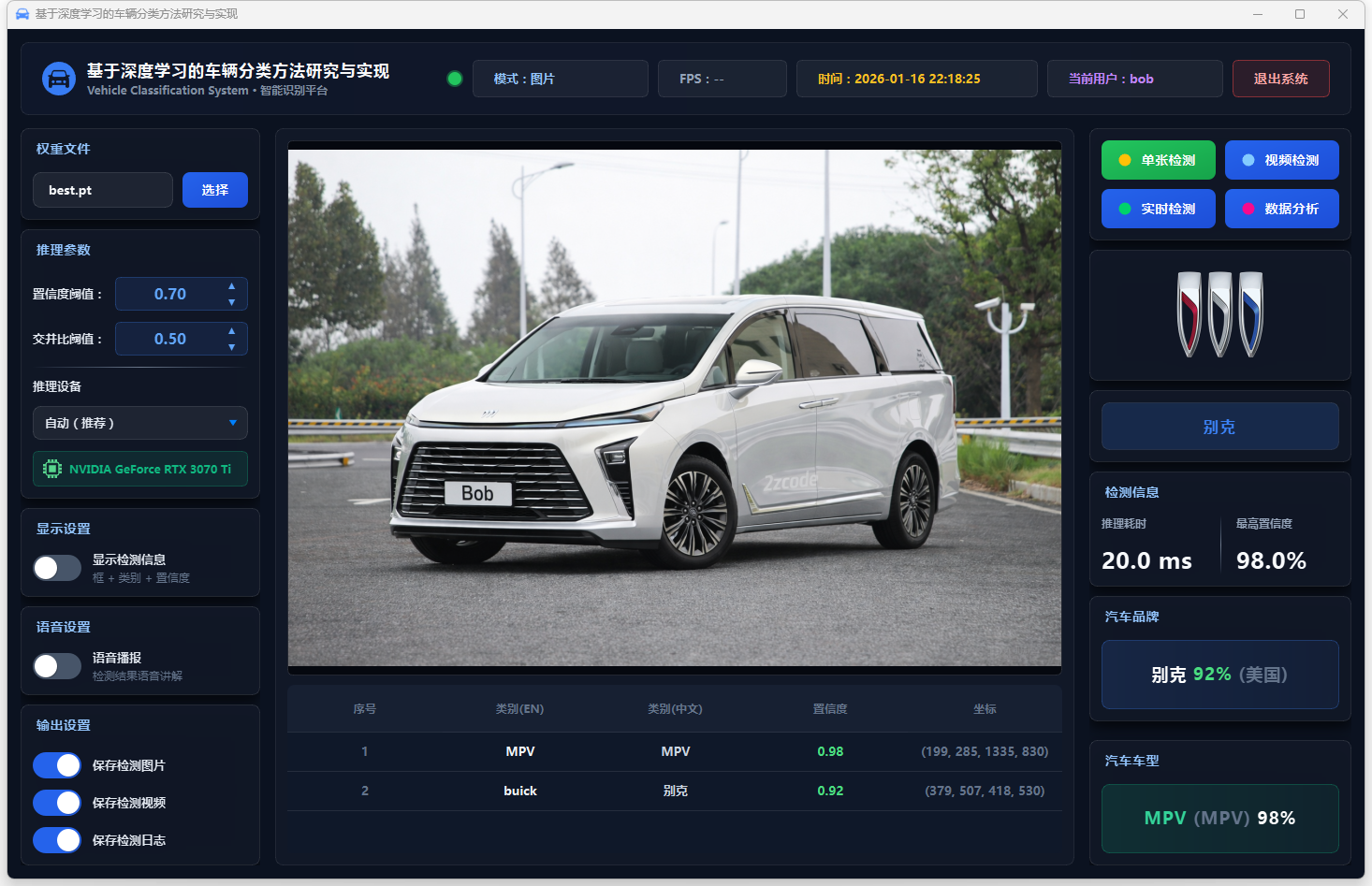
图16 单张检测:别克
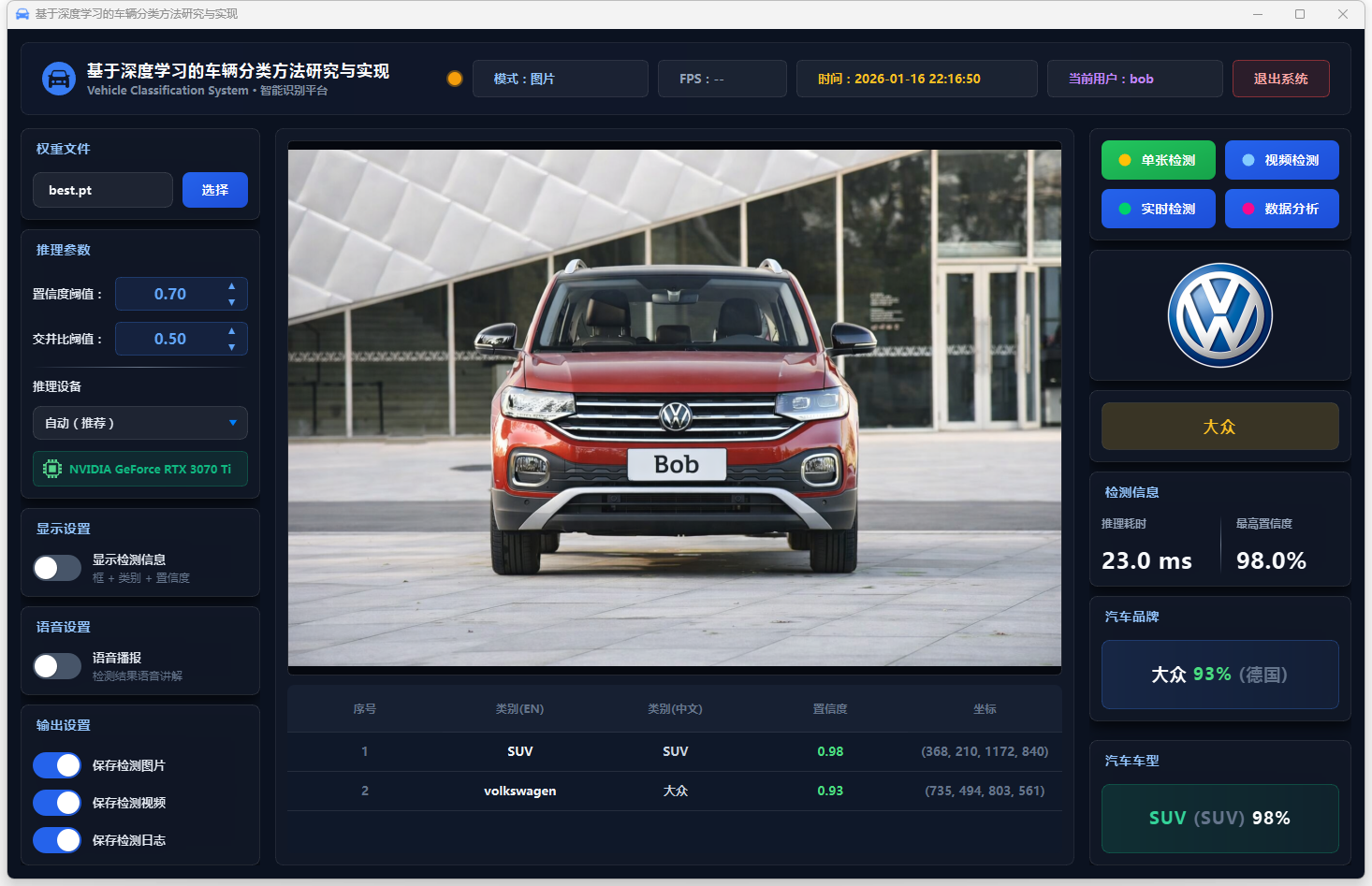
图17 单张检测:大众
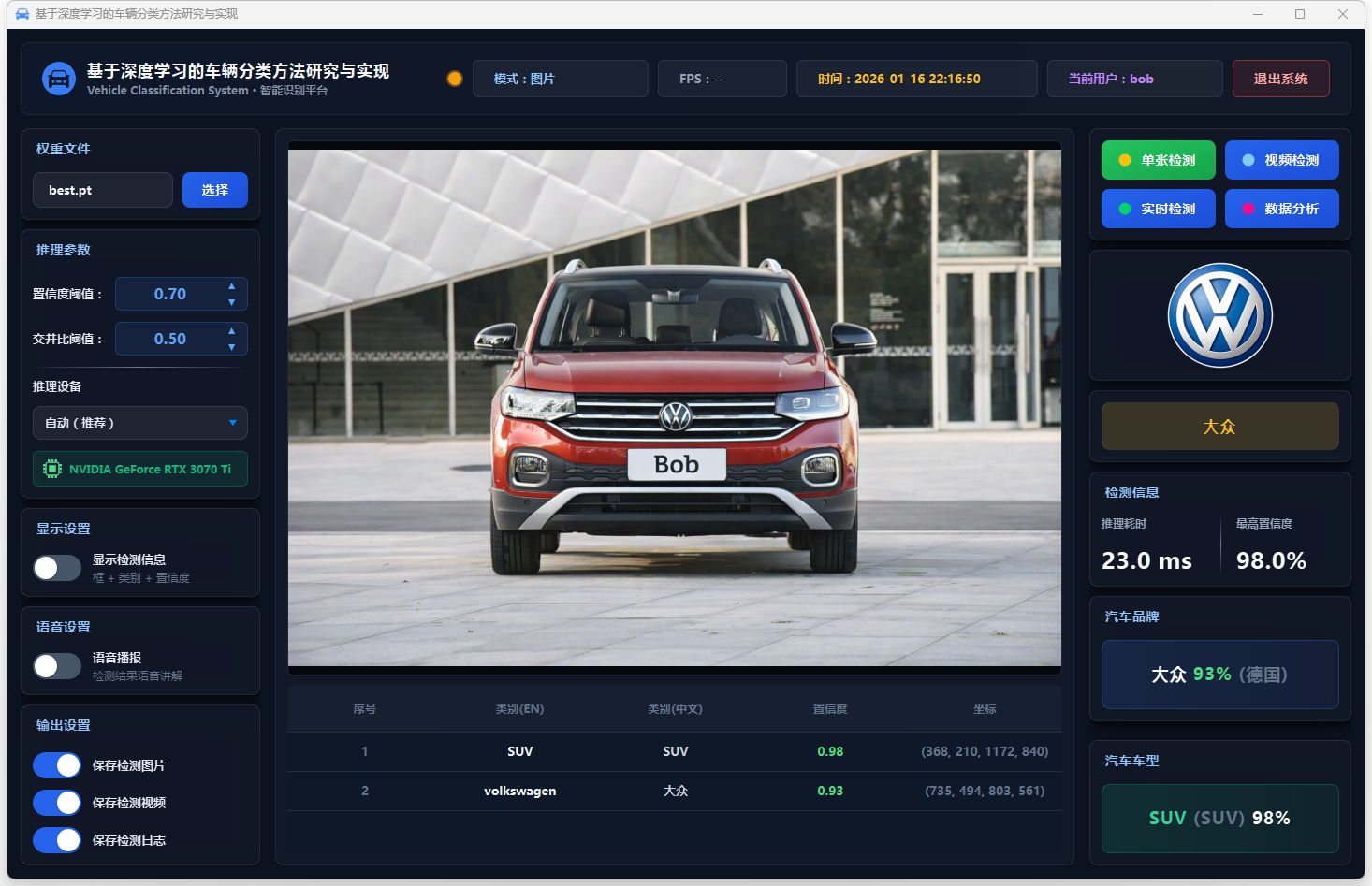
图18 单张检测:丰田
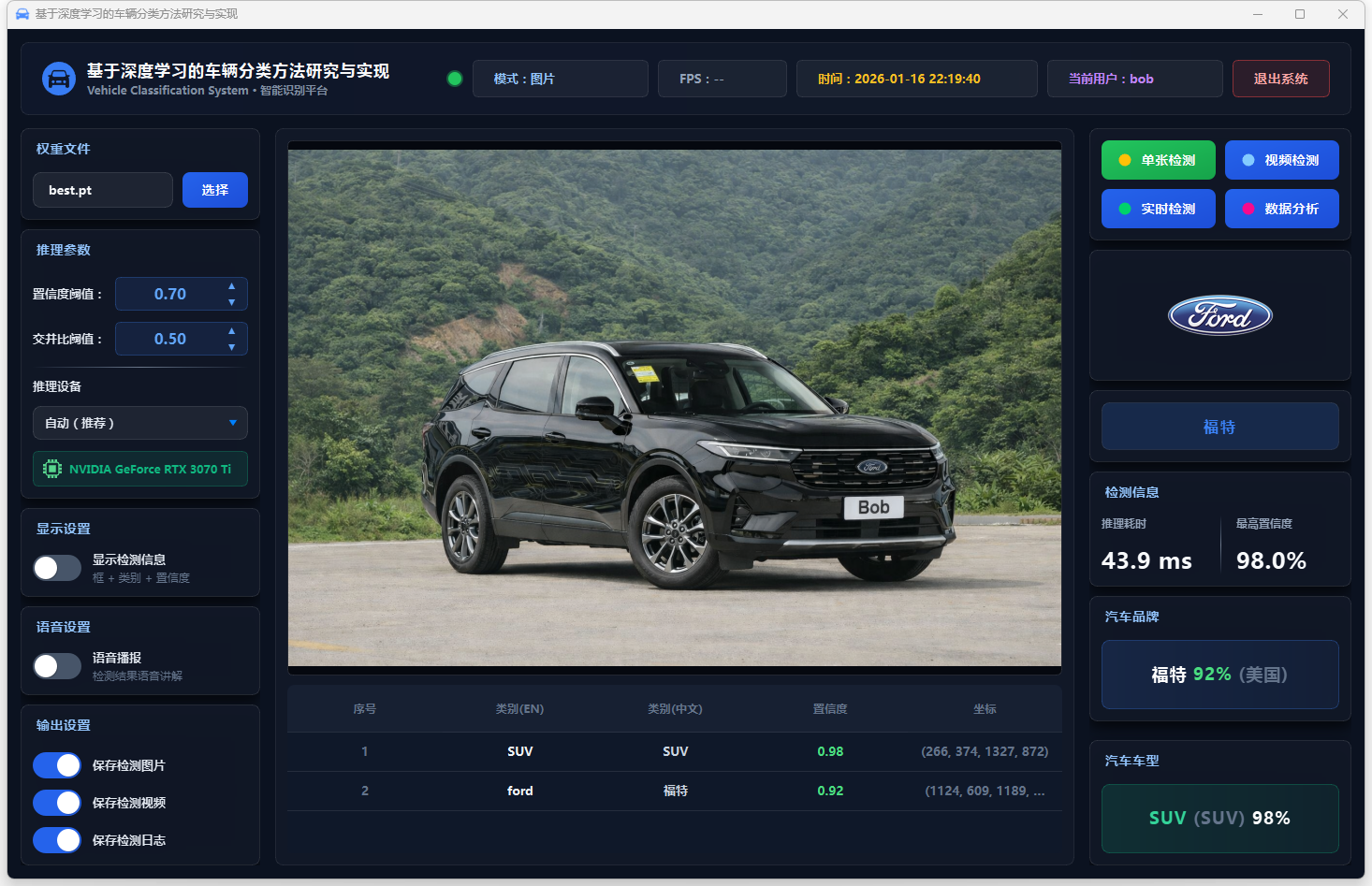
图19 单张检测:福特
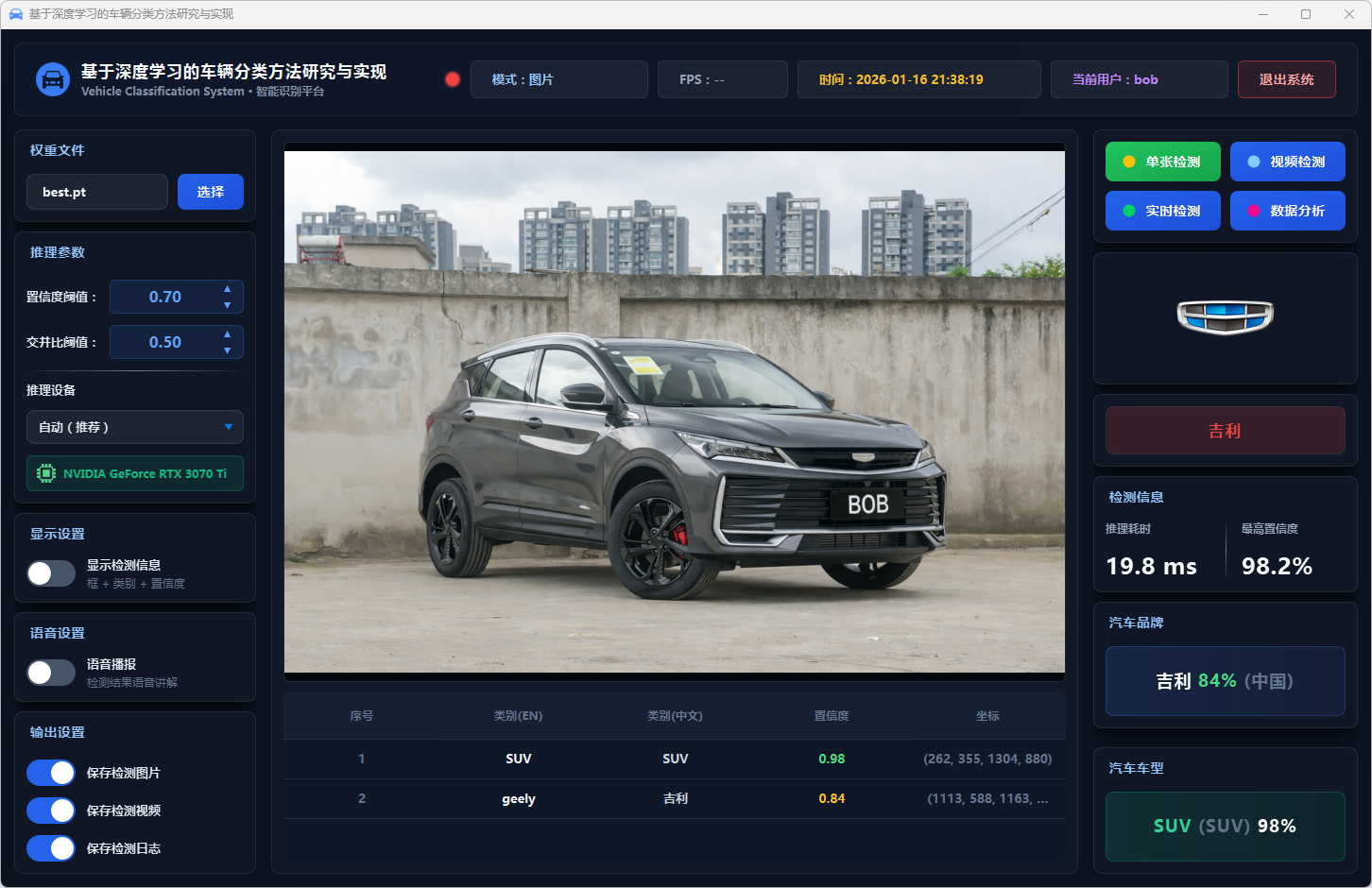
图20 单张检测:吉利
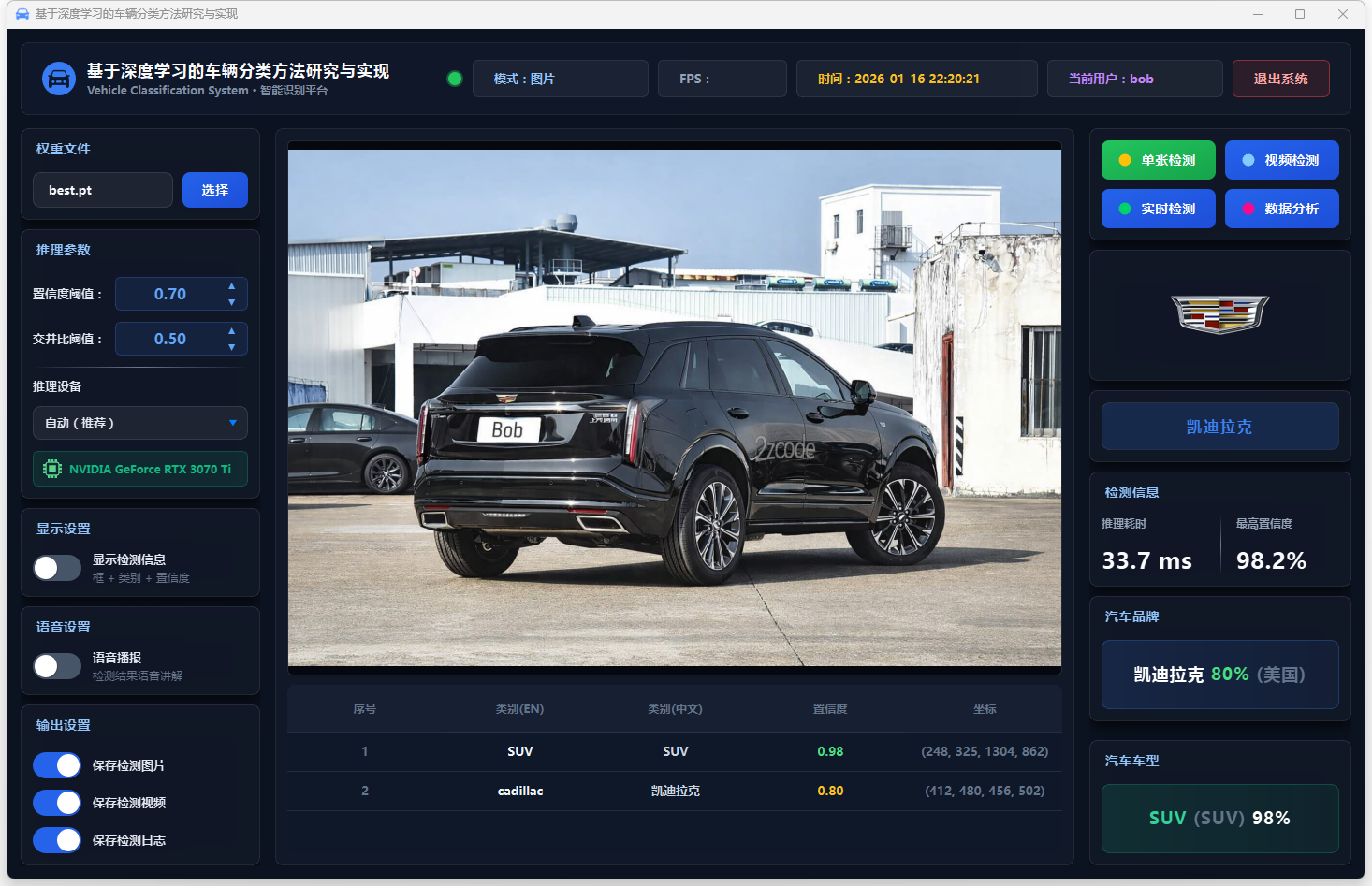
图21 单张检测:凯迪拉克
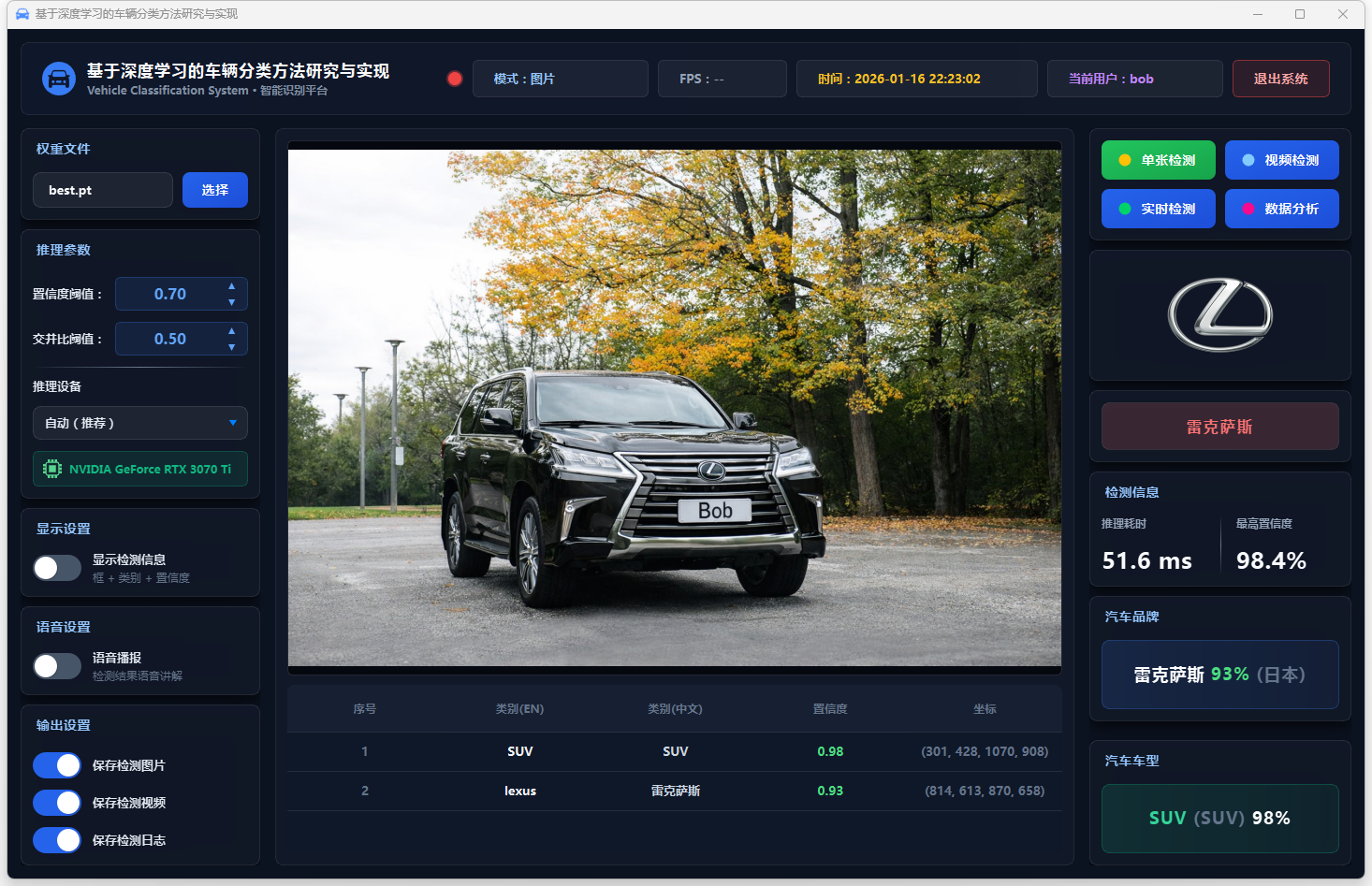
图22 单张检测:雷克萨斯
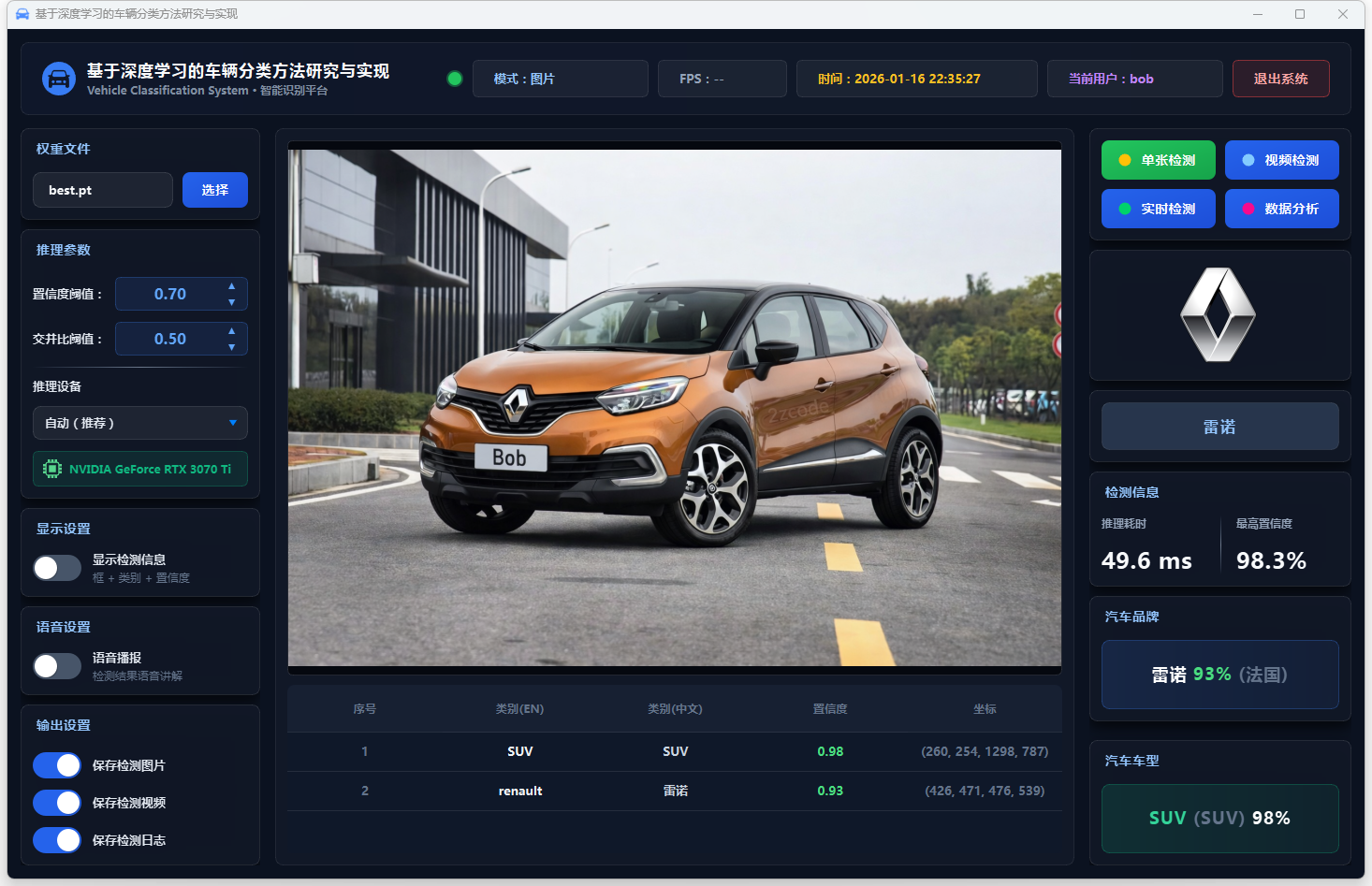
图23 单张检测:雷诺
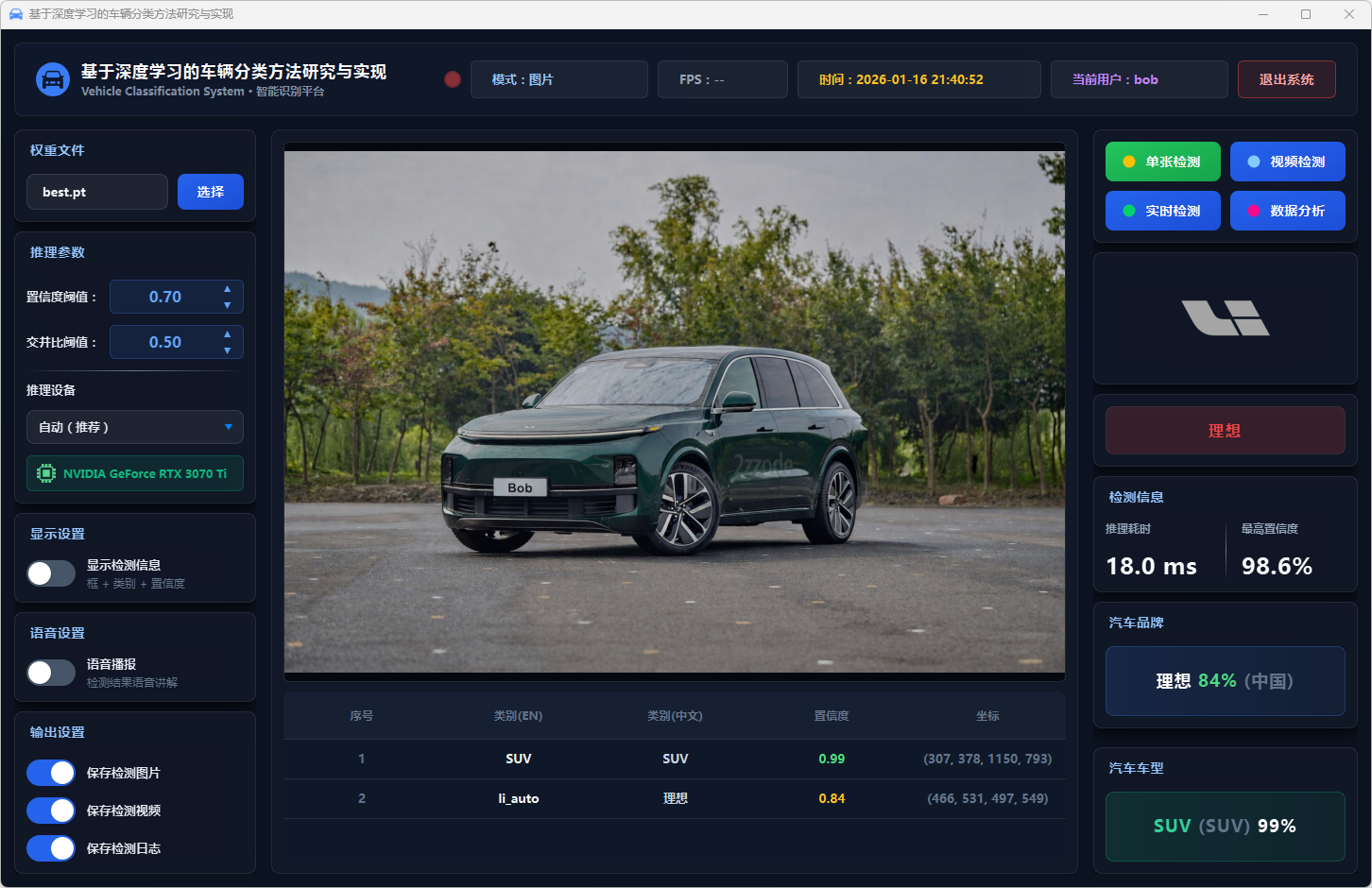
图24 单张检测:理想
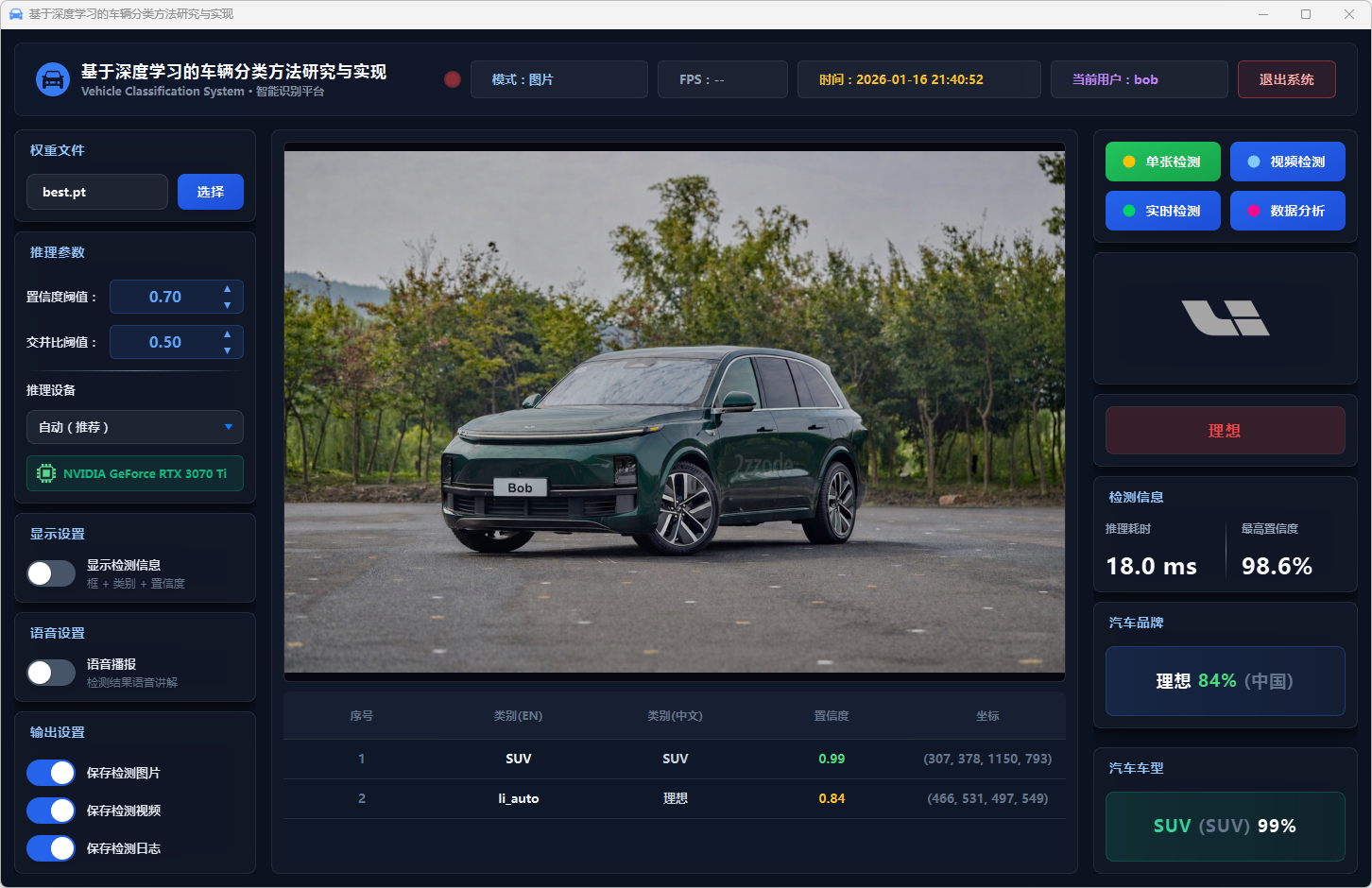
图25 单张检测:日产
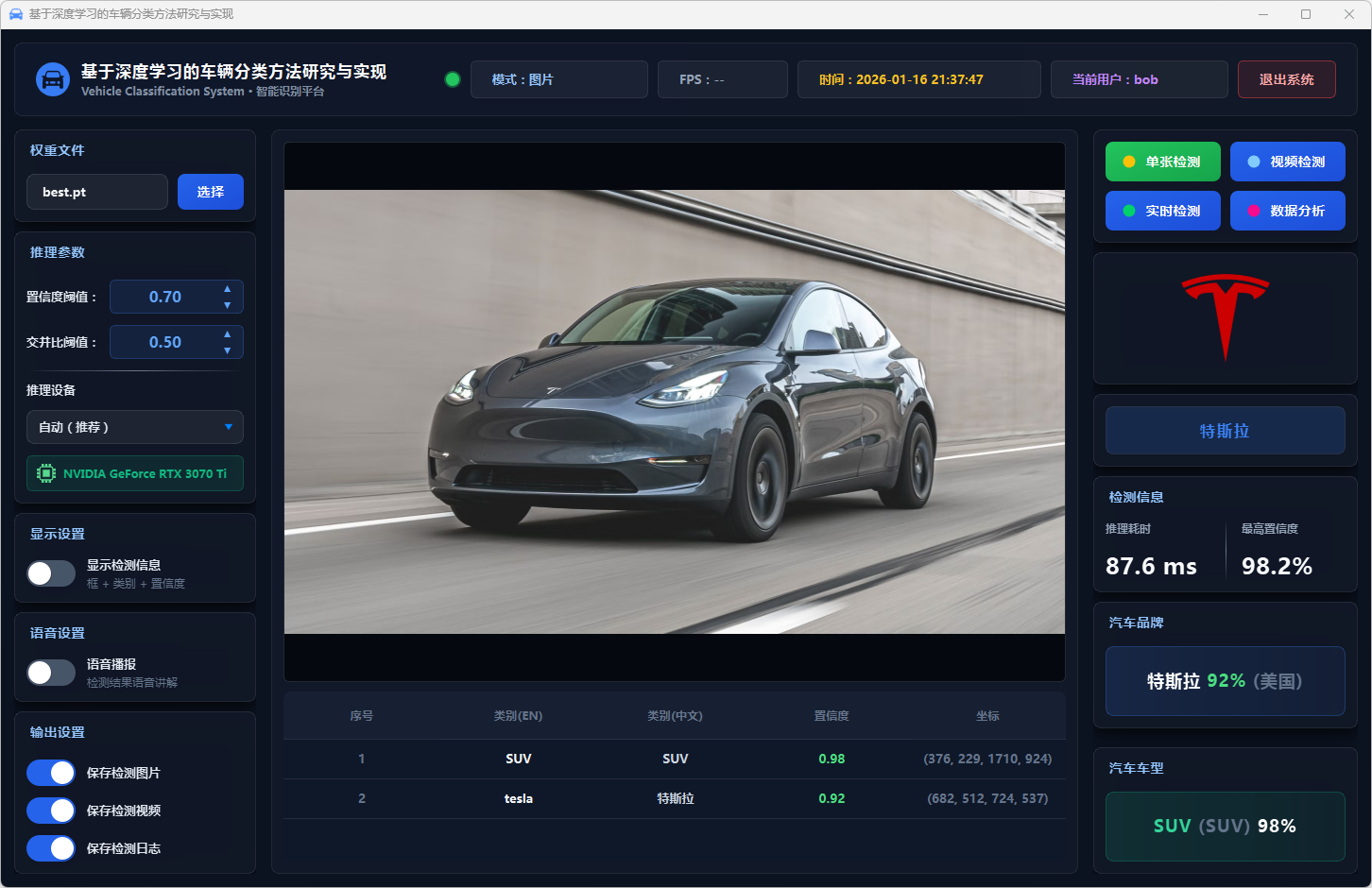
图26 单张检测:特斯拉
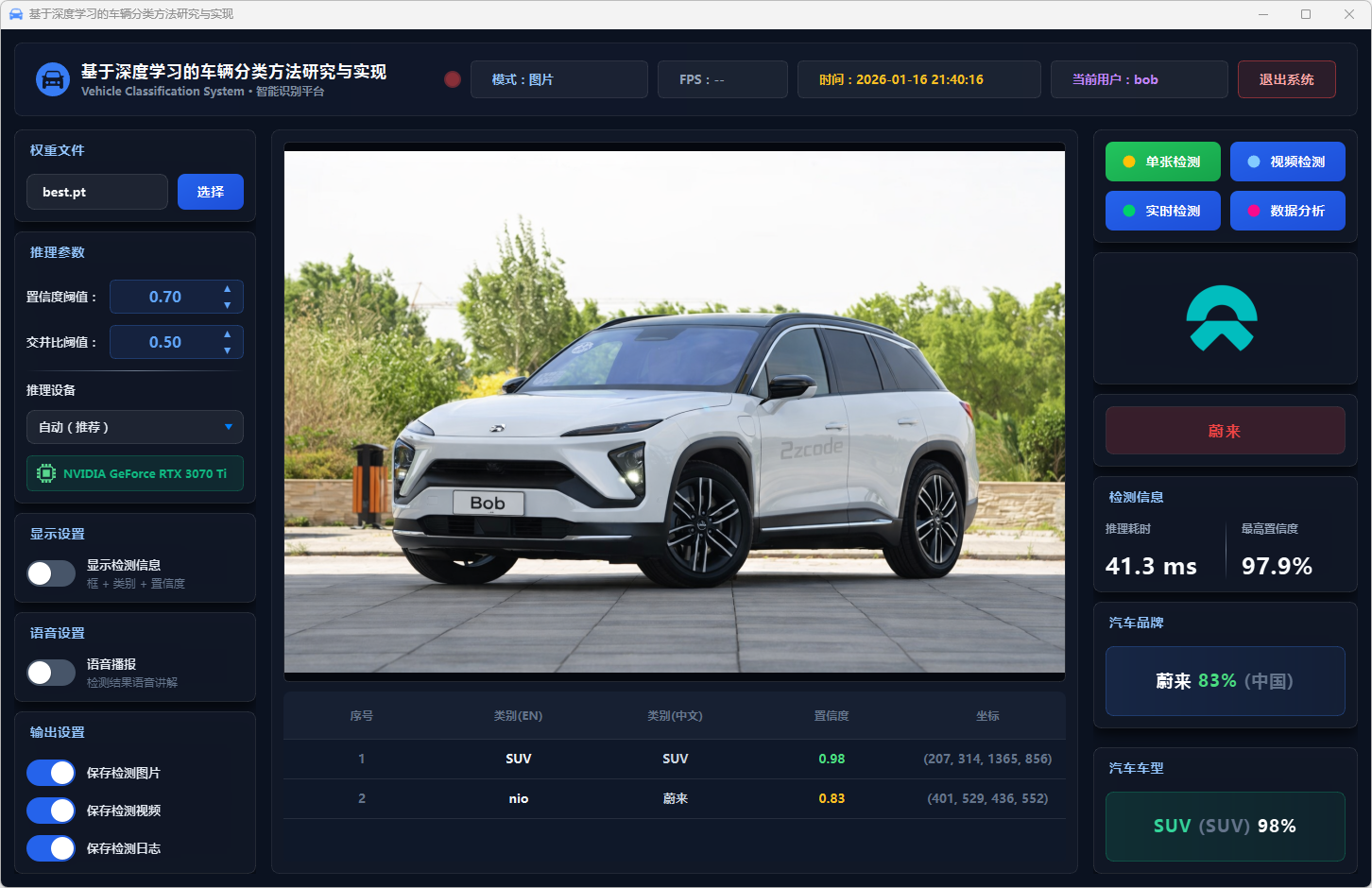
图27 单张检测:蔚来
图28 单张检测:问界
图29 单张检测:沃尔沃
图30 单张检测:小米
图31 单张检测:小鹏
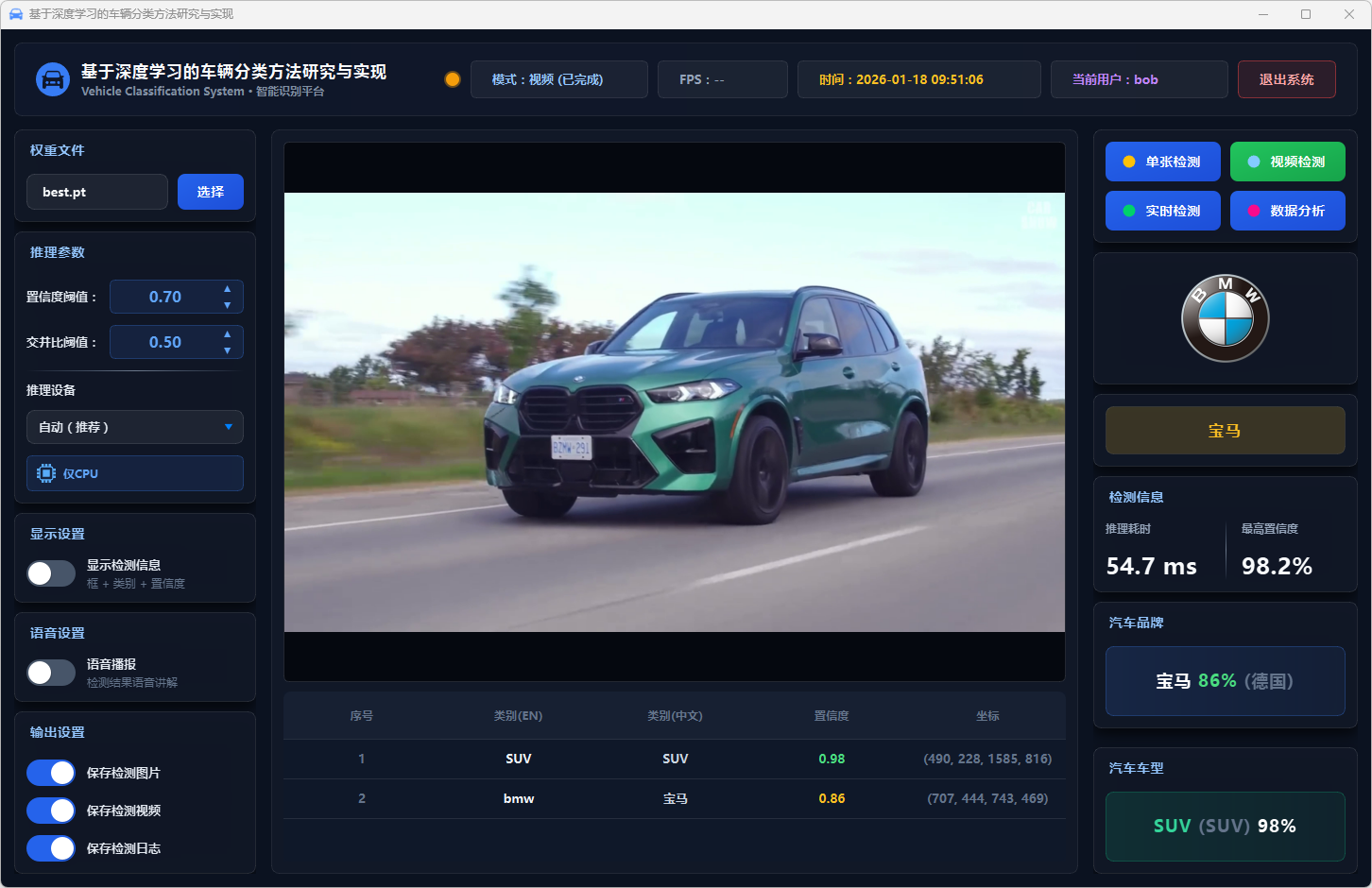
图32 视频检测:宝马
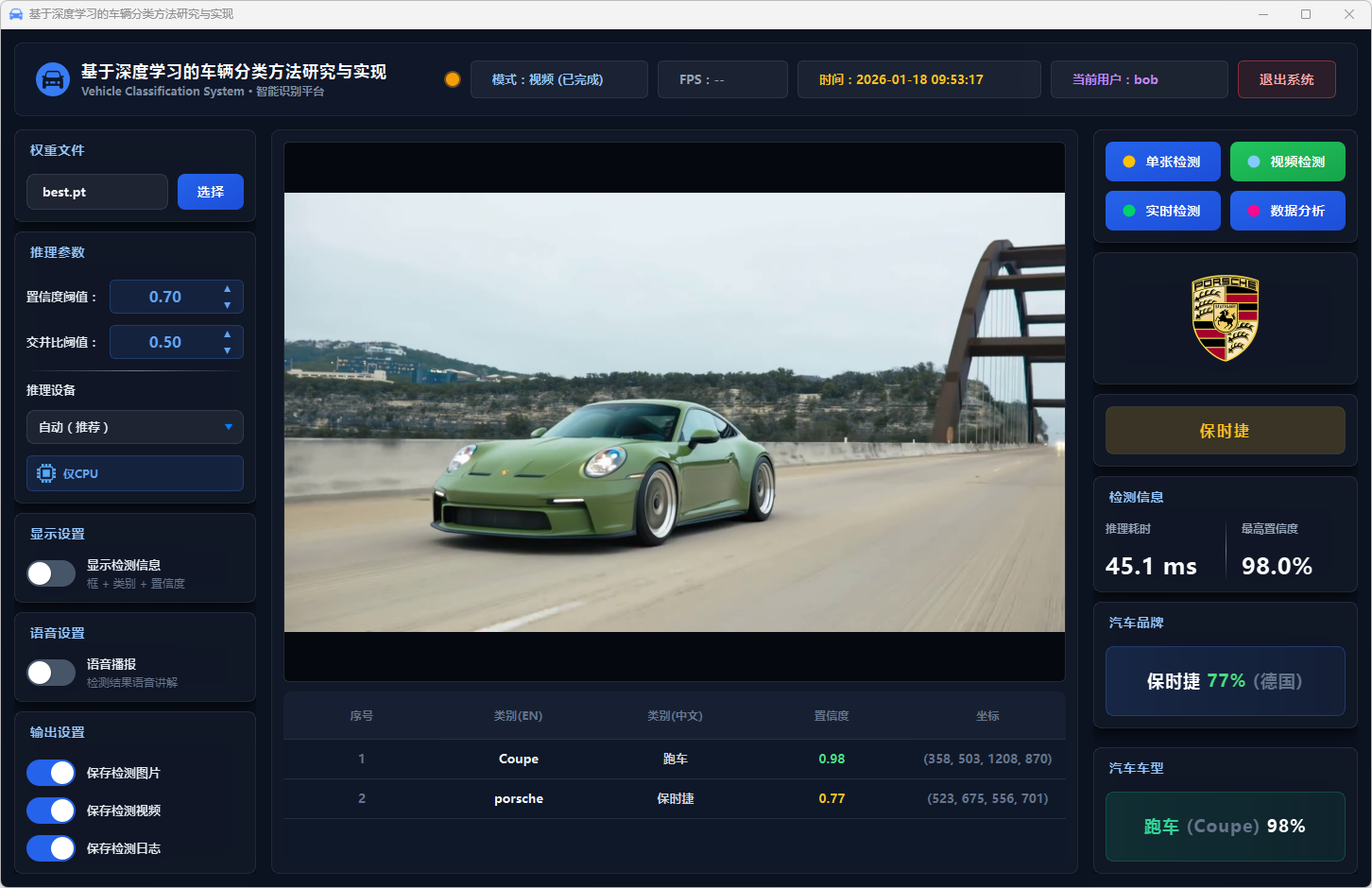
图33 视频检测:保时捷
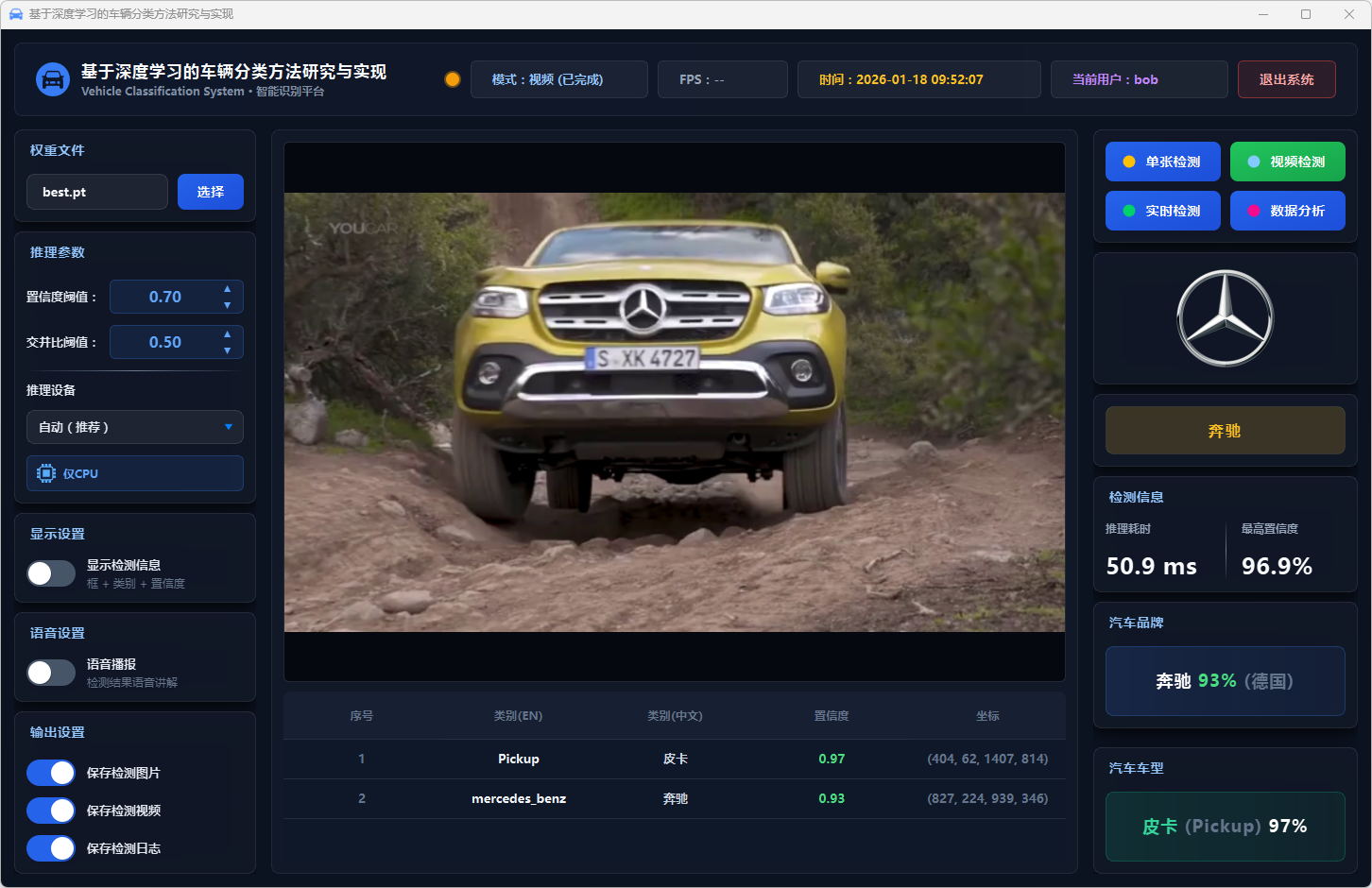
图34 视频检测:奔驰-皮卡
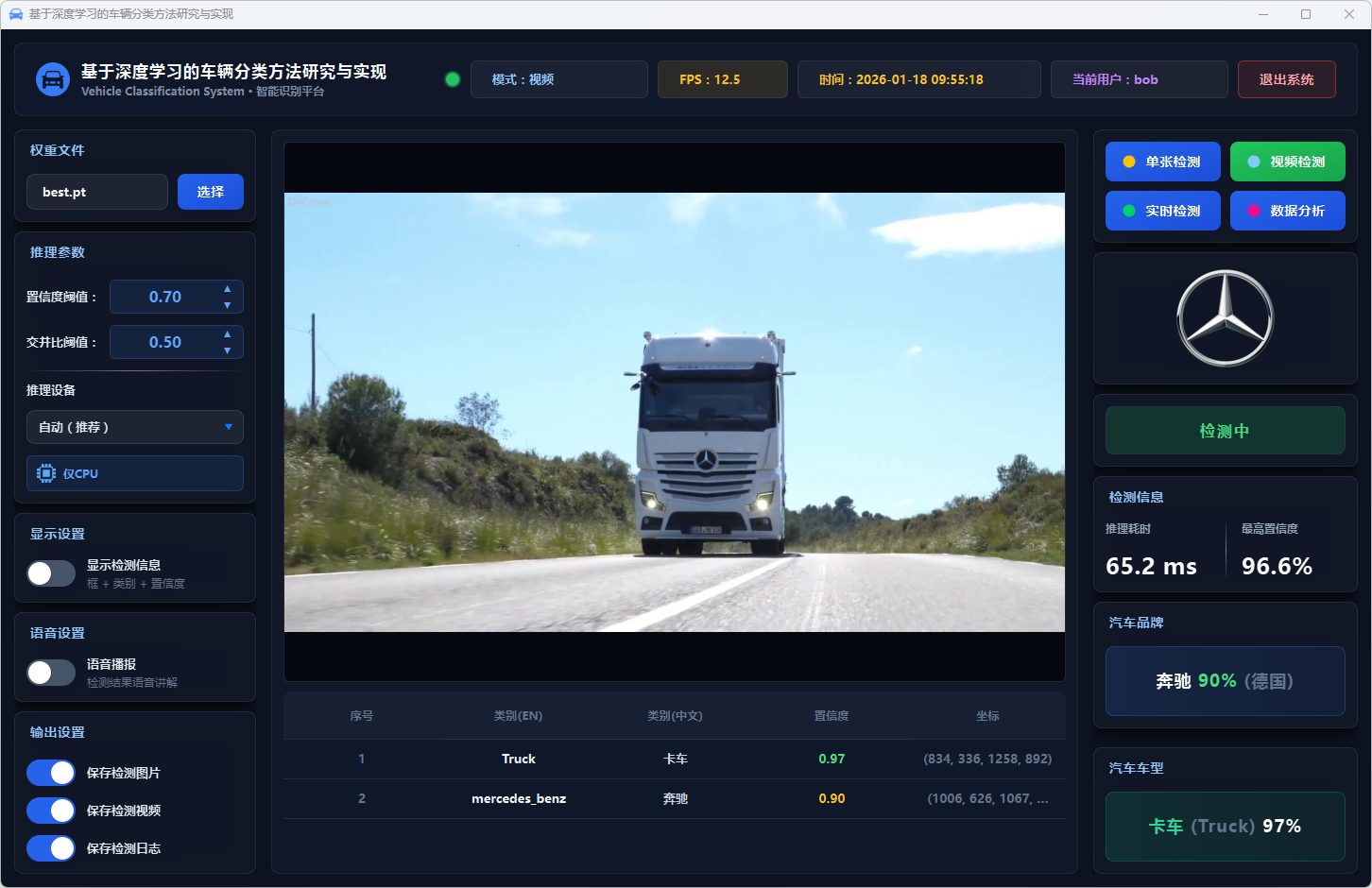
图35 视频检测:奔驰-卡车
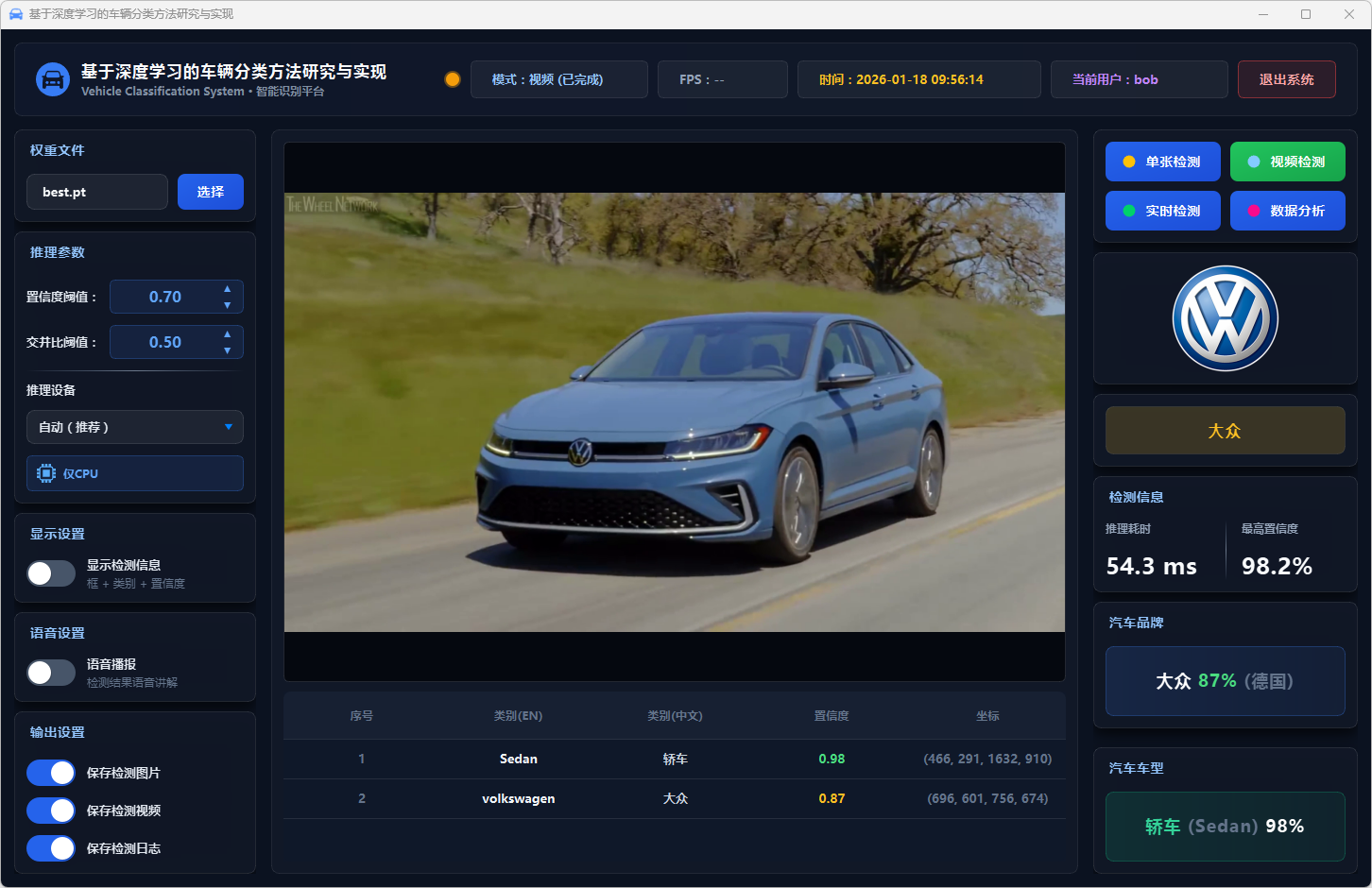
图36 视频检测:大众-轿车
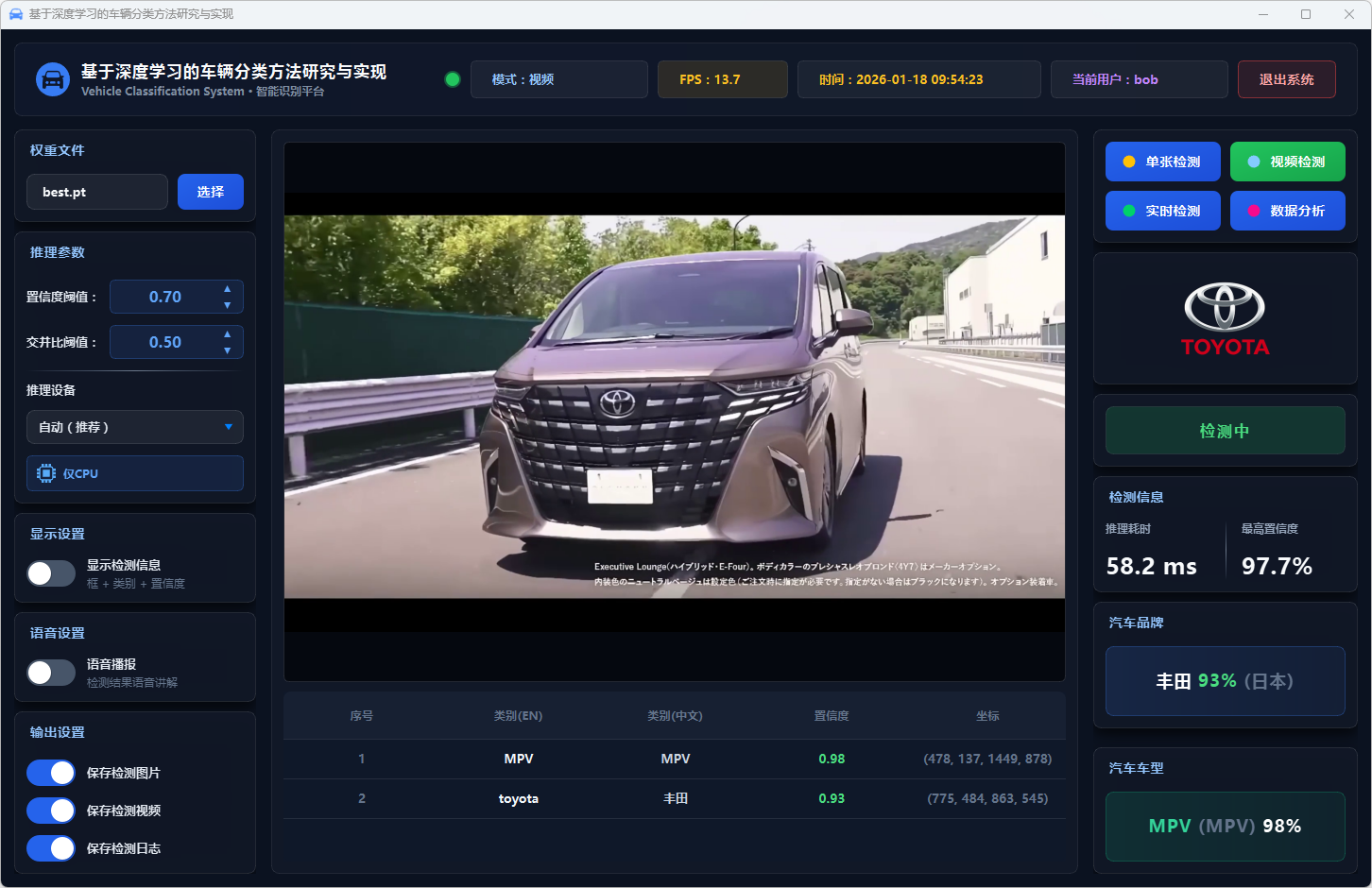
图37 视频检测:丰田-MPV
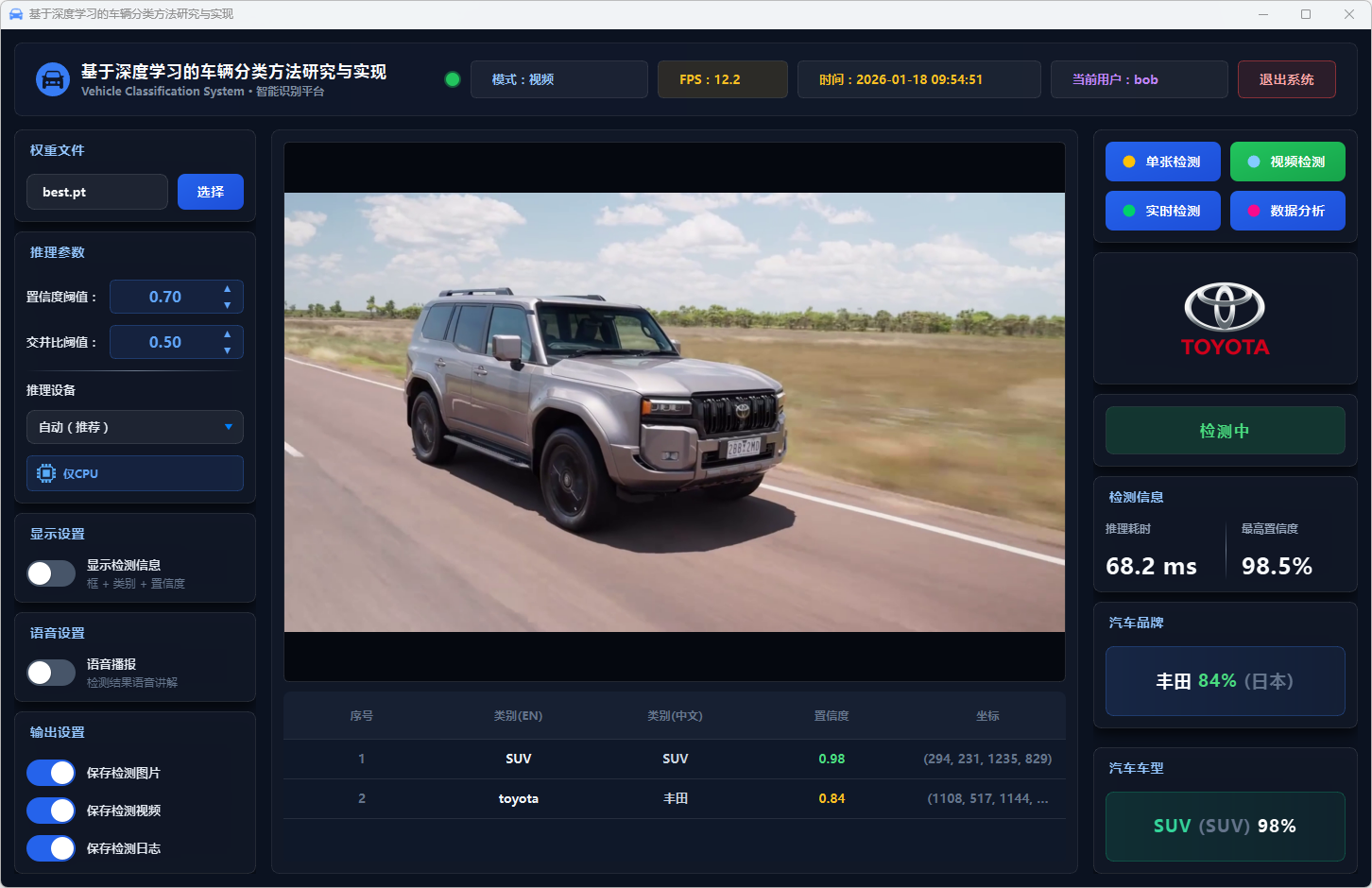
图38 视频检测:丰田-SUV
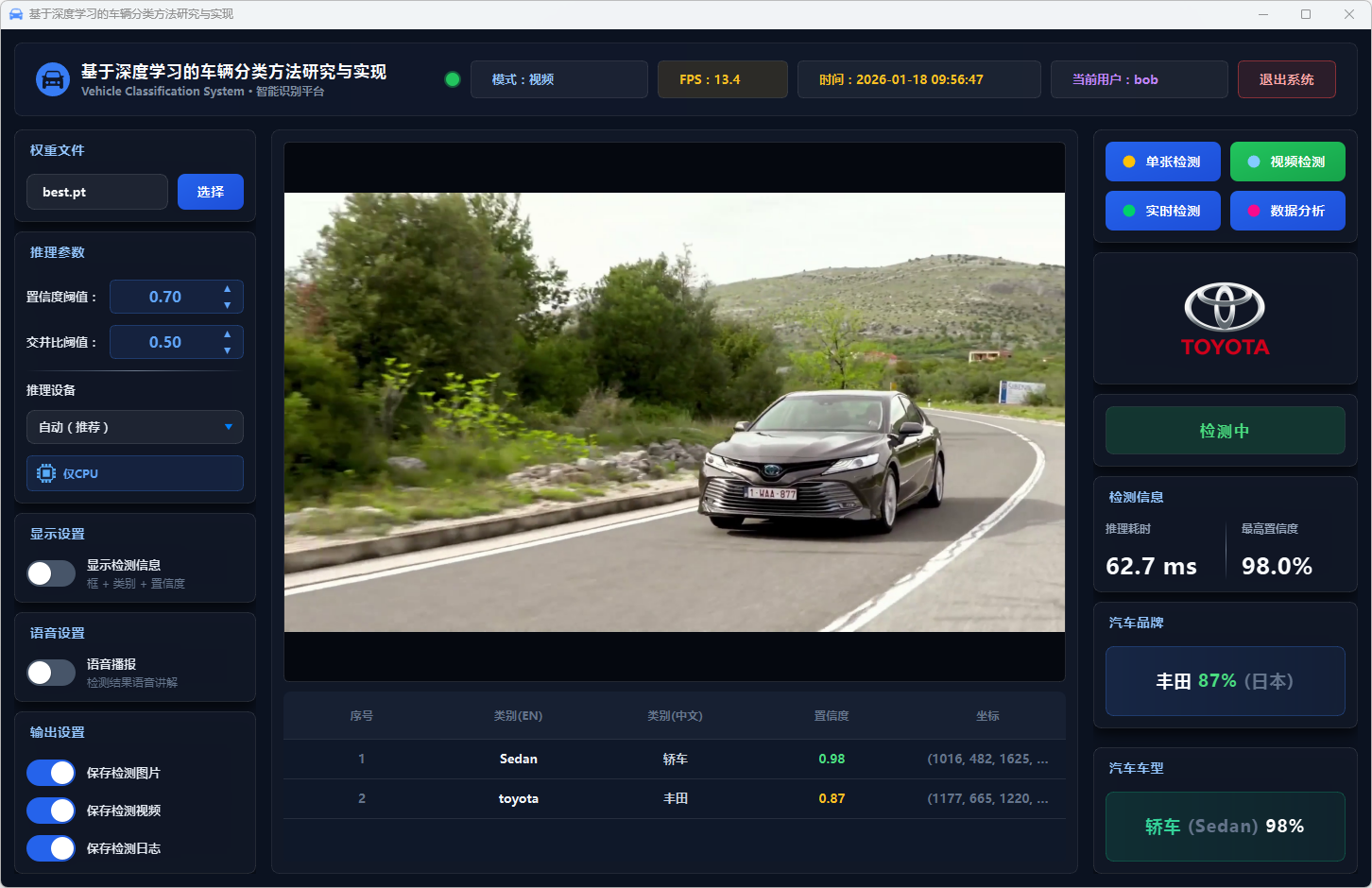
图39 视频检测:丰田-轿车
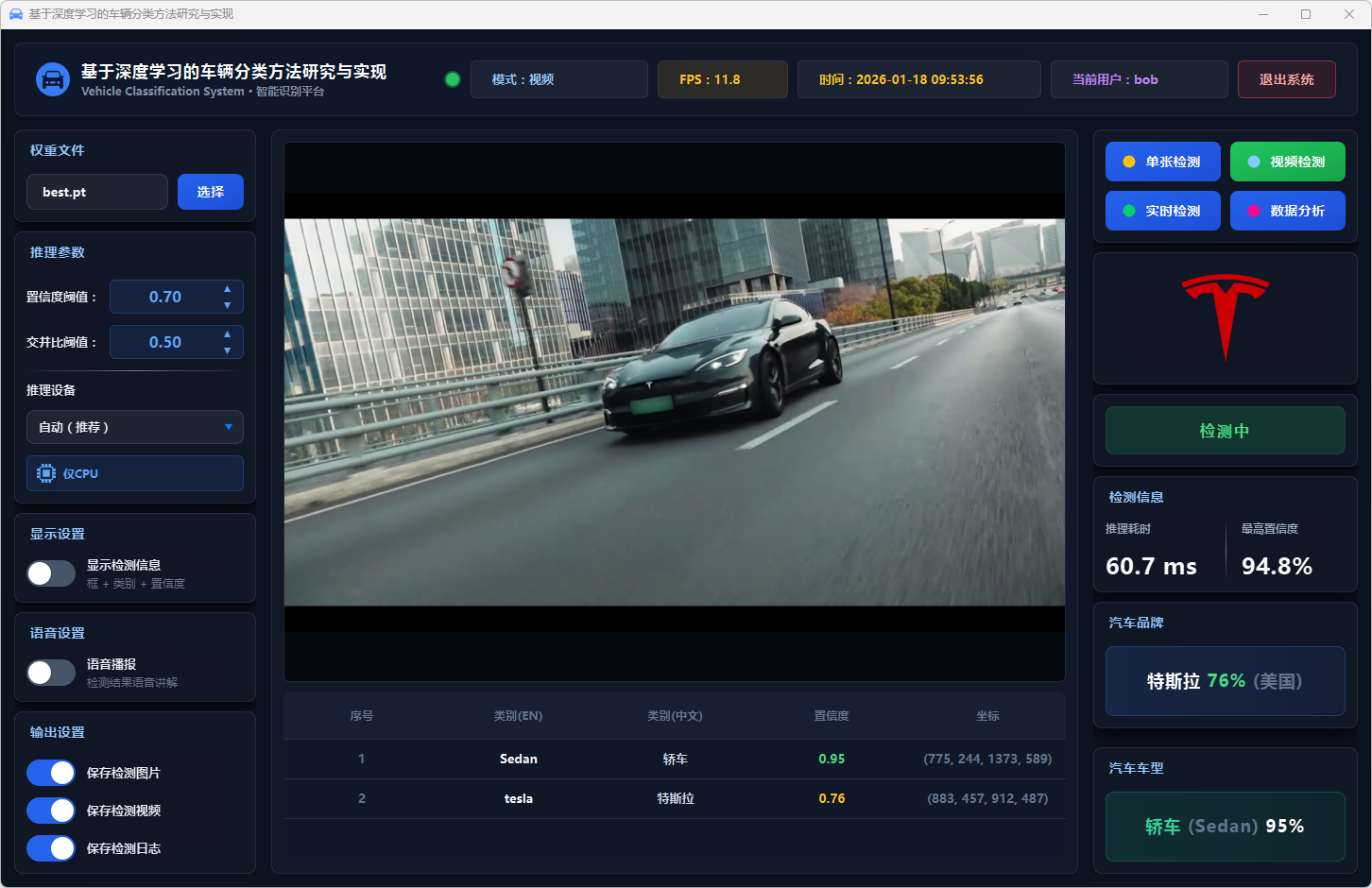
图40 视频检测:特斯拉
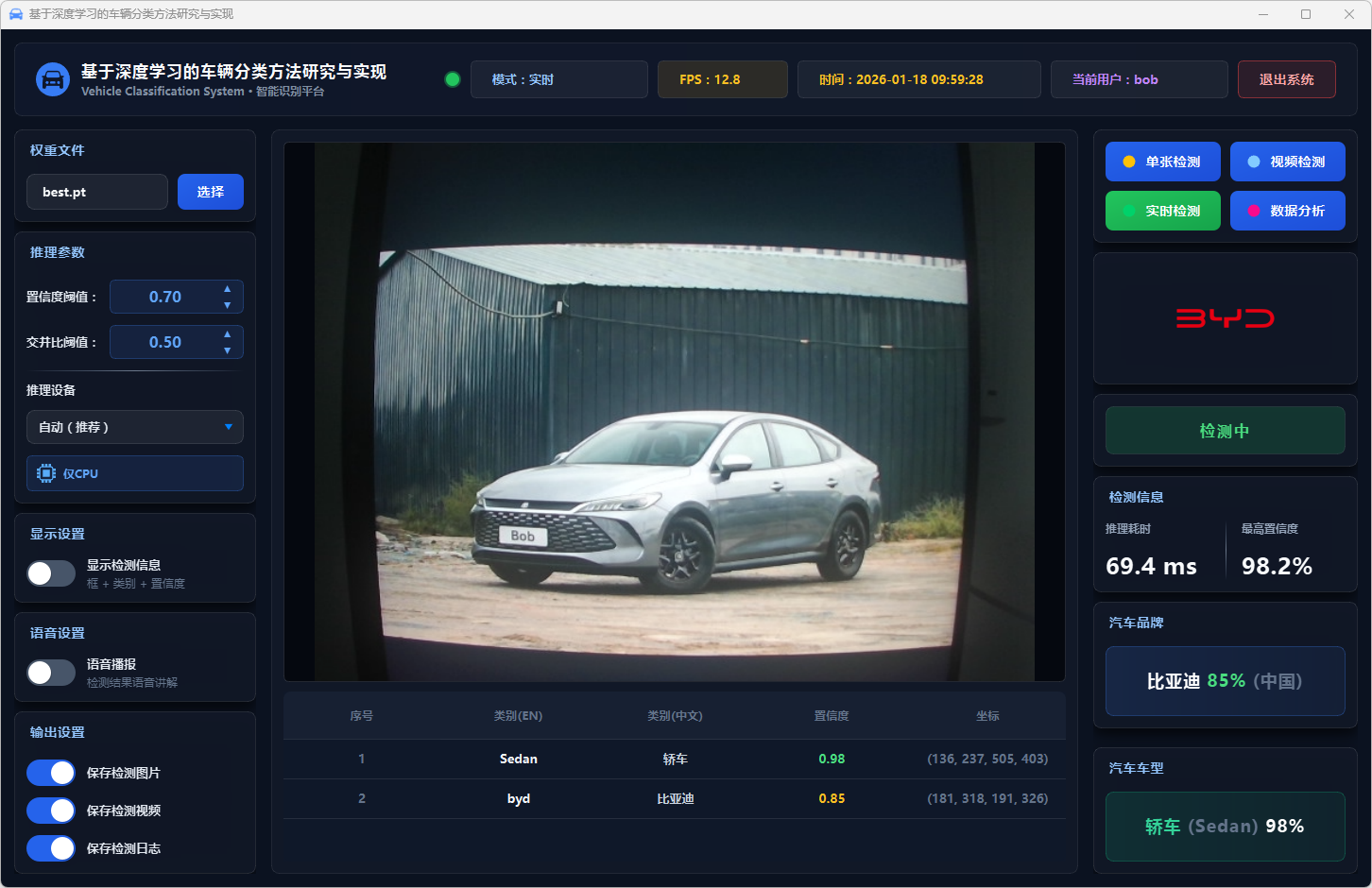
图41 实时检测:比亚迪轿车
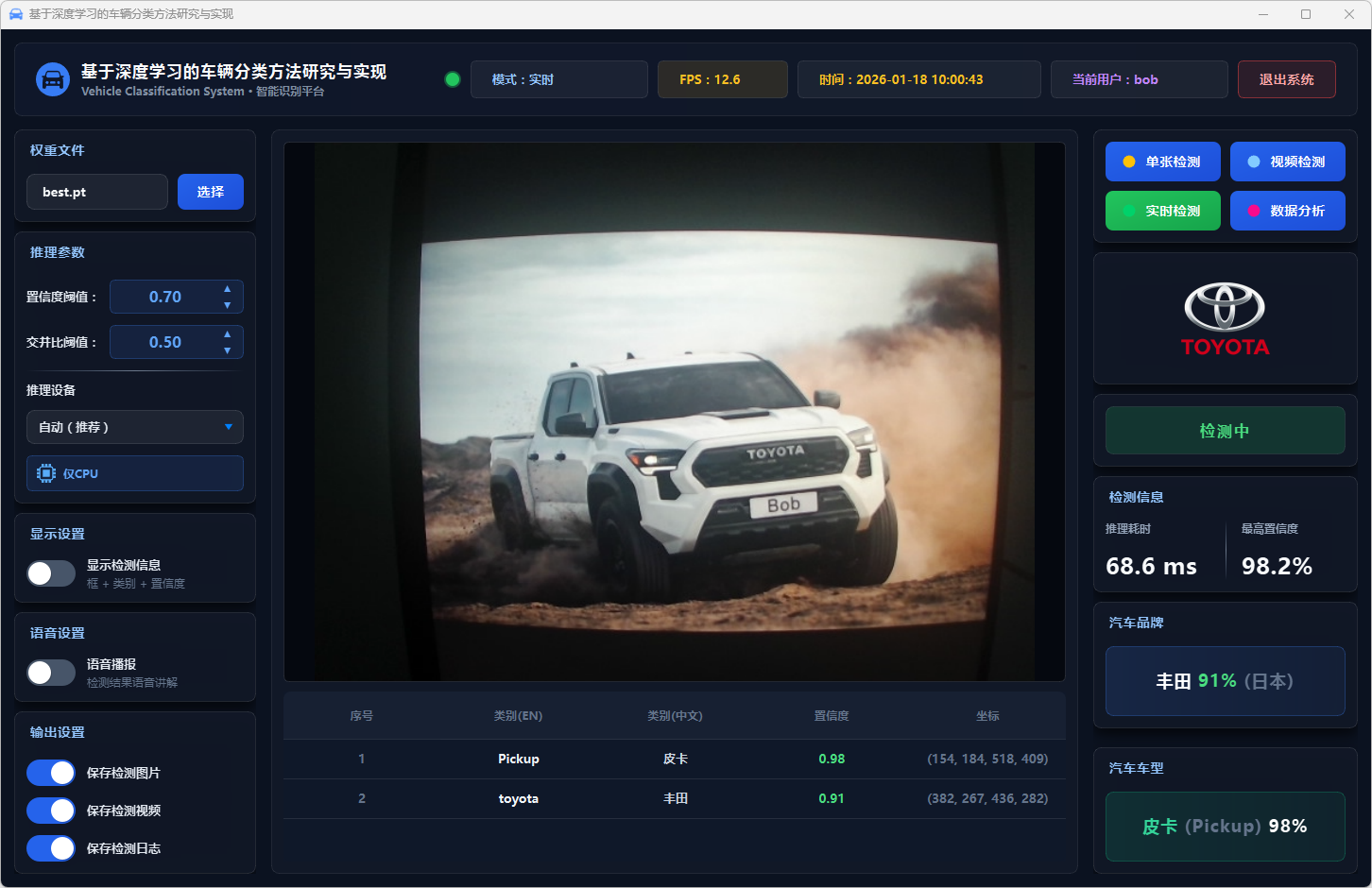
图42 实时检测:丰田皮卡
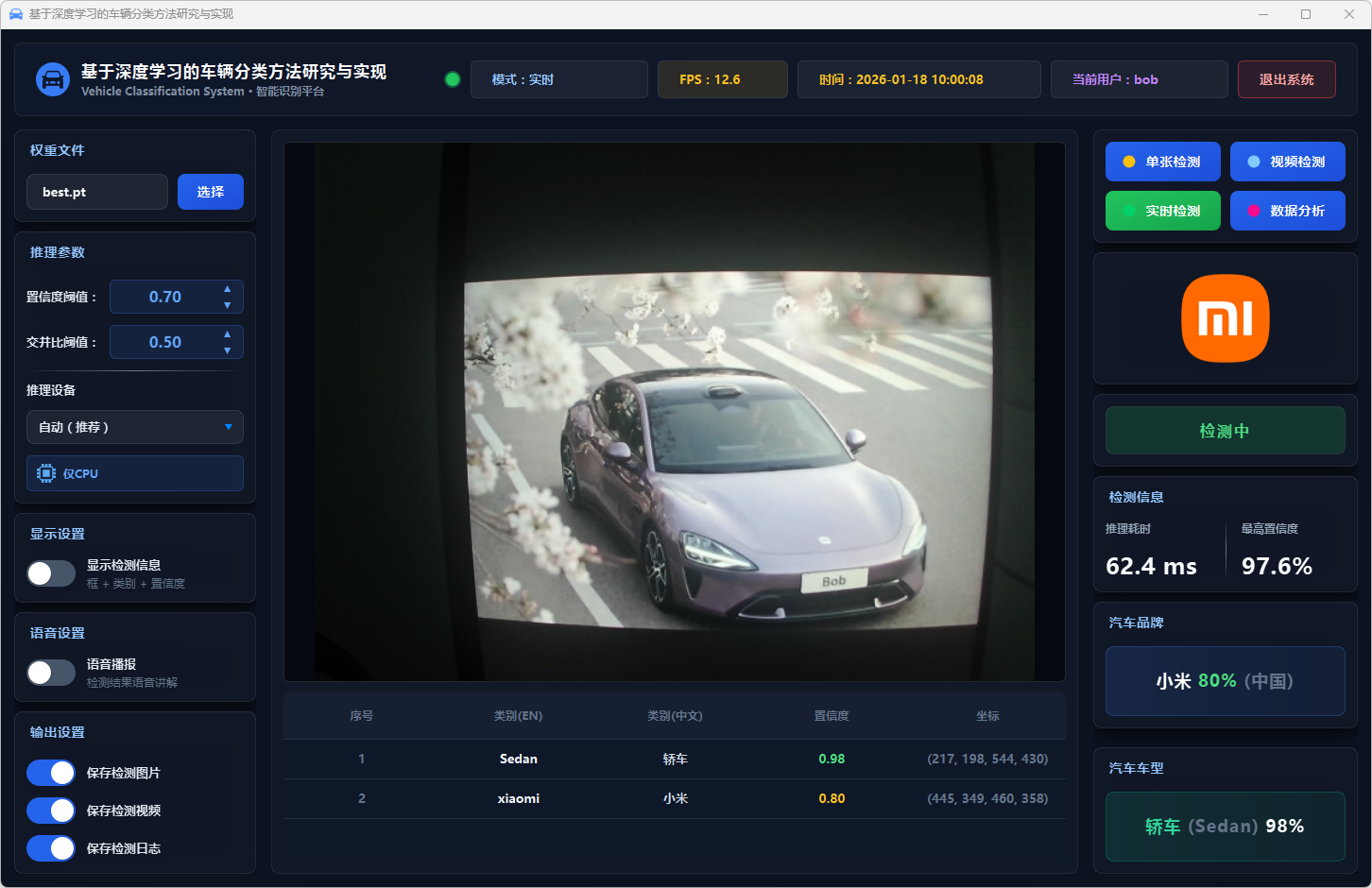
图43 实时检测:小米轿车
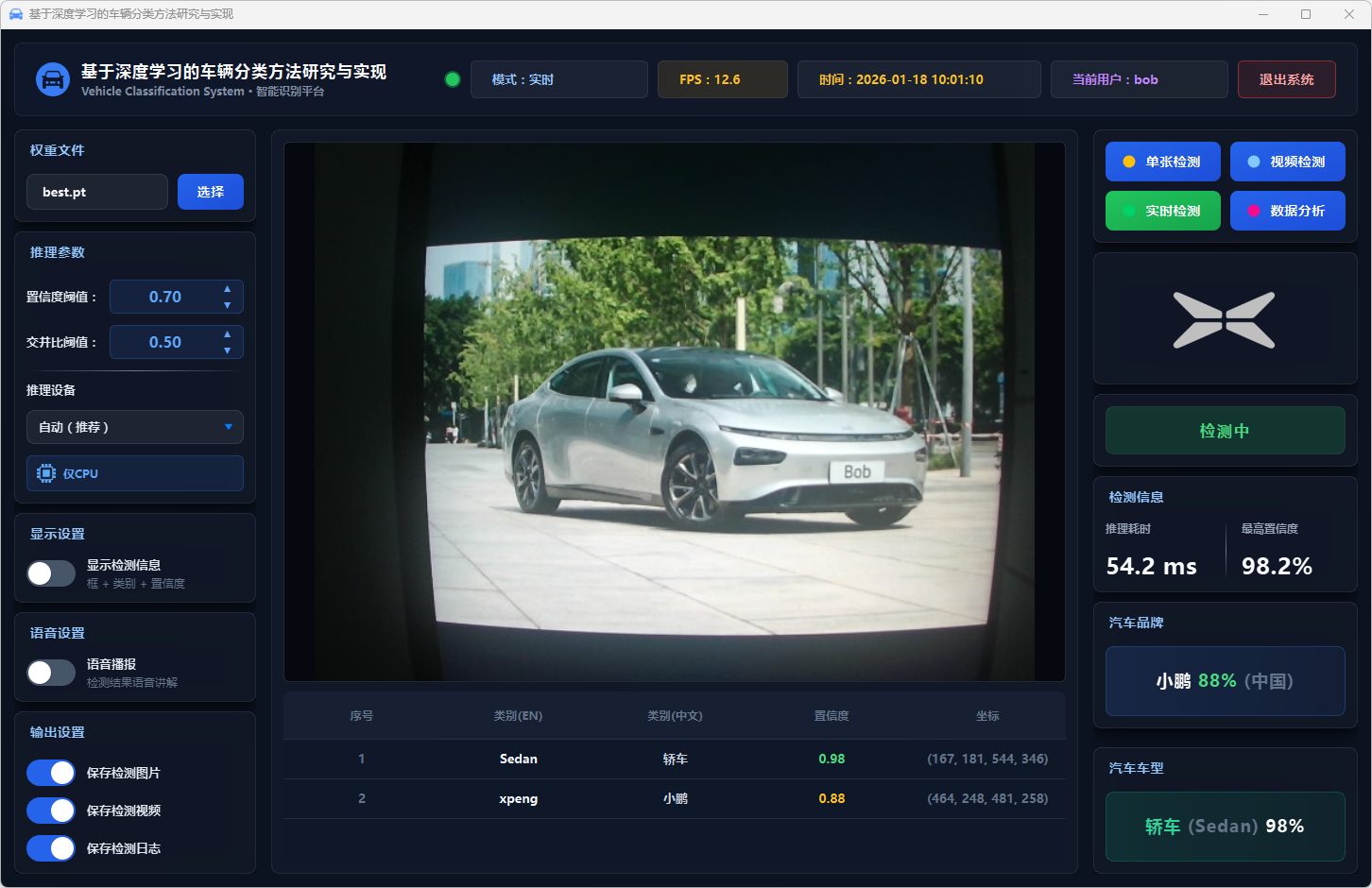
图44 实时检测:小鹏轿车
数据分析模块:
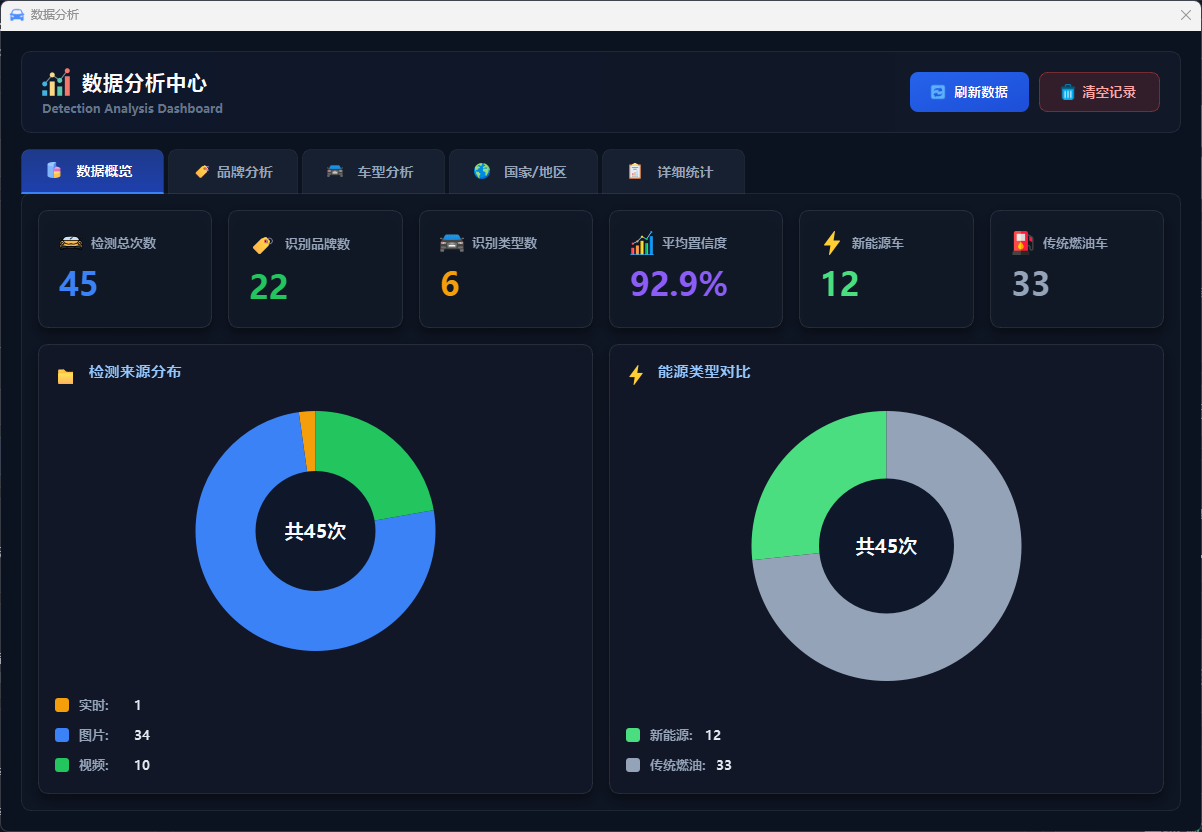
图45 数据分析概览
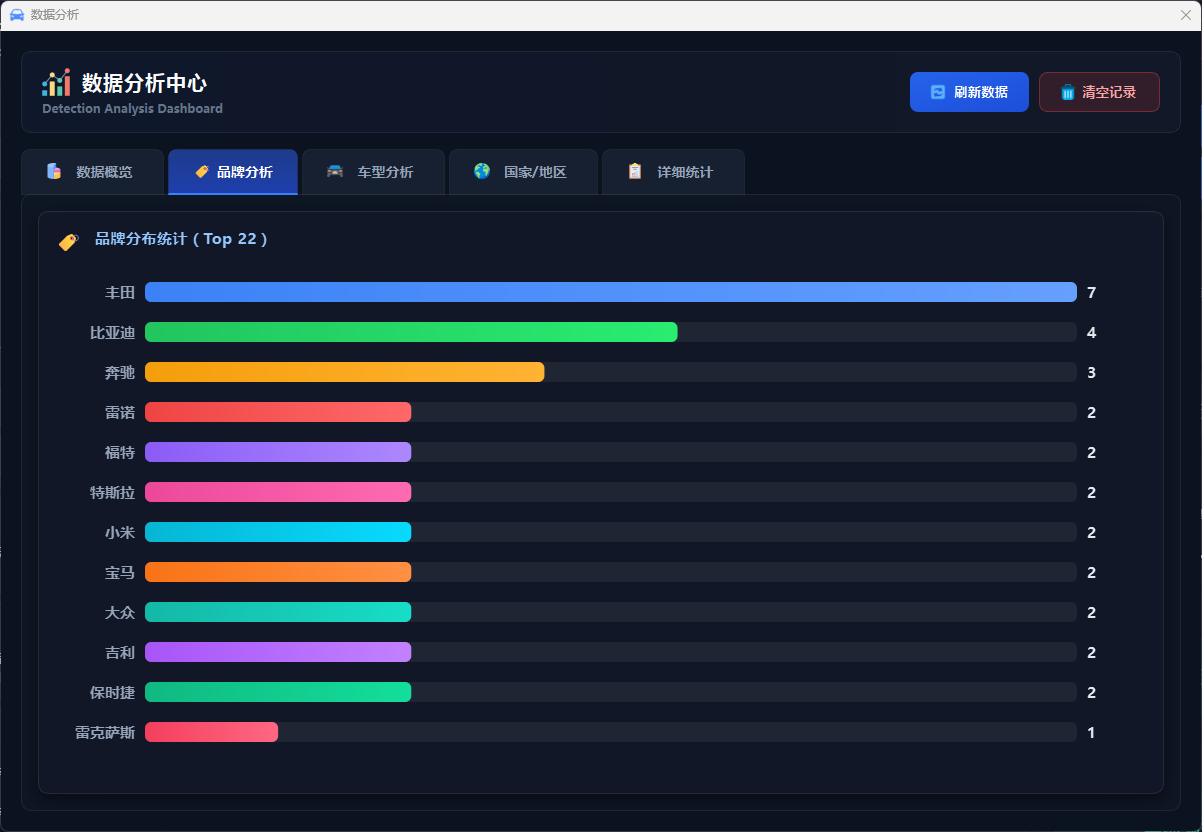
图46 数据分析品牌分析
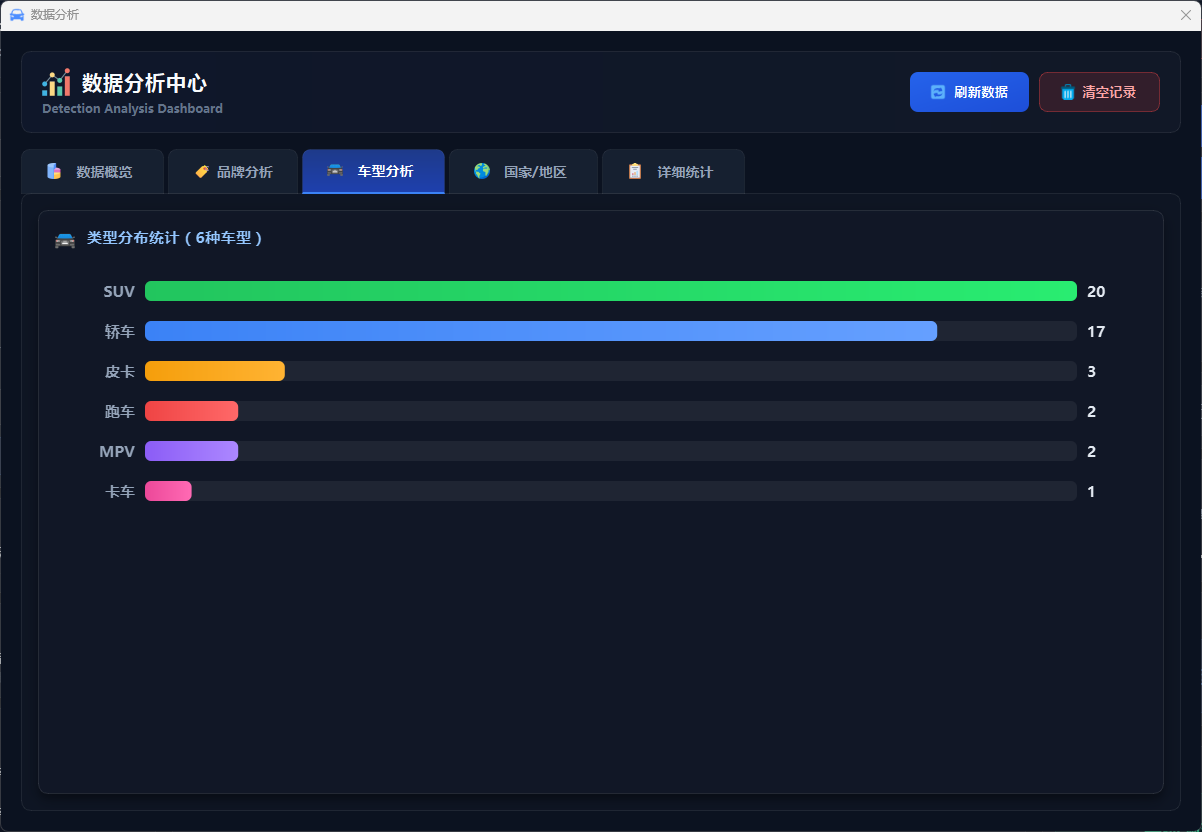
图47 数据分析车型分析
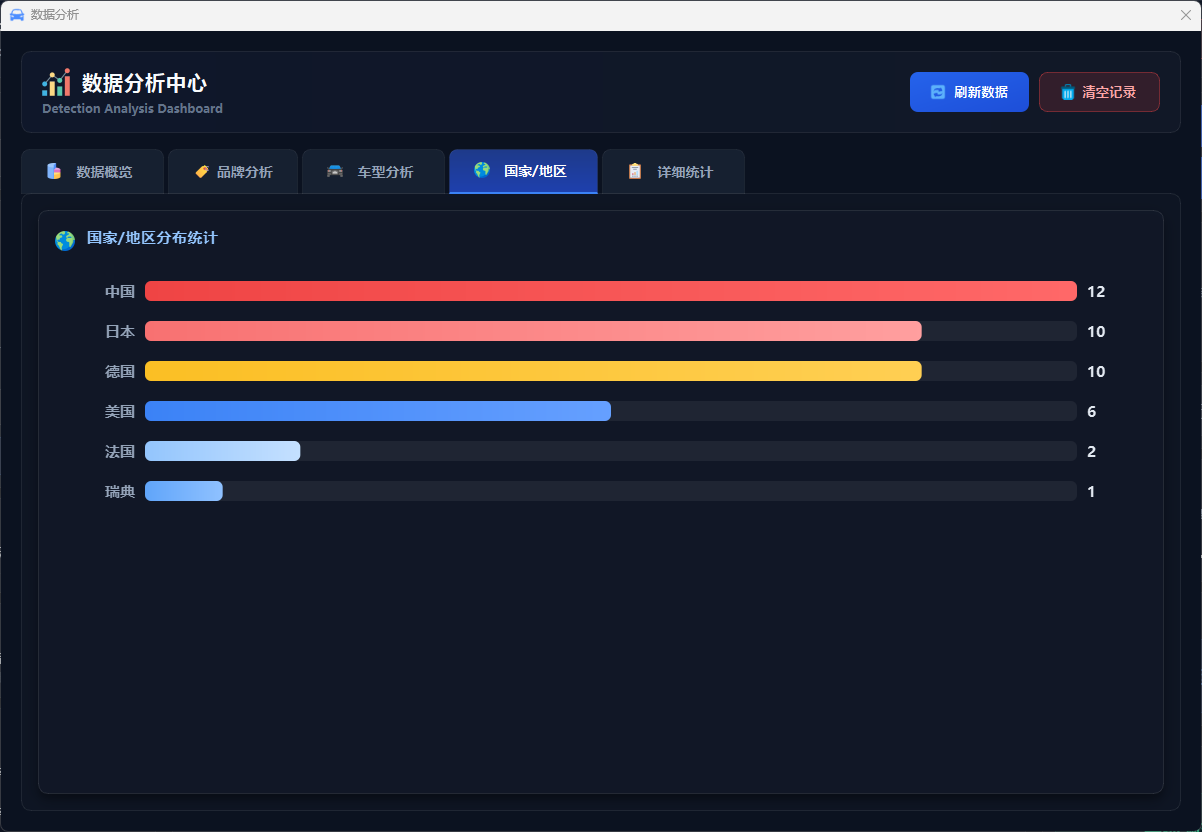
图48 数据分析国家地区分析
图49 数据分析详细统计
图50 数据分析:清空记录
数据集与训练
本章介绍了车辆品牌与类型识别数据集的构建过程、模型训练流程与配置,以及YOLOv11基线模型在验证集上达到98.7%的mAP@0.5和82.3%的mAP@0.5:0.95的优异性能。数据集包含7,029张高质量标注图像(训练集4,920张、验证集1,406张、测试集703张),涵盖28个识别类别(22个车辆品牌和6个车型类别),经过150轮充分训练,模型精确率达98.2%、召回率达97.2%,展现出卓越的识别能力和实用价值。
数据集构建
本研究使用的是车辆品牌与类型识别数据集,该数据集专门针对道路、停车场等场景中的车辆进行品牌和类型标注。数据集包含多种场景下的图像,涵盖室内外不同光照条件、不同拍摄角度和距离,包含22个主流车辆品牌(涵盖中国、德国、日本、美国等国家品牌)和6个车型类别(轿车、轿跑、皮卡、SUV、MPV、卡车),具有较强的场景多样性和实用价值。数据集共包含7,029张高质量标注图像,按照约7:2:1的比例划分为训练集(4,920张)、验证集(1,406张)和测试集(703张),为模型训练和评估提供了充足的数据支撑。
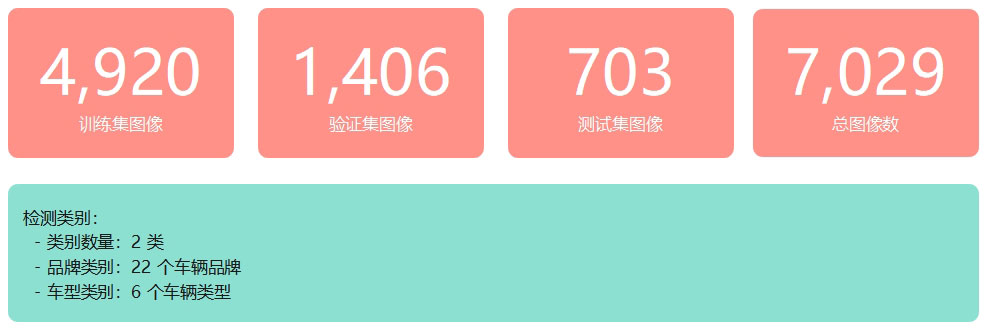
图51 数据集划分及类别信息统计示意图
数据集特点:
本研究使用的是车辆品牌与类型识别数据集,该数据集专门针对道路、停车场等场景中的车辆进行品牌和类型标注。数据集包含多种场景下的图像,涵盖室内外不同光照条件、不同拍摄角度和距离,包含22个主流车辆品牌(涵盖中国、德国、日本、美国等国家品牌)和6个车型类别(轿车、轿跑、皮卡、SUV、MPV、卡车),具有较强的场景多样性和实用价值。数据集共包含7,029张高质量标注图像,按照约7:2:1的比例划分为训练集(4,920张)、验证集(1,406张)和测试集(703张),为模型训练和评估提供了充足的数据支撑。
数据集划分:
数据集按照约 70:20:10 的比例划分为训练集、验证集和测试集:
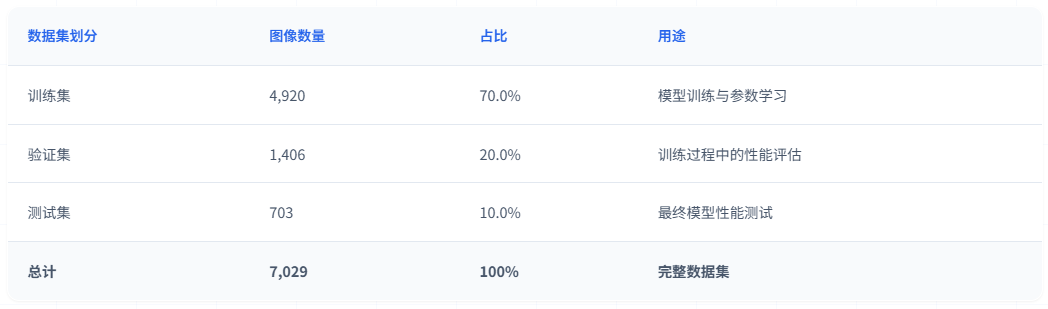
表1 数据集划分及用途说明
训练集用于模型的参数学习和特征提取能力训练。验证集用于训练过程中的性能监控和超参数调优,帮助选择最优模型。测试集用于最终的性能评估,确保模型在未见过的数据上具有良好的泛化能力。
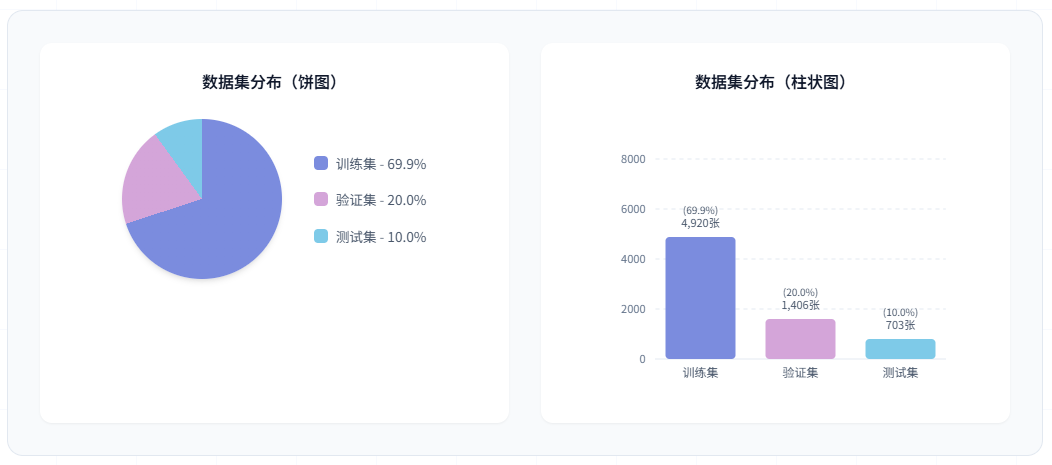
图52 数据集在训练、验证和测试集上的分布
数据预处理:
所有输入图像统一调整为 640×640 分辨率,采用letterbox填充方式保持原始长宽比,避免图像拉伸变形导致车辆特征失真,确保模型能够准确识别车辆品牌和类型特征。
数据增强策略:
训练过程中采用多种数据增强方法提升模型鲁棒性

图53 数据集图像增强方法
Mosaic关闭策略:diyizh在训练的最后 10 个 epoch 关闭 Mosaic 增强(close_mosaic=10),使模型在原始图像分布上精修检测框,提升边界定位精度。这意味着在第1-140轮使用Mosaic数据增强,在第141-150轮使用原始图像进行训练。
数据集质量保证:
为了确保实验数据的可靠性和有效性,本研究的数据集经过严格的质量控制。所有图像均无损坏或无效背景,保证了数据的完整性。标注工作经过多轮人工审核,确保边界框定位精确,类别标注一致且符合定义标准。这些措施有效提升了数据集的质量,为模型训练和性能评估提供了可靠保障。
训练流程
模型训练采用端到端的方式,首先加载训练集和验证集进行数据预处理,然后加载YOLOv11预训练权重进行模型初始化,接着使用SGD优化器进行150轮迭代训练,每轮训练后在验证集上评估性能指标,系统自动保存验证集上性能最佳的模型权重,最终输出完整的性能指标和训练曲线。
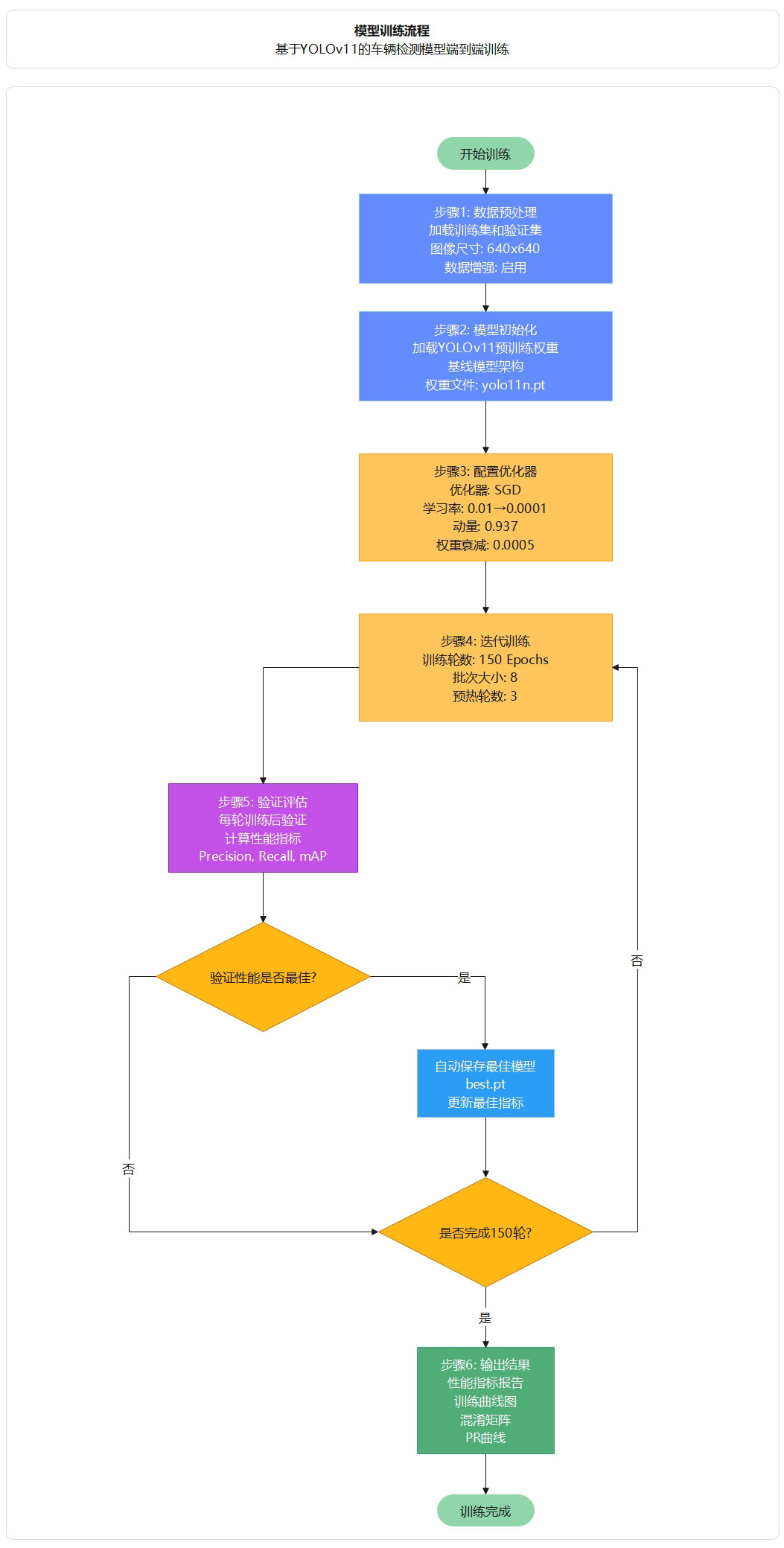
图54 模型训练流程
训练流程:
-
开始训练 → 加载训练集和验证集进行数据预处理
-
模型初始化 → 加载YOLOv11预训练权重(yolo11n.pt),使用标准YOLOv11架构
-
模型训练 → 使用SGD优化器进行150轮迭代训练,应用数据增强技术
-
模型验证 → 每轮训练后在验证集上评估性能指标(Precision, Recall, mAP@0.5, mAP@0.5:0.95)
-
最佳模型保存 → 系统自动监控验证性能,保存验证集上性能最佳的模型权重(best.pt)
-
训练完成 → 输出完整的性能指标报告和训练曲线图
训练配置
硬件环境:

软件环境

训练超参数

数据增强策略
为提高模型泛化能力,训练过程中采用以下数据增强方法:Mosaic增强将4张图像拼接成一张以增加小目标检测能力;随机翻转以50%的概率对图像进行水平翻转;随机缩放在0.5-1.5倍范围内调整图像尺寸;色彩抖动在HSV色彩空间进行随机调整,其中色调(Hue)调整范围为±0.015、饱和度(Saturation)为±0.7、明度(Value)为±0.4;随机平移在±10%范围内对图像进行位置偏移。
学习率调度策略
学习率调度策略采用线性衰减方式,前3个epoch进行warmup预热,学习率从0线性增长到初始学习率0.01,之后按线性方式从0.01逐步衰减到最终学习率0.0001。
训练结果
性能指标:
经过150轮训练,YOLO11n 基线模型在车辆检测验证集上取得了优异的性能:
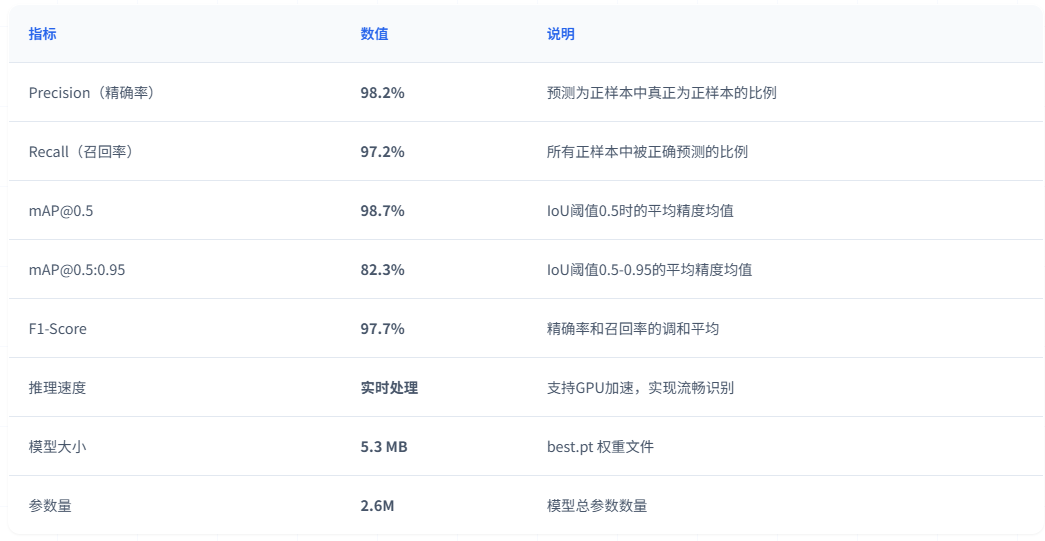
训练曲线分析:
下图展示了模型在150轮训练过程中的完整性能变化,包括损失函数曲线和精度指标曲线:
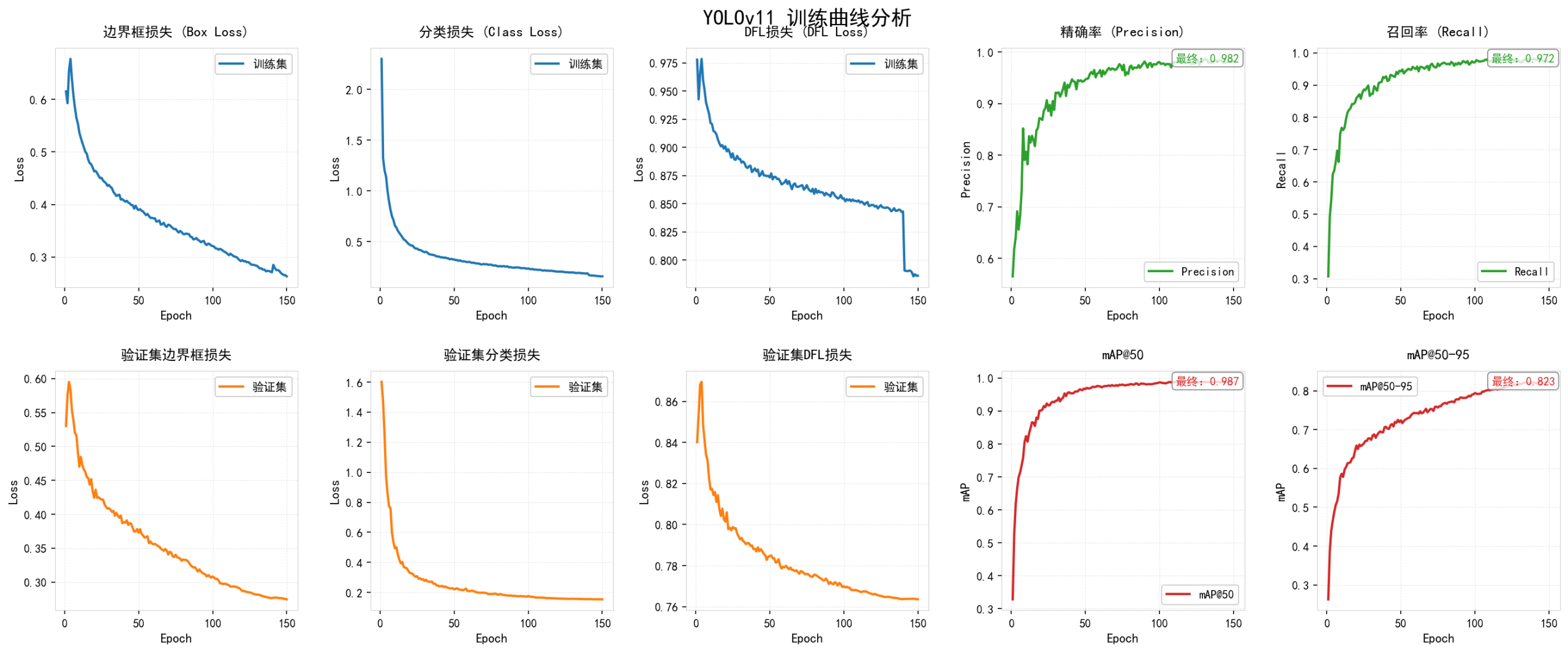
图55 训练曲线分析
图中展示了10个关键指标的训练过程:训练损失(box/cls/dfl)、验证损失(box/cls/dfl)、精确率、召回率、mAP@50和mAP@50-95
(1)损失函数曲线
训练过程中各项损失函数呈现稳定下降趋势。训练集边界框损失(train/box_loss)从初始的0.62快速下降,经过前3轮学习率预热后加速收敛,在第50轮后趋于稳定,最终收敛至约0.26;训练集分类损失(train/cls_loss)从初始的2.30快速下降,在第30轮后基本稳定在0.20左右,最终收敛至0.16,表明模型分类能力持续提升;训练集DFL损失(train/dfl_loss)从初始的0.98稳步下降至约0.79,分布焦点损失的降低反映了边界框预测精度的提高。验证集损失方面,验证集的box_loss从0.53降至0.27,cls_loss从1.60降至0.15,dfl_loss从0.84降至0.76,均呈现与训练集相似的下降趋势,且曲线平滑无明显波动,表明模型具有良好的泛化能力,未出现过拟合现象。
(2)精度指标曲线
模型性能指标在训练过程中持续提升。Precision(精确率)曲线从初始的56.5%快速上升,在第20轮达到87.1%,在第50轮达到94.7%,随后继续稳步提升,最终稳定在98.2%的高水平;Recall(召回率)曲线从初始的30.7%稳步提升,在第20轮达到86.0%,在第50轮达到94.3%,最终达到97.2%,表明模型对目标的检测能力优异;mAP@50指标从初始的32.8%快速上升,在第20轮达到90.2%,在第50轮达到96.8%,最终稳定在98.7%,显示模型在IoU阈值为0.5时具有极高的检测精度;mAP@50-95指标从初始的26.3%持续上升,在第20轮达到65.9%,在第50轮达到72.4%,在整个150轮训练过程中保持稳定增长态势,最终达到82.3%,表明模型在严格的IoU阈值范围(0.5至0.95)下仍能保持优异的检测性能,证明了模型定位精度的准确性。
(3)Precision-Recall 曲线
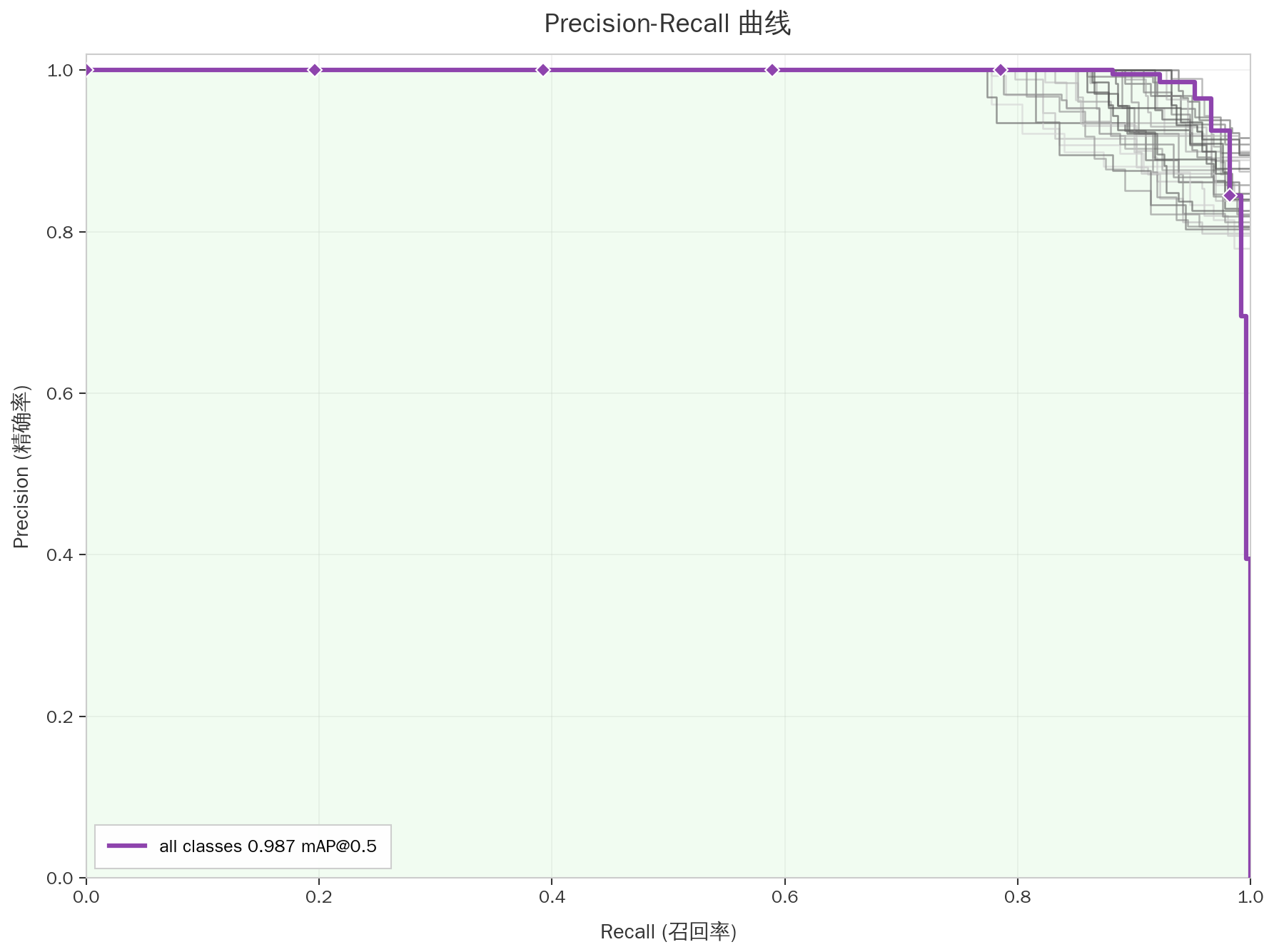
图56 Precision-Recall 曲线
展示模型在不同置信度阈值下的精确率和召回率关系,all classes mAP@0.5达到0.995
(4)混淆矩阵(归一化)
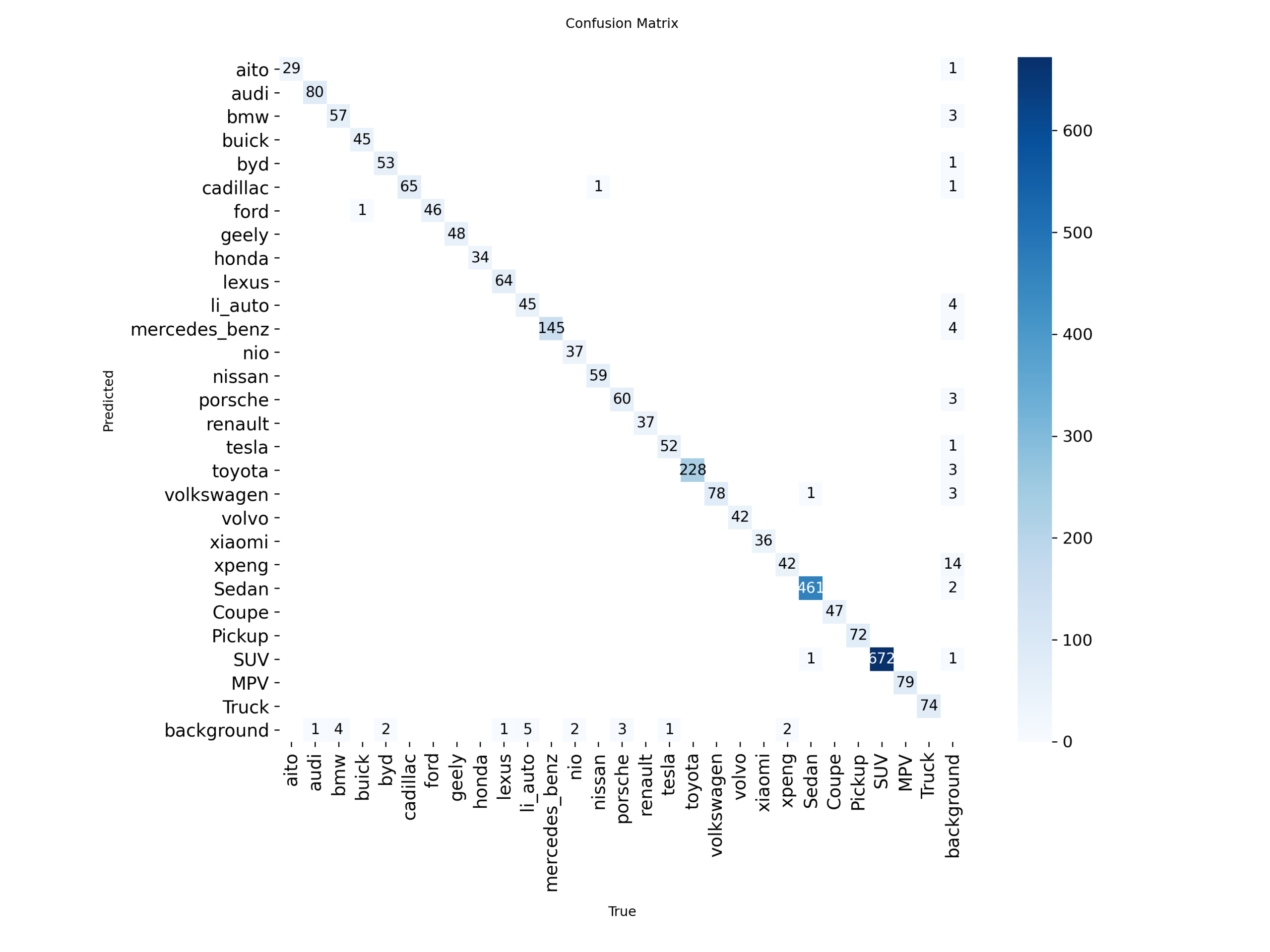
图57 归一化混淆矩阵
归一化混淆矩阵展示模型的分类准确性
最佳模型选择
训练过程中,系统自动保存验证集上性能最佳的模型,最佳模型出现在第150轮,保存路径为runs/train/yolo11/weights/best.pt,选择标准为验证集mAP@50:0.95指标最高。
训练稳定性分析
- 收敛速度:模型在前20轮快速收敛,第20-100轮稳定提升,第100-150轮精细调优
- 过拟合控制:训练集和验证集损失曲线走势一致,三类损失函数均平稳下降,无明显过拟合现象
- 训练稳定性:损失曲线平滑无剧烈波动,学习率逐步衰减,训练过程稳定可控
- 最终状态:模型在第150轮达到最佳性能,mAP50-95达到82.3%,训练过程稳定收敛
项目资源
我们提供项目的完整技术资源,包括源代码、训练脚本、配置文件、数据集和模型权重等全部内容。代码采用模块化设计,结构清晰,注释完善,支持完全复现论文中的所有实验结果。项目提供详细的文件清单和技术架构说明(网页已经提供),帮助用户快速理解项目结构,便于二次开发和功能扩展。所有资源均已开源,遵循AGPL-3.0协议,用户可自由使用、修改和分发。

关于项目
本项目基于YOLO11n目标检测算法,实现了对车辆类型与品牌的高精度智能检测。模型采用标准的YOLO11n (Nano)架构,在自定义28类车辆数据集上经过150轮训练,在验证集上达到98.7%的mAP@50和82.3%的mAP@50:0.95,同时保持了轻量级特性(模型大小仅5.3MB,参数量2.6M),为智能交通和车辆管理提供了高效的技术支持。
项目背景
随着智能交通系统的快速发展,车辆类型与品牌的精准识别成为交通管理、停车管理、车辆统计等应用场景的核心需求。传统的人工识别方式效率低下、成本高昂,难以满足海量车辆数据的实时处理需求。近年来,深度学习技术在目标检测领域取得突破性进展,为解决这一问题提供了新思路。本项目立足于实际应用需求,针对复杂交通场景下的车辆类型与品牌识别难题,采用基于YOLO11n的轻量级智能检测方案,旨在通过技术手段提升交通管理的智能化水平,降低管理成本,提高车辆识别的准确性和实时性。
作者信息
作者:Bob (张家梁)