第 3 篇:服务编排与自启动------把 Mac 变成"稳定可运维"的家庭 AI 机房
-
- [1)在 Mac 上的运行形态:三类服务,三种"最稳姿势"](#1)在 Mac 上的运行形态:三类服务,三种“最稳姿势”)
- 2)进程治理:端口、日志、健康检查,三件事必须标准化
-
- [2.1 端口治理:从一开始就做"端口表"](#2.1 端口治理:从一开始就做“端口表”)
- [2.2 日志治理:不要靠"终端窗口记忆"](#2.2 日志治理:不要靠“终端窗口记忆”)
- [2.3 健康检查:用"可机器读"的 /healthz](#2.3 健康检查:用“可机器读”的 /healthz)
- [3)在 macOS 上实现"自启动":用 launchd 做生产级托管](#3)在 macOS 上实现“自启动”:用 launchd 做生产级托管)
- [4)更新策略:灰度 + 回滚的最低配置(不搞花活也能稳)](#4)更新策略:灰度 + 回滚的最低配置(不搞花活也能稳))
-
- [4.1 最低成本灰度:双端口 + 反向代理切流](#4.1 最低成本灰度:双端口 + 反向代理切流)
- [4.2 最低配置回滚清单(建议你写成"强制执行")](#4.2 最低配置回滚清单(建议你写成“强制执行”))
- 5)少量伪代码:把"编排思路"抽象成可执行逻辑
- 6)风险点与踩坑清单(建议读者直接收藏)
- [7)本章行动项(你可以按这 7 步直接落地)](#7)本章行动项(你可以按这 7 步直接落地))
- 评论区互动(我想收集你们的真实环境参数)
- 下一章
如果第 1 篇解决"为什么选 Mac M2 Ultra",第 2 篇解决"资产怎么存",那这一篇解决的是最关键的一步:让 ComfyUI、RAG API、面板服务在 Mac 上像"生产环境"一样稳定跑起来------可自启动、可观测、可更新、可回滚。
你最终要的不是"能跑",而是:断网/重启/更新后依然能自动恢复,并且可定位问题。
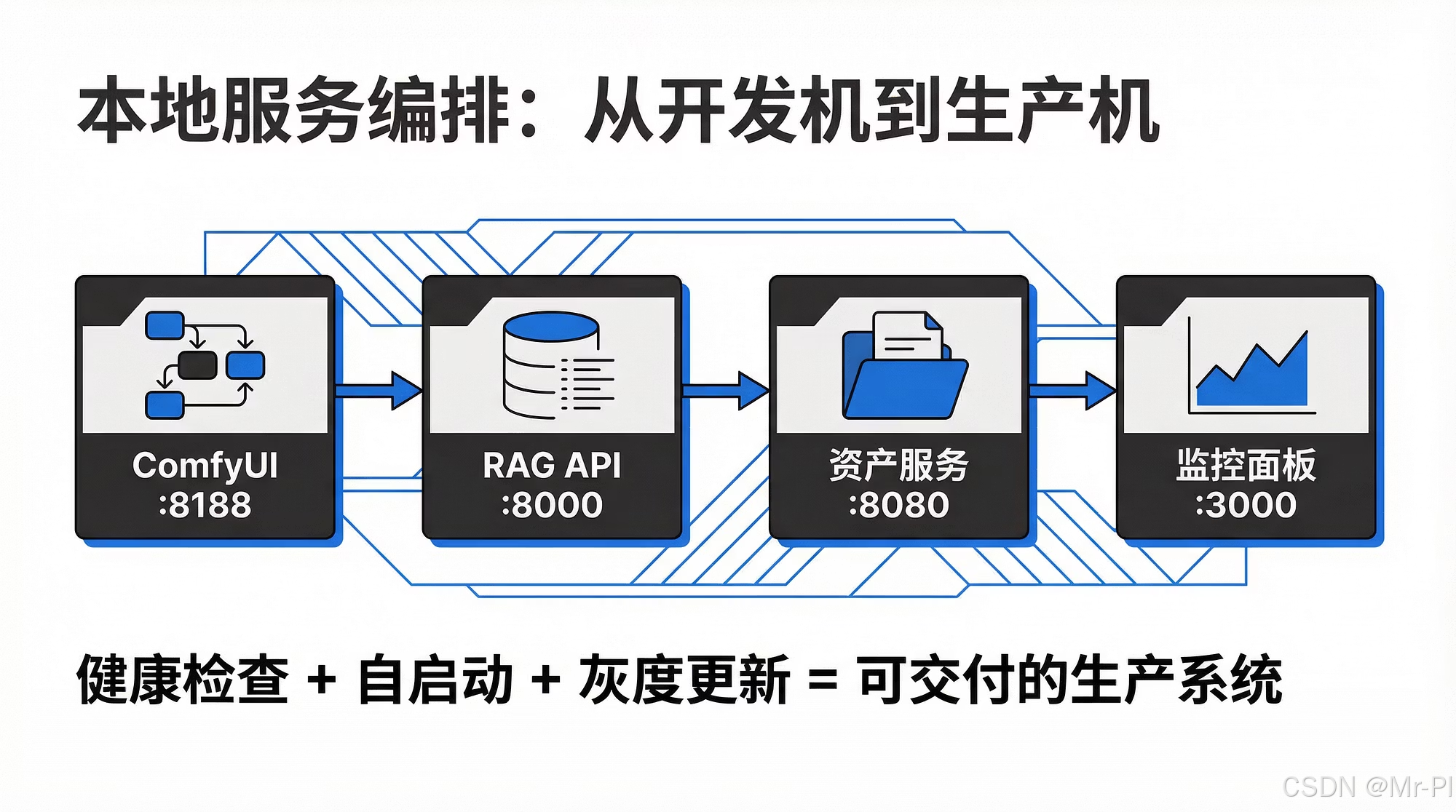
1)在 Mac 上的运行形态:三类服务,三种"最稳姿势"
我把你的服务拆成三类,分别用最适合的方式托管:
- ComfyUI(内容工厂):长运行 + GPU/推理任务队列
- RAG API(智能运营系统):FastAPI/Uvicorn 这类 HTTP 服务,强调健康检查、版本切换
- 面板服务(Dashboard/管理):Grafana/Streamlit/自研面板,强调鉴权与可观测
建议的"本地机房最小架构"如下:
Mac Studio M2 Ultra(本地算力层)
ComfyUI :8188
RAG API :8000
Dashboard :3000/8501
资产目录 /assets + /runs + /kb
日志 /logs
本地反向代理(Caddy/Nginx): 127.0.0.1:8080
关键点:
- Cloudflare Tunnel 后面建议只暴露 一个入口(反向代理),由它在本地做分流;这样端口治理、灰度发布、回滚都更简单。
- 每个服务"各占其职",不要把所有能力塞进一个进程里。
2)进程治理:端口、日志、健康检查,三件事必须标准化
2.1 端口治理:从一开始就做"端口表"
你至少要固定三类端口:
- ComfyUI:8188(默认)
- RAG API:8000(建议)
- Dashboard:3000(Grafana)或 8501(Streamlit)
建议你在仓库里放一份"端口登记表",并把它变成可执行的检查清单:
是
否
端口登记表(ports.yaml)
启动前检查:占用检测
端口冲突?
调整端口/停掉冲突服务
启动服务
反向代理路由生效
常用排查命令(你写成 SOP 就行):
lsof -i :8188/lsof -i :8000netstat -an | grep LISTEN
2.2 日志治理:不要靠"终端窗口记忆"
最低配置:每个服务都要有独立日志文件,并有滚动策略。
建议统一目录(举例):
/srv/ai/logs/comfyui//srv/ai/logs/rag//srv/ai/logs/dashboard/
你可以把"日志写入策略"标准化成一条规则:
- stdout/stderr 必须落盘
- 每天滚动、保留 7-14 天
- 关键事件打结构化字段(时间、服务名、request_id)
2.3 健康检查:用"可机器读"的 /healthz
RAG API 和面板服务必须提供健康检查接口;ComfyUI 可以用"端口可达 + 队列状态"做健康检查。
推荐的健康检查路径:
- RAG:
GET /healthz返回{"status":"ok","version":"x.y.z"} - Dashboard:
GET /healthz或简单的GET / - ComfyUI:
GET /可达 +(可选)查询队列/任务状态
健康检查在运维里不是"锦上添花",是你做灰度/回滚的闸门:
Dashboard ComfyUI RAG API Supervisor(守护/编排) Dashboard ComfyUI RAG API Supervisor(守护/编排) GET /healthz 200 OK + version TCP/HTTP 探活 reachable / status GET /healthz 200 OK 写入健康状态 + 触发告警(若失败)
3)在 macOS 上实现"自启动":用 launchd 做生产级托管
在 Mac 上,最稳的自启动是 launchd(launchctl + plist)。它比"开机登录后手动点脚本"靠谱得多。
你可以按"每个服务一个 plist"的方式管理:
comfyui.plistrag-api.plistdashboard.plist- (可选)
caddy.plist
一个最小的运行逻辑是:
- 进程崩溃自动拉起
- 标准输出落盘
- 启动后给固定端口服务
你不需要在文章里塞太多配置细节,但要把"可复制的骨架"讲清楚------读者能照做。
4)更新策略:灰度 + 回滚的最低配置(不搞花活也能稳)
你这套系统会频繁更新:
- ComfyUI 工作流、模型、节点
- RAG 的检索策略、提示词、向量库
- 面板与监控规则
所以更新策略必须从 Day 1 具备"回滚能力"。
4.1 最低成本灰度:双端口 + 反向代理切流
核心思路:新版本先在备用端口跑起来,健康检查通过后再切流。
stable
canary
用户/Agent
反向代理 /api
RAG v1 :8000
RAG v2 :8001
- 灰度:让 5%-20% 的请求走 v2(可用路径或子域区分也行)
- 回滚:只要把 upstream 切回 v1 即可,几秒恢复
4.2 最低配置回滚清单(建议你写成"强制执行")
- 旧版本二进制/环境保留(至少 1 个版本)
- 旧模型缓存可用(不要更新时把缓存清空)
- 配置文件版本化(Git 或至少 zip 归档)
- 关键目录可快照(assets、kb、vectors、workflows)
5)少量伪代码:把"编排思路"抽象成可执行逻辑
你可以把"自启动 + 健康检查 + 灰度切换"的逻辑理解成一个很朴素的守护流程:
伪代码 1:启动闸门(Health Gate)
text
start(service_v2)
wait_until(healthz(service_v2) == OK, timeout=60s)
if OK:
switch_traffic(to=service_v2)
else:
stop(service_v2)
keep(service_v1)
alert("release_failed")伪代码 2:持续探活(Watchdog)
text
every 30s:
for s in [comfyui, rag, dashboard, proxy]:
if not healthy(s):
restart(s)
record_incident(s)这两段"朴素到土"的逻辑,就是你专栏后面做 Make Agents 编排时的底层共识:所有自动化都要有闸门与回滚。
6)风险点与踩坑清单(建议读者直接收藏)
- 端口乱飞:临时改端口导致 Tunnel/反代/Agent 工具配置全部失效
- 日志不落盘:出问题只能靠猜,最痛苦
- 没有 /healthz:灰度发布等于赌博
- 更新直接覆盖:一旦出错只能重装,回滚成本爆炸
- ComfyUI 任务拥塞:无队列策略/无超时,导致"看似在线,实际不可用"
7)本章行动项(你可以按这 7 步直接落地)
- 制作端口登记表:8188 / 8000 / 3000(或 8501)固定化
- 给 RAG API 与面板加
/healthz(返回 version 字段) - 统一日志目录并落盘(stdout/stderr 分开也行)
- 用 launchd 给三类服务做自启动(每服务一个 plist)
- 引入一个本地反向代理作为唯一入口(便于切流)
- 实现"备用端口跑新版本"的灰度流程(8000/8001)
- 做一次演练:发布失败 → 30 秒内回滚
评论区互动(我想收集你们的真实环境参数)
- 你现在的"本地机房"更像哪种:Mac 常开、NAS 常开、还是云端为主?
- 你更需要我在下一篇先展开哪块:launchd plist 母模板 ,还是 反向代理切流(灰度/回滚)模板?
- 如果你已经跑过 ComfyUI:你遇到过最难排的稳定性问题是什么(节点崩、显存、队列、还是文件IO)?
下一章
《第 4 篇:为什么选择 Cloudflare Tunnel》