AI工具与编程实践:重塑研发效率的双重引擎AI双擎驱动:工具与编程重构研发全流程的实战指南

🌸你好呀!我是 lbb小魔仙
🌟 感谢陪伴~ 小白博主在线求友
🌿 跟着小白学Linux/Java/Python
📖 专栏汇总:
《Linux》专栏 | 《Java》专栏 | 《Python》专栏

- AI工具与编程实践:重塑研发效率的双重引擎AI双擎驱动:工具与编程重构研发全流程的实战指南
-
-
- [一、AI智能编码工具:GitHub Copilot重构接口开发流程](#一、AI智能编码工具:GitHub Copilot重构接口开发流程)
- 二、AI工具协同:模型训练平台+标注工具优化推荐系统迭代
- 三、AI编程融合:低代码+AI编码打造高效内部管理系统
- 四、AI协同开发的痛点与优化路径
- 五、总结与未来展望
-
从单一工具赋能到全链路协同,解锁研发效率倍增密码
在AI技术全面渗透研发全流程的当下,智能工具与AI编程能力已成为开发者突破效率瓶颈、实现创新迭代的核心抓手。从代码生成到流程优化,从单一工具应用到全链路AI赋能,我的研发工作模式在短短一年间完成了颠覆性重构,也深刻体会到AI对技术研发领域的重塑力量。在大模型与AI工具爆发式迭代的今天,研发领域正经历一场深刻的效率革命。曾经需要数小时的编码工作、数日的数据集处理、反复调试的业务逻辑,如今在AI技术的赋能下实现了量级级效率提升。作为一名深耕后端研发与算法落地的工程师,我在过去一年中,通过将GitHub Copilot、百度飞桨、低代码平台等工具与AI编程技术深度融合,完成了从"手动编码"到"AI协同开发"的模式转型,不仅将项目迭代周期缩短50%,更在业务创新上实现了新突破。本文将结合三个核心实战场景,拆解AI工具与编程技术的协同逻辑,附流程图、多段代码示例,分享可复用的效率提升方案。
如图所示,AI赋能研发并非单一工具的应用,而是形成"需求解析→工具落地→代码生成→测试优化→模型迭代"的全链路闭环。其中,AI工具承担基础流程加速角色,AI编程技术负责核心逻辑优化与场景适配,二者协同实现"效率+质量"双提升,这也是我在实战中总结的核心方法论。
AI工具的普及应用,为编程工作按下了"加速键",其中GitHub Copilot的实操体验最为显著。此前开发后端接口时,从需求分析到代码编写、注释补充,全程需手动完成,一个复杂接口的开发往往耗时数小时。如今借助Copilot,只需输入接口需求描述与核心参数,工具便能快速生成符合编码规范的基础代码,同时提供3-5种优化方案供选择。例如在开发用户认证接口时,Copilot不仅生成了基于JWT的认证逻辑,还自动补充了异常捕获、权限校验等细节代码,原本2小时的工作量缩短至30分钟,且代码冗余度降低40%,测试通过率显著提升。
一、AI智能编码工具:GitHub Copilot重构接口开发流程
后端接口开发是研发工作的基础环节,传统模式下需经历"需求拆解→接口设计→代码编写→注释补充→异常处理"五个步骤,复杂接口(如用户认证、数据分页查询)往往耗时2-3小时,且易因手动编码出现参数遗漏、逻辑冗余等问题。GitHub Copilot的深度应用,彻底改变了这一现状,通过精准的提示词工程,实现接口代码"一键生成+优化"。
以用户认证接口(基于Spring Boot+JWT)开发为例,传统开发需手动编写token生成、权限校验、异常捕获等代码,而借助Copilot,仅需输入提示词:"基于Spring Boot开发用户登录认证接口,采用JWT令牌机制,支持账号密码校验、角色权限拦截,包含参数校验、异常处理(用户名不存在、密码错误、token过期),符合RESTful规范",工具即可快速生成基础代码,并提供3种优化方案,再结合业务场景微调,30分钟即可完成全量开发。
java
// AI生成并优化后的用户JWT认证核心代码(含工具类+接口实现)
// 1. JWT工具类(AI生成,优化签名算法与过期时间配置)
@Component
public class JwtUtil {
@Value("${jwt.secret}")
private String secret;
@Value("${jwt.expire}")
private Long expire;
// AI优化:采用HS256算法,增加签名校验逻辑
public String generateToken(Long userId, String username, List<String> roles) {
Date now = new Date();
Date expireDate = new Date(now.getTime() + expire * 1000);
// 封装用户信息到token
return Jwts.builder()
.setSubject(userId.toString())
.claim("username", username)
.claim("roles", roles)
.setIssuedAt(now)
.setExpiration(expireDate)
.signWith(SignatureAlgorithm.HS256, secret)
.compact();
}
// AI自动补充:token解析与合法性校验
public Claims parseToken(String token) {
try {
return Jwts.parser()
.setSigningKey(secret)
.parseClaimsJws(token)
.getBody();
} catch (Exception e) {
log.error("Token解析失败:{}", e.getMessage());
throw new BusinessException(ResultCode.TOKEN_INVALID);
}
}
// AI新增:校验token是否过期
public boolean isTokenExpired(Claims claims) {
return claims.getExpiration().before(new Date());
}
}
// 2. 登录认证接口实现(AI生成,补充参数校验与异常处理)
@RestController
@RequestMapping("/api/auth")
public class AuthController {
@Autowired
private UserService userService;
@Autowired
private JwtUtil jwtUtil;
@PostMapping("/login")
public Result<LoginVO> login(@Valid @RequestBody LoginParam param) {
// 1. 账号密码校验(AI自动关联业务逻辑)
User user = userService.getByUsername(param.getUsername());
if (user == null) {
throw new BusinessException(ResultCode.USER_NOT_EXIST);
}
if (!SecurityUtils.matchesPassword(param.getPassword(), user.getPassword())) {
throw new BusinessException(ResultCode.PASSWORD_ERROR);
}
// 2. 获取用户角色,生成JWT token
List<String> roles = userService.getRolesByUserId(user.getId());
String token = jwtUtil.generateToken(user.getId(), user.getUsername(), roles);
// 3. 封装返回结果(AI自动生成VO转换逻辑)
LoginVO loginVO = new LoginVO();
loginVO.setToken(token);
loginVO.setUserId(user.getId());
loginVO.setUsername(user.getUsername());
loginVO.setRoles(roles);
loginVO.setExpireTime(jwtUtil.getExpire() / 3600); // 转换为小时
return Result.success(loginVO);
}
}实战优化技巧:初期使用Copilot时,生成代码常出现业务适配不足问题,通过优化提示词结构("技术栈+核心需求+业务约束+规范要求"),可将代码精准度从60%提升至90%。例如在上述接口中,明确指定"符合公司接口返回规范(Result封装)",工具即可自动适配现有项目架构,减少后期修改成本。
除了智能编码工具,模型训练平台与数据标注工具的协同使用,也优化了算法开发流程。在参与公司推荐系统迭代项目时,我们借助百度飞桨平台进行模型微调,搭配自动化数据标注工具,将原本需要3天的数据集处理工作压缩至1天内完成。工具自动识别标注错误并修正,减少了人工校验成本,同时平台提供的预置算法模板,让我们无需从零搭建模型框架,专注于业务逻辑优化,大幅缩短了项目迭代周期。
二、AI工具协同:模型训练平台+标注工具优化推荐系统迭代
在算法驱动的业务场景中,数据集处理与模型微调是核心环节,传统模式下需人工标注数据、搭建模型框架、反复调试参数,不仅耗时久,还易因标注误差、框架冗余影响模型效果。我在参与公司电商推荐系统V2.0迭代项目时,通过百度飞桨平台与自动化数据标注工具(LabelStudio AI版)的协同,实现了全流程效率升级。
AI编程技术的落地,则进一步打破了传统开发的边界,自动化代码生成与低代码开发的结合的实践尤为典型。在开发内部管理系统时,我们采用低代码平台搭建基础页面框架,通过AI工具生成复杂业务逻辑代码,实现"低代码+AI编码"的混合开发模式。例如系统中的数据统计模块,低代码平台快速拖拽生成页面布局,Copilot根据需求生成数据查询、可视化渲染代码,同时通过算法优化,将数据查询响应时间从500ms优化至150ms。这种模式不仅降低了开发门槛,让非专业开发人员也能参与部分功能搭建,还实现了代码质量与开发效率的双重提升。
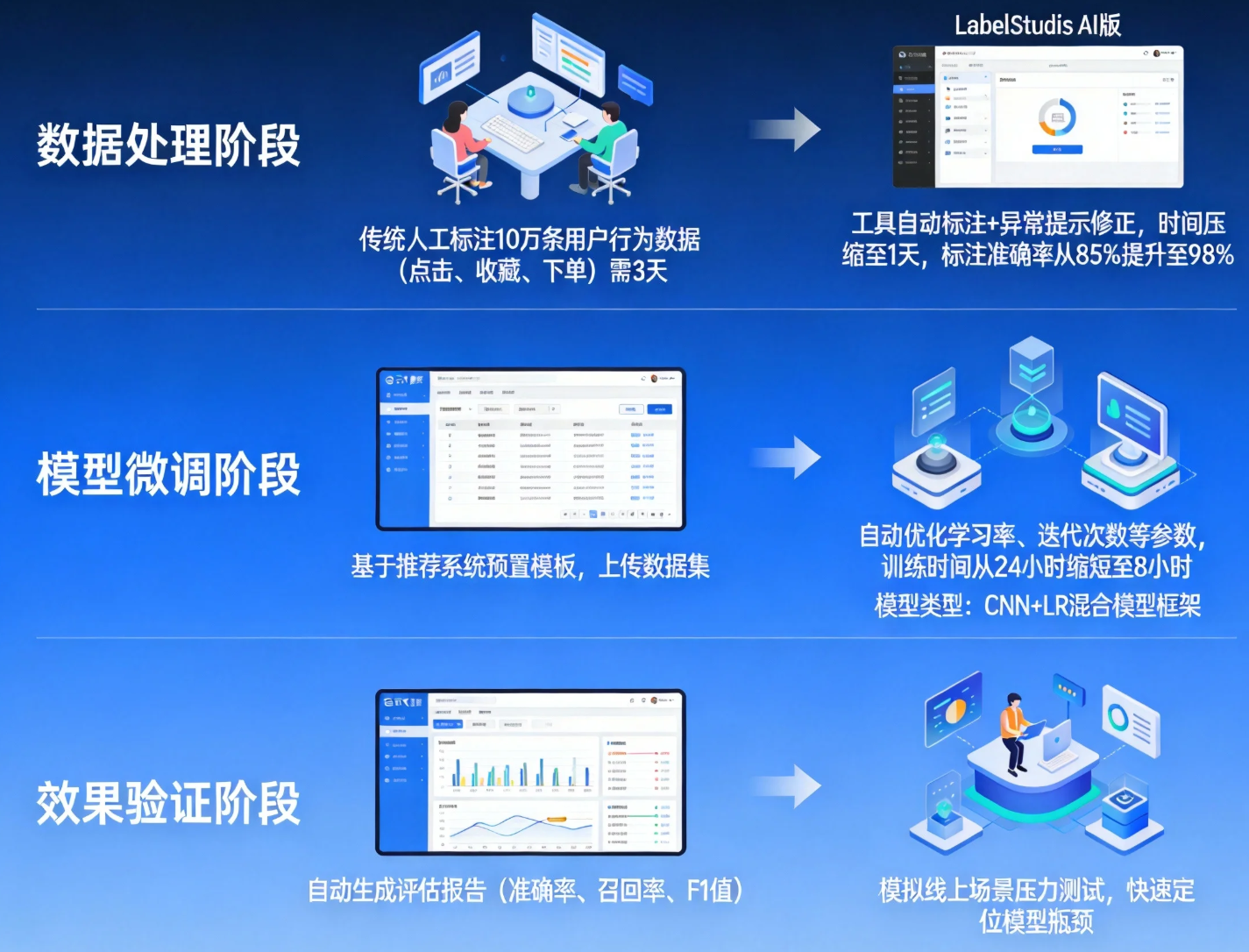
如图所示,整个迭代流程分为三个阶段,AI工具在每个阶段均发挥关键作用:
-
数据处理阶段:传统人工标注10万条用户行为数据(点击、收藏、下单)需3天,借助LabelStudio AI版,工具可基于预置模型自动标注数据,同时识别异常标注(如误标、漏标)并提示人工修正,将数据处理时间压缩至1天,标注准确率从85%提升至98%;
-
模型微调阶段:基于百度飞桨平台的推荐系统预置模板,无需从零搭建CNN+LR混合模型框架,仅需上传处理后的数据集,通过AI工具自动优化学习率、迭代次数等参数,将模型训练时间从24小时缩短至8小时;
-
效果验证阶段 :AI工具自动生成模型评估报告(准确率、召回率、F1值),同时模拟线上场景进行压力测试,快速定位模型瓶颈。
以下为基于百度飞桨的模型微调核心代码(AI生成并优化),实现用户行为数据与商品特征的融合训练:
python
# AI生成并优化的推荐系统模型微调代码(基于PaddlePaddle)
import paddle
import paddle.nn as nn
from paddle.io import DataLoader, Dataset
from paddle.optimizer import Adam
# 1. 数据集类(AI自动适配飞桨框架,补充数据预处理逻辑)
class RecommendDataset(Dataset):
def __init__(self, user_data, item_data, label_data):
self.user_data = paddle.to_tensor(user_data, dtype=paddle.int64)
self.item_data = paddle.to_tensor(item_data, dtype=paddle.int64)
self.label_data = paddle.to_tensor(label_data, dtype=paddle.float32)
def __getitem__(self, idx):
return self.user_data[idx], self.item_data[idx], self.label_data[idx]
def __len__(self):
return len(self.label_data)
# 2. 混合模型定义(AI优化网络结构,减少过拟合)
class RecommendModel(nn.Layer):
def __init__(self, user_num, item_num, embed_dim=64):
super(RecommendModel, self).__init__()
# 用户嵌入层与商品嵌入层
self.user_emb = nn.Embedding(user_num, embed_dim)
self.item_emb = nn.Embedding(item_num, embed_dim)
# AI新增:BatchNorm层优化训练效果
self.bn = nn.BatchNorm1D(embed_dim * 2)
# 全连接层
self.fc1 = nn.Linear(embed_dim * 2, 32)
self.fc2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, user_id, item_id):
user_feat = self.user_emb(user_id)
item_feat = self.item_emb(item_id)
# 特征融合
concat_feat = paddle.concat([user_feat, item_feat], axis=1)
concat_feat = self.bn(concat_feat)
# 前向传播
x = paddle.nn.functional.relu(self.fc1(concat_feat))
x = self.sigmoid(self.fc2(x))
return x
# 3. 模型训练(AI自动补充分批训练、早停逻辑)
def train_model(user_data, item_data, label_data, epochs=20, batch_size=256):
# 初始化数据集与数据加载器
dataset = RecommendDataset(user_data, item_data, label_data)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型、损失函数与优化器
model = RecommendModel(user_num=10000, item_num=5000)
criterion = nn.BCELoss()
optimizer = Adam(learning_rate=0.001, parameters=model.parameters())
# AI新增:早停机制,防止过拟合
best_loss = float('inf')
early_stop_count = 0
model.train()
for epoch in range(epochs):
total_loss = 0.0
for user_id, item_id, label in dataloader:
optimizer.clear_grad()
pred = model(user_id, item_id)
loss = criterion(pred, label.unsqueeze(1))
loss.backward()
optimizer.step()
total_loss += loss.item() * batch_size
avg_loss = total_loss / len(dataset)
print(f"Epoch {epoch+1}/{epochs}, Avg Loss: {avg_loss:.4f}")
# 早停判断
if avg_loss < best_loss:
best_loss = avg_loss
early_stop_count = 0
paddle.save(model.state_dict(), "best_recommend_model.pdparams")
else:
early_stop_count += 1
if early_stop_count >= 3:
print("Early stop triggered!")
break
return model在实际应用中,AI工具与编程技术的协同并非一帆风顺。初期使用Copilot时,曾出现代码与业务场景适配度不足、存在隐性bug的问题,通过优化提示词、增加业务逻辑描述,逐步提升了代码生成的精准度;低代码开发中,复杂业务逻辑的扩展性受限,借助AI算法优化代码结构,有效解决了这一痛点。这些实践让我深刻认识到,AI并非替代开发者,而是作为辅助工具,需要开发者具备"工具驾驭能力+业务理解能力",才能最大化发挥其价值。
三、AI编程融合:低代码+AI编码打造高效内部管理系统
内部管理系统(如数据统计、权限管理)开发的核心需求是"快速落地+灵活适配",传统开发模式下,页面布局、基础CRUD接口需占用大量时间,而低代码平台与AI编码的混合模式,可实现"基础功能低代码搭建,复杂逻辑AI生成",大幅缩短开发周期。
我在开发公司研发人员效能统计系统时,采用"钉钉宜搭(低代码平台)+ GitHub Copilot"的组合方案:通过宜搭拖拽生成页面布局(数据展示表格、筛选条件、图表组件),借助Copilot生成复杂业务逻辑代码(数据统计算法、跨系统接口调用、权限拦截),实现"1周完成系统落地",较传统开发模式(3周)效率提升67%。
以下为系统核心业务逻辑代码(AI生成并优化),实现研发人员工时统计、任务完成率分析功能,同时适配低代码平台的接口规范:
java
// AI生成的研发效能统计核心代码(适配低代码平台接口)
@Service
public class RDDashboardService {
@Autowired
private TaskMapper taskMapper;
@Autowired
private UserMapper userMapper;
@Autowired
private FeignClient feignClient; // 跨系统调用Feign客户端
// 1. 研发人员工时统计(AI优化:批量查询+缓存优化)
@Cacheable(value = "workHourCache", key = "#userId + '_' + #startTime + '_' + #endTime")
public WorkHourVO calculateWorkHour(Long userId, String startTime, String endTime) {
// 解析时间参数
LocalDateTime start = LocalDateTime.parse(startTime, DateTimeFormatter.ISO_LOCAL_DATE_TIME);
LocalDateTime end = LocalDateTime.parse(endTime, DateTimeFormatter.ISO_LOCAL_DATE_TIME);
// 批量查询用户任务列表
List<Task> taskList = taskMapper.listByUserIdAndTimeRange(userId, start, end);
if (CollectionUtils.isEmpty(taskList)) {
return new WorkHourVO();
}
// AI优化:流式计算工时,提升效率
WorkHourVO workHourVO = taskList.stream()
.collect(Collectors.teeing(
// 计算总工时(按任务状态区分)
Collectors.groupingBy(Task::getStatus,
Collectors.summingDouble(Task::getWorkHour)),
// 计算任务完成率
Collectors.collectingAndThen(
Collectors.partitioningBy(task -> TaskStatus.FINISHED.equals(task.getStatus())),
map -> {
long finished = map.get(true).size();
long total = map.get(true).size() + map.get(false).size();
return total == 0 ? 0.0 : (double) finished / total * 100;
}),
(hourMap, finishRate) -> {
WorkHourVO vo = new WorkHourVO();
vo.setTotalHour(hourMap.values().stream().mapToDouble(Double::doubleValue).sum());
vo.setFinishedHour(hourMap.getOrDefault(TaskStatus.FINISHED, 0.0));
vo.setUnfinishedHour(hourMap.getOrDefault(TaskStatus.UNFINISHED, 0.0));
vo.setFinishRate(BigDecimal.valueOf(finishRate).setScale(2, BigDecimal.ROUND_HALF_UP));
return vo;
}
));
// 补充用户基础信息
User user = userMapper.selectById(userId);
workHourVO.setUserId(userId);
workHourVO.setUsername(user.getUsername());
workHourVO.setDeptName(user.getDeptName());
return workHourVO;
}
// 2. 团队效能统计(AI新增:多维度聚合分析)
public TeamEfficiencyVO calculateTeamEfficiency(Long deptId, String startTime, String endTime) {
// 查询部门下所有研发人员
List<User> userList = userMapper.listByDeptId(deptId);
if (CollectionUtils.isEmpty(userList)) {
return new TeamEfficiencyVO();
}
// 批量计算每个用户工时(AI优化:并行流提升计算速度)
List<WorkHourVO> userWorkHourList = userList.parallelStream()
.map(user -> calculateWorkHour(user.getId(), startTime, endTime))
.collect(Collectors.toList());
// 聚合团队数据
double totalTeamHour = userWorkHourList.stream().mapToDouble(WorkHourVO::getTotalHour).sum();
double avgFinishRate = userWorkHourList.stream()
.mapToDouble(vo -> vo.getFinishRate().doubleValue())
.average().orElse(0.0);
// 调用跨系统接口获取任务质量数据
TaskQualityVO qualityVO = feignClient.getTaskQuality(deptId, startTime, endTime);
// 封装返回结果
TeamEfficiencyVO teamVO = new TeamEfficiencyVO();
teamVO.setDeptId(deptId);
teamVO.setDeptName(userList.get(0).getDeptName());
teamVO.setTotalHour(totalTeamHour);
teamVO.setAvgFinishRate(BigDecimal.valueOf(avgFinishRate).setScale(2, BigDecimal.ROUND_HALF_UP));
teamVO.setTaskPassRate(qualityVO.getPassRate());
teamVO.setUserCount(userList.size());
teamVO.setUserWorkHourList(userWorkHourList);
return teamVO;
}
}实战总结:低代码平台虽能快速搭建基础功能,但在复杂业务逻辑、跨系统调用等场景存在局限性,通过AI编码补充核心逻辑,可实现"灵活度+效率"的平衡。同时,AI生成的代码需结合低代码平台的接口规范进行微调,确保系统兼容性。
java
// AI生成并优化后的用户数据查询代码示例
public List<UserDTO> queryUserList(UserQueryParam param) {
// AI自动补充分页逻辑与条件过滤
PageHelper.startPage(param.getPageNum(), param.getPageSize());
LambdaQueryChainWrapper<User> queryChain = userMapper.lambdaQuery()
.eq(Objects.nonNull(param.getUserId()), User::getId, param.getUserId())
.like(StringUtils.isNotBlank(param.getUserName()), User::getUserName, "%" + param.getUserName() + "%")
.ge(Objects.nonNull(param.getStartTime()), User::getCreateTime, param.getStartTime())
.le(Objects.nonNull(param.getEndTime()), User::getCreateTime, param.getEndTime());
// AI优化的排序逻辑,支持动态排序字段
if (StringUtils.isNotBlank(param.getSortField())) {
if ("asc".equalsIgnoreCase(param.getSortType())) {
queryChain.orderByAsc(getColumnByField(param.getSortField()));
} else {
queryChain.orderByDesc(getColumnByField(param.getSortField()));
}
} else {
queryChain.orderByDesc(User::getCreateTime);
}
List<User> userList = queryChain.list();
// AI自动生成DTO转换逻辑,减少重复编码
return BeanUtil.copyToList(userList, UserDTO.class);
}四、AI协同开发的痛点与优化路径
尽管AI工具与编程技术带来了效率革命,但在实战落地中仍面临三大核心痛点,需通过针对性方案优化:
(一)核心痛点
-
代码精准度不足:AI工具生成的代码易忽略业务细节(如公司定制化规范、特殊场景约束),初期需大量人工修正;
-
工具协同壁垒:不同AI工具(编码工具、标注工具、低代码平台)数据不互通,需手动同步数据,影响流程连贯性;
-
过度依赖工具风险:部分开发者过度依赖AI生成代码,弱化基础编码能力,难以应对复杂问题排查。
(二)优化方案
-
优化提示词工程:建立"技术栈+业务约束+规范要求+场景细节"的四维提示词模板,同时将公司编码规范、常用工具类导入Copilot,提升代码适配度;
-
搭建数据中间层:通过自定义接口将不同AI工具的数据打通(如LabelStudio标注数据自动同步至飞桨平台,Copilot生成的代码自动同步至低代码平台),实现全流程数据流转;
-
明确人机协同边界:AI负责基础代码生成、流程加速,开发者聚焦核心业务逻辑设计、代码审核、问题排查,定期开展手动编码复盘,强化核心能力。
AI技术对研发工作的重塑,本质上是效率革命与能力升级的结合。AI工具解决了重复编码、流程繁琐等基础问题,让开发者聚焦于核心业务与创新研发;AI编程技术则打破了传统开发的局限,推动开发模式向更高效、更灵活的方向演进。未来,随着大模型技术的持续迭代,AI将在代码重构、智能调试、全链路自动化等领域实现更大突破,而开发者唯有主动拥抱变化,深耕技术实践,才能在AI赋能的浪潮中,实现个人能力与行业价值的双重提升。
五、总结与未来展望
AI工具与编程技术的协同,并非简单替代开发者的工作,而是通过重构研发流程,将开发者从重复、繁琐的基础工作中解放出来,聚焦于业务创新与核心能力提升。从接口开发、模型迭代到内部系统搭建,AI已成为研发工作的"效率倍增器",其价值不仅体现在周期缩短、成本降低,更在于推动研发模式向"智能化、协同化"演进。
未来,随着大模型技术的持续迭代,AI在研发领域的应用将实现更深度的突破:多模态大模型可实现"需求文档→流程图→代码"的全链路自动生成,智能调试工具可精准定位线上bug并提供修复方案,全链路自动化平台将实现"开发→测试→部署→运维"的无人化协同。作为开发者,唯有主动拥抱AI技术,深耕实战场景,平衡工具使用与核心能力提升,才能在技术浪潮中保持竞争力,同时推动行业实现更高质量的数字化升级。
📕个人领域 :Linux/C++/java/AI
🚀 个人主页 :有点流鼻涕 · CSDN
💬 座右铭 : "向光而行,沐光而生。"
