目录
[1.1 Ollama简介](#1.1 Ollama简介)
[1.2 DeepSeek-OCR简介](#1.2 DeepSeek-OCR简介)
[2.1 安装Ollama](#2.1 安装Ollama)
[2.2 安装Python依赖](#2.2 安装Python依赖)
[3.1 拉取DeepSeek-OCR模型](#3.1 拉取DeepSeek-OCR模型)
[3.2 验证模型安装](#3.2 验证模型安装)
[3.3 启动Ollama服务](#3.3 启动Ollama服务)
[4.1 完整代码](#4.1 完整代码)
[4.2 代码详解](#4.2 代码详解)
[4.2.1 encode_image函数](#4.2.1 encode_image函数)
[4.2.2 ocr_image函数](#4.2.2 ocr_image函数)
[4.2.3 构建请求payload](#4.2.3 构建请求payload)
[4.2.4 发送请求并处理响应](#4.2.4 发送请求并处理响应)
[5.1 准备测试图片](#5.1 准备测试图片)
[5.2 运行代码](#5.2 运行代码)
[5.3 查看结果](#5.3 查看结果)
[5.3.1 文字图片](#5.3.1 文字图片)
[5.3.2 纯图片](#5.3.2 纯图片)
一、什么是Ollama和DeepSeek-OCR
1.1 Ollama简介
Ollama是一个开源的大模型运行工具,它支持在本地运行多种大语言模型和视觉模型。Ollama具有以下特点:
-
轻量级:安装简单,资源占用少
-
跨平台:支持Windows、macOS和Linux系统
-
API友好:提供REST API接口,方便集成到各种应用中
-
模型丰富:支持多种开源模型,包括DeepSeek系列
如何安装相关说明:通过Ollama本地部署DeepSeek R1以及简单使用的教程(超详细) - 知乎
1.2 DeepSeek-OCR简介
DeepSeek-OCR是DeepSeek团队推出的OCR模型,具有以下优势:
-
识别准确率高:对多种字体和语言都有良好的识别效果
-
支持多语言:包括中文、英文等多种语言
-
易于部署:可以方便地通过Ollama进行本地部署
二、环境准备
2.1 安装Ollama
Windows系统安装
-
访问Ollama官网:https://ollama.com/download
-
点击"Download for Windows"按钮下载安装包
-
运行安装程序,按照提示完成安装
-
安装完成后,打开命令行终端,输入以下命令验证安装:ollama --version
如果显示版本号,说明安装成功。


2.2 安装Python依赖
我们需要安装Python的requests库来调用Ollama API:pip install requests
三、部署DeepSeek-OCR模型
3.1 拉取DeepSeek-OCR模型
在命令行终端中执行以下命令来下载DeepSeek-OCR模型:ollama pull deepseek-ocr:latest
这个过程可能需要一些时间,具体取决于你的网络速度。模型下载完成后,Ollama会自动将模型存储在本地。
3.2 验证模型安装
可以使用以下命令查看已安装的模型列表:ollama list
就能看到deepseek-ocr:latest出现在列表中。

3.3 启动Ollama服务
Ollama安装后会自动启动服务,默认监听在http://localhost:11434。如果服务没有自动启动,可以手动启动:
Windows系统 : 在开始菜单中找到Ollama并启动,或者在命令行中输入:ollama serve
运行代码测试之后会显示请求成功,代表我们启动成功了。如果命令行启动不成功的话,我们也可以双击运行对应桌面端应用

四、Python代码实现
下面我们通过完整的Python代码来实现OCR功能。代码分为几个部分:图片编码、API调用、结果展示。
4.1 完整代码
python
import requests
import base64
import json
import os
def encode_image(image_path):
"""
将图片文件编码为base64格式
Args:
image_path: 图片文件路径
Returns:
base64编码的字符串
"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def ocr_image(image_path, model="deepseek-ocr:latest"):
"""
使用DeepSeek-OCR模型识别图片中的文字
Args:
image_path: 图片文件路径
model: 使用的模型名称,默认为deepseek-ocr:latest
"""
url = "http://localhost:11434/api/generate"
# 检查文件是否存在
if not os.path.exists(image_path):
print(f"Error: File {image_path} not found.")
return
try:
# 将图片编码为base64
base64_image = encode_image(image_path)
# 构建请求payload
payload = {
"model": model,
"prompt": "Please transcribe the text in this image.",
"images": [base64_image],
"stream": False
}
print(f"Sending request to Ollama (model: {model})...")
# 发送POST请求
response = requests.post(url, json=payload)
# 处理响应
if response.status_code == 200:
result = response.json()
print("\n--- OCR Result ---\n")
print(result.get("response", "No response text found."))
print("\n------------------")
else:
print(f"Error: {response.status_code} - {response.text}")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
# 设置图片路径(请根据实际情况修改)
image_path = r"C:\Users\salute\...."
ocr_image(image_path)4.2 代码详解
4.2.1 encode_image函数
python
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')这个函数的作用是将图片文件转换为base64编码字符串。Ollama API要求图片数据以base64格式传输,因此我们需要先进行编码。
-
open(image_path, "rb"):以二进制读取模式打开图片文件 -
base64.b64encode():将二进制数据编码为base64 -
.decode('utf-8'):将字节串解码为UTF-8字符串
4.2.2 ocr_image函数
python
def ocr_image(image_path, model="deepseek-ocr:latest"):
url = "http://localhost:11434/api/generate"
if not os.path.exists(image_path):
print(f"Error: File {image_path} not found.")
return这是核心的OCR识别函数,参数包括:
-
image_path:要识别的图片路径 -
model:使用的模型名称,默认为deepseek-ocr:latest
首先检查图片文件是否存在,如果不存在则直接返回。
4.2.3 构建请求payload
python
base64_image = encode_image(image_path)
payload = {
"model": model,
"prompt": "Please transcribe the text in this image.",
"images": [base64_image],
"stream": False
}构建发送给Ollama API的请求参数:
-
model:指定使用的模型 -
prompt:提示词,告诉模型要做什么任务 -
images:base64编码的图片数据数组 -
stream:是否使用流式输出,这里设置为False
4.2.4 发送请求并处理响应
python
response = requests.post(url, json=payload)
if response.status_code == 200:
result = response.json()
print("\n--- OCR Result ---\n")
print(result.get("response", "No response text found."))
print("\n------------------")
else:
print(f"Error: {response.status_code} - {response.text}")使用requests库发送POST请求到Ollama API,然后处理响应结果。如果请求成功(状态码200),则解析JSON响应并提取识别结果。
五、实战演示
5.1 准备测试图片
首先准备一张包含文字的图片,保存为img.png或其他格式。图片可以是:
-
扫描的文档
-
截图
-
包含文字的照片
5.2 运行代码
将代码保存为test_ocr.py,然后在编译器中运行该代码
5.3 查看结果
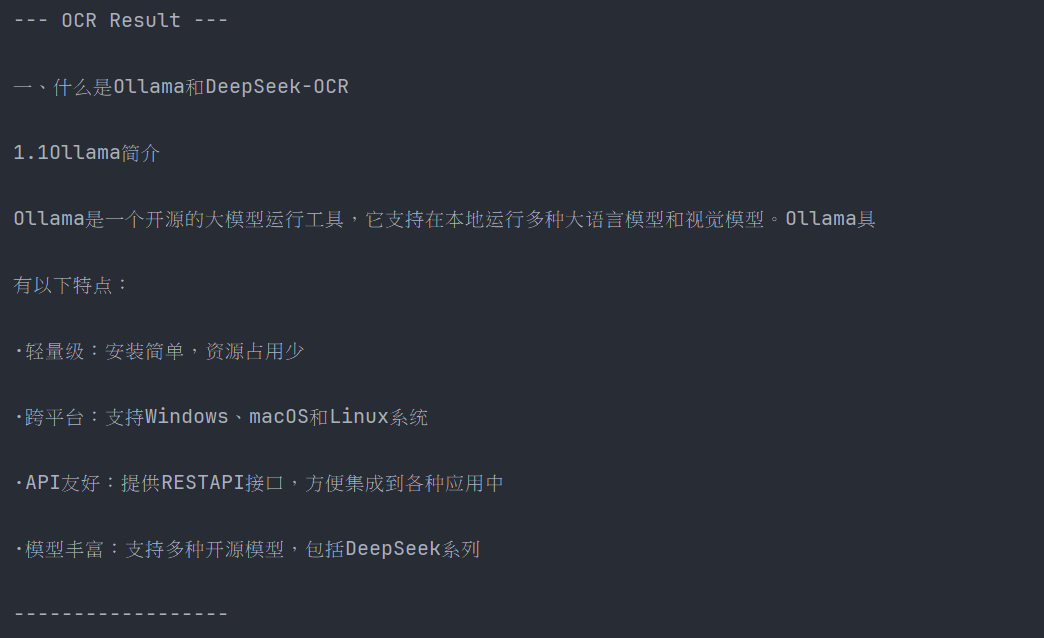
5.3.1 文字图片
图片:
对应输出内容:

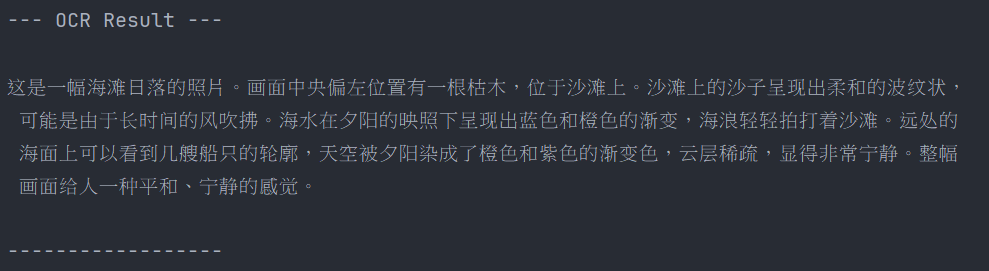
5.3.2 纯图片
图片:
对应输出内容:
六、应用场景
DeepSeek-OCR结合Ollama可以在以下场景中发挥作用:
-
文档数字化:将纸质文档转换为可编辑的电子文档
-
票据处理:自动识别发票、收据等票据信息
-
图片文字提取:从截图、照片中提取文字内容
-
多语言翻译:识别文字后进行翻译
-
数据录入自动化:自动将图片中的数据录入系统
-
无障碍辅助:为视障用户提供图片文字朗读服务
七、总结
本文详细介绍了如何使用Ollama部署DeepSeek-OCR模型,并通过Python代码实现了图像文字识别功能。主要内容包括:
-
Ollama和DeepSeek-OCR的介绍
-
环境准备和模型部署
-
完整的Python代码实现
-
代码详解和实战演示
通过本文的学习,你应该能够在本地快速搭建OCR识别系统,并将其应用到实际项目中。DeepSeek-OCR和Ollama的组合为我们提供了一个强大而易用的本地OCR解决方案,既保护了数据隐私,又提供了高效的识别能力。