智能问数系统(一):高质量的Text-to-SQL
文章目录
-
- 数据库Schema增强
- 构建业务知识库
- Text-to-SQL执行流程
-
- [查询意图识别 **(IntentRecognitionNode)**](#查询意图识别 (IntentRecognitionNode))
- [业务知识库召回 **(EvidenceRecallNode)**](#业务知识库召回 (EvidenceRecallNode))
- 查询增强阶段**(QueryEnhanceNode)**
- [数据库Schema召回**(SchemaRecallNode & TableRelationNode)**](#数据库Schema召回**(SchemaRecallNode & TableRelationNode)**)
- [计划生成SQL指令 **(PlannerNode)**](#计划生成SQL指令 (PlannerNode))
- [SQL 生成阶段 **(SQLGenerateNode) **](#SQL 生成阶段 **(SQLGenerateNode) **)
-
Text-to-SQL(自然语言转 SQL)本质是一个 语义解析(Semantic Parsing)的问题,与LLM交互的过程中涉及自然语言的理解、数据库模型的对齐、SQL语法的生成等多个问题,尤其在负责的多表关联查询、统计分析、特定的业务术语的场景下仅仅依赖LLM会出现"幻觉式生成" ,因此我们需要数据库Schema增强 + 构建业务知识库
-
下面是基于DataAgent进行分析编写,DataAgent 是一个基于 Spring AI Alibaba Graph 打造的企业级智能数据分析 Agent。
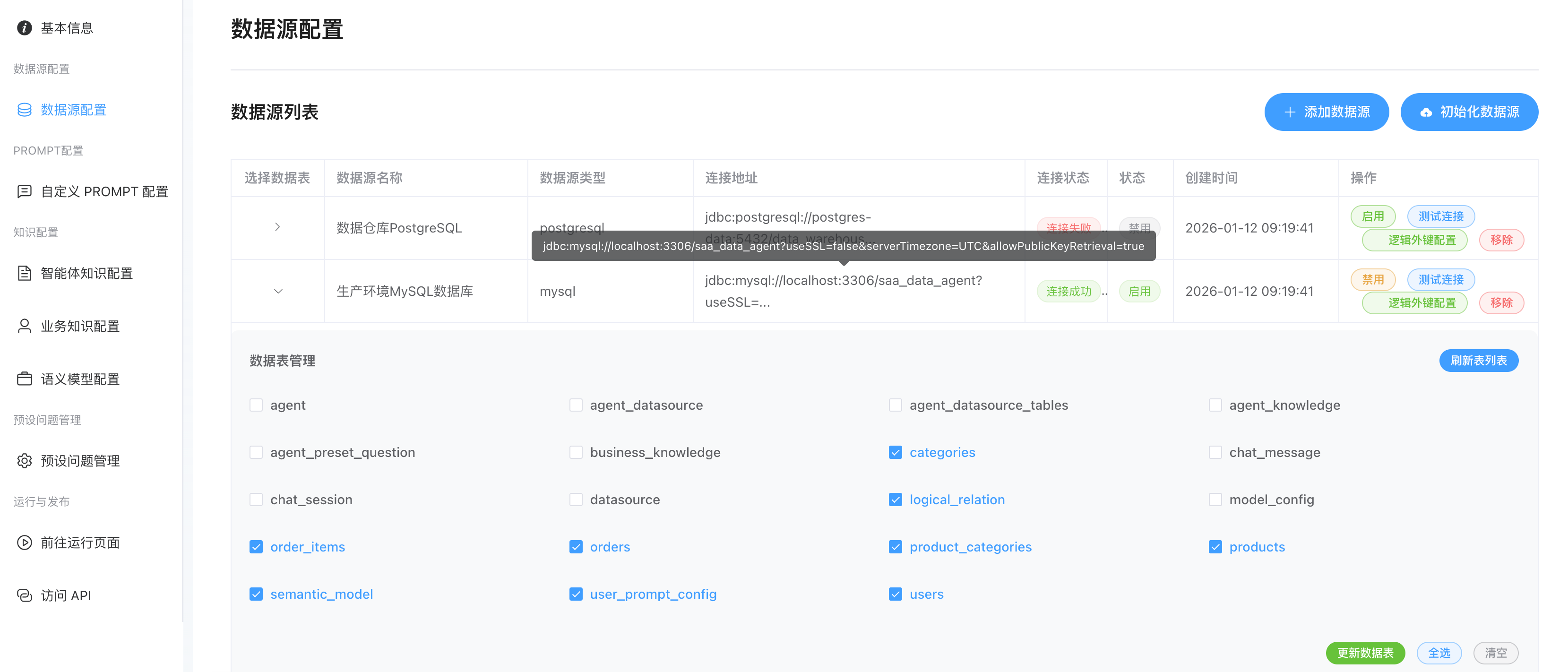
数据库Schema增强
- 为了解决 LLM 在面对海量表结构时的"信息过载"和"命名理解偏差",我们采用以下增强策略:
表元数据向量化
- 不仅仅存储表名,而是将"表名+字段名+字段注释+外键关系"组合成语义丰富的描述块进行向量化。这使得系统能够理解用户口语(如"销售额")与物理字段(如 total_amount)的关联。
字段样本数据向量化
- 抽取每个表的字段部分代表性样板数据(Sample Rows)存入向量库。比如:字段"name": "张三", "李四", "王五"
逻辑外键配置
- 结构化的维护主表:字段 映射 关联表:关联字段的关系,用于对表结构的原数据的补充,更好的帮忙LLM理解语义
构建业务知识库
- AI能力的上限取决于它锁掌握"知识"质量,为了让AI能够更准确的理解自然语言并准确的Text-To-SQL,我们可以将"知识"分为三类注入给到AI
语义模型
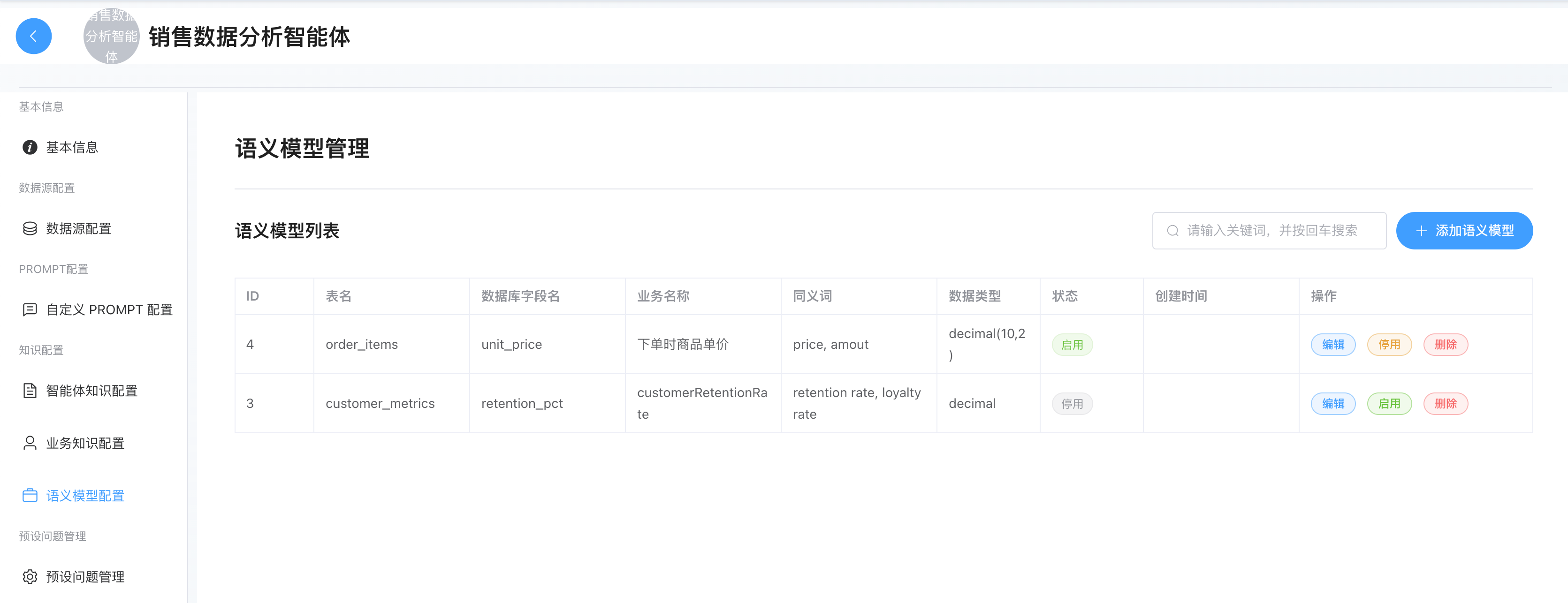
定位:
- 这是 Text-To-SQL的地基。它负责建立"业务名称"到"数据库表名/字段名"的映射。如果这里配置不准,SQL 一定会写错。
- 配置重点在于消除数据库字段的歧义。语义模型不是要求你要把所有的表和所有列都要配置到这里,这么多表你也配不完,如果你发现数据列的description字段描述太少,LLM不能很好理解该数据列,或者某个很"专业"的业务名词是映射到某个列的而LLM理解不了,此时你可以尝试在这里配置。
配置最佳实践:
- 数据库表名/字段名:
- 保持与数据库物理名称一致。
- 业务名称 (Business Name)
- 最佳实践:使用业务人员口语中常用的标准名称。
- 案例 :反例 :
csat_score-> "CSAT" (太技术化) 正例*:csat_score-> "客户满意度分数"
- 同义词 (Synonyms) ------ ⭐ 最重要配置
- 作用:解决用户问法多样性的问题。
- 最佳实践:枚举所有可能的叫法,用逗号分隔。
- 案例 :字段
price2(订单价格):同义词填入订单金额, 成交价, 销售额, 支付金额, amount
- 业务描述 (Description) ------ 解决逻辑歧义
- 作用:告诉 LLM 这个字段的特殊取值逻辑或业务含义。
- 最佳实践 :如果是枚举值或状态码,必须解释每个值的含义。
- 案例 :对于
order_status字段,描述应填:订单状态:0代表待支付,1代表已支付/已成交,2代表已取消,3代表退款中。计算GMV时通常只统计状态为1的订单。
- 数据类型
- 确保准确(如
int,varchar),这决定了生成的 SQL 中是否给值加引号。
- 确保准确(如
业务知识
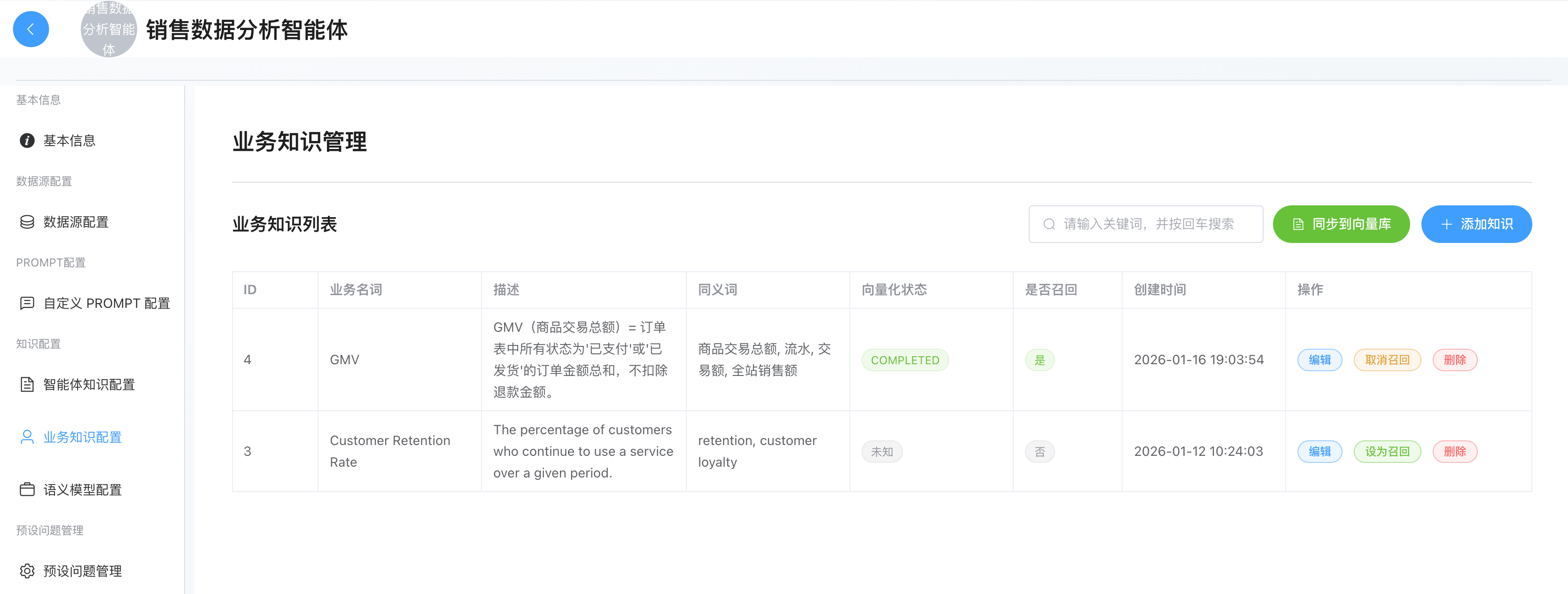
定位:
- 这是的专有业务逻辑字典 。解决"它是什么...? 它的计算规则是什么?"的问题,用于定义计算公式、专有名词和业务指标。注意,前面语义模型的业务名称侧重的是和表的映射,但是并不是所有的业务名词都会和表一一对应的。
- 比如当用户问"上个月的 GMV 是多少?"或者"高价值用户占比多少?"时,LLM 不知道 GMV 的公式,也不知道高价值用户的定义,这时需要业务知识召回(Recall)。
配置最佳实践:
- 业务名称:填写指标或术语的标准名称。
- *案例 :
GMV、复购率、高潜客户。
- *案例 :
- 描述 (Description) ------ 核心逻辑区
- 最佳实践:用自然语言清晰地描述计算公式、过滤条件或业务定义。
- GMV 案例:`GMV(商品交易总额)= 订单表中所有状态为'已支付'或'已发货'的订单金额总和,不扣除退款金额。
- 同义词
- 例 :
GMV的同义词:流水, 交易额, 全站销售额。
- 例 :
- 是否召回
- 务必开启。开启后,当用户的提问涉及这些词汇时,系统会通过向量检索将这段"描述"作为上下文注入给 Prompt,指导 SQL 生成节点写出正确的公式。
智能体知识库
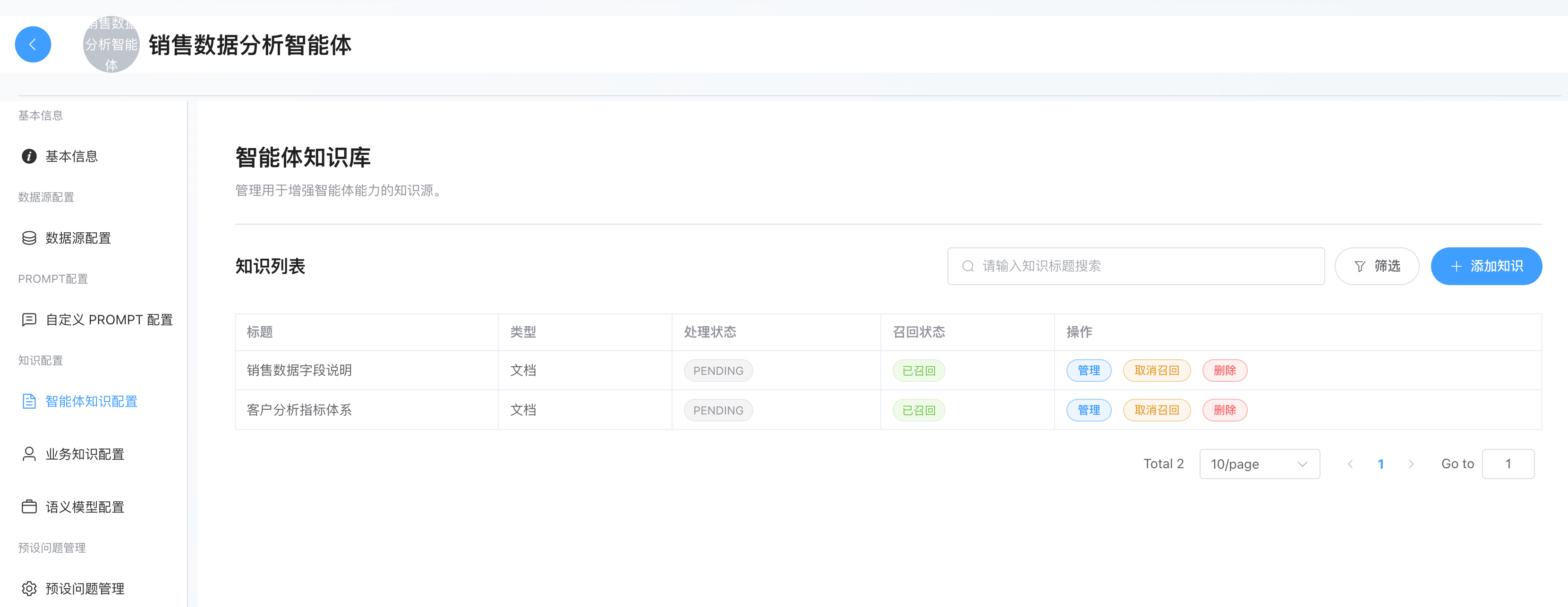
定位:负责业务场景的的知识扩充库(RAG)。支持非结构化文档上传,用于提供背景信息、行业知识、SOP 或历史案例。
配置最佳实践:
- A. 文档 (File Upload: PDF, DOCX, MD)
- 数据库Schema说明书:如果表结构极其复杂,语义模型写不下,可以上传一份详细的数据库设计文档。
- 业务流程SOP :帮助 Planner (规划节点) 理解业务流程,甚至更好地按你想要的步骤进行数据分析。例如你觉得Agent做的"销量预测"老是做不好,你们公司有自己的销量预测流程,第一步如何做,第二步如何...等等固定流程,此时你完全可以在文档写上 "如何进行销量预测的步骤",直接指定销量预测的流程。 强烈建议使用这个功能。当然你也可以放到Q&A问答对里面,或者把多个问答对塞到一个文档里面再上传。
- 行业报告:帮助 Report Generator (报告生成节点) 在生成最终 HTML 报告时,增加行业洞察和背景知识,而不只是单纯罗列数据。
-
B. 问答对/常见问题 (Q&A / FAQ) ------ ⭐ 调优神器
- 调优助手:当发现 Agent 对某类问题 SQL 生成总是错误时,不要反复改 Prompt,直接加一个 Q&A。
- 问题Q 回答A示例
markdown- **Q**: `查询去年的活跃用户数` - **A**: `活跃用户的定义是登录次数>3次。SQL逻辑应该是:SELECT count(distinct user_id) FROM login_logs WHERE login_time >= '2023-01-01' AND login_time <= '2023-12-31' GROUP BY user_id HAVING count(*) > 3`。
Text-to-SQL执行流程
查询意图识别 (IntentRecognitionNode)
- 由于用户可能会输出与问数完全无关的内容,比如:"你是谁?", "你叫什么名字?", "你能干什么?",那么系统需要过滤掉明显无效的请求,节约后续昂贵的计算资源。基于提示词识别出是闲聊的无关指令 还是 可能的数据分析指令
markdown
# 输出格式
分类名称必须是《闲聊或无关指令》或《可能的数据分析请求》
请严格按照以下JSON格式输出,不要有任何额外的解释、思维过程和说明,不要有json块(```json```)的输出标识。
\{"classification": "分类名称"\}
---
# 示例
## 示例1
【多轮输入】
用户: 查一下所有员工的工资
<最新>用户输入: 哈哈哈哈,太棒了!
# 输出
\{"classification": "《闲聊或无关指令》"\}
## 示例2
【多轮输入】
用户: 查一下所有员工的工资
<最新>用户输入: 他们呢?
# 输出
\{"classification": "《可能的数据分析请求》"\}业务知识库召回 (EvidenceRecallNode)
- 先进行查询问题重写:由于用户的多轮对话问题会存储在关联,因此需要指代消解、上下文补全等,比如:例子: "那个的销量如何" -> "A产品的销量如何",基于提示词进行查询问题重写
markdown
# 输出格式
请严格按照以下JSON格式输出,不要有任何额外的解释和说明,不要有json块(```json```)的输出标识。
\{"standalone_query": "重写后的完整句子"\}
---
# 示例
## 示例1 (指代消解)
【多轮输入】
用户: 帮我查一下上个月的退货率
AI: 上个月退货率是 5%。
<最新>用户输入: 那投诉率是多少?
# 输出
\{"standalone_query": "查询上个月的投诉率数据"\}
## 示例2 (上下文补全)
【多轮输入】
用户: 哪个部门花费最多?
AI: 研发部花费最多。
<最新>用户输入: 销售部呢?
# 输出
\{"standalone_query": "查询销售部的花费情况"\}- 通过"向量 + 关键词"进行融合查询召回业务知识(
business_knowledge)+ 智能体知识(agent_knowledge),后续注入 prompt,融合策略选择,默认RRF策略- 倒数排名融合 (Reciprocal Rank Fusion, RRF) :给每个文档分配一个基于排名的分值,排名越靠前分值越高,然后将多个搜索列表的分值累加。
- 线性加权融合 (Weighted Sum / Linear Combination):先将向量得分和关键词得分缩放到同一区间(如 0-1),然后按比例加权相加。
查询增强阶段**(QueryEnhanceNode)**
- 用于根据召回的知识库的信息把业务翻译,再通过LLM把用户的查询进行改写。
markdown
# 输出格式
你必须严格按照下面的JSON格式输出,不能有任何多余的解释。
\{
"canonical_query": "对用户最终意图的单一、清晰的重写,包含绝对时间和解析后的业务术语",
"expanded_queries": [
"基于完整信息的扩展问题表述 1",
"..."
]
\}
---
# 示例
[当前时间: 2025-11-08 11:11:12]
【参考信息 (Evidence)】: "核心用户"被定义为最近30天内消费总额超过5000元的用户。
【多轮输入】
<最新>用户输入: 帮我看看上个月的核心用户有多少
# 输出
\{
"canonical_query": "查询上个月(2025-10-01至2025-10-31)期间,消费总额超过5000元的用户数量",
"expanded_queries": [
"统计在2025年10月份,累计消费金额大于5000的客户总数是多少?",
"找出上个月消费超过5000元的核心用户有多少人"
]
\}
---
# 正式任务
[当前时间: {current_time_info}]
[参考信息 (Evidence): {evidence}]
【多轮输入】
{multi_turn}
<最新>用户输入: {latest_query}
# 输出数据库Schema召回**(SchemaRecallNode & TableRelationNode)**
- SchemaRecallNode 用上面增强的查询canonical_query从向量数据库召相关回表和列
- TableRelationNode 中用大模型精选出与问题相关的表,以及通过外键找到缺失的表,最终得到与问题相关的数据表和列(schema)
- 通过外键关系自动补全关联表:通过外键加载缺失的表和列,再次通过向量数据库精准召相关回表和列
- 获取逻辑外键:通过召回的表过滤出与其相关逻辑外键,并合并到对应表的外键中
- 通过LLM选择合适的表,在获取每个表的对应的语义模型,并存储到OverAllState上下文中
markdown
你现在是一位数据分析师,你的任务是分析用户的问题和数据库schema,数据库schema包括表名、表描述、表之间的外键依赖,每张表中包含多个列的列名、列描述和主键信息,现在你需要根据提供的数据库信息和用户的问题,分析与用户问题相关的table,给出相关table的名称。
[Instruction]:
1. 排除与用户问题完全不相关的table
2. 保留可能对回答用户问题有帮助的表
3. 结果输出一个JSON数组,但**不要使用任何多余的符号**,特别是Markdown标记
4. 直接输出结果,不要做多余的分析
以下样例供你参考:
【DB_ID】 station_weather
# Table: weekly_weather
[
(station_id::TEXT, 车站编号),
(day_of_week:TEXT, 星期, Examples: [Tuesday, Monday, Wednesday]),
(high_temperature:INT, 最高气温, Examples: [59, 55, 58]),
(low_temperature:INT, 最低气温, Examples: [54, 52, 55]),
(precipitation:DOUBLE, 降水量, Examples: [50.0, 90.0, 70.0]),
(wind_speed_mph:INT, 风速, Examples: [22, 14, 13])
]
【Foreign keys】
route.station_id=station.id
route.train_id=train.id
weekly_weather.station_id=station.id
===============
{schema_info}
【问题】
{question}
【参考信息】
{evidence}
【Answer】计划生成SQL指令 (PlannerNode)
-
结合上面的证据,以及数据库的schema和语义模型,LLM拿到了全面的业务信息和数据库信息了,可以做出比较完善和正确的计划。
-
第一步SQL_GENERATE_NODE:执行 SQL 查询以提取或聚合数据。这是分析的基础,下游指令SQLGenerateNode 将直接作为 SQL 生成专家的 Prompt。
-
第二步PYTHON_GENERATE_NODE: 给 Python 解释器的具体编程指令,当 SQL 难以满足需求时使用。适用于:复杂逻辑计算、数据清洗、高级统计分析、图表绘制。
-
第三部REPORT_GENERATOR_NODE:流程的最后一步。用于整合所有步骤的输出,回答用户最初的问题,并提供商业建议,报告的大纲、需要回答的关键问题和建议方向

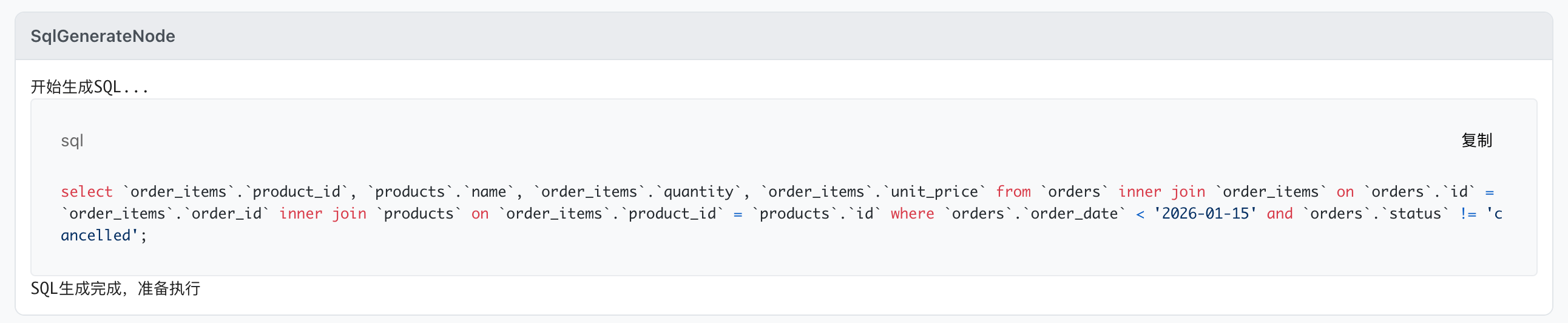
SQL 生成阶段 **(SQLGenerateNode) **
- 结合数据库 Schema (绝对事实)、业务知识 (参考)、全局任务背景 (用户原始问题)、上面第一步计划步骤 (生成的核心指令)来生产SQL
markdown
# 角色
你是一位精通 {dialect} 的高级数据工程师。
你的任务是根据【数据库 Schema】和【当前执行步骤】,编写一句高效、准确的 SQL 查询语句。
# 输入上下文
## 1. 数据库 Schema (绝对事实)
{schema_info}
*注意:你编写的 SQL 中所有表名和列名必须严格存在于上述 Schema 中,严禁臆造不存在的字段。*
## 2. 业务知识 (参考)
{evidence}
## 3. 全局任务背景 (用户原始问题)
{question}
*注意:这仅作为背景信息(例如用于提取原本问题中的具体时间范围、状态值等条件),不要直接试图通过一个 SQL 解决这个问题,你的工作只是完成下面的"当前步骤"。*
## 4. 当前执行步骤 (你的核心指令)
{execution_description}
*注意:这是你必须严格执行的任务。你的 SQL 必须完全匹配此步骤的意图(例如:如果步骤要求"按月统计",你的 SQL 必须包含 GROUP BY)。*
# 最终指令确认 (Critical)
不管【全局任务背景】多么复杂,你现在的唯一目标是**仅完成**以下任务:
**{execution_description}**
# 输出
输出格式:
仅输出 SQL 语句,**不要使用任何额外标记**,特别是Markdown的标记。不要在输出的sql中有任何的解释- 输出示例