历史:规则模式---》统计模型--》神经网络
规则模型(ELIZA 时代)的做法: 翻阅语法书 -> 查找"eat"是动词 -> 后面应该接名词 -> 查找食物列表 -> 随机填入"apple"。(即使填入"concrete(混凝土)"符合语法,但没意义)。
统计模型(N-gram 时代)的做法: 你完全不懂语法。你只是疯狂翻阅那本巨型账本,查找历史上大家说完 "I like to eat" 之后都接了什么词。
1.1 基于统计方法的语言模型
语言是概率的。
语言的概率性与认知的概率性也存在着密不可分的关系 。
语言模型(Language Models, LMs)旨在准确预测语言符号的概率。
术语:统计语言模型 (Statistical Language Model, SLM)
核心代表:N-gram 模型 (N-gram Model)。
定义: 它是一个通过计算概率来判断一句话是否"正常"的数学模型。 它不关心这句话的语法对不对(主谓宾),也不关心这句话的意思(语义),它只关心:"根据历史数据,这几个词凑在一起出现的概率有多大?"
统计模型的本质:它是基于"历史出现频率"的概率预测,而不是基于理解。
1.1.1 n-grams 语言模型
例子:


-
n-grams 具备对未知文本的泛化能力。但是,这种泛化能力会随着 n 的增大而逐渐减弱。在 n-grams 语言模型中,n 代表了拟合语料库的能力与对未知文本的泛化能力之间的权衡。
-
当 n 过大时,语料库中难以找到与 n-gram 一模一样的词序列,可能出现大量"零概率"现象;在 n 过小时,n-gram 难以承载足够的语言信息,不足以反应语料库的特性。因此,在 n-grams 语言模型中,n 的值是影响性能的关键因素。上述的"零概率"现象可以通过平滑(Smoothing)技术进行改善,具体技术可参见文献。
-
平滑技术
实质上就是杜绝0概率的出现



J&M 这本书提到的解决方案,本质上就是承认**"训练数据永远是不够的"。 通过平滑(Smoothing),特别是回退(Backoff)**机制,模型学会了在缺乏精确的高阶信息(N很大)时,灵活地借用低阶信息(N很小)来填补空白,从而解决了"零概率"问题。

缺点:

1.1.2 n-grams 的统计学原理
数学知识:



1.2 基于 RNN 的语言模型
1.2.1 循环神经网络 RNN









1.2.2 基于 RNN 的语言模型
训练的过程


结果如何得到


由于 RNN 模型循环迭代的本质,其不易进行并行计算,导致其在输入序列较长时,训练较慢。
1.3 基于 Transformer 的语言模型
1.3.1 Transformer
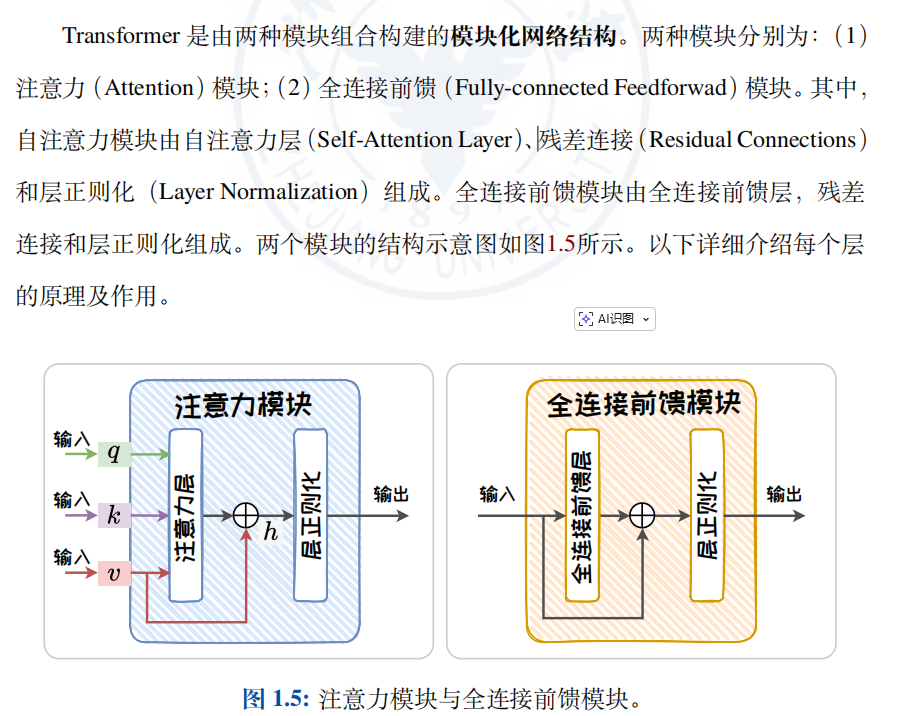







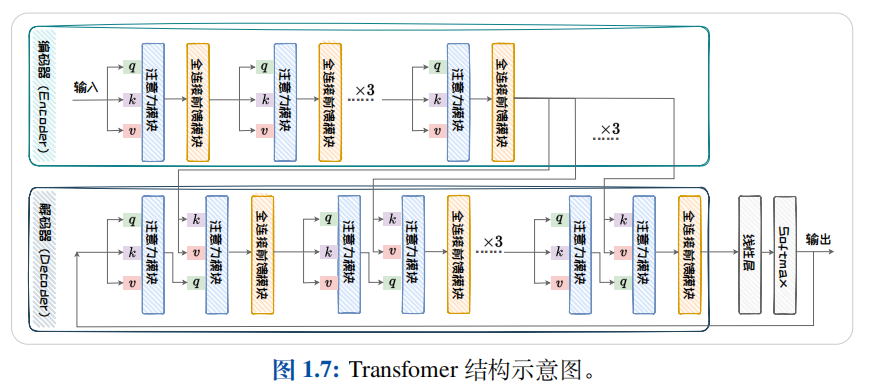
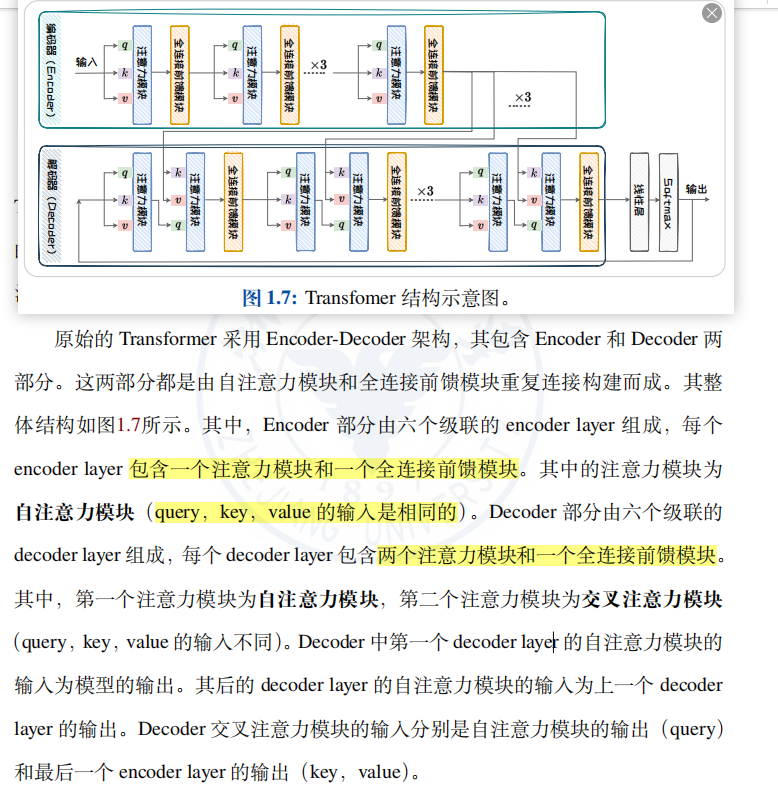
1.3.2 基于 Transformer 的语言模型

1.4 语言模型的采样方法
- 语言解码的方法

1.4.1 概率最大化方法

- 贪心搜索(Greedy Search)
-
- 波束搜索(Beam Search

- 波束搜索(Beam Search
1.4.2 随机采样方法

Top-K 采样可以有效的增加生成文本的新颖度
1.5 语言模型的评测

1.5.1 内在评测

1.5.2 外在评测

-
BLEU(BiLingual Evaluation Understudy)
核心定位:精度导向的评测指标,最初用于机器翻译任务。
核心逻辑:计算生成文本与参考文本在多层级 n-gram(单词、双词、多词组合)上的重合程度,取几何平均作为最终得分。
计算方式:分子为生成文本与参考文本匹配的 n-gram 数量,分母为生成文本中所有 n-gram 总数,再通过加权或长度惩罚项优化结果。
示例:若生成文本为 "big language models",参考文本为 "large language models",n=1 时重合度为 2/3,n=2 时重合度为 1/2,BLEU 会综合多维度 n-gram 精度计算得分。
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
核心定位:召回导向的评测指标,常用于文本摘要等生成任务。
核心逻辑:聚焦生成文本对参考文本关键信息的覆盖程度,主流包含四种变体,核心为 ROUGE-N 和 ROUGE-L。
ROUGE-N:基于 n-gram 的召回率计算,统计参考文本中 n-gram 被生成文本覆盖的比例。
ROUGE-L:基于最长公共子序列(LCS)计算,兼顾序列连续性,通过 F1 值平衡精确率和召回率。
计算方式:以 ROUGE-N 为例,分子为生成文本与参考文本匹配的 n-gram 数量,分母为参考文本中所有 n-gram 总数。
-
基于上下文词嵌入的方法:BERTScore
核心原理:利用 Encoder-only 架构模型(如 BERT)的上下文词嵌入能力,计算 "目标模型生成文本" 与 "参考文本" 的语义相似度,而非字面重合度。
具体步骤:
① 用 BERT 分别对生成文本(如摘要)和参考文本的每个 Token 进行编码,得到带上下文信息的向量(避免传统词嵌入 "一词一向量" 的局限性,如 "苹果" 在 "吃苹果" 和 "苹果手机" 中向量不同);
② 计算生成文本 Token 向量与参考文本 Token 向量的余弦相似度,取最大值作为 "单 Token 匹配分";
③ 对所有 Token 的匹配分取平均,得到 Precision(生成文本对参考文本的覆盖度)、Recall(参考文本在生成文本中的保留度)和 F1 值(综合指标),即 BERTScore。
优势:能捕捉语义层面的匹配(如 "大语言模型" 与 "大型语言模型" 语义相近,BERTScore 会给出高分,而 BLEU 可能因字面差异扣分),更贴近人类对 "语义一致性" 的判断;
局限:仍依赖 "参考文本"(若无参考文本则无法评估),且对 "裁判模型(如 BERT)的能力依赖较高"(若 BERT 无法理解专业领域文本,评估结果可能偏差)。
-
基于生成式评估的方法:G-EVAL、InstructScore
这类方法更灵活,无需参考文本,直接让 "裁判模型" 对生成结果进行开放式评分与解释,典型代表为 G-EVAL(用 GPT-4 作为裁判):
核心原理:通过 "Prompt 工程" 引导 "裁判模型" 按人类逻辑分步评估,输出量化分数与评估依据,适合无参考文本的场景(如创意写作、开放域问答)。
具体步骤(以 "评估摘要生成任务" 为例):
① 构造 Prompt 三部分:
任务描述与评分标准(如 "评分范围 1-10 分,1 分 = 信息缺失严重,10 分 = 完整覆盖原文核心信息且逻辑流畅");
评测步骤(让 GPT-4 生成 "先判断原文核心信息→再检查摘要是否覆盖→最后打分" 的思维链,即 CoT);
输入内容(原文 + 目标模型生成的摘要);
② 将 Prompt 输入 GPT-4,得到分数及 "为何打此分" 的自然语言解释;
③ (可选)对多次评分结果加权平均,降低随机性(如让 GPT-4 对同一摘要生成 3 次评分,取平均分为最终结果)。
延伸案例:InstructScore 在 G-EVAL 基础上增加 "多维度评分"(如同时评估 "准确性、流畅性、创造性"),且会输出详细的错误分析(如 "摘要遗漏了原文中'大模型参数高效微调'的核心方法")。
优势:
无需参考文本,适用于无标准答案的开放任务(如诗歌创作、商业文案生成);
能评估传统指标无法量化的维度(如逻辑性、创新性、伦理合规性);
输出的自然语言解释可辅助开发者定位目标模型的不足(如 "生成文本存在事实错误,混淆了 LLaMA 与 GPT 的架构差异")。