本专栏文章持续更新 ,新增内容使用蓝色表示。
Loki 是 Grafana Labs 开源的轻量级日志聚合系统,主打"低成本、易扩展、与 Prometheus 同语言"三大特点,适合云原生和 Kubernetes 场景。它像 Prometheus 存指标那样存日志------只给日志打标签、不做全文索引,因而极省资源。
架构
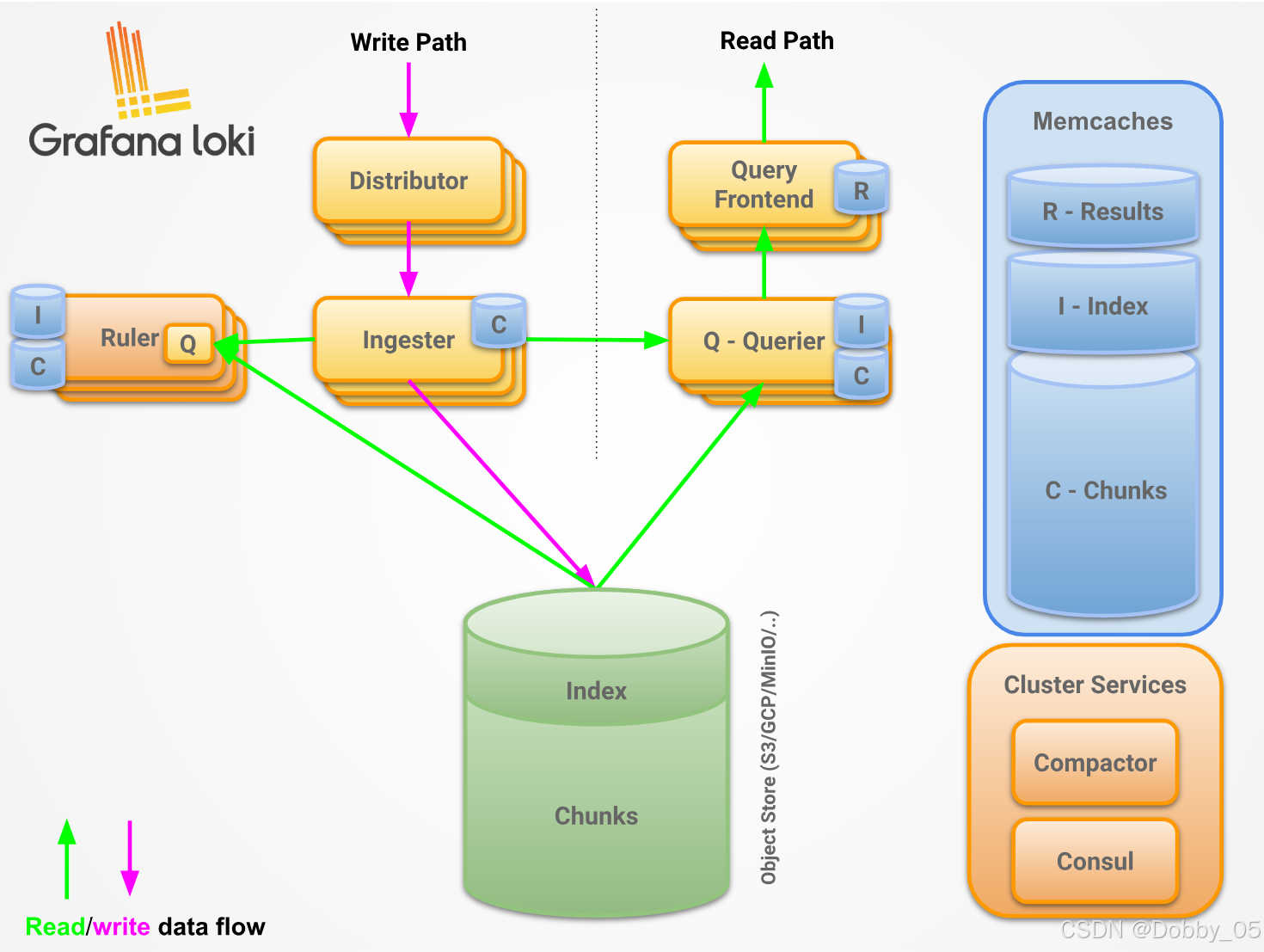
【补充】这个架构中 Distributor、Ingester、Querier 是必选组件,其余皆为可选组件。收集到的日志由 Distributor 进行简单处理,分发,Ingester 持久化,通过 Querier 查询,其余组件则是为了提升性能。
数据格式
Loki 在磁盘(或对象存储)里只有两类实体文件:index 和 chunk。

chunk
真正保存日志文本。
文件名:{ tenant }/{ shard }/{ fingerprint }-{ from }-{ through }.{ checksum }.gz
内容:同一个"流(stream)"在一段时间内的所有日志行,按时间顺序追加成块,压缩后落盘。
时间切分:默认 1 h 或 2 GB 触发新 chunk,旧 chunk 只读。
index
保存"标签 → 流 ID → 时间区间 → chunk 文件路径"的倒排映射。
文件名:boltdb / tsdb / 对象存储中的 { table }/{ hash }.{ uid }
内容:{ labels_hash, stream_id, chunk_id, from_unix, through_unix, checksum },查询时先根据标签找到 stream_id,再按时间区间定位到 chunk 文件名,最后去对象存储把 chunk 拉回来顺序扫描。
流(stream) 的生成规则:
对每条日志的标签集合做 fnv64a(labels) 得到 stream fingerprint;这个 fingerprint 就是"流 ID";只要标签 kv 完全相同,就复用同一个 stream,后续日志追加到同一个 chunk;标签哪怕只变一个值,就会得到新的 fingerprint,于是落到新的 chunk。
因此:不同 kv → 不同 fingerprint → 不同 stream → 不同 chunk;
相同 kv → 相同 fingerprint → 相同 stream → 同一个 chunk(直到时间/大小阈值触发新 chunk)。
组件
Distributor
必需。
功能:接收客户端推送的日志数据进行初步处理。
工作流程:
1)Distributor 实例接收带有日志流和日志行的 HTTP POST 请求,进行格式/语义校验(Validation)
-
检查 JSON/Protobuf 是否合法。
-
确保标签符合 Prometheus 标签规范。
-
时间戳限制:拒绝太旧(超出保留期)或太新(未来时间)。
-
日志长度限制。
失败直接返回 4xx,不进入下一步。
2)标签规格化(Normalization)
a. 把标签按 key 排序并去重,保证同一 stream 的哈希值始终一致。
b. 补充/覆盖内置标签(如 tenant_id)。
c. 生成最终的"stream 指纹"(labels + tenant)。
此处是 distributor 唯一会修改数据的地方。
3)速率限制(Rate Limiting)
以 tenant 为维度,检查"每秒 stream 数""每秒条目数""每秒字节数"三类配额。超限就丢弃并返回 429,同时把超限指标打到 rate_limit_discarded_bytes_total 等指标里,避免浪费后端资源。
4)分发/并发写(Replication & Fan-out)
a. 根据 stream 指纹→ 得到 64 bit 哈希值(默认 FNV-1a 算法)。
通过一致性哈希环查找,从该 token 开始,顺时针挑选 replication_factor (默认 3)个不同 ingester 的 token。
b. 并发向这 3 个 ingester 发起 gRPC Push 请求。
成功数 ≥ quorum = floor(replication_factor / 2) + 1 → Distributor 返回 204(写成功)。3 个全失败或超时(默认 2 s)→ 5xx,客户端重试。
【补充】若开启 distributor ring sharding,先算第二层哈希,决定"这条流归哪一组 Distributor 负责",防止 N 个 Distributor 重复写 3×N 份。
Ingester
必需。
功能:有状态写缓冲 + 热数据读缓存
1)写入路径(Write Path)
Distributor 并发 gRPC Push → Ingester 校验时间戳 → 写 WAL(预写日志) → 写内存 chunk → 周期刷对象存储(S3、GCS、Azure Blob 等)。
【补充】
-
乱序数据默认拒绝,显式开启 unordered_writes 后可接受一定时间窗口(max_chunk_age / reject_old_samples_max_age)内的乱序写入。
-
刷盘阈值:chunk_idle_period 30 min 或 chunk_target_size 2 MB 或 chunk_age 1 h 先到先刷。
2)读取路径(Read Path)
Querier 带 时间范围 + 标签 来 → Ingester 内存扫描 → 返回 尚未上传对象存储 的日志行 → Querier 和对象存储结果 合并/去重 后给前端。
生命周期管理:
|-----------|-------------------------------|----------|-------------|
| 状态 | 说明 | 读写权限 | 典型场景 |
| PENDING | 等待从 LEAVING 状态的 ingester 接管数据 | 不可读写 | 传统部署模式(已弃用) |
| JOINING | 正在向哈希环注册 tokens 并初始化 | 可写入 | 新实例启动时 |
| ACTIVE | 完全初始化就绪 | 可读写 | 正常运行期间 |
| LEAVING | 正在关闭/下线 | 可读取 不可写入 | 优雅关闭、滚动升级 |
| UNHEALTHY | 心跳失败,被 distributor 标记 | 不可读写 | 实例故障、网络问题 |
【补充】每个 ingester 拥有多个 token,所有 token 按值从小到大排列成环。
Query frontend
可选。
功能:把"一个大查询"拆成"N 个时间段小查询" + 内存队列 + 缓存层。防止大查询打爆单个 Querier、实现多租户公平调度、顺带缓存索引/空结果/日志量。
Client
│
▼
Query Frontend (拆分 + 缓存命中检查)
├─▶ 缓存命中 → 直接返回(Metric/Index Stats/Log Volume)
└─▶ 缓存未命中 → 拆成 N 个"子查询任务"→ 本机内存队列
│
▼
Querier (不断轮询队列,拉任务 → 并发查 Ingester/Store Gateway)
│
▼
Query Frontend (聚合子结果 → 再次缓存 → 返回 Client)【补充】没有独立 Query Scheduler 时,QF 自己当生产者 + 队列;Querier 当消费者;
| 缓存项 | 存储位置 | 命中场景 | 备注 |
|---|---|---|---|
| Metric 查询结果 | QF 内存 / Redis | 相同 PromQL + 时间区间 | 单存储 TSDB 模式 |
| Index Stats | QF 内存 / Redis | 相同标签选择器 + 时间区间 | 估算待查块数量 |
| Log Volume | QF 内存 / Redis | 相同标签选择器 + 时间区间 | 估算日志条数 |
| Log 空结果(负缓存) | QF 内存 | 相同标签 + 时间区间返回 0 条 | 避免重复进 Store Gateway |
Query schduler
可选。
功能:把 Query Frontend 的本地内存队列拆出来变成中央队列,使得 Frontend 彻底无状态(可运行多个副本保证高可用性,一般两个),Querier 也可以水平扩展。
Querier
必需。
功能:解析和执行 LogQL 语言,优先查询 ingester(热),补充查询持久化存储(冷),且会对结果进行去重处理(相同纳秒时间戳、标签集和日志消息的数据)。
工作模式:
-
独立模式:直接接收客户端 HTTP 查询。
-
协作模式:从 Query Frontend/Scheduler 拉取任务(微服务部署)。
Index Gateway
可选但建议。
功能:处理和提供元数据查询,块(chunk)的索引表由 Index Gateway 缓存、分片、快速返回。
Query frontend 会向 index gateway 查询查询的日志量,以便决定如何分片查询。
Querier 会向 index gateway 查询给定查询的块引用,以便获取和查询。
工作模式:
|--------|-------------------|------------------|
| 维度 | Simple 模式 | Ring 模式 |
| 架构 | 单层,无分片 | 分布式哈希环分片 |
| 数据分布 | 每个实例全量数据 | 数据分片到不同实例 |
| 适用规模 | 中小规模(索引 < 100GB) | 大规模(索引 > 100GB) |
| 扩展性 | 垂直扩展为主 | 水平扩展 |
| 容错性 | 单点故障影响大 | 分片副本,高可用 |
| 配置复杂度 | 简单 | 复杂,需配置哈希环 |
【补充】Simple 模式下,每个IGW都有环的完整视图。Ring 模式下每个 IGW 仅缓存自己分片的索引,但通过 Memberlist 仍持有整个哈希环的拓扑视图,用于请求路由与副本选择
Compactor
可选但建议。
功能 *:*把 Ingester 当日产生的多个小索引文件合并成一份大文件,并删除已过期数据,从而节省对象存储成本、提高查询速度。
| 级别 | 输入 | 输出 | 效果 |
|---|---|---|---|
| 索引压缩 | 每 ingester 周期性地刷小 boltdb/tsdb 文件(默认15 min/ 2GB) | 单表 大 boltdb/tsdb(默认 24 h 合并一次) | 元数据文件数从 N×1000 降到 N×1,Index Gateway 启动时间从 10 min → 1 min |
| chunk 压缩 | 原始 未压缩 or snappy 块 | zstd 重压缩(可选) | 对象存储体积再省 30 %~60 % |
| 过期删除 | 全量 chunk + 索引 | 保留期内数据 | 按 ** retention ** 自动删,S3 请求费用同步下降 |
Ruler
功能:按照用户写的 LogQL 规则周期性跑查询,一旦满足阈值就产生 Alertmanager 格式的告警。
| 模式 | 调用链 | 场景 | 优缺点 |
|---|---|---|---|
| 本地评估 | Ruler → 直接 Querier → Ingester/Store | 规则 <100 条、开发测试 | 部署简单,无 QF 也能跑;大查询容易把 Querier 打满 |
| 远程评估 | Ruler → Query Frontend → Querier | 生产默认 | 利用 QF 的队列+缓存,防止并发规则把后端冲垮;延迟稍高 |
| 哈希环分片 | Ruler 自己加入环,按 rule-group-name 哈希 | 规则 >1k 条 | 水平扩容,单 Ruler 只跑分片内的规则,内存/CPU 线性下降;需配 memberlist |
如有问题或建议,欢迎在评论区中留言~