一、Redis基础
1.1Redis特性
1、速度快:Redis所有数据都是存放在内存的;Redis是用C语言实现的,更接近操作系统;Redis使用了单线程,可以预防多线程可能产生的竞争问题
2、基于键值对的数据结构服务器:Redis的值不仅可以是字符串,还可以是数据结构(String、hash、list、set、ordered set)
3、功能丰富:键过期(实现缓存)、发布订阅(实现消息系统)、Lua脚本(创造新的Redis命令)、事务、流水线(减少网络开销)
4、简单稳定:源码量少、单线程模型、无依赖第三方类库
5、客户端语言多:支持C/C++、Java、Python等主流语言
6、持久化:RDB+AOF双机制(将数据保存在硬盘中)
7、主从复制:支持数据副本同步
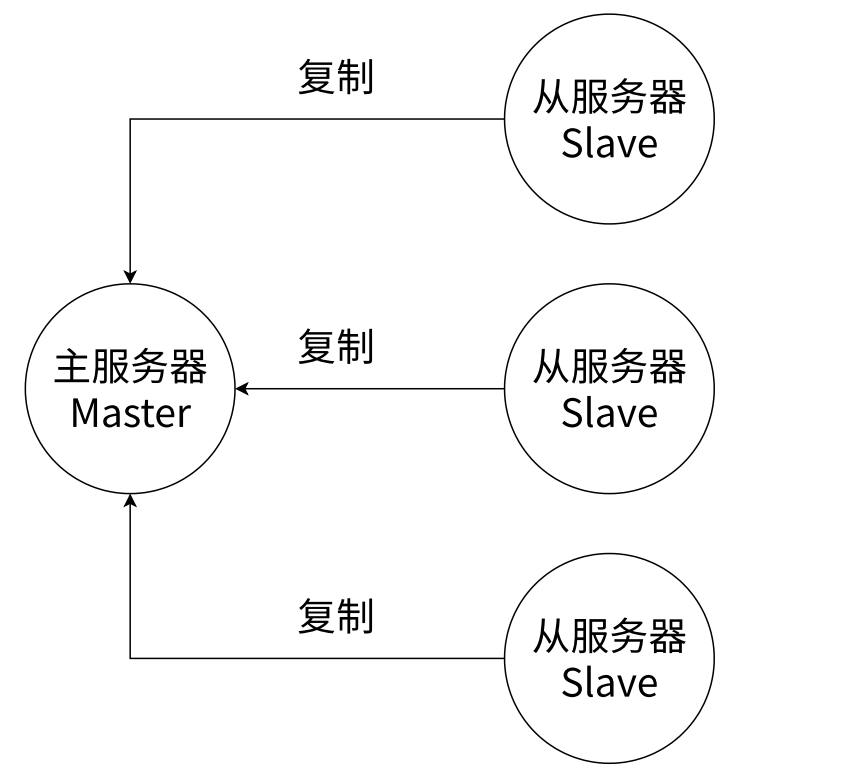
8、高可用与分布式:哨兵(保证Redis结点的故障发现和故障自动转移)+集群(真正的分布式实现、提供了高可用、读写和容量的扩展性)
1.2使用场景和边界
适用场景:缓存、排行榜系统、计数器、社交网络、消息队列系统
不适用场景:大规模冷数据存储(内存成本高)、复杂关系查询(无联表能力)
1.3版本选择
版本选择规则:偶数稳定(生产首选)、奇数开发
二、Redis常见数据类型
2.1通用命令
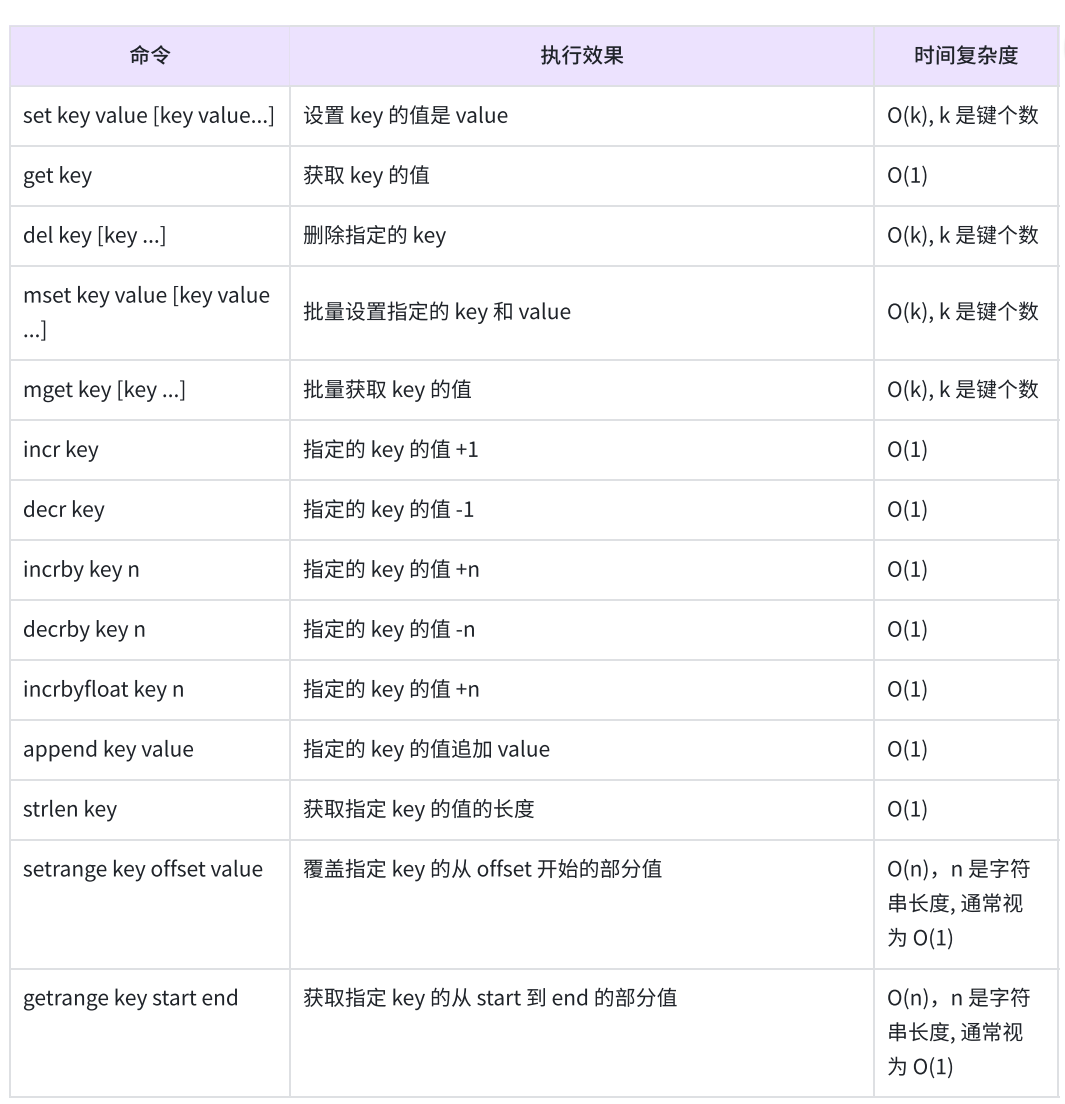
keys pattren:匹配所有符合规则的键(O(n),生成慎用)
exists keykey ... :判断某个key是否存在(O(1))
del keykey ... :删除指定的key(O(1))
expire key seconds :为指定的key添加秒级过期时间(O(1))
ttl key :获取指定key的过期时间,秒级(O(1))
type :返key对应的数据类型(O(1))
2.2 String字符串
注意:Redis中所有键的类型都是String类型
Redis内存存储字符串完全是按照二进制流的形式保存的,所以Redis不处理字符集编码问题,存储客户端传入的字符集编码
1、常见命令
set:将String类型的Value设置到key中,如果存在就会覆盖
set key value expiration EX seconds \| PX milliseconds NX \| XX
EX seconds------使用秒作为单位设置key的过期时间
PX miliseconds------使用毫秒为单位设置key的过期时间
NX------只在key不存在时才设置
XX------只在key存在时才设置
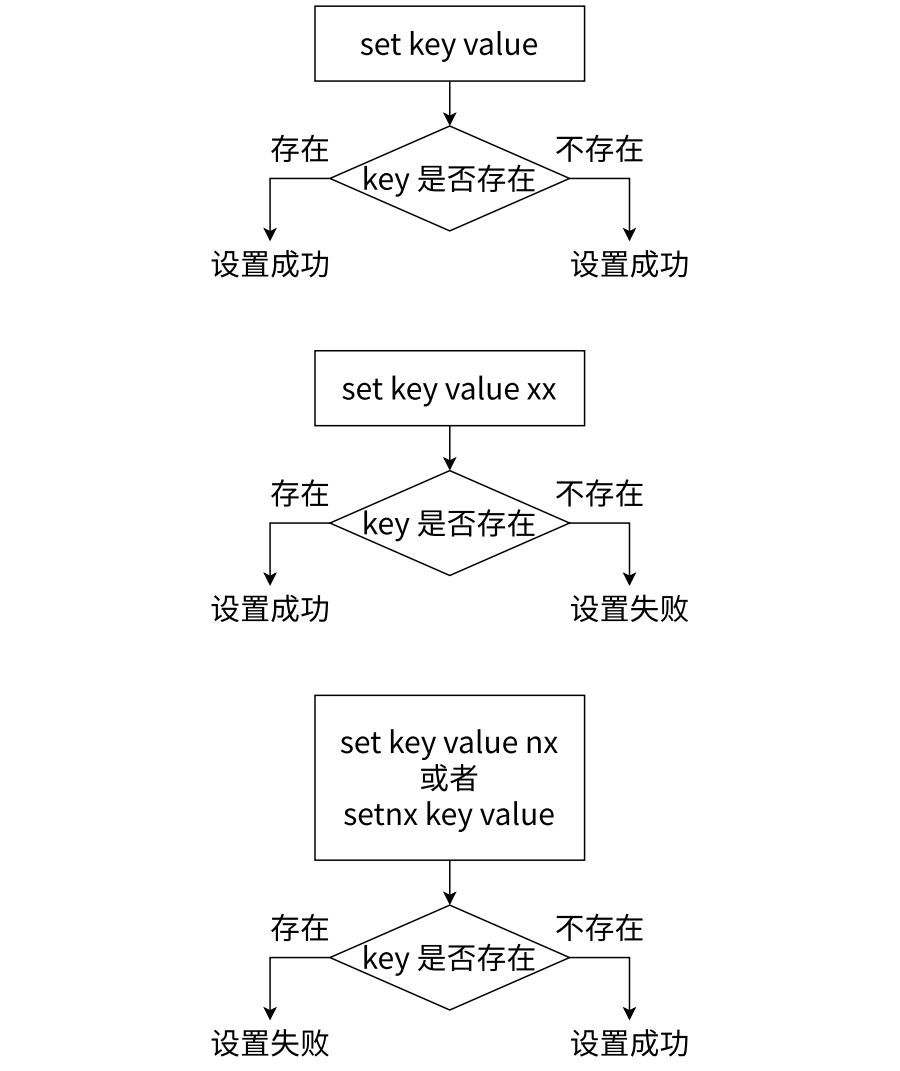
get:获取key对应的value,如果key不存在,返回nil;如果value的数据类型不是String会报错
get key
mget:一次性获取多个key的值,如果对应的key不存在或者对应的数据类型不是String,返回nil
mget key key ...
mset:一次性设置多个key的值
mset key value key value ...
incr:将key对应的String表示的数字+1。如果key不存在,视key对应的value是0,如果key对应的String不是一个整型或者范围超过了64位有符号整型,则报错
incr key
incrby:将key对应的String表示的数字加上对应的值。如果key不存在,则视key对应的value是0;如果key对应的String不是一个整型或者范围超过了64位有符号整型则报错
incrby key decrement
decr :将key对应的String表示的数字减1(限制同上)
decr key
decrby :将key对应的String表示的数字减去对应的值(限制同上)
decrby key decrement
incrbyfloat:将key对应的String表示的浮点数加上对应的值
incrbyfloat key increment
append:如果key已经存在并且是一个String,命令会将value追加到原有String的后边,如果key不存在,则效果等同于set命令
append key value
getrange:返回key对应的String的子串,由start和end确定(左右都闭)
getrange key start end
注:-1代表倒数 第一个字符,超过范围的偏移量会根据String的长度调整
setrange:覆盖字符串的一部分,从指定的偏移开始
setrange key offset value
strlen:获取key对应String的长度,当key存放的类型不是String时报错
strlen key
2、内部编码
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39字节的字符串
3、命令总结
2.3Hash哈希
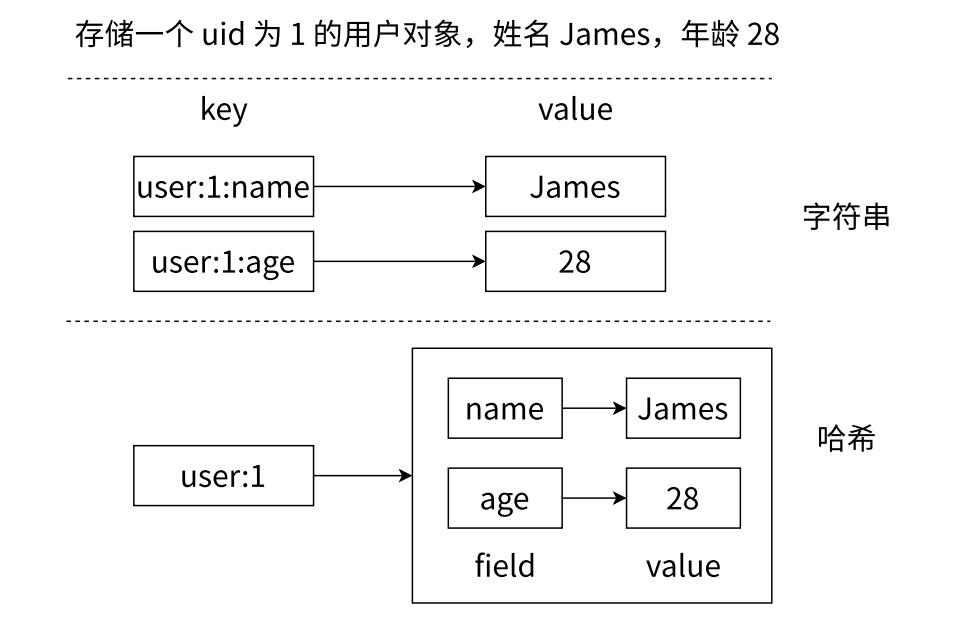
字符串和哈希类型对比:
1、命令
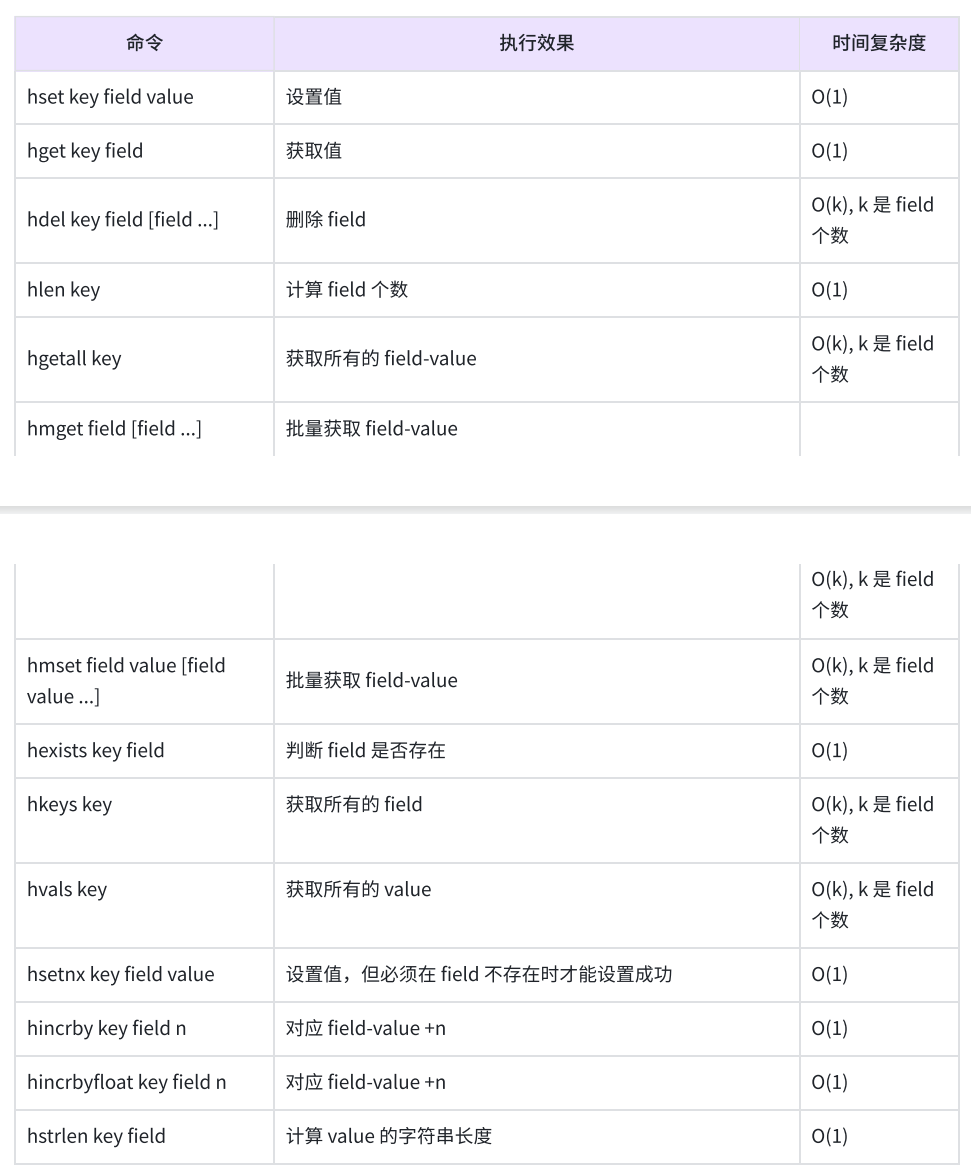
hset:设置hash中指定的字段(field)的值(value)
hset key field value field value ...
hget:获取hash中指定字段的值
hget key field
hexists:判断hash中是否有指定的字段
hexists key field
hdel:删除hash中指定的字段
hdel key field field ...
hkeys:获取hash中的所有字段
hkeys key
hvals:获取hash中的所有值
hvals key
hgetall:获取hash中的所有字段以及对应的值
hgetall key
hmget:一次获取hash中多个字段的值
hmget key field field ...
hlen:获取hash中所有字段的个数
hlen key
hsetnx:在字段不存在的情况下,设置hash中的字段和值
hsetnx key field value
hincrby:将hash中字段对应的数值添加指定的值
hincrby key field increment
hincrbyfloat:hincrby的浮点数版本
hincrbyfloat key field increment
2、内部编码
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、 同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现
3、命令总结
2.4 List列表
1、命令
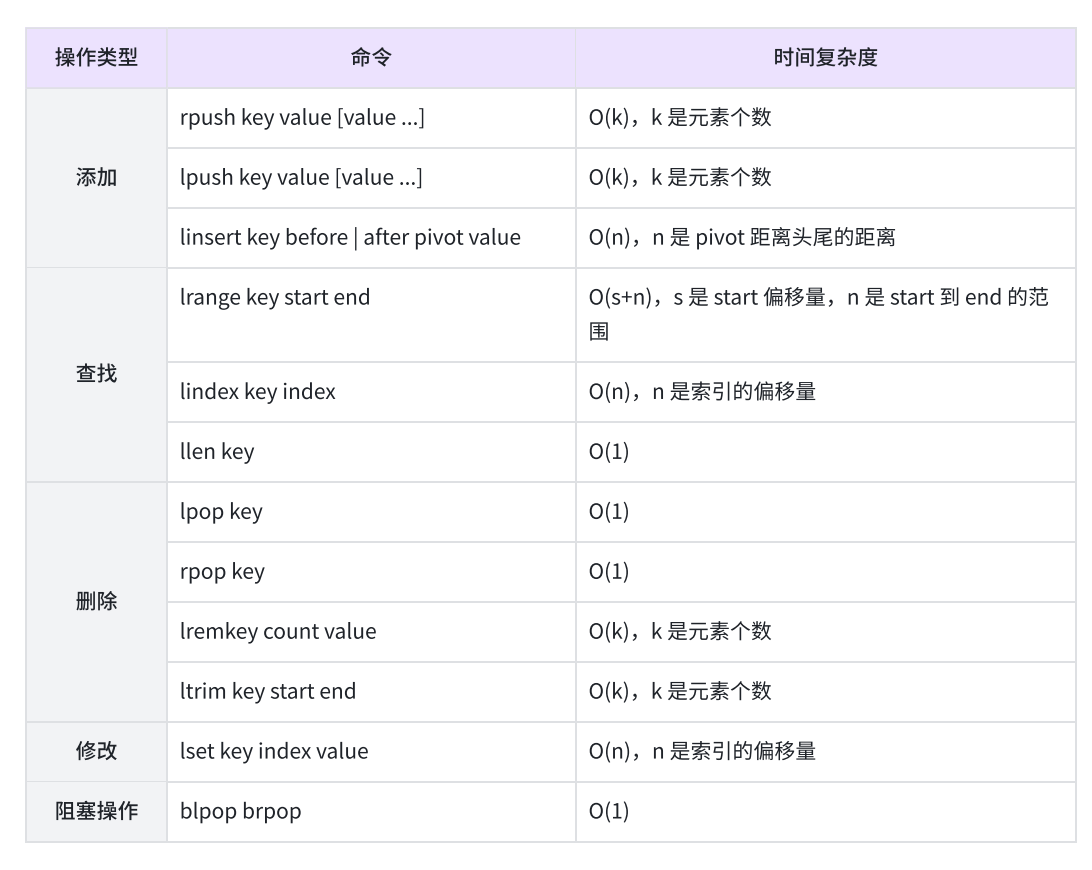
lpush:讲一个或多个元素从左侧放入(头插)到List中
lpush key element element ...
返回List的长度
lpushx:当key存在的时候将一个或者多个元素头插到List中,不存在的话直接返回(注意与lpush的区别)
lpush key element element ...
rpush:将一个或者多个元素尾插到List中
rpush key element elelment ...
rpushx:当key存在时,将一个或者多个元素尾插到List中
rpushx key element element ...
lrange:获取从start到end区间的所有元素,闭区间
lrange key start end
lpop:从 List左侧取出元素(头删)
lpop key
rpop:从List右侧取出元素(尾删)
rpop key
lindex:获取从左数第index位置的元素
lindex key index
linsert:在特定位置插入元素
linsert key <before | after> pivot element
返回插入之后的List的长度
llen:获取List长度
llen key
2、阻塞版本命令
blpop和brpop是lpop和rpop的阻塞版本,和对应非阻塞版本的作用基本一致,但是要注意以下不同之处:
(1)列表有元素:阻塞和非阻塞结果表现一致
(2)列表为空:非阻塞版本会立即返回nil,而阻塞版本会根据timeout阻塞一段时间,这段时间之内Redis可以执行其他命令,如果在这个timeout时间段中加入新元素,那么就和对应非阻塞版本的结果表现不一致
(3)命令中如果设置了多个键,会从左到右进行遍历键,一旦有一个键对应的列表中可以弹出元素就立即返回
(4)如果多个客户端同时对一个键执行pop,最先执行命令的客户端会得到弹出的元素
blpop key key ... timeout
brpop key key ... timeout
3、内部编码
ziplist(压缩列表);linkedlist(链表)
4、命令总结
Redis中的List是一个双端队列
同侧存取(lpush+lpop 或者 rpush+rpop)为栈
异侧存取(lpush+rpop 或者 rpush+lpop)为队列
2.5 Set集合
集合的元素之间是无序的,元素不允许重复,Redis支持集合的增删查改操作也支持交、并、差集。
1、命令
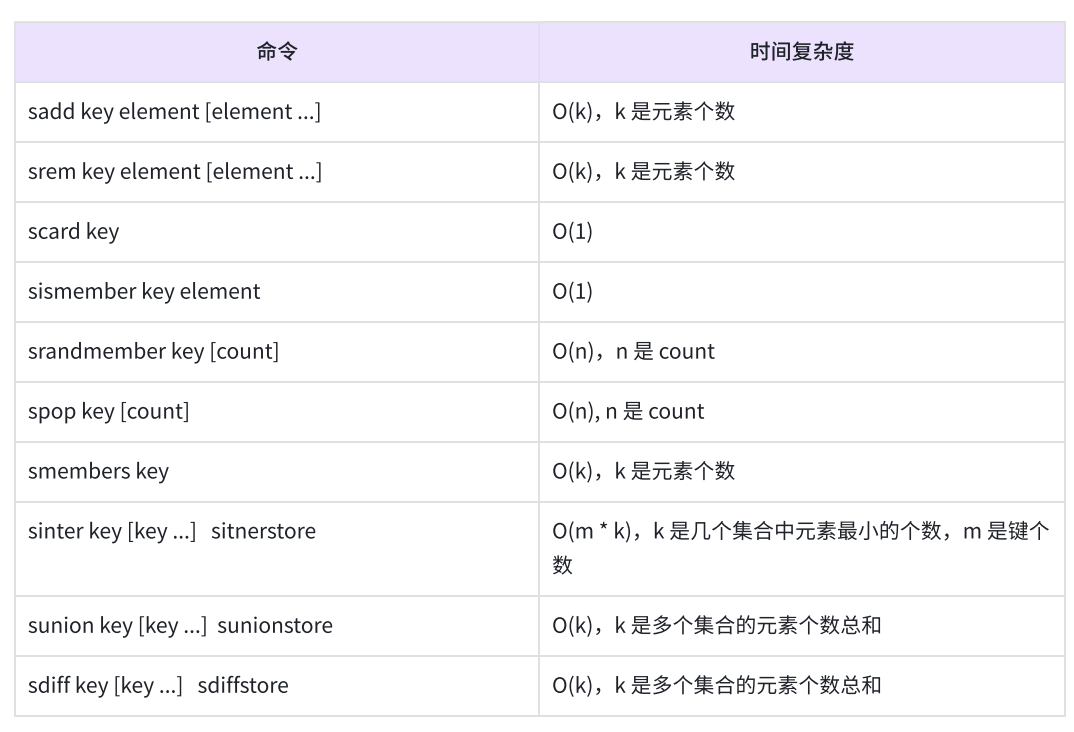
sadd:将一个或者多个元素添加到Set中,重复的元素无法添加到Set中
sadd key member member ...
返回本次添加成功的元素个数
smembers:获取一个Set中的所有元素,元素之间是无序的
smembers key
返回所有元素的列表
sismember:判断一个元素在不在Set中
sismember key member
1表示在,0表示不在或者key不存在
scard:获取一个Set的基数,即Set中的元素个数
scard key
spop:从Set中删除并返回一个或者多个元素。(由于Set内的元素是无序的,所以取出哪个元素实际是未定义行为,可以看作是随机的)
spop key count
smove:将一个元素从源Set取出并放入目标Set中
smove source destination member
srem:将指定的元素从Set中删除
srem key member member ...
2、集合间操作
sinter:获取给定Set的交集中的元素
sinter key key ...
返回交集的元素
sinterstore:获取给定Set的交集中的元素并保存到目标Set中
sinterstore destination key key ...
返回交集的元素个数
sunion:获取给定Set的并集中的元素
sunion key key ...
sunionstore:获取给定Set的并集中的元素并保存在目标Set中
sunionstore destination key key ...
sdiff:获取给定Set的差集中的元素
sdiff key key ...
sdiffstore:获取给定Set差集中的元素并保存在目标Set中
sdiffstore destination key key ...
3、命令总结
4、内部编码
intset(整数集合):当元素个数较少且都为整数时,内部编码为intset
hashtable(哈希表):当元素个数超过512个/当存在元素不是整数,内部编码为hashtable
2.6 Zset集合
有序集合保留了集合不能有重复成员的特点,但不同的是,有序集合中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,这样有序集合中的元素就可以维护有序性,但这个有序不是用下标作为依据而是使用这个分数的。
有序集合中的元素不能重复,但分数允许重复,类比于一次考试,每个人有唯一的分数,但分数允许相同。
1、命令
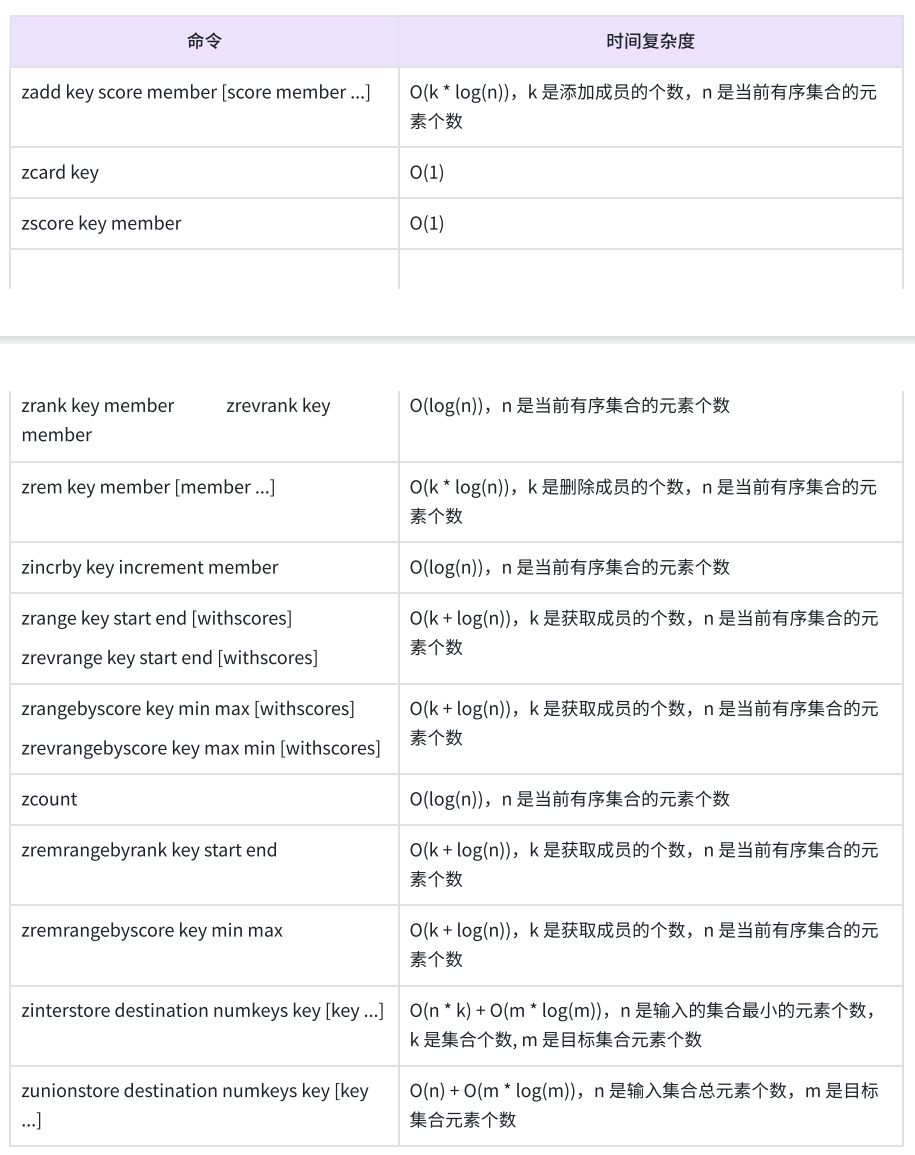
zadd:添加或者更新指定元素以及关联分数到Zset中,分数应该符合double类型,+inf/-inf作为正负极限也是合法的
zadd key NX \| XX GT \| LT CH INCR score member score member ...
返回本次添加成功的元素个数
XX:仅用于更新已经存在的元素,不会添加新元素NX:仅用于添加新元素,不会更新已经存在的元素
CH:默认情况下,zadd返回的是本次添加的元素个数,但指定这个选项之后,还会包含本次更新的元素个数
INCR:此时命令类似zincrby的效果,将元素分数加上指定的分数,此时只能指定一个元素和分数
zcard:获取一个zset的基数,即zset中元素的个数
zcard key
zcount:返回分数在min和max之间的元素个数,默认闭区间,可以使用( 排除
zcount key min max
zrange:返回指定区间里的元素,分数按升序,带上withscores可以把分数也返回
zrange key start stop withscores
zrevrange:返回指定区间里的元素,分数按照降序,带上withscores可以把分数也返回
zrevrange key start stop withscores
zrangebyscore:返回分数在min和max之间的元素,默认闭区间,可以使用( 排除
zrangebyscore key min max withscores
zpopmax:删除并返回分数最高的count个元素
zpopmax key count
返回分数和元素列表
bzpopmax:zpopmax的阻塞版本
bzpopmax key key ... timeout
zpopmin:删除并返回分数最低的count个元素
zpopmin key count
bzpopmin:zpopmin的阻塞版本
bzpopmin key key ... timeout
zrank:返回指定元素的排名,升序
zrank key member
zrevrank:返回指定元素排名,降序
zrevrank key member
zscore:返回指定元素的分数
zscore key member
zrem:删除指定的元素
zrem key member member ...
返回本次操作删除的元素个数
zremrangebbyrank:按照排序升序删除指定范围的元素,闭区间
zremrangebyrank key start stop
返回本次操作删除的元素个数
zremrangebyscore:按照分数删除指定范围的元素,闭区间
zremrangebyscore key min max
返回本次操作删除的元素个数
zincrby:为指定的元素的关联分数添加指定的分数值
zincrby key increment member
返回增加后元素的分数
2、集合间操作
zinterstore:求出给定有序集合中元素的交集并保存在目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
zinterstore destination numkeys key key ... weights weight \[weight ... ] aggregate \
返回目标集合中的元素个数
zunionstore:求出给定集合中的元素的并集并保存在目标有序集合中
zunionstore destination numkeys key key ... weights weight \[weight ... ] aggregate \
返回目标集合中的元素个数
3、命令总结
4、内部编码
ziplist(压缩列表):当元素个数较少且每个元素较小时,内部编码为ziplist
skiplist(跳表):当元素个数超过128或者某个元素大于64字节时,内部编码为skiplist
2.7渐进式遍历
Redis使用scan命令进行渐进式遍历,解决直接使用keys获取键时可能出现的阻塞问题
scan cursor MATCH pattern COUNT count TYPE type
返回下一次scan的游标(cursor)以及本次得到的键
渐进式遍历scan虽然解决了阻塞问题,但是如果在遍历期间键有所变化(增加、修改、删除),可能导致遍历时键的重复遍历或者遗漏