本文主要讲在LLM中RL的应用。
文章目录
- 前言
- 一、LLM模型论文解读
-
- [1.1 kimi 1.5](#1.1 kimi 1.5)
- [1.2 Deepseek R1](#1.2 Deepseek R1)
- [1.3 S1](#1.3 S1)
- 二、深度解析GRPO
-
- [2.1 推导GRPO](#2.1 推导GRPO)
- 总结
前言
合成数据与model collapse
在介绍LLM中RL的应用前,先来讲一下LLM中的一些问题和技巧;
1)介绍一下Nature调研正刊的文章;
这篇文章有兴趣大家可以去读一下,论文通过控制变量(是否包含真实数据):加10%的真实数据和完全使用合成数据的两组,分别在数据集上训练得到如下的结果: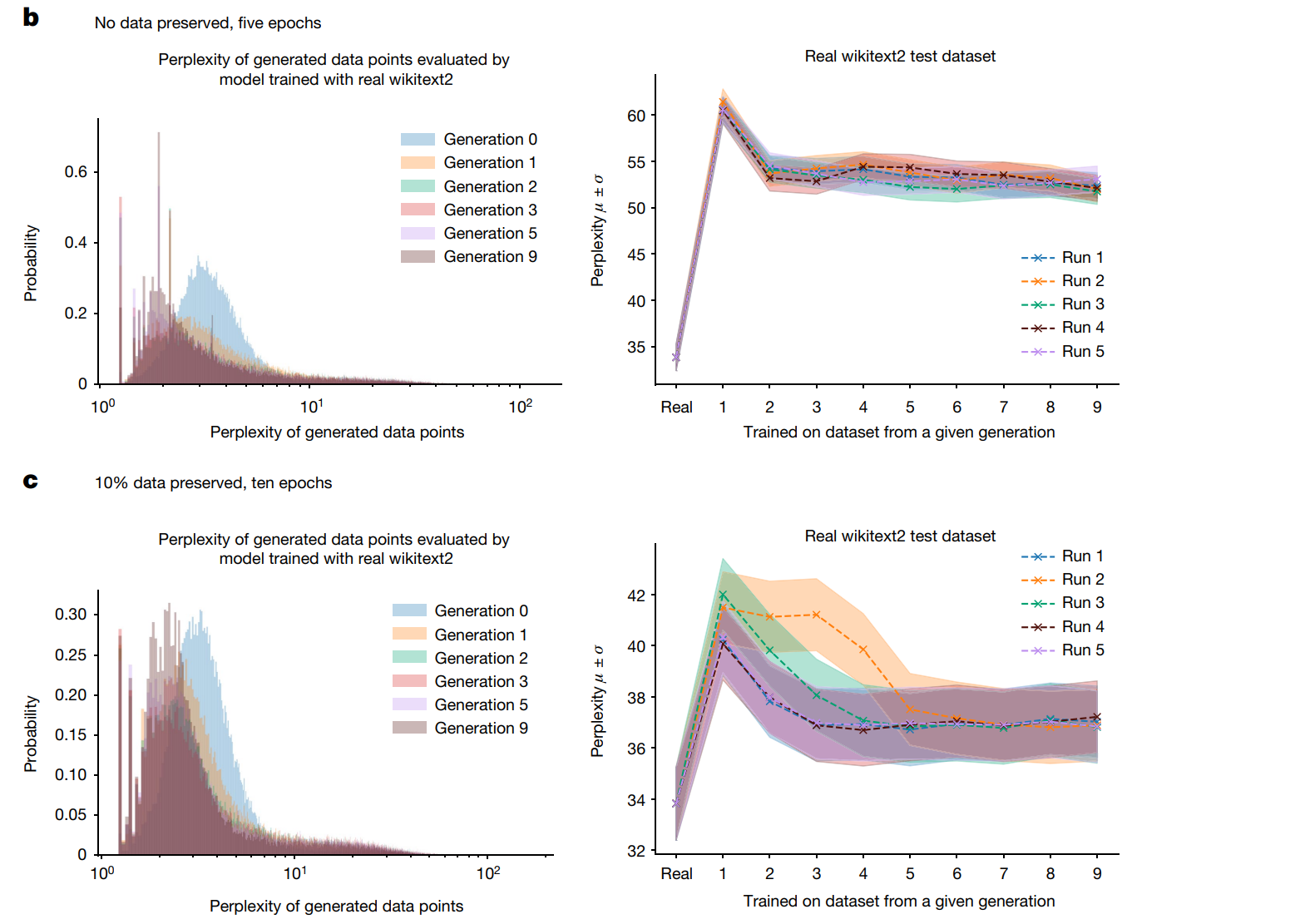
b组完全使用生成数据,c组添加10%的真实数据,可以从图中看出两组的表现从generation0-generation9,PPL都在降低,这是一个好的现象,b组的分布比c组的分布均值降低的更多,代表高概率事件被高估了;而且b组数据的尾部在变长(比c组更加明显),代表它生成了一些数据里没有的(比如不符合逻辑的句子)样本,这无疑是不合理的;
大语言模型和强化学习结合的优势在于强化学习算法,能够生成一些数据,在基于专家数据学习的基础上,能够继续提升表现,从而能够获得一个超越人类表现的模型;递归的去从模型生成数据再去训练模型会有问题,高概率的事件会被高估,低概率的事件会被低估,从而导致数据的分布发生改变;此外,现在大量LLM模型生成了大量AIGC数据,在公共数据已经混入大量的AIGC数据;
2) Model generate 之 beam search decoding strategy;
beam search
也称为束搜索,和贪心搜索不同,以输出一个句子为例,贪心搜索每次选择的都是输出中概率最大的词语;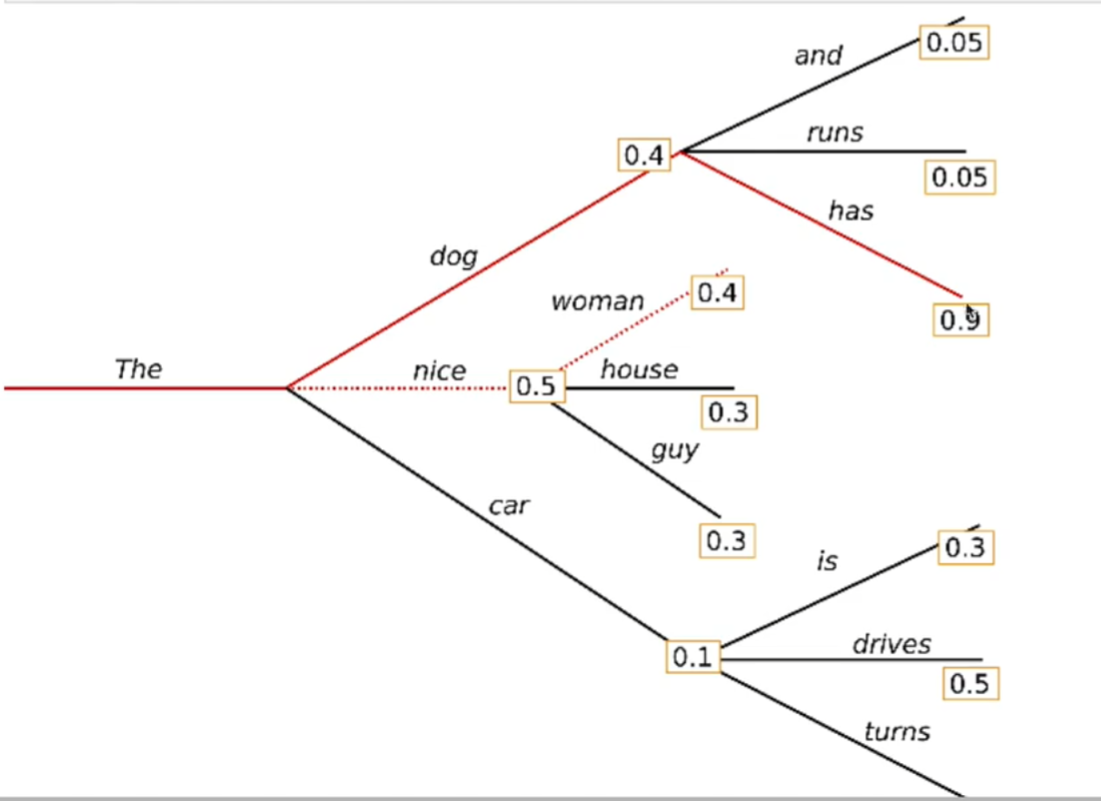
束搜索是每次输出概率前k的词语(k是束的宽度,由自己设定),往前再走一步时输出的前两步动作概率前k的组合,以此类推,这样就能在一定程度上避免陷入局部最优解;
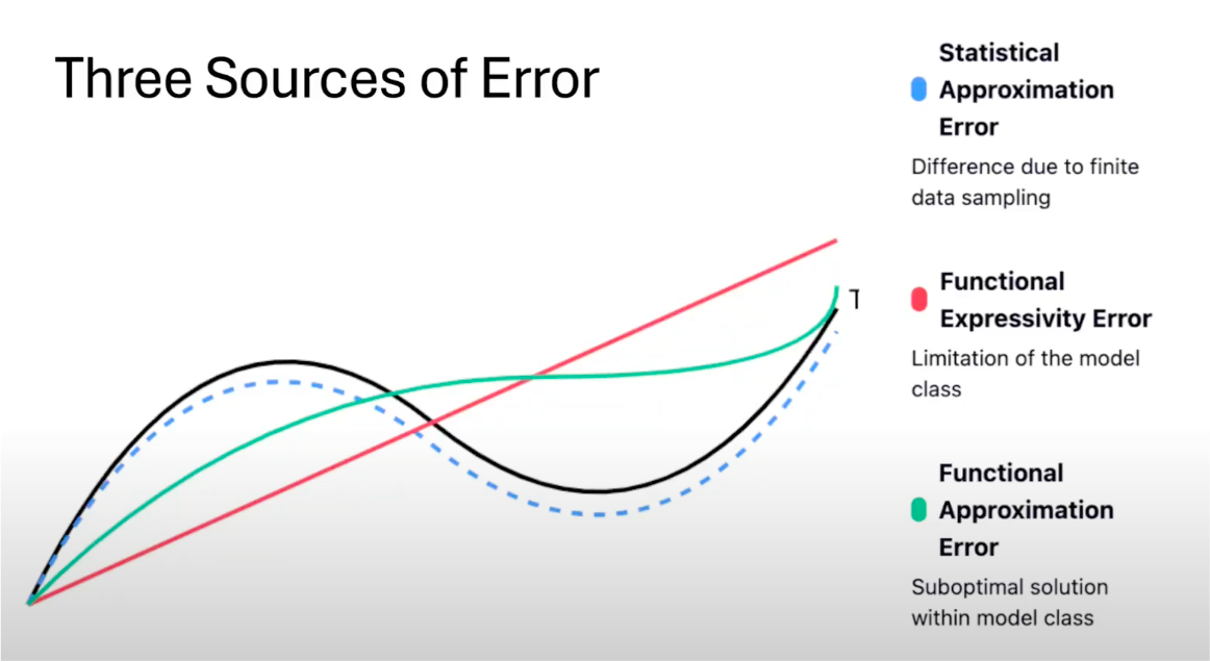
3)误差来源;
• 统计逼近误差:只能获取有限离散真实数据的采样,有限的数据就会导致误差;
• 函数表达性误差:选择的模型表达能力有限;
• 函数逼近误差:没有训练好比如只找到局部最优解;
一、LLM模型论文解读
kimi1.5和Deepseek R1都舍去了 mcts、value function、prm(process reward models),追求 simple & scaling;
1.1 kimi 1.5
• 数据来源;
kimi1.5首先说明了高质量数据的标准;
1)数据中用于训练的问题要选择能够丰富思考同时易于评估的问题(评估问题的难度使用SFT【Supervised Fine Tuning,监督训练微调】 模型去计算准确率,根据准确率判定问题的难易,思考过程,答案);
2)数据的质量包含数据多样性、难度适中(简单中等复杂都要有)、准确性评估必须简单容易可行;
• 提高模型能力;
kimi1.5通过训练发现:提高模型表现的一个重要方向是提升reasoning token 的计算量,其次是取消了蒙特卡洛树搜索,价值函数和过程奖励模型;随着reasoning token 变长,优化步数变多,表现会越来越好;
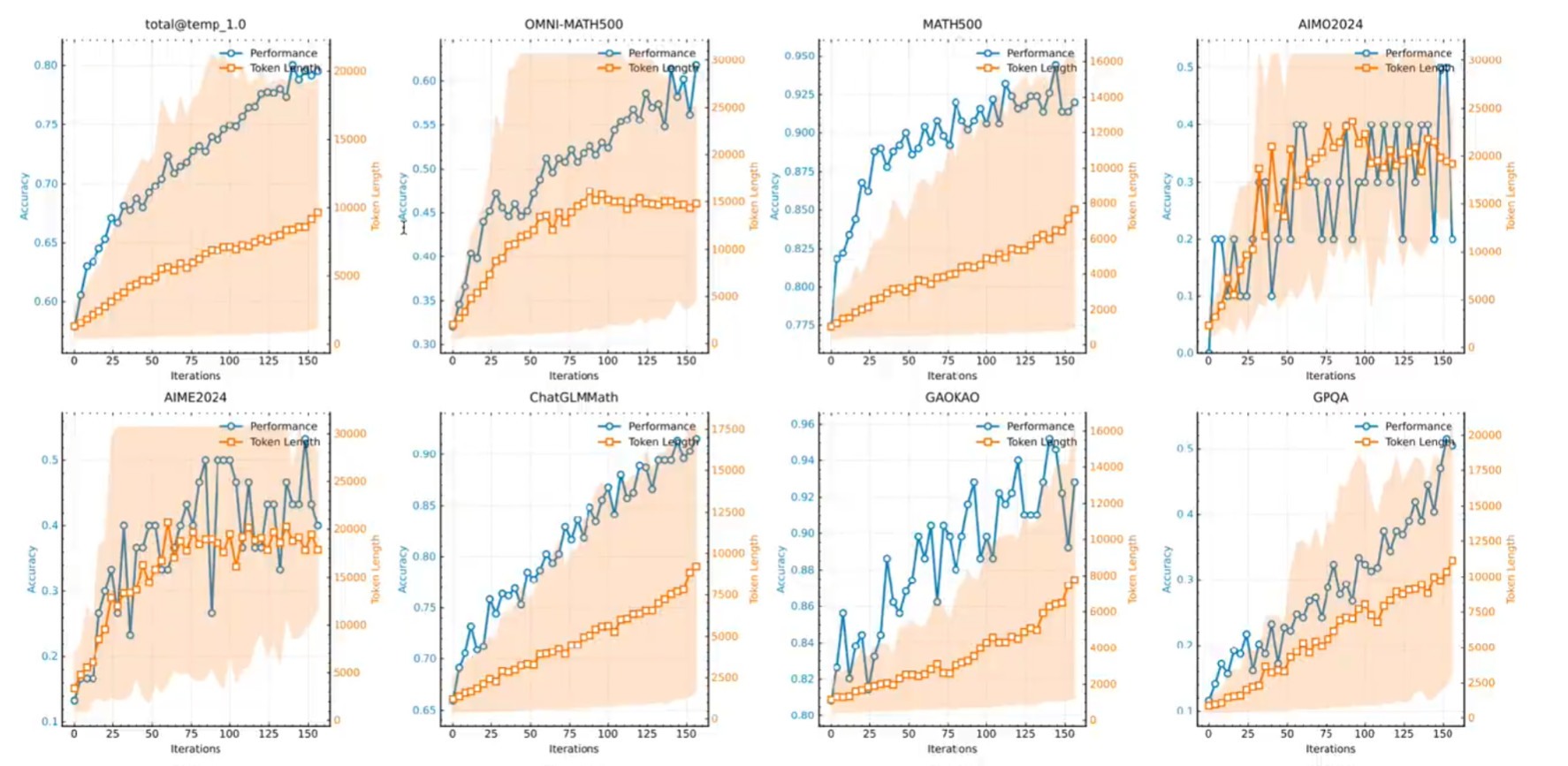
• 如何打磨和生成CoT(Chain of thought);
SFT 是模仿(人类专家写下思考过程和答案,用人类专家数据训练这是很重要的训练),RL是探索,在强化学习算法上生成多个解,选取前几个正确的解,反复训练算法,会在正确的解上反复强化;
Notes:在线学习是边实践边学习,数据利用率低,离线学习是观察他人学习,数据可以反复利用;
• 思考过程的重要性;
kimi1.5论文中提出:假设有两个推理过程,一个是正确的,一个是错误的,推理过程也是十分重要的,对于训练模型去生成思维链,因为错误的退过程可以被纠正区重新思考和探索试错;为了防止过度思考引入了长度的惩罚,防止思考过度时一些无意义的思考,防止训练过程中思维链越来越长,不收敛的问题;下图所示的是随着步数思维链一直变成未能收敛的训练过程示意图;
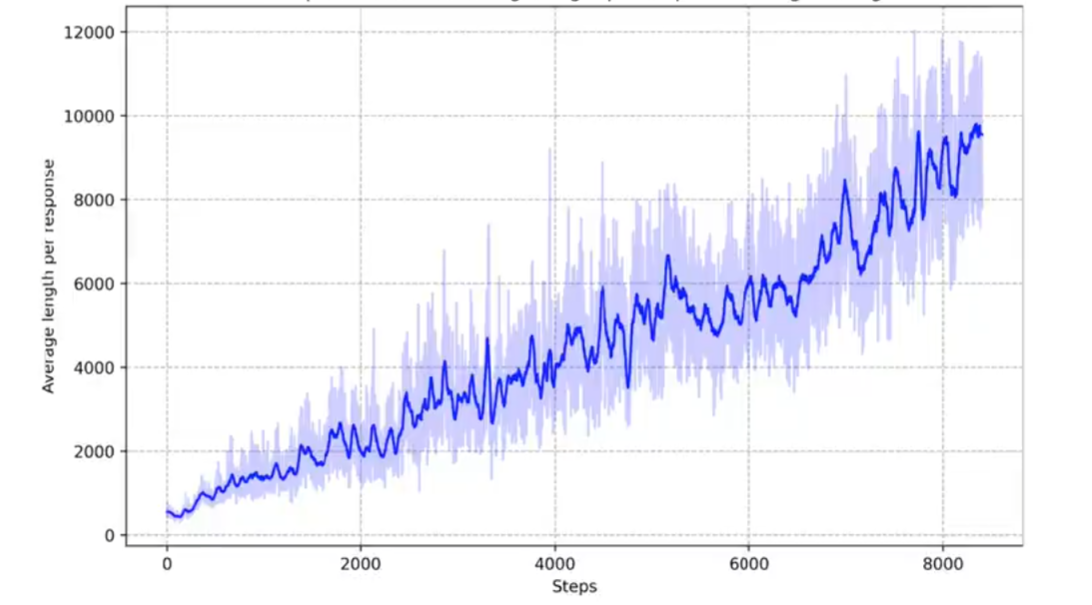 Notes:此外压缩上下文是一个十分重要的技巧,用来把思考过程从长的思考链转化为短的思考链,这样能够提高在有限的测试时间内模型表现;
Notes:此外压缩上下文是一个十分重要的技巧,用来把思考过程从长的思考链转化为短的思考链,这样能够提高在有限的测试时间内模型表现;
1.2 Deepseek R1
•Reasoning Model定义;
一个模型在回答问题时有显式思考的过程,思考的过程有助于回答问题,那么这个模型就叫reasoning model ;优化步数变多模型表现能力越来越好,同时模型思考长度和回复长度越来越多;
• 问答方式实现;
模型推理过程中会不断的出现假设和自我验证过程,直到回答对问题;Deepseek R1中实现的方式也很简单把think 放在标签为think 的xml 文件里,answer 放在answer 的xml 文件里;同时在回答第二次问题时第一次的思维链会被隐藏因为它太长了;
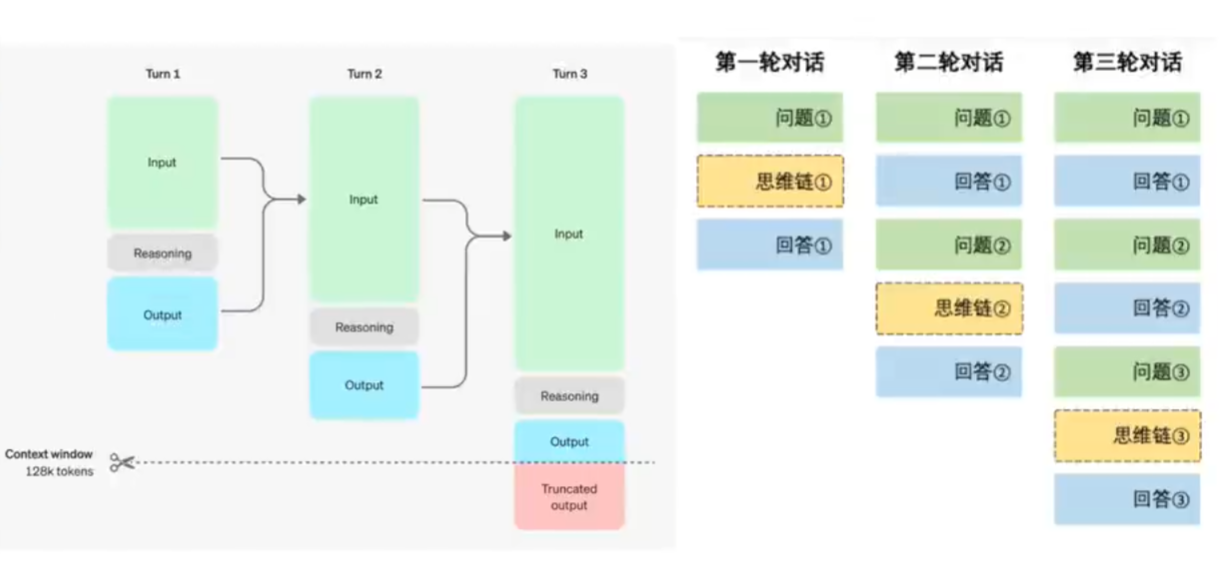
• DeepSeek大模型有两个重点一是数据集的构建过程,二是GRPO 算法 ;
GRPO算法是在DeepseekMath论文中提出的,它 追求的是数据的相关性和scale(分步扩展)扩召回的过程;同时如果说从网站爬取的数据有相关性的那么网站所有的数据都会被用来训练;
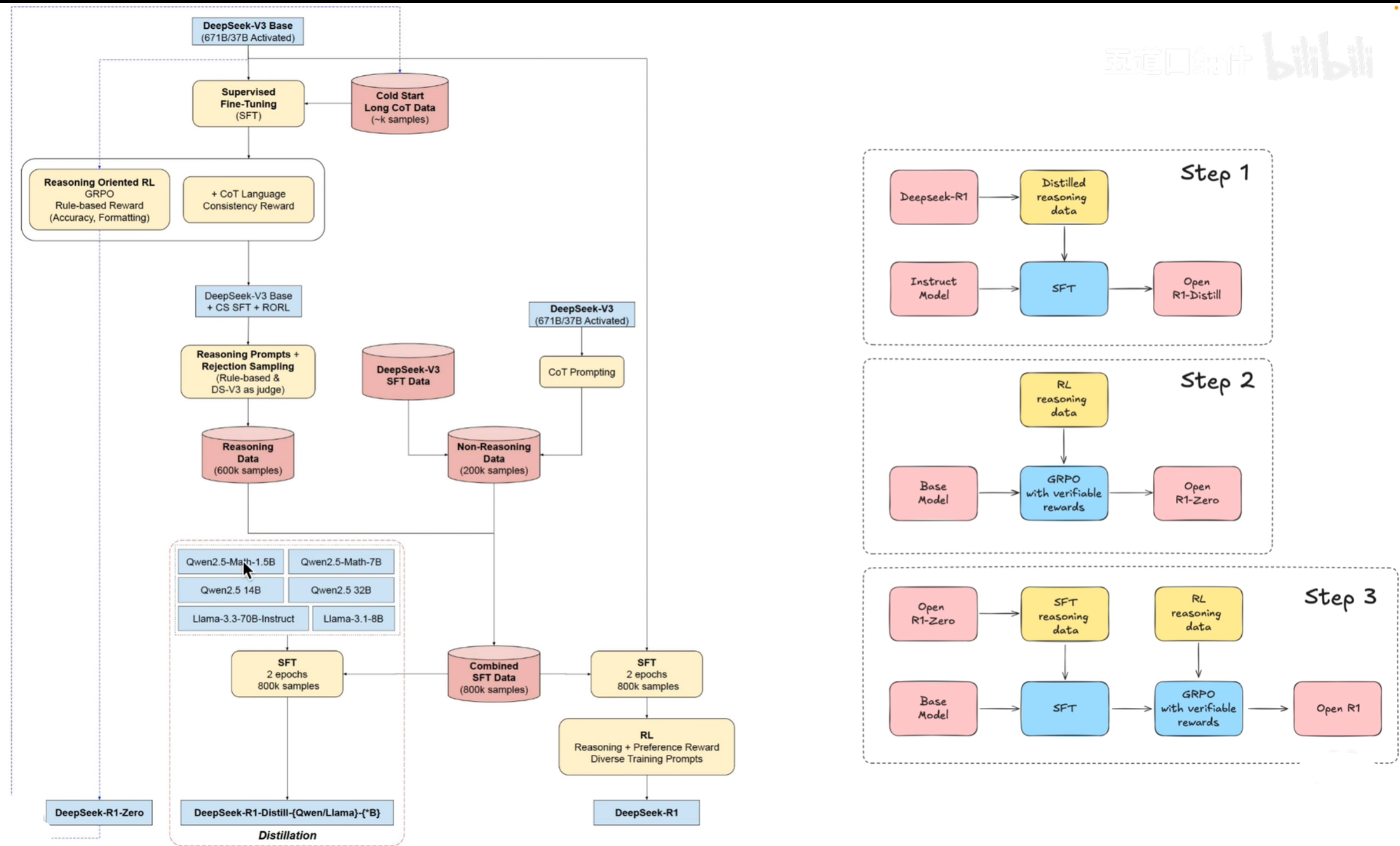
R1训练过程图示:红色表示数据,黄色表示算法,是训练,蓝色的是模型;
Deepseek R1zero 拿到deepseek-V3的模型通过GRP O算法(通过rule-based的奖励)训练得到,同时用产生高质量的推理数据;
如何消除模型的幻觉,如果答案正确且输出一些乱七八糟的信息那么奖励就比不给错乱信息少,不知道的奖励比答案错误且错乱信息多;
1.3 S1
S1的强大的推理能力得益于心选择的1000个问题,高质量,难易适中,多样性丰富,S1对现成的预训练模型(Qwen2.5)在该小型数据集上(1k)进行了监督微调(SFT);S1的通过数据蒸馏学习其他模型输出,再进行监督训练微调(SFT),本质上就是蒸馏+SFT;
二、深度解析GRPO
2.1 推导GRPO
持续更新
总结
以上就是强化学习和LLM结合一些工作简要概述,感兴趣可以去详细读一下论文和代码。