目录
[1. 光照变化导致的误检测](#1. 光照变化导致的误检测)
[2. 动态背景的干扰](#2. 动态背景的干扰)
[3. 阴影检测不准确](#3. 阴影检测不准确)
一、背景减法概述
背景减法(Background Subtraction)是视频分析中的核心技术之一,主要用于从视频序列中自动提取运动物体。其基本原理是通过比较当前帧与背景模型,将像素分为"背景"和"前景"(运动物体)两部分。
应用场景
视频监控系统中的行人检测
交通流量统计与车辆跟踪
智能安防中的异常行为检测
视频会议中的人物分割
工业生产线的物体检测
二、背景减法算法原理
OpenCV提供了多种背景减法算法,每种算法都有其独特的设计思路和适用场景:
1. 高斯混合模型(MOG2)
原理:
为每个像素建立一个高斯混合模型
每个像素值由多个高斯分布组合而成
通过EM算法自适应更新模型参数
支持光照变化和动态背景
核心参数:
history:历史帧数(默认500)
varThreshold:像素与模型的马氏距离阈值(默认16)
detectShadows:是否检测阴影(默认True)
2. K最近邻(KNN)
原理:
为每个像素维护一个历史像素值样本集
将当前像素值与样本集中的K个最近邻进行比较
基于相似性判断是否为背景
对动态背景有较好的适应性
核心参数:
history:历史样本数(默认500)
dist2Threshold:距离平方阈值(默认400.0)
detectShadows:是否检测阴影(默认True)
3. GMG(GoldenbergMillerGuy)
原理:
结合静态背景初始化和概率前景分割
使用贝叶斯推断更新背景模型
对突发场景变化有较好的适应性
4. CNT(Continuously Adaptive Mean and Variance Thresholding)
原理:
基于均值和方差的连续自适应阈值
计算效率高,适合实时应用
三、OpenCV背景减法函数详解
- createBackgroundSubtractorMOG2
//python
cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=16, detectShadows=True)
参数说明:history:用于训练背景模型的帧数
varThreshold:决定像素是否属于背景模型的阈值
detectShadows:是否检测阴影,阴影会被标记为灰色(值为127)
返回值:
背景减法器对象,可调用apply()方法处理帧
- createBackgroundSubtractorKNN
//python
cv2.createBackgroundSubtractorKNN(history=500, dist2Threshold=400.0, detectShadows=True)
参数说明:
history:用于训练背景模型的历史样本数
dist2Threshold:像素与背景模型的距离平方阈值
detectShadows:是否检测阴影
返回值:
背景减法器对象,可调用apply()方法处理帧
- apply方法
//python
foreground_mask = bg_subtractor.apply(frame, learningRate=None)
参数说明:
frame:当前处理的视频帧
learningRate:学习率,控制背景模型更新速度(01之间,默认1表示自动计算)
返回值:
前景掩码(二值图像),白色(255)表示前景,黑色(0)表示背景,灰色(127)表示阴影
- getBackgroundImage方法
//python
background = bg_subtractor.getBackgroundImage()
功能:获取当前的背景模型图像
返回值:背景图像
四、背景减法实战代码
1. 基本背景减法
//python
python
import cv2
import numpy as np
#创建视频捕获对象
cap = cv2.VideoCapture(0) #0表示默认摄像头
#创建背景减法器
bg_subtractor = cv2.createBackgroundSubtractorMOG2()
bg_subtractor = cv2.createBackgroundSubtractorKNN()
while True:
#读取视频帧
ret, frame = cap.read()
if not ret:
break
#应用背景减法
fg_mask = bg_subtractor.apply(frame)
#可选:去除阴影(将灰色像素设为黑色)
fg_mask[fg_mask == 127] = 0
#显示结果
cv2.imshow('Original Frame', frame)
cv2.imshow('Foreground Mask', fg_mask)
#按'q'键退出
if cv2.waitKey(30) & 0xFF == ord('q'):
break
#释放资源
cap.release()
cv2.destroyAllWindows()2. 运动物体检测与计数
//python
python
import cv2
import numpy as np
#创建视频捕获对象
cap = cv2.VideoCapture('traffic.mp4')
#创建背景减法器
bg_subtractor = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=40, detectShadows=True)
#初始化计数器
object_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
#应用背景减法
fg_mask = bg_subtractor.apply(frame)
#去除阴影
fg_mask[fg_mask == 127] = 0
#形态学操作:去除噪声
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
fg_mask = cv2.erode(fg_mask, kernel, iterations=1)
fg_mask = cv2.dilate(fg_mask, kernel, iterations=2)
#查找轮廓
contours, hierarchy = cv2.findContours(fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#绘制轮廓和边界框
for contour in contours:
#过滤小轮廓(可能是噪声)
if cv2.contourArea(contour) > 500:
#绘制边界框
(x, y, w, h) = cv2.boundingRect(contour)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
#绘制中心点
center = (x + w // 2, y + h // 2)
cv2.circle(frame, center, 4, (0, 0, 255), 1)
#更新物体计数
object_count = len([c for c in contours if cv2.contourArea(c) > 500])
#显示计数
cv2.putText(frame, f'Objects: {object_count}', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
#显示结果
cv2.imshow('Original Frame', frame)
cv2.imshow('Foreground Mask', fg_mask)
if cv2.waitKey(30) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()3. 背景模型可视化
//python
python
import cv2
import numpy as np
#创建视频捕获对象
cap = cv2.VideoCapture(0)
#创建背景减法器
bg_subtractor = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read()
if not ret:
break
#应用背景减法
fg_mask = bg_subtractor.apply(frame)
#获取当前背景模型
bg_model = bg_subtractor.getBackgroundImage()
#显示结果
cv2.imshow('Original Frame', frame)
cv2.imshow('Foreground Mask', fg_mask)
cv2.imshow('Background Model', bg_model)
if cv2.waitKey(30) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()五、背景减法的优化策略
- 噪声去除
//python
#方法1:形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
fg_mask = cv2.morphologyEx(fg_mask, cv2.MORPH_OPEN, kernel) #开运算去除小噪声
fg_mask = cv2.morphologyEx(fg_mask, cv2.MORPH_CLOSE, kernel) #闭运算填充空洞
方法2:高斯模糊
fg_mask = cv2.GaussianBlur(fg_mask, (5, 5), 0)
- 阴影处理
//python
#方法1:直接忽略阴影
fg_maskfg_mask == 127 = 0
#方法2:基于颜色信息识别阴影
#阴影通常比原物体暗,颜色信息相似
shadow_mask = np.zeros_like(fg_mask)
shadow_mask(fg_mask == 127) \& (hsv\[:, :, 2 < 100)] = 255
- 自适应学习率
//python
#静态场景:使用较小的学习率
learning_rate = 0.001
fg_mask = bg_subtractor.apply(frame, learningRate=learning_rate)
#动态场景:使用较大的学习率
learning_rate = 0.01
fg_mask = bg_subtractor.apply(frame, learningRate=learning_rate)
六、不同算法的性能比较
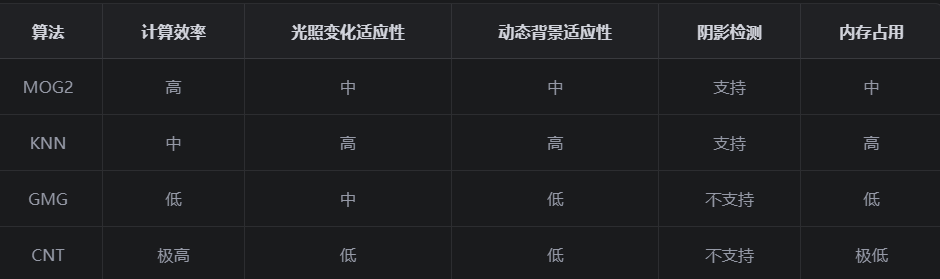
七、实际应用案例
1. 交通监控系统
//python
python
import cv2
import numpy as np
#视频源
cap = cv2.VideoCapture('highway_traffic.mp4')
#创建背景减法器
bg_subtractor = cv2.createBackgroundSubtractorMOG2(history=1000, varThreshold=30)
#定义检测区域(ROI)
roi_points = np.array([[200, 300], [600, 300], [800, 500], [0, 500]])
roi_mask = np.zeros((frame.shape[0], frame.shape[1]), dtype=np.uint8)
cv2.fillPoly(roi_mask, [roi_points], 255)
while True:
ret, frame = cap.read()
if not ret:
break
#应用ROI
roi_frame = cv2.bitwise_and(frame, frame, mask=roi_mask)
#背景减法
fg_mask = bg_subtractor.apply(roi_frame)
fg_mask = cv2.bitwise_and(fg_mask, roi_mask)
#形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
fg_mask = cv2.erode(fg_mask, kernel, iterations=1)
fg_mask = cv2.dilate(fg_mask, kernel, iterations=3)
#检测车辆
contours, _ = cv2.findContours(fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) > 2000:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
#显示结果
cv2.polylines(frame, [roi_points], True, (255, 0, 0), 2)
cv2.imshow('Traffic Monitoring', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()2. 行人检测与跟踪
//python
python
import cv2
import numpy as np
#创建视频捕获对象
cap = cv2.VideoCapture('pedestrians.mp4')
#创建背景减法器
bg_subtractor = cv2.createBackgroundSubtractorKNN(history=500, dist2Threshold=500)
#跟踪点列表
track_points = []
while True:
ret, frame = cap.read()
if not ret:
break
#背景减法
fg_mask = bg_subtractor.apply(frame)
fg_mask[fg_mask == 127] = 0
#形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
fg_mask = cv2.morphologyEx(fg_mask, cv2.MORPH_OPEN, kernel)
fg_mask = cv2.morphologyEx(fg_mask, cv2.MORPH_CLOSE, kernel)
#查找轮廓
contours, _ = cv2.findContours(fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#更新跟踪点
new_track_points = []
for contour in contours:
if cv2.contourArea(contour) > 800:
x, y, w, h = cv2.boundingRect(contour)
center = (x + w // 2, y + h // 2)
new_track_points.append(center)
#绘制行人框
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.circle(frame, center, 4, (0, 0, 255), 1)
track_points = new_track_points
#显示结果
cv2.imshow('Pedestrian Detection', frame)
if cv2.waitKey(30) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()八、常见问题与解决方案
1. 光照变化导致的误检测
问题:环境光照突然变化时,背景模型无法及时适应,导致大面积误检测。
解决方案:
使用MOG2或KNN算法,它们对光照变化有一定的适应性
增加history参数值,使模型更稳定
结合颜色空间转换(如HSV),仅使用亮度通道进行背景减法
2. 动态背景的干扰
问题:如树叶摇曳、水面波动等动态背景会被误判为前景。
解决方案:
选择KNN算法,它对动态背景有较好的处理能力
增加varThreshold或dist2Threshold参数值
使用形态学操作过滤小面积运动
3. 阴影检测不准确
问题:阴影被误判为前景或背景,影响检测精度。
解决方案:
结合颜色和亮度信息进行阴影识别
调整阴影检测的阈值参数
对于要求高的场景,可以使用专门的阴影检测算法
九、总结
背景减法是视频分析中的基础技术,OpenCV提供的MOG2和KNN算法已经能够满足大多数应用需求。在实际应用中,需要根据具体场景选择合适的算法,并通过参数调优、形态学操作等方法提高检测精度。
关键要点:
选择适合场景的背景减法算法
合理设置算法参数
使用形态学操作优化前景掩码
结合ROI减少计算量和干扰
考虑光照变化和动态背景的影响
通过背景减法技术,可以实现高效的运动物体检测,为后续的跟踪、识别和行为分析奠定基础。