前言
在信息传播速度以秒计的今天,新闻审查面临着前所未有的挑战:海量内容涌入、合规标准复杂、隐喻暗示难以捕捉。传统的关键词过滤早已力不从心,海量新闻内容对审核机制提出了极高的效率与准确性要求。传统的人工审查模式面临效率瓶颈、标准不一以及对隐蔽内容识别困难等痛点。
本文将深度解析一个基于 LangChain、LangGraph 和本地 Ollama 大模型构建的自动化新闻 AI 审查系统。该系统通过多 Agent 协作架构,将新闻审查从简单的"关键词匹配"进化为深度的"语义理解与逻辑推理"。
郑重声明:本系统只是以新闻AI审查场景为例来演示相关技术,相关数据都是模拟数据,并不能实际进行新闻的审查,不能直接作为审查系统使用!如有使用责任自负!
原型系统界面展示
新闻稿文档上传
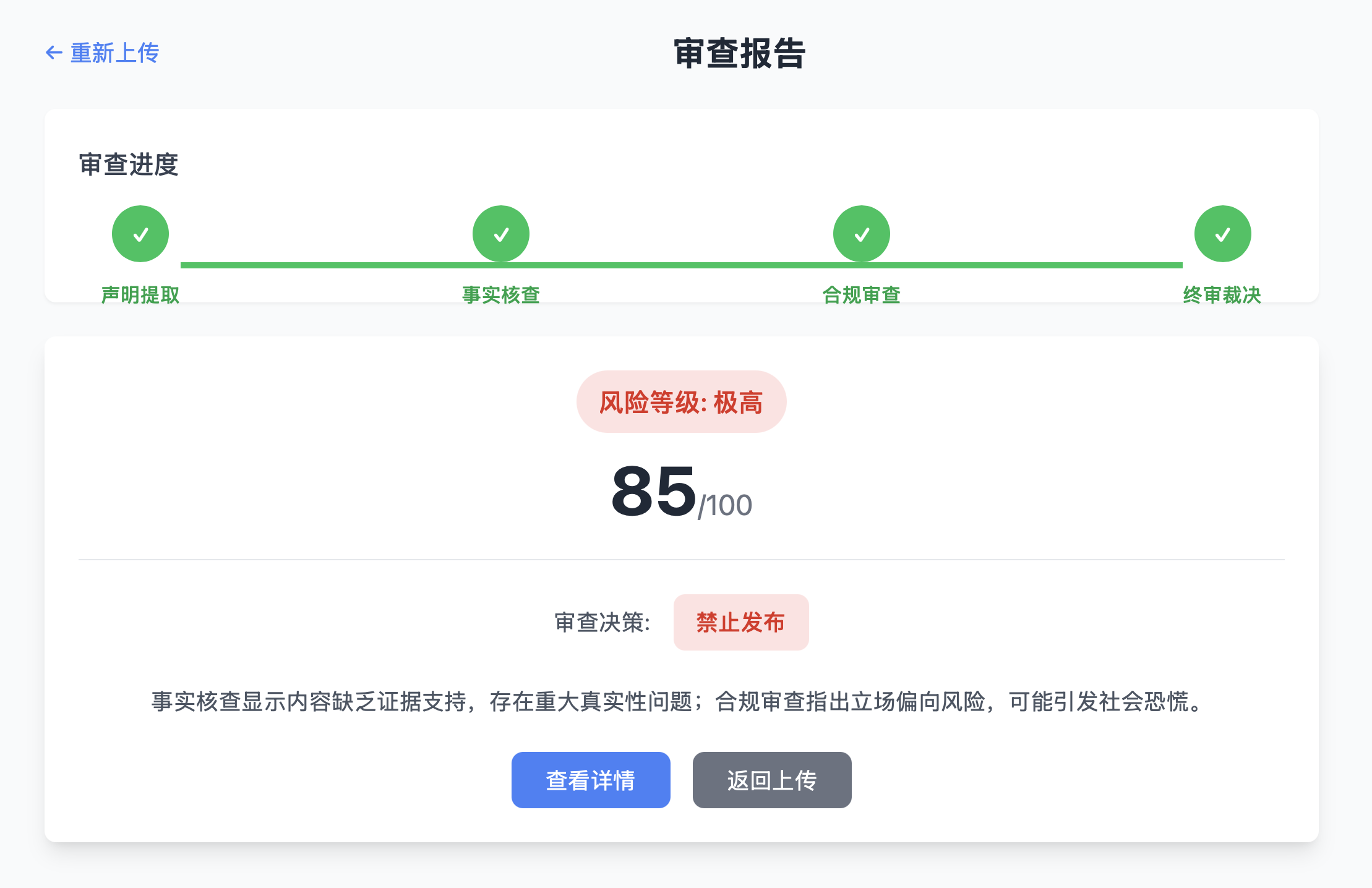
审查进度可视化

审查报告总览
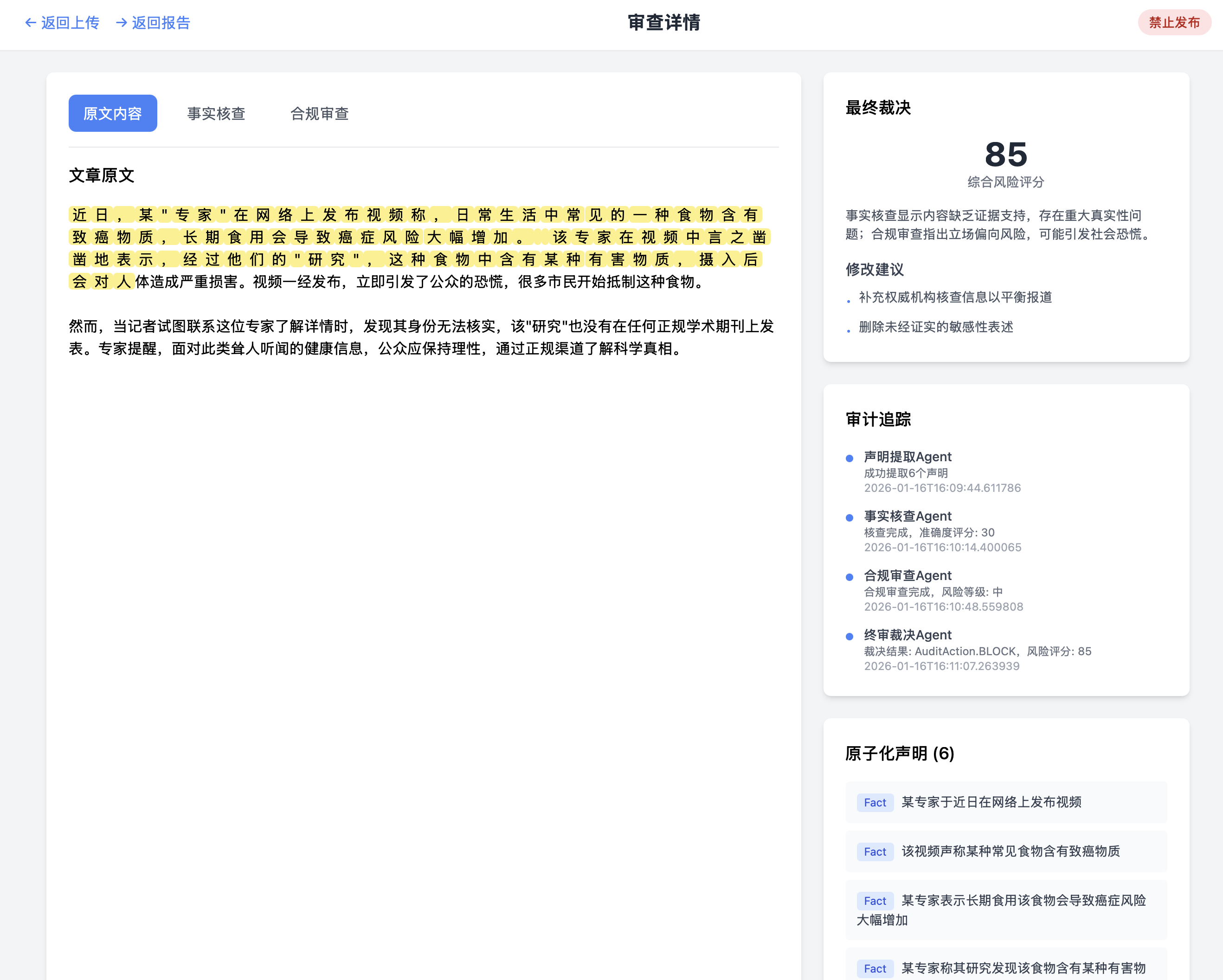
审查详情
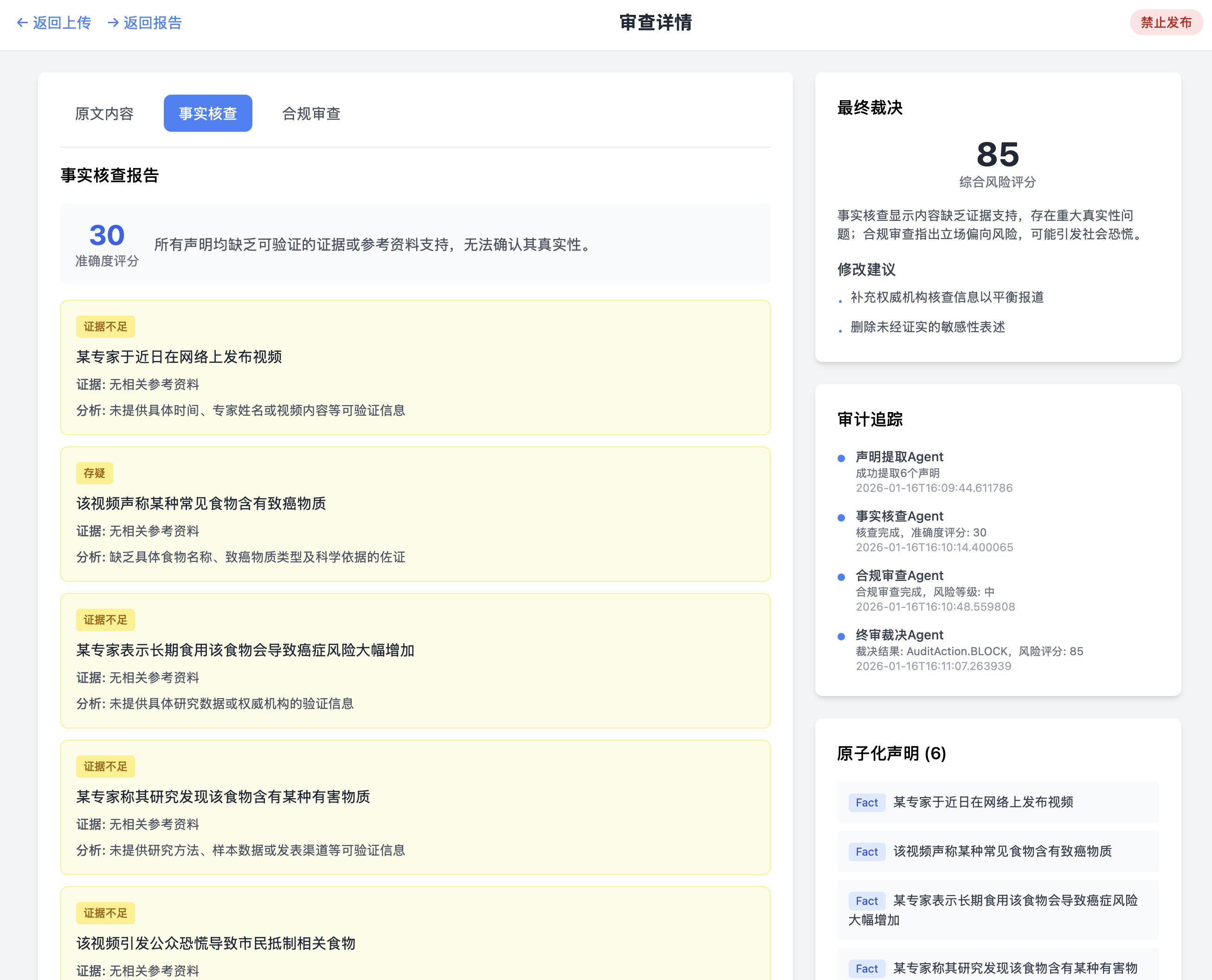
审查详情
审查详情
一、 系统架构:从单体模型到状态机编排
1.1 设计思路:原子化与专业化
本系统的设计核心在于专业化分工。我们没有使用单一的长 Prompt让模型完成所有任务,而是将任务拆解为四个独立的 Agent,每个 Agent 专注于特定领域,从而提高提示词的精准度与系统的可维护性。
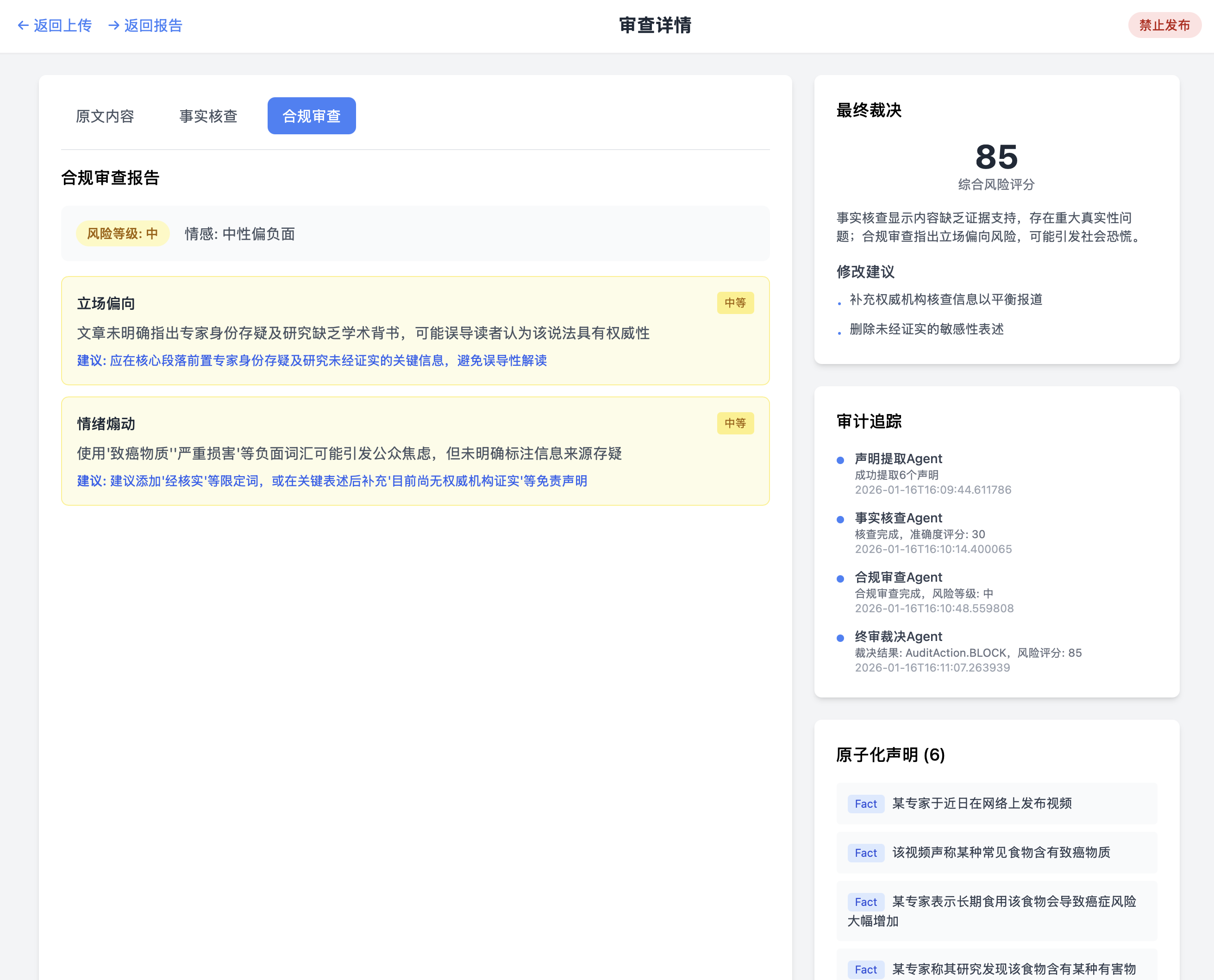
1.2 整体架构图
系统采用前后端分离架构,核心由 LangGraph 编排工作流,后端利用 FastAPI 支撑,LLM 服务则由本地运行的 Ollama 提供(模型选用 qwen2.5:7b),并利用 WebSocket 实现审计状态的实时推送。
1.3 数据流转图

1.4 多Agent协作模式
本系统采用专业化分工的设计思想,将复杂的新闻审查任务拆解为四个独立的Agent,每个Agent专注于特定领域:
| Agent | 职责 | 输入 | 输出 |
|---|---|---|---|
| 声明提取Agent | 将长文本拆解为原子化声明 | 新闻全文 | 声明列表(JSON) |
| 事实核查Agent | 验证每个声明的真实性 | 声明列表 + 原文 | 核查报告 |
| 合规审查Agent | 检测违规内容和风险 | 声明列表 + 原文 | 合规报告 |
| 终审裁决Agent | 综合评估并做出决策 | 核查报告 + 合规报告 | 最终决策 |
设计优势:
- 单一职责:每个Agent专注于一种任务,提示词更精准
- 可复用性:Agent可独立测试、升级和替换
- 并行潜力:未来可改为并行执行(部分Agent)
- 可观测性:每个阶段的输出都清晰可见
二、 LangGraph 状态机架构:超越线性 Pipeline
系统的核心灵魂在于基于 LangGraph 的 StateGraph 构建的工作流。不同于传统的线性链式调用,LangGraph 允许我们定义复杂的有向无环图(DAG),并管理跨节点的状态。
2.1 状态定义与流转
我们定义了 AuditState 对象在节点间传递信息,记录新闻全文、声明列表及各类审查报告。
python
class AuditState(TypedDict):
article_id: str # 稿件唯一标识
article_content: str # 原始新闻全文
claims: List[Dict] # 提取出的原子化声明
fact_check_reports: List[Dict]# 事实核查详细结果
compliance_report: Dict # 合规审查结果
final_decision: Dict # 最终裁决建议
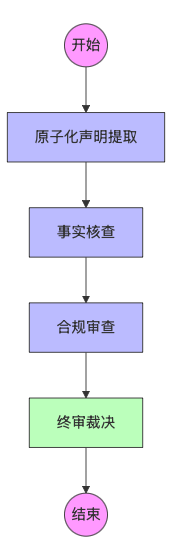
current_step: str # 当前执行进度2.2 审查流转图
使用LangGraph的StateGraph构建工作流,将Agent串联成有向无环图(DAG):
2.3 关键代码:定义状态机工作流
python
from langgraph.graph import StateGraph, END
class AuditWorkflow:
def _build_graph(self) -> StateGraph:
# 初始化状态图,AuditState 记录了新闻全文、声明列表、各类报告
workflow = StateGraph(AuditState)
# 添加 Agent 节点
workflow.add_node("extract_claims", self._extract_claims)
workflow.add_edge("extract_claims", "fact_check")
workflow.add_node("fact_check", self._fact_check)
workflow.add_edge("fact_check", "compliance_audit")
workflow.add_node("compliance_audit", self._compliance_audit)
workflow.add_edge("compliance_audit", "judge_decision")
workflow.add_node("judge_decision", self._judge_decision)
workflow.add_edge("judge_decision", END)
# 设置入口
workflow.set_entry_point("extract_claims")
return workflow.compile()三、 核心模块深度实现
3.1 原子化声明提取(Atomic Claim Extraction):消除"语义稀释"
痛点 :直接对 3000 字的长文进行 RAG(检索增强生成)或事实核查,模型容易出现"幻觉",且关键事实会被冗余背景淹没,检索精度下降。
实现逻辑 :ClaimExtractor 将长文本拆解为多个独立的、可验证的原子化声明。它会补全指代词,确保每个声明包含具体的数据、事实或观点。
- 上下文补全:将指代不明的词(如"该公司"、"他")替换为具体实体(如"华为"、"任正非")。
- 维度拆分:将复合句拆分为单一事实。例如"A 公司去年营收增长 20% 且裁员千人"会被拆分为两个独立声明。
python
# 提取Agent的核心Prompt
self.system_prompt = """
你是一个专业的新闻声明提取专家。
请将输入的新闻文章拆解为多个独立的、可验证的原子化声明。
要求:每个声明应该是独立的陈述,必须包含具体的主体、时间、地点、数字等,去除形容词等干扰项,JSON格式输出。
"""
def extract_claims(self, article_text: str) -> List[Dict]:
"""提取原子化声明"""
prompt = f"请提取以下文章中的所有可验证声明:\n\n{article_text}"
response = self.llm.invoke([
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
])
# 解析JSON响应
result = json.loads(response.content)
return result.get("claims", [])3.2 事实核查(Fact-Check):多维证据比对
事实核查 Agent 不仅仅是调用大模型,它实际上是一个小型的 RAG 系统。
职责 :验证每个声明的真实性。
逻辑:针对提取出的声明列表,Agent 在知识库(包含实时热点库、法规准绳层、实时事实层等)中进行混合检索(向量 + 关键词)。它会输出核查状态(如:支撑、证据不足、冲突)并附带推理过程。
- 冲突检测 :对比证据原文与声明。模型会输出三个等级:
支撑 (Support)、反驳 (Refute)、信息不足 (Not Enough Info)。 - 推理展示:Agent 必须给出"为什么认为它是假的新闻"的推理链条(Audit Trail)。
python
ACT_CHECK_SYSTEM_PROMPT = """你是一名严谨的调查记者。
你的任务是核实新闻稿件中的事实陈述。依据提供的参考资料,判断每个声明的准确性。
## 工作流程
1. 提取稿件中涉及的人物、时间、地点、数据、引用言论
2. 将每个事实点与参考资料进行比对
3. 标记出"准确"、"错误"、"证据不足"、"存疑"
## 输出要求
请严格按照以下JSON格式输出:
{
"fact_check_report": [
{
"claim": "原文中的表述(声明内容)",
"status": "准确/错误/证据不足/存疑",
"evidence": "参考资料中的原文依据(如果没有证据则说明)",
"reasoning": "为什么判定为该状态的详细分析"
}
],
"overall_accuracy_score": 准确度评分(0-100的整数),
"summary": "整体核查总结(1-2句话)"
}
"""3.3 合规审查(Compliance):红线与立场识别
合规 Agent 侧重于语义倾向和政策风险。
检查维度:
- 立场倾向:识别是否存在煽动性言论、立场偏颇、违规暗示或极端情绪。
- 敏感红线:检测是否包含涉政、涉黄、涉恐或其他平台禁止的暗示性表述。
- 修改建议 :Agent 会输出
suggested_modifications,告知编辑如何调整词汇以符合规范。
四、 风险评分算法:基于"短板理论"的决策
在终审裁决阶段,系统通过 Judge Agent 汇总所有报告。为了确保零容忍,我们采用的是基于**"短板效应"的非线性加权算法**。
4.1 算法逻辑:最大风险覆盖
系统不采用简单的加权平均,而是基于**"短板理论"**(一票否决制):只要有一个严重违规点,整篇稿件即判定为高风险。因为在新闻审查中,99% 的内容真实无法抵消 1% 的敏感违规带来的风险。
4.2 决策矩阵
| 风险评分 | 裁决动作 | 处理逻辑 |
|---|---|---|
| 0 - 30 | 自动通过 | 风险极低,符合发布标准。 |
| 31 - 60 | 修改后发布 | 存在小瑕疵或修辞风险,需按建议调整。 |
| 61 - 100 | 禁止发布 | 触碰红线或事实严重虚假,予以拦截。 |
五、 性能优化:如何提升 35-40% 的速度?
在私有化部署场景下,本地大模型的推理速度很重要。我们通过以下三个层面的优化,将单篇新闻处理耗时从 90s+ 压缩到了 30s 以内。
- 禁用推理过程 (Reasoning=False) :针对非逻辑推演类任务(如提取、分类),关闭 DeepSeek/Qwen 的深度思考过程,可节省 20-40 秒。
- Agent 单例模式:避免每次请求重复初始化 LLM 和 Agent 实例,内存占用减少 75%,并大幅提升响应速度。
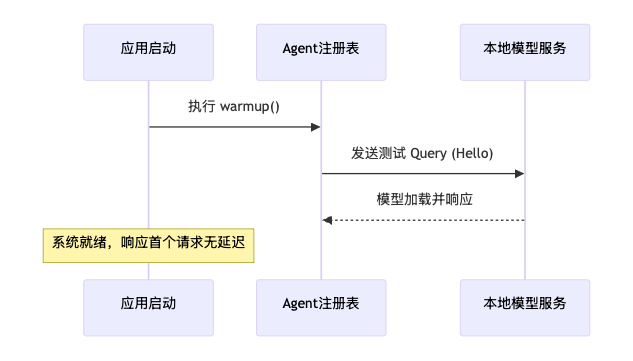
- 启动预热机制:在 FastAPI 启动时预先向 Ollama 发送测试消息,消除首次请求时加载模型到内存的 5-10 秒延迟。
5.1 禁用推理过程 (Reasoning=False)
对于"提取"和"分类"等非逻辑推导类任务,关闭模型的 Chain-of-Thought(思维链)可以显著降低首字延迟。
python
self._llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.1,
reasoning=False, # 关键优化:跳过冗长的思考过程
num_ctx=4096
)5.2 Agent 单例与启动预热
问题 :Ollama 模型在首次调用时会有 5-10 秒的加载延迟。
方案 :在 FastAPI 启动时执行 lifespan 钩子,预先发送一条"ping"消息加载模型。
六、 总结与下一步计划
通过 LangGraph 多 Agent 架构,我们实现了新闻审查的智能化与自动化。该系统不仅解决了长文本检索精度问题,还通过原子化提取和多维度审计确保了决策的可解释性。
下一步可继续开发:
6.1 短期优化
- 并行执行:事实核查和合规审查可并行执行(LangGraph支持)
- 流式输出:使用LLM的流式API,边推理边展示结果
- 缓存机制:对相同声明缓存核查结果
6.2 中期增强
- RAG集成:接入向量数据库(Milvus/Pinecone),实现证据检索
- 知识图谱:使用Neo4j构建实体关系图谱
- 人工审核:添加"人工复审"节点,实现Human-in-the-loop
6.3 长期演进
- Agent自动路由:根据新闻类型(政治/经济/社会)动态选择Agent
- 多模型协同:简单任务用小模型(qwen3:8b),复杂任务用大模型(qwen3:32b)
- 持续学习:通过人工复核反馈回流,实现知识库的自动更新。