什么是 Graph RAG?
GraphRAG(Graph-based Retrieval-Augmented Generation)是微软提出的一种结合知识图谱的增强检索生成框架,旨在改进传统 RAG的局限性。其核心思想是通过构建结构化知识图谱,对文档内容进行全局语义建模,从而提升大语言模型(LLM)在复杂问题中的推理能力和回答准确性。
一句话来说,GraphRAG 是对检索增强生成(retrieval-augmented generation)的一种增强,它利用了图结构。
与传统RAG依赖非结构化文本的向量检索不同,GraphRAG通过图谱的拓扑结构(如节点、边、子图)挖掘深层语义关联,解决传统RAG在长尾问题、多跳推理和全局一致性上的不足,总的来说,他们之间有以下区别:
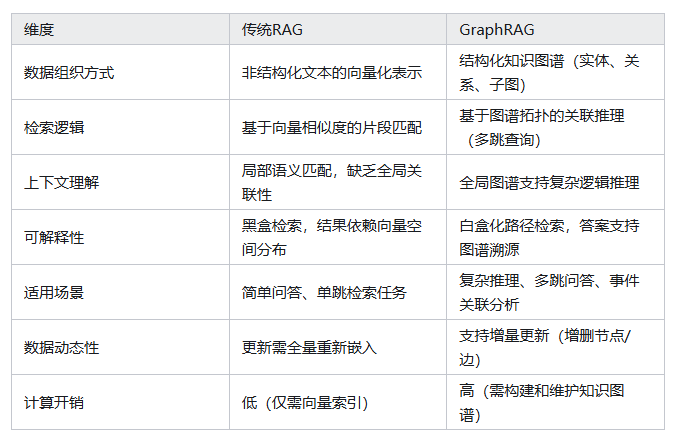
RAG每次检索出的chunk,只是某个文档的内容,而通过知识图谱,GraphRAG在全局语料层面检索知识,弥补了传统 RAG 在复杂关联推理中的不足,同时提升了回答的可解释性。
检索增强生成(RAG)
检索增强生成是一种结合检索系统和生成模型的方法,通常用于问答系统、对话系统等场景中。传统的生成模型仅依赖于训练数据,模型在面对新问题或信息匮乏时会出现性能下降的问题。为了解决这一问题,RAG方法引入了检索机制:在生成过程中,模型会从外部数据库或文档中检索相关信息,然后将检索到的内容作为输入的一部分,结合上下文生成更精确的输出。
RAG模型的关键优势在于,它能够结合静态模型的学习能力与动态的外部知识,尤其适合处理需要最新信息的任务。典型的RAG架构包括一个检索器(Retriever)和一个生成器(Generator)。检索器从大规模数据库中挑选出与当前问题最相关的文档片段,而生成器则基于这些片段和问题生成最终的答案。这种架构增强了模型的知识覆盖面和灵活性。
知识图谱
知识图谱是一种结构化的信息表示方式,它通过实体(nodes)和关系(edges)来组织和存储信息,形成一个可以直接进行推理和检索的网络。知识图谱的基本单位是三元组(subject, predicate, object),例如,"爱因斯坦(subject)-发明了(predicate)-相对论(object)"这样的语义表达。
知识图谱具有以下几个显著优势:
- 语义清晰:知识图谱将信息组织成实体和关系,能够清晰表示复杂概念之间的连接,便于机器理解和推理。
- 跨领域知识整合:它可以整合来自不同领域的知识,通过实体间的连接构建出广泛而连贯的知识体系。
- 易于扩展:知识图谱可以不断扩展和更新,支持不断增长的知识库。
GraphRAG的原理与架构
GraphRAG通过将知识图谱与RAG结合起来,解决了传统RAG方法在复杂推理任务上的局限性。它的核心思想是:在RAG检索的基础上,增加知识图谱作为辅助,进一步增强生成模型对复杂信息的理解和推理能力。
GraphRAG的架构主要包括以下几个部分:
-
知识图谱构建器:将非结构化文本转化为知识图谱,这是GraphRAG的独特之处。知识图谱构建器负责从文档或外部数据源中提取实体和关系,构建出结构化的知识表示。该层承担知识结构化的核心任务。涉及:
- 实体与概念抽取:在文档解析完成后,系统通过 LLM 统一识别出语义层级中的关键实体(如组织、人物、产品、技术名词)及其概念关系。这些元素被转化为图中的节点,形成知识网络的基础单元。
- 关系提取:系统进一步利用关系识别模型或 LLM 提取实体之间的逻辑关系(如"投资"、"依赖"、"属于"、"竞争"),并以边(Edge)的形式在节点间建立显式连接。这种结构化过程,实质上为文本语义注入了"逻辑骨架"。
- 社区发现:当节点与边逐渐增多后,系统通过图算法自动识别出紧密关联的节点群落,即知识的主题社区。每个社区代表文档集合中一个相对独立的知识域或叙事板块(如"新能源产业链"、"云原生生态")。
-
图谱推理模块:这一模块允许GraphRAG在生成过程中动态推理知识图谱中的关系。与普通RAG方法不同,GraphRAG能够根据问题中的细节沿着知识图谱中的路径推导出相关的结论。
-
检索器:与传统的RAG类似,检索器的任务是从大规模的文档库中选取与问题相关的文档。然而,GraphRAG不仅检索原始的文本数据,还可以基于知识图谱来检索与问题相关的实体和关系,确保更精确的信息检索。
-
生成器:生成器是基于大语言模型的,它不仅基于检索到的文本生成回答,还会参考知识图谱中包含的结构化信息进行更复杂的推理和生成。生成器可以将知识图谱中的节点和关系作为输入,帮助生成具有推理性和逻辑性的回答。
基于图结构的"全局推理"GraphRAG架构参考示意图可参考如下所示:
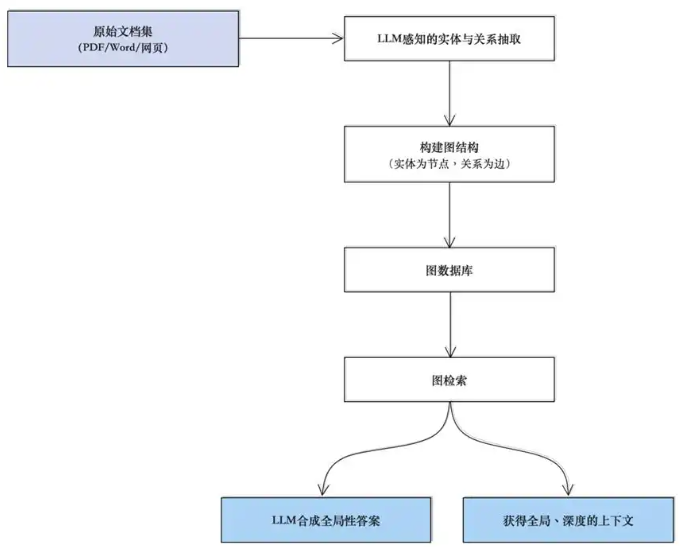
GraphRAG的典型工作流程如下:
GraphRAG的工作流可以分为索引和查询两大阶段 :
- 索引阶段(构建知识图谱):
- 知识抽取:使用LLM或专门的抽取模型,从文本单元中识别出实体(节点)和它们之间的关系(边),形成三元组。
- 图谱构建:将抽取出的三元组存储到图数据库中,形成初始知识图谱。
- 社区分析:对图谱进行聚类,发现社区,并为每个社区生成摘要,用于全局性查询。
- 查询阶段(检索与生成):
-
问题输入:用户提出问题,模型首先对问题进行分析,识别其中的实体和关系。分析用户问题,确定是全局搜索(需要总结性信息)还是本地搜索(需要特定实体或路径信息)。
-
知识图谱检索:GraphRAG从预先构建的知识图谱中检索与问题相关的实体和关系,生成一个包含多个三元组的子图。
- 全局搜索:检索相关的社区摘要作为上下文。
- 本地搜索:基于用户问题中的实体,在知识图谱中进行路径遍历或子图搜索,找到精确的知识路径。
-
文档检索:基于问题的关键词和知识图谱的提示,检索器从文档库中选取相关文档片段。
-
图谱推理与生成:生成器结合检索到的文档片段和知识图谱进行回答。图谱推理模块在这一过程中扮演关键角色,确保模型不仅参考静态知识,还能基于知识图谱中的关系进行推理。将检索到的结构化图信息(子图、路径、摘要)格式化为文本,作为上下文。
-
LLM生成输出:LLM结合上下文和用户问题,生成最终的答案。最终的输出是生成的文本,通常更加精准且具有逻辑性。
-
Graph RAG适用的应用场景
1 医疗领域
医疗领域是知识图谱应用的重要场景之一。在处理复杂的医学问题时,GraphRAG可以结合医学知识图谱,帮助医生或患者更好地理解病情或药物相互作用。生成的回答不仅基于文献检索,还能依赖医学知识图谱中的病理、药理等关系进行解释和推理。
2 法律领域
法律问题往往牵涉到复杂的法规、案例和法律解释。GraphRAG能够通过构建法律知识图谱,帮助法律从业者更快速、准确地找到相关法律条文和案例,生成法律意见或建议。
3 科研和教育
在学术研究中,科研人员需要在大量文献中找到与研究问题相关的信息。GraphRAG可以通过构建科研领域的知识图谱,提高文献检索的效率,并为科研人员生成有逻辑性的学术摘要或报告。
适用场景建议:
- 推荐采用GraphRAG:金融风控(关联交易分析)、医疗诊断(病因推理)、法律合规(案件关联性审查)。
- 仍适用传统RAG:客服问答(单轮对话)、文档摘要(无复杂逻辑)。
GraphRAG通过知识图谱的引入,解决了传统RAG在复杂推理任务中的局限性,但其实现成本较高,需权衡业务需求与资源投入。未来方向包括:
- 轻量化图谱构建:利用LLM自动生成三元组。
- 动态图谱更新:结合流数据处理技术实现实时更新。
- 多模态扩展:融合文本、图像、表格等多模态数据构建异构图谱。
评估RAG
为什么需要评估RAG
评估RAG(检索增强生成)系统至关重要,因为它直接关系到系统的准确性、可靠性、效率和可维护性。RAG通过结合检索外部信息和生成响应,弥补了大语言模型在特定领域知识、时效性和可解释性方面的不足,但这种架构引入了多个潜在错误点,需要系统评估来确保质量。
评估的核心目标是保障输出质量并避免关键问题。 RAG系统在检索、增强和生成三个阶段都可能出错,评估能有效识别和缓解这些问题:
- 避免幻觉和错误答案:大语言模型在生成阶段可能编造信息或产生偏见,评估通过指标如忠实度(评估答案是否严格基于检索内容)来检测和减少此类错误。
- 确保检索可靠性:检索阶段需平衡精度(相关结果比例)和召回率(相关结果被找到的比例),低精度或召回率会导致不完整或过时信息,影响响应质量。
- 提升效率和可维护性:评估帮助优化资源使用(如减少不必要的计算),并通过量化指标(如命中率、平均倒数排名)监控系统稳定性,支持持续改进。
RAG中的评估思路
评估指标和框架为质量提供量化标准。 常用指标包括:
- 检索阶段:命中率(命中率)、MRR(平均倒数排名)等,衡量检索相关文档的能力。
- 生成阶段:
- 自动化指标,忠实度、相关性、语义相似度等,确保答案准确且与上下文一致。工具如Ragas、Quotient AI和Arize Phoenix提供自动化框架,将评估流程工程化,便于集成到CI/CD中。
- 人工评测指标
有些指标机器算不出来,需要人判断:- 正确性(Correctness):回答是否事实正确;
- 完整性(Completeness):答案是否覆盖了核心信息;
- 可读性(Fluency):语言自然、表达流畅;
- 引用充分性(Attribution):是否标明信息来源。
这种方式常见于金融、医疗、政务等对合规性要求极高的领域。
- 系统整体评估(System Evaluation)
很多人以为评估完"检索 + 生成"就结束了,其实这只是局部。一个真正能上线的 RAG 系统,还要评估:- 延迟(Latency):检索 + 生成全流程响应时间;
- 吞吐(Throughput):高并发下性能稳定性;
- 缓存命中率(Cache Hit Rate):是否重复计算;
- 可复现性(Reproducibility):同样问题是否输出一致;
- 时效性(Recency):知识库更新后,是否能实时反映到答案中。