摘要
本周主要研究了两项关于多模态生成与扩散模型优化的前沿工作。深入分析了论文《ThinkDiff》,其核心创新在于通过视觉-语言训练作为代理任务,将视觉语言模型(VLM)与扩散解码器进行高效对齐,并利用随机掩码策略提升对齐网络的语义理解深度,实验结果显示其在多维度图像生成任务上显著优于现有方法。同时,进一步探讨了《Back to Basics: Let Denoising Generative Models Denoise》(JiT)中关于预测目标(x-prediction vs. v-prediction)的争议,明确了其结论适用于大Patch尺寸的DiT模型,而非单纯与分辨率相关。
Abstract
This week focused on two cutting-edge works concerning multimodal generation and diffusion model optimization. An in-depth analysis was conducted on the paper "ThinkDiff", whose core innovation lies in efficiently aligning the visual language model (VLM) with the diffusion decoder using vision-language training as a proxy task. It employs a random masking strategy to enhance the semantic understanding depth of the alignment network, with experimental results showing it significantly outperforms existing methods in multi-dimensional image generation tasks. Additionally, further discussion was held on the controversy regarding prediction targets (x-prediction vs. v-prediction) in "Back to Basics: Let Denoising Generative Models Denoise" (JiT), clarifying that its conclusion applies to DiT models with large patch sizes, rather than being solely related to resolution.
1、论文学习

1.1 创新点
✦直接对齐VLM与扩散解码器需要大量复杂数据和低效的扩散训练。为了解决这个问题,ThinkDiff通过一个代理任务,将VLM与大语言模型(LLM)的解码器进行视觉-语言训练(Vision-language Pretraining)。在将VLM与LLM解码器对齐之后,由于共享特征空间的存在,VLM就自然地与扩散解码器对齐。
✦为了避免对齐网络走捷径而非真正对齐特征空间,ThinkDiff在训练阶段对VLM输出的token特征使用随机掩码策略。这种策略随机丢掉一部分特征,让对齐网络学会仅从不完整的多模态信息中恢复语义。这种掩码训练使得对齐网络能够深度理解图像和文本,从而高效地将理解能力传递给扩散解码器。
1.2 方法
本文的的主要研究方法是通过代理任务实现视觉语言模型(VLM)与扩散模型的对齐,具体为利用视觉-语言训练作为代理任务,将VLM与大语言模型(LLM)的解码器进行对齐,再通过共享特征空间将VLM的多模态推理能力迁移至扩散模型。该方法通过自回归生成多模态特征向量,并利用轻量级对齐网络将其映射到LLM解码器的输入空间,以重建图像文字描述为监督目标进行训练。为避免对齐网络仅学习简单特征映射,训练阶段采用随机掩码策略丢弃部分VLM输出的token特征,迫使网络从残缺信息中恢复完整语义,从而深度理解图像与文本的逻辑关系。最终在推理阶段,通过共享特征空间将VLM的推理能力传递给扩散解码器,使其具备多模态上下文理解与生成能力。
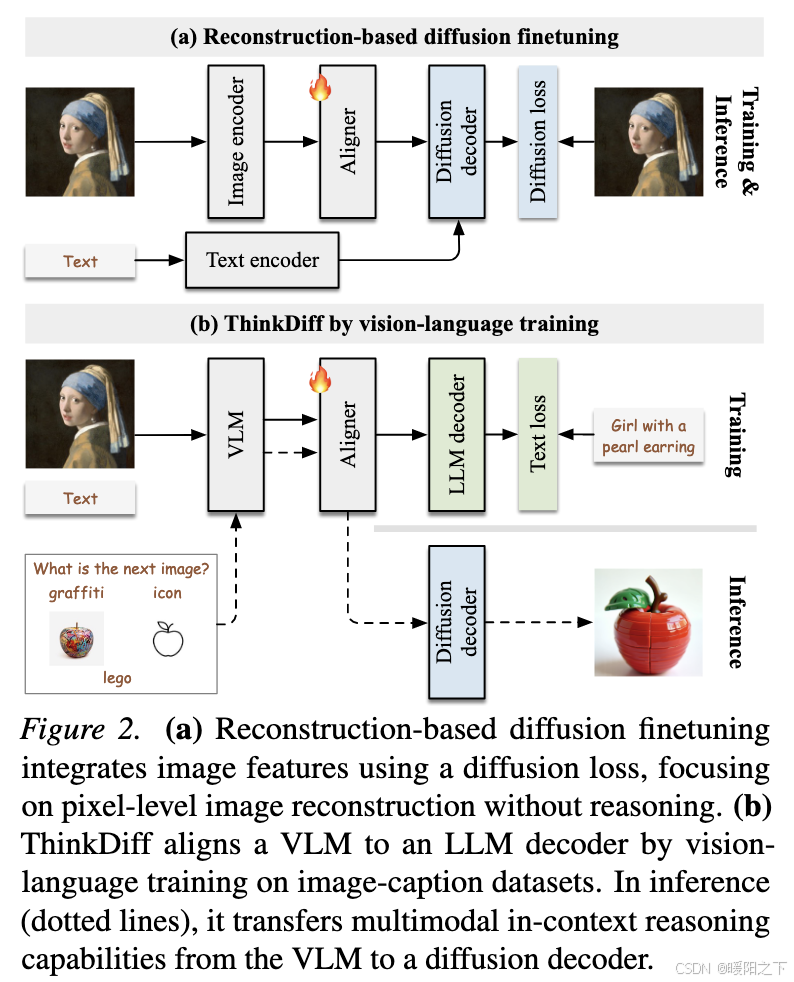
本图展示了ThinkDiff方法的核心流程,结合了视觉语言模型(VLM)的训练和基于重建的扩散微调。左侧部分描述了ThinkDiff在推理和训练过程中的主要步骤:首先,通过视觉语言模型(VLM)处理输入的图像和文本提示,然后通过一个对齐器将VLM的输出与大语言模型(LLM)解码器对齐,以计算文本损失。同时,VLM的输出通过扩散解码器生成最终的图像输出。右侧部分展示了通过视觉语言训练ThinkDiff的过程,包括使用文本编码器和图像编码器分别处理输入,再通过对齐器将信息传递给扩散解码器,以计算扩散损失。整个流程结合了多模态上下文理解和高质量图像生成,通过共享特征空间将视觉语言模型的推理能力迁移到扩散模型,使其具备根据文本提示生成和推理图像的能力。
1.3 实验

该表格展示了不同方法(SEED-LLaMA、Emu、GILL 和本文提出的方法)在多个生成维度(颜色、背景、风格、动作、质感,分为I和II两类)上的性能表现,以及本文方法相对于其他方法的提升百分比。数据显示,本文提出的方法在所有维度上的得分均显著高于其他对比方法,特别是在动作和背景维度上,提升幅度高达718.9%和676.3%(动作I和背景II),在其他维度也有明显提升,充分证明了本文方法在多模态生成任务中的优越性和全面性。
2、JiT研究
实验结果显示,x-prediction 比 v-prediction 差得多得多!这是论文有问题吗?
看了一遍论文后,认为论文的主要主张是「高分辨率像素 DiT 用 x-prediciton 更优」。
如下图所示,_base 指的是用 v-predition 的 baseline,_x0 指的是 JiT 最终采用的 x-prediction + v loss。这里输出的是 1000 个样本的 FID 指标 (越低越好)。训练一共执行 200 个 epoch,batch size 为 256。
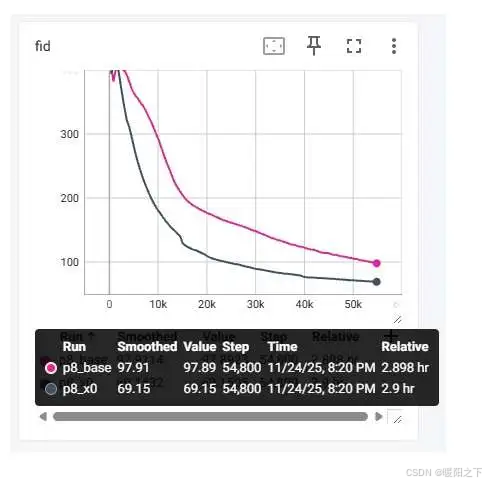
这样看来,对论文的结论理解似乎有误。论文的真正结论应该是「大 patch size 的 DiT 用 x-prediciton 更优」,和分辨率究竟多大,以及是否是像素 DiT 无关。
总结
本周通过对两篇前沿论文的系统性研读,深化了对多模态生成模型架构设计与扩散模型训练目标优化的理解。