序列化的概念
去网上检索序列化的概念,大概会得到如下的答案。
序列化 :将数据结构或对象状态 转换为一种可以存储或传输的格式的过程。这个过程使数据能够在不同的系统、平台或语言之间进行交换。
反序列化 :是相反的过程:将序列化后的数据还原为原始的数据结构或对象。
还是不太好理解,简单说下我的理解。
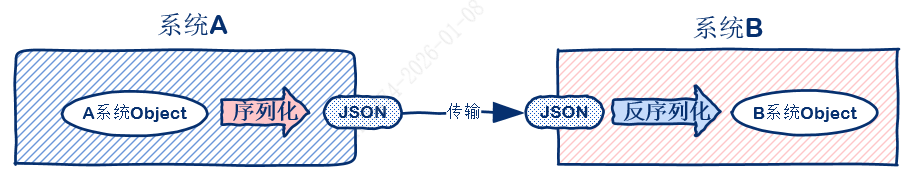
序列化就是为了数据交换做的一层翻译。
就比如键值对(key-value) 这个数据结构,在python中是字典,在javascript中是对象,在java中是hashmap,在数据库中是关系表。
如果一个python系统A想要把自己的键值对保存到数据库,或者告诉java系统B,因为语言不通,则系统A在传输之前,需要先将数据转化成一种接收方可以理解的格式。这个转化过程就是序列化。
常用的序列化的结果格式有JSON、XML等。
反序列化就是接收方把JSON、XML等转为自己支持的数据结构或对象。
在DRF中,序列化器是同时支持序列化和反序列化,因此序列化的代码和反序列化的代码也是揉在一起的,分析起来就不太容易理清。因此下面的分析采用面向功能进行拆解,把序列化和非序列化分开解析。
另外也有些代码是强合在一起,两边都会用的。比如初始化函数
python
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
pass当序列化时,只需要传入instance参数,传入一个object或者queryset实例即可。
当反序列化时,如果是新增数据,只需要将原始数据传入data,不需要传instance。
如果是要更新数据,除了要将更新数据传入data,还要将要更新的object传入instance。
初始化时的主要参数有:
data: 需要反序列化的数据,一般取自视图函数的request.data
instance: 序列化或者修改数据的时候使用。
many: bool类型,模型实例为查询结果集(QuerySet)需要传入
partial:部分更新模型实例数据的时候需要用到
context:需要传入额外反序列化数据的时候用到,如传入user_id
DRF中的序列化
序列化基本使用方法
python
# 定义model
from django.db import models
class User(models.Model):
name = models.CharField(max_length=12, verbose_name='姓名')
birthday = models.DateField(verbose_name='出生年月')
class Meta:
verbose_name = '用户表'
# 定义序列化:serializers.Serializer
from rest_framework import serializers
class UserSerializer(serializers.Serializer):
name = serializers.CharField(max_length=12,)
birthday = serializers.DateField()
# 视图中使用,序列化
from rest_framework.views import APIView
class UserViewSet(APIView):
# 对单个用户信息序列化
def get(self,request,pk,*args,**kwargs):
user_obj = User.objects.get(id=pk)
# instance传入单个object
ser = UserSerializer(instance=user_obj)
return Response(data=ser.data)
# 对多个用户序列化
def get(self,request,*args,**kwargs):
user_qs = User.objects.all()
# instance传入queryset时,设置many=True
ser = UserSerializer(instance=user_qs, many=True)
return Response(data=ser.data)
# 上面使用serializers.Serializer需要把models中的每个字段再定义一遍,比较麻烦
# 因此DRF提供了更便捷的方法serializers.ModelSerializer
# ModelSerializer会自动拆解model中的字段
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = '__all__'基础流程代码解析
总结下基础使用样例中对序列化的使用:
1、序列化定义
class UserSerializer(serializers.Serializer):
2、初始化
ser = UserSerializer(instance=user_obj)
或者
ser = UserSerializer(instance=user_qs, many=True)
3、获取序列化后的数据
ser.data
先看下初始化的过程ser = UserSerializer(instance=user_obj)
python
# rest_fromework.serializers.py
# class Serializer(BaseSerializer)类并没有定义__new__、__init__方法,因此走BaseSerializer类的初始化
class BaseSerializer(Field):
def __new__(cls, *args, **kwargs):
# 当many=True时,使用many_init函数新建实例,最终的序列化器使用ListSerializer
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
# 当many=False时,使用当前类新建实例,最终的序列化器使用Serializer
return super(BaseSerializer, cls).__new__(cls, *args, **kwargs)
@classmethod
def many_init(cls, *args, **kwargs):
# 此处的child_serializer就是用户自定义的序列化器,比如UserSerializer
# 注意__new__函数中的kwargs.pop('many', False)
# 因此此处child_serializer是不带many参数的序列化器
# 也就是此处的UserSerializer的父类是Serializer而不是ListSerializer
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
# 此处支持用户自定义List序列化方法
meta = getattr(cls, 'Meta', None)
# 默认使用ListSerializer类
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
return list_serializer_class(*args, **list_kwargs)也就是在many=True的情况下UserSerializer是serializers.ListSerializer的子类,
在many=False的情况下UserSerializer是serializers.Serializer的子类。
先分析下ser = UserSerializer(instance=user_obj)的情况,也就是
python
# rest_fromework.serializers.py
# 先从Serializer类入手,获取该类的data
@six.add_metaclass(SerializerMetaclass)
class Serializer(BaseSerializer):
@property
def data(self)
: # 调用父类的data
ret = super(Serializer, self).data
# ReturnDict就是一个有序字典,只不过增加了一个属性指向序列化器
return ReturnDict(ret, serializer=self)
class BaseSerializer(Field):
@property
def data(self):
if not hasattr(self, '_data'):
# instance is not None是序列化过程中使用的,其他分支是反序列化使用的
if self.instance is not None and not getattr(self, '_errors', None):
# 调用实例的to_representation
self._data = self.to_representation(self.instance)
return self._data
class Serializer(BaseSerializer):
def to_representation(self, instance):
ret = OrderedDict()
fields = self._readable_fields
# 循环所有可读字段
for field in fields:
attribute = field.get_attribute(instance)
# 调用每个字段的to_representation,对每个字段进行序列化
ret[field.field_name] = field.to_representation(attribute)
return ret再看下ser = UserSerializer(instance=user_qs, many=True)的情况
python
class ListSerializer(BaseSerializer):
def __init__(self, *args, **kwargs):
# 此处child是用户自定义的序列化类UserSerializer
self.child = kwargs.pop('child', copy.deepcopy(self.child))
super(ListSerializer, self).__init__(*args, **kwargs)
# .data调用此处的to_representation方法
def to_representation(self, data):
iterable = data.all() if isinstance(data, models.Manager) else data
# 返回用户自定义序列化器的to_representation方法
# 也就是Serializer类的to_representation
return [
self.child.to_representation(item) for item in iterable
]
class Serializer(BaseSerializer):
def to_representation(self, instance):
ret = OrderedDict()
fields = self._readable_fields
# 循环所有可读字段
for field in fields:
attribute = field.get_attribute(instance)
# 调用每个字段的to_representation,对每个字段进行序列化
ret[field.field_name] = field.to_representation(attribute)
return retsource参数
source参数的作用有
1、修改后端真实字段名
2、数据由表模型的方法生成,表中可能不存在相关字段。
3、关系型字段跨表操作。
用法如下:
python
# 表中存储的是name字段,序列化出来的是zh_name
class UserSerializer(serializers.Serializer):
zh_name = serializers.CharField(source="name")
# souce指向函数
class User(models.Model):
birthday = models.DateField(verbose_name='出生年月')
def age(self):
# 伪代码
return date.today() - self.birthday
class UserSerializer(serializers.Serializer):
age = serializers.IntegerField(source="age", read_only=True)
# souce指向关联字段,以点号连接
class User(models.Model):
dept= models.ForeignKey(to="deptment",verbose_name='所属部门',db_constraint=False)
class UserSerializer(serializers.Serializer):
dept_name = serializers.CharField(source="dept.name", read_only=True)相关代码说明
python
# 获取单个字段的数据实例位于to_representation函数
# attribute = field.get_attribute(instance)
# rest_framework.fields
class Field(object):
# 解析source属性,转化为内部使用的self.source_attrs
def bind(self, field_name, parent):
if self.source is None:
self.source = field_name
# SerializerMethodField字段就会用到source='*'
if self.source == '*':
self.source_attrs = []
else:
# 拆分多级字段
self.source_attrs = self.source.split('.')
def get_attribute(self, instance):
return get_attribute(instance, self.source_attrs)
def get_attribute(instance, attrs):
# 对于嵌套多层,逐层获取字段实例
for attr in attrs:
try:
if isinstance(instance, collections.Mapping):
instance = instance[attr]
else:
instance = getattr(instance, attr)
# 对于函数,直接调用函数返回实例
if is_simple_callable(instance):
instance = instance()
return instanceSerializerMethodField的使用
上面聊的source属性可以调用模型中的方法,序列化器也提供了可替代的机制,就是SerializerMethodField。
python
# model里只存储出生年月
class User(models.Model):
birthday = models.DateField(verbose_name='出生年月')
class UserSerializer(serializers.Serializer):
age = serializers.SerializerMethodField(read_only=True)
def get_age(self, obj):
# 伪代码
return date.today() - obj.birthday可以通过SerializerMethodField定义一个model里不存在的字段,然后定义一个名为get_{字段名}的函数,即可实现自定义的取数逻辑。
python
# rest_framework.fields
class SerializerMethodField(Field):
def bind(self, field_name, parent):
# 默认调用函数名为get_{field_name}
default_method_name = 'get_{field_name}'.format(field_name=field_name)
# 也可以通过method_name属性直接指定函数名
if self.method_name is None:
self.method_name = default_method_name
super(SerializerMethodField, self).bind(field_name, parent)
def to_representation(self, value):
method = getattr(self.parent, self.method_name)
# 执行函数,获取数据
return method(value)嵌套序列化器
序列化器可以嵌套使用。
python
class DeptSerializer(serializers.Serializer):
dept_name = serializers.CharField(max_length=12)
class UserSerializer(serializers.Serializer):
dept = DeptSerializer()相关代码
python
class BaseSerializer(Field):
pass
# 序列化器集成了Field类,也就是说序列化器也是field的一种。
# 因此就可以直接嵌套解析了depth参数
对于使用serializers.ModelSerializer的情况,默认是将关系自动解析成id,也就是PrimaryKeyRelatedField。
如果想要自动实现关系字段展开,就可以使用depth参数
python
class User(models.Model):
dept= models.ForeignKey(to="deptment",verbose_name='所属部门',db_constraint=False)
class UserSerializer(serializers.Serializer):
class Meta:
model = User
fields = '__all__'
depth = 1相关代码:
python
class ModelSerializer(Serializer):
def get_fields(self):
# 不设置depth的情况下,默认值为0
depth = getattr(self.Meta, 'depth', 0)
for field_name in field_names:
# ModelSerializer需要自动展开models中的字段,build_field对每个字段进行展开处理
field_class, field_kwargs = self.build_field(
source, info, model, depth
)
return fields
def build_field(self, field_name, info, model_class, nested_depth):
# 非关系字段,使用build_standard_field构建
if field_name in info.fields_and_pk:
model_field = info.fields_and_pk[field_name]
return self.build_standard_field(field_name, model_field)
# 关系字段处理
elif field_name in info.relations:
relation_info = info.relations[field_name]
# depth=0时,使用build_relational_field处理,转为主键格式
if not nested_depth:
return self.build_relational_field(field_name, relation_info)
# depth!=0时,使用build_nested_field处理成嵌套格式
else:
return self.build_nested_field(field_name, relation_info, nested_depth)DRF中的反序列化
常规的反序列化就是把A格式转为B格式,但DRF中的反序列化不能按照常规概念去理解。
转格式只是DRF反序列化提供的一个环节,之所以需要把前端数据转成后端的model对象格式,主要是为了保存或者更新后端数据表(model),因此序列化器默认提供了create()、update()方法。
因为要持久化数据,数据保存之前要加一层校验,比如常规的字段长度、是否为空等,于是序列化器又提供了数据校验的工具方法is_valid()函数。
而核心的反序列化的过程,又被打包进is_valid的过程中。
并且在create、update之前也必须要调用is_valid。因为create、update使用的数据validated_data是由is_valid函数生产的。因此可以说,is_valid函数处于整个反序列化过程的入口位置。
所以整体看,DRF的反序列化的功能如下:
validated_data
validated_data
数据校验+格式转化is_valid
保存model save
更新model update
以下分析主要基于serializers.ModelSerializer,因为ModelSerializer实现了update、create方法,一般情况下不需要自定义就可以用,而serializers.Serializer需要自己实现update、create方法。
基础使用
python
from rest_framework.views import APIView
class UserViewSet(APIView):
# 新增数据
def post(self, request, *args, **kwargs):
ser = UserSerializer(data=request.data)
ser.is_valid(raise_exception=True)
ser.save()
return Response(ser.data)
# 部分更新数据
def patch(self, request, pk, *args, **kwargs):
instance = User.objects.get(id=pk)
ser = UserSerializer(instance=instance, data=request.data, partial=True)
ser.is_valid(raise_exception=True)
ser.save()
return Response(ser.data)
# 不更新不保存,只对数据进行校验,很少有场景会用到
def put(self, request, pk, *args, **kwargs):
ser = UserSerializer(data=request.data)
ser.is_valid(raise_exception=True)
# 对校验过后的数据进行自定义处理,compute_user_info是自定义函数
compute_user_info(ser.validated_data)
return Response(ser.data)数据校验+格式转化is_valid
增加数据验证有以下几种方式:
1、字段级别定义validators属性,适合定义可复用的字段验证逻辑。
2、序列化器中定义validate_{字段名}的验证函数,适合对单个字段验证。
3、序列化器增加validate函数,适合跨字段关联验证。
python
from rest_framework import serializers
from rest_framework.validators import ValidationError
# 自定义验证化器,参数为验证的值value,若验证不通过则raise serializers.ValidationError
# 验证通过返回验证通过的value即可
class UniqueUsernameValidator:
def __call__(self, value):
if User.objects.filter(username=value).exists():
raise serializers.ValidationError("用户名已存在")
return value
class UserSerializer(serializers.Serializer):
# 字段级别定义validators属性,
username = serializers.CharField(
validators=[UniqueUsernameValidator()]
)
# 字段级别验证,定义validate_{字段名}
def validate_username(self, value):
if 'admin' in value.lower():
raise ValidationError("不能包含敏感词")
return value
# 对象级别验证,validate函数,可支持跨字段
# attrs为包含所有字段的字典
def validate(self, attrs):
if attrs['password'] != attrs['confirm_password']:
raise serializers.ValidationError({
'confirm_password': '两次密码不一致'
})
return attrs代码解析先从入口函数is_valid开始。
python
# ModelSerializer类、Serializer类都没有重写is_valid,使用的还是BaseSerializer类中的。
class ModelSerializer(Serializer):
pass
@six.add_metaclass(SerializerMetaclass)
class Serializer(BaseSerializer):
pass
class BaseSerializer(Field):
def is_valid(self, raise_exception=False):
if not hasattr(self, '_validated_data'):
try:
# 调用序列化器的run_validation进行验证
self._validated_data = self.run_validation(self.initial_data)
class Serializer(BaseSerializer):
def run_validation(self, data=empty):
# 先调用序列化类的to_internal_value函数--字段级别验证 + 反序列化
value = self.to_internal_value(data)
try:
# 再调用序列化类的run_validators函数
self.run_validators(value)
# 最后调用序列化类validate函数--全局验证函数
value = self.validate(value)
return value
# 序列化器的to_internal_value,实现字段级别验证 + 反序列化
def to_internal_value(self, data):
ret = OrderedDict()
fields = self._writable_fields
for field in fields:
validate_method = getattr(self, 'validate_' + field.field_name, None)
primitive_value = field.get_value(data)
try:
# 字段级别的run_validation
validated_value = field.run_validation(primitive_value)
# 字段级别的validate_{字段名}函数
if validate_method is not None:
validated_value = validate_method(validated_value)
else:
# 反序列化完成赋值给字典
set_value(ret, field.source_attrs, validated_value)
return ret
def run_validators(self, value):
# 精简掉去掉默认值的部分
to_validate = value
# 调用的Field类的run_validators
super(Serializer, self).run_validators(to_validate)
# 全局验证函数,支持跨字段验证
def validate(self, attrs):
return attrs
class Field(object):
# 字段级别的处理
def run_validation(self, data=empty):
# 对单个字段反序列化
value = self.to_internal_value(data)
# 运行字段级别定义的验证器
self.run_validators(value)
return value
# 单个字段的反序列化函数,每个字段中自定义的
def to_internal_value(self, data):
raise NotImplementedError(
'{cls}.to_internal_value() must be implemented.'.format(
cls=self.__class__.__name__
)
)
# 字段定义的验证器
def run_validators(self, value):
# 其中validators是字段属性,通过字段初始化的时候传入
for validator in self.validators:
try:
validator(value)
# 具体字段级别validators属性的逻辑
@property
def validators(self):
if not hasattr(self, '_validators'):
self._validators = self.get_validators()
return self._validators
@validators.setter
def validators(self, validators):
self._validators = validators
def __init__(self, read_only=False, write_only=False,
required=None, default=empty, initial=empty, source=None,
label=None, help_text=None, style=None,
error_messages=None, validators=None, allow_null=False):
pass数据保存
主要涉及三个函数
save()
create()
update()
但从上面使用可以知道,不管是更新还是保存,都是调用ser.save方法,而没有直接调用create、update方法,因为save方法会根据传参进行判定,是要update还是create。
python
class BaseSerializer(Field):
# 调用save之前必须要调用is_valid的原因在这,用到了self.validated_data
validated_data = dict(
list(self.validated_data.items()) +
list(kwargs.items())
)
# 反序列化过程中,对instance赋值就是更新,否则就是新增
# 序列化过程中,也是对instance赋值,参数复用,容易误导
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
else:
self.instance = self.create(validated_data)
return self.instance
# 只有ModelSerializer实现了create、update,使用其他序列化类要自定义
# create、update方法时,validated_data参数是直接传入的,并没有使用self.validated_data.
# 因此这两个方法并不直接依赖is_valid
# 只是为了数据安全,强烈建议先调用is_valid函数后使用self.validated_data传入create/update
class ModelSerializer(Serializer):
def create(self, validated_data):
pass
def update(self, instance, validated_data):
passModelSerializer反序列化时对关系字段的支持说明:
ModelSerializer默认的create和update方法支持关系字段,但有以下特点:
支持类型:
支持ForeignKey、OneToOneField(使用主键)
支持ManyToManyField(使用主键列表)
默认行为:
默认都使用主键字段进行操作,即前端传给后端的需要是主键,而不是对象。
限制:
不支持嵌套序列化器的创建/更新(需要自定义)
不支持反向关系字段(除非显式定义)
不支持复杂的关联对象创建逻辑
所以如果遇到限制情况,还是需要手动重写create\update
Django中的序列化
Django中序列化并没有向DRF中那么重的角色。
因为DRF是前后端分离的框架,需要后端把序列化后的数据传给前端,
而Django默认是返回给浏览器html,在view中可以直接把对象传递给Template系统,Template系统支持对象解析,并渲染成html后返给浏览器,因此很多时候用不到序列化。
但Django还是提供了序列化的方法。
基础使用
python
from django.core.serializers import serialize
from django.http import HttpResponse
from .models import Student
class UserView(View):
def get(self, request):
# 获取查询集
origin_students = User.objects.all()
# 将查询集序列化为JSON格式
serialized_students = serialize("json", origin_students)
# 将JSON数据响应给客户端
return HttpResponse(serialized_students, content_type='application/json')Django中的序列化方法就跟常规的序列化概念很像,
提供一个工具函数,传入待转化的对象A和格式要求,输出转化后的数据。
其中格式支持json、xml、yaml等。待转化的对象为QuerySet。
代码结构比较简单,就不再展开说明了,直接贴出来工具函数的定义如下。
python
# django.core.serializers.__init__
def serialize(format, queryset, **options):
s = get_serializer(format)()
s.serialize(queryset, **options)
return s.getvalue()另外还有一个函数也可以支持对象转字典--model_to_dict。
python
class UserView(View):
def get(self, request, *args, **kwargs):
obj = User.objects.get(id=pk)
obj_dict = model_to_dict(obj)
return HttpResponse(obj_dict , content_type='application/json')相关代码解析
python
# django.forms.models
def model_to_dict(instance, fields=None, exclude=None):
opts = instance._meta
data = {}
for f in chain(opts.concrete_fields, opts.private_fields, opts.many_to_many):
if not getattr(f, 'editable', False):
continue
if fields and f.name not in fields:
continue
if exclude and f.name in exclude:
continue
data[f.name] = f.value_from_object(instance)
return dataDjango中的反序列化
Django中的反序列化其实主要在forms模块中实现,包括数据校验,因为现在大家都有DRF了,这部分就不展开说明了。