突然问你一个问题:你听说过 Annapurna Labs 吗?
如果你对 AWS 这些年的"自研芯片路线"有所关注,那这个名字,你其实早就"用过",只是未必意识到。
Annapurna Labs 是一家半导体设计初创公司,在 2015 年被 Amazon / AWS 收购 。从那一刻起,它正式成为 AWS 内部最核心、也最低调的一支"芯片军团"。
此后,AWS 一系列关键自研芯片的背后,都有它的身影------
AWS Nitro、AWS Graviton、AWS Trainium、Inferentia,全部出自这支团队之手。
在每年的 re:Invent Keynote 上,AWS 总会留出一部分时间,聊一聊这些平时"躲在幕后"的自研芯片。对很多资深 AWS 用户来说,这几乎已经成了 Keynote 的"固定彩蛋"。
而就在 12 月 1 日~5 日举办的 re:Invent 2025 上,Annapurna Labs 再次站到了聚光灯下,带来了两项重量级发布:
这两款芯片,分别代表了 AWS 在通用计算与 AI 训练领域的最新野心。
本文将把焦点放在 AWS Trainium3 上 ,带你一起看看:
AWS 是如何一步步,把 AI 训练这件事,真正"做到自己手里"的。
下面是在严格保持技术准确性的前提下,对全文进行系统性中文翻译 + 科技写作向润色 的版本。
整体风格偏 AWS 技术深度解读 / re:Invent 技术盘点,逻辑连贯、信息完整,也更适合公众号 / 技术博客 / 小红书长文阅读。
AWS Trainium3
AWS Trainium3 是 AWS 自研 AI 芯片路线上的第四代产品。
从时间线上看,这条路线可以追溯到 2019 年 。当年,AWS 正式推出了搭载第一代推理专用芯片 Inferentia 的实例,宣告 AWS 正式进入自研 AI 加速芯片时代。
从那一刻开始,Inferentia → Trainium → Trainium2 → Trainium3,AWS 在 AI 芯片领域的演进路径异常清晰。
在刚刚结束的 re:Invent 2025 上,Trainium3 被推到了舞台中央:
无论是 AWS CEO Matt Garman 的 Keynote,
还是 AWS 基础设施负责人 Peter DeSantis 主讲的 Infrastructure Innovations Keynote,
Trainium3 都是被反复强调的核心发布之一。
最初,AWS 将推理专用芯片命名为 Inferentia ,而将同时支持训练的芯片命名为 Trainium 。
但从 Trainium2 开始,这种"推理 / 训练"的界线已经明显变得模糊------Trainium 在推理与训练两类工作负载中都被广泛使用。

这也反映了当下 AI 基础设施的一个现实趋势:
将推理芯片与训练芯片严格区分的意义,正在迅速降低。
随着模型规模持续扩大、推理复杂度不断提升,以及在线微调、持续学习等场景的普及,
一颗同时兼顾训练与推理效率的 AI 芯片,反而更具工程与商业价值。
Trainium2 已经在大规模实战中"打过仗"
很多人可能还没意识到,其实 Trainium2 早已进入大规模生产环境。
根据 AWS 在 2025 年 10 月 29 日 发布的官方文章,在 AWS 与 Anthropic 的联合项目------
位于美国印第安纳州的最新数据中心 Project Rainier 中,
已有约 50 万颗 Trainium2 芯片在稳定运行 ,并计划在 2025 年底扩展到 100 万颗以上。

更有意思的是:
最新版本的 Claude 模型,正是运行在 Trainium2 之上。
也就是说,很多人每天在使用 Claude 的过程中,其实早已在"无感享受" Trainium2 带来的算力红利。
而现在,接过这根接力棒的,就是 AWS Trainium3。
Trainium3:一次面向下一代大模型的硬件跃迁
先用几个关键数字,快速感受一下 Trainium3 的升级幅度(相较 Trainium2):
-
FP8 计算性能:提升 2 倍
-
HBM 内存容量:从 96 GiB 提升至 144 GiB(1.5 倍)
-
内存带宽:提升 1.7 倍
-
芯片间互连带宽:提升 2 倍
这些提升,直接作用于多芯片、多节点场景下的分布式训练与分布式推理性能。
此外,Trainium3 还在硬件层面新增支持 MXFP4(4-bit 量化) ,这一格式也已被 OpenAI 公布的 GPT-OSS 模型采用。
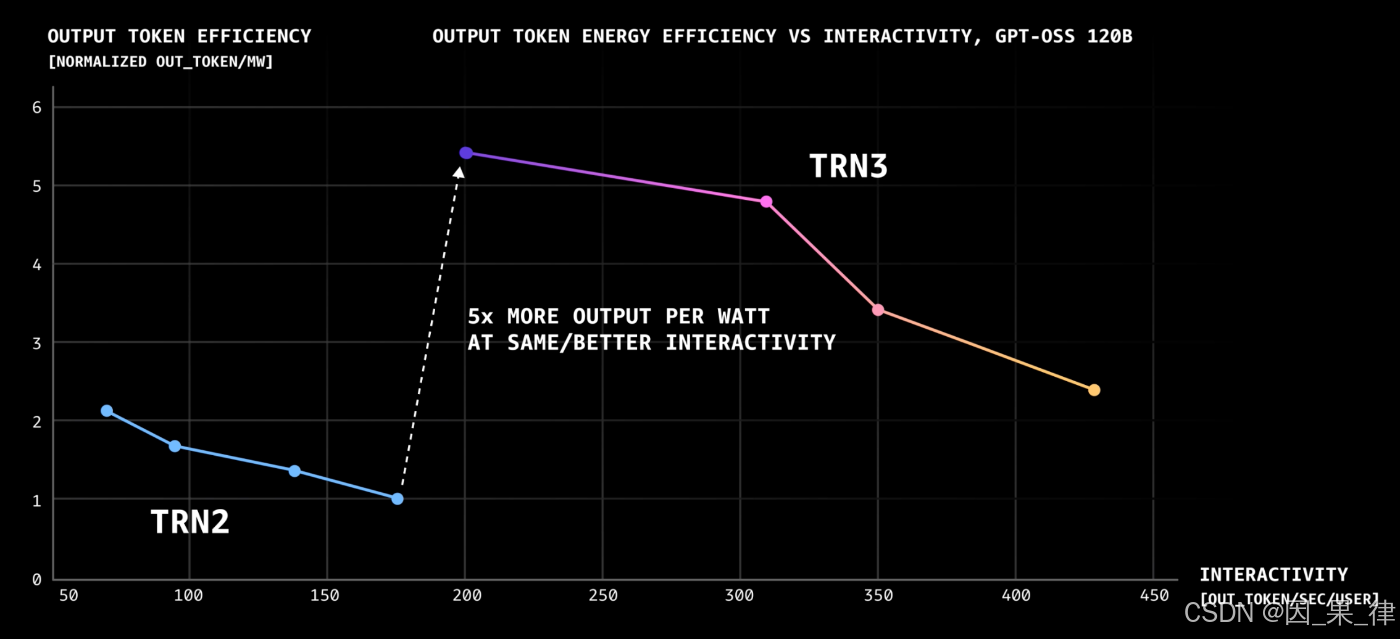
在 Trn3 UltraServers 上运行 GPT-OSS-120B 模型时,实测数据显示:
👉 单位功耗下的 Token 生成性能,相比 Trn2 提升超过 5 倍。
这并不是"参数堆出来的提升",而是一次真正面向 AI 工作负载的系统级优化。
Trainium3 UltraServers:把"规模"做到极致
上一代 Trainium2 UltraServers ,是由 4 台 trn2.48xlarge 组成,
总计 64 颗 Trainium2 芯片 。
在 2025 AWS Summit Tokyo 上,甚至还有等比例的实物展示,不少人应该都留下了深刻印象。
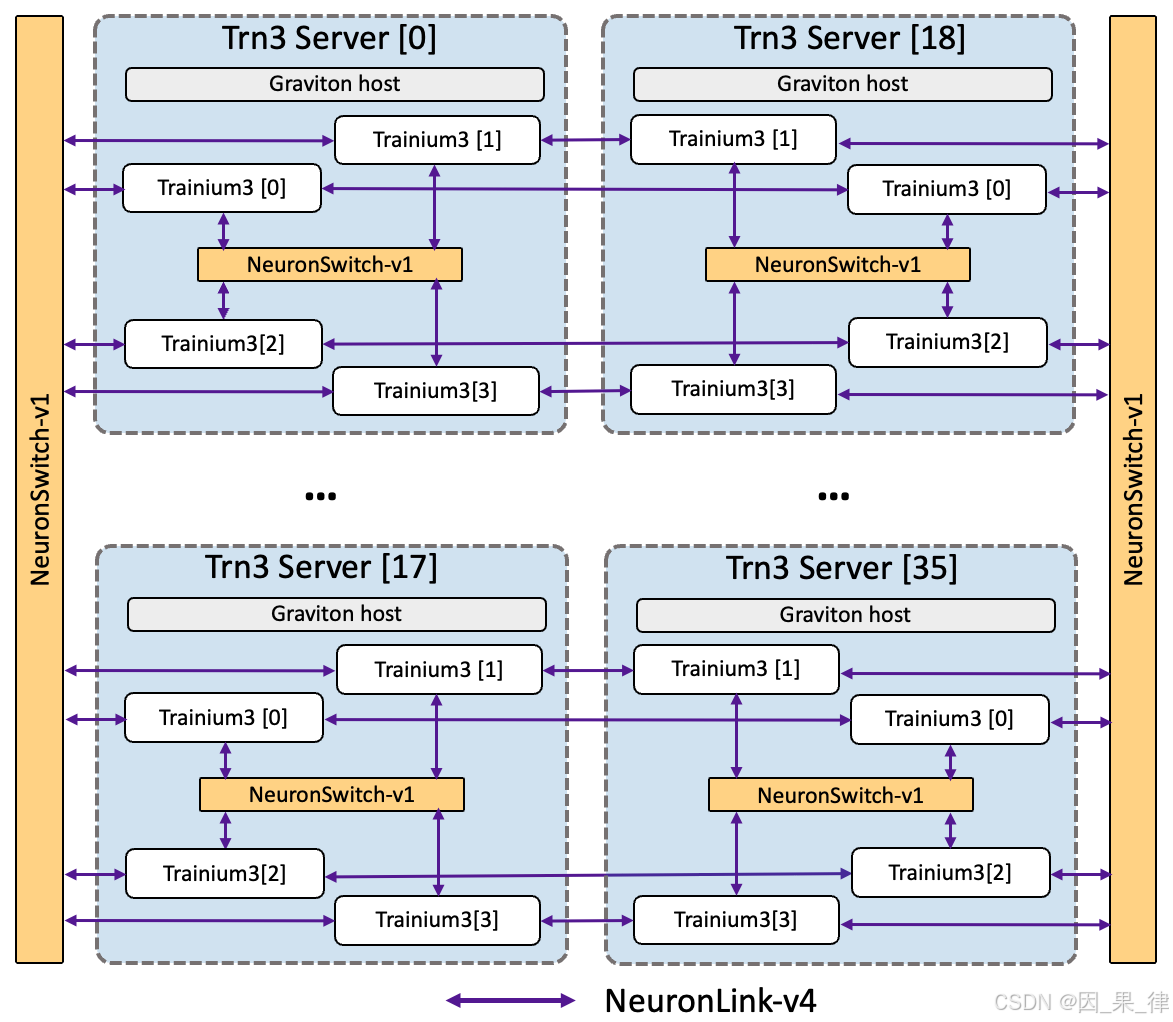
而这一次,第二代 UltraServers 直接拉满规格:
-
36 个模块
-
每个模块 4 颗 Trainium3
-
总计 144 颗 Trainium3 芯片
芯片之间采用 all-to-all 互联结构 ,
并为此专门开发了新的 NeuronSwitch 互连芯片。
最终形成的能力指标相当夸张:
-
360 PFLOPS(MXFP8)算力
-
20 TB HBM3E 内存容量
-
700 TB/s 以上的内存带宽
同时,每个模块还集成了 Graviton 处理器 与 两颗 Nitro 芯片 ------
可以说,这是一次把 AWS 所有自研硅创新"打包上阵" 的设计。

Native PyTorch:真正降低上手门槛
硬件之外,软件生态的变化,可能更重要。
虽然 Trainium 已经被 Anthropic 、Amazon Rufus 等大规模使用,但在更广泛的开发者群体中,普及仍然面临现实阻力。
原因很简单:
-
AWS 同时也提供大量 NVIDIA GPU 实例
-
GPU 拥有成熟、稳固的生态
-
Neuron SDK 的学习成本,一直是心理门槛
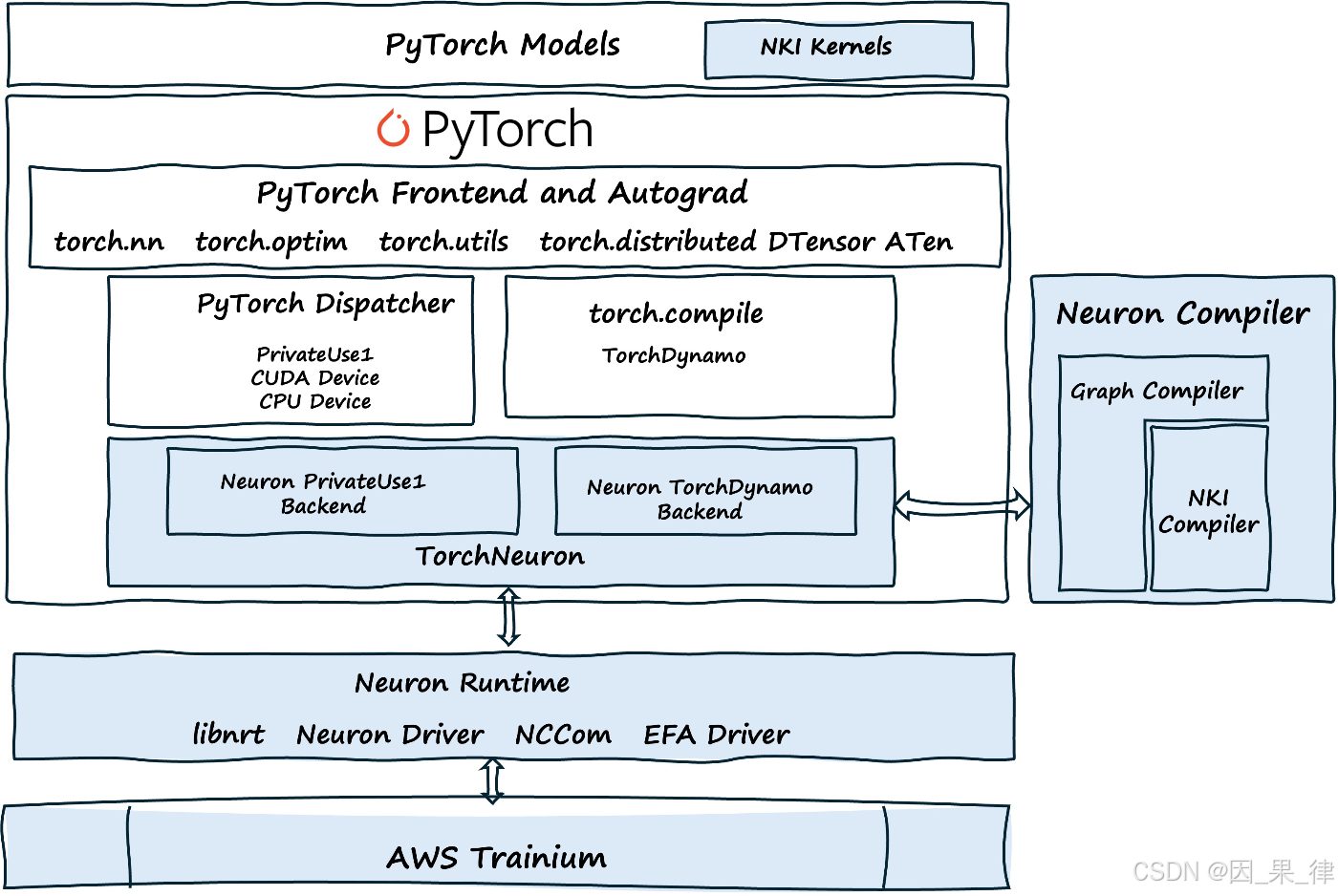
这一次,AWS 给出了一个非常"工程化"的答案 ------ TorchNeuron。
TorchNeuron 是什么?
TorchNeuron 是一个开源的 PyTorch 后端 ,
为 Trainium(Trn1 / Trn2 / Trn3)实例提供原生 PyTorch 支持。
它带来的变化非常关键:
-
支持 Eager(即时执行)模式
-
支持
torch.compile -
原生支持 DTensor、FSDP 等 PyTorch 分布式 API
对于 AI 研究者和 ML 工程师来说,这意味着:
👉 几乎不需要改代码,就能在 Trainium 上跑 PyTorch。
代码对比(几乎"零侵入")
原本基于 GPU 的典型代码:
model = MyModel().to('cuda')
optimizer = torch.optim.AdamW(model.parameters())
for batch in dataloader:
optimizer.zero_grad()
output = model(batch)
loss = criterion(output, targets)
loss.backward()
optimizer.step()使用 TorchNeuron 后,仅需一行修改:
model = MyModel().to('neuron') # 仅此一处修改
optimizer = torch.optim.AdamW(model.parameters())
for batch in dataloader:
optimizer.zero_grad()
output = model(batch)
loss = criterion(output, targets)
loss.backward()
optimizer.step()如果你使用的是 torch.accelerator.is_available()、
torch.accelerator.memory_allocated() 这类加速器无关 API ,
甚至连这一行都不需要改。
在 re:Invent 2025 现场,AWS 还演示了:
直接从官方仓库 clone TorchTitan ,
在 不修改任何代码的情况下 ,完成 Qwen3 模型的分布式训练。
NKI:把性能"榨到最后一滴"
如果你想进一步突破性能上限,那就要认识 NKI(Neuron Kernel Interface)。
NKI 是一个直接面向 Trainium 内部执行引擎的裸金属级接口 ,
采用 Python 风格语法,体验类似 Triton / NumPy,但控制粒度更细。
在本次发布中,NKI 迎来了质变级升级:
关键新特性
-
开源编译器:基于 MLIR,Apache 2.0 许可
-
指令级控制 API:精细控制计算、内存、调度
-
完整 ISA 访问:真正意义上的硬件直控
-
NKI-Lib:提供 Dense / MoE / 多模态模型的高性能内核
-
框架集成:无缝对接 PyTorch、JAX、vLLM、Optimum Neuron
即便你不打算自己写内核,
直接使用 NKI-Lib 也已经覆盖大量生产级场景。
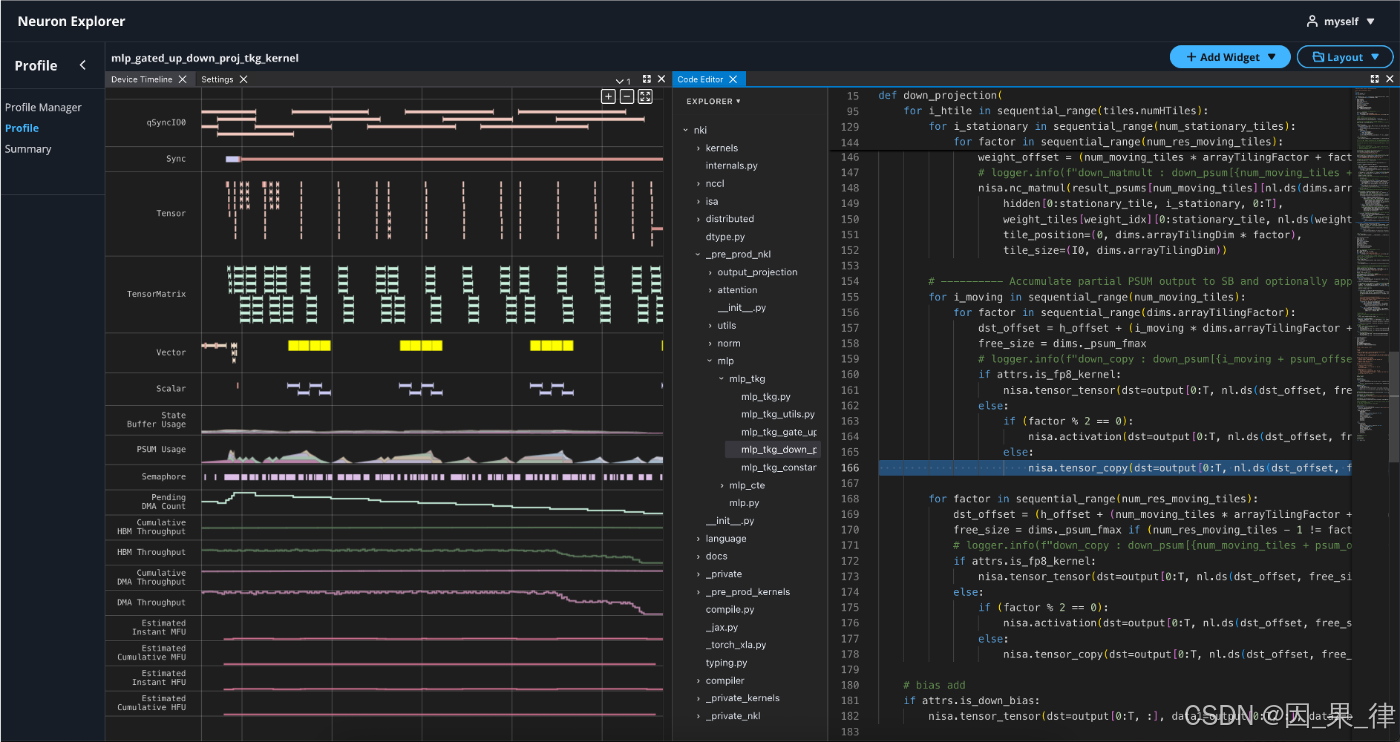
Neuron Explorer:优化不再靠"猜"
性能优化,第一步永远是看清楚问题在哪。
这一次,原本的 Neuron Profiler 系列工具,全面升级为 Neuron Explorer:
-
分层可视化:从框架 → HLO → 指令
-
源码级关联:直接定位到 PyTorch / JAX / NKI 代码行
-
VS Code 集成
-
AI 自动优化建议
-
系统级统一监控
-
更快的分析后端(Parquet 优化)
从定位瓶颈到给出优化方向,整个闭环明显更短、更可操作。
总结
也许你会想:
"这些东西看起来都很强,但我并不需要这么大的训练规模。"
其实 AWS 早已考虑到了这一点。
在大规模发布之外,AWS 也已经推出了单芯片的 trn2.3xlarge 实例 ,
re:Invent 2025 现场也安排了多场基于该实例的动手实验。
re:Invent 的 Keynote 与相关 Session 目前已陆续在 YouTube 上线。
如果只能推荐一场,我个人最推荐的是:
AIM3335: AWS Trn3 UltraServers: Power next-generation enterprise AI performance