本章是学习 宅学部落-王利涛 内存管理视频教程的笔记,方便后面复习。讲的很好很细,怒赞推广一下。
目录
三,CMA
一,重要概念
PFN:物理页帧,其中PAGE_SHIFT是页大小的对数值(如4KB对应PAGE_SHIFT=12)
ORDER:伙伴系统的阶数(最大为MAX_ORDER),在大多数主流系统上,其默认值为 11 当 MAX_ORDER 为 11 时,意味着内核维护了从阶数 0 到阶数 10 的 11 个空闲块链表,因此能分配的最大内存块是阶数为 10 的块(即 2¹⁰ = 1024 个页面)
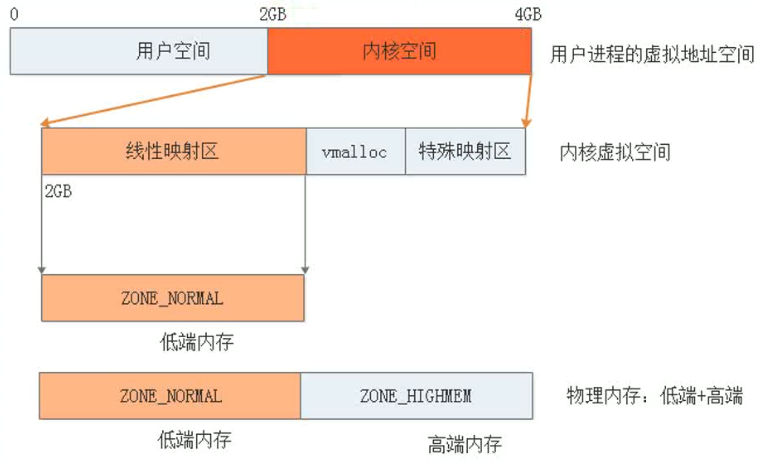
ZONE域:kernel物理内存分成几块区域,如图
二,伙伴系统
伙伴系统是Linux内核中基于伙伴内存分页模型的物理内存管理算法,由Knowlton设计,采用二进制伙伴算法管理物理页面。其通过free_area数组维护11个阶数(2^0至2^10)的空闲块链表,最大支持分配4MB连续内存。系统以页框为单位分配内存,采用递归拆分与合并机制:当申请特定大小内存块时,优先匹配对应阶数的链表;若无可用块则拆分更高阶块,释放时合并相邻空闲块。
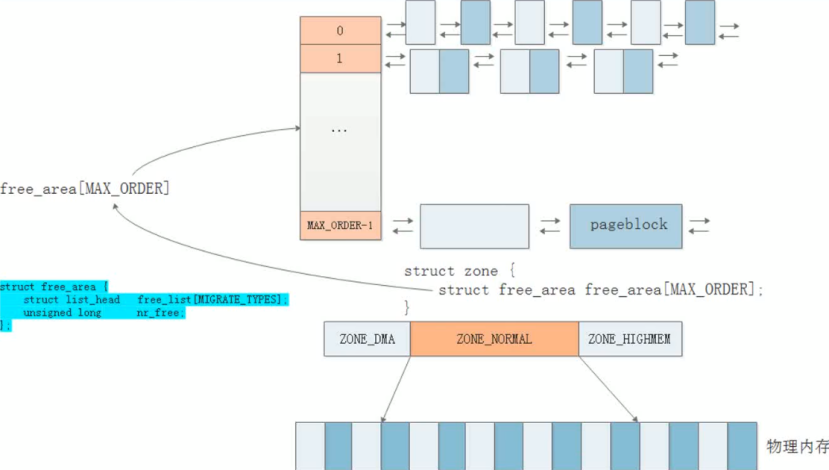
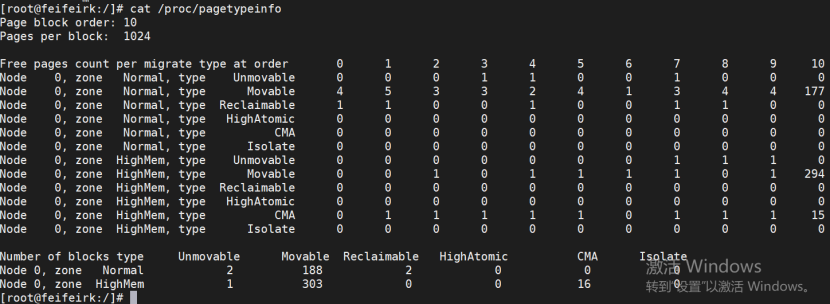
通过命令查看伙伴系统信息,每个order显示一列

新版的伙伴系统根据权限将每个ORDER细分为可移动的,不可移动的,可回收的,孤立的等等,对应不同的权限和功能属性。
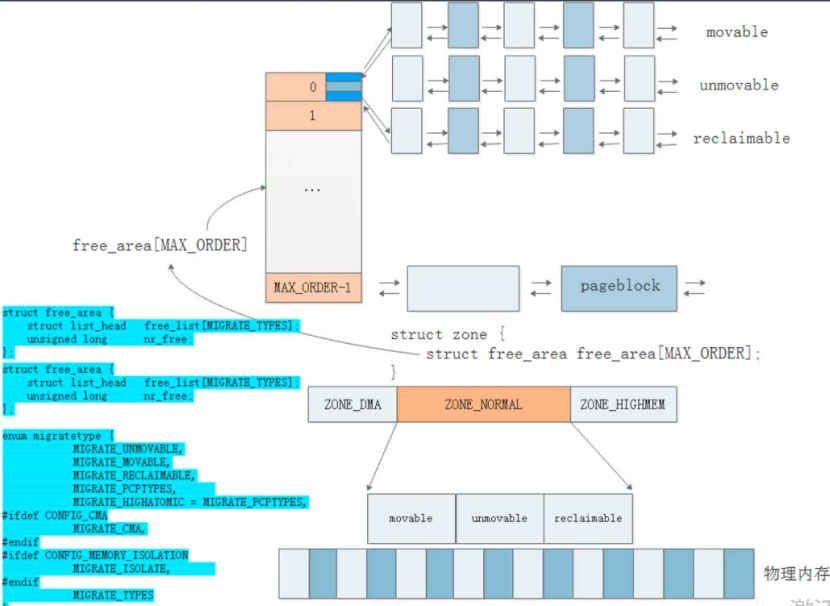
通过/proc/pagetypeinfo可以查看详细信息
通过命令可以手动处理内存碎片迁移,前提是迁移的page是可移动或可回收的。

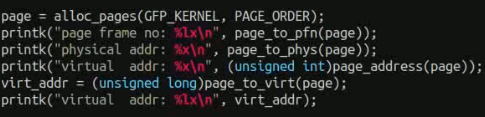
申请Page的方法
alloc_page函数实现页申请,GFP flag属性可以配置申请的属性,比如申请的zone域,是否可睡眠,是否等待等等。

三,CMA
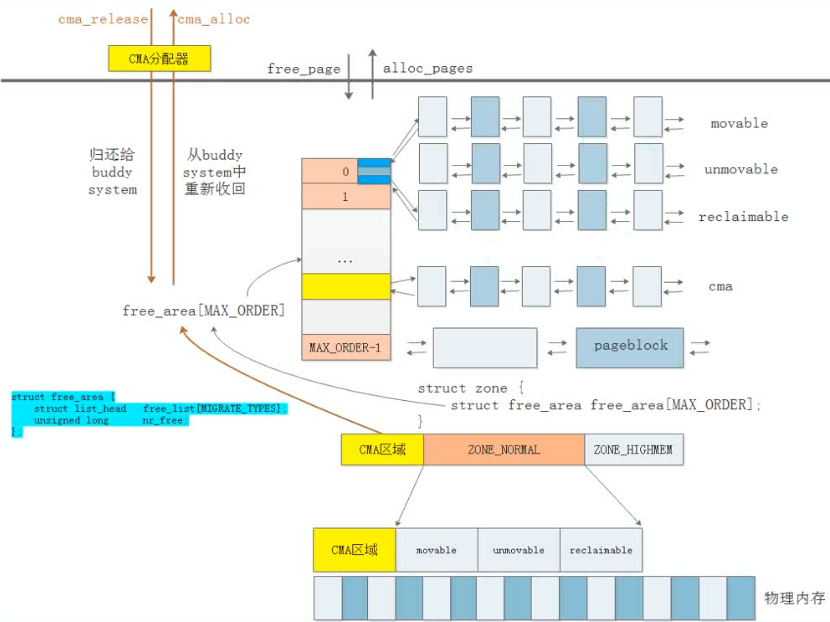
Linux kernel中的CMA即连续内存区管理,其提供配置为CONFIG_CMA和CONFIG_CMA_DEBUG ,其管理的是一块块连续内存块。这个在物理地址上是连续的。这点跟我们使用的伙伴算法 以及虚拟地址有点不一样。尽管伙伴算法中使用kmalloc申请连续物理内存也可以,但是在长时间 测试环境下,连续物理内存可能申请不到。因此,内核设计者设计了CMA,即连续物理内存管理。 其定制了一块连续物理内存,专门用于需要连续物理内存的场景,比如DMA。
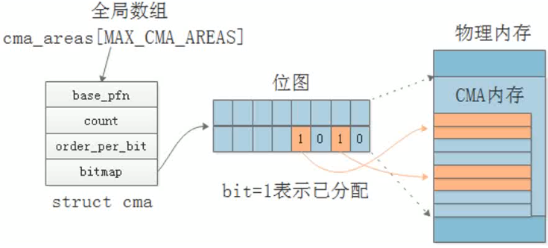
cma根据order_per_bit将连续内存分割成块,使用bitmap位图标识每一块的使用状态。
用户不使用cma空间时,cma的内存被释放到伙伴系统中使用,但只能释放到可移动的或可回收的链表中。
用户使用cma时,cma结构体根据bitmap的状态进行cma块回收,释放出连续的物理内存,通过cma接口返回给调用者。
四,Reserve内存
Reserve内存包括:
(1)内核代码段(text/data/bss)(init除外)
(2)dtb
(3)uboot
(4)页表
(5)initrd
(6)设备数的reserved-memory区域(cma除外)
通过命令cat /proc/sys/kernel/debug/memblock/reserved可以查看reserved信息
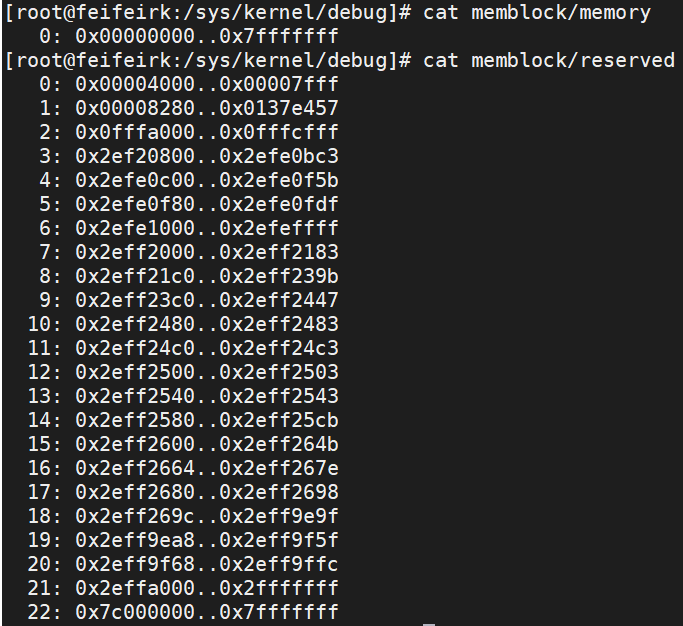
reserved结构体存储方式
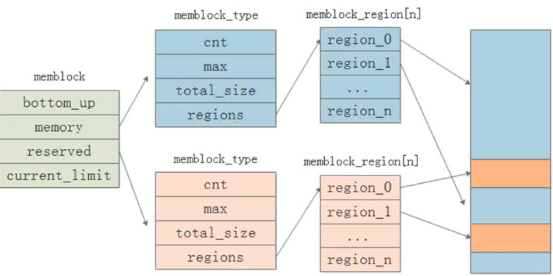
五,slab
slab是Linux操作系统内核采用的小内存分配机制。
该机制基于对象管理思想,通过为频繁分配的内核对象(如进程描述符)建立缓存,减少内存碎片并提升分配效率。其核心结构包括cache和slab:每个cache存储同类对象,分配时从预留列表获取,释放后保留对象复用以减少伙伴系统的调用次数;每个slab由连续页框构成并包含多个空闲对象 。Linux系统通过定义kmem_cache对象初始化缓存,支持硬件缓存对齐优化。
分配算法优先使用部分空闲slab,不足时申请新slab。在嵌入式系统中,SLOB分配器可作为替代方案,但存在碎片问题且扩展性受限。内核启动阶段通过kmem_cache_init()函数完成slab分配器初始化,标志着内存管理系统正式启用。
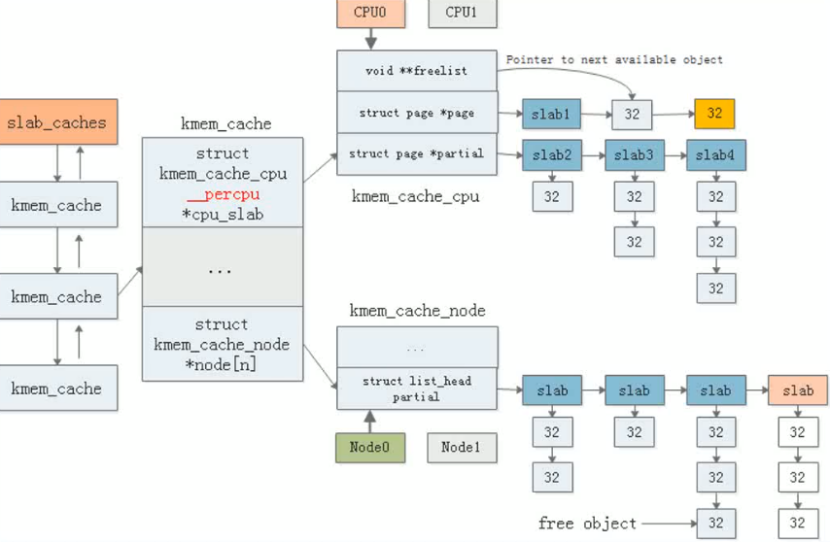
可以通过kmem_cache_create创建kmem_cache,通过kmem_cache_alloc申请slab内存

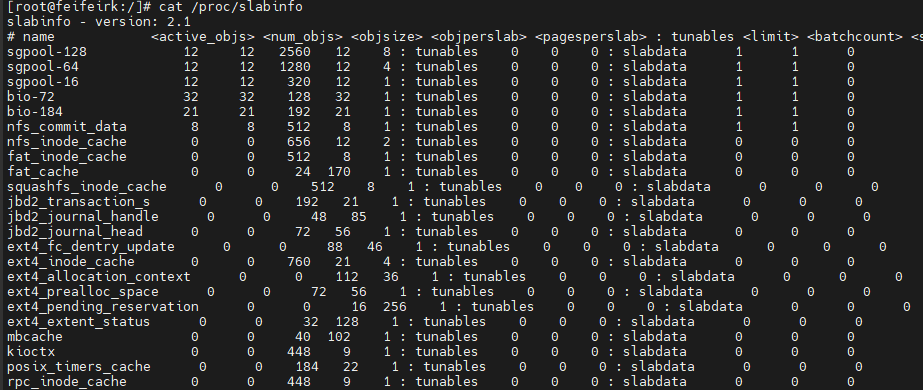
通过命令cat /proc/slabinfo可以查看slab状态信息
name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
六,section页表和二级page页表
页表是MMU的重要概念,MMU需要通过页表映射实现物理地址和虚拟地址的转换,kernel采用多级页表的形式实现内存使用轻量化。有两中页表映射方式:page映射和section映射。
kernel运行前期采用section映射,每个section页表项对应1M字节,直接使用页表项的最高12位替代虚拟地址的高12位即可得到物理地址。
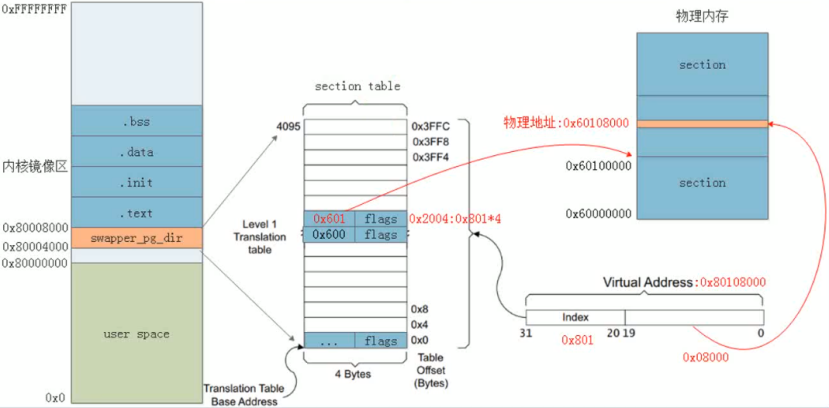
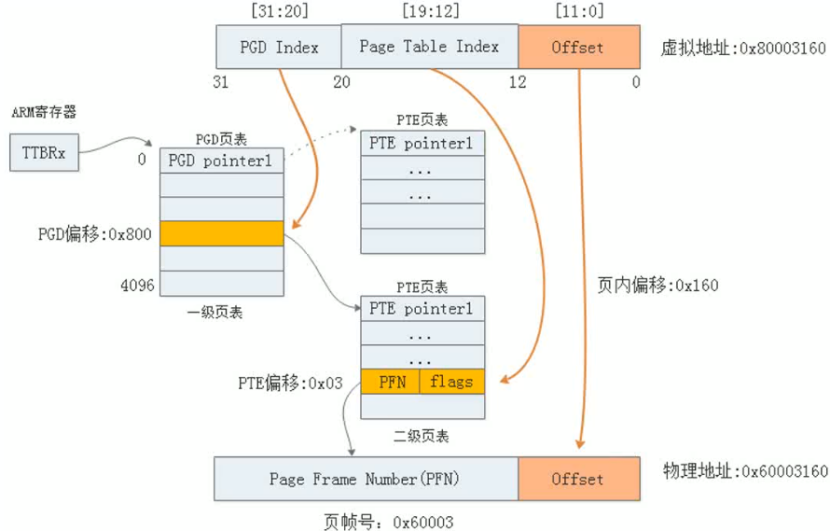
kernel运行后期采用Page映射方式,常用的Page映射是二级页表映射,使用Page映射方式的优势是内存地址与伙伴系统对齐,节省转换的耗时。二级页表分为PGD和PTE两种页表:
一级页表PGD:一个4096项,每个entry 4个字节,一共16个字节
二级页表PTE:一共4096个PTE页表,每个二级页表包含256个页表项entry,大小1KB。所有二级页表大小(4KB*1KB=4MB)
七,vmalloc
vmalloc 和 kmalloc 的核心区别在于物理内存是否连续:kmalloc 分配物理连续的内存块,适合小块高速需求;vmalloc 分配虚拟连续但物理不连续的内存,适合大块灵活需求。 以下是详细对比:
物理内存是否连续
- kmalloc:分配的内存物理地址连续(如设备驱动、DMA 操作),硬件可直接访问。
- vmalloc:物理地址不连续,通过页表映射实现虚拟地址连续,无法直接用于硬件操作。
虚拟内存连续性
- 两者相同 :都保证虚拟地址空间连续,但实现方式不同:
- kmalloc 的虚拟地址与物理地址仅差固定偏移(如
物理地址 + PAGE_OFFSET),无需修改页表。15 - vmalloc 需动态建立页表映射离散物理页到连续虚拟地址,效率较低。
- kmalloc 的虚拟地址与物理地址仅差固定偏移(如
分配大小限制
- kmalloc:通常 ≤128KB(如内核对象、缓冲区),超过此值可能失败。
- vmalloc:无硬性限制,可分配 GB 级内存(如模块加载、大缓冲区)。

vm_struct的pages会缓存所有vmalloc使用的非连续的pages页
八,ioremap
ioremap是一个内核函数,仅由内核驱动程序调用,用于将设备的物理内存(MMIO区域) 映射到内核的虚拟地址空间。
原理如下:
(1)设备(如PCIe网卡)的寄存器或板载内存通过BAR被配置到一段物理地址。CPU无法直接用这个物理地址编程。
(2)驱动在初始化时调用ioremap(phys_addr, size)。
(3)内核在其虚拟地址空间找一段空闲的虚拟地址,并建立该虚拟地址到设备物理地址的页表映射。
(4)函数返回一个内核虚拟地址。驱动后续通过这个虚拟地址,可使用专用函数访问设备。

九,进程虚拟内存
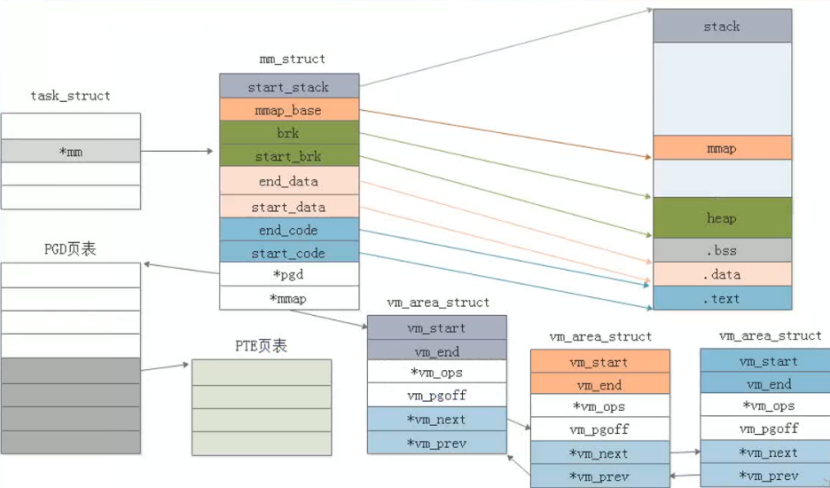
进程的虚拟地址空间是指可供该进程使用的一组虚拟内存地址。 每个进程的地址空间均为私有;除非进行共享,否则其他进程无法访问该地址空间。
虚拟地址不表示内存中某一对象的实际物理位置;相反,系统会为每个进程维护一个页面表;它是一个内部数据结构,可用于将虚拟地址转换为相应的物理地址。 每当线程引用地址时,系统均会将虚拟地址转换为物理地址。
因为每个进程的虚拟地址范围相同,所以每个进程维护自己的一套页映射表,通过将进程页表地址配置给MMU实现不同的进程相同的虚拟地址映射到不同的物理地址。进程的页表地址通过pdg成员变量保存。


十,mmap
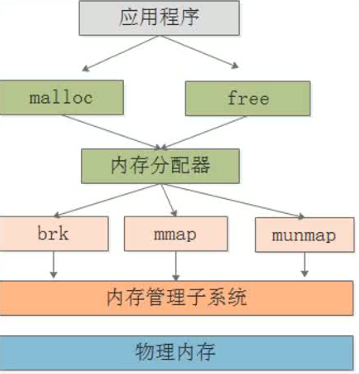
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
实际上,mmap()系统调用并不是完全为了用于共享内存而设计的。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。而Posix或System V的共享内存IPC则纯粹用于共享目的,当然mmap()实现共享内存也是其主要应用之一。
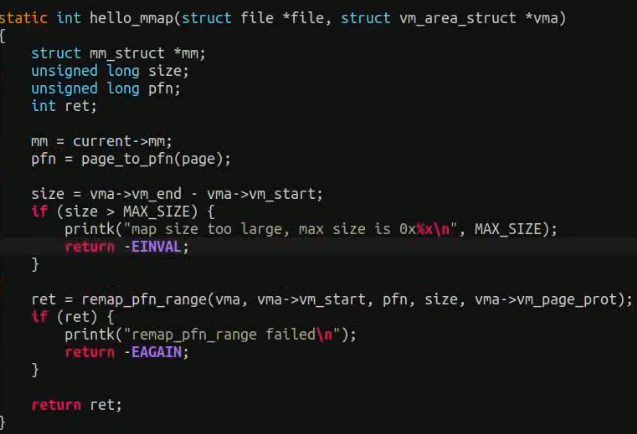
mmap ko实现的例子,使用remap_pfn_range实现
remap_pfn_range 是 Linux 内核中的一个函数,用于将物理页面框号(PFN)映射到用户空间的虚拟地址范围中。PFN 是物理页面在内存中的索引,而不是直接的物理地址。这个函数在内核中的 mm/memory.c 文件中定义。
int remap_pfn_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long pfn, unsigned long size, pgprot_t prot);
// 参数和返回值说明
vma: 虚拟内存区域结构体指针,描述了要进行映射的虚拟内存区域。
virt_addr: 用户空间中要映射的虚拟地址的起始地址。
pfn: 物理页面框号的起始地址,即要映射的物理页面在内存中的索引。
size: 要映射的内存区域大小。
prot: 要应用于映射区域的页面保护标志,通常使用 vm_page_prot 定义。
映射成功返回0,失败返回错误码