欠拟合与过拟合
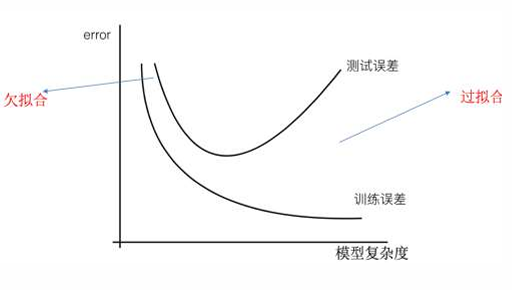
• 欠拟合:模型在训练集上表现不好,在测试集上也表现不好。模型过于简单,在训练集和测试集上的误差都较大。
• 过拟合:模型在训练集上表现好,在测试集上表现不好。模型过于复杂,在训练集上误差较小,而测试集上误差较大。
欠拟合出现的原因
学习到数据的特征过少,解决办法 【从数据、模型、算法的角度去想解决方案】
解决方法:
• 有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决
• "组合"、"泛化"、"相关性"三类特征是特征添加的重要手段
• 模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强
过拟合出现的原因
原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决方法:
• 重新清洗数据,对于过多异常点数据、数据不纯的地方再处
• 增大数据的训练量,对原来的数据训练的太过了,增加数据量的情况下,会缓解
• 正则化,解决模型过拟合的方法,在机器学习、深度学习中大量使用
• 减少特征维度,防止维灾难 ,由于特征多,样本数量少,导致学习不充分,泛化能力差。
欠拟合案例
python
# 1.导入依赖包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm01_underfitting():
# 2.准备数据x y(增加上噪声)
# 固定随机种子用于复现
np.random.seed(666)
# -3~3 的随机数
x = np.random.uniform(-3, 3, size=100)
# 正态分布,方差为0,均值为1
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 3 训练模型
# 3.1 实例化线性回归模型
estimator = LinearRegression()
# 3.2 模型训练
X = x.reshape(-1, 1)
estimator.fit(X, y)
# 4 模型预测
y_predict = estimator.predict(X)
# 5 模型评估,计算均方误差
# 5.1 模型评估MSE
myret = mean_squared_error(y, y_predict)
print('myret -->', myret)
# 5.2 展示效果
plt.scatter(x, y)
plt.plot(x, y_predict, color='r')
plt.show()
dm01_underfitting()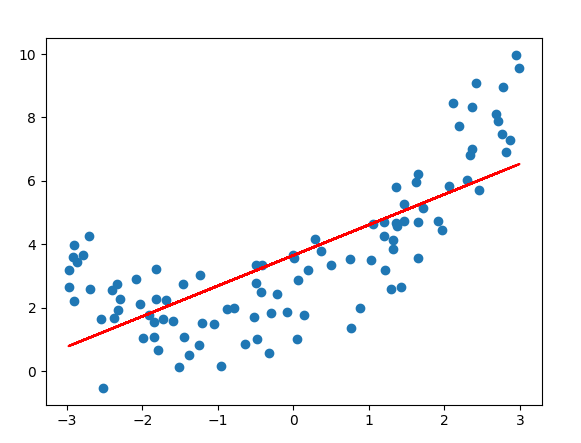
过拟合案例
python
def dm02_overfitting():
# 2.准备数据x y(增加上噪声)
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 3 训练模型
# 3.1 实例化线性回归模型
estimator = LinearRegression()
# 3.2 模型训练
X = x.reshape(-1, 1)
# print('X.shape-->', X.shape)
X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 数据增加高次项
estimator.fit(X3, y)
# 4.模型预测
y_predict = estimator.predict(X3)
# 5.模型评估,计算均方误差
# 5.1 模型评估MSE
myret = mean_squared_error(y, y_predict)
print('myret -->', myret)
# 5.2 展示效果
plt.scatter(x, y)
# 画图时输入的x数据: 要求是从小到大
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
dm02_overfitting()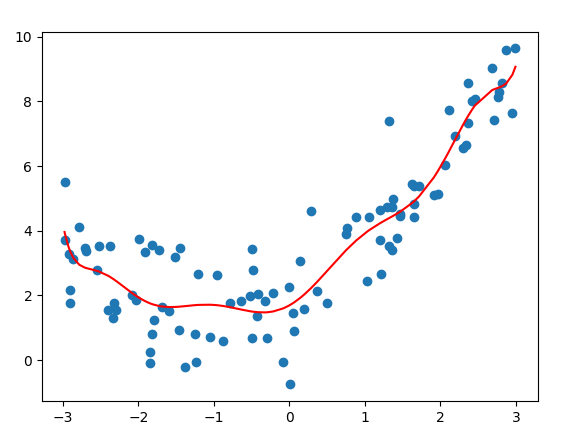
代码
python
def dm_fitting():
# 2.准备数据x y(增加上噪声)
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 3.模型训练
# 3.1实例化线性回归模型
estimator = LinearRegression()
# 3.2 模型训练
X = x.reshape(-1, 1)
# print('X.shape-->', X.shape)
X2 = np.hstack([X, X ** 2]) # 数据增加二次项
estimator.fit(X2, y)
# 4.模型预测
y_predict = estimator.predict(X2)
# 5.模型评估,计算均方误差
myret = mean_squared_error(y, y_predict)
print('myret -->', myret)
# 6 展示效果
plt.scatter(x, y)
# 画图plot折线图时 需要对x进行排序, 取x排序后对应的y值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
dm_fitting()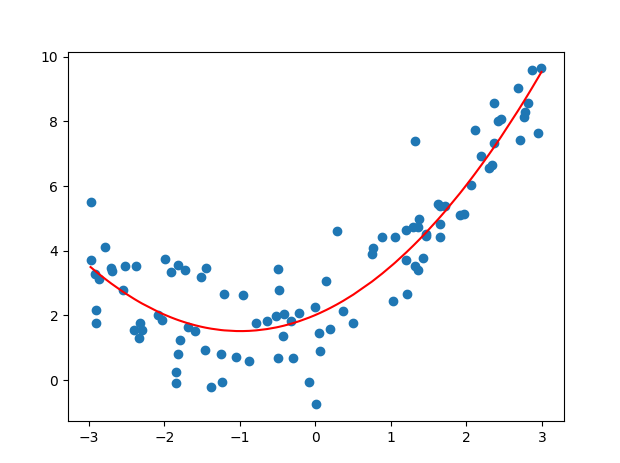
正则化
在模型训练时,数据中有些特征影响模型复杂度、或者某个特征的异常值较多,所以要尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化。
在损失函数中增加正则化项,分为L1正则化、L2正则化。
L1正则化
L1正则化,在损失函数中添加L1正则化项
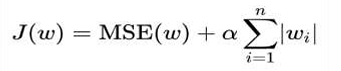
• α 叫做惩罚系数,该值越大则权重调整的幅度就越大,即:表示对特征权重惩罚力度就越大
• L1 正则化会使得权重趋向于 0,甚至等于 0,使得某些特征失效,达到特征筛选的目的
• 使用 L1 正则化的线性回归模型是 Lasso 回归
python
from sklearn.linear_model import LassoL1正则化代码
python
# 1.导入依赖包
from sklearn.linear_model import Lasso
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import mean_squared_error
def dm_l1():
# 2.准备数据x y(增加上噪声)
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 3 训练模型
# 3.1 实例化L1正则化模型 做实验:alpha惩罚力度越来越大,k值越来越小,返回会欠拟合
estimator = Lasso(alpha=0.005)
# 3.2 模型训练
X = x.reshape(-1, 1)
X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 数据增加二次项
estimator.fit(X3, y)
print('estimator.coef_', estimator.coef_)
# 4.模型预测
y_predict = estimator.predict(X3)
# 5.模型评估,计算均方误差
# 5.1 模型评估MSE
myret = mean_squared_error(y, y_predict)
print('myret -->', myret)
# 5.2 展示效果
plt.scatter(x, y)
# 画图时输入的x数据: 要求是从小到大
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
dm_l1()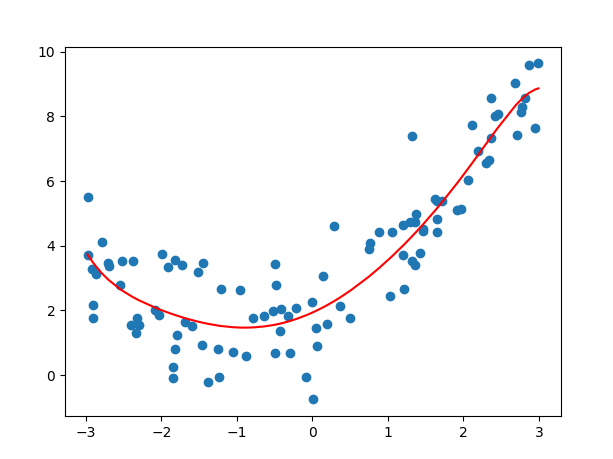
L2正则化
L2正则化,在损失函数中添加L2正则化项
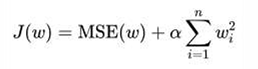
• α 叫做惩罚系数,该值越大则权重调整的幅度就越大,即:表示对特征权重惩罚力度就越大
• L2 正则化会使得权重趋向于 0,一般不等于 0
• 使用 L2 正则化的线性回归模型是岭回归
• 把高次项前面的系数变成特别小的值
python
from sklearn.linear_model import Ridge
L2正则化代码
python
from sklearn.linear_model import Ridge
def dm_l2():
# 2.准备数据x y(增加上噪声)
np.random.seed(666)
x = np.random.uniform(-3, 3, size=100)
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 3.训练模型
# 3.1 实例化L2正则化模型
# estimator = Ridge(alpha=0.005)
estimator = Ridge(alpha=1)
# 3.2 模型训练
X = x.reshape(-1, 1)
X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 数据增加二次项
estimator.fit(X3, y)
print('estimator.coef_', estimator.coef_)
# 4.模型预测
y_predict = estimator.predict(X3)
# 5.模型评估,计算均方误差
# 5.1 模型评估,MSE
myret = mean_squared_error(y, y_predict)
print('myret -->', myret)
# 5.2 展示效果
plt.scatter(x, y)
# 画图时输入的x数据: 要求是从小到大
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
dm_l2()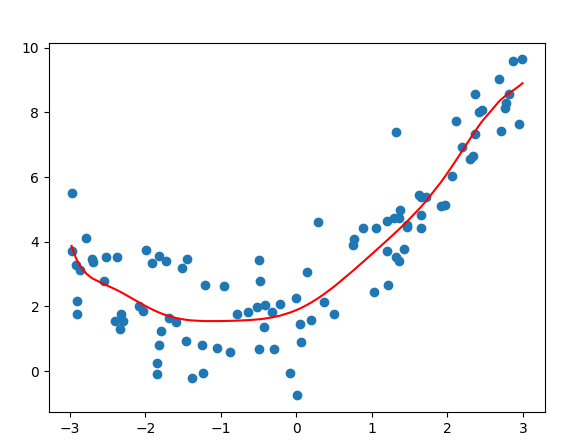
L1和L2区别
L1 和 L2 正则化是机器学习中最常用的两种正则化方式,它们的主要区别可以从以下几个维度对比(表格最直观):
| 维度 | L1 正则化 (Lasso) | L2 正则化 (Ridge) | 谁更常用 / 典型场景 |
|---|---|---|---|
| 正则项公式 | λ × Σ |wᵢ| | λ × Σ wᵢ² | --- |
| 梯度更正项 | λ × sign(wᵢ)(固定大小 λ,方向由符号决定) | 2λ × wᵢ(与当前权重成正比) | --- |
| 对权重的效果 | 很多权重直接变为 0(产生稀疏解) | 权重整体变小,但几乎不会为 0 | L1 强于特征选择,L2 更平滑 |
| 特征选择能力 | 强(自动把不重要特征权重置为 0) | 弱(所有特征都会保留,只是权重缩小) | L1 适合高维、冗余特征多的场景 |
| 几何约束形状 | 菱形(L1 范数) | 圆形(L2 范数) | 菱形更容易碰到坐标轴 → 产生稀疏解 |
| 对异常值/噪声敏感度 | 相对鲁棒(因为能直接忽略无用特征) | 更敏感(所有特征都会被缩放) | L1 更鲁棒 |
| 解的唯一性 | 可能不唯一(菱形拐角处有多个解) | 通常唯一(圆形光滑) | L2 更稳定 |
| 计算复杂度 | 不可导(需要 subgradient 或近似方法,如坐标下降) | 可导(直接梯度下降) | L2 优化更简单 |
| sklearn 实现 | Lasso(alpha=...) | Ridge(alpha=...) | --- |
| 最典型应用场景 | 特征选择、高维稀疏数据、需要解释性强的模型 | 防止过拟合、多重共线性、权重平滑 | 竞赛/高维数据 → L1 常规防过拟合 → L2 |
一句话总结区别
- L1 :让很多权重直接变成 0 → 自动特征选择 + 稀疏模型
- L2 :让所有权重整体变小 → 权重平滑 + 防过拟合,但不会自动去掉特征
实际选择建议(最务实版)
| 你的目标是什么 | 优先选哪个 | 为什么 |
|---|---|---|
| 想自动做特征选择、降维 | L1 (Lasso) | 直接把不重要特征权重清零 |
| 数据有严重多重共线性 | L2 (Ridge) | L2 对共线性更鲁棒 |
| 模型解释性很重要 | L1 | 稀疏模型更容易看懂哪些特征重要 |
| 单纯想防过拟合、权重别太大 | L2 | 更稳定、优化更容易 |
| 两者都想试试 | ElasticNet | L1 和 L2 的混合(sklearn 有 ElasticNet) |