LLMs之MoE之Thinking:LongCat-Flash-Thinking-2601的简介、安装和使用方法、案例应用之详细攻略
目录
LongCat-Flash-Thinking-2601的简介
LongCat-Flash-Thinking-2601的案例应用
LongCat-Flash-Thinking-2601的简介
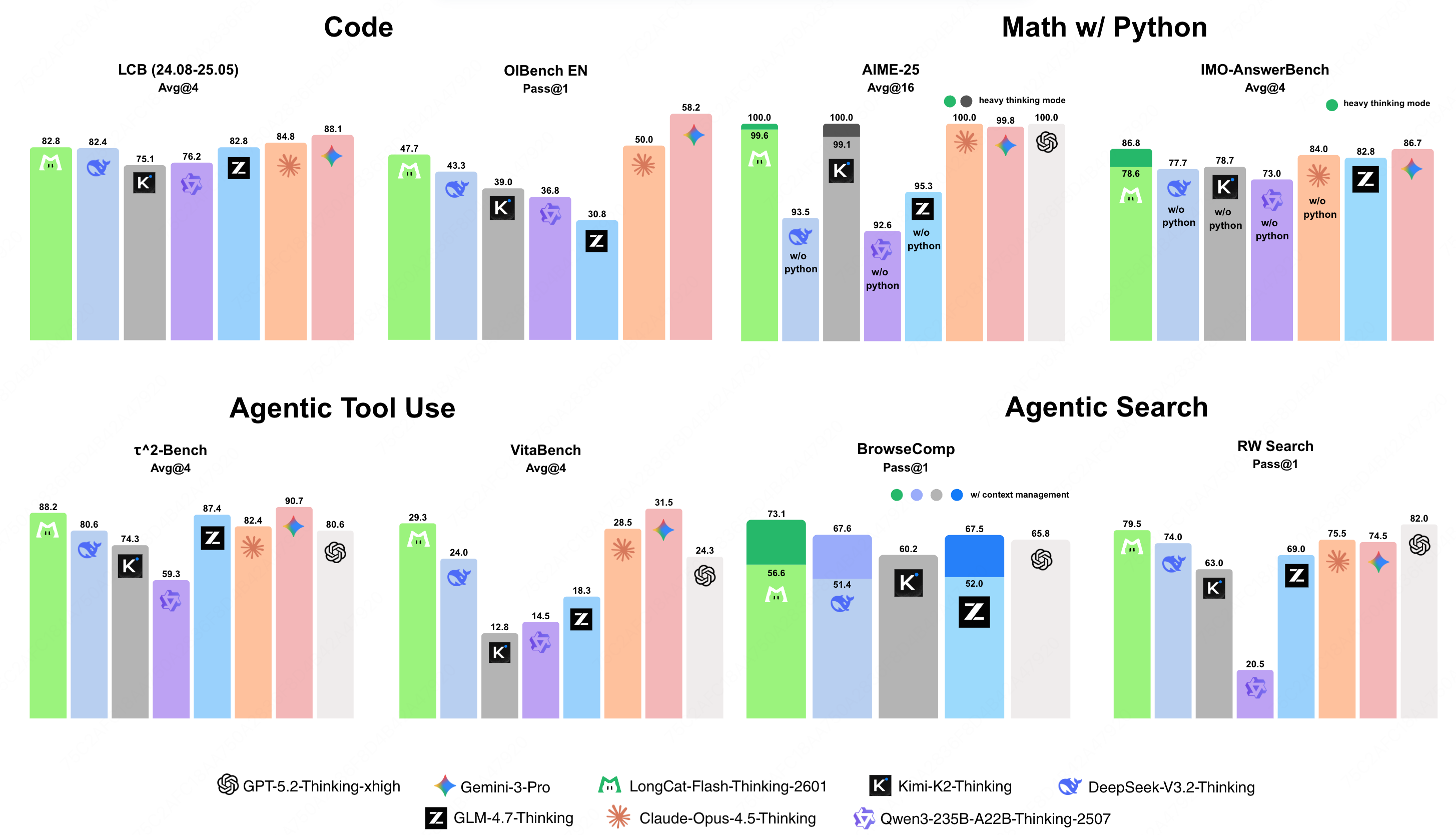
LongCat-Flash-Thinking-2601 是美团发布的 LongCat-Flash-Thinking 系列的更新版本。它是一款功能强大且高效的大型推理模型(Large Reasoning Model, LRM),基于创新的专家混合(Mixture-of-Experts, MoE)架构构建。
该模型的总参数量达到 5600 亿,激活参数量为 270 亿。它不仅继承了先前版本的领域并行训练方法,在传统推理基准上保持了极高的竞争力,还通过一个精心设计的流程系统性地增强了其"智能体思维"(agentic thinking)能力。该流程结合了环境扩展(environment scaling)、后续任务合成(task synthesis),以及可靠高效的大规模多环境强化学习。
为了更好地适应现实世界智能体任务中固有的噪声和不确定性,模型在多种类型和级别的环境噪声下进行了系统的分析和课程学习(curriculum training),使其在非理想条件下也能表现出强大的性能。因此,LongCat-Flash-Thinking-2601 不仅在智能体工具使用、智能体搜索和工具集成推理等基准测试中取得了顶级性能,还在任意的分布外(out-of-distribution)真实世界智能体场景中展现了显著提升的泛化能力。
此外,该模型还引入了"重思考模式"(Heavy Thinking Mode),通过密集的并行思考,进一步增强了模型在应对极端挑战性任务时的表现。
Huggingface地址 :https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601
1、特点
LongCat-Flash-Thinking-2601 的核心优势体现在以下几个方面:
|----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 环境扩展与多环境强化学习 | - **高质量环境构建**:模型构建了一系列多样化的高质量环境作为强化学习的"训练场"。每个环境包含超过60个工具,这些工具组织在一个密集的依赖关系图中,为构建复杂任务和大规模探索提供了充足的复杂度。研究发现,随着训练环境数量的增加,模型在领域外评估中的表现持续提升,表明其泛化能力得到加强。 - **高质量任务构建**:为了保证训练任务的质量,模型明确地控制了任务的复杂性和多样性。每个任务都在从高质量环境中采样出的连通子图上定义,并通过要求在子图内协调使用尽可能多的工具来控制任务复杂度。为了促进任务多样性,先前已选择工具的采样概率会逐渐降低。 - **多环境强化学习**:模型扩展了其强化学习基础设施(DORA),以支持大规模的多环境智能体训练。来自多个环境的任务以平衡的方式被共同组织在每个训练批次中,并根据任务的复杂度和当前训练状态分配不同的推演预算(rollout budgets)。 |
| 针对噪声环境的稳健性训练 | - **模拟真实世界**:认识到现实世界的智能体环境本质上是充满噪声和不完美的,模型在训练过程中明确地引入了环境缺陷以增强其稳健性。 - **系统性噪声注入**:团队系统性地分析了智能体场景中现实世界噪声的主要来源,并设计了一个自动化流程,将这些噪声注入到训练环境中。 - **课程学习策略**:在强化学习期间,模型采用了一种课程学习策略,随着训练的进行,逐步增加噪声的类型和强度。得益于这种稳健性训练,模型对环境的不确定性表现出强大的韧性,并在非理想条件下持续获得性能提升。 |
| 重思考模式 | - **目标**:旨在将模型的推理能力推向新的边界。 - **两阶段过程**:将挑战性问题的解决分解为两个互补的阶段:并行思考(parallel thinking)和总结(summarization),从而同时扩展推理的深度和广度。 - **推理广度扩展**:在"重思考模式"下,模型以并行方式独立生成多个推理轨迹,从而对推理路径进行广泛探索。通过应用合理较高的推理温度(inference temperature)来确保路径的多样性。 - **推理深度扩展**:在总结阶段提炼出的轨迹可以被递归地反馈给总结模型,形成一个支持逐步深化推理的迭代循环。 - **专项训练**:通过一个额外的、专门为训练总结能力而定制的强化学习阶段,进一步释放了此模式的潜力。您可以在龙猫AI平台(`https://longcat.chat/\`)上体验此模式。 |
LongCat-Flash-Thinking-2601的安装和使用方法
1、安装
模型下载地址:https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601/tree/main
2、使用方法
模型本身无需特殊安装,可以通过标准的 `transformers` 库进行加载和使用。核心步骤是使用 `AutoTokenizer` 和 `AutoModelForCausalLM` 从 Hugging Face Hub 加载模型和分词器。
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meituan-longcat/LongCat-Flash-Thinking-2601"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
# model = AutoModelForCausalLM.from_pretrained(model_name) # 加载模型的标准方式聊天模板概览
模型的使用核心在于其独特的聊天模板(Chat Template),通过 `apply_chat_template` 方法应用。
为了支持高级工具使用场景和复杂的推理模式,聊天模板进行了重要更新。
基本用法
python
text = tokenizer.apply_chat_template(
messages,
tools=tools,
tokenize=False,
enable_thinking=True, # 启用思考模式
add_generation_prompt=True,
save_history_reasoning_content=False # 默认不保存历史思考内容
)- **模板关键特性**:
-
**工具声明 (Tool Declaration)**: 在会话开始时声明可用工具,以激活模型的工具使用能力并定义可用动作的范围。
-
**交错式思考 (Interleaved Thinking)**: 默认模式。在此模式下,最终的回答会被保留,而先前用户交互中的思考内容会被丢弃,以维持一个简洁的上下文窗口。工具调用和响应会被保留以提供必要的执行历史。
-
**推理保留 (Reasoning Retention)**: 如果需要跨轮次保留模型的思考内容,可以将 `save_history_reasoning_content` 设置为 `True`。
部署
模型已在 SGLang 和 vLLM 中实现了基本适配,以支持部署。详细的部署说明请参考项目文件中的 `Deployment Guide`。
在线体验
您可以在官方网站 `https://longcat.ai` 上与 LongCat-Flash-Thinking-2601 进行聊天。请注意,在提交请求前,需要开启"Think"(中文为"深度思考")按钮。
3、代码示例
以下是使用 `apply_chat_template` 方法处理不同场景的两个具体代码示例。
多轮对话 (Multi-Turn Dialogue)
此示例演示了模板如何处理对话历史和思考内容。
python
from transformers import AutoTokenizer #, AutoModelForCausalLM
model_name = "meituan-longcat/LongCat-Flash-Thinking-2601"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# model = AutoModelForCausalLM.from_pretrained(model_name) # 假设模型已加载
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please tell me what is $$1 + 1$$ and $$2 \\times 2$$?"
},
{
"role": "assistant",
"reasoning_content": "This question is straightforward: $$1 + 1 = 2$$ and $$2 \\times 2 = 4$$.",
"content": "The answers are 2 and 4."
},
{
"role": "user",
"content": "Check again?"
}
]
# 应用聊天模板,不保存历史思考内容以节省token
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
enable_thinking=True,
add_generation_prompt=True,
save_history_reasoning_content=False
)
# 打印生成的模板化文本结构
# 预期结构: <longcat_system>You are a helpful assistant.<longcat_user>Please tell me what is $$1 + 1$$ and $$2 \times 2$$?<longcat_assistant>The answers are 2 and 4</longcat_s><longcat_user>Check again? /think_on <longcat_assistant><longcat_think>\n
print(text)
# # --- 模型生成部分 ---
# model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# generated_ids = model.generate(
# **model_inputs,
# max_new_tokens=32768
# )
# output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# response = tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
# print(response)
# 示例输出:
# The user wants a double-check. Since $$1 + 1 = 2$$ and $$2 \times 2 = 4$$ are basic arithmetic truths, the previous answer is correct.\n</longcat_think>\nI have verified the calculations: $$1 + 1 = 2$$ and $$2 \times 2 = 4$$. The initial answer remains correct.</longcat_s>**说明**: 在这个例子中,由于 `save_history_reasoning_content` 为 `False`,第一轮助手的 `reasoning_content`("This question is straightforward...")在构建第二轮输入的提示时被丢弃,只保留了最终回答 `content`("The answers are 2 and 4.")。模型在生成新一轮回答时,会先生成新的思考过程(`<longcat_think>...</longcat_think>`),然后再给出最终答案。
工具调用 (Tool Calling)
此示例展示了如何在推理框架内集成函数调用。
python
# from transformers import AutoTokenizer, AutoModelForCausalLM
# model_name = "meituan-longcat/LongCat-Flash-Thinking-2601"
# tokenizer = AutoTokenizer.from_pretrained(model_name)
# model = AutoModelForCausalLM.from_pretrained(model_name) # 假设模型已加载
tools = [
{
"type": "function",
"function": {
"name": "func_add",
"description": "Calculate the sum of two numbers",
"parameters": {
"type": "object",
"properties": {
"x1": {"type": "number", "description": "The first addend"},
"x2": {"type": "number", "description": "The second addend"}
},
"required": ["x1", "x2"]
}
}
}
]
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please tell me what is $$125679 + 234519$$?"
},
{
"role": "assistant",
"reasoning_content": "This calculation requires precision; I will use the func_add tool.",
"tool_calls": [{
"type": "function",
"function": {
"name": "func_add",
"arguments": {"x1": 125679, "x2": 234519}
}
}]
},
{
"role": "tool",
"name": "func_add",
"content": '{"ans": 360198}'
}
]
text = tokenizer.apply_chat_template(
messages,
tools=tools,
tokenize=False,
enable_thinking=True,
add_generation_prompt=True,
save_history_reasoning_content=False
)
# # --- 模型生成部分 ---
# model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# # 根据工具结果生成响应
# generated_ids = model.generate(
# **model_inputs,
# max_new_tokens=32768
# )
# output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# response = tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
# print(response)**说明**: 在这个例子中,`messages` 列表包含了完整的工具调用流程:
-
用户提出需要计算的问题。
-
助手(`assistant`)角色决定使用工具,并在 `tool_calls` 中指定了要调用的函数 `func_add` 及其参数。
-
工具(`tool`)角色返回了函数执行的结果。
-
接下来,模型将基于这个工具返回的结果(`{"ans": 360198}`)生成最终的人类可读的回答。
LongCat-Flash-Thinking-2601的案例应用
更新中......