目录
[互斥锁(Mutex Lock)](#互斥锁(Mutex Lock))
概述
在使用Redis作为缓存层的系统中,我们经常会遇到三个经典问题:缓存穿透 、缓存击穿和缓存雪崩。这三个问题虽然名字相似,但产生的原因和影响却各不相同。
本文将通过通俗易懂的方式,带你深入理解这三个问题及其解决方案,其中还会详细说明解决缓存穿透的方案"布隆过滤器"。
缓存穿透
介绍
缓存穿透是指查询一个根本不存在 的数据,无论是缓存还是数据库中都没有这条数据。
想象一下这个场景:你开了一家奶茶店(数据库),为了提高效率,你雇了一个记忆力超强的店员(缓存)来记住常点的订单。现在有个恶意顾客不断询问"有没有榴莲味的珍珠奶茶"(你店里根本不卖这个)。每次店员都要跑到后厨确认一遍,虽然每次答案都是"没有",但店员和后厨都被频繁打扰,效率大打折扣。
产生原因
**1.恶意攻击:**攻击者故意查询不存在的数据
**2.业务逻辑漏洞:**代码bug导致查询了错误的key
**3.数据被删除:**数据在数据库中被删除,但请求还在持续
危害
**1.**缓存完全失效,所有请求都打到数据库
2.数据库压力骤增,可能导致数据库宕机
**3.**系统响应时间增加,用户体验变差
解决方案
缓存穿透造成伤害通常是由于"恶意攻击 "导致,网络上常见的解决方案"Redis缓存空数据 "会造成极大内存无端消耗且效果不好,因此需要采用"请求限流/行为检查 + 参数校验 + 布隆过滤器"的组合拳来预防。
Redis缓存空数据的弊端
如果是恶意攻击,攻击者通常会选择"合理但不存在的key"进行请求,如果每一次都将空结果放到Redis的Set中,即使设置了短TTL还是会造成比较大的内存消耗。
请求限流/行为检查对于"恶意攻击"最有效的方案既是请求限流和行为检测,将攻击扼杀在摇篮中。
布隆过滤器作用是在缓存前加一层布隆过滤器,将所有可能存在的Key哈希到一个足够大的bitmap中。查询时先通过布隆过滤器判断数据是否存在。
布隆过滤器
**位置:**在缓存之前
**作用:**提前检查请求的key是否存在于Redis中,如果存在再去查询缓存/DB。

原理: 布隆过滤器是一个由位(Bit)组成的数组。它通过多个哈希函数将数据映射到位数组中。
通俗来说: 布隆过滤器中维护了一个数组,数组存储的元素值是0或1(位图),当一个请求key来的时候,比如id=101,拿到id进行哈希计算并取模数组长度(内层算法),会得到数组中对应的一个索引,将该索引位置标记为1。下次使用同样的方式计算如果发现数组元素为1则判定为存在。
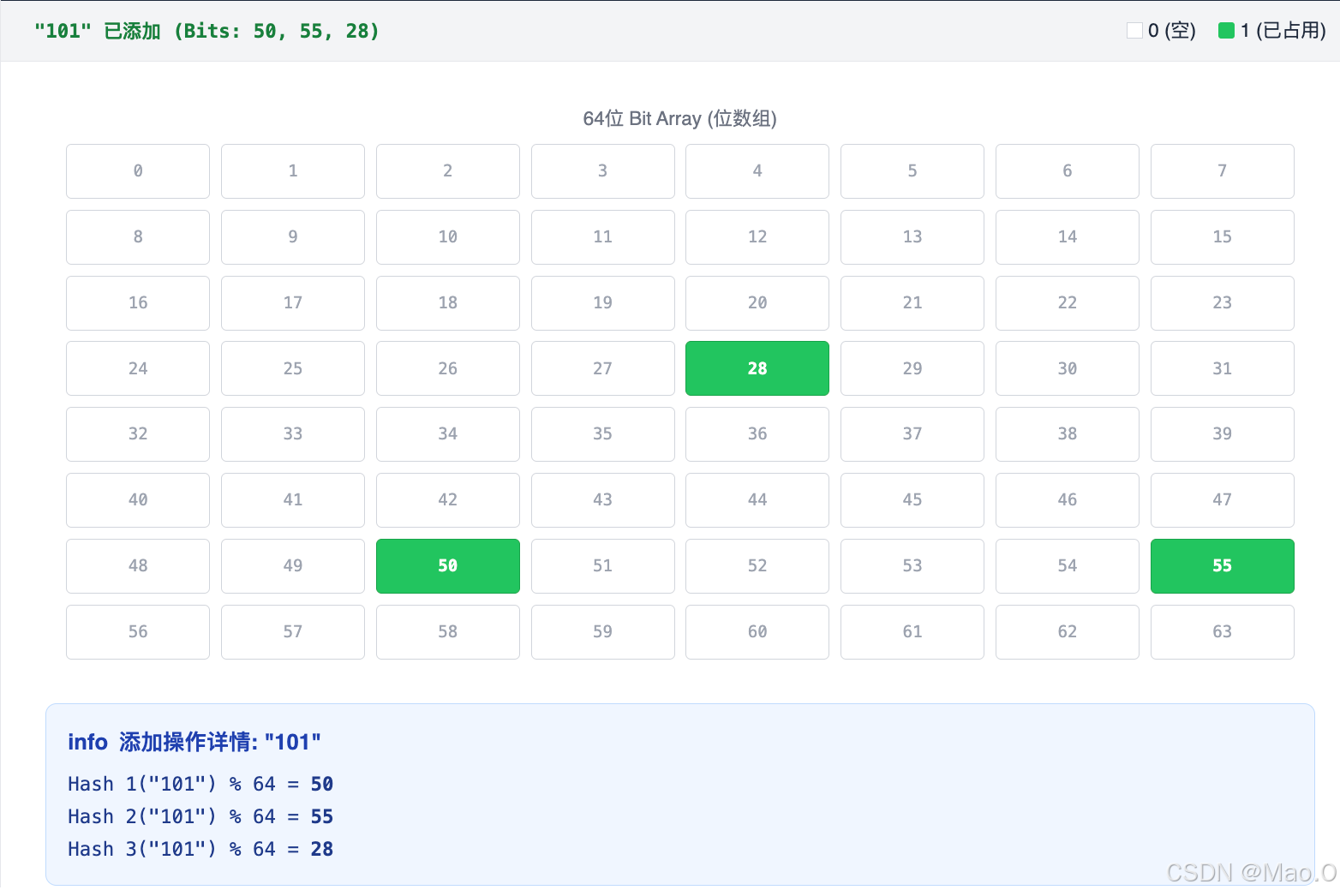
其中关键的部分:
**1.哈希函数 (Hash):**使用 n 个不同的哈希函数将输入映射到数组的 n 个不同位置。演示中使用 3 个简单的取模哈希函数。
2.查询机制:如果 n 个位置的位全为 1 ,则数据可能存在 。如果任意一位为 0 ,则数据一定不存在。
**3.误判率 (False Positive):**计算机制可能会出现"误报"(说存在但实际不存在),因为位可能被其他数据置为 1。但绝不会出现"漏报"。
布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%。其实这个误判是必然存在的,要不就得增加数组的长度。5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
java
public User getUserById(String userId) {
// 1. 先检查布隆过滤器
if (!bloomFilter.mightContain(userId)) {
// 一定不存在,直接返回
return null;
}
// 2. 可能存在,查缓存
User user = redis.get(userId);
if (user != null) {
return user;
}
// 3. 查数据库
user = database.get(userId);
if (user != null) {
redis.setex(userId, 3600, user);
}
return user;
}总结:
布隆过滤器在缓存穿透场景中主要承担两个职责:
**1.**是以极低内存成本维护一个"可能存在的 key 集合";
**2.**是作为前置过滤器,在请求进入缓存和数据库之前,快速识别"一定不存在"的 key,从而避免无意义的查询。
在工程实践中,当 Bloom 判断 key 不存在时,并不会一刀切返回,而是结合参数合法性、请求频率和业务合理性进行判断:对明显不合理的请求直接拦截,对少量合理的边界请求进行数据库兜底校验,若数据存在则回写缓存并增量更新 Bloom,从而在保证正确性的同时有效防止缓存穿透。
缓存击穿
介绍
缓存击穿是指一个热点key在缓存中过期的瞬间,有大量并发请求同时访问这个key,导致所有请求都打到数据库。
继续用奶茶店的例子:店里有一款爆款奶茶"霸气芝士莓莓",店员1(缓存)记住了这个配方。但当店员1去上厕所,店员2帮忙接待,店员2不记得这个配方(缓存过期),而此时恰好有100个顾客同时点这款奶茶。于是店员不得不同时跑到后厨问100次同样的问题,后厨(DB)瞬间崩溃。
有人说这种情况很难发生,他说"一个热点key怎么可能设置过期时间呢?"
其实这种情况我想可能会发生在:那就是设置了过期时间的冷门key如果爆火,一个冷门的key如果爆火,例如一个冷门商品突然火爆。这种情况在现实生活中我想并不少见。
产生原因
**1.**热点数据的缓存key过期
**2.**大量并发请求同时到达
**3.**没有对数据库访问进行保护
危害
**1.**瞬间大量请求穿透到数据库
**2.**数据库连接数暴增,可能导致数据库崩溃
**3.**影响系统整体性能
解决方案
互斥锁(Mutex Lock)
当缓存失效时,我们设置互斥锁仅允许一个线程去重建缓存,其他线程阻塞等待,缓存重建完毕后再放行。
这种方案的优点是能解决问题且一致性强,但是会降低系统吞吐量;如果数据库查询很慢,会导致大量请求等待
java
public User getUserById(String userId) {
String key = "user:" + userId;
// 1. 查缓存
User user = redis.get(key);
if (user != null) {
return user;
}
// 2. 缓存未命中,尝试获取锁
String lockKey = "lock:" + key;
String lockValue = UUID.randomUUID().toString();
try {
// 使用SETNX实现分布式锁,设置过期时间防止死锁
boolean locked = redis.setNX(lockKey, lockValue, 10, TimeUnit.SECONDS);
if (locked) {
// 3. 获取锁成功,查询数据库
user = database.get(userId);
if (user != null) {
// 4. 写入缓存
redis.setex(key, 3600, user);
}
return user;
} else {
// 5. 获取锁失败,等待一段时间后重试
Thread.sleep(50);
return getUserById(userId); // 递归重试
}
} finally {
// 6. 释放锁(需要验证lockValue防止误删)
String currentValue = redis.get(lockKey);
if (lockValue.equals(currentValue)) {
redis.del(lockKey);
}
}
}逻辑过期
在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间。
当查询的时候,从redis取出数据后判断时间是否过期。
如果过期,则用互斥锁开通另外一个线程进行缓存重建,当前线程直接正常返回数据,这个数据可能不是最新的,其他线程获取不到互斥锁直接返回缓存中的旧数据。
java
public User getUserById(String userId) {
String key = "user:" + userId;
// 1. 查缓存(缓存永不过期)
CacheObject cacheObj = redis.get(key);
// 2. 缓存未命中(首次查询需要加锁处理,此处省略)
if (cacheObj == null) {
// ... 首次加载逻辑
return loadAndCache(userId);
}
// 3. 检查是否逻辑过期
if (System.currentTimeMillis() > cacheObj.getExpireTime()) {
// 4. 尝试获取锁(非阻塞)
String lockKey = "lock:rebuild:" + key;
boolean locked = redis.setNX(lockKey, "1", 10, TimeUnit.SECONDS);
if (locked) {
// 5. 获取锁成功,提交异步任务重建缓存
threadPool.execute(() -> {
try {
User user = database.get(userId);
CacheObject newObj = new CacheObject();
newObj.setData(user);
newObj.setExpireTime(System.currentTimeMillis() + 3600000);
redis.set(key, newObj); // 不设置Redis过期时间
} finally {
redis.del(lockKey);
}
});
}
// 6. 无论是否获取到锁,都直接返回旧数据(不等待)
}
// 7. 返回数据(即使逻辑过期也返回,保证高可用)
return cacheObj.getData();
}缓存雪崩
介绍
缓存雪崩是指在某一个时间段内,大量的缓存key同时失效,或者Redis服务宕机,导致大量请求直接打到数据库。
还是奶茶店的例子:你的店员(缓存)每天晚上12点准时下班(缓存集中过期)。如果恰好这个时候来了很多顾客,所有订单都要直接找后厨,后厨瞬间被压垮。更糟糕的情况是,店员突然生病了(Redis宕机),整天所有订单都要直接找后厨。
产生原因
1.缓存集中过期:大量key使用相同的过期时间
2.Redis服务宕机:硬件故障、网络问题等
3.流量激增:促销活动、热点事件等导致流量突增
危害
**1.**数据库瞬间承受巨大压力
**2.**可能引发数据库连接池耗尽
**3.**系统整体崩溃,产生级联故障
解决方案
过期时间随机化
该解决方案主要针对"大量key同时过期"的情况。
给缓存的过期时间添加随机值,避免大量key同时过期。
java
public void setCache(String key, User user) {
// 基础过期时间:1小时
int baseExpire = 3600;
// 添加随机值:0-300秒(5分钟内)
int randomExpire = new Random().nextInt(300);
// 最终过期时间:3600-3900秒
int finalExpire = baseExpire + randomExpire;
redis.setex(key, finalExpire, user);
}这种方案实现简单,有效避免集中过期,但只能缓解问题,无法完全解决。
对于Redis服务宕机的问题,就要提前考虑搭建Redis集群保证高可用了。
三大问题对比总结
|------|-------------------|----------|------------------|
| 问题类型 | 根本原因 | 影响范围 | 核心解决思路 |
| 缓存穿透 | 查询不存在的数据 | 单个或少量key | 防止无效查询(布隆过滤器) |
| 缓存击穿 | 热点key过期 | 单个热点key | 防止并发冲击(互斥锁、永不过期) |
| 缓存雪崩 | 大量key同时失效或Redis宕机 | 大量key | 分散过期时间、高可用架构 |
缓存穿透、缓存击穿和缓存雪崩是使用Redis缓存时必须要面对的三大经典问题。理解它们的本质区别,并根据实际业务场景选择合适的解决方案,是构建高可用、高性能系统的关键。
在实际应用中,我们往往需要组合多种方案,形成立体化的防护体系,才能真正保障系统的稳定性和可用性。