文章目录
-
- [一、SQL 解析顺序:为什么不是按书写顺序执行](#一、SQL 解析顺序:为什么不是按书写顺序执行)
- [二、FROM 子句:确定数据源和表连接](#二、FROM 子句:确定数据源和表连接)
- [三、WHERE 子句:过滤行数据](#三、WHERE 子句:过滤行数据)
- [四、GROUP BY 子句:数据分组](#四、GROUP BY 子句:数据分组)
- [五、HAVING 子句:过滤分组](#五、HAVING 子句:过滤分组)
- [六、SELECT 子句:处理表达式和去重](#六、SELECT 子句:处理表达式和去重)
- [七、ORDER BY 子句:最终排序](#七、ORDER BY 子句:最终排序)
- 八、完整示例:理解整个执行流程
SQL 语句的执行顺序与书写顺序不同,理解解析顺序有助于编写高效的查询、排查问题,以及理解为什么某些写法会报错或性能差。SQL 解析按照 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY 的顺序进行,每个步骤都会生成一个虚拟表。
核心要点:
- FROM 子句最先执行,包括表的连接和 ON 过滤
- WHERE 在 GROUP BY 之前执行,用于过滤行
- HAVING 在 GROUP BY 之后执行,用于过滤分组
- SELECT 在大部分子句之后执行,处理表达式和去重
- ORDER BY 最后执行,对最终结果排序
一、SQL 解析顺序:为什么不是按书写顺序执行
SQL 语句按照以下顺序解析和执行:
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY为什么是这个顺序:
- FROM 最先:需要先确定数据源,才能进行后续操作
- **WHERE :先过滤行,再分组,效率更高
- HAVING :只能对分组后的结果进行过滤
- SELECT 靠后:大部分操作完成后,再处理表达式和去重
- ORDER BY 最后:对最终结果进行排序
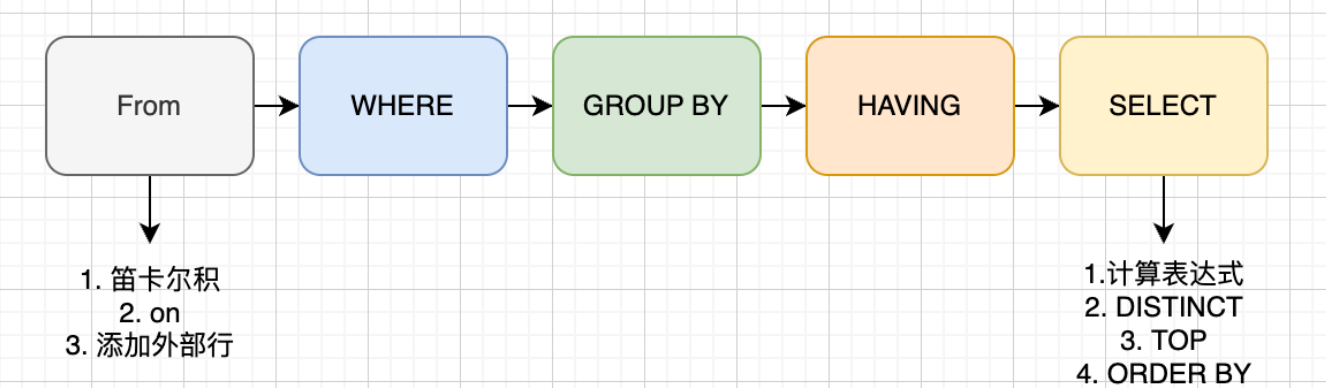
二、FROM 子句:确定数据源和表连接
FROM 子句最先执行,确定查询的数据源,包括表的连接操作。
FROM 的执行步骤
1. 确定数据源
- FROM 后面的表标识了查询的数据源
- 生成虚拟表 VT1
2. 表的连接(如果有多表)
(1-J1)笛卡尔积
- 计算两个相关联表的笛卡尔积(CROSS JOIN)
- 生成虚拟表 VT1-J1
- 如果没有 JOIN 条件,会产生所有可能的组合
(1-J2)ON 过滤
- 基于虚拟表 VT1-J1 进行过滤
- 过滤出所有满足 ON 谓词条件的行
- 生成虚拟表 VT1-J2
- 注意:ON 条件只影响连接,不影响最终结果的行数(外连接除外)
(1-J3)添加外部行
- 如果使用了外连接(LEFT/RIGHT/FULL JOIN)
- 保留表中不符合 ON 条件的行也会被加入
- 作为外部行,生成虚拟表 VT1-J3
sql
-- 假设有两个表:users (id, name) 和 orders (id, user_id, amount)
SELECT u.name, o.amount
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE o.amount > 100;执行过程:FROM users 生成 VT1(users 表的所有行),LEFT JOIN orders 计算笛卡尔积生成 VT1-J1,ON u.id = o.user_id 过滤连接条件生成 VT1-J2,添加外部行保留 users 中没有匹配的行生成 VT1-J3,WHERE o.amount > 100 过滤最终结果。
三、WHERE 子句:过滤行数据
WHERE 子句在 FROM 之后执行,对虚拟表 VT1 进行过滤,满足条件的行被插入到 VT2。
WHERE 的作用
- 过滤行:基于行的条件进行过滤
- 在分组之前:先过滤行,再分组,减少需要处理的数据量
- 不能使用聚合函数:因为此时还没有分组
sql
SELECT department, AVG(salary)
FROM employees
WHERE salary > 5000 -- WHERE 先执行,过滤掉 salary <= 5000 的行
GROUP BY department;执行过程:FROM employees 生成 VT1(所有员工),WHERE salary > 5000 过滤生成 VT2(只包含 salary > 5000 的员工),GROUP BY department 对 VT2 分组生成 VT3。
为什么 WHERE 在 GROUP BY 之前:先过滤行,减少数据量;如果先分组再过滤,需要处理更多数据,效率低。
四、GROUP BY 子句:数据分组
GROUP BY 子句对 WHERE 过滤后的表进行分组,生成分组后的虚拟表 VT3。
GROUP BY 的作用
- 分组:按照指定的列对数据进行分组
- 生成分组:每个不同的组合生成一个组
- 为聚合函数准备:分组后可以使用聚合函数(COUNT、SUM、AVG 等)
sql
SELECT department, COUNT(*) as emp_count, AVG(salary) as avg_salary
FROM employees
WHERE salary > 5000
GROUP BY department;执行过程:FROM employees 生成 VT1,WHERE salary > 5000 生成 VT2,GROUP BY department 生成 VT3(按部门分组,每个部门一个组,每个组包含该部门的所有员工)。
五、HAVING 子句:过滤分组
HAVING 子句在 GROUP BY 之后执行,对分组后的结果进行过滤,满足条件的分组被加入到 VT4。
HAVING 与 WHERE 的区别
| 特性 | WHERE | HAVING |
|---|---|---|
| 执行时机 | GROUP BY 之前 | GROUP BY 之后 |
| 作用对象 | 行 | 分组 |
| 可以使用聚合函数 | 否 | 是 |
| 效率 | 更高(先过滤行) | 较低(后过滤分组) |
sql
SELECT department, AVG(salary) as avg_salary
FROM employees
WHERE salary > 5000 -- 先过滤行
GROUP BY department
HAVING AVG(salary) > 8000; -- 再过滤分组(平均工资 > 8000 的部门)执行过程:FROM → WHERE → GROUP BY 生成 VT3(分组后的结果),HAVING AVG(salary) > 8000 生成 VT4(只保留平均工资 > 8000 的部门)。
为什么需要 HAVING:WHERE 不能使用聚合函数,需要在分组后过滤分组结果。
六、SELECT 子句:处理表达式和去重
SELECT 子句在大部分操作之后执行,处理表达式、去重和限制结果数量。
SELECT 的执行步骤
(5-1)计算表达式
- 计算 SELECT 子句中的表达式
- 包括列名、函数、计算等
- 生成虚拟表 VT5-1
(5-2)DISTINCT
- 寻找 VT5-1 中的重复行
- 删除重复行
- 生成虚拟表 VT5-2
(5-3)TOP/LIMIT
- 从结果中筛选出符合条件的行数
- 生成虚拟表 VT5-3
sql
SELECT DISTINCT department, COUNT(*) as emp_count
FROM employees
WHERE salary > 5000
GROUP BY department
HAVING COUNT(*) > 10;执行过程:FROM → WHERE → GROUP BY → HAVING 生成 VT4,SELECT 计算表达式生成 VT5-1(计算 COUNT(*)),DISTINCT 去重生成 VT5-2(如果有重复),TOP/LIMIT 限制数量生成 VT5-3。
为什么 SELECT 靠后执行:需要先完成过滤、分组等操作,再处理表达式和去重,这就是为什么 WHERE 中不能使用 SELECT 中的别名。
七、ORDER BY 子句:最终排序
ORDER BY 子句最后执行,对最终结果进行排序,生成最终结果表 VC6。
ORDER BY 的特点
- 最后执行:在所有其他操作完成后执行
- 可以使用别名:可以使用 SELECT 中定义的别名
- 影响性能:排序操作通常比较耗时
- 可选:不是必需的子句
sql
SELECT department, AVG(salary) as avg_salary
FROM employees
WHERE salary > 5000
GROUP BY department
HAVING AVG(salary) > 8000
ORDER BY avg_salary DESC; -- 可以使用 SELECT 中的别名执行过程:FROM → WHERE → GROUP BY → HAVING → SELECT 生成 VT5-3,ORDER BY avg_salary DESC 生成 VC6(最终结果,按平均工资降序排列)。
为什么 ORDER BY 可以使用别名:因为 ORDER BY 在 SELECT 之后执行,SELECT 中定义的别名已经可用。
八、完整示例:理解整个执行流程
sql
SELECT department, COUNT(*) as emp_count, AVG(salary) as avg_salary
FROM employees
WHERE salary > 5000
GROUP BY department
HAVING COUNT(*) > 10
ORDER BY avg_salary DESC
LIMIT 5;执行步骤详解
FROM:从 employees 表读取所有数据,生成虚拟表 VT1。
WHERE:过滤 salary > 5000 的行,生成虚拟表 VT2(只包含工资 > 5000 的员工)。
GROUP BY:按 department 分组,生成虚拟表 VT3(每个部门一个组)。
HAVING:过滤 COUNT(*) > 10 的分组,生成虚拟表 VT4(只保留员工数 > 10 的部门)。
SELECT:计算表达式 COUNT(*) 和 AVG(salary),生成 VT5-1;如果有 DISTINCT 则去重生成 VT5-2;LIMIT 5 限制数量生成 VT5-3。
ORDER BY:按 avg_salary DESC 排序,生成最终结果表 VC6。
关键理解点
- WHERE 中不能使用别名:因为 WHERE 在 SELECT 之前执行
- HAVING 可以使用聚合函数:因为 HAVING 在 GROUP BY 之后执行
- ORDER BY 可以使用别名:因为 ORDER BY 在 SELECT 之后执行
- 先过滤再分组:WHERE 在 GROUP BY 之前,效率更高
参考资源: