文章目录
-
- 零:核心概念链条
- [一、从 SQL 语法到关系代数:为什么需要数学抽象](#一、从 SQL 语法到关系代数:为什么需要数学抽象)
- 二、RelNode:关系表达式的树形表示
- [三、RelNode 与 RexNode:关系级与行级的分离](#三、RelNode 与 RexNode:关系级与行级的分离)
- 四、Convention:不同执行引擎的统一抽象
- 五、RelOptRule:基于规则的优化机制
- 六、优化器:启发式与基于成本的两种策略
- 七、Adapter:连接不同数据源的桥梁
- 八、从逻辑计划到物理计划:逻辑计划关心做什么,物理计划关心怎么做
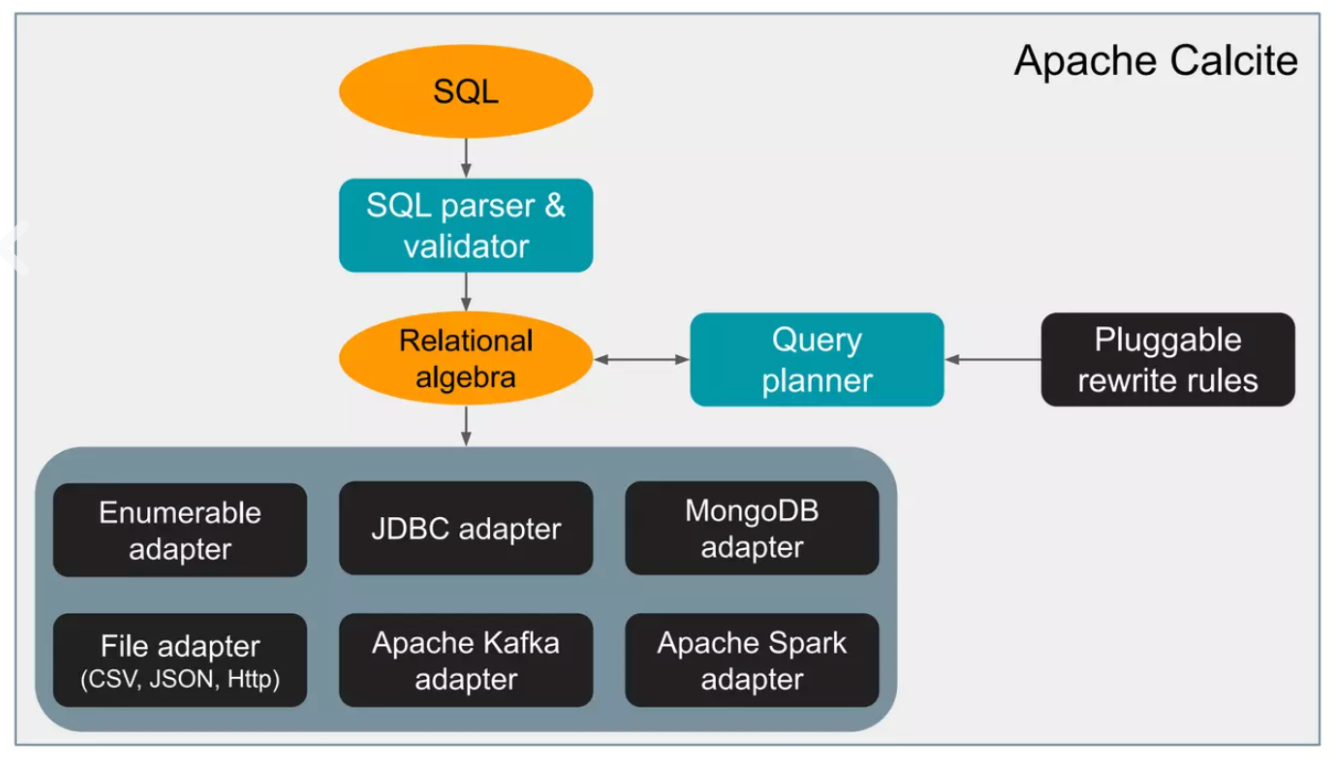
Calcite 的设计目标是 one size fits all,为不同计算存储引擎提供统一的 SQL 查询引擎。它的架构有三个核心特点:flexible(灵活性)、embeddable(可嵌入)、extensible(可扩展)。
核心问题:Calcite 如何将 SQL 转换为可执行计划?这个过程中需要哪些核心概念?
零:核心概念链条
理解 Calcite 的核心概念,需要把握它们之间的完整链条:
SQL 是声明式的,但优化需要数学基础,所以需要关系代数。
- 关系代数是数学概念,需要数据结构表示,所以有了 RelNode。RelNode 处理整个关系,但还需要处理行级数据,所以有了 RexNode。
- RelNode 是统一抽象,但不同执行引擎有不同实现,所以有了 Convention。
- 有了 RelNode 树需要优化,所以有了 RelOptRule。
- 规则定义了如何转换,但需要选择最优计划,所以有了优化器。有了优化器,但需要访问不同数据源,所以有了 Adapter。RelNode 有逻辑和物理两种形态,所以需要从逻辑计划转换为物理计划。
这些概念共同支撑了 Calcite 的架构设计,使得 Calcite 可以灵活地处理不同的数据源和执行引擎,实现真正的联邦查询。每个概念都解决了前一个概念带来的新问题,形成了一个完整的思维链条。
一、从 SQL 语法到关系代数:为什么需要数学抽象
SQL 是声明式的语言,描述了"要什么"而不是"怎么做"。但优化器需要知道如何优化,这就需要将 SQL 转换为可以进行数学变换的形式。
关系代数提供了这个基础。关系代数是关系型数据库操作的理论基础,支持并、差、笛卡尔积、投影和选择等基本运算。更重要的是,关系代数提供了等价变换规则:两个关系表达式如果产生相同的结果,就可以相互替换。
通过将 SQL 转换为关系代数,Calcite 实现了查询逻辑与优化逻辑的解耦,优化器可以应用各种优化规则,而不需要理解 SQL 的具体语法。
二、RelNode:关系表达式的树形表示
关系代数是数学概念,在代码中需要一种数据结构来表示,这就是 RelNode。
RelNode 是关系表达式的核心抽象,代表了对数据的一个处理操作。它的名称通常是动词:Sort、Join、Project、Filter、Scan。RelNode 会标识其 input RelNode 信息,这样就构成了一棵 RelNode 树。
RelNode 代表的是对整个 Relation(关系)的操作,它蕴含的是"做什么"而不是"怎么做"。例如,LogicalJoin 表示需要做连接操作,但不指定如何连接(是 hash join 还是 sort merge join)。
树形结构使得查询可以被递归地优化和执行,每个节点只关注自己的操作,通过组合不同的节点可以表达复杂的查询逻辑。
三、RelNode 与 RexNode:关系级与行级的分离
在 RelNode 中,我们还需要表达对一行数据的处理逻辑,比如 age + 1 这样的表达式。这就引出了 RexNode。
RelNode 是关系表达式,代表对整个关系的操作,如 Sort、Join、Project、Filter。它处理的是整个表。RexNode 是行表达式(标量表达式),蕴含的是对一行数据的处理逻辑,如 age + 1、name。它处理的是表中的一行数据。
例如,在 SELECT name, age + 1 FROM users WHERE age > 18 中,age + 1 是 RexNode(行表达式),而整个 SELECT 查询是 RelNode(关系表达式)。
这种分层设计将关系操作和标量计算分离,使得优化器可以分别优化关系操作(如 join 顺序)和标量计算(如表达式简化),提高了优化的灵活性。
四、Convention:不同执行引擎的统一抽象
有了 RelNode,但不同的执行引擎(Spark、Flink、JDBC)有不同的实现方式。如何统一处理?
Convention(调用约定)解决了这个问题。Convention 就像是不同执行引擎的"语言"。Spark 有自己的 Convention,Flink 有自己的 Convention,JDBC 也有自己的 Convention。
同数据引擎的 RelNode 可以直接相互连接,而非同引擎的则需要通过 Converter 进行转换。如果要在同一个查询中处理来源于异构系统的逻辑表,Calcite 要求先用 Converter 把异构系统的逻辑表转换为同一种 Convention。
Convention 机制实现了执行引擎的抽象,使得 Calcite 可以统一处理不同的数据源和执行引擎,支持联邦查询。
五、RelOptRule:基于规则的优化机制
有了 RelNode 树,如何优化?关系代数提供了等价变换规则,但需要一种机制来应用这些规则。
RelOptRule(规则)提供了这个机制。规则定义了如何将一个关系表达式转换为另一个等价的、更优的表达式。优化器会遍历 RelNode 树,尝试匹配每个规则。如果规则匹配成功,就会应用规则进行转换。
ConverterRule 是规则的一种,专门用来做数据源之间的转换。例如,JdbcToSparkConverterRule 可以将 JDBC Table 转换为 Spark RDD。
基于规则的优化系统具有高度的可扩展性,每个优化规则都是独立的,可以轻松添加新的优化规则,规则之间相互独立,便于维护。
六、优化器:启发式与基于成本的两种策略
规则定义了如何转换,但如何选择最优的执行计划?这需要优化器。
Calcite 支持两种优化器。HepPlanner 是启发式优化器,它简单地按树结构匹配所有已知规则,直到没有规则能够匹配为止。启发式优化比基于成本的优化更快,适合规则简单明确的场景。
VolcanoPlanner 是火山式优化器,它会匹配并应用规则,当整棵树的成本降低趋于稳定后,优化完成。成本优化器依赖于比较准确的成本估算。
提供两种优化器体现了 Calcite 的灵活性,不同的场景需要不同的优化策略。如果优化规则简单明确,可以使用 HepPlanner 快速优化。如果需要基于成本选择最优执行计划,特别是在复杂查询场景下,应该使用 VolcanoPlanner。
七、Adapter:连接不同数据源的桥梁
有了优化器,但如何访问不同的数据源?Adapter 解决了这个问题。
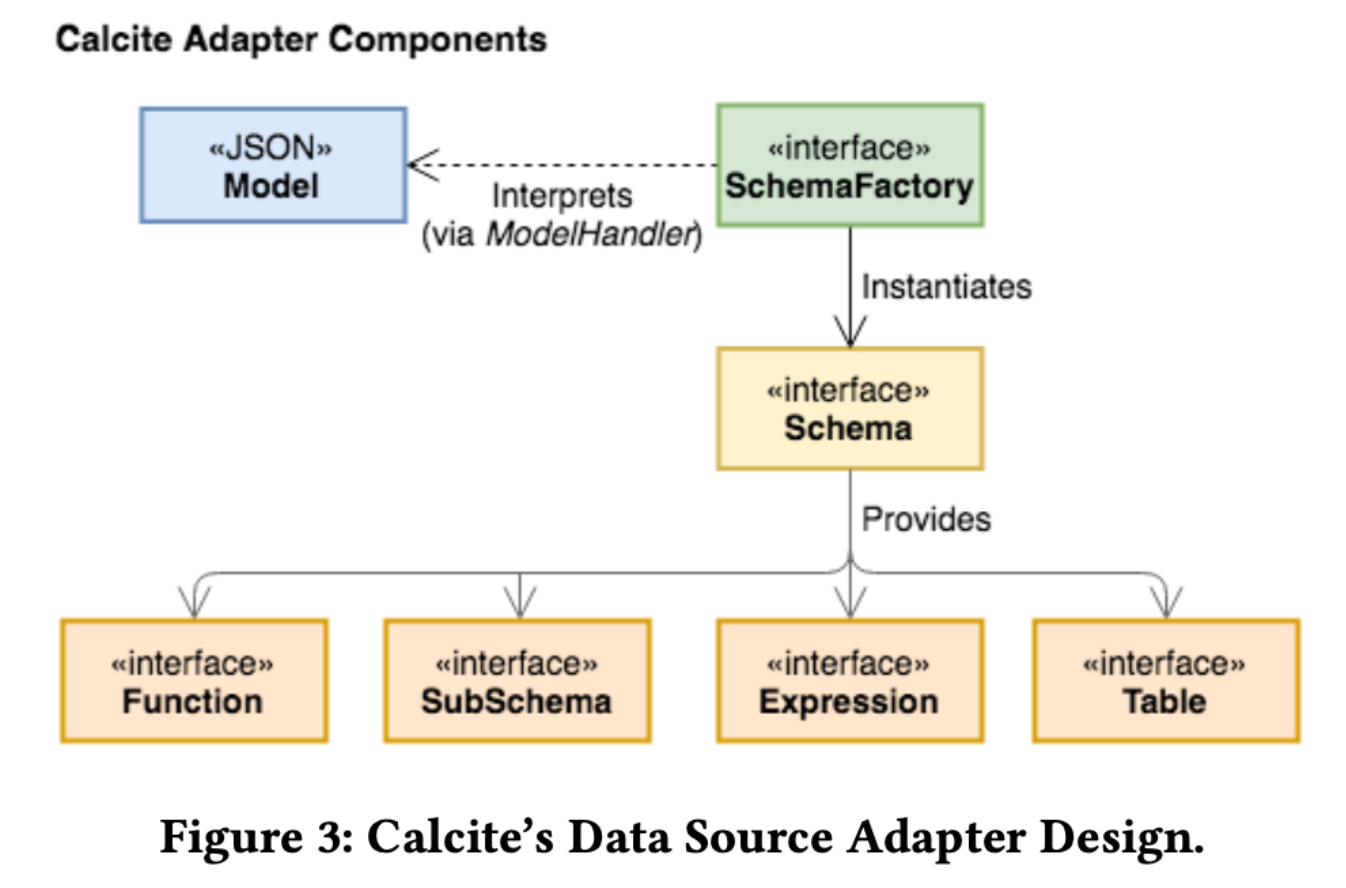
Adapter 就像是不同数据源的"翻译器"。它告诉 Calcite 如何访问数据源,如何将数据源的表转换为 RelNode,如何将逻辑计划转换为数据源可以执行的计划。
一个数据源的 Adapter 对应有一个 model(定义数据源的物理属性)、一个 schema(定义数据的格式和层次)、一个 schema Factory(解析 model 来创建 schema)。
Adapter 机制实现了数据源的抽象,使得 Calcite 可以统一处理不同的数据源,而不需要为每个数据源编写特定的代码。这种设计支持联邦查询,可以在一个 SQL 查询中访问多个数据源。
八、从逻辑计划到物理计划:逻辑计划关心做什么,物理计划关心怎么做
RelNode 树有两种形态:逻辑计划和物理计划。
Calcite 的核心算子都有对应的纯逻辑子类 LogicalXXX,如 LogicalProject、LogicalFilter、LogicalJoin。它们并不能生成可执行的执行计划,只是用于表示 SQL 对应的关系表达式结构。
与 Calcite 对接的后端执行引擎的 Adapter 都会实现这些算子的可执行的实现,如 CassandraProject。在优化器对 RelNode 树执行优化时,会根据优化 Rule 将逻辑算子替换成对应的物理算子。
这种设计将逻辑计划与物理计划分离,逻辑计划(LogicalXXX)只关注"做什么",物理计划(如 CassandraProject)关注"怎么做"。 优化器通过规则将逻辑计划转换为物理计划,这种分离使得优化器可以独立于执行引擎进行优化。