目录
前言
碎碎念: 一年过去了,你还是那个你。阵眼一直都是死磕一件事,请给我一点时间成长。
学的东西也是需要被筛选的,有些东西本身存在是为了让人理解,但是实际呈现却不便于让人理解,或者把它的本质搞复杂化了,就可以直接忽略了
被谁调用,调用了谁,输入是什么,输出是什么
实际如何调用:拿到开源工程,import代码文件进来后,我们做一个实例化的继承,调用它们的方法,按照自己的需要构建自己思路的parser
本项目旨在为一家金融保险公司开发一款基于RAG(Retrieval-Augmented Generation)的多模态问答助手,帮助员工快速获取公司制度、销售策略、产品信息、市场情、研报解读等多维度知识。通过四大核心模块优化(query理解、解析入库、混合检索、生成),显著提升知识检索效率与问答准确率。
Q&A
干一件什么事?
负责构建面向金融保险业务的检索增强生成式RAG问答系统,整合了5000+份多模态文档(pdf、ppt、扫描图片、视频字幕等),为xx金融公司员工提供基于本地知识库的即时问答服务。
核心流程:
离线处理阶段:
数据提取与清洗:如何收集多源数据,进行格式统一和预处理
文本分割:如何根据embedding模型对文档进行智能分割,保证语义的完整性
向量化和入库:用哪种预训练的embedding模型,如何构建向量索引
应用阶段:
检索策略:介绍相似性检索,全文检索以及多路召回(倒排序,RRF融合)的具体表现
prompts设计:如何构建有效prompts,将检索到的文本与原问题相融合,调用大模型生成答案,如何调优prompts以应对幻觉问题
模块化设计:如何分层次,分模块实现不同的功能,从而提升系统的稳定性和扩展性
parser_challenge
面对多模态的文件,会面临复杂格式文档解析错误
问题:表格未按逻辑结构排序解析,而是单纯得文本排序解析
某保险公司提供的⼀份理赔流程指南,采⽤双栏排版,其中左栏介绍步骤,右栏提供具体要求。
原因:RAG召回时通常会利用到chunk之间的上下文关系,应该按照 逻辑结构 ⽽⾮ ⽂本顺序 解析 PDF,
问题:表格结构丢失,所有数据串在⼀起,难以辨识字段和对应值。
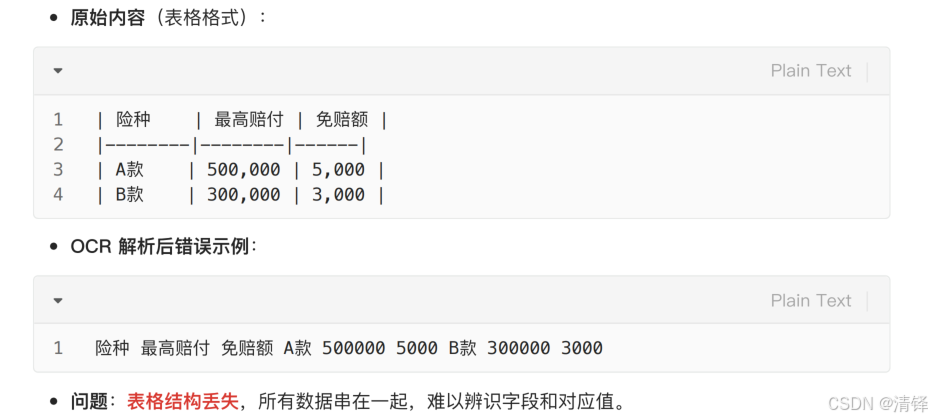
代码如何解决?
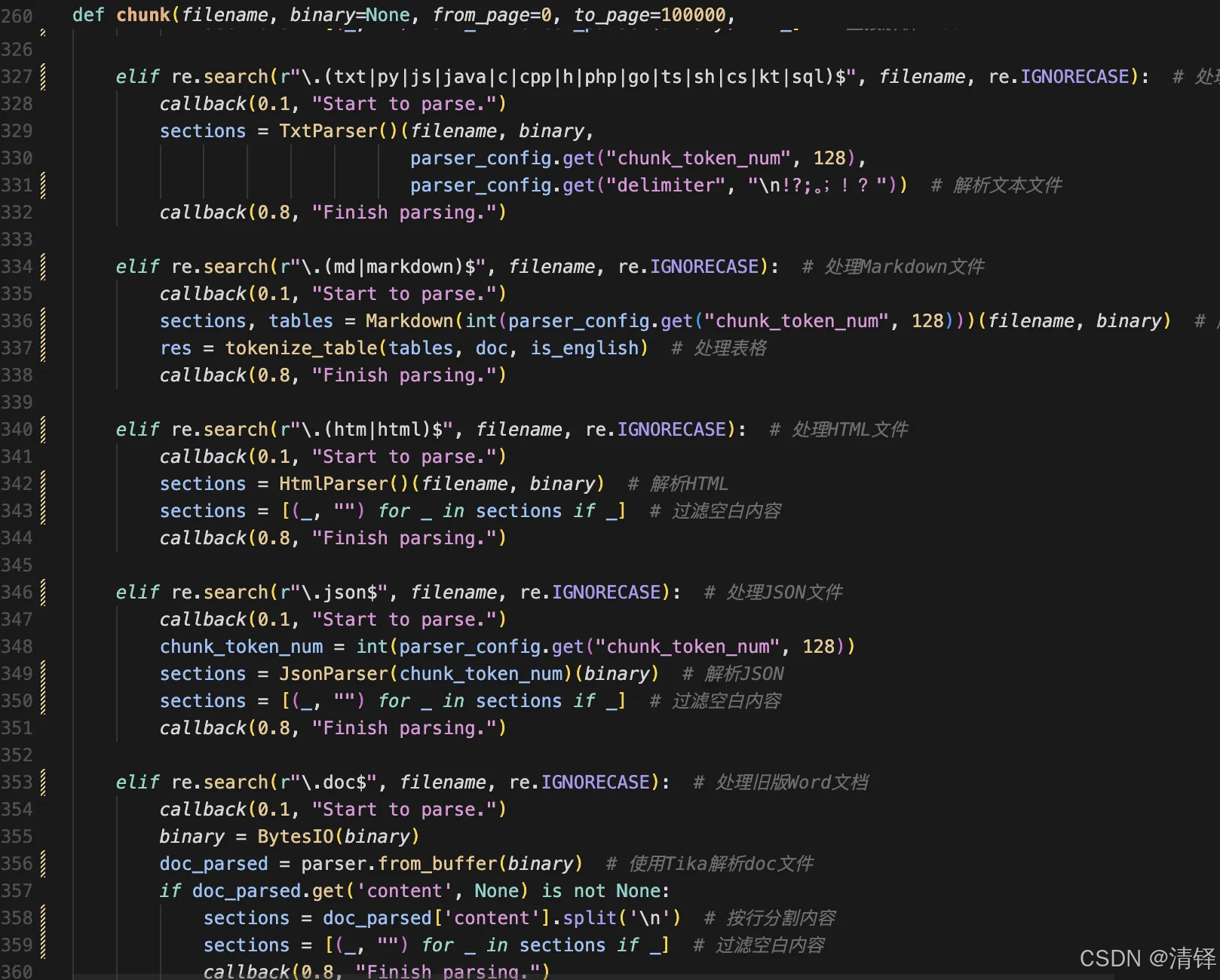
在chunk()函数中,针对不同的格式文件如md,pdf,docx,txt,json,py,。。。建立了不同的处理pipeline
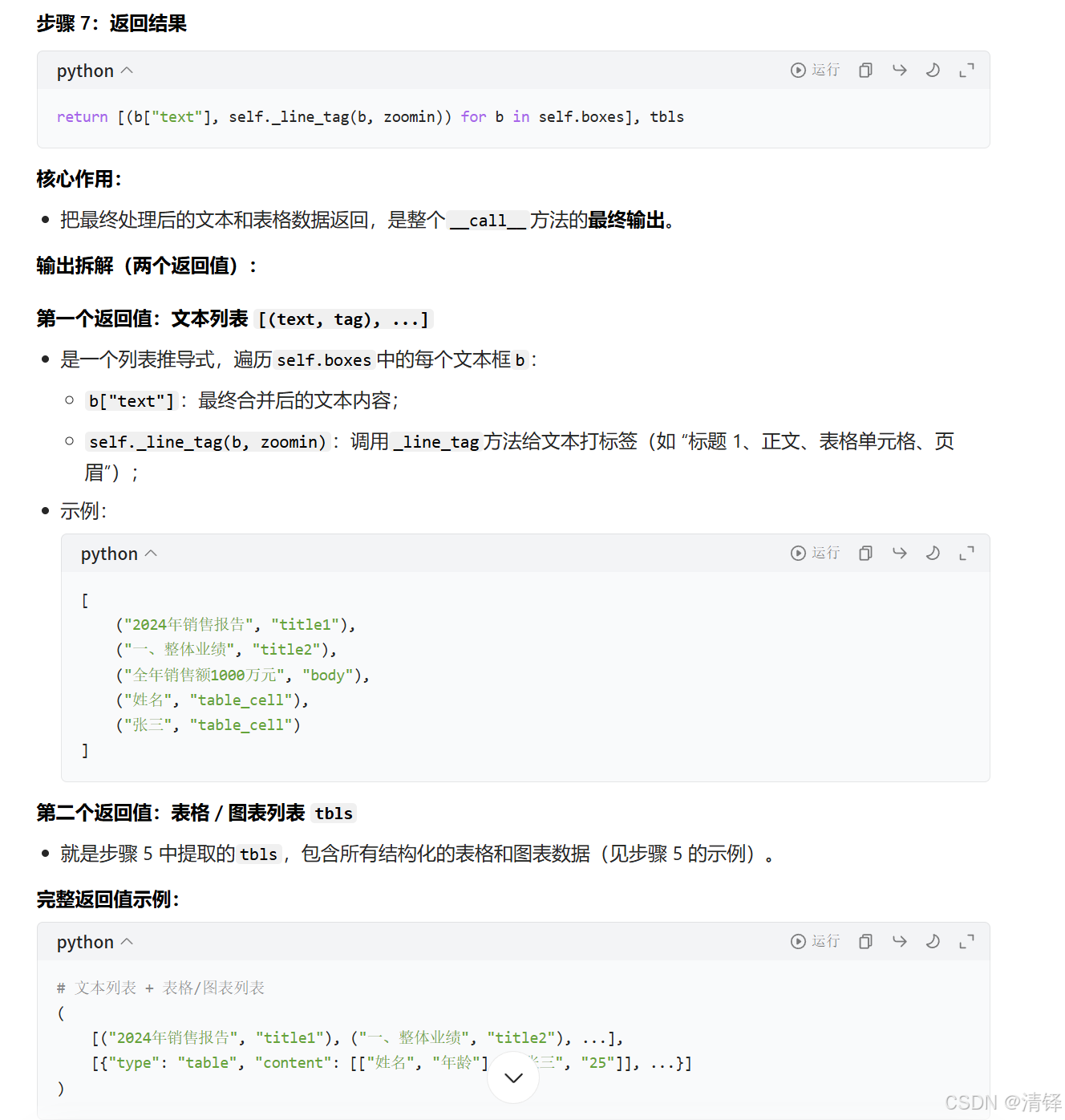
其中pdf的代码量是最多的。pdf的解析主要是从pdf中提取文本,图像,表格信息,以下详细介绍这个类里每个函数的输入,输出,作用。
__call__方法
__image__方法
将pdf转化为图片,便于后面OCR识别
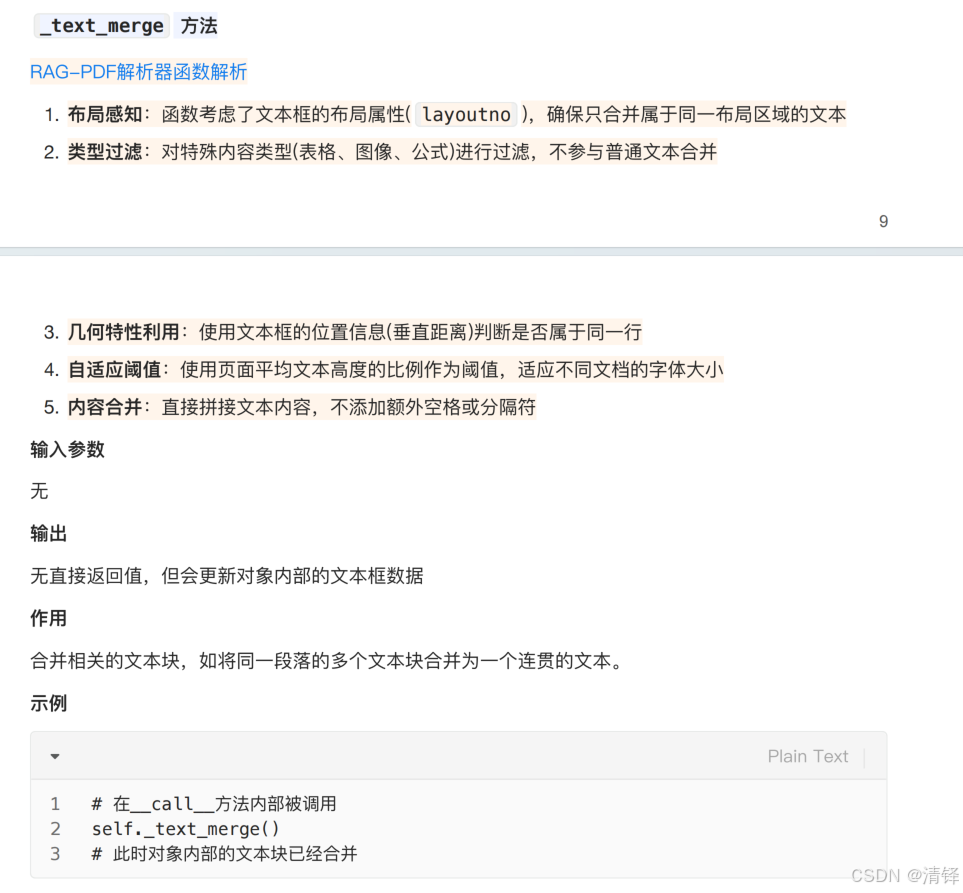
下文相关性合并,用的xgboost机器学习方法


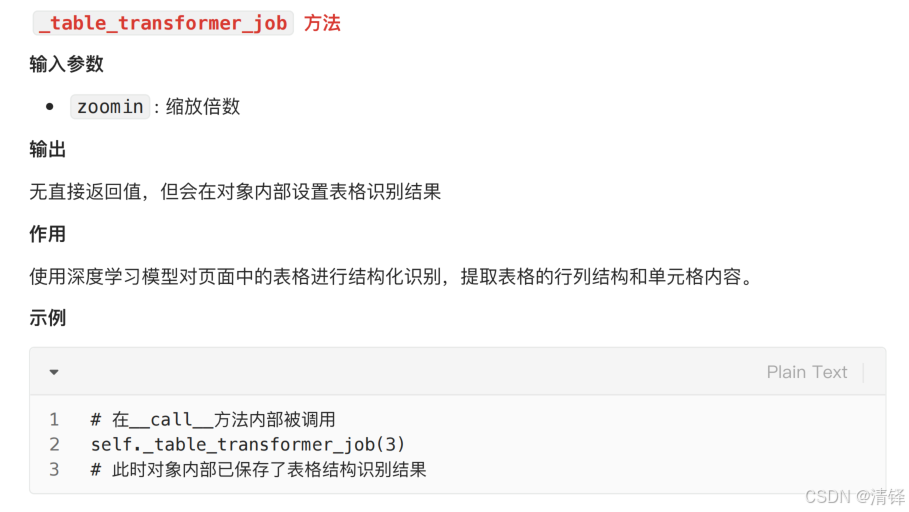


parser的价值是什么?解析不当会有什么negative impact?
parser是原始文档转化为可检索内容的第一步,是后续的向量检索和内容生成的基础,它的价值在于:提取关键信息(可用文本,结构化数据,上下文关系);保留文档的结构(章节层次,表格,列表等结构)有利于后续检索阶段好match;保证文档的质量,提高召回的精准度。
不同模态的文件,如何统一解析流程?

很多⽂档是扫描版的,需要OCR才能识别⽂本。你在实践中如何最⼤化地提⾼OCR识别的准确率和保真度?

有些⽂档在结构上⽐较复杂,⽐如有多层嵌套标题、表格、图例、脚注等。你在解析后,如何保证在检索阶段还能保持⼀定的层级信息?

如果我们要评估'⽂档解析'这个步骤的质量,或者在上线后持续监控它,该从哪些维度来衡量?

优化方向:
在布局识别时候用大模型来实现
chunk_challenge
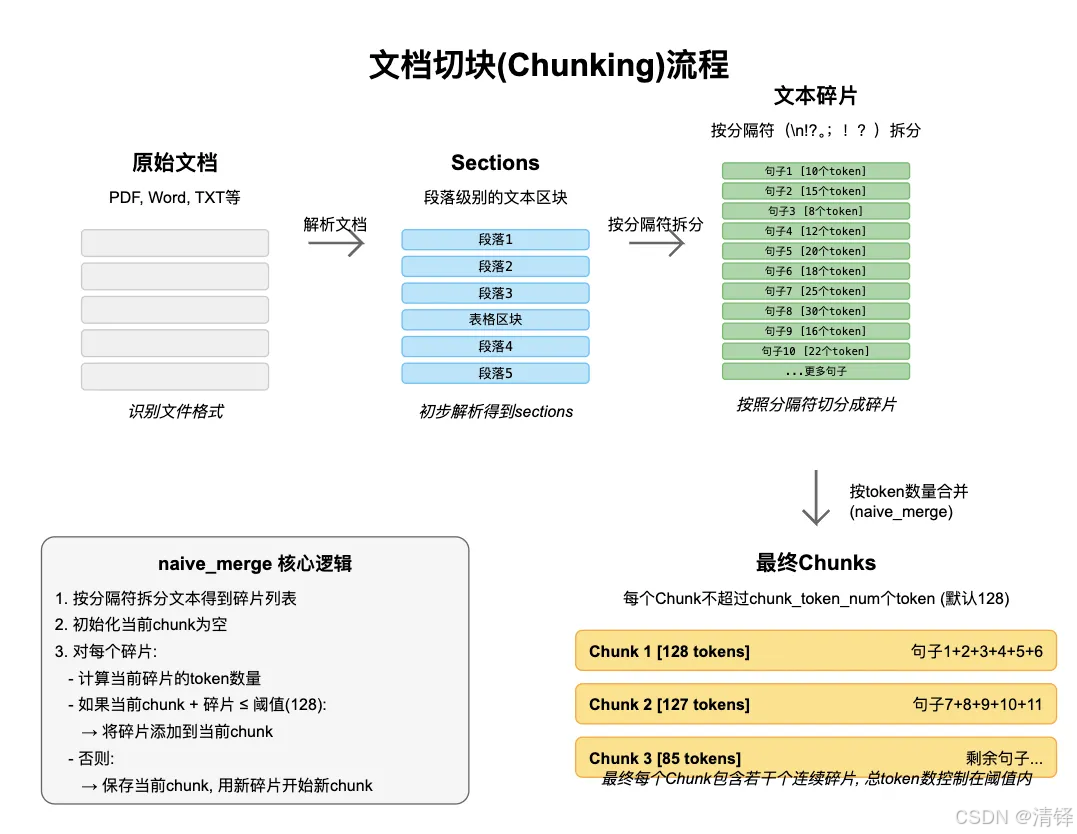
将上一步拆分的section和表格块合并成chunk

文本自身 和 文本自身分词后的结果 (用到了llamaindex)
3个parser,chunk没做好产生的问题
1、表格/图片的标题和它对应的标题的模块没有对应上。

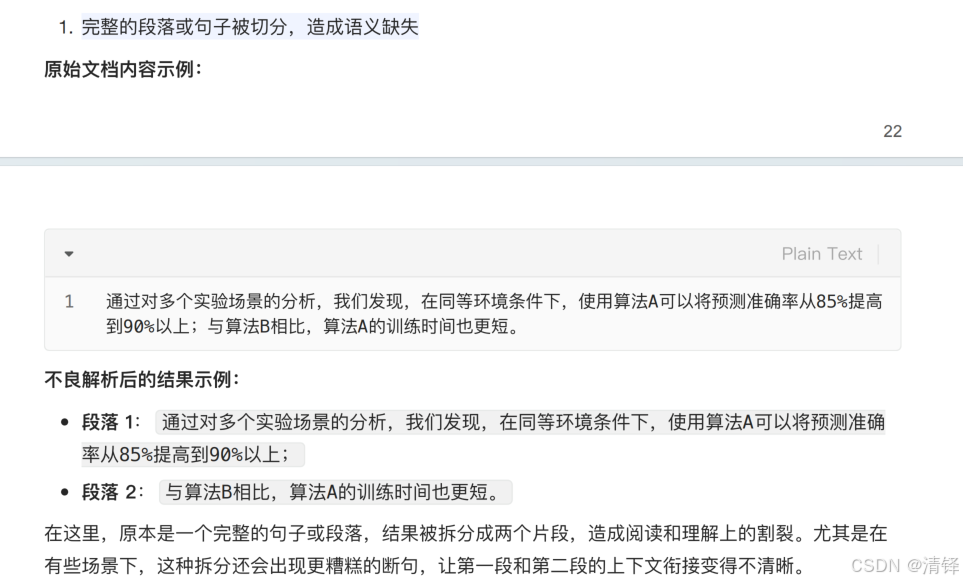
2、一个完整的段落,句子被切开了,完整的语义没有了
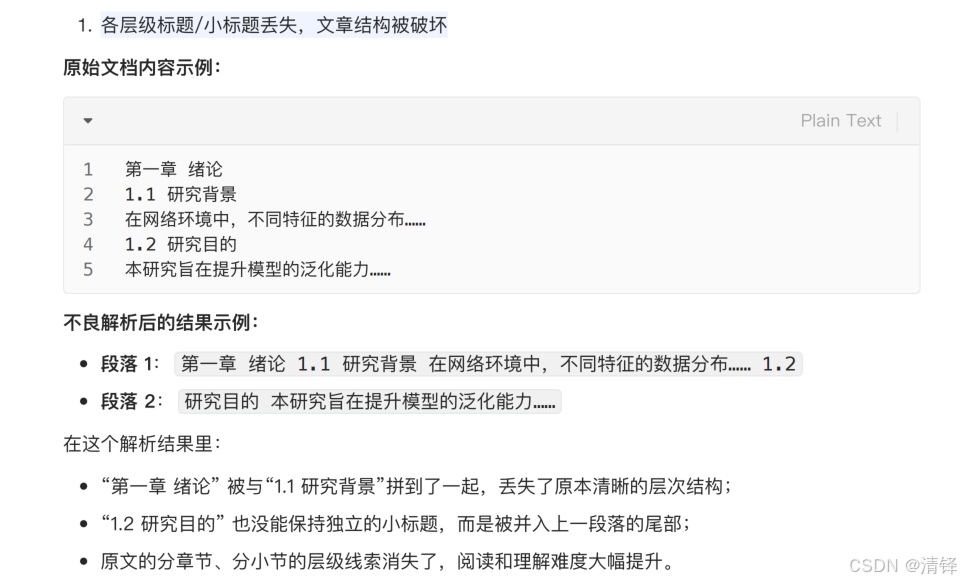
3.一个完整的文章有不同的层级,不同的标题,小标题,不管是按规则还是语义切分,切分后章节的标题不见了。
代码处理

使用naive_merge()函数
在最大字数token限制(chunk_token_num)内尽量合并文本段。若合并后超出限制,就另开一个新的chunk块。其工作原理如下。

naive_merge() 里的 add_chunk()函数原理

用tk_nums 计数器控制添加的token的数量,实现切分
chunk_token_num是可以自定义的
可以通过pos参数拼接位置信息,比如在chunk结尾添加这种自定义标签,如果说文本过短就自动忽略pos,可以切分的更快

优化方向:





chunk切分:针对表格/图⽚在跨⻚断⾏时易被拆分或丢失的问题,引⼊基于Token计数的智能切分策略,保障表格/图⽚整体性与段落连续性,将跨⻚信息缺失率由30%降⾄5%
为什么在RAG流程中需要进⾏Chunk切分?
RAG需要先将⻓⽂档拆分成可检索的⽂本块(chunks)供向量检索或索引,以保证检索效率和模型 处理的上下⽂⻓度限制。
不经过合理切分,会导致检索和⽣成时出现重要信息丢失或上下⽂拼接不完整等问题。
适当切分可以减轻检索负担,提⾼检索准确度和后续模型⽣成效果。
在Chunk切分时,为什么要特别关注表格和图⽚等⾮⽂本元素?
表格/图⽚往往承载了⾼度结构化或关键信息,如果被拆分或跨⻚丢失,会严重影响⽂档的可读性和 语义完整度。
不可拆分(atomic)处理可以确保检索过程中"表头"与对应"表格数据"或"图⽚标题"与其内容不会
脱节,从⽽提⾼对⽂档整体语义的保真度。


项目code结构

fastapi的路由模块
简单说,它决定了 "客户端(前端)请求哪个 URL,会触发后端哪个函数执行",是连接前端请求和后端业务逻辑的关键桥梁。
something概念
parser
**流程:**上传文档;格式文档解析;OCR解析质量,还原文字,表格,双栏,代码块等特殊结构;智能chunk切分(层级结构、语义连贯性);保留应有的层级结构,章节、子章节、要点、子内容。

**目的:**通过以上策略,系统能够最⼤程度保留⽂档原有信息结构,避免因解析不当导致内容遗漏,并保证
Chunk划分合理不割裂上下⽂。在检索时,丰富的上下⽂标签和⾼质量的Chunk内容可以显著提升召回 的准确性,使相关⽚段更容易被查询命中。
备注: 文档解析:deepdoc,mineru
像pdf这种有太多的非结构化内容就很难解析
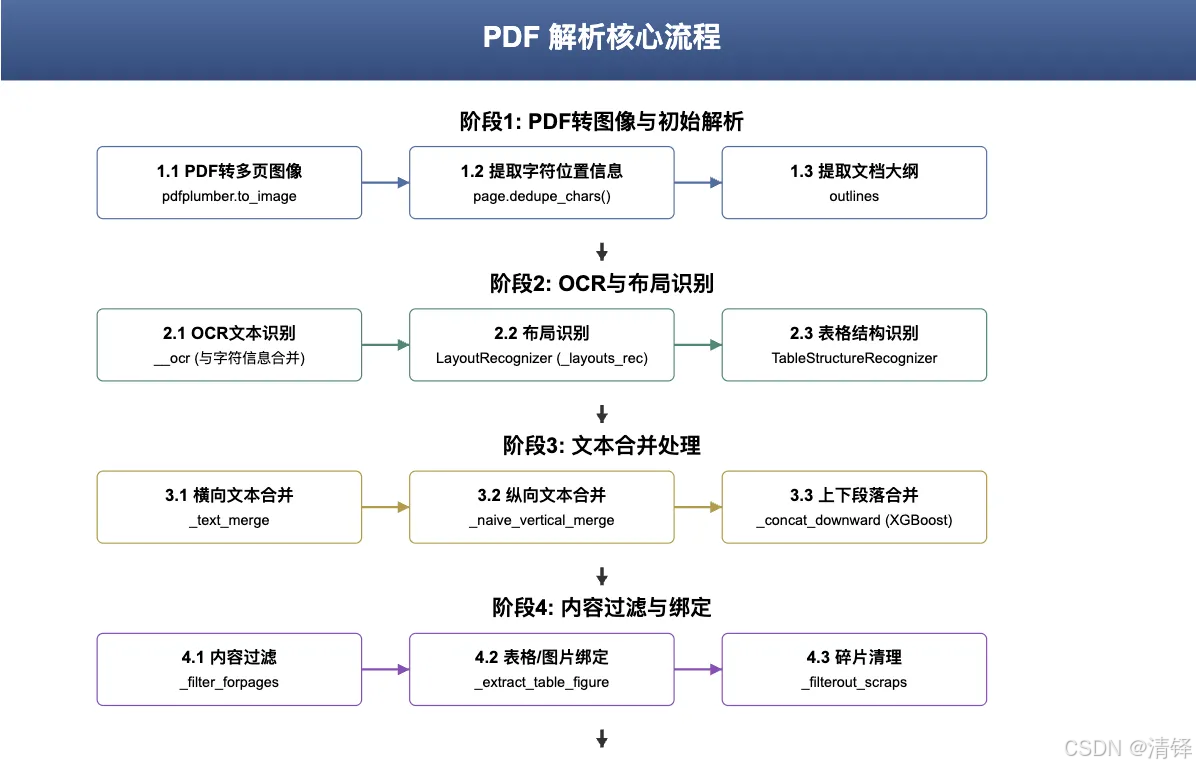
代码整体概览
这个⽂件主要定义了两个类:
-
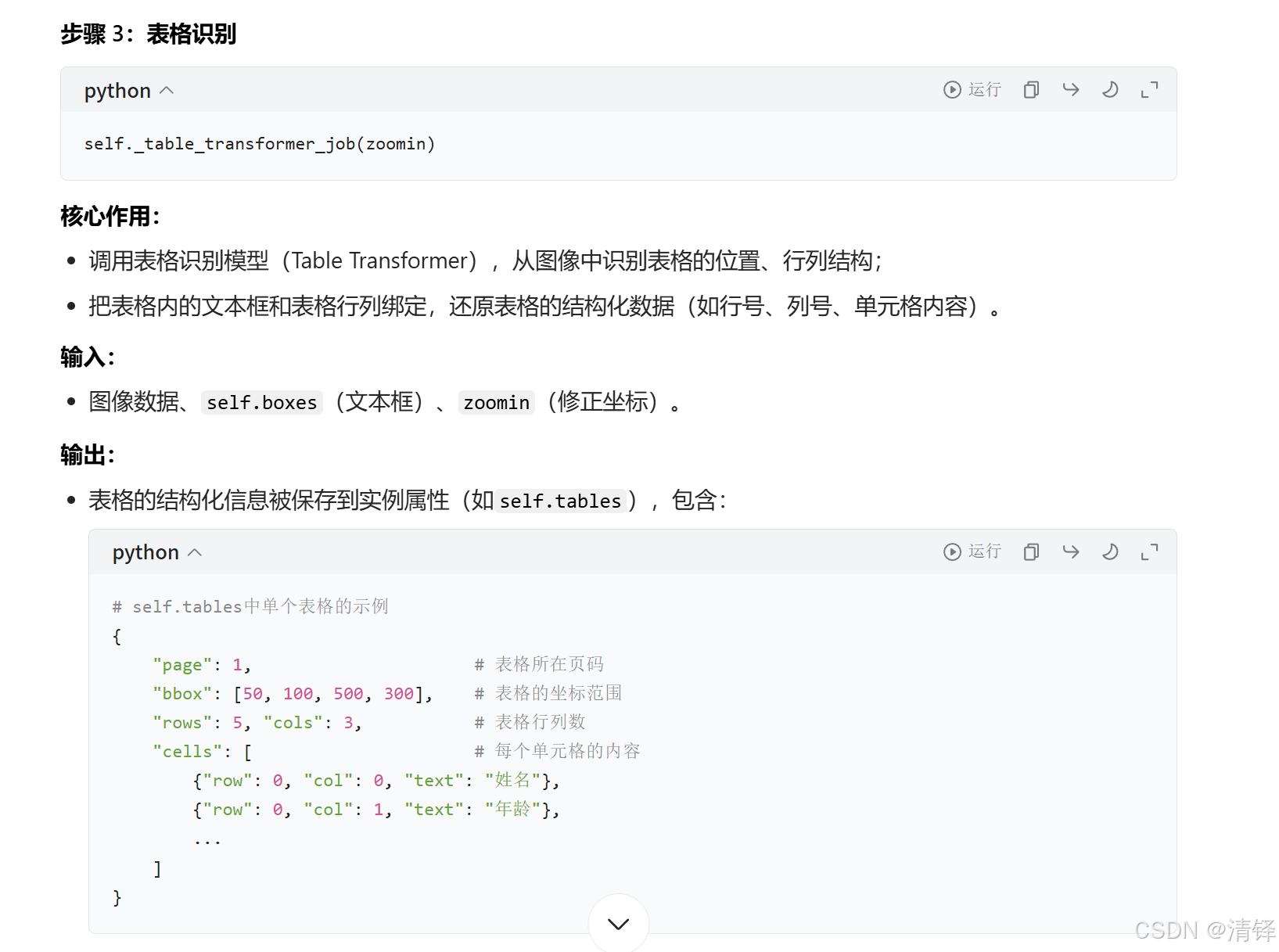
RAGFlowPdfParser:⽤于 PDF ⽂件解析,抽取⽂本块、表格、图⽚等结构化信息,做⼀些⽂本合 并与处理。
-
PlainParser:⼀个更简单的 PDF ⽂本解析器,仅仅⽤于读取纯⽂本。RAGFlowPdfParser 使⽤了多个外部库与内部的辅助函数/类,结合了 OCR(光学字符识别)、布局识别、表格识别、XGBoost (向下连接相关文本)等组件,实现了对 PDF 内容的深度解析。PlainParser 则⽐较简单,只是基 于 pypdf 的 extract_text() ⽅法来获取 PDF 每⻚的纯⽂本。
站在巨人的肩膀上,前辈已经对这个parser做了一轮又一轮的优化了。
向量化
调整向量相似度
insert knowledgebase:包含向量,文本,文本分词后的结果
聊天的api部分,路由到chat_on_docx里面去。然后调用到retrieval_content函数(进入到dealer.retrieval混合检索类里面,里面有不同的检索逻辑,对向量相似度 相似度权重,文本相似度tf-idf bm25再加入一些其它的场景加一些rerank逻辑)进行知识库检索,然后我们形成了一个新的提示词模版喂给大模型
难点在于调用一些深层的类是
用llamaindex可以快速地搭建一个demo RAG应用,
怎么评估你的这个RAG问答系统?
召回率,准确率,生成答案的可信度,系统响应速度,可扩展性以及用户体验。
召回率/准确率评估
该维度评估RAG系统回答问题的正确性和检索相关性。主要包括:
答案准确率 :比较生成的答案与标准答案的匹配程度,可使用自然语言处理中的评价指标如 BLEU (衡量n元语法匹配程度)、ROUGE (衡量召回的n元语法覆盖率)等来量化答案与参考答案的相似度。
检索召回率 :评估检索模块是否找到了包含正确答案的文档。例如计算 Top-k召回率 (正确答案所在文档是否出现在前k个检索结果中)以及 MRR(平均倒数排名) ,以衡量正确文档在检索结果中的位置(MRR越高表示相关文档排名越靠前)。
生成答案的可信度评估
这一维度关注生成的答案在多大程度上有文档支持,以及答案内容和检索到的文档是否一致、可靠。具体包括:
答案与支持文档匹配度 :验证生成答案中的关键信息是否能在检索文档中找到。可以计算答案和支持文档之间的相似度或重合率,例如关键词重叠度。
文档覆盖率 :检查检索到的文档是否覆盖了回答所需的所有要点。如果答案涉及多个要点,评估这些要点是否均能在提供的文档集合中找到依据。
系统响应速度评估
在金融保险业务场景中,用户提问往往希望即时得到答案,因此系统的响应延迟是关键指标。本部分评估RAG系统处理查询的速度,包括:
平均响应时间 :系统处理单个查询的平均用时。
P95/P99 延迟 :95%和99%的请求在多少时间内完成(尾部延迟),用于评估最慢响应的情况。
整体响应分布 :可以绘制响应时间分布图(如直方图)来了解大部分查询的延迟范围(本示例中不绘制图表,仅说明指标)。
可扩展性评估
可扩展性评估旨在测试RAG系统在不同数据规模和负载下的性能表现,包括:
数据规模扩展 :增大知识库或文档集规模,观察检索和生成性能的变化(如响应时间是否随数据量线性增长,检索准确率是否保持稳定)。
吞吐量 :衡量系统每秒可处理的查询数(QPS),以及在高并发情况下的性能表现。
用户体验评估
用户体验评估侧重于系统给用户带来的主观感受和易用性,包括:
人工满意度评价 :通过人工评估或用户反馈来打分,衡量用户对答案的满意度。例如收集用户评分(1-5分)或对答案是否解决问题的二元反馈,以计算平均满意度分或满意率。
答案可读性 :评价生成答案表述的清晰易懂程度。可以使用可读性评分 (如基于句子长度和词汇复杂度的指标)来定量分析答案文本的可读性,确保答案语言简洁明了,便于用户理解。

RAG
目标:
目标:掌握rag的关键技术和优化手段,具备诊断和系统性提升rag应用的能力,能够根据业务需求设计,构建,迭代rag系统。
掌握rag核心原理和工作流程
掌握文档处理,chunking, embedding模型选择与应用
熟练使用向量数据库进行索引构建和相似度检查
掌握使用llamaindex 快速构建rag应用的能力
掌握rag优化方案 16种
初期:能用llamaindex搭建一个自己的研报助手,后期搭建一样金融保险公司rag文档系统
检索 and 生成
如何结合RAG flow和本地\云端 部署的大模型创建个人/企业的知识库呢?
快速做一个基于课题组知识库的一个问答去帮助师门,赋能团队
rag:检索增强的处理。本地私有的数据,模型是不知道。r1训练的截止时间是23年年底。rag就是用来解决模型的幻觉和数据更新的事情
query一定能找到相关文档吗?一个企业可能有上万个文档,一个文档可能就有上百页。
医疗或者法律的场景? 即使让你开卷考你一定能回答出来吗
掌握2阶段,3模型,13种优化方案,以及在什么场景下使用
手撕基础的rag应用:加载文档,创建索引,实现检索,llm生成
rag优化
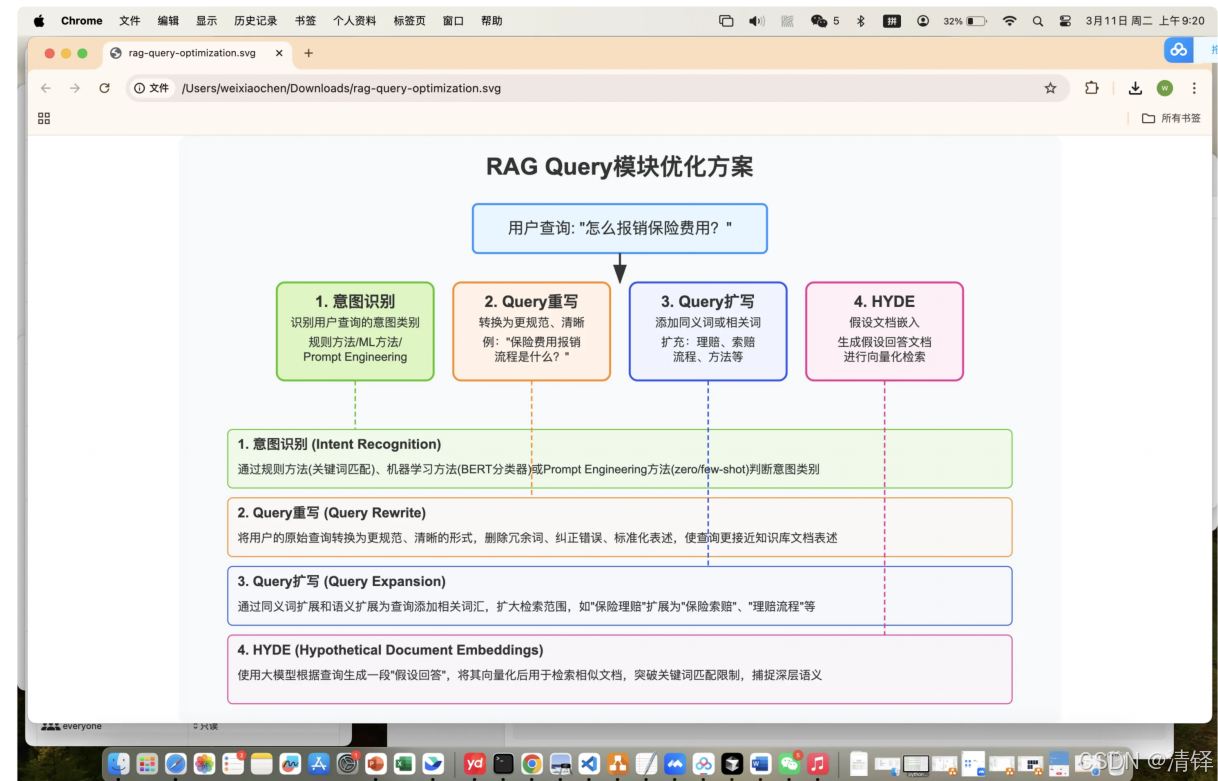
意图识别
python
def classify_intent_rule(query: str) -> str:
# 函数定义:
# - 函数名:classify_intent_rule(规则式意图分类)
# - 参数:query: str 表示输入的用户查询语句,类型注解为字符串
# - 返回值:-> str 表示返回意图名称,类型注解为字符串
query = query.lower() # 统⼀⼩写处理(如适⽤英⽂,此处对中⽂影响可忽略)
# 作用:将输入的查询语句全部转为小写,目的是统一字符格式,避免因大小写(如"报销"和"报销"无区别,但英文"Reimburse"和"reimburse"会有区别)导致匹配失败;对中文无实际效果,属于通用兼容处理
# 定义关键词列表
intent_keywords = {
"报销流程查询": ["报销", "费⽤", "报销流程"], # 意图名称:对应的核心关键词列表,只要命中任意一个关键词就归为该意图
"保险产品销售技巧": ["卖保险", "销售", "技巧", "销售技巧"] # 同理,命中"卖保险"/"销售"/"技巧"/"销售技巧"任一关键词则归为该意图
}
for intent, keywords in intent_keywords.items():
# 遍历意图字典:intent 是当前遍历到的意图名称(如"报销流程查询"),keywords 是该意图对应的关键词列表
if any(keyword in query for keyword in keywords):
# 核心匹配逻辑:
# - 遍历当前意图的所有关键词,检查是否有任意一个关键词出现在用户查询语句中
# - any() 函数:只要有一个条件满足(关键词在query中),就返回True
return intent # 匹配到则立即返回对应的意图名称,终止函数执行
return "未知意图" # 遍历完所有意图都未匹配到任何关键词时,返回默认的"未知意图"
# 测试用例定义
queries = ["怎么报销保险费⽤?", "新⼈怎么提升保险产品销售技巧?", "保险理赔需要哪些材料?"]
# 构建待测试的查询列表,包含3个典型场景:匹配报销意图、匹配销售技巧意图、无匹配的未知意图
for q in queries:
# 遍历测试列表中的每一个查询语句
print(q, "->", classify_intent_rule(q))
# 调用意图分类函数,打印原始查询语句 + 箭头 + 分类结果,直观展示测试效果if any(keyword in query for keyword in keywords):
any() 满足一个就返回true
从keywords逐个拿keyword,看keyword是不是在query里面
hyde可以让大模型直接做用户意图,query重写,query扩写这几个事情