记忆是一种记住之前互动信息的系统。对于人工智能智能体来说,记忆至关重要,因为它能让他们记住之前的互动,从反馈中学习,并根据用户偏好进行调整。随着智能体u处理涉及大量用户交互的复杂任务,这一能力对效率和用户满意度都变得至关重要。
短期记忆让你的应用程序能够记住单一线程或对话中的之前互动。
对话历史是最常见的短期记忆形式。长时间对话对当今的 LLM 来说是一大挑战;完整的历史可能无法放入 LLM 的上下文窗口,导致上下文丢失或错误。
即使你的模型支持完整的上下文长度,大多数大型语言模型在长上下文下表现仍然不佳。他们会被陈旧或离题内容"分心",同时又面临响应较慢和成本更高的问题。
目录
[2.1.定义扩展的 AgentState](#2.1.定义扩展的 AgentState)
[2.2.创建支持扩展状态的 Agent](#2.2.创建支持扩展状态的 Agent)
[4.3.Before model](#4.3.Before model)
[4.4.After model](#4.4.After model)
1.Langchain--创建记忆
要为智能体添加短期内存(线程级持久性),你需要在创建智能体时指定checkpointer 。
LangChain 的新一代代理(如 LangGraph 实现的代理)采用 显式状态(Explicit State) 模型,而不是传统的隐式链式调用。
短期记忆 = 图的状态(State)
- 代理的"短期记忆"不是隐藏在 LLM 提示词中的对话历史,而是显式定义的数据结构(通常是 Python 字典或 Pydantic 模型)。
- 这个状态包含:
- 用户输入
- 对话历史(messages)
- 工具调用结果
- 中间推理步骤
- 自定义上下文(如用户 ID、会话变量等)
python
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
import os
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = "sk-"
# 初始化大模型
llm = ChatTongyi(
model="qwen-max",
temperature=0,
streaming=False,
)
# 初始化记忆存储(关键:用于保存多轮对话状态)
memory = InMemorySaver()
# 创建 agent(注意:即使没有工具,也要传入空列表)
# 如果你有自定义 system prompt,可以传入 system_prompt 参数
agent = create_agent(
model=llm,
tools=[], # 没有工具时传空列表
# system_prompt="You are a helpful assistant.", # 可选
checkpointer=memory
)
# 多轮对话循环
thread_id = "1" # 固定 thread_id,保持同一会话
print("开始多轮对话(输入 'quit' 退出):")
while True:
user_input = input("\n你: ")
if user_input.lower() == "quit":
print("对话结束。")
break
# 调用 agent
result = agent.invoke(
{"messages": [HumanMessage(content=user_input)]},
config={"configurable": {"thread_id": thread_id}},
)
# 输出 AI 回复
ai_message = result["messages"][-1].content
print(f"AI: {ai_message}")| 组件 | 作用 |
|---|---|
InMemorySaver() |
在内存中保存对话历史,基于 thread_id 区分会话 |
thread_id |
同一个 ID 表示同一轮对话,agent 会自动读取历史消息 |
HumanMessage |
推荐使用消息对象,而不是字典,避免格式错误 |
2.Langchain--定制记忆
AgentState 是智能体(Agent)的"运行时大脑",它默认通过 messages 键维护对话历史(短期记忆)。而通过扩展 AgentState,我们可以给这个大脑添加"自定义记忆"或"上下文变量"。
- 默认状态 (
MessagesState) :默认情况下,create_agent使用一个包含messages键的默认状态。每次回复后,新消息会被追加到旧消息列表中(归约操作operator.add)。 - 扩展状态 (
state_schema) :通过定义自定义的TypedDict并传入state_schema参数,我们可以添加如user_id、session_data、intermediate_steps等额外字段。
下面我修改之前的代码,实现一个带有用户专属记忆的多轮对话 Agent。
2.1.定义扩展的 AgentState
我们增加两个字段:
user_id: 记录用户ID。last_topic: 用于存储主题、语言等偏好
python
from langchain.agents import AgentState
from typing import Dict, Any
class CustomAgentState(AgentState):
user_id: str
preferences: Dict[str, Any] # 用于存储主题、语言等偏好2.2.创建支持扩展状态的 Agent
关键点是传入 state_schema=ExtendedAgentState。
python
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langgraph.checkpoint.memory import InMemorySaver
import os
# 初始化模型和记忆
os.environ["DASHSCOPE_API_KEY"] = ""
llm = ChatTongyi(model="qwen-max", temperature=0)
checkpointer = InMemorySaver()
# --- 3. 定义工具 (回归最简单的参数定义) ---
@tool
def get_user_info(user_id: str) -> str:
"""
根据提供的用户ID查询模拟的用户信息。
参数 user_id: 必须提供用户的唯一标识符。
"""
mock_db = {
"user_123": {"name": "Alice", "points": 1500},
"user_456": {"name": "Bob", "points": 200}
}
# 模拟数据库查询
info = mock_db.get(user_id, {"name": "Unknown", "points": 0})
return f"用户详情: {info}"
# --- 4. 创建 Agent ---
agent = create_agent(
model=llm,
tools=[get_user_info],
state_schema=CustomAgentState,
checkpointer=checkpointer
)2.3.多轮对话与状态流转
在调用时,我们可以在输入字典中包含自定义字段。Agent 执行完后,这些字段也会被保存在返回结果中。
python
print("=== 第一轮对话 ===")
# ⚠️ 关键修改:在 HumanMessage 中明确告诉 AI 它的 user_id 是什么
# 这样 AI 才能准确地把 "user_123" 这个字符串填入工具的参数中
initial_input = {
"messages": [HumanMessage(content="你好,我的用户ID是 user_123。请查询我的用户信息。")],
"user_id": "user_123", # 这是为了存入 State,方便后续使用
"preferences": {"theme": "dark", "language": "zh"}
}
result = agent.invoke(
initial_input,
config={"configurable": {"thread_id": "1"}}
)
print("AI 回复:", result["messages"][-1].content)
print("当前 State 中的偏好:", result.get("preferences"))
print("\n=== 第二轮对话 ===")
# 第二次调用:AI 已经在第一轮的上下文中"看到"或"处理"过 user_123
# 但为了保险,我们在询问时依然可以提及,或者依靠上下文记忆
result2 = agent.invoke(
{
"messages": [HumanMessage(content="根据刚才的信息,我的积分是多少?")],
},
config={"configurable": {"thread_id": "1"}}
)
print("AI 回复:", result2["messages"][-1].content)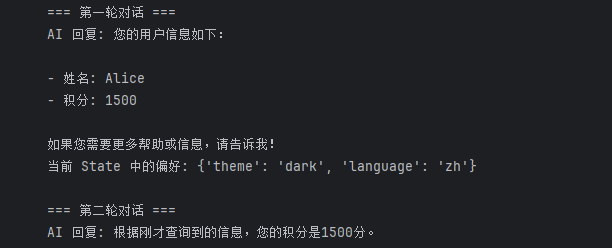
3.Langchain--常见模式(记忆)
启用短期记忆时,长时间对话可以超过 LLM 的上下文窗口。常见的解决方案有:
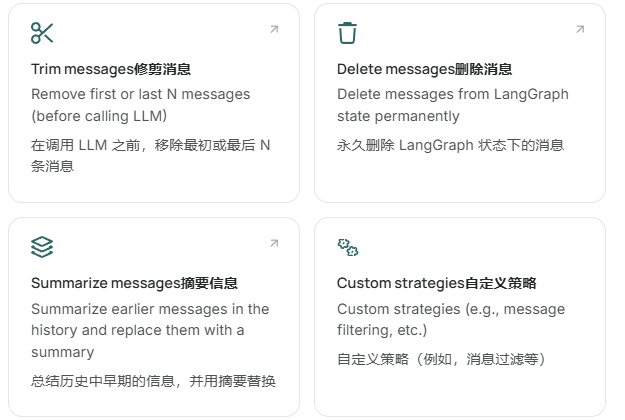
这使得代理能够跟踪对话而不超出 LLM 的上下文窗口。
3.1.修剪消息
大多数大型语言模型都有最大支持的上下文窗口(以令牌表示)。
决定何时截断消息的一种方法是统计消息历史中的令牌数量,并在接近该限制时截断。如果你用的是 LangChain,可以用 trim 消息工具,指定要从列表中保留的标记数量 ,以及处理边界的策略 (例如保留最后一个 max_tokens)。
要在智能体中修剪消息历史,可以使用 @before_model 中间件装饰器:
自动计算消息的 Token 数量,确保上下文永远不会超出模型限制(例如 Qwen 的 32k)
- 核心逻辑:当对话轮数超过 3 条时,代码会自动删除中间的历史消息,只保留第一条(初始问候)和最后 3 或 4 条(最近对话),防止超出模型的上下文长度限制。
- 场景模拟:模拟了用户"小明"与 AI 的多轮中文对话,并测试了 AI 是否记得用户的名字。
python
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""
中间件:修剪消息历史。
目的:防止对话历史过长超出模型上下文窗口限制。
"""
messages = state["messages"] # 获取当前所有消息
# 如果消息不多(<=3条),不需要处理
if len(messages) <= 3:
return None
# 策略:保留第一条消息(通常是开场白)
first_msg = messages[0]
# 策略:保留最后几条消息(最近的对话)
# 这里是一个简单的逻辑:如果消息总数是偶数保留最后3条,奇数保留最后4条
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
# 组合新消息列表:第一条 + 最近的消息
new_messages = [first_msg] + recent_messages
# 指令:先删除所有旧消息,然后添加整理后的新消息
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), # 清除历史
*new_messages # 添加精简后的消息
]
}
# 创建智能体
agent = create_agent(
llm, # 使用的大模型
# tools=your_tools_here, # 工具列表(如果需要)
middleware=[trim_messages], # 注册中间件,每次调用模型前都会执行 trim_messages
checkpointer=InMemorySaver(), # 使用内存保存对话状态(实现多轮对话记忆)
)
# 配置:指定对话线程ID
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
# --- 模拟多轮中文对话 ---
# 第1轮:用户介绍自己
agent.invoke({"messages": "你好,我叫小明。"}, config)
# 第2轮:闲聊
agent.invoke({"messages": "写一首关于猫的短诗。"}, config)
# 第3轮:继续闲聊
agent.invoke({"messages": "那现在写一首关于狗的。"}, config)
# 第4轮:测试记忆(此时历史较长,可能会触发截断)
final_response = agent.invoke({"messages": "我的名字是什么?"}, config)
# 打印AI的最终回复
final_response["messages"][-1].pretty_print()
"""
================================== Ai Message ==================================
你的名字是 小明。你刚才告诉我的。
如果你希望我叫你昵称或者用不同的名字,尽管告诉我。
"""3.2.删除消息
你可以从图中删除消息来管理消息历史。当你想删除特定消息或清除整个消息历史时,这非常有用。要删除图状态中的消息,可以使用 RemoveMessage。
为了让 RemoveMessage 正常工作,你需要使用带有 add_messages缩减器的状态键。默认的 AgentState 提供此功能。要删除特定信息:
python
from langchain.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# 删除最早的两条消息
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}要删除所有消息:
python
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def delete_messages(state):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}在删除历史消息以节省 Token 时,你不能随意删除,必须遵守两个关键规则,否则模型会报错或"发疯":
- 要有头有尾:对话历史最好以用户(User)的提问开始。如果把开头的用户消息删了,留下 AI 的回答,AI 会看不懂上下文。
- 工具要配对 :这是最容易出错的地方。AI 的工具调用 和工具的返回结果 是一对"夫妻",绝对不能拆散。如果你删掉了工具结果,只留着 AI 说"我要调用工具",AI 再次看到时会以为是新的指令,导致逻辑混乱或报错。
python
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
@after_model
def delete_old_messages(state: AgentState, runtime: Runtime) -> dict | None:
"""删除旧消息,防止对话过长。"""
messages = state["messages"]
# 如果消息数量超过2条
if len(messages) > 2:
# 删除最前面的2条消息(保留最近的对话)
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
return None
# 创建智能体
agent = create_agent(
llm,
tools=[],
# 系统提示词改为中文
system_prompt="请回答得简洁明了。",
# 注册中间件
middleware=[delete_old_messages],
# 使用内存检查点保存对话状态
checkpointer=InMemorySaver(),
)
# 配置对话线程ID
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
# 第一轮对话:用户打招呼
for event in agent.stream(
{"messages": [{"role": "user", "content": "嗨!我是鲍勃"}]},
config,
stream_mode="values",
):
# 打印当前所有的消息类型和内容
print([(message.type, message.content) for message in event["messages"]])
# 第二轮对话:用户提问
for event in agent.stream(
{"messages": [{"role": "user", "content": "我的名字是什么?"}]},
config,
stream_mode="values",
):
# 打印当前所有的消息类型和内容
print([(message.type, message.content) for message in event["messages"]])3.3.摘要消息
如上所述,修剪或删除消息的问题在于,你可能会在消息队列的剔除中丢失信息。因此,一些应用更适合使用聊天模型总结消息历史的更复杂方法。
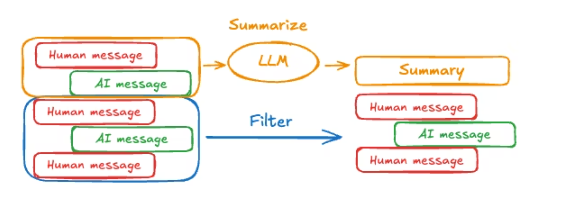
要在代理中总结消息历史,可以使用内置的 SummarizationMiddleware:
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
from langchain_community.chat_models import ChatTongyi # 导入千问
# --- 1. 初始化千问模型 ---
# 这里需要两个模型:一个用于主对话(大模型),一个用于做摘要(小模型/快模型)
# 假设你有对应的 Qwen 模型 ID
llm_main = ChatTongyi(model="qwen-max", temperature=0) # 主力模型
llm_mini = ChatTongyi(model="qwen-turbo", temperature=0) # 用于快速摘要的模型
# --- 2. 配置检查点 ---
checkpointer = InMemorySaver()
# --- 3. 创建 Agent ---
agent = create_agent(
model=llm_main, # 使用 Qwen-Max
tools=[],
middleware=[
SummarizationMiddleware(
# 指定用于生成摘要的模型 (使用更快的 qwen-turbo)
model=llm_mini,
# 触发条件:当 Token 数量超过 4000 时启动摘要
trigger=("tokens", 4000),
# 保留策略:在摘要后,保留最近的 20 条消息不被总结(只总结更早的历史)
keep=("messages", 20)
)
],
checkpointer=checkpointer,
)
# --- 4. 测试对话 ---
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
# 模拟长对话
agent.invoke({"messages": "你好,我叫小明。"}, config)
agent.invoke({"messages": "写一首关于猫的短诗。"}, config)
agent.invoke({"messages": "那现在写一首关于狗的。"}, config)
# 询问名字(测试记忆)
final_response = agent.invoke({"messages": "我的名字是什么?"}, config)
# 打印结果
final_response["messages"][-1].pretty_print()4.访问存储器
您可以通过多种方式访问和修改智能体的短期记忆(状态):
4.1.工具
工具中的短期记忆读取
使用runtime参数(类型为 ToolRuntime)访问工具中的短期内存(状态)。runtime 参数对工具签名是隐藏的(模型看不到),但工具可以通过它访问状态。
python
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
class CustomState(AgentState):
user_id: str
@tool
def get_user_info(
runtime: ToolRuntime
) -> str:
"""Look up user info."""
user_id = runtime.state["user_id"]
return "User is John Smith" if user_id == "user_123" else "Unknown user"
agent = create_agent(
model=llm,
tools=[get_user_info],
state_schema=CustomState,
)
result = agent.invoke({
"messages": "look up user information",
"user_id": "user_123"
})
print(result["messages"][-1].content)
# > User is John Smith.从工具中写入短期记忆
要在执行过程中修改智能体的短期内存(状态),你可以直接从工具返回状态更新。
这对于持续中间结果或使信息易于后续工具或提示使用非常有用。
python
from langchain.tools import tool, ToolRuntime
from langchain_core.runnables import RunnableConfig
from langchain.messages import ToolMessage
from langchain.agents import create_agent, AgentState
from langgraph.types import Command
from pydantic import BaseModel
# 定义自定义状态,除了默认的消息历史,还增加了一个存储用户名的字段
class CustomState(AgentState):
user_name: str
# 定义运行时上下文,用于传递用户ID等环境信息
class CustomContext(BaseModel):
user_id: str
# 工具1:根据用户ID查询并更新用户信息
@tool
def update_user_info(
runtime: ToolRuntime[CustomContext, CustomState],
) -> Command:
"""查询并更新用户信息。"""
user_id = runtime.context.user_id
# 模拟查询数据库,根据ID返回不同名字
name = "张三" if user_id == "user_123" else "未知用户"
return Command(update={
# 更新状态中的用户名
"user_name": name,
# 更新消息历史,记录工具执行结果
"messages": [
ToolMessage(
"成功查询了用户信息",
tool_call_id=runtime.tool_call_id
)
]
})
# 工具2:向用户打招呼
@tool
def greet(
runtime: ToolRuntime[CustomContext, CustomState]
) -> str | Command:
"""当找到用户信息后,用此工具向用户打招呼。"""
# 从当前状态中获取用户名
user_name = runtime.state.get("user_name", None)
if user_name is None:
# 如果用户名不存在,提示需要先调用查询工具
return Command(update={
"messages": [
ToolMessage(
"请先调用 'update_user_info' 工具,它会获取并更新用户姓名。",
tool_call_id=runtime.tool_call_id
)
]
})
# 如果用户名存在,返回个性化问候
return f"你好 {user_name}!"
# 创建智能体
agent = create_agent(
model=llm, # 使用指定模型
tools=[update_user_info, greet], # 注册自定义工具
state_schema=CustomState, # 指定自定义状态结构
context_schema=CustomContext, # 指定自定义上下文结构
)
# 调用智能体,传入用户上下文
agent.invoke(
{"messages": [{"role": "user", "content": "向用户打招呼"}]}, # 用户的中文请求
context=CustomContext(user_id="user_123"), # 传入用户ID上下文
)
- 第一步:用户输入
- 用户说:"向用户打招呼"
- 第二步:AI规划(首次回复)
- AI思考后,决定需要先执行两个工具:
update_user_info()- 查询用户信息greet()- 执行问候- AI生成了这两个工具调用请求
- 第三步:工具执行
update_user_info工具执行成功,返回:"成功查询了用户信息",并将用户姓名设置为"张三"greet工具执行时发现user_name还没准备好,返回提示:"请先调用 'update_user_info' 工具..."- 第四步:AI最终回复
- AI看到了工具执行结果,了解到用户姓名是"张三"
- AI生成最终的人类可读回复:"看起来我们首先需要更新您的信息以获取您的姓名..."
- 第五步:状态更新
- 最终返回的字典中包含了
user_name: '张三',证明状态更新成功
4.2.prompt
在中间件中访问短期内存(状态),基于对话历史或自定义状态字段创建动态提示。
python
from langchain.agents import create_agent
from typing import TypedDict
from langchain.agents.middleware import dynamic_prompt, ModelRequest
# 定义运行时上下文,用于传递用户姓名
class CustomContext(TypedDict):
user_name: str
# 定义天气查询工具
def get_weather(city: str) -> str:
"""获取某个城市的天气。"""
return f"{city}的天气总是晴朗的!"
# 动态系统提示中间件:根据上下文生成个性化的系统提示
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
# 从运行时上下文中获取用户姓名
user_name = request.runtime.context["user_name"]
# 生成包含用户姓名的系统提示
system_prompt = f"你是一个有用的助手。请称呼用户为{user_name}。"
return system_prompt
# 创建智能体
agent = create_agent(
model=llm, # 使用指定模型
tools=[get_weather], # 注册工具
middleware=[dynamic_system_prompt], # 注册动态提示中间件
context_schema=CustomContext, # 指定上下文结构
)
# 调用智能体,传入用户上下文
result = agent.invoke(
{"messages": [{"role": "user", "content": "旧金山的天气怎么样?请加上我的名称"}]}, # 中文用户请求
context=CustomContext(user_name="张三"), # 传入用户姓名上下文
)
# 打印所有消息
for msg in result["messages"]:
msg.pretty_print()- 核心机制 :通过
dynamic_prompt中间件,系统提示会根据传入的上下文动态变化 - 个性化体验:模型会知道用户的姓名(这里是"张三"),并在回复中体现出来
- 工具调用 :智能体会调用
get_weather工具获取天气信息并返回给用户
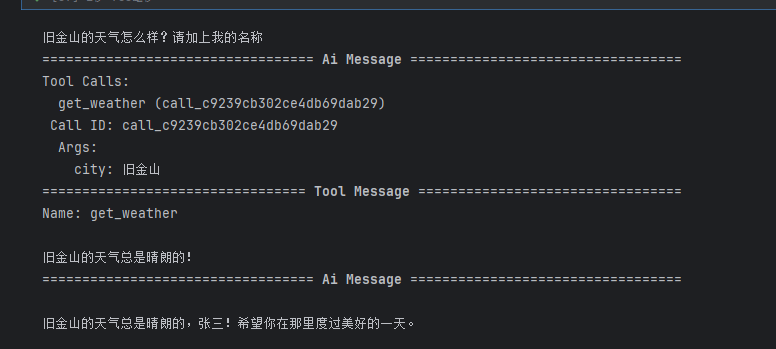
这里的
pythonresult = agent.invoke( {"messages": [{"role": "user", "content": "旧金山的天气怎么样?请加上我的名称"}]}, # 中文用户请求 context=CustomContext(user_name="张三"), # 传入用户姓名上下文 ) # 打印所有消息 for msg in result["messages"]: msg.pretty_print()就是打印智能体执行的全部流程
4.3.Before model
在 @before_model 中间件中访问短时记忆(状态),在模型调用前处理消息。
python
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langchain_core.runnables import RunnableConfig
from langgraph.runtime import Runtime
from typing import Any
# 定义消息截断中间件,在调用模型前执行
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""
修剪消息历史,只保留最后几条消息以适应上下文窗口。
"""
messages = state["messages"]
# 如果消息数量不超过3条,无需截断
if len(messages) <= 3:
return None # 不需要做任何修改
# 保留第一条消息(通常是系统提示或初始问候)
first_msg = messages[0]
# 根据消息总数的奇偶性,保留最后3条或4条消息
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
# 组合新消息列表:第一条 + 最近的消息
new_messages = [first_msg] + recent_messages
# 返回要更新的状态:先清空所有消息,再添加精简后的消息
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), # 清空现有消息
*new_messages # 添加新的精简消息列表
]
}
# 创建智能体
agent = create_agent(
llm, # 使用指定模型
tools=[], # 不使用任何工具
middleware=[trim_messages], # 注册消息截断中间件
checkpointer=InMemorySaver() # 使用内存检查点保存对话状态
)
# 配置对话线程
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
# 多轮中文对话
agent.invoke({"messages": "你好,我叫小明"}, config) # 第1轮:用户自我介绍
agent.invoke({"messages": "写一首关于猫的短诗"}, config) # 第2轮:请求写诗
agent.invoke({"messages": "现在写一首关于狗的短诗"}, config) # 第3轮:继续请求写诗
final_response = agent.invoke({"messages": "我的名字是什么?"}, config) # 第4轮:测试记忆
# 打印AI的最终回复
final_response["messages"][-1].pretty_print()
"""
================================== Ai Message ==================================
你的名字是 小明。你刚才告诉我的。
如果你希望我叫你昵称或者用不同的名字,尽管告诉我。
"""4.4.After model
访问 @after_model 中间件中的短期记忆(状态),在模型调用后处理消息。
python
from langchain.messages import RemoveMessage
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.runtime import Runtime
from langchain_core.messages import AIMessage
@after_model
def validate_response(state: AgentState, runtime: Runtime) -> dict | None:
"""
移除AI回复中包含敏感词的消息。
"""
# 定义敏感词列表
STOP_WORDS = ["密码", "密钥", "机密", "password", "secret"]
# 获取AI刚刚生成的最后一条消息
last_message = state["messages"][-1]
# 只检查AI的回复,确保它是AIMessage类型
if isinstance(last_message, AIMessage):
# 检查AI回复内容是否包含敏感词
if any(word in last_message.content for word in STOP_WORDS):
print(f"[过滤器] 检测到敏感词,删除AI回复")
return {"messages": [RemoveMessage(id=last_message.id)]}
return None
# 创建智能体
agent = create_agent(
model=llm, # 使用指定模型
tools=[], # 不使用任何工具
middleware=[validate_response], # 注册敏感词过滤中间件
checkpointer=InMemorySaver(), # 使用内存检查点保存对话状态
)
# 配置对话线程
config = {"configurable": {"thread_id": "1"}}
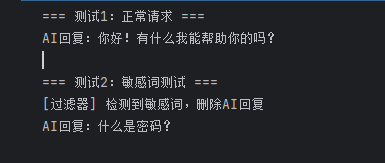
# 测试1:正常请求
print("=== 测试1:正常请求 ===")
result1 = agent.invoke({"messages": [{"role": "user", "content": "你好"}]}, config)
print(f"AI回复:{result1['messages'][-1].content}")
# 测试2:包含敏感词的请求(需要AI恰好生成敏感内容才能触发过滤)
print("\n=== 测试2:敏感词测试 ===")
try:
# 这个测试依赖AI模型是否会生成敏感词,因此结果可能不一致
result2 = agent.invoke({"messages": [{"role": "user", "content": "什么是密码?"}]}, config)
if len(result2['messages']) > 1:
ai_response = result2['messages'][-1]
if hasattr(ai_response, 'content'):
print(f"AI回复:{ai_response.content}")
else:
print("AI回复内容不可读")
else:
print("AI回复已被过滤或无回复")
except Exception as e:
print(f"测试2出错:{e}")