AI辅助的困境与突破
大语言模型(LLM)正在重塑软件开发的方式。然而,当我们真正将LLM应用于实际开发场景时,一些根本性的问题开始浮现。
第一个痛点是上下文管理的困境。每一次与LLM的对话都像是与一位失忆的专家交流------无论昨天讨论得多么深入,今天又要从头解释你的项目结构、编码规范、技术栈偏好。Token是稀缺资源,而重复的上下文注入不仅浪费了这些资源,更打断了开发者的心流状态。
第二个痛点是领域知识的缺失。通用LLM对特定领域的理解往往停留在表面。它可能知道PDF是什么,却不知道你们公司处理PDF表单的特定工作流程;它理解Git的基本概念,却不了解你团队的commit message规范。这种"知其然而不知其所以然"的状态,限制了LLM在专业场景中的应用深度。
传统的解决方案各有局限:System Prompt体量有限且难以复用;RAG系统需要复杂的向量数据库基础设施;自定义Plugin开发成本高昂。开发者需要的是一种轻量级、可组合、易于维护的知识封装方式。
这正是Agent Skills诞生的背景。Anthropic将其定义为:有组织的文件夹,包含指令、脚本和资源,Agent可以动态发现和加载这些内容以更好地执行特定任务。简单来说,Skill将通用Agent转化为专业Agent,就像为新员工准备入职指南一样,为AI助手注入领域专业知识。
Skill核心概念与架构设计
Skill的本质:可插拔的专业知识模块
如果用一句话概括Skill的本质,那就是:以文件系统为载体的、可组合的专业知识封装。
与其将Skill理解为代码意义上的"插件",不如将其视为一份结构化的"专家手册"。当你希望AI掌握某项特定能力时,你不是在编写复杂的集成代码,而是在撰写一份清晰的操作指南------只不过这份指南是写给AI阅读的。
一个Skill在物理形态上是一个目录,其中必须包含一个SKILL.md文件:
my-skill/
├── SKILL.md # 必需:包含元数据和核心指令
├── reference.md # 可选:补充参考文档
├── examples.md # 可选:使用示例
└── scripts/
└── helper.py # 可选:可执行脚本SKILL.md文件的结构遵循YAML frontmatter + Markdown内容的约定:
yaml
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
For advanced form filling, see [FORMS.md](FORMS.md).与传统Plugin/Extension的根本区别
理解Skill与传统插件系统的差异,是把握其设计哲学的关键:
| 维度 | 传统Plugin | Agent Skills |
|---|---|---|
| 载体 | 代码(API接口实现) | 文本(Markdown文档) |
| 加载方式 | 编译时/启动时全量加载 | 运行时按需加载 |
| 扩展能力 | 新增功能接口 | 注入领域知识与工作流 |
| 开发门槛 | 需要了解插件API | 只需会写Markdown |
| 组合性 | 依赖显式依赖声明 | 自然语言描述即可组合 |
| 版本管理 | 需要包管理器 | Git即可 |
传统Plugin本质上是能力扩展 ------让系统能做原本做不到的事情。而Skill则是知识注入------让系统知道如何更好地完成它本已能做的事情。
这种差异决定了Skill的应用场景:当你需要Claude学会使用一个新的外部API时,你需要的是MCP(Model Context Protocol);当你需要Claude按照你团队的规范来生成代码时,你需要的是Skill。
技术架构:Markdown格式的知识封装
选择Markdown作为知识载体并非偶然。这一选择体现了几个设计考量:
- 人机可读性:Markdown对人类友好,便于编写和维护;同时LLM对Markdown有极好的理解能力
- 结构化与灵活性的平衡:YAML frontmatter提供必要的结构化元数据,Markdown正文则允许自由形式的知识表达
- 生态兼容性:与现有的文档工具、版本控制系统无缝集成
- 渐进式复杂度:从简单的单文件Skill到复杂的多文件Skill,Markdown都能良好支持
Skill解决的核心问题
上下文窗口的有效利用:按需加载 vs 全量注入
上下文窗口是LLM最宝贵的资源。传统方法面临一个两难选择:要么在System Prompt中注入大量上下文(浪费token且可能超出限制),要么每次对话重新提供(体验糟糕且依赖用户记忆)。
Skill通过 渐进式披露(Progressive Disclosure) 机制解决了这一问题:

这种分层加载策略意味着:
- 安装100个Skill,启动时可能只消耗10K tokens的元数据
- 实际执行任务时,只有相关Skill的核心指令被加载
- 复杂任务所需的扩展文档和脚本按需读取
领域专业知识的模块化管理
Skill将知识封装为独立、可组合的模块。每个Skill专注解决一类问题:
~/.claude/skills/
├── code-review/ # 代码审查规范
├── commit-message/ # Git提交信息规范
├── api-documentation/ # API文档生成规范
├── unit-testing/ # 单元测试最佳实践
└── security-audit/ # 安全审计检查清单这种模块化带来的好处是显而易见的:
- 独立演进:每个Skill可以独立更新,不影响其他Skill
- 按需组合:复杂任务可以自动调用多个相关Skill
- 团队协作:不同团队成员可以贡献和维护不同领域的Skill
- 知识积累:组织的最佳实践以Skill形式沉淀和传承
工作流的标准化与可复用性
Skill不仅是静态知识的容器,更是工作流程的编纂。以一个真实的PDF处理Skill为例:
markdown
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
---
# PDF Processing
## Workflow: Extract and Analyze
1. Use `pdfplumber` to extract raw text
2. Identify table structures using layout analysis
3. Convert tables to pandas DataFrames for analysis
4. Handle multi-page documents with page-by-page processing
## Workflow: Form Filling
For form operations, see [FORMS.md](FORMS.md) which covers:
- Reading existing form fields
- Validating input data
- Filling and saving forms
## Common Patterns
### Error Handling
Always wrap PDF operations in try-except blocks...
### Performance Tips
For large PDFs (>100 pages), use streaming mode...这种工作流编纂意味着:
- 新团队成员可以快速上手复杂任务
- 最佳实践被显式记录而非口口相传
- Claude的行为在同类任务上保持一致性
实际案例分析:文档处理技能
Anthropic提供的预置Skill是理解Skill设计理念的最佳案例。以xlsx Skill为例,它展示了一个成熟Skill的完整形态:
元数据设计:
yaml
name: xlsx
description: Comprehensive spreadsheet creation, editing, and analysis with support for formulas, formatting, data analysis, and visualization. When Claude
needs to work with spreadsheets (.xlsx, .xlsm, .csv, .tsv, etc) for:
(1) Creating new spreadsheets with formulas and formatting,
(2) Reading or analyzing data,
(3) Modify existing spreadsheets while preserving formulas...注意description的设计------它不仅说明了"做什么",更明确列出了"何时使用"的触发条件。这是让Claude能够自动匹配Skill的关键。
分层内容组织:
- Level 1:元数据提供发现信息
- Level 2:SKILL.md包含核心用法和常见模式
- Level 3:reference.md提供API详细参考,只在需要高级操作时加载
代码与指令的协作:
markdown
## Creating Charts
For data visualization, use the bundled charting utilities:
python
from openpyxl.chart import BarChart, Reference
# Chart creation code...
See scripts/chart_helper.py for ready-to-use chart templates.这种设计让指令与代码各司其职:指令提供方向和上下文,代码提供确定性的执行能力。
Skill实践指南
创建自定义Skill的最佳实践
创建一个高质量的Skill需要遵循几个原则:
1. 保持聚焦
一个Skill应该解决一类明确的问题。避免创建"瑞士军刀"式的万能Skill:
markdown
# 不推荐:过于宽泛
---
name: document-tools
description: Handle all document operations
---
# 推荐:聚焦明确
---
name: pdf-form-filler
description: Fill PDF forms with structured data. Use when user needs to populate PDF forms, handle form validation, or batch-fill multiple forms.
## Instructions
1. First, check if the PDF is encrypted using `pypdf`
2. If encrypted, ask user for password before proceeding
3. For text extraction, prefer `pdfplumber` over `pypdf` for better accuracy
4. Always validate extracted data against expected schema
## Common Mistakes to Avoid
- Don't use `PyPDF2` (deprecated, use `pypdf` instead)
- Don't load entire PDF into memory for large files
- Don't ignore PDF metadata, it often contains useful context4. 迭代式开发
最佳实践是在实际使用中逐步完善Skill:
bash
# 观察Claude如何使用Skill
claude --debug
# 让Claude帮助改进Skill
"Based on how you just handled that task, what additional instructions
would help you do it better next time?"Skill的组织结构与命名规范
目录结构:
skill-name/
├── SKILL.md # 必需:核心文件
├── REFERENCE.md # 可选:详细参考
├── EXAMPLES.md # 可选:使用示例
├── CHANGELOG.md # 可选:版本历史
├── scripts/ # 可选:可执行脚本
│ ├── __init__.py
│ ├── helper.py
│ └── validator.py
├── templates/ # 可选:模板文件
│ └── report.md
└── resources/ # 可选:静态资源
└── schema.json命名规范:
name字段:小写字母、数字、连字符(最多64字符)- 目录名:与name保持一致
- 避免使用保留词:
anthropic、claude
yaml
# 合规命名
name: pdf-form-filler
name: my-company-code-review
name: data-analysis-v2
# 不合规命名
name: PDF_Form_Filler # 包含大写和下划线
name: claude-helper # 使用保留词
name: a # 过于简短,缺乏描述性Personal vs Project vs Plugin Skills的使用场景
根据Skill的存储位置,存在三种类型的Skill,各有其适用场景:
Personal Skills(个人Skill)
- 位置:
~/.claude/skills/ - 范围:仅当前用户可用
- 场景:个人工作流偏好、实验性Skill开发
bash
# 创建个人Skill
mkdir -p ~/.claude/skills/my-workflow
cat > ~/.claude/skills/my-workflow/SKILL.md << 'EOF'
---
name: my-workflow
description: My personal coding preferences and patterns
---
...
EOFProject Skills(项目Skill)
- 位置:
.claude/skills/(项目根目录) - 范围:项目团队成员共享
- 场景:团队规范、项目特定工作流
bash
# 创建项目Skill并提交到版本控制
mkdir -p .claude/skills/team-conventions
# ... 创建SKILL.md
git add .claude/skills/
git commit -m "Add team coding conventions skill"Plugin Skills(插件Skill)
- 来源:通过Claude Code Plugin安装
- 范围:安装该插件的所有用户
- 场景:通用工具Skill的分发
bash
# 从Anthropic官方marketplace安装
/plugin install document-skills@anthropic-agent-skills选择建议:
| 场景 | 推荐类型 |
|---|---|
| 个人编码习惯 | Personal |
| 团队代码规范 | Project |
| 通用工具能力 | Plugin |
| 公司内部工作流 | Project + 内部Plugin分发 |
Claude Code中的Skill应用
在Claude Code环境中,Skill的使用是自动化的:
bash
# 查看可用Skill
claude> What Skills are available?
# 隐式触发Skill(Claude自动匹配)
claude> Help me extract data from this PDF form
# 显式请求使用特定Skill
claude> Use the PDF skill to extract form fields from contract.pdf调试模式:
bash
# 查看Skill加载和触发详情
claude --debug工具权限限制:
Skill可以通过allowed-tools限制Claude可用的工具:
yaml
---
name: safe-file-reader
description: Read files without making changes.
allowed-tools: Read, Grep, Glob
---当此Skill激活时,Claude只能使用指定的工具,适用于需要只读访问或受限操作的场景。
技术对比与生态定位
理解Skill在AI工具生态中的位置,需要将其与相关技术进行对比:
vs GPTs/Custom Instructions:知识封装层面
| 维度 | GPTs/Custom Instructions | Agent Skills |
|---|---|---|
| 知识容量 | 受限于System Prompt长度 | 通过渐进式披露理论上无限 |
| 组合性 | 单一GPT/Instruction | 多Skill自动组合 |
| 版本管理 | 平台内管理 | Git原生支持 |
| 分发方式 | 平台商店 | 文件系统/Git/Plugin |
| 可执行代码 | 不支持 | 支持脚本执行 |
GPTs适合面向终端用户的固定场景应用;Skills适合开发者和团队的工作流定制。
vs Function Calling/Tools:能力扩展层面
| 维度 | Function Calling/Tools | Agent Skills |
|---|---|---|
| 本质 | 能力扩展(做新的事) | 知识注入(更好地做已有的事) |
| 实现 | 代码定义函数签名和实现 | Markdown描述工作流 |
| 运行时 | LLM决定调用,外部执行 | LLM读取知识,内部执行 |
| 开发成本 | 需要后端开发 | 仅需文档编写 |
当你需要Claude调用外部API时,使用Tools/MCP;当你需要Claude按照特定方式完成任务时,使用Skills。
vs RAG:知识检索层面
| 维度 | RAG | Agent Skills |
|---|---|---|
| 知识类型 | 事实性知识(What) | 程序性知识(How) |
| 检索方式 | 向量相似度 | 语义描述匹配 |
| 基础设施 | 向量数据库 | 文件系统 |
| 知识粒度 | 文档片段 | 完整工作流 |
| 适用场景 | 问答、知识库查询 | 任务执行、流程自动化 |
RAG解决"Claude不知道的事实",Skills解决"Claude不知道的做法"。
vs Prompt Engineering:使用复杂度层面
| 维度 | Prompt Engineering | Agent Skills |
|---|---|---|
| 复用性 | 需要每次重写或复制粘贴 | 一次创建,自动应用 |
| 维护性 | 分散在各处 | 集中管理 |
| 一致性 | 依赖编写者记忆 | 自动保持一致 |
| 协作性 | 难以共享和版本控制 | Git原生支持 |
Prompt Engineering是即兴演奏,Skills是编写乐谱。
适用场景
| 事实性知识 | 程序性知识 | |
|---|---|---|
| 一次性/简单任务 | RAG | Prompt Engineering |
| 重复性/复杂任务 | RAG + Skills | Skills |
| 需要外部能力 | MCP/Tools | MCP/Tools + Skills |
实现原理与技术细节
Skill的加载时机与触发机制
理解Skill的运行时行为,需要跟踪其在整个请求生命周期中的状态变化:
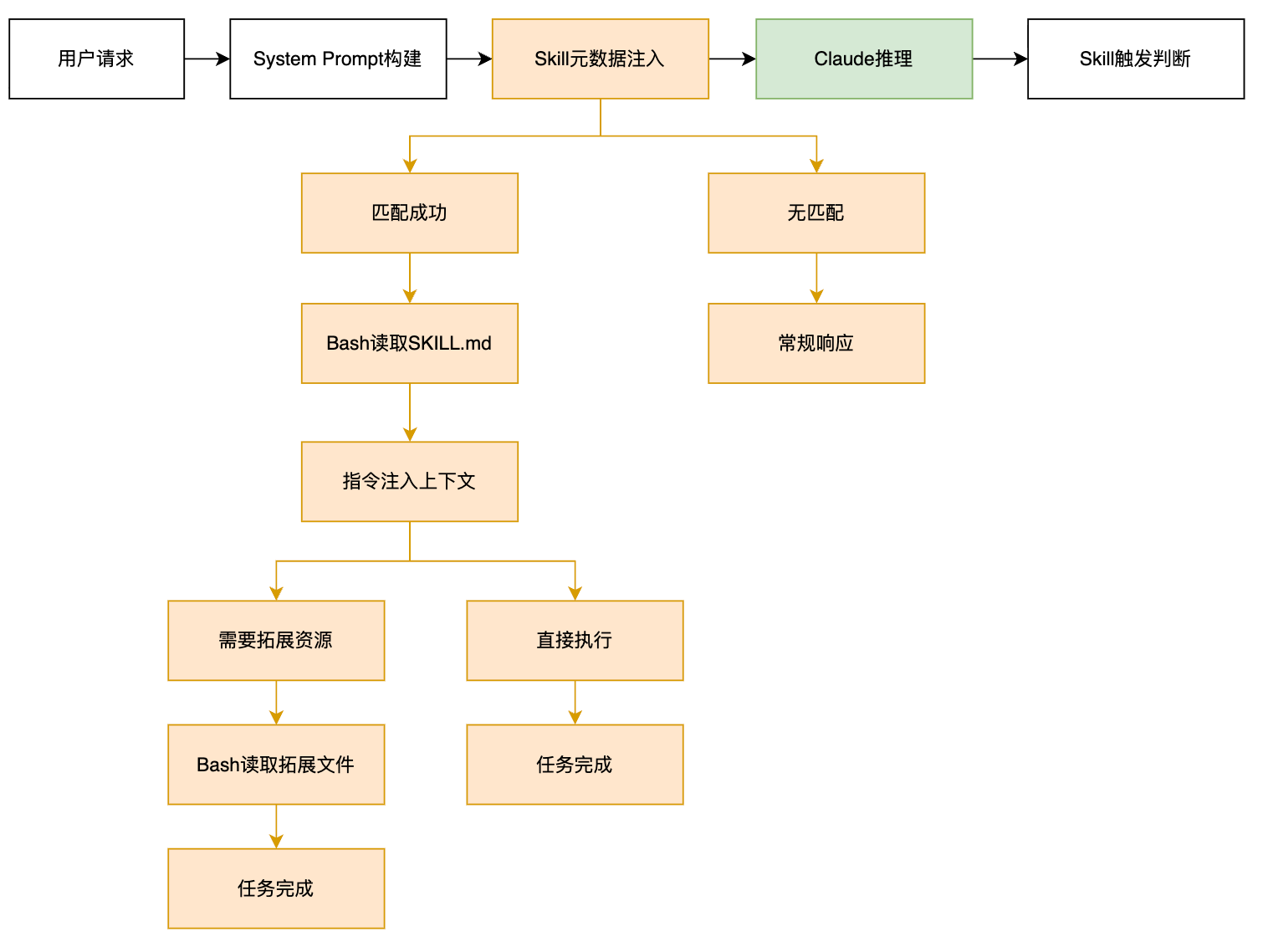
启动阶段:
- 系统收集所有可用Skill的元数据(name + description)
- 元数据被注入System Prompt
- 每个Skill仅消耗约100 tokens
触发阶段:
- Claude分析用户请求
- 基于description进行语义匹配
- 决定是否需要加载某个Skill
加载阶段:
- Claude通过Bash工具执行文件读取
- SKILL.md内容进入上下文窗口
- 根据需要继续加载扩展文件
上下文注入策略:Bash工具读取文件
在Claude Code环境中,Skill内容通过Bash命令加载。根据Anthropic官方文档:
python
# 基于官方文档的概念性伪代码
def trigger_skill(skill_path):
# Step 1: 读取核心SKILL.md
skill_content = bash(f"cat {skill_path}/SKILL.md")
context_window.append(skill_content)
# Step 2: 解析引用,按需加载
references = parse_references(skill_content)
for ref in references:
if needs_loading(ref, current_task):
ref_content = bash(f"cat {skill_path}/{ref}")
context_window.append(ref_content)
# Step 3: 执行脚本(不加载代码到上下文)
if needs_script_execution(current_task):
result = bash(f"python {skill_path}/scripts/helper.py {args}")
# 仅result进入上下文,script代码不进入这种设计的关键是:代码执行与代码阅读是不同的上下文需求。
Token预算管理
Skill的Token消耗遵循以下模型:
| 级别 | 加载时机 | 典型消耗 | 管理策略 |
|---|---|---|---|
| L1 元数据 | 始终 | ~100/Skill | 控制Skill数量 |
| L2 核心指令 | 触发时 | <5K | 保持SKILL.md精简 |
| L3 扩展资源 | 按需 | 无上限 | 合理分割文件 |
优化建议:
- 元数据层:description要精确但简洁,避免冗余
- 核心指令层:只保留最常用的指令,高级内容移至扩展文件
- 扩展资源层:利用文件分割实现细粒度加载
markdown
# 优化前:单个大文件
SKILL.md (8000 tokens)
├── Quick Start
├── Basic Usage
├── Advanced Usage
├── API Reference
├── Error Handling
└── Examples
# 优化后:分层文件
SKILL.md (2000 tokens)
├── Quick Start
└── Basic Usage
ADVANCED.md (2500 tokens)
├── Advanced Usage
└── Error Handling
REFERENCE.md (3500 tokens)
├── API Reference
└── Examples多Skill协同工作原理
当一个任务涉及多个Skill时,Claude会按需组合使用:
用户请求: "从这个PDF提取数据并生成Excel报表"
Claude推理过程:
1. 分析任务需求
2. 识别需要 pdf-processing skill (提取数据)
3. 识别需要 xlsx skill (生成报表)
4. 顺序加载并执行
上下文变化:
[System Prompt + PDF skill metadata + XLSX skill metadata]
↓ 触发PDF skill
[+ PDF SKILL.md内容]
↓ 完成PDF处理
[+ XLSX SKILL.md内容]
↓ 完成Excel生成
[最终响应]Skill的组合是隐式的------Claude基于任务需求自动判断需要哪些Skill,无需显式声明依赖关系。
架构启示
从Skill设计看AI系统的模块化思想
Skill的设计体现了AI系统架构的几个重要原则:
1. 关注点分离
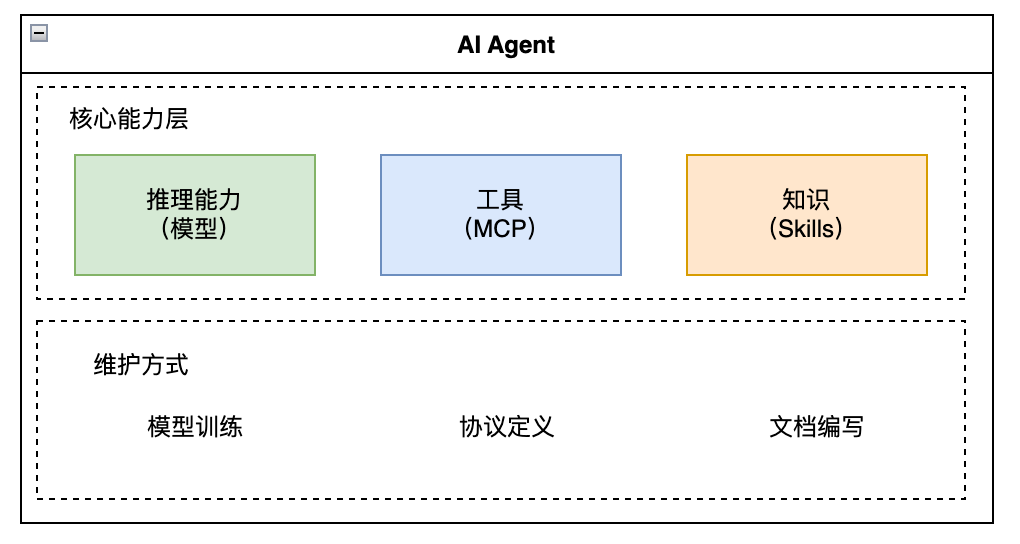
这种分离使得:
- 模型可以独立升级而不影响业务知识
- 工具能力可以独立扩展而不修改知识定义
- 领域知识可以独立维护而不依赖技术团队
2. 渐进式复杂度
Skill支持从简单到复杂的平滑过渡:
- 最简形式:单个SKILL.md文件
- 中等复杂度:添加扩展文档
- 高复杂度:包含脚本、模板、资源
这种设计降低了入门门槛,同时不限制高级用例的表达能力。
3. 可组合性优于整体性
多个小而专注的Skill优于一个大而全的Skill:
- 更容易测试和调试
- 更容易维护和演进
- 更灵活的组合方式
知识与能力分离的架构理念
Skill设计的一个深刻洞察是:程序性知识(How)和执行能力(What)应该分离管理 。
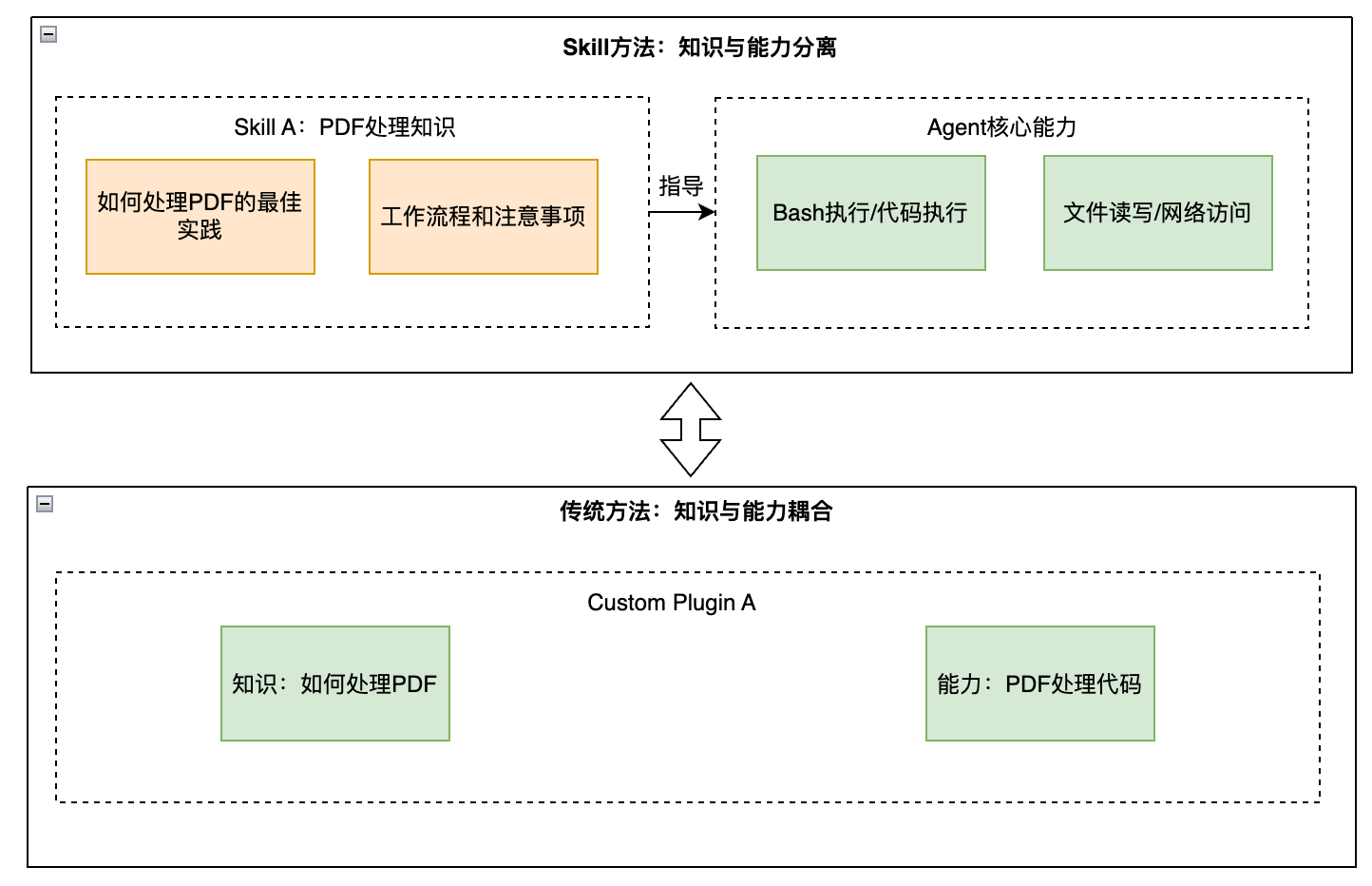
这种分离带来的好处:
- 知识可以快速迭代而不需要重新部署
- 同样的知识可以应用于不同的执行环境
- 执行能力的提升自动惠及所有相关知识
对企业级AI应用架构的启发
Skill的设计模式对企业级AI应用有重要启发:
1. 知识资产化
组织的隐性知识可以通过Skill显性化:
- 编码规范 → Code Review Skill
- 运维手册 → Operations Skill
- 业务流程 → Business Process Skills
2. 渐进式AI采用
Skill提供了一条低风险的AI采用路径:
阶段1: 创建只读Skill(信息查询)
↓
阶段2: 添加辅助脚本(半自动化)
↓
阶段3: 完整工作流Skill(全自动化)3. 知识治理
通过Skill的版本控制和权限管理:
- 审计知识变更历史
- 控制敏感知识访问
- 标准化知识分发
结语
Agent Skills代表了AI系统架构设计的一种新思路:通过将领域知识封装为可组合、可发现、渐进式加载的模块,让通用Agent能够快速转化为专业Agent。
对于开发者而言,Skill提供了一种低门槛、高收益的方式来定制和扩展AI能力。你不需要深入理解模型内部机制,只需要把你的专业知识以Markdown形式编纂出来。
对于架构师而言,Skill展示了一种优雅的关注点分离模式------将知识、能力、推理清晰解耦,为构建可维护、可演进的AI系统提供了参考。
最后,Skill的成功验证了一个朴素的观点:在AI时代,最有价值的资产不是数据本身,而是将数据转化为行动的程序性知识。那些能够系统化编纂和管理这类知识的组织,将在AI赋能的竞争中占据优势。