
内容提要
本文分为三大部分,一是对原论文的一些笔记;二是I-JEPA代码的一些记录;三是最后的一点总结;
论文内容
Intro:
1.图像自监督学习分为invariance- based 方法以及 generative methods;
Invariance-based 方法优化encoder 使其为同一张图的多视角图像编码成相似embedding,这种方法可以产生high semantic level的表征,但是可能会对下游任务产生不良的影响;因为对于不同任务,需要的语意层级是不一样的,比如图像分类和instance segmentation;
生成室方法如MAE或BERT,通过遮住一部分,去预测另一部分;其合理之处在于生物系统中一个驱动机制是,人类的大脑也在做预测,比如听到半句话来猜后面的话,看到半个物体猜整个物体等等;
Invariance-based VS generative :
生成方法通常对数据要求 更低,但是往往效果不如invariance- based 方法;
2.本文的目的是怎么通过自监督方法提升语意级别的表征;并且没有任何的图像变换;
3.动机是预测缺失信息,但是在一个抽象表征的空间;相比较于生成式方法,JEPA利用抽象预测目标,因此可以避免模型过度关注到图像细节,而是真正学习语意表征;
4.一个核心设计是 multi-block masking strategy;
5.几点结论:
I-JEPA 学习到的是一种很强大的表征,要超越MAE;
I-JEPA 在semantic tasks 上和view-invariant pretraining 方法具有竞争力,在low-level task上 如目标计数和深度估计则更强;
I-JEPA 是一种scalable and efficient architecture; 训练速度比MAE快10X;
related works
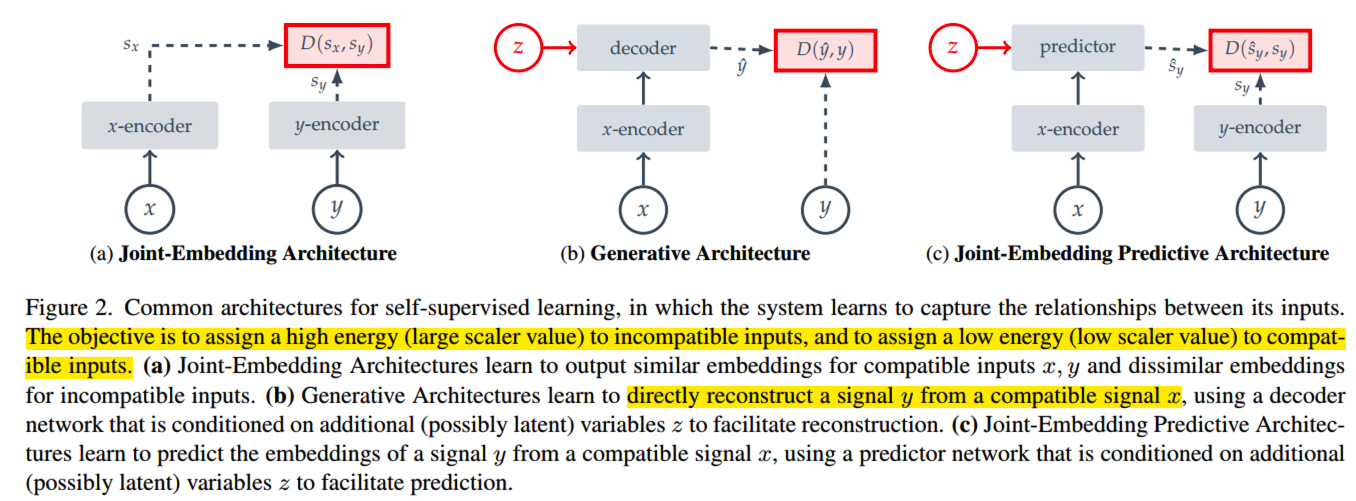
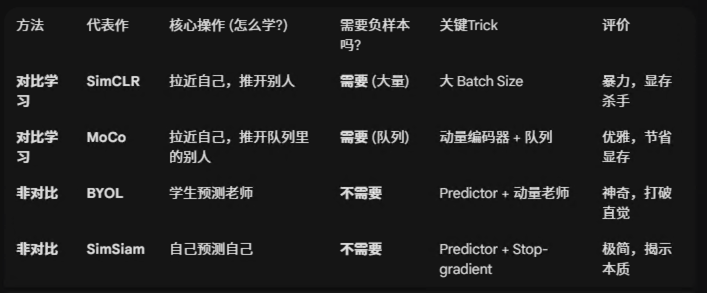
1.Joint-Embedding Architecture 对于compatible inputs 输出相似的embedding,对于incompatible inputs 输出dissimilar embedding,这种dissimilar 被称为 高能量状态,Energy- based model: EBMs; 这里的compatible 在图像中是指随机施加图像增强方法得到的样本;JEA 面临的问题是representation collapse:编码器不管输入什么都输出constant content;过去解决representation collapse 的方法有对比学习,最小化信息redundancy,以及聚类的方法来最大化average- based embedding 的 entropy;以及启发式的方法,对x-encoder和y-encoder采用非对称结构;
2.Reconstruction-based
CV领域比较常见的做法是,作为y的一个copy版本,并且mask掉一些区域作为x; 而conditioning variable Z 对应的是MASK or position tokens; 用于指定需要重建哪部分.为避免表征坍塌,representation collapse, 需要保证z的信息量要少于y;
3.JEPA:
与基于重建的方法类似,这里最重要的一个区别是loss在 latent space进行处理; 并且采用非对称的x-encoder和y-encoder避免导致representation collapse;
Method
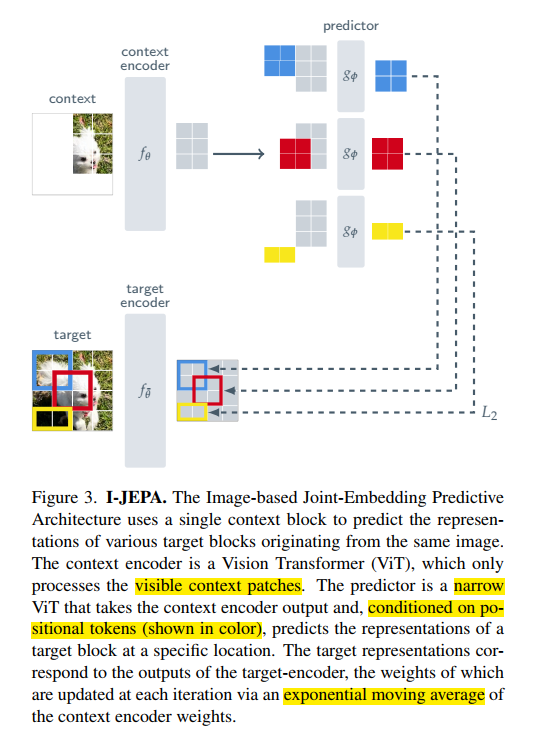
x-encoder和y-encoder以及predictor 都采用vit, predictor是一个narrow ViT; context-encoder 将可见部分作为输入, predictor 输入是 x-encoder输出的embedding以及conditioning variable z,这里是postion; x-encoder和y-encoder采用EMA进行更新;
Targets
targets是图像块的表征;
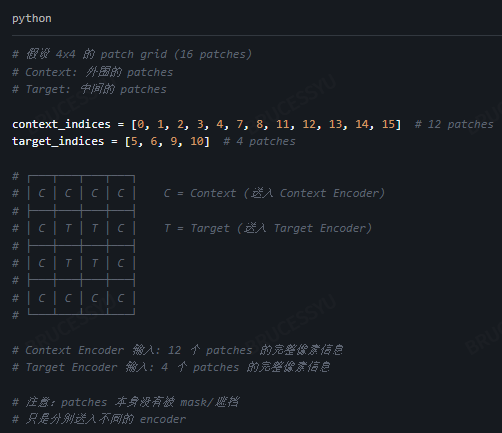
首先切分成non-overlapping的图像块 image patches,然后送入target-encoder获得对应的patch-level的表示,Syk, k表示第k块; Sy = {Sy1, Sy2, Sy3,...,Syn}
然后随机选择M个Blocks组成targets;通常这里设置M=4;
这里用Bi对应第i个Block,并且采样长宽比为(0.75,1.5),占有图像整个面积的比例为(0.15,0.2);
关键点在于这里是对target-encoder的embedding做mask操作,而非原本的输入;
Context
在图像中采样一个context Block Sx,这个块占图像的(0.85,1);
并且设置为正方形;
由于targets 和 context 是独立采样的,因此需要将重叠部分去除;然后送入context-encoder进行编码;

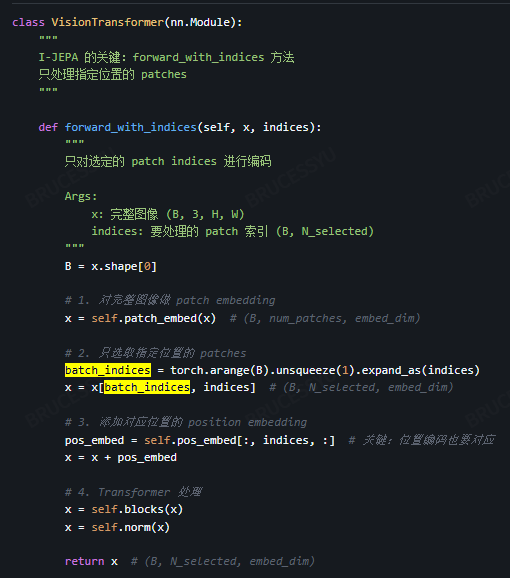
Predictor :
预测头的输入是Sx,以及M个targets对应的 learnable vector, 和位置编码;
一个共享的可学习向量加上附加的位置嵌入
Loss
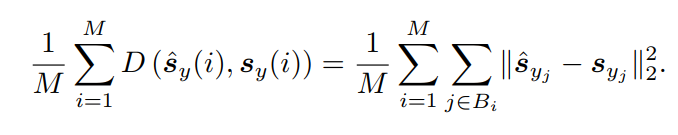
Details
关于EMA的实现:

采用混合精度训练的情况下,EMA模型也是在FP32下进行的;

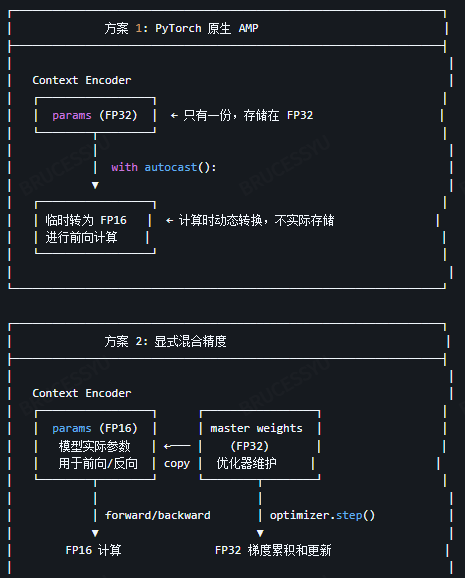
因此无论采用torch原生AMP还是DeepSpeed/FSDP, target encoder都是从context-encoder的FP32中直接更新;

更新越来越慢,保证后期训练的稳定性;

Related works
data2vec: target-encoder online;
Context Autoencoders: 采用对齐约束和上下文重建;
与这些相比,JEPA 具有更高的计算效率,并且语义更好;
Classification
1.efficiency
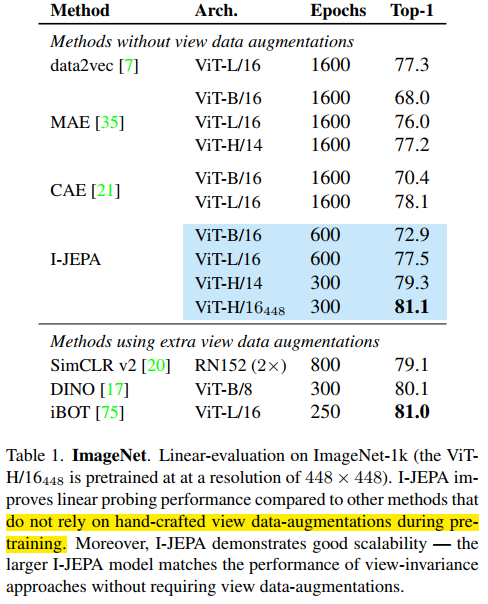
训练的收敛速度更快一些;
2.low-shot, 每一类只用12/13张图;
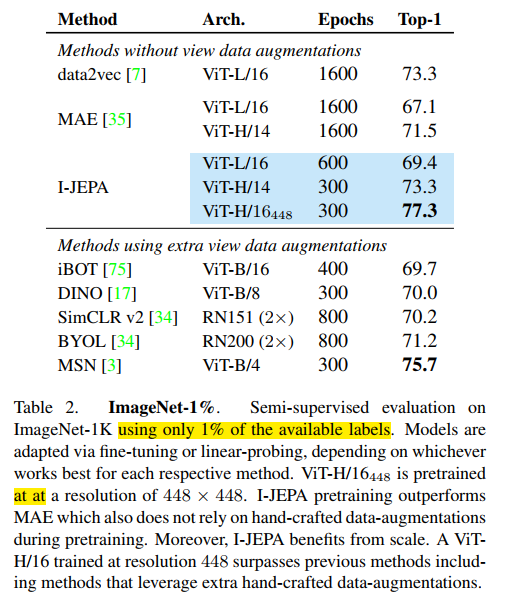
这里省略后续的一些实验
代码
python
import torch
import math
import random
from typing import Tuple, List
class MultiBlockMaskCollator:
"""
I-JEPA 的 multi-block masking 策略
适配任意尺寸的 patch grid
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
num_targets: int = 4,
target_aspect_ratio: Tuple[float, float] = (0.75, 1.5),
target_scale: Tuple[float, float] = (0.15, 0.2),
context_aspect_ratio: Tuple[float, float] = (1.0, 1.0),
context_scale: Tuple[float, float] = (0.85, 1.0),
min_context_patches: int = 10, # 最少保留的context patches
):
self.img_size = img_size
self.patch_size = patch_size
self.num_patches_side = img_size // patch_size
self.num_patches = self.num_patches_side ** 2
self.num_targets = num_targets
self.target_aspect_ratio = target_aspect_ratio
self.target_scale = target_scale
self.context_aspect_ratio = context_aspect_ratio
self.context_scale = context_scale
self.min_context_patches = min_context_patches
print(f"Masking配置: {self.num_patches_side}x{self.num_patches_side} patches, "
f"共 {self.num_patches} patches")
def _sample_block_size(self, scale, aspect_ratio):
"""采样 block 的大小"""
num_patches = self.num_patches
min_s, max_s = scale
target_area = random.uniform(min_s, max_s) * num_patches
min_ar, max_ar = aspect_ratio
ar = random.uniform(min_ar, max_ar)
h = int(round(math.sqrt(target_area / ar)))
w = int(round(math.sqrt(target_area * ar)))
h = min(max(h, 1), self.num_patches_side)
w = min(max(w, 1), self.num_patches_side)
return h, w
def _sample_block_position(self, h, w):
"""采样 block 的位置"""
top = random.randint(0, self.num_patches_side - h)
left = random.randint(0, self.num_patches_side - w)
return top, left
def _get_block_indices(self, top, left, h, w):
"""获取 block 内所有 patch 的 indices"""
indices = []
for i in range(top, top + h):
for j in range(left, left + w):
idx = i * self.num_patches_side + j
indices.append(idx)
return indices
def sample_masks(self):
"""
为单个样本采样 context 和 target masks
Returns:
context_indices: list of context patch indices
target_indices: list of target patch indices
"""
all_target_indices = set()
# 采样多个 target blocks
for _ in range(self.num_targets):
h, w = self._sample_block_size(self.target_scale, self.target_aspect_ratio)
top, left = self._sample_block_position(h, w)
indices = self._get_block_indices(top, left, h, w)
all_target_indices.update(indices)
# 确保有足够的 context patches
all_indices = set(range(self.num_patches))
context_indices = list(all_indices - all_target_indices)
# 如果 context 太少,减少 target
while len(context_indices) < self.min_context_patches and len(all_target_indices) > 1:
# 随机移除一些 target
remove_idx = random.choice(list(all_target_indices))
all_target_indices.remove(remove_idx)
context_indices.append(remove_idx)
target_indices = list(all_target_indices)
context_indices.sort()
target_indices.sort()
return context_indices, target_indices
def __call__(self, batch):
"""
Args:
batch: list of (image, label) tuples
Returns:
dict with images, context_indices, target_indices, masks
"""
B = len(batch)
# Stack images
images = torch.stack([item[0] for item in batch], dim=0)
batch_context_indices = []
batch_target_indices = []
for _ in range(B):
context_indices, target_indices = self.sample_masks()
batch_context_indices.append(context_indices)
batch_target_indices.append(target_indices)
# 填充到相同长度
max_context = max(len(c) for c in batch_context_indices)
max_target = max(len(t) for t in batch_target_indices)
padded_context = []
padded_target = []
context_masks = []
target_masks = []
for ctx, tgt in zip(batch_context_indices, batch_target_indices):
# Context padding
pad_len = max_context - len(ctx)
padded_ctx = ctx + [0] * pad_len
ctx_mask = [True] * len(ctx) + [False] * pad_len
padded_context.append(padded_ctx)
context_masks.append(ctx_mask)
# Target padding
pad_len = max_target - len(tgt)
padded_tgt = tgt + [0] * pad_len
tgt_mask = [True] * len(tgt) + [False] * pad_len
padded_target.append(padded_tgt)
target_masks.append(tgt_mask)
return {
'images': images,
'context_indices': torch.tensor(padded_context, dtype=torch.long),
'target_indices': torch.tensor(padded_target, dtype=torch.long),
'context_masks': torch.tensor(context_masks, dtype=torch.bool),
'target_masks': torch.tensor(target_masks, dtype=torch.bool),
}
def create_collate_fn(config):
"""创建数据 collate 函数"""
masker = MultiBlockMaskCollator(
img_size=config.image_size,
patch_size=config.patch_size,
num_targets=config.num_targets,
target_aspect_ratio=config.target_aspect_ratio,
target_scale=config.target_scale,
context_aspect_ratio=config.context_aspect_ratio,
context_scale=config.context_scale,
)
return masker以上是关键的mask部分的实现,未来有时间会把简化版本上传到GitHub;
写在最后
其实从JEPA那篇长达六七十页的论文中,可以看到lecun想描述的world model其实是一个世界模拟器,就像人类在建模世界一样,希望从一个latent space进行建模,而非直接的pixel;
这一点其实还是有道理的,因为对于生成模型而言,过度关注到一些细节,但是一只鸟羽毛排布不会影响它是一只鸟的语义,也不会影响它的动作;
因此其实现在主流的所谓的video generation world model其实跟lecun所说的world model恰恰是大相径庭的两种路线; video generation 希望建模显式的物理规律和变化趋势;而JEPA则是在一个latent space 做抽象建模;
关于推理:
LLM迭代到现在,其实不仅仅是一个词预测器的作用了,感觉是量变引起了一些质变;就像那个非常恰当的例子,如果一个悬疑小说将凶手写在最后,LLM如果具备了抽丝剥茧的能力,从长文中预测对了最终的凶手,这很难说不是一种推理能力;
但是视觉建模或者说视觉推理的路,感觉才刚开始.