浅堆深堆与支配树
浅堆和深堆
一、浅堆(Shallow Heap)
浅堆(Shallow Heap)指单个对象自身占用的内存字节数,仅包含对象本身的结构数据,不包含其引用的任何其他对象,是对象内存占用的基础度量。
二、深堆(Retained Heap)
深堆(Retained Heap)即对象保留集中所有对象的浅堆大小之和。
理解深堆需明确保留集(Retained Set)的定义,二者存在强关联:
对象A的保留集,指当对象A被垃圾回收器回收时,可被连带释放的所有对象的集合(包含对象A自身)。核心限定条件为:该集合中的对象仅能通过对象A直接或间接访问,无其他非A路径的外部引用(即这些对象被A"独占")。若某对象同时被A及其他对象引用,则该对象不属于A的保留集------即使A被回收,其仍会被其他引用持有,无法被连带释放。
三、对象的实际大小(Actual Size)
对象的实际大小,定义为该对象所能直接或间接触及(访问)的所有对象的浅堆大小之和,涵盖了对象自身及所有引用链可达的对象,不区分这些对象是否被其他对象共享。
该概念更符合日常开发中对"对象大小"的直观认知,它仅描述对象引用覆盖的内存范围,而非对象被回收时实际能释放的内存量。例如,若对象A和B共享对象C,C的浅堆大小会同时计入A和B的实际大小,但不会计入二者中任何一个的深堆(因C并非被单一对象独占)。
代码案例:
创建学生类
java
public class Student {
private int id;
private String name;
private List<WebPage> history = new Vector<WebPage>();
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
//省略setter和getter方法
}
public void visit(WebPage webPage){
history.add(webPage);
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<WebPage> getHistory() {
return history;
}
public void setHistory(List<WebPage> history) {
this.history = history;
}
}创建WebPage类
java
public class WebPage {
private String url;
private String content;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}创建TraceStudent类
java
public class TraceStudent {
static List<WebPage> webpages = new Vector<WebPage>();
public static void createWebPages() {
for (int i = 0; i < 100; i++) {
WebPage wp = new WebPage();
wp.setUrl("http:/ /www." + Integer.toString(i) + ".com");
wp.setContent(Integer.toString(i));
webpages.add(wp);
}
}
public static void main(String[] args) {
createWebPages();
Student st3 = new Student(3, "billy");
Student st5 = new Student(5, "alice");
Student st7 = new Student(7, "taotao");
for (int i = 0; i < webpages.size(); i++) {
if (i % st3.getId() == 0)
st3.visit(webpages.get(i));
if (i % st5.getId() == 0)
st5.visit(webpages.get(i));
if (i % st7.getId() == 0)
st7.visit(webpages.get(i));
}
webpages.clear();
System.gc();
}
}通过参数执行
-XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=D:/analyzer/data_temp/stu.hprof
可以看到,在TraceStudent类中,首先创建了100 个网址,为阅读方便,这里的网址均以数字作为域名,分别为0~99。之后,程序创建了3名学生: billy、 alice 和taotao。他们分别浏览了能被3、5、7整除的网页。在程序运行后,3名学生的history中应该保护他们各自访问过的网页。现在,希望在程序退出前,得到系统的堆信息,并加以分析,查看每个学生实际访问的网页地址。
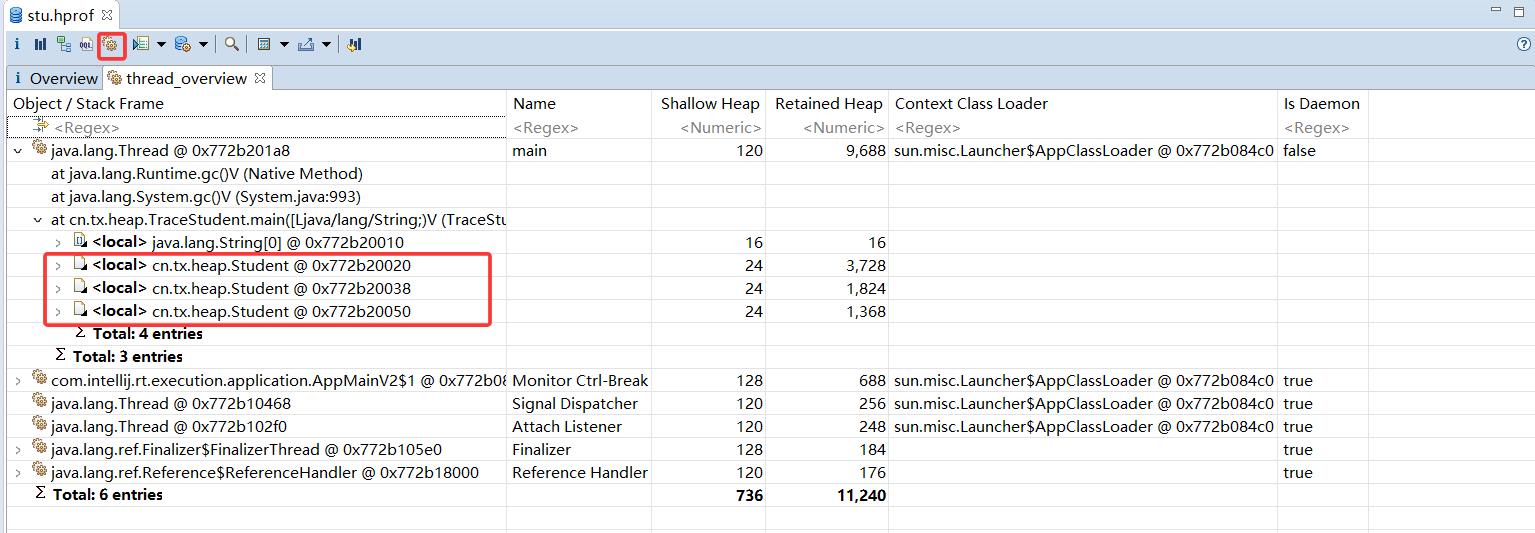
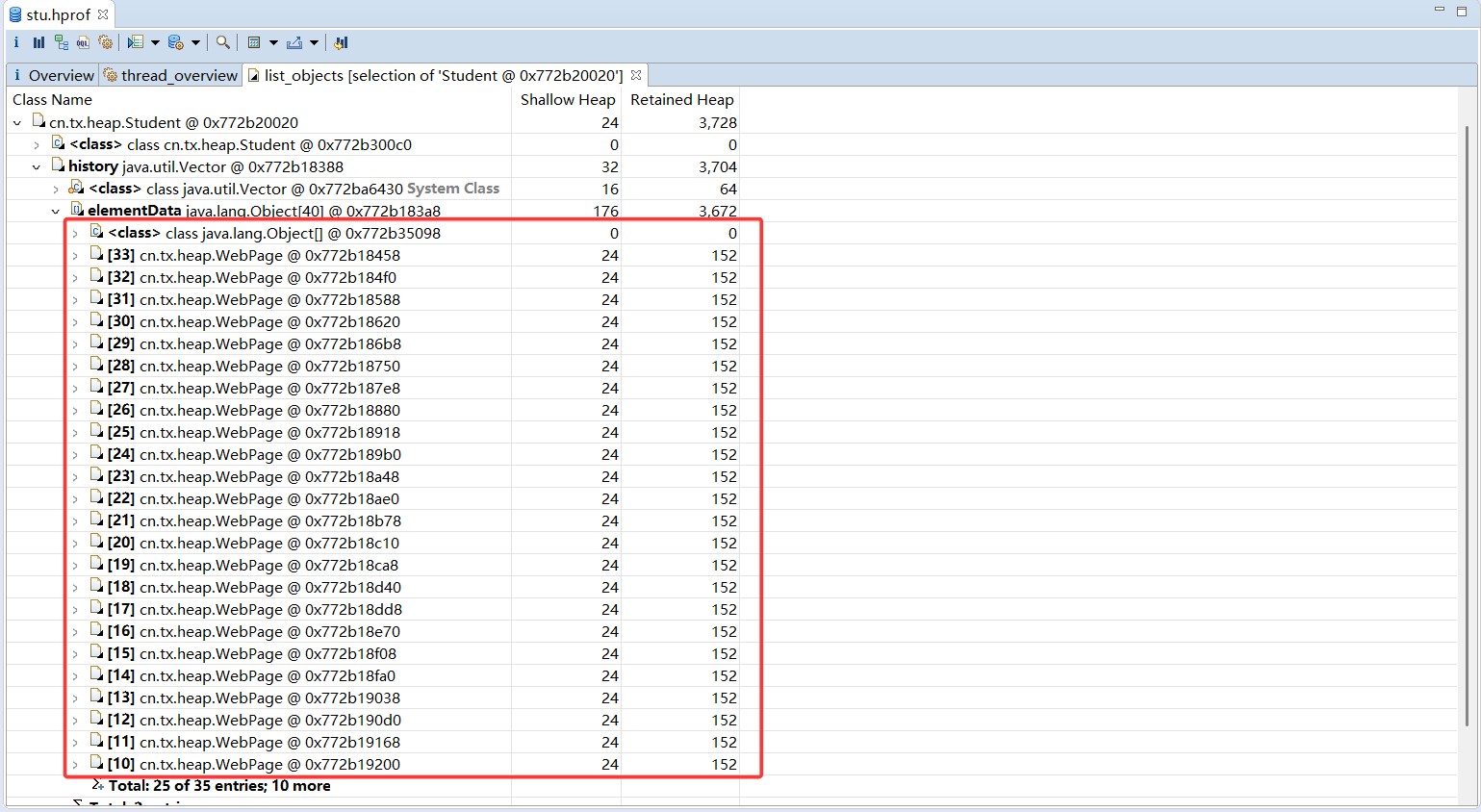
使用MAT打开产生的stu.hrof文件。在线程视图中可以通过主线程,找到3名学生的引用,如图所示,这里已经标出了每个实例的学生名。除了对象名称外,MAT还给出了浅堆大小和深堆大小。可以看到,所有Student 类的浅堆统一为24 字节,和它们持有的内容无关,而深堆大小各不相同,这和每名学生访问的网页有关。
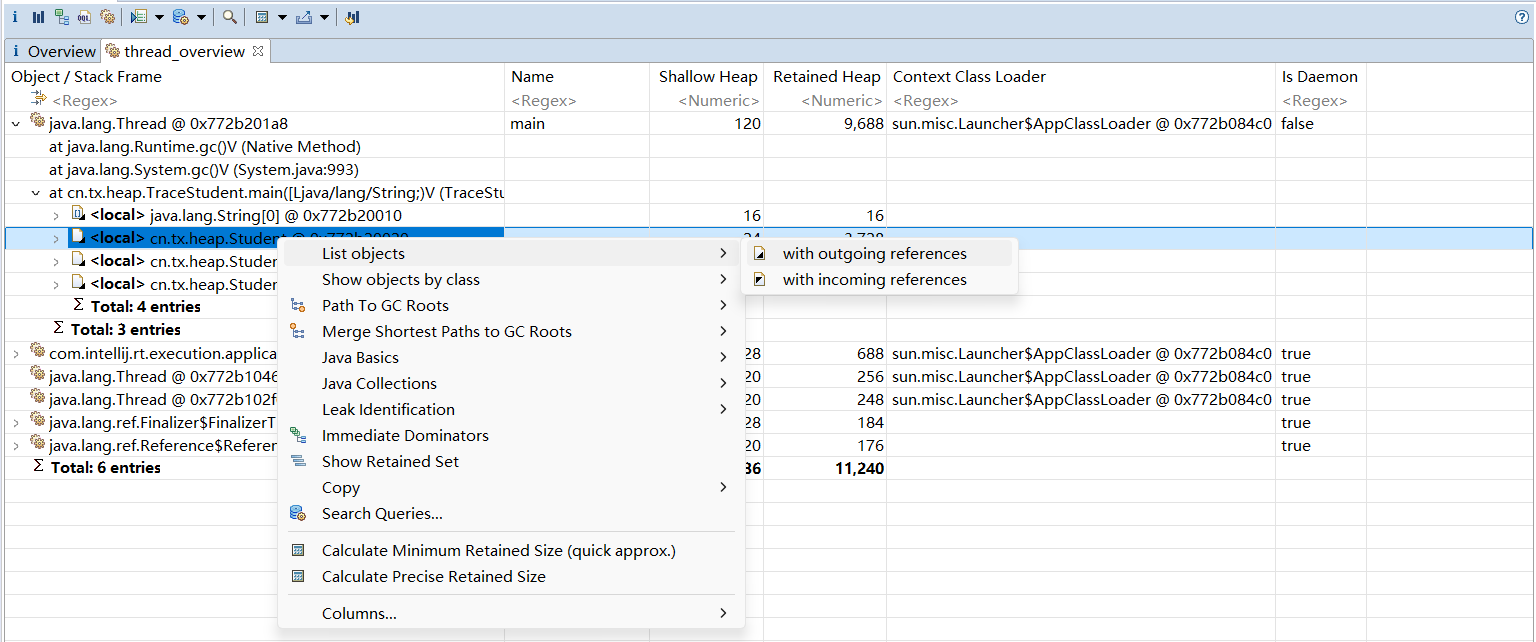
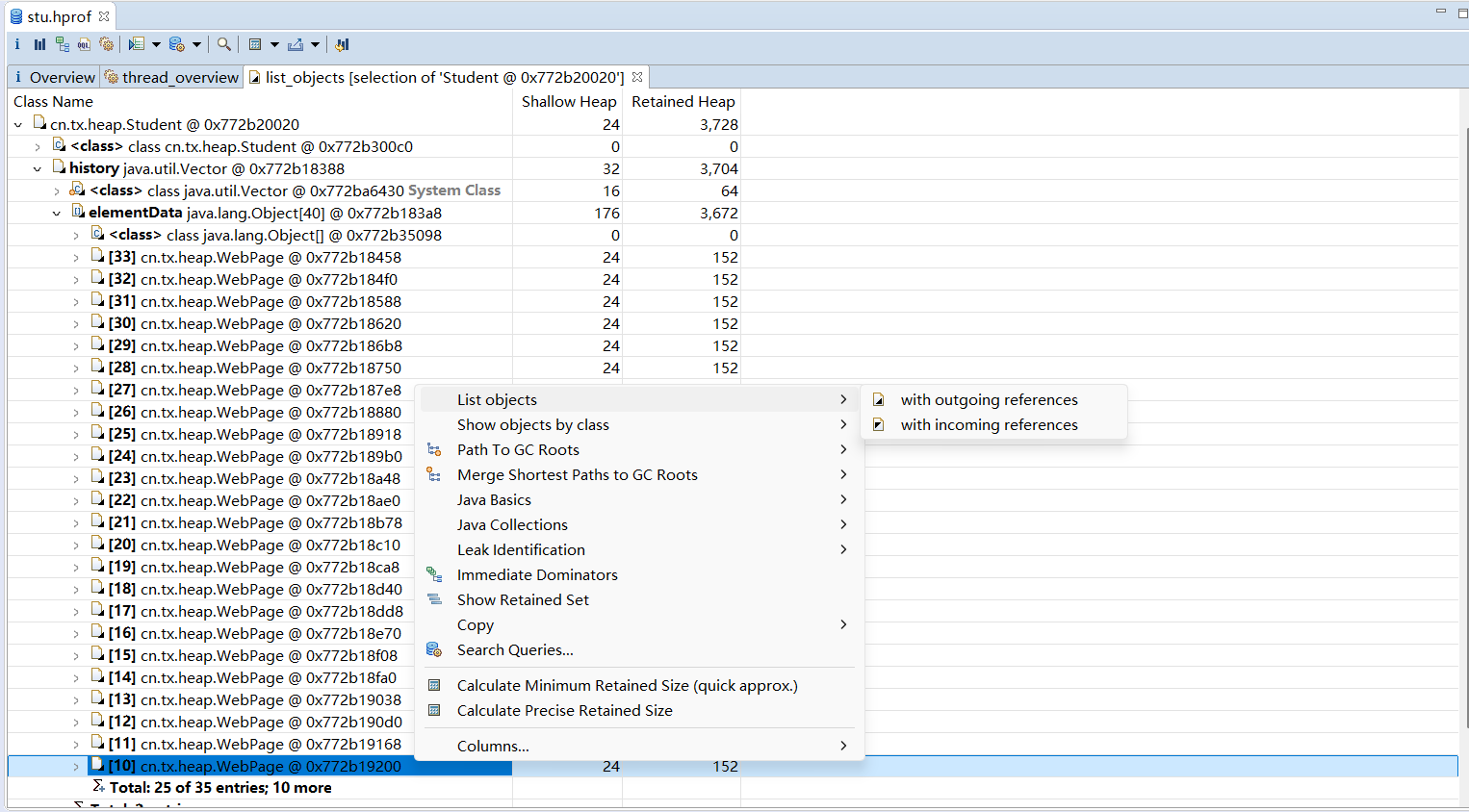
为了获得bily同学访问过的网页,可以在bily的记录中通过"出引用"(Outgoing References)查找,就可以找到由bily可以触及的对象,也就是他访问过的网页,如图所示。
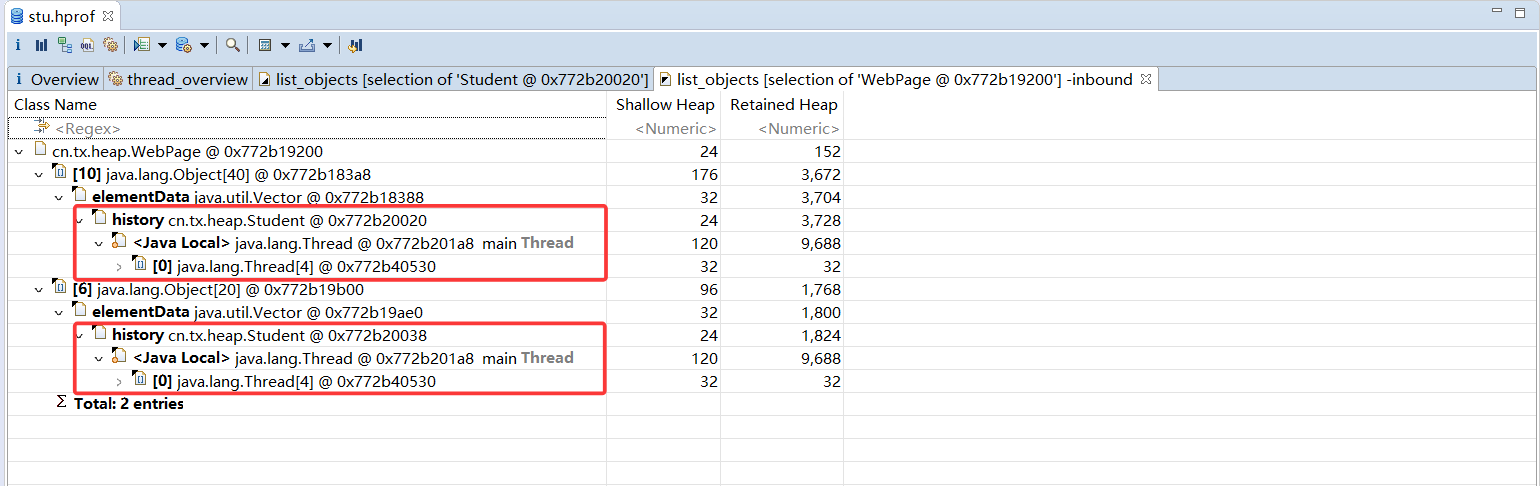
如果现在希望查看哪些同学访问了"http://www.0.com" ,则可以在对应的WebPage对象中通过"入引用"( Incoming References) 查找。如图所示,显然这个网址被3名学生都访问过了。
支配树
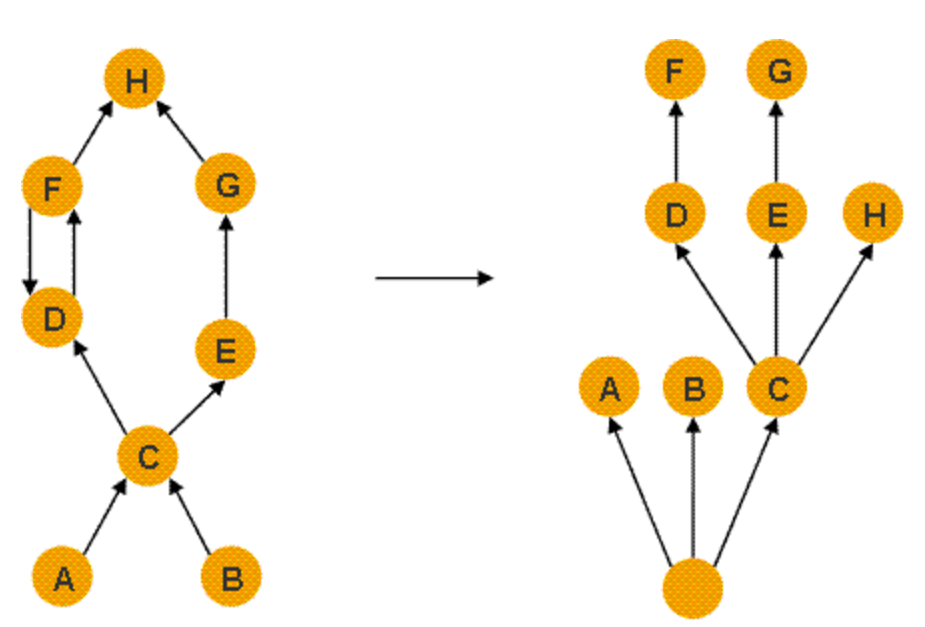
MAT 提供了一个称为支配树(Dominator Tree)的对象图,支配树体现了对象实例间的支配关系。
支配关系:在对象引用图中,如果所有指向对象 B 的路径都必须经过对象 A,则称 A 支配 B。
直接支配者:在所有支配 B 的对象中,离 B 最近的那个对象,就是 B 的直接支配者,也是 B 在支配树里的父节点。
支配树的根节点,就是整个对象图的 GC Root。
支配树是基于对象间的引用图所建立的,如图所示,左图表示对象引用图,右图表示左图所对应的支配树。
下面进行逐对象分析支配关系:
对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点出发,也是经过对象C的,所以,对象D的直接支配者为对象C。同理,对象E支配对象G。到达对象H的可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者。