在多模态大模型飞速发展的今天,CLIP作为连接视觉与语言的"基石"依然发挥着重要作用。然而,随着应用场景的深入,研究人员逐渐发现CLIP的文本编码器已经成为整个系统的瓶颈:不仅受限于77个Token的长度限制,在处理复杂、长篇的图像描述时也显得力不从心。
来自同济大学、微软和麦考瑞大学的研究团队提出了 LLM2CLIP(Large Language Model to CLIP) ,通过将大语言模型的深厚知识"注入"到CLIP架构中,显著提升了长文本检索的精度,同时赋予了模型强大的多语言处理能力。
这项研究凭借其卓越的创新性,成功斩获 AAAI 2026 杰出论文奖。
论文地址: arxiv.org/abs/2411.04...
项目主页: aka.ms/llm2clip
代码仓库: github.com/microsoft/L... (已开源)

编辑
传统CLIP的"语言瓶颈"
自2021年OpenAI发布CLIP以来,这种双塔结构模型已经成为多模态领域的标配。
无论是LLaVA这样的理解模型,还是Stable Diffusion这样的生成模型,都离不开CLIP的贡献。
但问题在于,传统的CLIP文本编码器通常是规模较小的Transformer结构,其处理长描述(Dense Captions)的能力非常有限。
与此同时,大语言模型在文本理解上已经达到了惊人的高度。那么,为什么不直接把LLM拿来当CLIP的文本编码器呢?
研究团队发现,这里存在两个核心挑战:
- 特征可分性问题:原始LLM的特征空间并不是为了对比学习设计的。实验显示,像Llama 3这样的模型在处理图像描述时,其特征区分度极差,Top-1检索准确率甚至不到6%
- 训练成本过高:如果每次训练CLIP都要微调一个7B甚至更大的LLM,那算力开销将是天文数字
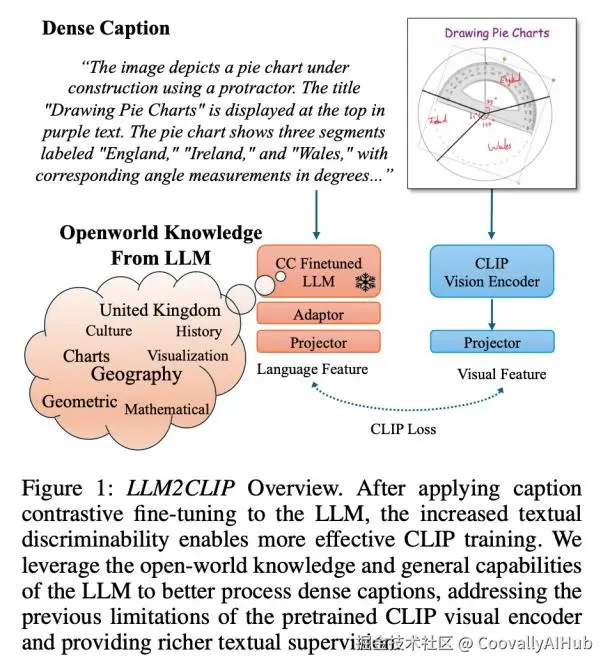
两阶段"注入"方案:巧妙的架构设计
LLM2CLIP的核心创新在于提出了一个巧妙的两阶段微调方案,既解决了特征可分性问题,又大幅降低了训练成本。
编辑
- 第一阶段:让LLM学会"提取特征"
为了解决LLM特征区分度不足的问题,研究者首先对LLM进行了"嵌入化"改造:
架构调整: 移除了LLM原有的因果掩码,改为双向注意力机制,并采用平均池化来获取整句的嵌入向量
对比学习: 利用LoRA技术,在高质量的描述语料库(如DreamLIP)上进行监督式描述对比微调
简单来说,这一步是让LLM明白:即使是两段描述同一个物体的不同文字,在特征空间里也应该靠得更近。
效果惊人:经过这一阶段,Llama 3在COCO描述检索上的准确率从5.2%飙升到了29.5%

编辑
- 第二阶段:视觉与语言的轻量级对齐
在LLM具备了良好的特征区分度后,接下来的任务是将其与CLIP的视觉编码器对齐:
轻量级适配器: 选择冻结LLM,仅在LLM输出后添加一个由4层线性层组成的线性适配器
离线特征加载: 这是提升效率的神来之笔。由于LLM是冻结的,研究者可以预先计算并存储所有文本的特征。这样在训练视觉编码器时,就不需要反复运行庞大的LLM
损失函数:研究团队发现,最简单的方法效果最好------直接用LLM替换原有的文本编码器进行对比学习
全方位性能提升:从长文本到多语言
研究团队在多个SOTA基准模型(如OpenAI CLIP, EVA02, SigLIP2)上应用了LLM2CLIP方案,结果令人振奋。
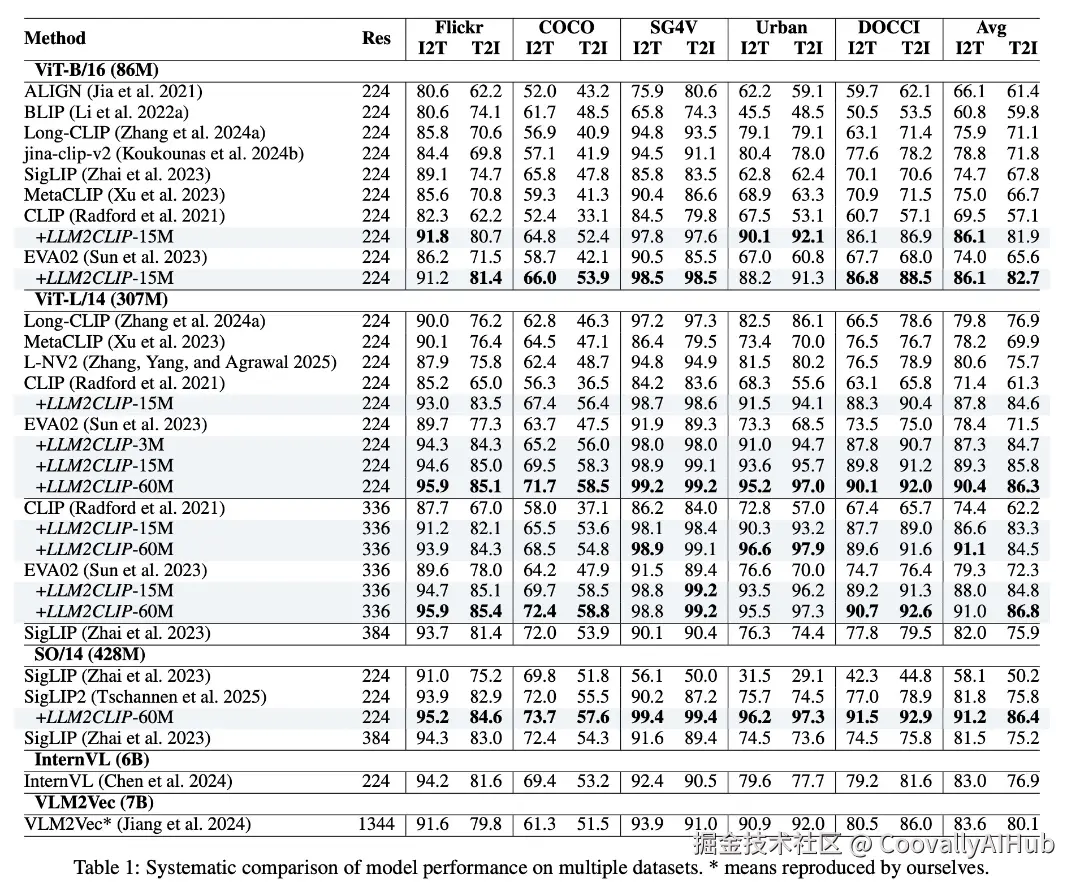
- 长文本检索:性能大幅提升
在长文本检索数据集(如DOCCI和Urban1K)上,相比于原本已经非常强大的SigLIP2,LLM2CLIP带来了巨大提升:
在DOCCI数据集上,SigLIP2经过LLM2CLIP微调后,平均检索精度提升了14-15个百分点
即使在短文本的Flickr和COCO任务上,性能也稳步提升
编辑
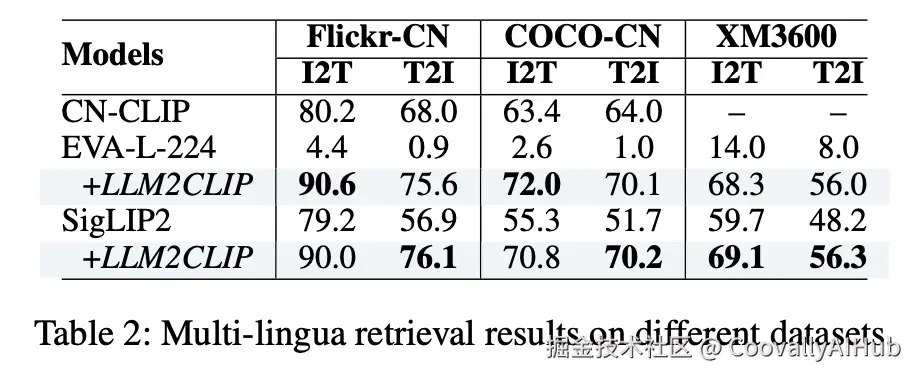
- 多语言能力:意外惊喜
由于LLM本身就是在海量多语言语料上训练的,LLM2CLIP继承了这种天赋:
原本只支持英文的EVA02在加入LLM2CLIP后,在中文检索任务上直接从"不可用"变成了"顶尖水平"
SigLIP2的多语言能力也得到了显著增强,在XM3600任务上的表现提升了11.9/15.2
编辑
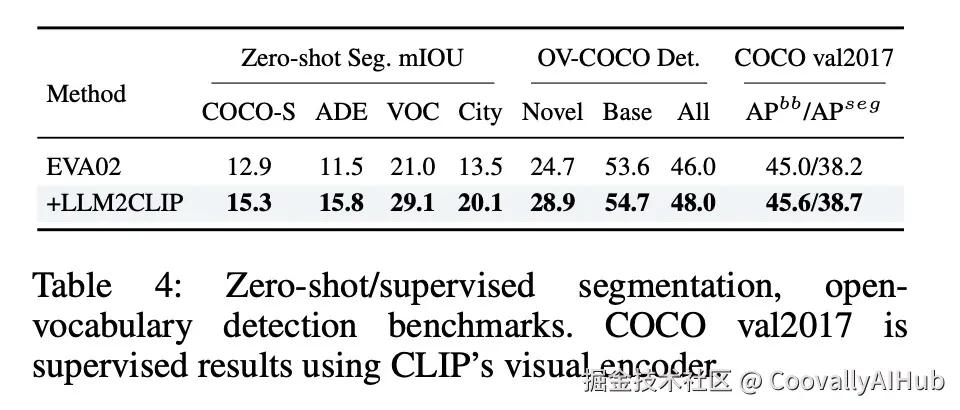
- 视觉表征的"反哺效应"
高质量的文本监督不仅让检索变准了,还让视觉编码器本身变得更强:
在ImageNet的线性探测实验中,LLM2CLIP提升了视觉特征的质量;
在下游的零样本分割和检测任务中,性能也有显著增长
编辑
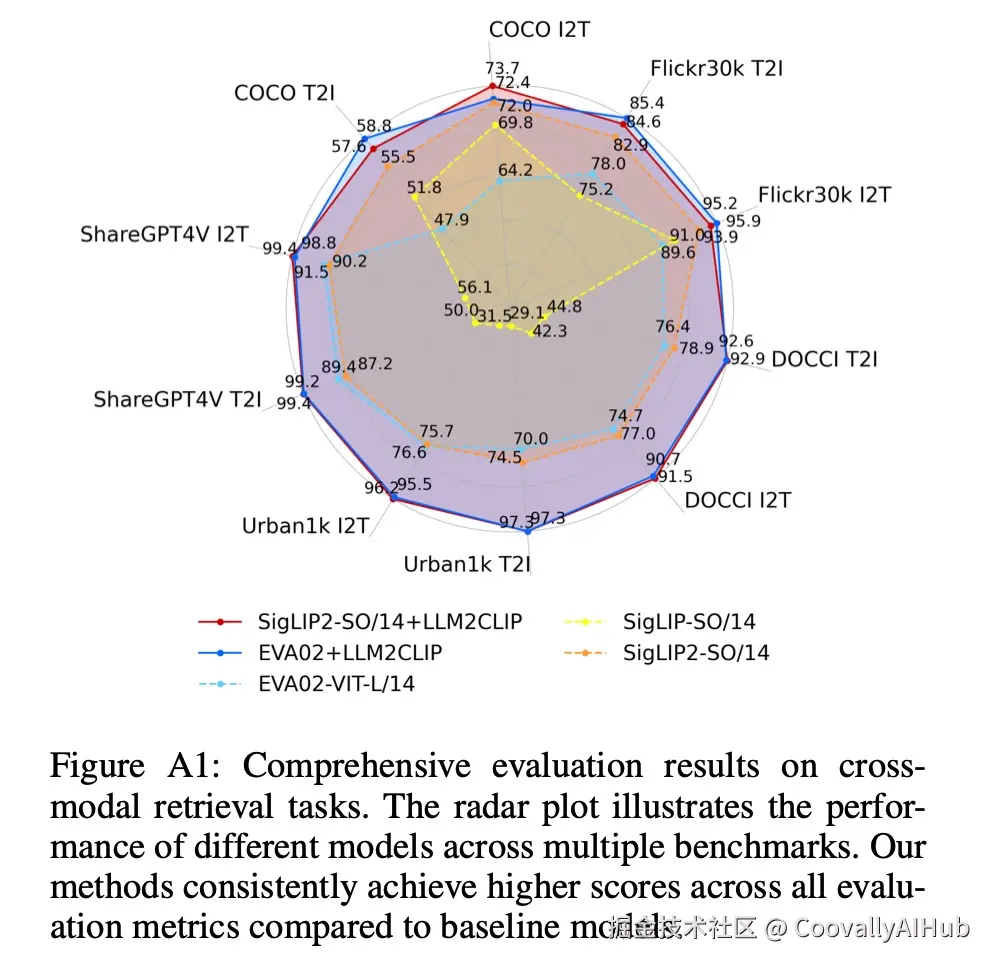
- 综合性能:全方位优势
从雷达图上可以清晰看到,LLM2CLIP构成的多边形面积远超其他对比模型。
这意味着它不仅在长文本上遥遥领先,在传统的短文本检索任务上也保持了极高的水准,没有任何短板。
编辑
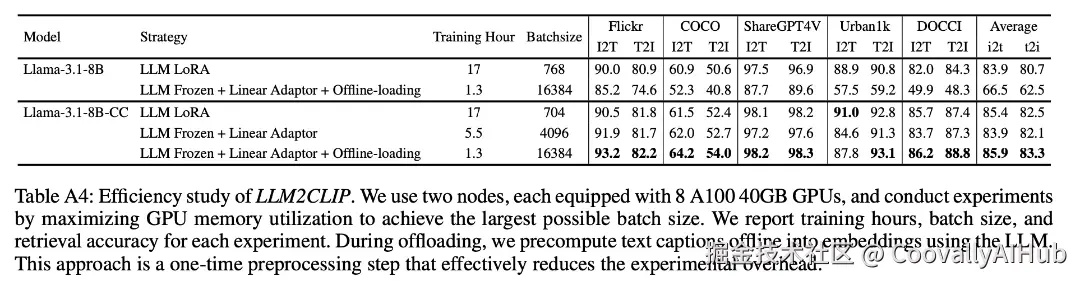
惊人的训练效率:1.3小时完成微调
对于开发者来说,LLM2CLIP最吸引人的地方在于其惊人的效率。
通过Offline-loading策略,在两台8卡A100机器上,第二阶段的训练时间从17小时缩短到了仅仅1.3小时。
这意味着普通研究团队也能轻松复现并定制自己的LLM2CLIP模型。
编辑
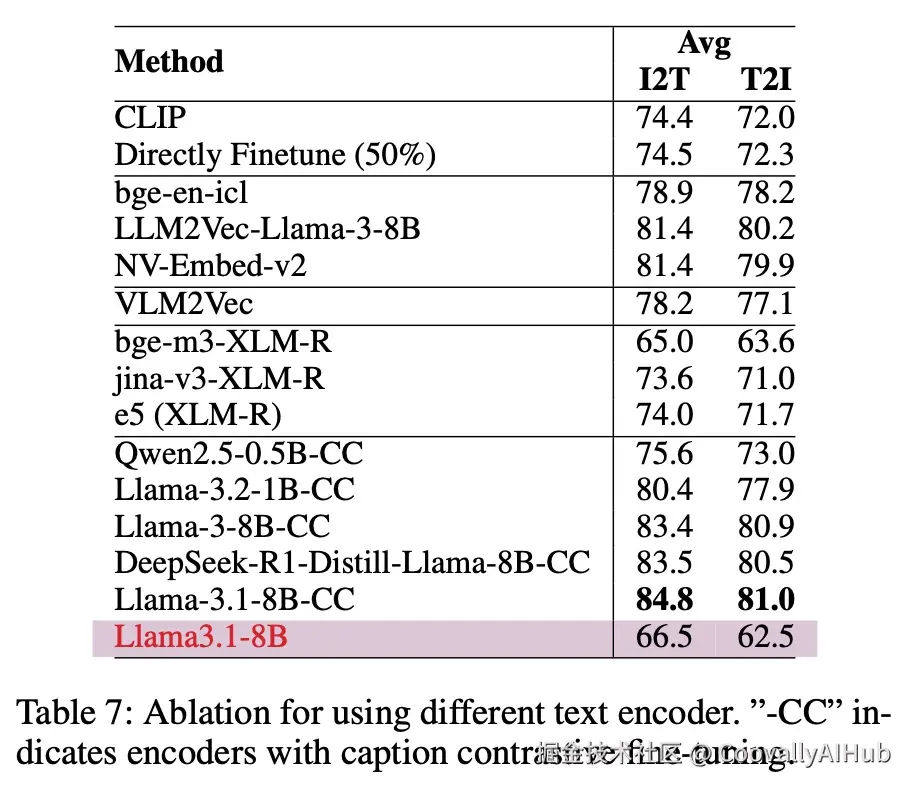
研究团队还测试了最新的模型兼容性。令人惊喜的是,即使是最近大火的DeepSeek-R1-Distill-Llama-8B,在经过CC Fine-tuning后也能作为极佳的文本编码器。
编辑
核心启示与未来展望
LLM2CLIP的成功给了我们一个非常重要的启示:
多模态模型的上限,往往取决于语言端对世界的理解深度。
过去我们试图通过堆视觉数据来提升CLIP,但LLM2CLIP证明了,通过引入一个已经"读过万卷书"的LLM,并辅以少量的、高质量的描述数据,就能让视觉表征产生质的飞跃。
这种"低成本、高收益"的方案,很可能会成为未来多模态预训练的新范式。
目前,研究团队已经开源了基于SigLIP2、EVA02和OpenAI CLIP增强的多个版本模型。
如果你正受困于CLIP的文本理解能力,或者需要一个强大的多语言多模态编码器,LLM2CLIP绝对值得一试。
技术的发展总是在解决一个个瓶颈中前进。LLM2CLIP通过巧妙的设计,不仅突破了CLIP的文本编码器限制,更为多模态研究开辟了新的思路:让专业的人(模型)做专业的事,再通过轻量化的方式将它们连接起来。
这或许正是未来AI系统设计的重要方向之一。