一、主流国产时序数据库概览 (2026)
国产时序数据库已形成多元产品矩阵,根据其核心技术路线、商业模式和市场定位,主要代表性产品如下:
数据库产品对比
TDengine
- 核心厂商/社区: 涛思数据
- 主要特点与定位: 高性能、分布式,定位为AI驱动的工业大数据平台,在写入吞吐和存储成本方面优势显著,集群开源、生态开放。
KaiwuDB
- 核心厂商/社区: 浪潮云弈
- 主要特点与定位: 强调分布式多模融合架构,支持时序、关系、文档等多种数据模型的统一处理,原生集成AI算法。
Apache IoTDB
- 核心厂商/社区: 清华大学 (Apache基金会)
- 主要特点与定位: 专为物联网设计,采用"端-边-云"协同原生架构,数据模型常采用树形结构贴合物理设备层级。
DolphinDB
- 核心厂商/社区: 浙江智臾科技
- 主要特点与定位: 将数据库与强大的编程语言、流计算引擎融合,在金融量化交易、高频数据分析领域表现突出。
openGemini
- 核心厂商/社区: 华为云
- 主要特点与定位: 开源的多模态时序数据库,兼容InfluxDB生态,强调高性能与云原生特性。
CnosDB
- 核心厂商/社区: 诺司时空
- 主要特点与定位: 云原生时序数据库,支持分布式与集中式部署,在监控和物联网场景有应用。
GreptimeDB
- 核心厂商/社区: 格睿科技
- 主要特点与定位: 云原生分布式时序数据库,主打实时分析能力。
YMatrix, RealHistorian, GoldenData等
- 核心厂商/社区: 四维纵横、紫金桥、庚顿数据等
- 主要特点与定位: 在特定工业或监控领域拥有深厚的行业积累和定制化解决方案。
金仓时序数据库
- 核心厂商/社区: 中电科金仓(原人大金仓)
- 主要特点与定位: 基于成熟稳定的金仓数据库管理系统(KES)内核打造的时序能力增强插件,最大特点是继承了KES的融合多模架构,支持时序数据与关系型、空间(GIS)等数据的统一存储、处理与关联分析。
二、焦点解析:金仓时序数据库的融合多模架构
在众多专注于时序场景极致优化的产品中,金仓数据库的时序组件选择了一条独特的路径:不追求做一个孤立的专用时序引擎,而是作为其强大的融合数据库体系(KES)中的一个版块。这种架构选择带来了以下显著优势:
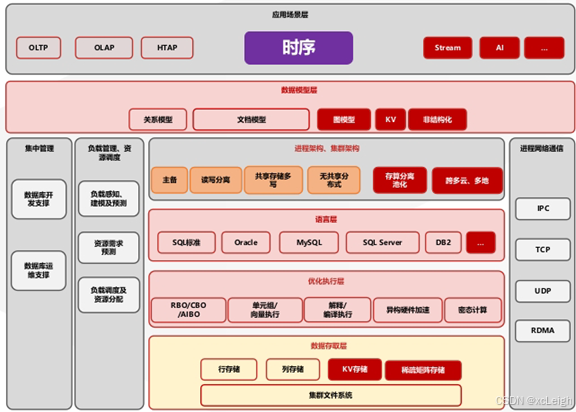
1. 内核级多模态融合,打破数据孤岛
统一底座: 金仓时序组件并非独立产品,而是基于成熟的KingbaseES关系型数据库内核进行融合。这意味着企业无需为时序数据单独搭建和维护一套新的数据基础设施。
无缝关联查询: 时序数据(如传感器读数)与业务关系数据(如设备台账、生产工单)天然存储在同一数据库中。用户可以使用标准的SQL(支持Oracle/PostgreSQL兼容模式)直接进行跨时序表和关系表的复杂JOIN查询,无需繁琐的数据同步与导出,极大简化了数据分析链路。
支持丰富数据类型: 得益于KES内核,它不仅支持时序数据常用的数值、时间戳类型,还原生支持JSON、GIS空间数据、数组等复杂类型,能够满足更广泛的工业数字化场景需求。
2. 复用并强化企业级核心能力
极致的事务(ACID)保证: 在金仓的时序表上,数据写入同样享有完整的关系型数据库事务支持,这在要求数据强一致性的金融、电力调度等关键业务场景中是独特优势。
企业级高可用与安全: 时序数据可直接受益于KES已构建成熟的读写分离、共享存储、分布式集群等高可用架构,以及行列级权限控制、数据加密等企业级安全特性。
成熟的生态与工具链: 可直接复用KES的备份恢复、监控运维、数据迁移(KDTS)等整套运维管理工具,以及与各类BI、ETL工具的连接生态,降低学习与运维成本。
3. 面向复杂场景的综合性能表现
从金仓官方披露的测试报告(如使用TSBS工具对比InfluxDB)来看,其时序组件在特定场景下展现出竞争力:
写入性能: 通过优化分区策略、并行插入等手段,在特定配置下可实现单机百万级、集群千万级数据点/秒的写入能力。
查询性能: 在涉及多维度聚合、跨表关联等复杂查询场景中,凭借成熟的SQL优化器与执行引擎,性能表现显著优于部分原生时序数据库,尤其适合需要将时序数据与业务数据进行深度整合分析的场景。
三、行业应用与实践
金仓时序组件的融合架构使其在那些既需要处理海量时序数据流,又需要与核心业务系统紧密集成的场景中找到了用武之地,公开案例包括:
福建省船舶安全综合管理平台: 处理沿海数十万船舶终端的GPS定位时序数据,基于KES分片(Sharding)方案实现日峰值亿级写入与百亿级历史数据的毫秒级地理空间查询。
国家电网智能电网调度系统: 在国产化迁移项目中,支撑高频、可靠的电力数据录入,并实现与大量既有关系型业务数据的混合处理与分析。
智慧港口(如厦门港)、智能制造厂区: 记录设备轨迹、工况时序数据,并与生产管理系统、设备管理系统进行实时关联分析。
四、2026年国产时序数据库选型思考
企业在2026年进行时序数据库选型时,应超越对单一峰值性能指标的过度关注,从更宏观的视角评估:
数据架构复杂性: 如果业务中时序数据与关系数据、空间数据等紧密耦合,需要频繁关联分析,金仓的融合多模架构将提供极大的便利性和整体性价比。
长期运维与总拥有成本(TCO): 考虑引入新产品带来的学习成本、运维复杂度以及生态整合成本。复用现有关系型数据库团队的技能栈和工具链,是金仓方案的另一大隐性优势。
结论
2026年的国产时序数据库赛道已进入"精耕细作"阶段。以TDengine、IoTDB、DolphinDB为代表的专业时序库在各自优势领域持续深化。
金仓时序数据库凭借其独特的融合多模架构,走出了一条差异化道路。它并非"万能钥匙",但对于那些业务逻辑复杂、数据形态多样、且对事务一致性与系统整合有高要求的企业级用户而言,提供了一个能够将时序数据能力平滑、稳健地嵌入到现有企业数据核心中的优秀选择,体现了国产基础软件在架构设计上的深度思考与务实创新。
未来,随着AI for Data、实时智能分析的普及,时序数据库的"智能"与"融合"能力将愈发关键。如何更好地将时序处理能力与多模数据、AI框架、流批计算无缝结合,将是所有厂商共同面临的下一个课题。
五、代码示例:金仓时序数据库实战
5.1 创建时序表
sql
-- 创建设备传感器时序表
CREATE TABLE sensor_data (
ts TIMESTAMP NOT NULL, -- 时间戳
device_id VARCHAR(50) NOT NULL, -- 设备ID
temperature FLOAT, -- 温度
pressure FLOAT, -- 压力
humidity FLOAT, -- 湿度
location GEOMETRY(POINT, 4326), -- GIS地理位置
metadata JSONB -- JSON元数据
) PARTITION BY RANGE (ts);
-- 创建按月分区
CREATE TABLE sensor_data_202601 PARTITION OF sensor_data
FOR VALUES FROM ('2026-01-01') TO ('2026-02-01');
CREATE TABLE sensor_data_202602 PARTITION OF sensor_data
FOR VALUES FROM ('2026-02-01') TO ('2026-03-01');
-- 创建时间索引
CREATE INDEX idx_sensor_ts ON sensor_data (ts DESC);
CREATE INDEX idx_sensor_device ON sensor_data (device_id, ts DESC);5.2 批量写入时序数据
python
import psycopg2
from datetime import datetime, timedelta
import random
# 连接金仓数据库
conn = psycopg2.connect(
host="localhost",
port=54321,
database="timeseries_db",
user="system",
password="password"
)
cursor = conn.cursor()
# 批量插入传感器数据
def batch_insert_sensor_data(batch_size=10000):
start_time = datetime.now()
values = []
for i in range(batch_size):
ts = start_time + timedelta(seconds=i)
device_id = f"DEVICE_{random.randint(1, 100):03d}"
temperature = round(random.uniform(20.0, 30.0), 2)
pressure = round(random.uniform(100.0, 105.0), 2)
humidity = round(random.uniform(40.0, 60.0), 2)
lon = round(random.uniform(118.0, 120.0), 6)
lat = round(random.uniform(24.0, 26.0), 6)
metadata = f'{{"status": "normal", "version": "v1.0"}}'
values.append(f"('{ts}', '{device_id}', {temperature}, {pressure}, {humidity}, "
f"ST_SetSRID(ST_MakePoint({lon}, {lat}), 4326), '{metadata}')")
# 执行批量插入
sql = f"""
INSERT INTO sensor_data (ts, device_id, temperature, pressure, humidity, location, metadata)
VALUES {','.join(values)}
"""
cursor.execute(sql)
conn.commit()
print(f"成功插入 {batch_size} 条数据")
# 执行批量插入
batch_insert_sensor_data(10000)
cursor.close()
conn.close()5.3 时序数据查询与聚合
sql
-- 查询最近1小时的平均温度
SELECT
device_id,
AVG(temperature) as avg_temp,
MAX(temperature) as max_temp,
MIN(temperature) as min_temp,
COUNT(*) as data_points
FROM sensor_data
WHERE ts >= NOW() - INTERVAL '1 hour'
GROUP BY device_id
ORDER BY avg_temp DESC;
-- 时间窗口聚合(每5分钟)
SELECT
time_bucket('5 minutes', ts) as time_window,
device_id,
AVG(temperature) as avg_temp,
AVG(pressure) as avg_pressure
FROM sensor_data
WHERE ts >= NOW() - INTERVAL '24 hours'
GROUP BY time_window, device_id
ORDER BY time_window DESC, device_id;
-- 移动平均计算
SELECT
ts,
device_id,
temperature,
AVG(temperature) OVER (
PARTITION BY device_id
ORDER BY ts
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
) as moving_avg_temp
FROM sensor_data
WHERE device_id = 'DEVICE_001'
AND ts >= NOW() - INTERVAL '1 hour'
ORDER BY ts DESC;5.4 融合多模查询:时序+关系+空间
sql
-- 创建设备信息表(关系型)
CREATE TABLE device_info (
device_id VARCHAR(50) PRIMARY KEY,
device_name VARCHAR(100),
device_type VARCHAR(50),
install_date DATE,
location_name VARCHAR(100)
);
-- 跨时序表和关系表的关联查询
SELECT
d.device_name,
d.device_type,
d.location_name,
s.ts,
s.temperature,
s.pressure,
ST_AsText(s.location) as gps_location
FROM sensor_data s
INNER JOIN device_info d ON s.device_id = d.device_id
WHERE s.ts >= NOW() - INTERVAL '1 hour'
AND s.temperature > 28.0
AND d.device_type = 'Temperature Sensor'
ORDER BY s.ts DESC
LIMIT 100;
-- 地理空间范围查询(融合GIS)
SELECT
d.device_name,
s.device_id,
s.ts,
s.temperature,
ST_Distance(
s.location::geography,
ST_SetSRID(ST_MakePoint(119.5, 25.0), 4326)::geography
) / 1000 as distance_km
FROM sensor_data s
INNER JOIN device_info d ON s.device_id = d.device_id
WHERE ST_DWithin(
s.location::geography,
ST_SetSRID(ST_MakePoint(119.5, 25.0), 4326)::geography,
50000 -- 50公里范围内
)
AND s.ts >= NOW() - INTERVAL '1 hour'
ORDER BY distance_km
LIMIT 20;5.5 Python应用示例:实时数据分析
python
import psycopg2
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
class KingbaseTimeSeriesAnalyzer:
def __init__(self, conn_params):
self.conn = psycopg2.connect(**conn_params)
def get_device_trend(self, device_id, hours=24):
"""获取设备温度趋势"""
query = """
SELECT
ts,
temperature,
pressure,
humidity
FROM sensor_data
WHERE device_id = %s
AND ts >= NOW() - INTERVAL '%s hours'
ORDER BY ts
"""
df = pd.read_sql_query(query, self.conn, params=(device_id, hours))
return df
def get_abnormal_devices(self, temp_threshold=30.0):
"""获取异常设备列表"""
query = """
SELECT
d.device_name,
s.device_id,
AVG(s.temperature) as avg_temp,
MAX(s.temperature) as max_temp,
COUNT(*) as alert_count
FROM sensor_data s
INNER JOIN device_info d ON s.device_id = d.device_id
WHERE s.ts >= NOW() - INTERVAL '1 hour'
AND s.temperature > %s
GROUP BY d.device_name, s.device_id
HAVING COUNT(*) > 10
ORDER BY avg_temp DESC
"""
df = pd.read_sql_query(query, self.conn, params=(temp_threshold,))
return df
def analyze_spatial_distribution(self, center_lon, center_lat, radius_km=50):
"""分析空间分布"""
query = """
SELECT
device_id,
AVG(temperature) as avg_temp,
ST_X(location) as longitude,
ST_Y(location) as latitude,
ST_Distance(
location::geography,
ST_SetSRID(ST_MakePoint(%s, %s), 4326)::geography
) / 1000 as distance_km
FROM sensor_data
WHERE ts >= NOW() - INTERVAL '1 hour'
AND ST_DWithin(
location::geography,
ST_SetSRID(ST_MakePoint(%s, %s), 4326)::geography,
%s
)
GROUP BY device_id, location
ORDER BY distance_km
"""
df = pd.read_sql_query(
query,
self.conn,
params=(center_lon, center_lat, center_lon, center_lat, radius_km * 1000)
)
return df
def close(self):
self.conn.close()
# 使用示例
if __name__ == "__main__":
conn_params = {
'host': 'localhost',
'port': 54321,
'database': 'timeseries_db',
'user': 'system',
'password': 'password'
}
analyzer = KingbaseTimeSeriesAnalyzer(conn_params)
# 获取设备趋势
trend_df = analyzer.get_device_trend('DEVICE_001', hours=24)
print("设备温度趋势:")
print(trend_df.head())
# 获取异常设备
abnormal_df = analyzer.get_abnormal_devices(temp_threshold=28.0)
print("\n异常设备列表:")
print(abnormal_df)
# 空间分布分析
spatial_df = analyzer.analyze_spatial_distribution(119.5, 25.0, radius_km=50)
print("\n空间分布分析:")
print(spatial_df.head())
analyzer.close()5.6 性能优化配置
sql
-- 创建超表(Hypertable)以提升时序性能
CREATE EXTENSION IF NOT EXISTS timescaledb;
SELECT create_hypertable('sensor_data', 'ts',
chunk_time_interval => INTERVAL '1 day',
if_not_exists => TRUE
);
-- 添加压缩策略
ALTER TABLE sensor_data SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'device_id',
timescaledb.compress_orderby = 'ts DESC'
);
-- 自动压缩历史数据
SELECT add_compression_policy('sensor_data', INTERVAL '7 days');
-- 数据保留策略(自动删除90天前数据)
SELECT add_retention_policy('sensor_data', INTERVAL '90 days');
-- 连续聚合(物化视图)
CREATE MATERIALIZED VIEW sensor_data_hourly
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 hour', ts) AS hour,
device_id,
AVG(temperature) as avg_temp,
MAX(temperature) as max_temp,
MIN(temperature) as min_temp,
AVG(pressure) as avg_pressure,
COUNT(*) as data_points
FROM sensor_data
GROUP BY hour, device_id;
-- 添加刷新策略
SELECT add_continuous_aggregate_policy('sensor_data_hourly',
start_offset => INTERVAL '3 hours',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 hour'
);以上代码示例展示了金仓时序数据库在实际应用中的核心功能,包括表结构设计、批量数据写入、复杂查询分析、多模融合查询以及性能优化策略,充分体现了其融合架构的技术优势。