引言:国产数据库迁移的时代背景
在当前数字化转型与信息技术应用创新的双重驱动下,数据库国产化迁移已经成为众多企业的战略选择。电科金仓(KingbaseES) 作为中国电子科技集团自主研发的企业级关系型数据库管理系统,在Oracle迁移场景中展现出独特的技术优势和市场价值。本文将从技术角度深入剖析Oracle到金仓数据库迁移过程中面临的兼容性挑战、迁移成本控制等核心问题,为正在进行或计划进行数据库迁移的企业提供技术参考和实践指导。

一:Oracle迁移至金仓数据库的技术背景
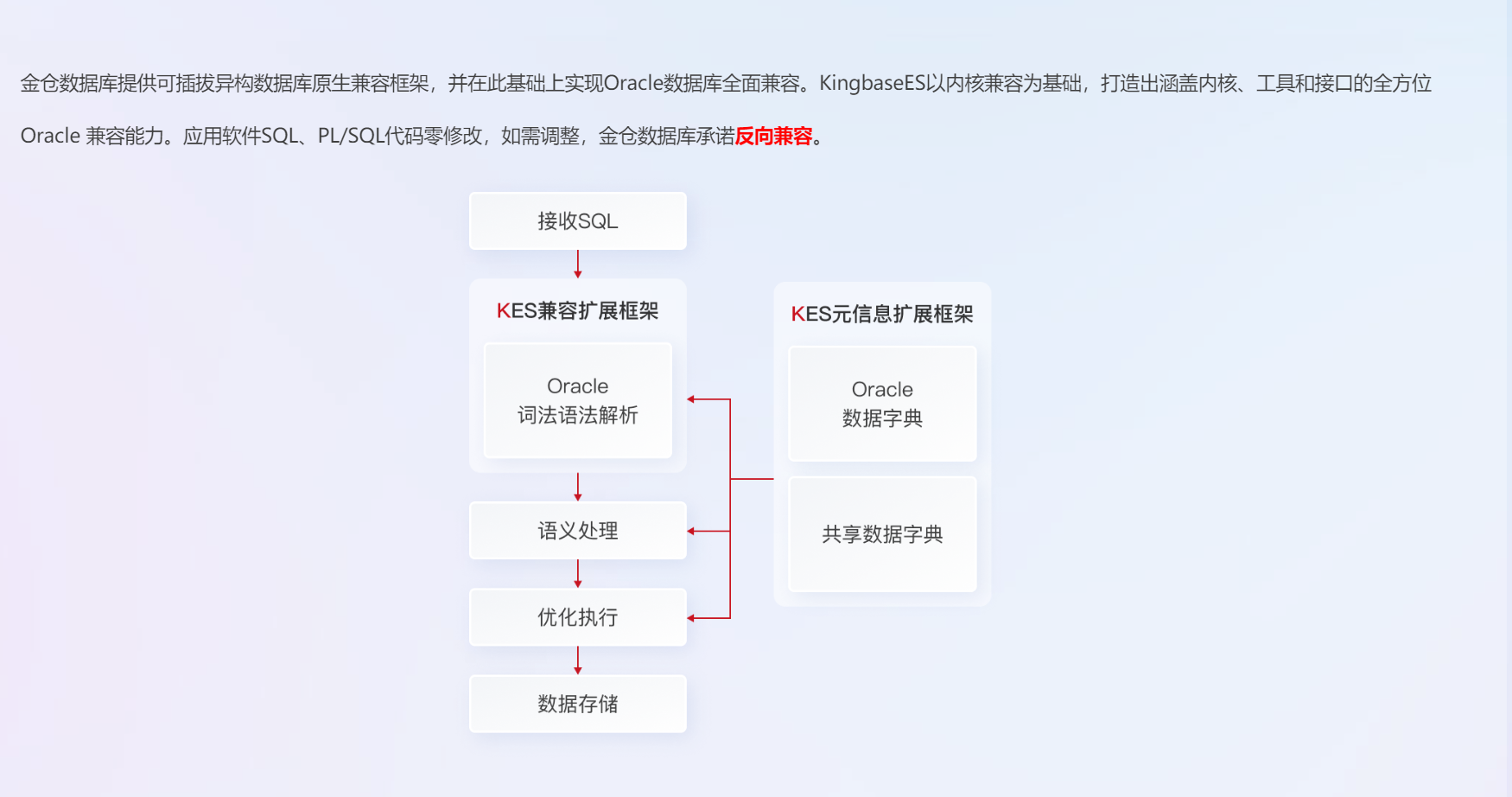
1.1 金仓数据库技术特性概述
金仓数据库(官网地址)作为国产数据库的重要代表,经过多年的技术积累和产品迭代,已经形成了完整的企业级数据库产品体系。其核心特性包括:
高可用架构:金仓数据库提供了基于流复制、逻辑复制和共享存储等多种高可用解决方案,能够满足不同业务场景的可用性要求。与Oracle Data Guard相比,金仓数据库的复制机制更加灵活,支持级联复制和延迟复制等高级特性。
安全合规特性:金仓数据库符合国家信息安全等级保护要求,提供数据加密、访问控制、审计跟踪等全面的安全功能。特别在数据加密方面,支持透明数据加密(TDE)和列级加密,能够满足金融、政务等敏感行业的安全需求。
性能优化机制:金仓数据库采用多版本并发控制(MVCC)技术,结合高效的查询优化器和执行引擎,在处理复杂查询和高并发场景时表现出良好的性能。数据库内置的并行查询功能可以充分利用多核CPU资源,提升数据处理效率。
管理工具生态:金仓数据库提供了完整的数据库管理工具套件,包括安装部署工具、监控管理平台、备份恢复工具等,降低了数据库运维的技术门槛。
1.2 Oracle迁移的技术驱动力
企业从Oracle迁移到金仓数据库通常基于以下技术考虑:
技术架构现代化:传统集中式架构向分布式、云原生架构演进过程中,数据库选型需要重新评估。金仓数据库支持容器化部署和云原生特性,能够更好地适应现代应用架构。
性能优化需求:随着数据量的增长和业务复杂度的提升,Oracle数据库在某些场景下可能遇到性能瓶颈。金仓数据库通过优化存储引擎和查询处理器,在特定工作负载下能够提供更好的性能表现。
功能特性匹配:金仓数据库持续增强企业级功能,如分区表、物化视图、存储过程等,逐步缩小与Oracle在功能特性方面的差距,使得迁移变得更加可行。
技术自主可控:在关键信息基础设施领域,数据库技术的自主可控具有战略意义。金仓数据库的完全自主知识产权为企业提供了可靠的技术选择。
二:兼容性挑战的深度剖析
2.1 数据类型系统差异
数据类型是数据库设计的基础,Oracle和金仓数据库在数据类型定义和使用上存在诸多差异,这是迁移过程中最早遇到的技术挑战。
2.1.1 数值类型映射策略
数值类型的差异需要仔细处理,以确保数据的精确性和业务逻辑的正确性。
-- Oracle数值类型示例
CREATE TABLE oracle_financial_data (
account_id NUMBER(10) PRIMARY KEY,
-- NUMBER类型在不同精度下的处理
balance NUMBER(15,2), -- 金融金额,保留2位小数
interest_rate NUMBER(5,4), -- 利率,4位小数
transaction_count NUMBER, -- 无精度限制的整数
metric_value FLOAT(5) -- 浮点数
);
-- 金仓数据库数值类型映射
CREATE TABLE kingbase_financial_data (
account_id NUMERIC(10) PRIMARY KEY,
-- NUMERIC类型对应Oracle的NUMBER
balance NUMERIC(15,2),
-- 注意:金仓NUMERIC的精度和标度处理方式
interest_rate NUMERIC(5,4),
-- 对于无精度限制的情况,需要考虑性能影响
transaction_count NUMERIC, -- 或使用BIGINT如果确定是整数
-- 浮点数类型的映射
metric_value REAL -- REAL对应单精度浮点
);
-- 数值运算的差异
-- Oracle中的数值运算
SELECT balance * (1 + interest_rate) FROM oracle_financial_data;
-- 金仓数据库数值运算注意事项
-- 1. 注意整数除法的行为差异
SELECT 5 / 2; -- 在Oracle中返回2.5,在金仓中返回2(整数除法)
-- 正确的写法
SELECT 5::NUMERIC / 2; -- 显式转换为NUMERIC类型迁移策略建议:
-
对于金融等对精度要求高的场景,使用NUMERIC类型并明确指定精度和标度
-
对于确定是整数的字段,考虑使用INTEGER或BIGINT以提高性能
-
注意数值运算中的类型转换,避免精度丢失
2.1.2 日期时间类型处理
日期时间类型是迁移中最容易出错的环节之一,需要特别关注时区、精度和函数使用的差异。
-- Oracle日期时间相关定义
CREATE TABLE oracle_schedule (
event_id NUMBER PRIMARY KEY,
-- 日期类型
start_date DATE, -- 包含日期和时间
end_date DATE,
-- 时间戳类型
created_at TIMESTAMP, -- 默认精度
updated_at TIMESTAMP(6), -- 微秒精度
-- 带时区的时间戳
event_time TIMESTAMP WITH TIME ZONE,
-- 时间间隔
duration INTERVAL DAY(3) TO SECOND(2)
);
-- 金仓数据库日期时间映射
CREATE TABLE kingbase_schedule (
event_id INTEGER PRIMARY KEY,
-- DATE类型只包含日期,不包含时间
start_date DATE,
end_date DATE,
-- 对于需要时间的字段,使用TIMESTAMP
start_time TIMESTAMP, -- 对应Oracle的DATE
end_time TIMESTAMP,
-- 时间戳精度
created_at TIMESTAMP(6), -- 明确指定精度
updated_at TIMESTAMP(6),
-- 时区处理
event_time TIMESTAMP WITH TIME ZONE,
-- 时间间隔类型
duration INTERVAL
);
-- 日期时间函数差异
-- Oracle日期函数
SELECT
SYSDATE,
ADD_MONTHS(SYSDATE, 1),
LAST_DAY(SYSDATE),
MONTHS_BETWEEN(SYSDATE, TO_DATE('2023-01-01', 'YYYY-MM-DD'))
FROM DUAL;
-- 金仓数据库日期函数
SELECT
CURRENT_DATE, -- 当前日期
CURRENT_TIMESTAMP, -- 当前时间戳
-- 月份加减
CURRENT_DATE + INTERVAL '1 month',
-- 获取月份最后一天
DATE_TRUNC('MONTH', CURRENT_DATE) + INTERVAL '1 month' - INTERVAL '1 day',
-- 月份差计算
EXTRACT(YEAR FROM AGE(CURRENT_DATE, '2023-01-01')) * 12 +
EXTRACT(MONTH FROM AGE(CURRENT_DATE, '2023-01-01'))关键迁移注意事项:
-
Oracle的DATE类型包含时间部分,而金仓的DATE只包含日期,需要TIMESTAMP来存储日期时间
-
时区处理逻辑需要重新设计,金仓数据库的时区支持与Oracle有差异
-
日期函数语法不同,需要重写相关业务逻辑
2.1.3 字符串和二进制类型
字符串类型的处理需要考虑字符集、排序规则和存储方式的差异。
-- Oracle字符串类型
CREATE TABLE oracle_document (
doc_id NUMBER PRIMARY KEY,
-- 可变长度字符串
title VARCHAR2(200 CHAR), -- 按字符计算长度
-- 固定长度字符串
code CHAR(10 BYTE), -- 按字节计算长度
-- 大文本
content CLOB,
-- 二进制数据
attachment BLOB,
-- 国家字符集
ncontent NCLOB
);
-- 金仓数据库字符串类型映射
CREATE TABLE kingbase_document (
doc_id INTEGER PRIMARY KEY,
-- VARCHAR按字符计算长度
title VARCHAR(200),
-- CHAR类型
code CHAR(10),
-- 文本类型
content TEXT,
-- 二进制类型
attachment BYTEA,
-- Unicode支持通过字符集实现
ncontent TEXT
);
-- 字符串函数差异
-- Oracle字符串处理
SELECT
SUBSTR('金仓数据库', 2, 3), -- 返回'仓数据'
INSTR('金仓数据库', '数据'), -- 返回3
LENGTH('金仓数据库'), -- 返回5(字符数)
LENGTHB('金仓数据库') -- 返回字节数
FROM DUAL;
-- 金仓数据库字符串函数
SELECT
SUBSTRING('金仓数据库' FROM 2 FOR 3), -- 返回'仓数据'
POSITION('数据' IN '金仓数据库'), -- 返回3
CHAR_LENGTH('金仓数据库'), -- 返回5(字符数)
OCTET_LENGTH('金仓数据库') -- 返回字节数字符集处理策略:
-
迁移前评估源数据库的字符集设置
-
金仓数据库默认使用UTF-8字符集,确保数据迁移时正确转换
-
注意多字节字符的长度计算差异
2.2 SQL语言兼容性分析
SQL语言的兼容性是迁移成功的关键,需要详细分析DDL、DML、查询等各个方面的差异。
2.2.1 数据定义语言(DDL)差异
-- 1. 表定义差异
-- Oracle表定义
CREATE TABLE oracle_employee (
emp_id NUMBER(10) PRIMARY KEY,
emp_name VARCHAR2(100) NOT NULL,
salary NUMBER(10,2) DEFAULT 0,
hire_date DATE DEFAULT SYSDATE,
-- 虚拟列
annual_salary AS (salary * 12)
) TABLESPACE users;
-- 金仓数据库表定义
CREATE TABLE kingbase_employee (
emp_id INTEGER PRIMARY KEY,
emp_name VARCHAR(100) NOT NULL,
salary NUMERIC(10,2) DEFAULT 0,
hire_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- 生成列
annual_salary NUMERIC GENERATED ALWAYS AS (salary * 12) STORED
);
-- 2. 索引定义差异
-- Oracle索引
CREATE INDEX idx_oracle_emp_name ON oracle_employee(emp_name)
TABLESPACE index_ts;
-- 函数索引
CREATE INDEX idx_oracle_upper_name ON oracle_employee(UPPER(emp_name));
-- 金仓数据库索引
CREATE INDEX idx_kingbase_emp_name ON kingbase_employee(emp_name);
-- 函数索引
CREATE INDEX idx_kingbase_upper_name ON kingbase_employee(UPPER(emp_name));
-- 3. 约束定义
-- Oracle约束
ALTER TABLE oracle_employee ADD CONSTRAINT ck_salary
CHECK (salary >= 0);
-- 金仓数据库约束
ALTER TABLE kingbase_employee ADD CONSTRAINT ck_salary
CHECK (salary >= 0);2.2.2 数据操作语言(DML)差异
-- 1. INSERT语句差异
-- Oracle INSERT
INSERT INTO oracle_employee (emp_id, emp_name, salary)
VALUES (1, '张三', 5000);
-- 多表插入(Oracle特有)
INSERT ALL
INTO emp_details (emp_id, detail) VALUES (1, 'Detail 1')
INTO emp_history (emp_id, action) VALUES (1, 'Hired')
SELECT 1 FROM DUAL;
-- 金仓数据库INSERT
INSERT INTO kingbase_employee (emp_id, emp_name, salary)
VALUES (1, '张三', 5000);
-- 2. UPDATE语句差异
-- Oracle UPDATE
UPDATE oracle_employee
SET salary = salary * 1.1
WHERE emp_id = 1
RETURNING salary INTO :new_salary;
-- 金仓数据库UPDATE
UPDATE kingbase_employee
SET salary = salary * 1.1
WHERE emp_id = 1
RETURNING salary;
-- 3. DELETE语句差异
-- Oracle DELETE
DELETE FROM oracle_employee
WHERE emp_id = 1
RETURNING emp_name INTO :deleted_name;
-- 金仓数据库DELETE
DELETE FROM kingbase_employee
WHERE emp_id = 1
RETURNING emp_name;2.2.3 查询语句差异
查询语句的差异主要体现在连接语法、子查询、分析函数等方面。
-- 1. 连接语法差异
-- Oracle外连接(旧语法)
SELECT e.emp_name, d.dept_name
FROM oracle_employee e, oracle_department d
WHERE e.dept_id = d.dept_id(+); -- 左外连接
-- Oracle标准外连接
SELECT e.emp_name, d.dept_name
FROM oracle_employee e
LEFT JOIN oracle_department d ON e.dept_id = d.dept_id;
-- 金仓数据库只支持标准连接语法
SELECT e.emp_name, d.dept_name
FROM kingbase_employee e
LEFT JOIN kingbase_department d ON e.dept_id = d.dept_id;
-- 2. 层次查询差异
-- Oracle层次查询
SELECT emp_id, emp_name, manager_id, LEVEL
FROM oracle_employee
START WITH manager_id IS NULL
CONNECT BY PRIOR emp_id = manager_id
ORDER SIBLINGS BY emp_name;
-- 金仓数据库使用递归CTE
WITH RECURSIVE emp_hierarchy AS (
-- 锚点查询
SELECT emp_id, emp_name, manager_id, 1 as level
FROM kingbase_employee
WHERE manager_id IS NULL
UNION ALL
-- 递归查询
SELECT e.emp_id, e.emp_name, e.manager_id, eh.level + 1
FROM kingbase_employee e
JOIN emp_hierarchy eh ON e.manager_id = eh.emp_id
)
SELECT * FROM emp_hierarchy
ORDER BY level, emp_name;
-- 3. 分析函数差异
-- Oracle分析函数
SELECT
emp_id,
emp_name,
salary,
AVG(salary) OVER (PARTITION BY dept_id) as dept_avg_salary,
RANK() OVER (ORDER BY salary DESC) as salary_rank,
LEAD(salary, 1) OVER (ORDER BY emp_id) as next_salary
FROM oracle_employee;
-- 金仓数据库分析函数(语法基本兼容)
SELECT
emp_id,
emp_name,
salary,
AVG(salary) OVER (PARTITION BY dept_id) as dept_avg_salary,
RANK() OVER (ORDER BY salary DESC) as salary_rank,
LEAD(salary, 1) OVER (ORDER BY emp_id) as next_salary
FROM kingbase_employee;2.3 存储过程和函数迁移
存储过程和函数是迁移中最复杂的部分,涉及语法、内置函数、异常处理等多方面差异。
2.3.1 基本结构转换
-- Oracle存储过程示例
CREATE OR REPLACE PROCEDURE process_salary_bonus (
p_employee_id IN NUMBER,
p_bonus_percent IN NUMBER,
p_total_salary OUT NUMBER
)
IS
v_base_salary NUMBER;
v_bonus_amount NUMBER;
v_error_message VARCHAR2(200);
BEGIN
-- 查询基本工资
SELECT salary INTO v_base_salary
FROM employees
WHERE employee_id = p_employee_id;
-- 计算奖金
v_bonus_amount := v_base_salary * p_bonus_percent / 100;
-- 更新工资
UPDATE employees
SET salary = salary + v_bonus_amount,
last_updated = SYSDATE
WHERE employee_id = p_employee_id;
-- 返回总工资
p_total_salary := v_base_salary + v_bonus_amount;
-- 提交事务
COMMIT;
DBMS_OUTPUT.PUT_LINE('处理完成: 员工' || p_employee_id);
EXCEPTION
WHEN NO_DATA_FOUND THEN
v_error_message := '员工不存在: ' || p_employee_id;
ROLLBACK;
RAISE_APPLICATION_ERROR(-20001, v_error_message);
WHEN OTHERS THEN
v_error_message := '未知错误: ' || SQLERRM;
ROLLBACK;
RAISE_APPLICATION_ERROR(-20002, v_error_message);
END;
/
-- 金仓数据库存储过程转换
CREATE OR REPLACE PROCEDURE process_salary_bonus (
p_employee_id INTEGER,
p_bonus_percent NUMERIC,
INOUT p_total_salary NUMERIC
)
LANGUAGE plpgsql
AS $$
DECLARE
v_base_salary NUMERIC;
v_bonus_amount NUMERIC;
v_error_message TEXT;
BEGIN
-- 查询基本工资
SELECT salary INTO v_base_salary
FROM employees
WHERE employee_id = p_employee_id;
-- 检查是否找到数据
IF NOT FOUND THEN
v_error_message := '员工不存在: ' || p_employee_id;
RAISE EXCEPTION '%', v_error_message USING ERRCODE = '20001';
END IF;
-- 计算奖金
v_bonus_amount := v_base_salary * p_bonus_percent / 100;
-- 更新工资
UPDATE employees
SET salary = salary + v_bonus_amount,
last_updated = CURRENT_TIMESTAMP
WHERE employee_id = p_employee_id;
-- 返回总工资
p_total_salary := v_base_salary + v_bonus_amount;
-- 注意:金仓中默认自动提交,这里不显式COMMIT
-- 由调用者控制事务
-- 输出信息(使用RAISE NOTICE替代DBMS_OUTPUT)
RAISE NOTICE '处理完成: 员工%', p_employee_id;
EXCEPTION
WHEN OTHERS THEN
-- 获取错误信息
GET STACKED DIAGNOSTICS v_error_message = MESSAGE_TEXT;
RAISE EXCEPTION '处理工资奖金时出错: %', v_error_message;
END;
$$;2.3.2 内置包函数迁移
Oracle的内置包(如DBMS_OUTPUT、DBMS_SQL、DBMS_JOB等)在金仓数据库中需要找到相应的替代方案。
-- Oracle DBMS_OUTPUT使用
DECLARE
v_message VARCHAR2(100) := '调试信息';
BEGIN
DBMS_OUTPUT.ENABLE(1000000);
DBMS_OUTPUT.PUT_LINE('开始处理: ' || v_message);
-- 业务逻辑
DBMS_OUTPUT.PUT_LINE('处理完成');
END;
/
-- 金仓数据库替代方案
DO $$
DECLARE
v_message TEXT := '调试信息';
BEGIN
-- 使用RAISE NOTICE输出调试信息
RAISE NOTICE '开始处理: %', v_message;
-- 业务逻辑
RAISE NOTICE '处理完成';
END;
$$;
-- Oracle DBMS_SQL动态SQL
DECLARE
v_cursor_id INTEGER;
v_rows_processed INTEGER;
BEGIN
v_cursor_id := DBMS_SQL.OPEN_CURSOR;
DBMS_SQL.PARSE(v_cursor_id, 'UPDATE employees SET salary = salary * 1.1', DBMS_SQL.NATIVE);
v_rows_processed := DBMS_SQL.EXECUTE(v_cursor_id);
DBMS_SQL.CLOSE_CURSOR(v_cursor_id);
DBMS_OUTPUT.PUT_LINE('更新了' || v_rows_processed || '行');
END;
/
-- 金仓数据库动态SQL
DO $$
DECLARE
v_sql TEXT;
v_rows_affected INTEGER;
BEGIN
v_sql := 'UPDATE employees SET salary = salary * 1.1';
EXECUTE v_sql;
GET DIAGNOSTICS v_rows_affected = ROW_COUNT;
RAISE NOTICE '更新了%行', v_rows_affected;
END;
$$;2.4 事务处理和并发控制
事务处理和并发控制的差异直接影响应用的稳定性和性能。
2.4.1 事务隔离级别实现差异
sql
-- Oracle事务隔离级别
-- Oracle默认使用READ COMMITTED隔离级别
-- 但实现方式与标准SQL有所不同
-- 设置事务隔离级别(Oracle)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 金仓数据库事务隔离级别
-- 支持标准SQL的四个隔离级别
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 或者在会话级别设置
SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 隔离级别差异对比
/*
Oracle的READ COMMITTED:
- 基于多版本并发控制(MVCC)
- 使用回滚段存储旧版本数据
- 查询只能看到在查询开始前已提交的数据
金仓数据库的READ COMMITTED:
- 基于MVCC和快照隔离
- 使用多版本存储
- 每个语句看到的是语句开始时的快照
重要区别:
1. 幻读处理:Oracle的SERIALIZABLE级别通过乐观锁实现,
而金仓使用标准的基于锁的SERIALIZABLE
2. 死锁检测:两者的死锁检测和解决机制不同
*/2.4.2 锁机制差异
sql
-- Oracle锁机制示例
-- 行级排他锁
SELECT * FROM employees
WHERE department_id = 10
FOR UPDATE NOWAIT;
-- 表级锁
LOCK TABLE employees IN EXCLUSIVE MODE NOWAIT;
-- 金仓数据库锁机制
-- 行级锁
SELECT * FROM employees
WHERE department_id = 10
FOR UPDATE;
-- 添加NOWAIT选项
SELECT * FROM employees
WHERE department_id = 10
FOR UPDATE NOWAIT;
-- 表级锁
LOCK TABLE employees IN EXCLUSIVE MODE;
-- 锁超时设置
SET lock_timeout = '5s'; -- 设置锁等待超时为5秒
-- 死锁处理差异
/*
Oracle死锁处理:
- 自动检测死锁
- 选择代价最小的事务进行回滚
- 抛出ORA-00060错误
金仓数据库死锁处理:
- 自动检测死锁
- 终止后发起的事务
- 抛出死锁检测错误
*/
-- 死锁避免最佳实践
BEGIN;
-- 按照相同顺序访问表
SELECT * FROM table_a WHERE id = 1 FOR UPDATE;
SELECT * FROM table_b WHERE id = 2 FOR UPDATE;
-- 业务逻辑
COMMIT;
-- 使用锁超时避免长时间等待
SET LOCAL lock_timeout = '2s';
SELECT * FROM table_a WHERE id = 1 FOR UPDATE;三:迁移成本分析与控制策略
3.1 迁移成本的多维度分析
数据库迁移的成本是多维度的,需要从技术、人力、时间、风险等多个角度进行全面评估。
3.1.1 直接成本构成
软件许可成本:
-
金仓数据库许可证费用
-
第三方工具许可费用(如迁移工具、测试工具)
-
中间件和配套软件费用
硬件基础设施成本:
-
服务器硬件成本(可能需要新的服务器)
-
存储设备成本(考虑性能需求和容量规划)
-
网络设备成本(可能需要升级网络带宽)
云计算资源成本(如果采用云部署):
-
云服务器实例费用
-
云存储费用
-
网络流量费用
-
数据库服务管理费用
3.1.2 间接成本分析
人力成本:
-
迁移团队人员成本(项目经理、DBA、开发人员、测试人员)
-
培训和学习成本
-
知识转移成本
时间成本:
-
迁移项目周期时间
-
并行运行期间的双倍运维成本
-
业务影响时间(性能下降、功能不可用等)
机会成本:
-
迁移期间无法开展的其他项目
-
市场机会的损失
-
技术创新的延迟
风险成本:
-
迁移失败导致的业务中断损失
-
数据丢失或损坏的风险
-
性能不达标导致的用户体验下降
3.2 成本控制最佳实践
3.2.1 迁移前评估与规划
数据库规模评估工具:
sql
#!/usr/bin/env python3
"""
Oracle数据库迁移评估工具
用于评估从Oracle迁移到金仓数据库的成本和复杂度
"""
import cx_Oracle
import logging
from dataclasses import dataclass
from typing import Dict, List, Any
from datetime import datetime
@dataclass
class DatabaseObject:
"""数据库对象基类"""
name: str
type: str
size_mb: float = 0.0
complexity_score: int = 0 # 复杂度评分,1-10
@dataclass
class TableInfo(DatabaseObject):
"""表信息"""
row_count: int = 0
column_count: int = 0
index_count: int = 0
constraint_count: int = 0
partition_count: int = 0
has_lob: bool = False
@dataclass
class ProcedureInfo(DatabaseObject):
"""存储过程信息"""
line_count: int = 0
oracle_specific_features: List[str] = None
class OracleMigrationAssessor:
"""Oracle迁移评估器"""
def __init__(self, oracle_dsn, username, password):
self.oracle_dsn = oracle_dsn
self.username = username
self.password = password
self.logger = self._setup_logger()
self.connection = None
self.assessment_results = {}
def _setup_logger(self):
"""设置日志"""
logger = logging.getLogger('OracleMigrationAssessor')
logger.setLevel(logging.INFO)
# 文件处理器
fh = logging.FileHandler(f'assessment_{datetime.now():%Y%m%d_%H%M%S}.log')
fh.setLevel(logging.INFO)
# 控制台处理器
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)
return logger
def connect(self):
"""连接Oracle数据库"""
try:
self.connection = cx_Oracle.connect(
user=self.username,
password=self.password,
dsn=self.oracle_dsn
)
self.logger.info("成功连接到Oracle数据库")
return True
except cx_Oracle.Error as e:
self.logger.error(f"连接Oracle数据库失败: {e}")
return False
def assess_database_size(self):
"""评估数据库大小"""
query = """
SELECT
SUM(bytes)/1024/1024 as total_size_mb,
COUNT(*) as object_count
FROM user_segments
"""
with self.connection.cursor() as cursor:
cursor.execute(query)
result = cursor.fetchone()
total_size_mb = result[0] or 0
object_count = result[1] or 0
self.assessment_results['database_size'] = {
'total_size_mb': total_size_mb,
'object_count': object_count
}
self.logger.info(f"数据库总大小: {total_size_mb:.2f} MB")
self.logger.info(f"数据库对象总数: {object_count}")
return total_size_mb, object_count
def assess_tables(self):
"""评估表信息"""
query = """
SELECT
t.table_name,
t.num_rows,
COUNT(c.column_name) as column_count,
COUNT(i.index_name) as index_count,
SUM(s.bytes)/1024/1024 as size_mb,
CASE WHEN COUNT(l.column_name) > 0 THEN 1 ELSE 0 END as has_lob
FROM user_tables t
LEFT JOIN user_tab_columns c ON t.table_name = c.table_name
LEFT JOIN user_indexes i ON t.table_name = i.table_name
LEFT JOIN user_segments s ON t.table_name = s.segment_name
LEFT JOIN user_lobs l ON t.table_name = l.table_name
GROUP BY t.table_name, t.num_rows
ORDER BY size_mb DESC NULLS LAST
"""
tables = []
with self.connection.cursor() as cursor:
cursor.execute(query)
for row in cursor:
table_name, num_rows, column_count, index_count, size_mb, has_lob = row
# 计算复杂度评分
complexity_score = self._calculate_table_complexity(
column_count, index_count, has_lob
)
table_info = TableInfo(
name=table_name,
type='TABLE',
size_mb=size_mb or 0,
complexity_score=complexity_score,
row_count=num_rows or 0,
column_count=column_count or 0,
index_count=index_count or 0,
has_lob=bool(has_lob)
)
tables.append(table_info)
self.assessment_results['tables'] = tables
self.logger.info(f"评估完成,共 {len(tables)} 个表")
return tables
def assess_procedures(self):
"""评估存储过程和函数"""
query = """
SELECT
object_name,
object_type,
source
FROM user_source
WHERE object_type IN ('PROCEDURE', 'FUNCTION', 'PACKAGE', 'PACKAGE BODY')
ORDER BY object_name, line
"""
procedures = {}
with self.connection.cursor() as cursor:
cursor.execute(query)
for object_name, object_type, source_line in cursor:
if object_name not in procedures:
procedures[object_name] = {
'type': object_type,
'source': [],
'oracle_features': set()
}
procedures[object_name]['source'].append(source_line)
# 分析Oracle特有特性
procedure_infos = []
oracle_features_patterns = {
'DBMS_': 'Oracle内置包',
'UTL_': 'Oracle工具包',
'CONNECT BY': '层次查询',
'ROWNUM': '行号伪列',
'MERGE': '合并语句',
'BULK COLLECT': '批量收集',
'FORALL': '批量操作'
}
for proc_name, proc_info in procedures.items():
source_text = '\n'.join(proc_info['source'])
line_count = len(proc_info['source'])
# 检测Oracle特有特性
oracle_features = []
for pattern, feature_name in oracle_features_patterns.items():
if pattern in source_text.upper():
oracle_features.append(feature_name)
# 计算复杂度评分
complexity_score = min(10, line_count // 50 + len(oracle_features))
procedure_info = ProcedureInfo(
name=proc_name,
type=proc_info['type'],
line_count=line_count,
oracle_specific_features=oracle_features,
complexity_score=complexity_score
)
procedure_infos.append(procedure_info)
if oracle_features:
self.logger.info(
f"存储过程 {proc_name} 包含Oracle特有特性: {oracle_features}"
)
self.assessment_results['procedures'] = procedure_infos
self.logger.info(f"评估完成,共 {len(procedure_infos)} 个存储过程/函数")
return procedure_infos
def _calculate_table_complexity(self, column_count, index_count, has_lob):
"""计算表复杂度评分"""
score = 0
# 基于列数
if column_count > 50:
score += 3
elif column_count > 20:
score += 2
elif column_count > 10:
score += 1
# 基于索引数
if index_count > 10:
score += 3
elif index_count > 5:
score += 2
elif index_count > 2:
score += 1
# 基于LOB字段
if has_lob:
score += 2
return min(score, 10) # 最高10分
def estimate_migration_effort(self):
"""估算迁移工作量"""
total_effort_days = 0
# 表迁移工作量
tables = self.assessment_results.get('tables', [])
for table in tables:
# 基础工作量:每个表0.5天
table_effort = 0.5
# 复杂度加成
table_effort += table.complexity_score * 0.2
# 数据量加成(每百万行增加0.1天)
if table.row_count:
table_effort += (table.row_count / 1000000) * 0.1
total_effort_days += table_effort
# 存储过程迁移工作量
procedures = self.assessment_results.get('procedures', [])
for proc in procedures:
# 基础工作量:每个存储过程1天
proc_effort = 1.0
# 行数加成(每50行增加0.1天)
proc_effort += (proc.line_count / 50) * 0.1
# Oracle特性加成
if proc.oracle_specific_features:
proc_effort += len(proc.oracle_specific_features) * 0.5
total_effort_days += proc_effort
# 其他对象(视图、序列、触发器等)
other_count = self.assessment_results.get('database_size', {}).get('object_count', 0)
other_count -= len(tables) + len(procedures)
if other_count > 0:
total_effort_days += other_count * 0.2
# 测试和验证工作量(占总工作量的50%)
total_effort_days *= 1.5
self.assessment_results['migration_effort'] = {
'estimated_days': total_effort_days,
'estimated_weeks': total_effort_days / 5,
'estimated_months': total_effort_days / 20
}
self.logger.info(f"预计迁移工作量: {total_effort_days:.1f} 人天")
self.logger.info(f"约合 {total_effort_days/5:.1f} 周")
self.logger.info(f"约合 {total_effort_days/20:.1f} 月")
return total_effort_days
def generate_assessment_report(self, output_file='migration_assessment_report.html'):
"""生成评估报告"""
from jinja2 import Template
# HTML模板
template_str = """
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Oracle到金仓数据库迁移评估报告</title>
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
h1, h2, h3 { color: #333; }
table { border-collapse: collapse; width: 100%; margin-bottom: 20px; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background-color: #f2f2f2; }
.complexity-high { background-color: #ffcccc; }
.complexity-medium { background-color: #ffffcc; }
.complexity-low { background-color: #ccffcc; }
.summary { background-color: #f9f9f9; padding: 15px; border-radius: 5px; }
</style>
</head>
<body>
<h1>Oracle到金仓数据库迁移评估报告</h1>
<p>生成时间: {{ generation_time }}</p>
<div class="summary">
<h2>评估摘要</h2>
<p>数据库总大小: {{ "%.2f"|format(assessment.database_size.total_size_mb) }} MB</p>
<p>数据库对象总数: {{ assessment.database_size.object_count }}</p>
<p>表数量: {{ assessment.tables|length }}</p>
<p>存储过程/函数数量: {{ assessment.procedures|length }}</p>
<p><strong>预计迁移工作量: {{ "%.1f"|format(assessment.migration_effort.estimated_days) }} 人天</strong></p>
</div>
<h2>表分析</h2>
<table>
<tr>
<th>表名</th>
<th>行数</th>
<th>列数</th>
<th>大小(MB)</th>
<th>复杂度评分</th>
<th>LOB字段</th>
</tr>
{% for table in assessment.tables %}
<tr class="complexity-{{ 'high' if table.complexity_score > 7 else 'medium' if table.complexity_score > 4 else 'low' }}">
<td>{{ table.name }}</td>
<td>{{ "{:,}".format(table.row_count) }}</td>
<td>{{ table.column_count }}</td>
<td>{{ "%.2f"|format(table.size_mb) }}</td>
<td>{{ table.complexity_score }}/10</td>
<td>{{ '是' if table.has_lob else '否' }}</td>
</tr>
{% endfor %}
</table>
<h2>存储过程分析</h2>
<table>
<tr>
<th>名称</th>
<th>类型</th>
<th>行数</th>
<th>Oracle特有特性</th>
<th>复杂度评分</th>
</tr>
{% for proc in assessment.procedures %}
<tr class="complexity-{{ 'high' if proc.complexity_score > 7 else 'medium' if proc.complexity_score > 4 else 'low' }}">
<td>{{ proc.name }}</td>
<td>{{ proc.type }}</td>
<td>{{ proc.line_count }}</td>
<td>{{ proc.oracle_specific_features|join(', ') if proc.oracle_specific_features else '无' }}</td>
<td>{{ proc.complexity_score }}/10</td>
</tr>
{% endfor %}
</table>
<h2>迁移建议</h2>
<ul>
<li>优先迁移复杂度低的表和存储过程</li>
<li>对于包含Oracle特有特性的存储过程,建议重写或寻找替代方案</li>
<li>LOB字段需要特别处理,考虑性能影响</li>
<li>建议分阶段迁移,降低风险</li>
</ul>
</body>
</html>
"""
template = Template(template_str)
html_content = template.render(
assessment=self.assessment_results,
generation_time=datetime.now().strftime('%Y-%m-%d %H:%M:%S')
)
with open(output_file, 'w', encoding='utf-8') as f:
f.write(html_content)
self.logger.info(f"评估报告已生成: {output_file}")
return output_file
def run_full_assessment(self):
"""运行完整评估"""
self.logger.info("开始Oracle数据库迁移评估")
if not self.connect():
return None
try:
# 执行各项评估
self.assess_database_size()
self.assess_tables()
self.assess_procedures()
self.estimate_migration_effort()
# 生成报告
report_file = self.generate_assessment_report()
self.logger.info("评估完成")
return self.assessment_results
finally:
if self.connection:
self.connection.close()
# 使用示例
if __name__ == "__main__":
# 配置Oracle连接信息
oracle_config = {
'dsn': 'localhost:1521/orcl',
'username': 'system',
'password': 'oracle'
}
# 创建评估器
assessor = OracleMigrationAssessor(
oracle_dsn=oracle_config['dsn'],
username=oracle_config['username'],
password=oracle_config['password']
)
# 运行评估
results = assessor.run_full_assessment()
if results:
print("\n评估结果摘要:")
print(f"数据库大小: {results['database_size']['total_size_mb']:.2f} MB")
print(f"表数量: {len(results['tables'])}")
print(f"存储过程数量: {len(results['procedures'])}")
print(f"预计工作量: {results['migration_effort']['estimated_days']:.1f} 人天")3.2.2 自动化迁移工具开发
为了降低迁移成本,开发自定义的自动化迁移工具是有效的策略。
sql
#!/usr/bin/env python3
"""
Oracle到金仓数据库自动化迁移工具
处理SQL语法转换和对象迁移
"""
import re
import sqlparse
from sqlparse.sql import Identifier, Function, Comparison
from sqlparse.tokens import Keyword, Name, Punctuation
import logging
from typing import Dict, List, Tuple
from dataclasses import dataclass
@dataclass
class ConversionRule:
"""转换规则定义"""
oracle_pattern: str
kingbase_replacement: str
pattern_type: str # keyword, function, datatype, operator
description: str
class OracleToKingbaseConverter:
"""Oracle到金仓数据库SQL转换器"""
def __init__(self):
self.logger = self._setup_logger()
self.conversion_rules = self._load_conversion_rules()
self.context_stack = [] # 用于跟踪上下文(如存储过程、触发器等)
def _setup_logger(self):
"""设置日志"""
logger = logging.getLogger('SQLConverter')
logger.setLevel(logging.INFO)
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
ch.setFormatter(formatter)
logger.addHandler(ch)
return logger
def _load_conversion_rules(self):
"""加载转换规则"""
rules = []
# 数据类型转换规则
rules.extend([
ConversionRule(
oracle_pattern=r'\bVARCHAR2\b',
kingbase_replacement='VARCHAR',
pattern_type='datatype',
description='字符串类型转换'
),
ConversionRule(
oracle_pattern=r'\bNUMBER\b',
kingbase_replacement='NUMERIC',
pattern_type='datatype',
description='数值类型转换'
),
ConversionRule(
oracle_pattern=r'\bDATE\b',
kingbase_replacement='TIMESTAMP',
pattern_type='datatype',
description='日期类型转换(注意:金仓DATE不包含时间)'
),
ConversionRule(
oracle_pattern=r'\bCLOB\b',
kingbase_replacement='TEXT',
pattern_type='datatype',
description='大文本类型转换'
),
ConversionRule(
oracle_pattern=r'\bBLOB\b',
kingbase_replacement='BYTEA',
pattern_type='datatype',
description='二进制类型转换'
),
])
# 函数转换规则
rules.extend([
ConversionRule(
oracle_pattern=r'\bSYSDATE\b',
kingbase_replacement='CURRENT_TIMESTAMP',
pattern_type='function',
description='系统日期函数转换'
),
ConversionRule(
oracle_pattern=r'\bTO_DATE\(',
kingbase_replacement='TO_TIMESTAMP(',
pattern_type='function',
description='日期转换函数'
),
ConversionRule(
oracle_pattern=r'\bADD_MONTHS\(',
kingbase_replacement='', # 需要特殊处理
pattern_type='function',
description='月份加减函数'
),
ConversionRule(
oracle_pattern=r'\bNVL\(',
kingbase_replacement='COALESCE(',
pattern_type='function',
description='空值处理函数'
),
])
# 关键字转换规则
rules.extend([
ConversionRule(
oracle_pattern=r'\bCONNECT BY\b',
kingbase_replacement='', # 需要重写为递归CTE
pattern_type='keyword',
description='层次查询转换'
),
ConversionRule(
oracle_pattern=r'\bSTART WITH\b',
kingbase_replacement='',
pattern_type='keyword',
description='层次查询开始条件'
),
ConversionRule(
oracle_pattern=r'\bPRIOR\b',
kingbase_replacement='',
pattern_type='keyword',
description='层次查询关键字'
),
])
# 运算符转换规则
rules.extend([
ConversionRule(
oracle_pattern=r'\|\|',
kingbase_replacement='||',
pattern_type='operator',
description='字符串连接运算符(相同但保留)'
),
ConversionRule(
oracle_pattern=r'\bMOD\(',
kingbase_replacement='%',
pattern_type='operator',
description='取模运算'
),
])
return rules
def convert_sql_file(self, input_file: str, output_file: str):
"""转换SQL文件"""
self.logger.info(f"开始转换文件: {input_file}")
try:
with open(input_file, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
# 解析SQL语句
statements = sqlparse.parse(content)
converted_statements = []
for statement in statements:
converted = self.convert_statement(str(statement))
converted_statements.append(converted)
# 写入输出文件
with open(output_file, 'w', encoding='utf-8') as f:
f.write('\n\n'.join(converted_statements))
self.logger.info(f"转换完成,输出文件: {output_file}")
# 生成转换报告
self._generate_conversion_report(input_file, output_file)
return True
except Exception as e:
self.logger.error(f"转换文件时出错: {e}")
return False
def convert_statement(self, sql: str) -> str:
"""转换单个SQL语句"""
# 检测语句类型
statement_type = self._detect_statement_type(sql)
self.logger.debug(f"检测到语句类型: {statement_type}")
# 根据语句类型应用不同的转换策略
if statement_type == 'CREATE_PROCEDURE':
return self._convert_procedure(sql)
elif statement_type == 'CREATE_TABLE':
return self._convert_table_ddl(sql)
elif statement_type == 'SELECT':
return self._convert_select(sql)
elif statement_type == 'INSERT':
return self._convert_insert(sql)
elif statement_type == 'UPDATE':
return self._convert_update(sql)
elif statement_type == 'DELETE':
return self._convert_delete(sql)
else:
# 通用转换
return self._apply_general_conversions(sql)
def _detect_statement_type(self, sql: str) -> str:
"""检测SQL语句类型"""
sql_upper = sql.upper().strip()
if sql_upper.startswith('CREATE OR REPLACE PROCEDURE'):
return 'CREATE_PROCEDURE'
elif sql_upper.startswith('CREATE OR REPLACE FUNCTION'):
return 'CREATE_FUNCTION'
elif sql_upper.startswith('CREATE TABLE'):
return 'CREATE_TABLE'
elif sql_upper.startswith('SELECT'):
return 'SELECT'
elif sql_upper.startswith('INSERT'):
return 'INSERT'
elif sql_upper.startswith('UPDATE'):
return 'UPDATE'
elif sql_upper.startswith('DELETE'):
return 'DELETE'
elif sql_upper.startswith('MERGE'):
return 'MERGE'
else:
return 'UNKNOWN'
def _convert_procedure(self, sql: str) -> str:
"""转换存储过程"""
self.logger.info("开始转换存储过程")
# 提取过程名和参数
proc_match = re.search(
r'CREATE\s+(OR\s+REPLACE\s+)?PROCEDURE\s+(\w+)\s*\((.*?)\)\s*(IS|AS)',
sql, re.IGNORECASE | re.DOTALL
)
if not proc_match:
self.logger.warning("无法解析存储过程定义,使用通用转换")
return self._apply_general_conversions(sql)
proc_name = proc_match.group(2)
params_text = proc_match.group(3)
self.logger.info(f"处理存储过程: {proc_name}")
# 转换参数定义
kingbase_params = self._convert_procedure_params(params_text)
# 转换过程体
# 这里简化处理,实际需要更复杂的解析
converted_sql = self._apply_general_conversions(sql)
# 替换参数定义
converted_sql = re.sub(
r'PROCEDURE\s+\w+\s*\(.*?\)\s*(IS|AS)',
f'PROCEDURE {proc_name}({kingbase_params})',
converted_sql,
flags=re.IGNORECASE | re.DOTALL
)
# 添加语言声明
if 'LANGUAGE' not in converted_sql.upper():
# 在AS或IS后添加LANGUAGE声明
converted_sql = re.sub(
r'\s+(AS|IS)\s+',
r' LANGUAGE plpgsql\1 ',
converted_sql,
flags=re.IGNORECASE
)
return converted_sql
def _convert_procedure_params(self, params_text: str) -> str:
"""转换存储过程参数定义"""
# 分割参数
params = [p.strip() for p in params_text.split(',')]
converted_params = []
for param in params:
if not param:
continue
# 解析参数:param_name [IN|OUT|IN OUT] param_type [DEFAULT value]
param_pattern = r'(\w+)\s+(IN|OUT|IN\s+OUT)?\s*(\w+(?:\(\d+(?:,\d+)?\))?)\s*(DEFAULT\s+.*)?'
match = re.match(param_pattern, param, re.IGNORECASE)
if match:
param_name, direction, param_type, default_value = match.groups()
# 转换数据类型
converted_type = self._convert_data_type(param_type)
# 转换方向(金仓使用INOUT表示输入输出参数)
if direction and 'OUT' in direction.upper():
kingbase_direction = 'INOUT'
else:
kingbase_direction = ''
# 构建参数定义
if kingbase_direction:
converted_param = f'{param_name} {kingbase_direction} {converted_type}'
else:
converted_param = f'{param_name} {converted_type}'
if default_value:
converted_param += f' {default_value}'
converted_params.append(converted_param)
else:
# 无法解析的参数,原样保留
converted_params.append(param)
return ', '.join(converted_params)
def _convert_table_ddl(self, sql: str) -> str:
"""转换表定义DDL"""
self.logger.info("开始转换表定义")
# 应用通用转换
converted_sql = self._apply_general_conversions(sql)
# 特殊处理:移除TABLESPACE子句
converted_sql = re.sub(
r'\s+TABLESPACE\s+\w+',
'',
converted_sql,
flags=re.IGNORECASE
)
# 特殊处理:转换虚拟列
# Oracle: column_name [GENERATED ALWAYS] AS (expression) [VIRTUAL]
# 金仓: column_name data_type GENERATED ALWAYS AS (expression) STORED
virtual_col_pattern = r'(\w+)\s+(?:GENERATED\s+ALWAYS\s+)?AS\s*\((.*?)\)\s*(?:VIRTUAL|$)'
def replace_virtual_column(match):
col_name = match.group(1)
expression = match.group(2)
# 需要推断数据类型,这里简化处理
return f'{col_name} NUMERIC GENERATED ALWAYS AS ({expression}) STORED'
converted_sql = re.sub(
virtual_col_pattern,
replace_virtual_column,
converted_sql,
flags=re.IGNORECASE
)
return converted_sql
def _convert_select(self, sql: str) -> str:
"""转换SELECT语句"""
converted_sql = self._apply_general_conversions(sql)
# 处理层次查询
if 'CONNECT BY' in sql.upper():
converted_sql = self._convert_hierarchical_query(sql)
# 处理ROWNUM
converted_sql = self._convert_rownum(converted_sql)
# 处理分页
converted_sql = self._convert_pagination(converted_sql)
return converted_sql
def _convert_hierarchical_query(self, sql: str) -> str:
"""转换层次查询为递归CTE"""
# 提取层次查询部分
connect_by_match = re.search(
r'START WITH\s+(.*?)\s+CONNECT BY\s+(.*?)(?=\s+(?:ORDER|GROUP|WHERE|$))',
sql,
re.IGNORECASE | re.DOTALL
)
if not connect_by_match:
return sql
start_with = connect_by_match.group(1)
connect_by = connect_by_match.group(2)
# 提取LEVEL、CONNECT_BY_ROOT等伪列的使用
# 这里简化处理,实际需要完整解析SELECT列表
# 构建递归CTE
cte_name = 'hierarchy_cte'
# 解析连接条件中的PRIOR
# Oracle: CONNECT BY PRIOR child = parent
# 递归CTE: JOIN cte ON child = cte.parent
# 这里返回一个占位符,实际需要更复杂的转换
self.logger.warning("检测到层次查询,需要手动重写为递归CTE")
return f"-- 需要手动重写层次查询为递归CTE\n-- 原SQL: {sql[:100]}..."
def _convert_rownum(self, sql: str) -> str:
"""转换ROWNUM伪列"""
# ROWNUM在WHERE子句中的使用
# Oracle: WHERE ROWNUM <= 10
# 金仓: LIMIT 10
# 简单情况:WHERE ROWNUM <= n
rownum_pattern1 = r'WHERE\s+ROWNUM\s*<=\s*(\d+)'
def replace_rownum1(match):
limit_value = match.group(1)
return f'LIMIT {limit_value}'
converted_sql = re.sub(rownum_pattern1, replace_rownum1, sql, flags=re.IGNORECASE)
# 复杂情况:ROWNUM在表达式中,需要更复杂的处理
# 这里简化处理
return converted_sql
def _convert_pagination(self, sql: str) -> str:
"""转换分页查询"""
# Oracle分页模式:使用子查询和ROWNUM
# 这里检测常见分页模式并转换
# 模式1:三层嵌套分页
pattern1 = r'SELECT\s+\*\s+FROM\s*\(\s*SELECT\s+.*?,\s*ROWNUM\s+AS\s+rn\s+FROM\s*\(\s*SELECT\s+(.*?)\s+FROM\s+(.*?)\s+WHERE\s+(.*?)\s+ORDER\s+BY\s+(.*?)\s*\)\s+WHERE\s+ROWNUM\s*<=\s*(\d+)\s*\)\s+WHERE\s+rn\s*>\s*(\d+)'
def replace_pagination1(match):
select_list = match.group(1)
from_clause = match.group(2)
where_clause = match.group(3)
order_by = match.group(4)
page_end = match.group(5)
page_start = match.group(6)
offset = int(page_start)
limit = int(page_end) - offset
return f'SELECT {select_list} FROM {from_clause} WHERE {where_clause} ORDER BY {order_by} LIMIT {limit} OFFSET {offset}'
converted_sql = re.sub(pattern1, replace_pagination1, sql, flags=re.IGNORECASE | re.DOTALL)
return converted_sql
def _convert_data_type(self, oracle_type: str) -> str:
"""转换数据类型"""
oracle_type_upper = oracle_type.upper()
# 基本数据类型映射
type_mapping = {
'VARCHAR2': 'VARCHAR',
'NVARCHAR2': 'VARCHAR',
'CHAR': 'CHAR',
'NCHAR': 'CHAR',
'NUMBER': 'NUMERIC',
'NUMERIC': 'NUMERIC',
'DECIMAL': 'NUMERIC',
'INTEGER': 'INTEGER',
'INT': 'INTEGER',
'SMALLINT': 'SMALLINT',
'FLOAT': 'REAL',
'REAL': 'REAL',
'DOUBLE PRECISION': 'DOUBLE PRECISION',
'DATE': 'TIMESTAMP',
'TIMESTAMP': 'TIMESTAMP',
'CLOB': 'TEXT',
'BLOB': 'BYTEA',
'RAW': 'BYTEA',
'LONG RAW': 'BYTEA',
'ROWID': 'TEXT', # 注意:ROWID需要特殊处理
'UROWID': 'TEXT',
'BOOLEAN': 'BOOLEAN',
}
# 检查是否带精度
if '(' in oracle_type_upper:
base_type = oracle_type_upper.split('(')[0].strip()
if base_type in type_mapping:
# 保留精度信息
precision_part = oracle_type[oracle_type.find('('):]
return type_mapping[base_type] + precision_part
# 不带精度的情况
if oracle_type_upper in type_mapping:
return type_mapping[oracle_type_upper]
# 未知类型,原样返回
return oracle_type
def _apply_general_conversions(self, sql: str) -> str:
"""应用通用转换规则"""
converted_sql = sql
for rule in self.conversion_rules:
try:
if rule.pattern_type == 'function':
# 函数转换需要处理参数
pattern = r'\b' + re.escape(rule.oracle_pattern) + r'\b'
else:
pattern = r'\b' + re.escape(rule.oracle_pattern) + r'\b'
# 特殊处理ADD_MONTHS函数
if rule.oracle_pattern == 'ADD_MONTHS(':
converted_sql = self._convert_add_months(converted_sql)
continue
# 应用替换
if rule.kingbase_replacement:
converted_sql = re.sub(
pattern,
rule.kingbase_replacement,
converted_sql,
flags=re.IGNORECASE
)
except Exception as e:
self.logger.warning(f"应用规则时出错: {rule.description}, 错误: {e}")
return converted_sql
def _convert_add_months(self, sql: str) -> str:
"""转换ADD_MONTHS函数"""
# ADD_MONTHS(date, n) -> date + INTERVAL 'n month'
def replace_add_months(match):
date_expr = match.group(1)
months = match.group(2)
return f'{date_expr} + INTERVAL \'{months} month\''
# 匹配ADD_MONTHS(date, n)
pattern = r'ADD_MONTHS\s*\(\s*(.*?)\s*,\s*(-?\d+)\s*\)'
return re.sub(pattern, replace_add_months, sql, flags=re.IGNORECASE)
def _convert_insert(self, sql: str) -> str:
"""转换INSERT语句"""
converted_sql = self._apply_general_conversions(sql)
# 处理多表插入(Oracle特有)
if 'INSERT ALL' in sql.upper():
self.logger.warning("检测到多表插入,需要手动重写")
converted_sql = f"-- 需要手动重写多表插入\n-- 原SQL: {sql[:100]}..."
return converted_sql
def _convert_update(self, sql: str) -> str:
"""转换UPDATE语句"""
converted_sql = self._apply_general_conversions(sql)
# 处理RETURNING子句
# Oracle: RETURNING column INTO variable
# 金仓: RETURNING column
returning_pattern = r'RETURNING\s+(.*?)\s+INTO\s+\:?(\w+)'
def replace_returning(match):
columns = match.group(1)
# 金仓中不需要INTO子句
return f'RETURNING {columns}'
converted_sql = re.sub(returning_pattern, replace_returning, converted_sql,
flags=re.IGNORECASE)
return converted_sql
def _convert_delete(self, sql: str) -> str:
"""转换DELETE语句"""
return self._apply_general_conversions(sql)
def _generate_conversion_report(self, input_file: str, output_file: str):
"""生成转换报告"""
report = f"""
Oracle到金仓数据库SQL转换报告
===============================
转换时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
输入文件: {input_file}
输出文件: {output_file}
转换规则应用情况:
"""
# 统计各类型转换规则的应用
rule_stats = {}
for rule in self.conversion_rules:
rule_stats[rule.description] = 0
# 这里可以添加更详细的统计信息
report += "\n注意事项:\n"
report += "1. 层次查询需要手动重写为递归CTE\n"
report += "2. 多表插入需要手动重写为多个INSERT语句\n"
report += "3. 存储过程参数方向需要检查(INOUT转换)\n"
report += "4. 虚拟列语法已转换,但可能需要调整数据类型\n"
# 写入报告文件
report_file = output_file.replace('.sql', '_report.txt')
with open(report_file, 'w', encoding='utf-8') as f:
f.write(report)
self.logger.info(f"转换报告已生成: {report_file}")
# 使用示例
if __name__ == "__main__":
# 创建转换器
converter = OracleToKingbaseConverter()
# 转换单个文件
input_sql = "oracle_schema.sql"
output_sql = "kingbase_schema_converted.sql"
success = converter.convert_sql_file(input_sql, output_sql)
if success:
print(f"转换成功,结果保存在 {output_sql}")
else:
print("转换失败")3.3 性能优化与成本控制
迁移后的性能优化直接影响系统的运行成本和用户体验。
3.3.1 查询性能优化
sql
-- 1. 索引策略优化
-- Oracle迁移后常见的索引问题
-- 问题:迁移后索引失效或性能不佳
-- 分析索引使用情况
SELECT
schemaname,
tablename,
indexname,
idx_scan as index_scans,
idx_tup_read as tuples_read,
idx_tup_fetch as tuples_fetched
FROM pg_stat_user_indexes
ORDER BY idx_scan DESC;
-- 创建适合金仓数据库的索引
-- 覆盖索引优化
CREATE INDEX idx_employee_covering ON employees
(company_id, department_id, hire_date)
INCLUDE (salary, bonus);
-- 条件索引(部分索引)
CREATE INDEX idx_active_employees ON employees (employee_id)
WHERE active = true;
-- 2. 查询重写优化
-- Oracle风格的查询(可能性能不佳)
SELECT e.employee_name, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+)
AND e.hire_date > ADD_MONTHS(SYSDATE, -12);
-- 优化为金仓数据库最佳实践
SELECT e.employee_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id
WHERE e.hire_date > CURRENT_DATE - INTERVAL '1 year'
AND e.active = true;
-- 3. 分区表优化
-- 创建分区表
CREATE TABLE sales (
sale_id INTEGER,
sale_date DATE,
customer_id INTEGER,
amount NUMERIC(10,2),
region VARCHAR(20)
)
PARTITION BY RANGE (sale_date);
-- 创建月份分区
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
CREATE TABLE sales_2023_02 PARTITION OF sales
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01');
-- 分区表查询优化
-- 使用分区键的条件可以提升查询性能
EXPLAIN ANALYZE
SELECT * FROM sales
WHERE sale_date >= '2023-01-15'
AND sale_date < '2023-02-15';
-- 4. 物化视图优化
-- 创建物化视图
CREATE MATERIALIZED VIEW monthly_sales_summary AS
SELECT
DATE_TRUNC('month', sale_date) as month,
region,
COUNT(*) as transaction_count,
SUM(amount) as total_amount,
AVG(amount) as average_amount
FROM sales
GROUP BY DATE_TRUNC('month', sale_date), region;
-- 创建物化视图索引
CREATE INDEX idx_monthly_sales_month ON monthly_sales_summary (month);
CREATE INDEX idx_monthly_sales_region ON monthly_sales_summary (region);
-- 刷新物化视图
REFRESH MATERIALIZED VIEW CONCURRENTLY monthly_sales_summary;3.3.2 配置优化建议
金仓数据库的配置优化对于性能提升至关重要,特别是在迁移后的调优阶段。
四:迁移实施路线图与最佳实践总结
4.1 金仓数据库迁移实施路线图
4.1.1 分阶段迁移策略设计
成功的数据库迁移需要一个精心设计的路线图。以下是推荐的六阶段迁移策略:
第一阶段:评估与规划(2-4周)
sql
# 迁移规划评估脚本示例
class MigrationRoadmapPlanner:
def __init__(self, system_complexity):
self.phases = {
'assessment': {
'duration_weeks': 2,
'activities': [
'系统架构分析',
'兼容性评估',
'工作量估算',
'风险识别'
],
'deliverables': ['迁移评估报告', '详细项目计划']
},
'poc': {
'duration_weeks': 3,
'activities': [
'概念验证环境搭建',
'核心模块迁移测试',
'性能基准测试',
'问题识别与解决'
],
'deliverables': ['POC测试报告', '技术方案验证']
},
'preparation': {
'duration_weeks': 4,
'activities': [
'目标环境准备',
'工具链配置',
'团队技术培训',
'迁移脚本开发'
],
'deliverables': ['技术准备就绪报告']
},
'execution': {
'duration_weeks': 'variable',
'activities': [
'分模块迁移实施',
'数据迁移验证',
'应用适配改造',
'集成测试'
],
'deliverables': ['迁移完成报告']
},
'optimization': {
'duration_weeks': 2,
'activities': [
'性能调优',
'监控体系建立',
'备份策略实施',
'文档完善'
],
'deliverables': ['系统优化报告']
},
'operation': {
'duration_weeks': 'ongoing',
'activities': [
'生产运维',
'持续监控',
'定期评估',
'知识传承'
],
'deliverables': ['运维手册', '知识库']
}
}
def generate_timeline(self, start_date):
"""生成详细的时间线"""
from datetime import datetime, timedelta
timeline = []
current_date = datetime.strptime(start_date, '%Y-%m-%d')
for phase_name, phase_info in self.phases.items():
if phase_info['duration_weeks'] != 'variable' and phase_info['duration_weeks'] != 'ongoing':
duration_days = phase_info['duration_weeks'] * 7
end_date = current_date + timedelta(days=duration_days)
timeline.append({
'phase': phase_name,
'start': current_date.strftime('%Y-%m-%d'),
'end': end_date.strftime('%Y-%m-%d'),
'duration_weeks': phase_info['duration_weeks'],
'key_activities': phase_info['activities'][:3] # 只显示前三项关键活动
})
current_date = end_date
return timeline
# 使用示例
planner = MigrationRoadmapPlanner(system_complexity='high')
timeline = planner.generate_timeline('2024-01-01')
for item in timeline:
print(f"阶段: {item['phase']}")
print(f"时间: {item['start']} 到 {item['end']}")
print(f"关键活动: {', '.join(item['key_activities'])}")
print("-" * 50)第二阶段:概念验证(Proof of Concept)
概念验证阶段的目标是验证技术方案的可行性,识别关键风险点。
sql
-- POC阶段测试用例设计
-- 1. 数据类型兼容性测试
CREATE TABLE poc_data_types (
id INTEGER PRIMARY KEY,
-- 测试各种Oracle数据类型的转换
varchar2_col VARCHAR(100),
number_col NUMERIC(10,2),
date_col TIMESTAMP,
timestamp_col TIMESTAMP(6),
clob_col TEXT,
blob_col BYTEA
);
-- 2. 复杂查询兼容性测试
WITH RECURSIVE employee_hierarchy AS (
SELECT employee_id, manager_id, employee_name, 1 as level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.employee_id, e.manager_id, e.employee_name, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.employee_id
)
SELECT * FROM employee_hierarchy;
-- 3. 性能基准测试
-- 创建测试数据
INSERT INTO performance_test
SELECT
generate_series(1, 1000000),
md5(random()::text),
random() * 10000,
current_timestamp - (random() * 365) * INTERVAL '1 day'
;
-- 执行性能测试查询
EXPLAIN (ANALYZE, BUFFERS)
SELECT customer_id, SUM(amount) as total_amount
FROM performance_test
WHERE transaction_date >= '2023-01-01'
GROUP BY customer_id
HAVING SUM(amount) > 5000
ORDER BY total_amount DESC;4.1.2 风险评估与缓解策略
sql
# 风险评估矩阵
class MigrationRiskAssessor:
def __init__(self):
self.risk_matrix = {
'high': [],
'medium': [],
'low': []
}
def identify_risks(self):
"""识别迁移风险"""
risks = [
{
'id': 'R001',
'description': '数据类型不兼容导致数据丢失',
'probability': 'medium',
'impact': 'high',
'category': '技术风险'
},
{
'id': 'R002',
'description': '存储过程转换复杂,工期延误',
'probability': 'high',
'impact': 'medium',
'category': '技术风险'
},
{
'id': 'R003',
'description': '性能不达标,用户体验下降',
'probability': 'medium',
'impact': 'high',
'category': '性能风险'
},
{
'id': 'R004',
'description': '团队技能不足,学习曲线陡峭',
'probability': 'high',
'impact': 'medium',
'category': '人力资源风险'
},
{
'id': 'R005',
'description': '回滚机制不完善,故障恢复困难',
'probability': 'low',
'impact': 'high',
'category': '运维风险'
}
]
for risk in risks:
risk_score = self._calculate_risk_score(risk['probability'], risk['impact'])
risk['score'] = risk_score
risk['mitigation'] = self._suggest_mitigation(risk)
# 分类到风险矩阵
if risk_score >= 12:
self.risk_matrix['high'].append(risk)
elif risk_score >= 6:
self.risk_matrix['medium'].append(risk)
else:
self.risk_matrix['low'].append(risk)
return risks
def _calculate_risk_score(self, probability, impact):
"""计算风险评分"""
prob_map = {'low': 1, 'medium': 2, 'high': 3}
impact_map = {'low': 1, 'medium': 2, 'high': 3}
return prob_map[probability] * impact_map[impact]
def _suggest_mitigation(self, risk):
"""建议风险缓解措施"""
mitigations = {
'R001': '进行全面的数据类型映射测试,开发数据验证工具',
'R002': '分阶段迁移存储过程,优先迁移核心业务逻辑',
'R003': '建立性能基准测试,优化查询和索引策略',
'R004': '组织技术培训,建立知识共享机制',
'R005': '设计完善的回滚方案,定期进行故障恢复演练'
}
return mitigations.get(risk['id'], '需要进一步分析')
def generate_risk_report(self):
"""生成风险评估报告"""
risks = self.identify_risks()
report = "数据库迁移风险评估报告\n"
report += "=" * 50 + "\n\n"
for level in ['high', 'medium', 'low']:
report += f"{level.upper()}风险等级 ({len(self.risk_matrix[level])}个):\n"
report += "-" * 30 + "\n"
for risk in self.risk_matrix[level]:
report += f"ID: {risk['id']}\n"
report += f"描述: {risk['description']}\n"
report += f"概率: {risk['probability']}, 影响: {risk['impact']}, 评分: {risk['score']}\n"
report += f"缓解措施: {risk['mitigation']}\n"
report += "\n"
return report
# 使用示例
assessor = MigrationRiskAssessor()
report = assessor.generate_risk_report()
print(report)4.2 最佳实践总结与经验分享
4.2.1 技术最佳实践
数据迁移最佳实践:
-
增量迁移策略:对于大型数据库,采用增量迁移减少停机时间
-
数据验证自动化:开发自动化工具验证数据一致性
-
回滚机制设计:确保在任何阶段都能安全回滚
sql
# 增量数据迁移工具
class IncrementalDataMigrator:
def __init__(self, source_conn, target_conn):
self.source = source_conn
self.target = target_conn
self.checkpoint_table = 'migration_checkpoints'
def setup_checkpoint(self):
"""设置迁移检查点"""
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.checkpoint_table} (
table_name VARCHAR(100) PRIMARY KEY,
last_migrated_id INTEGER,
last_migration_time TIMESTAMP,
migration_status VARCHAR(20)
)
"""
with self.target.cursor() as cursor:
cursor.execute(create_table_sql)
self.target.commit()
def migrate_table_incrementally(self, table_name, primary_key):
"""增量迁移表数据"""
# 获取上次迁移的检查点
last_id = self._get_last_checkpoint(table_name)
# 查询增量数据
incremental_query = f"""
SELECT * FROM {table_name}
WHERE {primary_key} > {last_id}
ORDER BY {primary_key}
"""
with self.source.cursor() as cursor:
cursor.execute(incremental_query)
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
if not rows:
print(f"表 {table_name} 没有新的增量数据")
return
# 迁移数据
batch_size = 1000
for i in range(0, len(rows), batch_size):
batch = rows[i:i+batch_size]
self._insert_batch(table_name, columns, batch)
# 更新检查点
last_row_id = batch[-1][0] # 假设第一列是主键
self._update_checkpoint(table_name, last_row_id)
print(f"表 {table_name}: 已迁移 {i+len(batch)}/{len(rows)} 行")
def _get_last_checkpoint(self, table_name):
"""获取最后检查点"""
query = f"""
SELECT last_migrated_id FROM {self.checkpoint_table}
WHERE table_name = '{table_name}'
"""
with self.target.cursor() as cursor:
cursor.execute(query)
result = cursor.fetchone()
return result[0] if result else 0
def _update_checkpoint(self, table_name, last_id):
"""更新检查点"""
upsert_sql = f"""
INSERT INTO {self.checkpoint_table}
(table_name, last_migrated_id, last_migration_time, migration_status)
VALUES ('{table_name}', {last_id}, CURRENT_TIMESTAMP, 'IN_PROGRESS')
ON CONFLICT (table_name) DO UPDATE
SET last_migrated_id = EXCLUDED.last_migrated_id,
last_migration_time = EXCLUDED.last_migration_time,
migration_status = 'IN_PROGRESS'
"""
with self.target.cursor() as cursor:
cursor.execute(upsert_sql)
self.target.commit()
def _insert_batch(self, table_name, columns, batch):
"""批量插入数据"""
if not batch:
return
# 构建INSERT语句
col_list = ', '.join(columns)
placeholders = ', '.join(['%s'] * len(columns))
insert_sql = f"""
INSERT INTO {table_name} ({col_list})
VALUES ({placeholders})
ON CONFLICT DO NOTHING
"""
with self.target.cursor() as cursor:
cursor.executemany(insert_sql, batch)
self.target.commit()性能优化最佳实践:
-
查询优化:重写复杂查询,使用合适的连接方式
-
索引策略:基于查询模式创建合适的索引
-
配置调优:根据硬件资源和负载特征优化数据库参数
sql
-- 金仓数据库性能优化检查清单
-- 1. 检查慢查询
SELECT
query,
calls,
total_exec_time,
mean_exec_time,
rows
FROM pg_stat_statements
WHERE mean_exec_time > 100 -- 超过100毫秒的查询
ORDER BY mean_exec_time DESC
LIMIT 20;
-- 2. 检查索引使用情况
SELECT
schemaname,
tablename,
indexname,
idx_scan,
idx_tup_read,
idx_tup_fetch
FROM pg_stat_user_indexes
WHERE idx_scan = 0 -- 从未使用过的索引
ORDER BY schemaname, tablename;
-- 3. 检查表膨胀
SELECT
schemaname,
tablename,
n_live_tup,
n_dead_tup,
round(n_dead_tup::numeric / (n_live_tup + n_dead_tup) * 100, 2) as dead_tuple_percent
FROM pg_stat_user_tables
WHERE n_live_tup + n_dead_tup > 10000
AND n_dead_tup::numeric / (n_live_tup + n_dead_tup) > 0.1 -- 死元组超过10%
ORDER BY dead_tuple_percent DESC;
-- 4. 检查连接状态
SELECT
COUNT(*) as total_connections,
COUNT(*) FILTER (WHERE state = 'active') as active_connections,
COUNT(*) FILTER (WHERE state = 'idle') as idle_connections,
COUNT(*) FILTER (WHERE state = 'idle in transaction') as idle_in_xact,
MAX(age(now(), query_start)) as oldest_query
FROM pg_stat_activity
WHERE datname = current_database();
-- 5. 自动执行维护
-- 创建自动维护脚本
CREATE OR REPLACE PROCEDURE perform_maintenance()
LANGUAGE plpgsql
AS $$
BEGIN
-- 更新统计信息
ANALYZE;
-- 清理死元组
VACUUM ANALYZE;
-- 重新索引需要优化的索引
REINDEX TABLE CONCURRENTLY problematic_table;
RAISE NOTICE '维护任务完成于 %', CURRENT_TIMESTAMP;
END;
$$;
-- 设置定时任务(使用操作系统cron或类似工具)
-- 每天凌晨2点执行维护
-- 0 2 * * * kingbase -d mydb -c "CALL perform_maintenance()"4.2.2 项目管理最佳实践
团队协作与知识管理:
-
建立知识库:记录迁移经验、问题解决方案
-
定期技术分享:组织团队内部技术交流
-
文档自动化:自动生成迁移文档和报告
sql
# 知识管理工具
class MigrationKnowledgeBase:
def __init__(self, db_connection):
self.conn = db_connection
self.setup_knowledge_base()
def setup_knowledge_base(self):
"""设置知识库表结构"""
tables = {
'migration_issues': """
CREATE TABLE IF NOT EXISTS migration_issues (
id SERIAL PRIMARY KEY,
issue_type VARCHAR(50),
description TEXT,
oracle_context TEXT,
kingbase_solution TEXT,
severity VARCHAR(20),
resolved BOOLEAN DEFAULT false,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
resolved_at TIMESTAMP
)
""",
'best_practices': """
CREATE TABLE IF NOT EXISTS best_practices (
id SERIAL PRIMARY KEY,
category VARCHAR(50),
title VARCHAR(200),
description TEXT,
code_example TEXT,
reference_link TEXT,
created_by VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""",
'conversion_patterns': """
CREATE TABLE IF NOT EXISTS conversion_patterns (
id SERIAL PRIMARY KEY,
oracle_pattern TEXT,
kingbase_pattern TEXT,
pattern_type VARCHAR(50),
description TEXT,
example TEXT,
success_rate INTEGER DEFAULT 0
)
"""
}
with self.conn.cursor() as cursor:
for table_name, create_sql in tables.items():
cursor.execute(create_sql)
self.conn.commit()
def record_issue(self, issue_type, description, oracle_context, solution=None):
"""记录迁移问题"""
insert_sql = """
INSERT INTO migration_issues
(issue_type, description, oracle_context, kingbase_solution, severity)
VALUES (%s, %s, %s, %s, %s)
RETURNING id
"""
with self.conn.cursor() as cursor:
cursor.execute(insert_sql,
(issue_type, description, oracle_context, solution, 'medium'))
issue_id = cursor.fetchone()[0]
self.conn.commit()
print(f"问题已记录,ID: {issue_id}")
return issue_id
def add_best_practice(self, category, title, description, code_example=None):
"""添加最佳实践"""
insert_sql = """
INSERT INTO best_practices
(category, title, description, code_example, created_by)
VALUES (%s, %s, %s, %s, %s)
"""
with self.conn.cursor() as cursor:
cursor.execute(insert_sql,
(category, title, description, code_example, 'system'))
self.conn.commit()
print(f"最佳实践已添加: {title}")
def search_solutions(self, keyword):
"""搜索解决方案"""
search_sql = """
SELECT title, description, code_example
FROM best_practices
WHERE title ILIKE %s OR description ILIKE %s
UNION
SELECT
'Issue: ' || issue_type as title,
description,
kingbase_solution as code_example
FROM migration_issues
WHERE description ILIKE %s OR oracle_context ILIKE %s
"""
search_pattern = f'%{keyword}%'
with self.conn.cursor() as cursor:
cursor.execute(search_sql,
(search_pattern, search_pattern, search_pattern, search_pattern))
results = cursor.fetchall()
return results
def generate_knowledge_report(self):
"""生成知识库报告"""
report_sql = """
SELECT
'最佳实践' as category,
COUNT(*) as count
FROM best_practices
UNION ALL
SELECT
'已解决问题',
COUNT(*)
FROM migration_issues
WHERE resolved = true
UNION ALL
SELECT
'待解决问题',
COUNT(*)
FROM migration_issues
WHERE resolved = false
UNION ALL
SELECT
'转换模式',
COUNT(*)
FROM conversion_patterns
"""
with self.conn.cursor() as cursor:
cursor.execute(report_sql)
stats = cursor.fetchall()
report = "迁移知识库统计报告\n"
report += "=" * 40 + "\n"
for category, count in stats:
report += f"{category}: {count}\n"
return report
# 使用示例
kb = MigrationKnowledgeBase(db_connection)
kb.record_issue(
issue_type='数据类型转换',
description='Oracle的NUMBER类型转换为金仓NUMERIC时精度丢失',
oracle_context='NUMBER(15,4)',
solution='使用NUMERIC(15,4)确保精度'
)
kb.add_best_practice(
category='性能优化',
title='分区表使用规范',
description='对于时间序列数据,按时间分区可大幅提升查询性能',
code_example='CREATE TABLE sales PARTITION BY RANGE (sale_date);'
)
solutions = kb.search_solutions('分区')
for title, desc, example in solutions:
print(f"标题: {title}")
print(f"描述: {desc[:100]}...")
print()4.3 未来展望与持续优化
4.3.1 金仓数据库发展趋势
随着国产数据库技术的快速发展,金仓数据库在以下方面展现出明显趋势:
云原生与分布式架构:
sql
-- 分布式架构示例
-- 金仓数据库分布式版本支持水平扩展
CREATE DISTRIBUTED TABLE distributed_sales (
sale_id BIGINT,
customer_id INTEGER,
sale_date DATE,
amount DECIMAL(10,2),
region VARCHAR(20)
) DISTRIBUTE BY HASH(customer_id); -- 按客户ID哈希分布
-- 跨节点查询优化
SET distributed_optimizer = on;
SET enable_partitionwise_join = on;
SET enable_partitionwise_aggregate = on;
-- 分布式事务支持
BEGIN;
-- 跨节点数据操作
UPDATE distributed_sales SET amount = amount * 1.1 WHERE region = '北京';
UPDATE distributed_customers SET credit_limit = credit_limit + 1000 WHERE region = '北京';
COMMIT;智能化运维管理:
sql
# 智能运维监控系统
class IntelligentDBAssistant:
def __init__(self, db_connection):
self.conn = db_connection
self.ml_model = self.load_ml_model()
def load_ml_model(self):
"""加载机器学习模型"""
# 这里可以加载预测性能问题、识别异常模式等的模型
return None
def predict_performance_issues(self):
"""预测性能问题"""
# 收集性能指标
metrics = self.collect_performance_metrics()
# 使用模型预测
# predictions = self.ml_model.predict(metrics)
# 返回预测结果和建议
return {
'high_risk_queries': self.identify_slow_queries(),
'index_recommendations': self.suggest_indexes(),
'configuration_optimizations': self.analyze_configuration()
}
def collect_performance_metrics(self):
"""收集性能指标"""
metrics_sql = """
SELECT
CURRENT_TIMESTAMP as timestamp,
(SELECT COUNT(*) FROM pg_stat_activity WHERE state = 'active') as active_connections,
(SELECT SUM(n_dead_tup) FROM pg_stat_user_tables) as total_dead_tuples,
(SELECT SUM(idx_scan) FROM pg_stat_user_indexes) as total_index_scans,
(SELECT setting::integer FROM pg_settings WHERE name = 'shared_buffers') as shared_buffers
"""
with self.conn.cursor() as cursor:
cursor.execute(metrics_sql)
return cursor.fetchone()
def identify_slow_queries(self):
"""识别慢查询"""
slow_query_sql = """
SELECT
query,
mean_exec_time,
calls
FROM pg_stat_statements
WHERE mean_exec_time > 1000 -- 超过1秒的查询
ORDER BY mean_exec_time DESC
LIMIT 10
"""
with self.conn.cursor() as cursor:
cursor.execute(slow_query_sql)
return cursor.fetchall()
def suggest_indexes(self):
"""建议创建索引"""
index_suggestion_sql = """
SELECT
schemaname,
tablename,
attname,
null_frac,
n_distinct
FROM pg_stats
WHERE schemaname NOT LIKE 'pg_%'
AND schemaname != 'information_schema'
AND n_distinct > 0.1 -- 区分度高的列
ORDER BY n_distinct DESC
LIMIT 20
"""
with self.conn.cursor() as cursor:
cursor.execute(index_suggestion_sql)
return cursor.fetchall()4.3.2 持续优化建议
性能持续监控与优化:
sql
-- 创建性能监控仪表板视图
CREATE VIEW performance_dashboard AS
WITH connection_stats AS (
SELECT
COUNT(*) as total_connections,
COUNT(*) FILTER (WHERE state = 'active') as active_connections,
COUNT(*) FILTER (WHERE state = 'idle') as idle_connections
FROM pg_stat_activity
WHERE datname = current_database()
),
query_stats AS (
SELECT
SUM(calls) as total_calls,
SUM(total_exec_time) as total_exec_time,
AVG(mean_exec_time) as avg_query_time,
MAX(max_exec_time) as slowest_query_time
FROM pg_stat_statements
),
table_stats AS (
SELECT
SUM(n_live_tup) as total_live_rows,
SUM(n_dead_tup) as total_dead_rows,
SUM(n_dead_tup)::float / NULLIF(SUM(n_live_tup + n_dead_tup), 0) * 100 as dead_tuple_percent
FROM pg_stat_user_tables
),
index_stats AS (
SELECT
COUNT(*) as total_indexes,
SUM(idx_scan) as total_index_scans,
COUNT(*) FILTER (WHERE idx_scan = 0) as unused_indexes
FROM pg_stat_user_indexes
)
SELECT
cs.total_connections,
cs.active_connections,
cs.idle_connections,
qs.total_calls,
ROUND(qs.avg_query_time::numeric, 2) as avg_query_time_ms,
ROUND(qs.slowest_query_time::numeric, 2) as slowest_query_ms,
ts.total_live_rows,
ROUND(ts.dead_tuple_percent::numeric, 2) as dead_tuple_percent,
isc.total_indexes,
isc.unused_indexes
FROM connection_stats cs
CROSS JOIN query_stats qs
CROSS JOIN table_stats ts
CROSS JOIN index_stats isc;
-- 创建自动优化策略
CREATE OR REPLACE PROCEDURE auto_optimization_routine()
LANGUAGE plpgsql
AS $$
DECLARE
dead_tuple_percent FLOAT;
unused_index_count INTEGER;
BEGIN
-- 检查表膨胀
SELECT dead_tuple_percent INTO dead_tuple_percent
FROM performance_dashboard;
IF dead_tuple_percent > 20 THEN
RAISE NOTICE '检测到表膨胀(%.2f%),执行VACUUM', dead_tuple_percent;
VACUUM ANALYZE;
END IF;
-- 检查未使用索引
SELECT unused_indexes INTO unused_index_count
FROM performance_dashboard;
IF unused_index_count > 10 THEN
RAISE NOTICE '发现%d个未使用索引,建议审查', unused_index_count;
-- 这里可以添加自动删除未使用索引的逻辑
END IF;
-- 更新统计信息
IF EXTRACT(HOUR FROM CURRENT_TIME) BETWEEN 2 AND 4 THEN
RAISE NOTICE '执行统计信息更新';
ANALYZE;
END IF;
RAISE NOTICE '自动优化任务完成';
END;
$$;安全与合规性持续改进:
sql
-- 安全审计配置
-- 启用详细审计日志
ALTER SYSTEM SET log_statement = 'ddl'; -- 记录DDL语句
ALTER SYSTEM SET log_duration = on; -- 记录查询耗时
ALTER SYSTEM SET log_connections = on; -- 记录连接信息
ALTER SYSTEM SET log_disconnections = on; -- 记录断开连接信息
-- 创建安全审计视图
CREATE VIEW security_audit_log AS
SELECT
event_time,
user_name,
database_name,
command_tag,
query_text,
client_addr,
application_name
FROM pg_log_directory()
WHERE command_tag IN ('CREATE', 'ALTER', 'DROP', 'INSERT', 'UPDATE', 'DELETE', 'GRANT', 'REVOKE')
ORDER BY event_time DESC;
-- 数据加密配置
-- 透明数据加密(TDE)
-- 注意:具体语法可能因版本而异
CREATE TABLESPACE encrypted_ts
LOCATION '/data/encrypted_tablespace'
WITH (encryption = true, encryption_key_id = 'my_key_id');
-- 列级加密示例
CREATE TABLE sensitive_data (
id SERIAL PRIMARY KEY,
-- 加密存储的敏感数据
credit_card_number TEXT, -- 实际使用中应加密存储
ssn TEXT, -- 社会安全号码,加密存储
-- 非敏感数据
customer_name VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建加密函数(示例)
CREATE OR REPLACE FUNCTION encrypt_data(data TEXT, key TEXT)
RETURNS BYTEA
LANGUAGE plpgsql
AS $$
BEGIN
-- 实际应用中应使用安全的加密算法
-- 这里仅为示例
RETURN convert_to(data, 'UTF8'); -- 实际应加密
END;
$$;
-- 访问控制策略
-- 创建细粒度权限角色
CREATE ROLE data_reader;
CREATE ROLE data_writer;
CREATE ROLE data_admin;
-- 授予权限
GRANT SELECT ON ALL TABLES IN SCHEMA public TO data_reader;
GRANT SELECT, INSERT, UPDATE ON ALL TABLES IN SCHEMA public TO data_writer;
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO data_admin;
-- 行级安全策略
ALTER TABLE sensitive_data ENABLE ROW LEVEL SECURITY;
CREATE POLICY sensitive_data_policy ON sensitive_data
FOR ALL
USING (current_user = created_by); -- 只能访问自己创建的数据
-- 审计数据访问
CREATE TABLE data_access_audit (
id SERIAL PRIMARY KEY,
user_name VARCHAR(100),
table_name VARCHAR(100),
operation VARCHAR(20),
access_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
client_ip INET,
query_text TEXT
);
-- 创建审计触发器
CREATE OR REPLACE FUNCTION audit_data_access()
RETURNS TRIGGER
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO data_access_audit
(user_name, table_name, operation, client_ip, query_text)
VALUES (
current_user,
TG_TABLE_NAME,
TG_OP,
inet_client_addr(),
current_query()
);
RETURN NEW;
END;
$$;
-- 在敏感表上应用审计触发器
CREATE TRIGGER audit_sensitive_data_access
AFTER INSERT OR UPDATE OR DELETE ON sensitive_data
FOR EACH ROW EXECUTE FUNCTION audit_data_access();4.4 总结
随着国产数据库技术的不断成熟和金仓数据库产品的持续完善,我们有理由相信:
-
技术差距将进一步缩小:金仓数据库在企业级功能、性能表现等方面将不断提升
-
生态系统将更加完善:工具链、中间件、应用框架的适配将更加成熟
-
迁移成本将持续降低:自动化迁移工具和最佳实践的积累将降低迁移难度
-
应用场景将更加广泛:从传统OLTP到分析型应用、从集中式到分布式架构
对于正在进行或计划进行数据库国产化迁移的企业来说,现在是一个合适的时机。通过科学规划、精心实施和持续优化,Oracle到金仓数据库的迁移不仅可以实现技术自主可控的目标,还可以为企业带来性能提升、成本优化和架构升级的多重价值。