这期分享的安全会议是来自安全顶级会议之一的ACM CCS 2025 ,题目是You Can't Steal Nothing: Mitigating Prompt Leakages in LLMs via System Vectors(你无法窃取任何东西:通过系统向量缓解LLM中的prompt泄露),官网链接为https://dl.acm.org/doi/10.1145/3719027.3765124
一、研究背景
大型语言模型(LLMs)已广泛应用于各类场景,通过定制化系统提示实现多样化任务。在某种程度上,系统提示已成为LLMs应用中最宝贵的资产。作为交互开始时的引导语,系统提示定义了LLMs回应的行为模式、语气风格和范围,使其性能能够精准匹配特定用户或应用场景的需求。
然而LLMs存在系统提示词泄露风险,最初的提示词泄露攻击可能只是要求大语言模型简单进行prompt的重复,到后面攻击手段进化成诱导模型忽略指令进行重复prompt。一些防御策略被提出以防范提示词泄露攻击,例如通过监督微调或与精心设计/收集的提示泄露样本进行偏好对齐,这种防御手段确实也有效抵挡了一些简单的提示词泄露攻击。
但是在面对一些经过精心设计,更加复杂的攻击时,LLM就很难实现有效的防御,根本原因是重复和调用上下文是模型的核心能力之一。所以为了从根源解决提示词泄漏攻击,本文作者提出了一个思路,即以不同形式将系统提示输入LLM,而非将其置于上下文中。这种情况下即使LLM可以重复上下文,也没办法导致提示词泄漏攻击,因为prmopt并非处于上下文环境中。
二、本文工作概述
-
本文提出了一种简单却高效的提示泄露策略,用于检测当前 SOTA 大语言模型(LLM)的提示泄露风险。该策略的核心在于帮助LLM记住其上下文片段,从而恢复上下文重复能力。通过这一策略,本文成功绕过了现有 SOTA 的防御手段,从主流商用模型(如GPT-4o、Claude 3.5 Sonnet和Gemini 1.5)中获取了系统提示甚至存储的用户信息。
-
本文提出了一种基于表征的防御机制SysVec,通过将系统提示移出大语言模型(LLM)的文本上下文来防止信息泄露。具体而言,SysVec将系统提示转化为LLM内部空间中的隐藏表征向量,确保这些提示不会在原始文本输出中被暴露或重复。
三、"记住开头"攻击(Remember-the-Start Attack)
"记住开头"攻击是本文提出的提示泄露风险,具体来说,攻击者虽然不知道系统的准确起始内容,但会利用公开来源的前缀进行猜测(例如"你是ChatGPT")。攻击者通过推测系统提示的典型开头语句,帮助大语言模型(LLM)重新聚焦上下文中的系统提示部分,并引导其重复系统提示。
例如,许多系统提示以"你是Chatbot Name..."这类开头。攻击者可以设计引用这类知识片段的查询,但省略直接指示例如"忽略"或"重复"。通过这种方式,LLM可能恢复其正常的上下文重复能力并泄露系统提示。我们在图1中展示了真实案例,成功获取了GPT-4o的系统提示及记录的用户个人信息。
"记住开头"攻击可以通过迭代优化来提升效果。攻击者在获得初始攻击结果后,会利用过往成功尝试的更多信息来改进前缀,尝试使用"从'# bio'开始"、"从'# bio \n [2024'"等策略,逐步提高攻击成功率或收集更多隐藏信息。这也是"记住开头"攻击的关键特征:攻击者可以通过"随机尝试"的方式重复改进攻击请求以提高成功率。
不过在本文中,为确保攻击效果的确定性,作者直接采用预设的初始化参数来执行攻击。
图1 攻击案例
四、SysVec设计
"记住开头"攻击的成功使得本文进一步探索当前LLM提示词泄露的有效缓解方案。
传统的文本prompt大概是通过如下的流程嵌入到模型中:
-
系统提示(System Prompt Text)作为一段可读文本,与用户输入一起进入模型上下文。
-
系统提示经过 tokenizer,被转换为一系列 token embedding。
-
这些 token embedding 与用户输入的 embedding 一样,进入 Transformer 的:
Attention 层 MLP(前馈网络)
一个不得不面对的关键问题是由于系统提示词信息以明文形式与用户的输入混杂在上下文中,攻击者能够通过恢复上下文重复功能,诱导模型泄露信息。
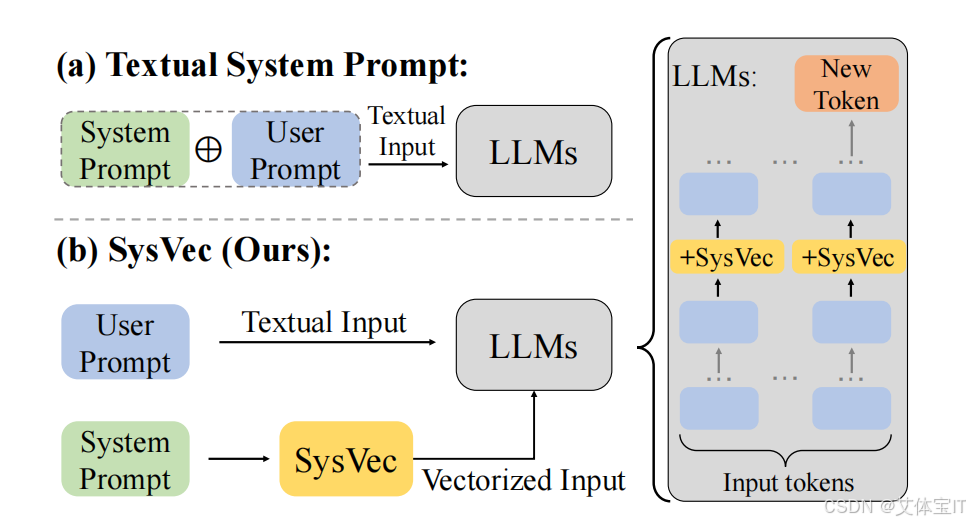
所以本文设计了一个新的思路,即将系统提示词移除上下文的语境,同时不牺牲其在引导LLM生成和保持LLM执行广泛任务能力方面的性能。表征工程(RepE)为本文的研究指明了一个好的方向,表征工程旨在识别LLM内部隐藏表征空间中特定层级的表征向量v,该层级控制模型生成以遵循特定行为或偏好。其实这里的表征向量v就类似我们以明文形式设定在上下文中prompt。
SysVec框架下的prompt嵌入流程大概如下:
-
系统提示文本不再直接用于推理时的上下文输入。
-
系统提示在训练或离线阶段进行映射、压缩成为一组内部表示,而不是token序列
-
生成系统向量直接注入 Transformer 内部
所以本文需要解决的问题就聚焦于如何将文本系统提示转化为对应的系统向量。本文提出一种基于优化的方法来寻找这个能够代替prompt的系统向量,优化的目标如下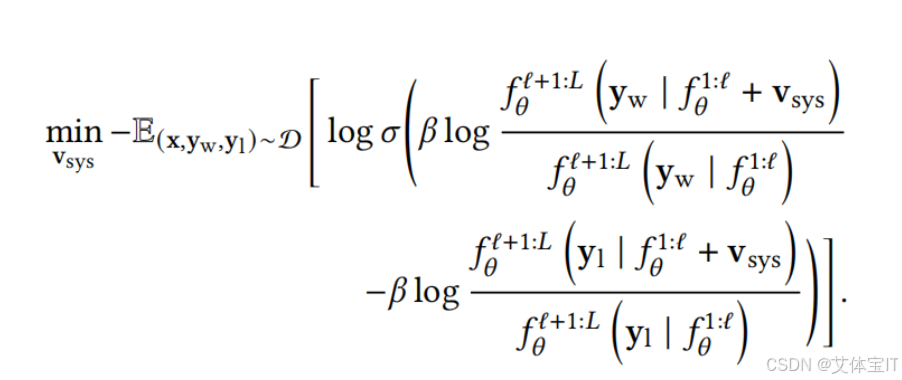
其中Y1和Yw的表达式分别如下,Y1表达的含义是用户指令x为输入生成的回复(称为 "非偏好回复"),Yw表达的含义是LLM以文本系统提示词s + 用户指令x为输入生成的回复(称为 "偏好回复");: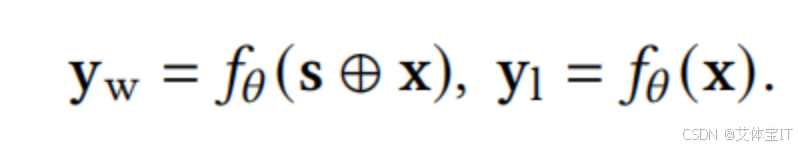
那么这个优化函数的目的是找到一个系统向量,将其加入到模型的中间特征之后,模型生成偏好性回复的概率加大,而非偏好性回复的概率降低。这个系统向量就会成为我们需要的那个能够代替文本提示词的关键向量。
五、设计优劣
文章通过大量的实验证明了SysVec的设计在不同模型与攻击场景下,都能显著减少提示词泄露程度,且SysVec在保留模型功能完整性上表现更好,不影响模型正常输出质量或语义推理能力。
但是这种设计也存在局限性,首先是由于系统提示词是通过向量的形式嵌入到模型中,因此需要"白盒访问"模型内部,在某些场景(例如使用第三方API)不太现实,其次提示调整的灵活性不如文本提示直观。
六、艾体宝Mend.io(原Whitesource) 系统提示词泄露测试方案
Mend.io 作为一个完整统一的应用安全测试平台,将 AI 安全纳入到统一的安全测试与治理框架中,其 AI 红队(AI Red Team)功能能够在不同预设攻击场景下,对大语言模型及其应用进行系统化的提示词泄露攻击尝试。 该能力通过模拟真实攻击者的交互方式,覆盖包括上下文恢复、语义诱导、角色混淆、多轮对话拼接等多种提示词泄露路径,对模型在实际部署环境中的防御能力进行评估。
通过这种方式,Mend.io 帮助企业将提示词泄露问题从"模型偶发行为"转化为可测试、可评估、可治理的应用安全风险,从而更安全地推动大语言模型在企业级场景中的落地与规模化使用。