title: 2026-01-19-论文阅读-AgiBot
date: 2026-01-19
tags:
- 论文阅读
- 具身智能
AgiBot World Colosseo: Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
一、论文基本信息
- 标题:《AgiBot World Colosseo: Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems》
- 原文链接
- 作者:Team AgiBot-World∗
关键词:具身智能,ViLLA,人机协作,通用机器人。
二、研究背景与问题定义
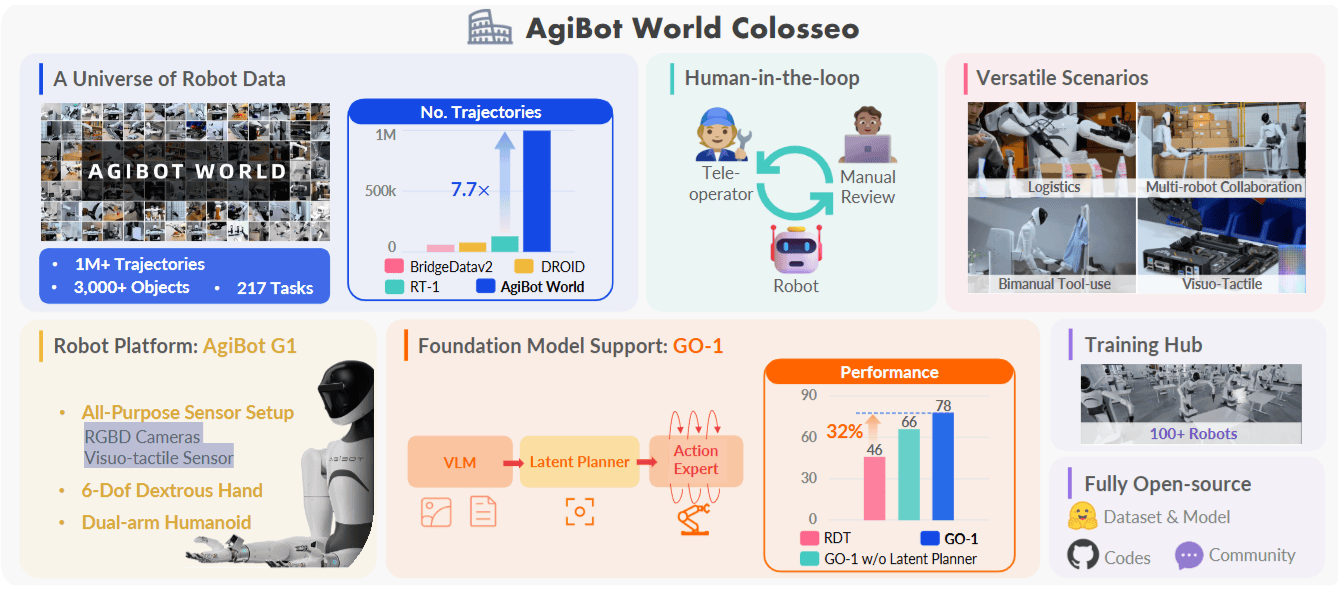
这篇论文的核心是一个大规模操纵平台,并配套高质量数据与通用策略:
- 平台规模: 完全开源,1M+轨迹,3000+物体,217个任务
- 采集方式: 远程控制(双臂机器人),人工评审
- 传感配置: RGBD摄像头,视觉触觉传感器
- 多场景任务适用:
- 后勤/物流
- 多机器人协作
- 视觉触觉
- 双手工具使用
- 部署规模: 100台多功能人形机器人,完全开源
Teleoperation(远程操作)说明:
- 在数据收集过程中,熟练的远程操作员使用VR控制器或动作捕捉系统控制 Agibot G1 机器人,采集大量操纵演示数据。
- 该方式可模拟人类精细操作,生成高质量操纵轨迹,尤其适用于复杂、长时或需要精细控制的任务。
- 操作员技能水平和操作质量直接影响数据有效性,因此培训与标准化流程非常关键。
三、核心方法 / 模型 / 系统设计
数据采集通过边云双端协同实现,需要人的远程操控进行训练,并进行手动评估。
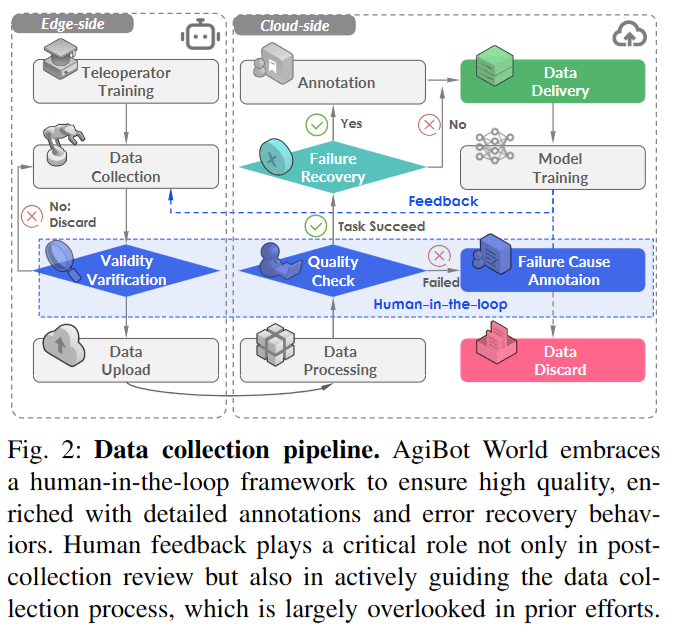
数据特征与训练框架:
- 相比此前数据集,目标控制时间更长,平均约30s
- 采用三阶段 Vision-Language-Latent-Action (ViLLA) 架构训练
- VLM Backbone: 使用了 InternVL2.5-2B 模型
三阶段要点:- Stage 1: 在互联网规模的异构数据上训练编码器-解码器潜在动作模型(LAM),将连续图像映射到潜在动作空间,作为连接图文输入与机器人动作的中间表示。
- Stage 2: 用潜在动作作为伪标签训练潜在规划器,实现与机器人形态无关的长时规划,并利用预训练 VLM 的泛化能力。
- Stage 3: 引入动作专家(Action Expert),与潜在规划器联合训练,支持灵巧操作学习。
四、实验
- 评估环境: 全部在真实物理环境进行,未使用仿真
- 评估任务: 覆盖工具使用、柔性物体操作、人机交互、语言跟随
- Restock Bag: 将零食从推车放到货架上
- Table Bussing: 清理桌面垃圾到垃圾桶
- Pour Water: 拿起水壶倒水进杯子
- Restock Beverage: 将饮料瓶放到货架上
- Fold Shorts: 将短裤折叠两次
- Wipe Table: 用海绵擦拭桌上的水渍
- 测试场景:
- 分布内(In-distribution / Seen): 训练中见过的场景
- 分布外(Out-of-distribution / Unseen): 位置变化、视觉干扰物、语言指令变化
- 评分标准: 每个任务、场景、方法进行10次滚降测试(Rollouts),完全成功记1.0,部分成功记分,取平均归一化分数
Baseline
为了验证 GO-1 模型与数据集质量,论文使用了以下对比基线:
- RDT-1B:
- 开源的基于扩散模型(Diffusion-based)的双臂操作基础模型,作为主要外部对比对象(Prior generalist policy)
- GO-1 w/o Latent Planner(消融实验):
- 论文模型变体,去掉潜在规划器(Latent Planner)
- 用于验证 ViLLA 架构中潜在规划器对长序列任务与泛化能力的重要性
- 基于 Open X-Embodiment(OXE) 训练的策略:
- 使用相同模型架构,分别在 AgiBot World 与 OXE 上预训练,用于对比数据质量
核心实验结果与发现
实验结果主要回答三个问题:
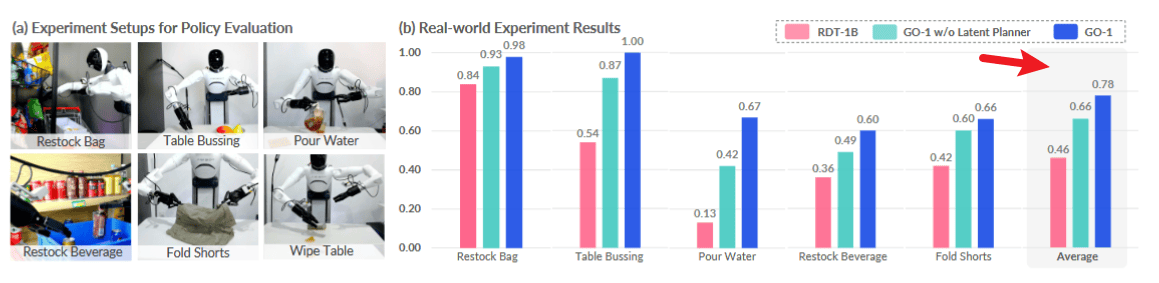
A. GO-1 是否是更强的通用策略?
- 结果: GO-1 在所有任务中均大幅超越 RDT-1B 与不带潜在规划器的变体
- 数据: 平均得分 RDT-1B 约0.36,不带规划器版本约0.49,完整版 GO-1 约0.66(参考图表数据)
- 分析: 潜在规划器显著提升复杂任务(如叠短裤)性能,并增强对指令跟随(如补货饮料)的泛化能力
B. AgiBot World 数据集是否比现有数据集(如 OXE)更有效?
- 结果: 在 AgiBot World 上预训练的策略显著优于在 OXE 上训练的策略
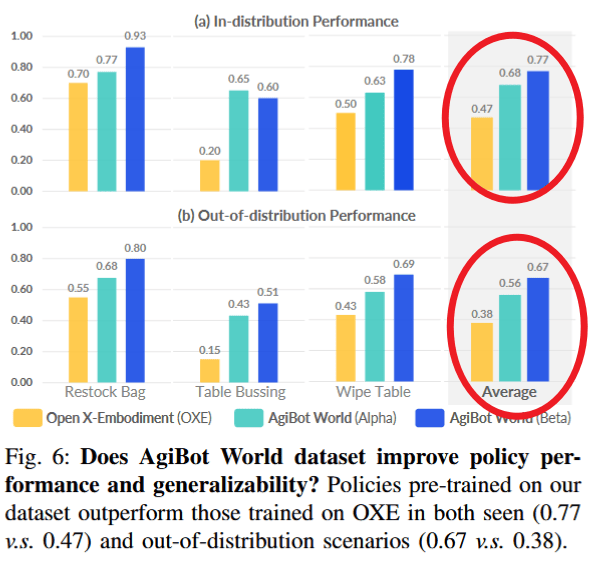
- 数据: 分布内成功率从0.47提升至0.77; 分布外(泛化)从0.38提升至0.67
- 效率: 仅使用 AgiBot World Alpha(约236小时)也超过 OXE(约2000小时),证明高质量数据的重要性
C. 数据规模与质量的影响(Scaling Laws & Data Quality)
- 规模法则(Data Scaling): 训练轨迹从9.2k增至1M,性能呈幂律(Power-law)增长,相关系数 r=0.97
- 质量大于数量: 仅使用人工验证(Human-in-the-loop verified)高质量小数据集(528条)优于混合未验证数据的大数据集(1010条),得分提升0.18,强调 Human-in-the-loop 数据清洗机制
五、创新点与改进空间
创新点
- AgiBot World 平台: 1M+轨迹、217任务、5类部署场景,规模较主流数据集(如 OXE)高一个数量级
- GO-1 + 潜在动作规划器: 提出通用策略 Genie Operator-1(GO-1),在多数据体上统一训练,性能较 prior arts 提升约32%
改进空间
Limitation. All evaluations are conducted in real-world scenarios. We are currently developing the simulation environment, aligning with the real-world setup and aiming to reflect real-world policy deployment outcome. It would thereby facilitate fast and reproducible evaluation.
- 所有评估在真实世界场景进行,正在开发仿真环境,目前复现不方便
六、我的思考
- 传感器: 目前机器人多用视觉与触觉,部分用雷达/三维成像,是否还有其他类型传感器适合对应任务?
- 数据特性: NLP/CV 发展快,但机器人训练数据异构、非结构化、碎片化,现实任务仍有很大空间
- 保留1%失败恢复数据对鲁棒性的贡献?
- 采集中遥操作员可能失误(如掉落物体),AgiBot World 要求从错误中恢复并继续任务(不重置)
- 研究团队保留轨迹并精细处理:
- 手动标注: 每条轨迹标注失败原因时间戳(failure reasons timestamps)
- 策略对齐(Policy Alignment): 学习人类纠错动作,使策略更贴近人类意图,提升鲁棒性
- 失败反思(Failure Reflection): 学习识别失败状态并恢复,真实场景意外(抓取滑脱)可补救
- 图表呈现: 关键数据可用不同背景标注,便于读者阅读