目录
一、langchain4j如何解析PDF文档
1.1 添加依赖
<!-- Source: https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-document-parser-apache-pdfbox --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-pdfbox</artifactId> <version>1.10.0-beta18</version> <scope>compile</scope> </dependency>
1.2、 写一段测试代码
java
package com.ai.langgraph4j.codehelper2.pdfbox;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import static org.bsc.langgraph4j.agentexecutor.AgentExecutor.log;
public class PDFBoxTest {
public static void main(String[] args) throws Exception {
String path = "/Users/apple/Documents/AI/langchain4jAIdemo/pdf/5.成绩登记表模板(系统中打印).pdf";
DocumentParser parser = new ApachePdfBoxDocumentParser();
Document document = FileSystemDocumentLoader.loadDocument(path, parser);
log.info("textSegment:{}", document.toTextSegment());//返回textSegment,这个可以跟向量数据库结合在一起
log.info("meta data:{}", document.metadata().toMap());
log.info("text:{}", document.text());
}
}二、向量数据库
2.1 向量数据库
在传统数据库中,精确查询匹配,检索通常依赖于关键词、精确匹配或范围查询。
大模型场景中,在自然语言处理、图像识别等 AI 场景中,更需要的是语义相似度检索,即"查找与某个内容在语义上最接近的内容"。这正是向量数据库的核心用途。比如,基于相似度搜索(如余弦相似度),返回近似匹配结果(如"视觉相似的图片"),容忍容错。
2.2 什么是向量
向量是通过深度学习模型(如 BERT、OpenAI Embedding、CLIP 等)对文本、图片、音频等内容提取出的稠密特征表示。通常表现为高维浮点数组。
例子: vector = -0.049977552, -0.022875419, 0.028773291, -0.058595255, 0.009328811, 0.025546558, -0.022599563, 0.004922383, 0.031749923, -0.014742963, -0.0051747668, -0.0023935703, 0.01949408, 0.053132694, 0.07271755, -0.0037443836
2.3 如何实现语义检索
在语义空间中,++相似的内容对应的向量距离会更近++,从而实现语义检索。此功能基于欧氏距离和余弦相似度等度量,在高维空间中查找与给定查询向量接近的向量。
2.4 核心功能
(1)向量存储 :支持大量高维向量的高效存储,通常采用列式存储或专用压缩格式以减少空间占用。
(2)相似性搜索 :通过近似最近邻(ANN, Approximate Nearest Neighbor)算法(如HNSW、IVF、FAISS等)快速检索与查询向量最相似的数据。
(3)索引优化:构建空间分区或图结构索引(如Hierarchical Navigable Small World, HNSW),平衡搜索速度与精度。
(4)元数据支持:可关联向量与文本、标签等元数据,支持混合查询(如"查找与向量A相似且标签为'猫'的图片")。
2.5 与传统数据库的区别
| 功能点 | 传统数据库 | 向量数据库 |
|---|---|---|
| 检索方式 | 精确匹配 / 范围查询 | 语义相似度(向量Top-K) |
| 数据结构 | 行/列、主键索引 | 高维向量 + 元数据结构 |
| 查询能力 | SQL 查询 | 向量相似度 + 条件过滤 |
| 典型应用场景 | 电商、金融系统 | 搜索推荐、AI检索、RAG场景 |
2.6 那些常用的向量数据库
- 主流开源向量数据库(免费可自托管),这些适合技术团队自主部署,灵活控制数据:
Milvus:处理海量数据(如十亿级向量),支持图像、文本搜索,社区活跃。
Chroma:轻量级,适合快速开发原型(如聊天机器人),集成简单。
Qdrant:平衡搜索速度与精度,支持实时更新,适合推荐系统。
Weaviate:结合图数据库,擅长语义搜索(如问答系统),支持多模态数据。
Faiss:Meta 开发,适合学术研究,支持 GPU 加速但配置复杂。
- 托管服务向量数据库(免运维)适合资源有限的团队,开箱即用:
Pinecone:最快响应(亚秒级),自动扩展,适合生产级 AI 应用。
Elasticsearch:同时支持全文和向量搜索,适合已有 Elastic 生态的企业。
SingleStore:唯一融合 SQL 和向量搜索,适合实时分析(如金融风控)。
MongoDB:文档数据库 + 向量搜索,适合混合数据场景。
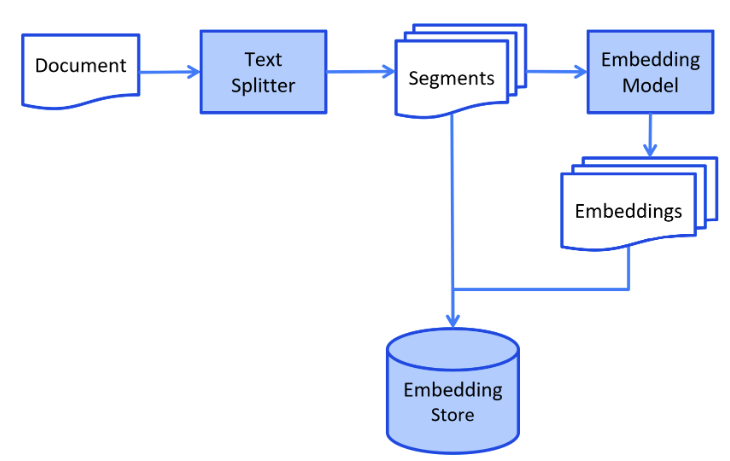
2.7 向量嵌入(Embedding)
向量嵌入(Embedding)是将文本转换为数值向量的技术,是 RAG 和语义搜索的基础
文本到向量的转换
示例1:
java
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
TextSegment segment1 = TextSegment.from("I like football.");
//将单个文本转换为向量
Embedding embedding1 = embeddingModel.embed(segment1).content();
System.out.println("向量维度: " + embedding1.dimension()); //384
System.out.println("向量值: " + Arrays.toString(embedding1.vector()));//向量值: [-7.621452E-5, -0.0026724, 0.0048467875, -0.066098645, 0.04864948, 0.00899909, 0.07489078, 0.019991739, 0.10673115, -0.036116153, -0.07130266, -0.07919503,...]
//计算余弦相似度
System.out.println("计算余弦相似度: " + CosineSimilarity.between(embedding1, embedding1));//0.9999999999999999示例2:https://github.com/langchain4j/langchain4j-examples/blob/main/other-examples/src/main/java/embedding/store/InMemoryEmbeddingStoreExample.java
java
package com.ai.langgraph4j.codehelper2.pdfbox;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.onnx.bgesmallenv15q.BgeSmallEnV15QuantizedEmbeddingModel;
//import dev.langchain4j.model.embedding.onnx.allminilml6v2.AllMiniLmL6V2EmbeddingModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.util.List;
public class InMemoryEmbeddingStoreExample {
public static void main(String[] args) {
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
TextSegment segment1 = TextSegment.from("I like football.");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
TextSegment segment2 = TextSegment.from("The weather is good today.");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.search(embeddingSearchRequest).matches();
EmbeddingMatch<TextSegment> embeddingMatch = matches.get(0);
System.out.println(embeddingMatch.score()); // 0.8235980955180371
System.out.println(embeddingMatch.embedded().text()); // I like football.
// In-memory embedding store can be serialized and deserialized to/from JSON
// String serializedStore = embeddingStore.serializeToJson();
// InMemoryEmbeddingStore<TextSegment> deserializedStore = InMemoryEmbeddingStore.fromJson(serializedStore);
// In-memory embedding store can be serialized and deserialized to/from file
// String filePath = "/home/me/embedding.store";
// embeddingStore.serializeToFile(filePath);
// InMemoryEmbeddingStore<TextSegment> deserializedStore = InMemoryEmbeddingStore.fromFile(filePath);
}
}2.8 Embedding 模型
方法1: 用于开发调试 BgeSmallEnV15QuantizedEmbeddingModel
注: 只需要添加依赖即可
java
public static void main(String[] args) {
// 1. 创建嵌入模型
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
// EmbeddingModel embeddingModel = new BgeSmallZhEmbeddingModel();
// 2. 创建内存向量数据库
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
// 3. 准备批量文档片段
List<TextSegment> segments = List.of(
TextSegment.from("Java 是一种面向对象的编程语言"),
TextSegment.from("Python 是一种简洁易学的编程语言"),
TextSegment.from("JavaScript 主要用于 Web 开发"),
TextSegment.from("机器学习是人工智能的一个分支")
);
// 4. 嵌入并存储文档片段
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment);
}
// 5. 搜索
String query = "什么编程语言适合 Web?";
Embedding queryEmbedding = embeddingModel.embed(query).content();
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder().maxResults(1).minScore(Double.valueOf("0.5")).queryEmbedding(queryEmbedding).build();
// 6. 输出结果
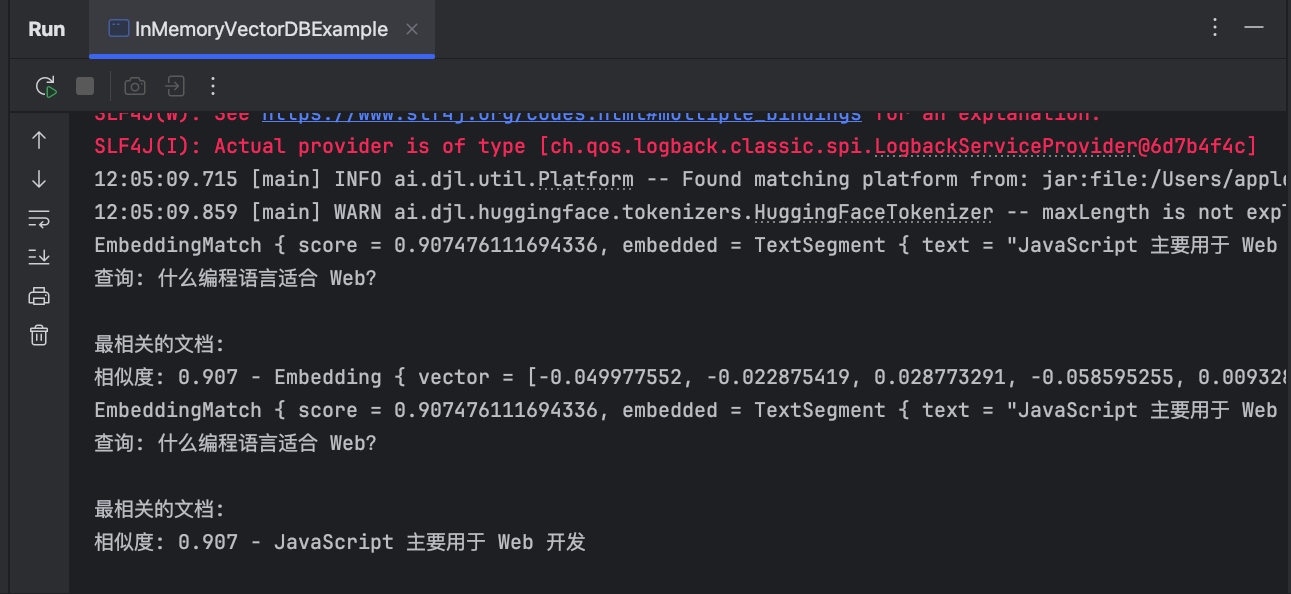
EmbeddingSearchResult searchResult = embeddingStore.search(searchRequest);
searchResult.matches().forEach(embedding -> {
System.out.println(embedding.toString());
});
List<EmbeddingMatch<ImageCacher.Embedded>>matches = searchResult.matches();
System.out.println("查询: " + query);
System.out.println("\n最相关的文档:");
for (EmbeddingMatch<ImageCacher.Embedded> match : matches) {
//没有语句,是语句的向量
System.out.printf("相似度: %.3f - %s\n", match.score(), match.embedding().toString());
System.out.println( match.toString());// EmbeddingMatch { score = 0.907476111694336, embedded = TextSegment { text = "JavaScript 主要用于 Web 开发" metadata = {} }, embeddingId = 5215685a-5715-4634-9c44-72be8206e4a3, embedding = Embedding
// String information = match.embedded().text();//报错,使用不了
// System.out.println( information);
}
List<EmbeddingMatch<TextSegment>>matches2 = searchResult.matches();
System.out.println("查询: " + query);
System.out.println("\n最相关的文档:");
for (EmbeddingMatch<TextSegment> match : matches2) {
//没有语句,是语句的向量
System.out.printf("相似度: %.3f - %s\n", match.score(), match.embedded().text());
}
}控制台输出结果:
注:
// 嵌入单个文本
Embedding embedding = model.embed("Hello World").content();
// 批量嵌入
List<TextSegment> segments = List.of(
TextSegment.from("文本1"),
TextSegment.from("文本2"),
TextSegment.from("文本3")
);
List<Embedding> embeddings = model.embedAll(segments).content();
三、构建PDF文件摘要总结功能
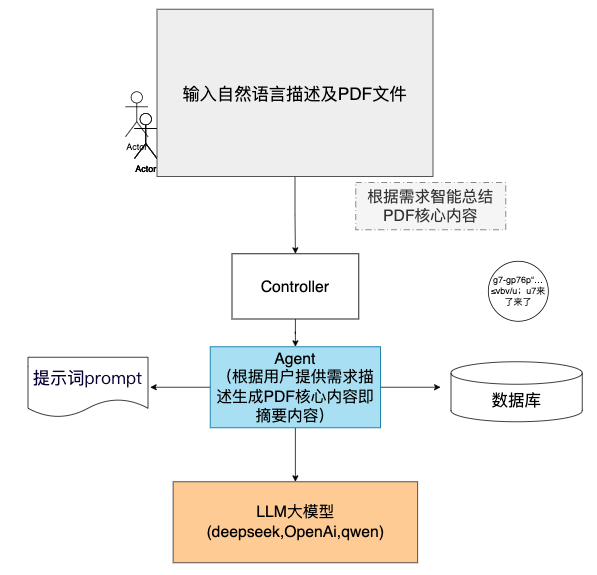
注: 很多PDF大量应用的场景,比如 专业论文等场景都可以用到。