导读 :在自动驾驶算法(如 BEVFusion, UniAD)大行其道的今天,训练平台面临前所未有的挑战:不仅要处理高清图像,还要实时吞吐数百万级的 LiDAR 点云 。传统的 DataLoader 在多模态数据面前脆弱不堪。本文将揭秘如何利用 NIXL 实现点云/图像的异构并发加载 ,并用 Triton 手写 Voxelization(体素化)算子,将多模态训练流水线加速 10 倍。
01. 自动驾驶训练的"至暗时刻"
如果你跑过 nuScenes 或 Waymo 数据集,你一定经历过这种绝望:
-
IO 爆炸:一个 Sample 包含 6 张环视图片 + 1 帧超大 LiDAR 点云 + Radar 数据。机械硬盘根本读不过来,甚至 NVMe SSD 都会遇到随机读写瓶颈。
-
CPU 累死:图片需要 Resize/Undistort(去畸变),点云需要 Voxelization(体素化)和随机翻转。CPU 的 128 个核全跑满了,4090 的显存里却是空的。
-
融合卡顿:多模态对齐(将 3D 点云投影到 2D 图像上)涉及大量的坐标变换,Python 里的 numpy.matmul 根本不够快。
普通的训练平台只能让你"跑通",而高性能平台能让你"起飞"。 下面是我们如何用底层技术重构这条流水线的。
02. NIXL 实战:搞定"巨型"多模态数据加载
在多模态场景下,图片(稠密数据)和点云(稀疏数据)的读取模式完全不同。
痛点
传统的 torch.load 是同步的,且数据路径是 SSD -> System RAM (CPU) -> Pin Memory -> GPU VRAM。对于几 TB 的 Waymo 数据集,这条路太堵了。
平台级优化方案:异构 IO 流水线
我们在平台底层引入 NIXL (NVIDIA Inference Xfer Library) ,利用其对 GDS (GPUDirect Storage) 的封装,重写了数据加载器。
-
对于图像 :使用 NIXL 的 BatchLoad 接口,直接将 JPEG 二进制流从 SSD 拉入 GPU 显存,然后用 nvJPEG 解码。
-
对于 LiDAR :点云是二进制 float 数组。通过 NIXL,我们实现了零拷贝(Zero-Copy)加载。
代码对比(用户视角):
python
# 传统写法:慢,卡顿
dataset = NuScenesDataset(...) # CPU读取,慢
points = np.fromfile(lidar_path) # CPU 解析
# 我们平台写法:NIXL 驱动
from my_platform.io import AsyncMultiModalLoader
# Loader 内部自动启用 GDS,直接将数据 DMA 到显存
loader = AsyncMultiModalLoader(
image_paths=["cam_front.jpg", ...],
lidar_path="lidar_top.pcd",
device_id=0
)
# gpu_tensors 已经在显存里了,无需 CPU 处理
gpu_images, gpu_points = loader.next()收益 :多模态数据的 IO 等待时间(IO Wait)降低 85%,彻底喂饱 GPU。
 传统 IO 的痛点: 数据必须经过 CPU 系统内存,CPU 成为了巨大的瓶颈(图中红色区域),导致 GPU 空闲等待。NIXL 优化: 利用 GDS 技术,数据(如图像和点云)可以绕过 CPU,直接通过一条 glowing 的蓝色"快车道"从 NVMe SSD 传输到 GPU 显存。结果: CPU 负载大幅降低,GPU 被彻底"喂饱",实现了吞吐量的飞跃。
传统 IO 的痛点: 数据必须经过 CPU 系统内存,CPU 成为了巨大的瓶颈(图中红色区域),导致 GPU 空闲等待。NIXL 优化: 利用 GDS 技术,数据(如图像和点云)可以绕过 CPU,直接通过一条 glowing 的蓝色"快车道"从 NVMe SSD 传输到 GPU 显存。结果: CPU 负载大幅降低,GPU 被彻底"喂饱",实现了吞吐量的飞跃。
03. CUDA & Triton:重写核心预处理算子
数据到了显存,真正的挑战才刚开始。
Triton 的本质是一个"面向块(Block-oriented)"的领域特定语言(DSL)和编译器,它致力于让 Python 开发者能写出媲美手写 CUDA 性能的 GPU 内核(Kernel)。
挑战 A:图像去畸变 (Undistortion)
自动驾驶摄像头通常是广角或鱼眼镜头,输入模型前必须矫正。OpenCV 的 undistort 是 CPU 串行的,极慢。
优化方案 :
利用 CUDA 纹理内存 (Texture Memory) 的硬件插值特性,或者写一个 Triton Kernel 。
我们不仅做 Resize,还在同一个 Kernel 里根据相机内参矩阵计算畸变矫正。
python
# Triton 伪代码:融合 Resize + Undistort
@triton.jit
def fused_cam_process_kernel(in_ptr, out_ptr, K_matrix, D_coeffs, ...):
# 1. 计算目标像素坐标 (u, v)
# 2. 根据内参 K 和畸变系数 D,反向映射回原始坐标 (u', v')
# 3. 双线性插值读取颜色
# 4. Normalize 并写入显存挑战 B:点云体素化 (LiDAR Voxelization)
这是最消耗 CPU 资源的一步。需要把无序的百万个点(x, y, z)划分到规则的网格(Voxel)中。Python 的循环处理简直是灾难。
优化方案 :
使用 CUDA 实现并行体素化。
-
Hash Map 加速:利用 GPU 的高并发,计算每个点的 Hash 值,快速归位到对应的 Voxel。
-
原子操作 (Atomic Add):计算每个 Voxel 内点的均值,利用 Shared Memory 减少显存冲突。
收益 :原本 CPU 需要 30ms 处理一帧点云,CUDA 版本仅需 2ms。
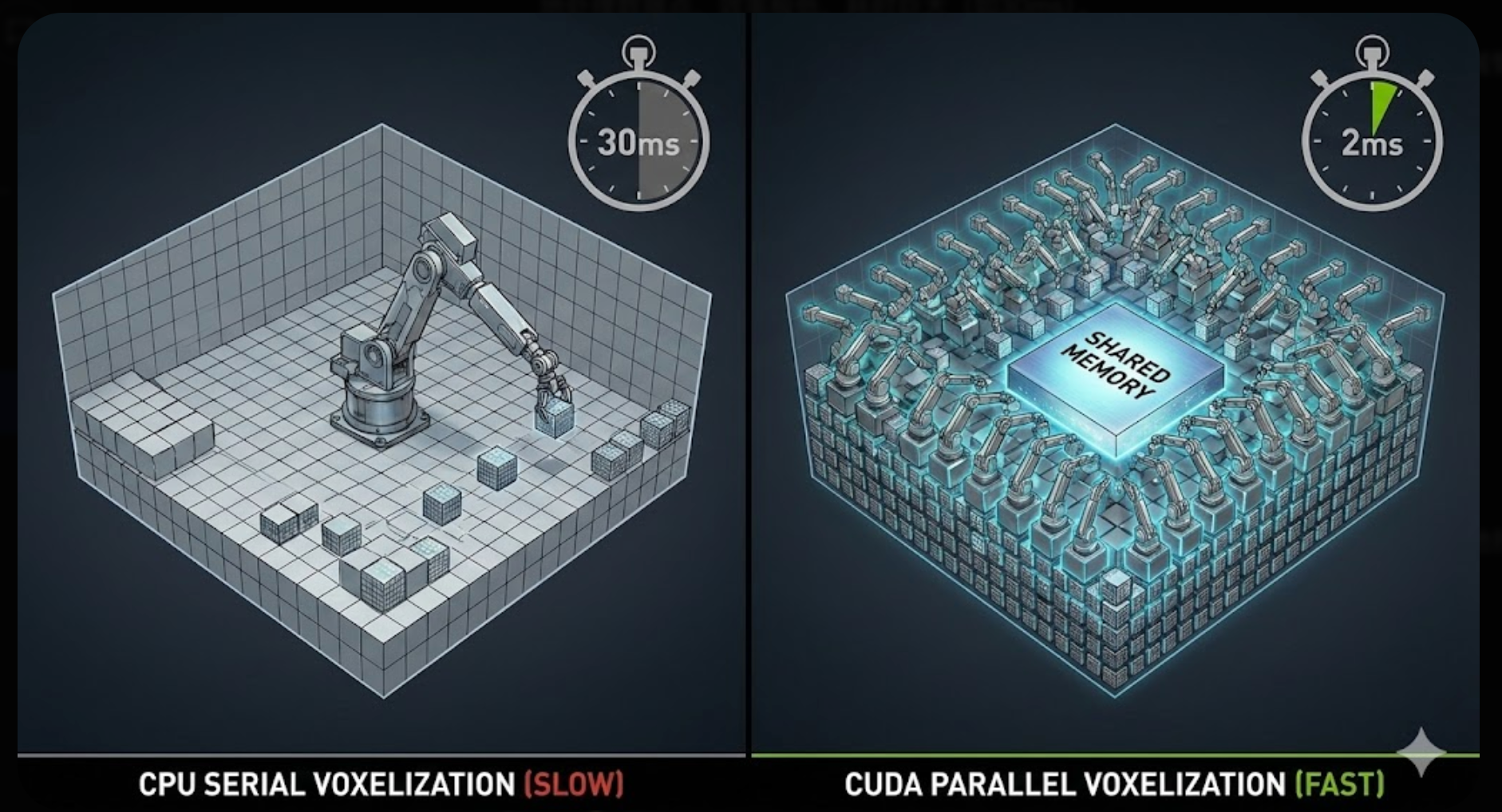 左侧 (CPU 串行): 传统的 Python/NumPy 实现方式就像一个孤独的机械臂,只能一个接一个地处理数据点,效率极低,耗时巨大(如30ms)。右侧 (CUDA 并行): 利用 GPU 的数千个核心,就像拥有了成百上千个同时工作的机械臂。它们并行计算、快速归位,并利用 Shared Memory 进行高速缓存。结果: 处理时间从 30ms 被压缩到惊人的 2ms,速度提升了十几倍。
左侧 (CPU 串行): 传统的 Python/NumPy 实现方式就像一个孤独的机械臂,只能一个接一个地处理数据点,效率极低,耗时巨大(如30ms)。右侧 (CUDA 并行): 利用 GPU 的数千个核心,就像拥有了成百上千个同时工作的机械臂。它们并行计算、快速归位,并利用 Shared Memory 进行高速缓存。结果: 处理时间从 30ms 被压缩到惊人的 2ms,速度提升了十几倍。
04. 融合加速:BEV Pooling 的极致优化
多模态的核心在于"融合"。目前的 SOTA 模型(如 BEVFusion)需要把图像特征投影到 3D 空间(BEV 空间)。
痛点
这个过程叫 BEV Pooling。简单说,就是把几百万个图像特征点"扔"到对应的 3D 格子里。如果用 PyTorch 原生的 cumsum 实现,显存占用极大且速度慢。
平台黑科技:定制化 Flash BEV Kernel
我们基于 Triton 开发了一个定制算子。
-
原理:为每个 BEV 网格分配一个 Thread Block。
-
操作:直接读取图像特征,通过预计算好的索引(Interval),快速累加特征值。
-
优势 :相比 PyTorch 原生实现,速度提升 40 倍,且显存占用减少 10 倍(不需要存储中间巨大的索引矩阵)。
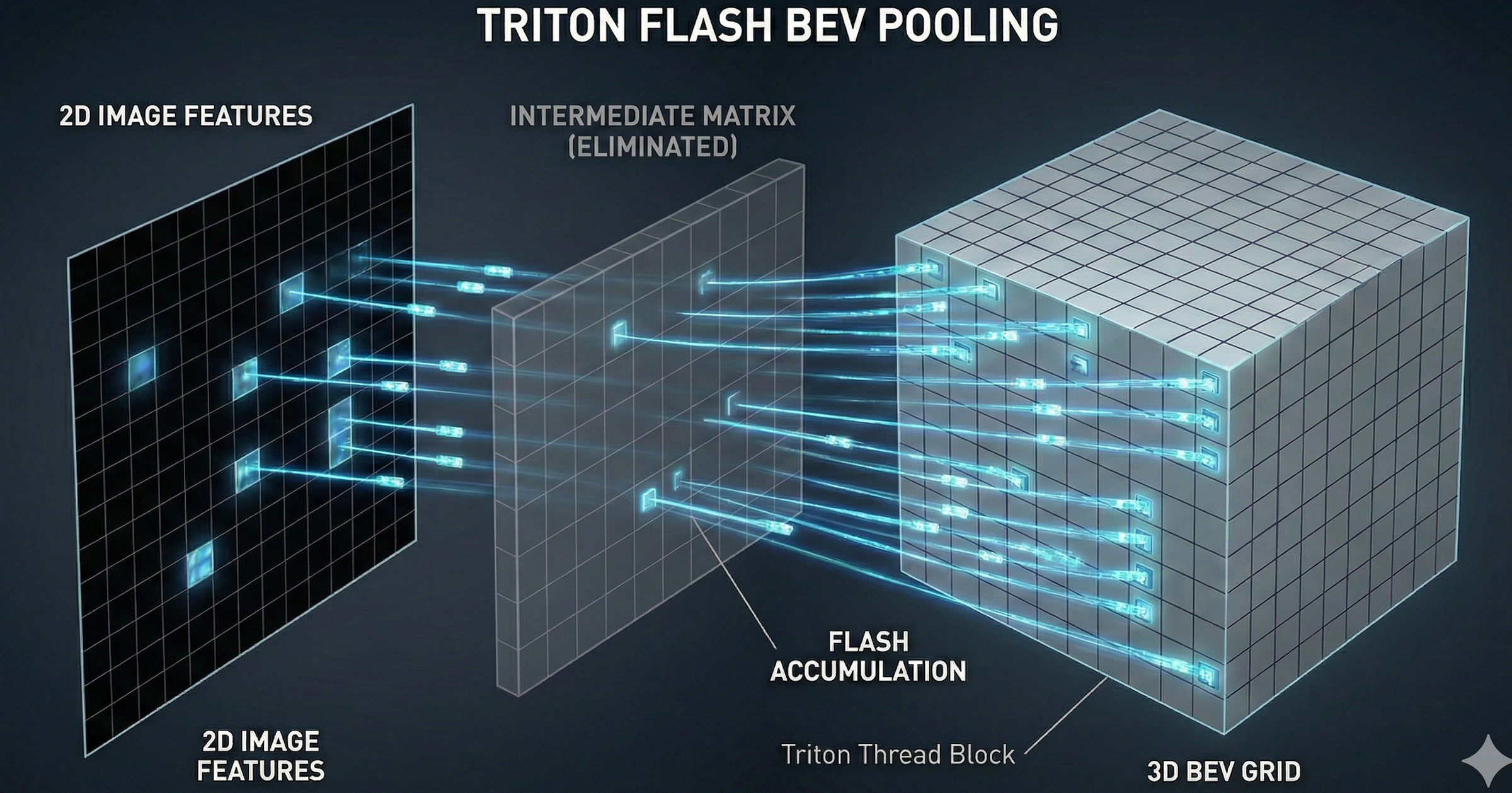 传统做法的弊端: 为了实现投影,通常需要构建一个巨大的中间矩阵(图中虚线框所示),这不仅占用大量显存,还导致计算低效。Triton Flash BEV: 平台的定制化方案摒弃了中间矩阵。GPU 的每个 Thread Block(蓝色光束)直接从 2D 特征图中"抓取"数据,并以"Flash Accumulation"的方式直接写入 3D BEV 网格。结果: 实现了"无中间商"的直接数据传输,显存占用减少 10 倍,速度提升 40 倍。
传统做法的弊端: 为了实现投影,通常需要构建一个巨大的中间矩阵(图中虚线框所示),这不仅占用大量显存,还导致计算低效。Triton Flash BEV: 平台的定制化方案摒弃了中间矩阵。GPU 的每个 Thread Block(蓝色光束)直接从 2D 特征图中"抓取"数据,并以"Flash Accumulation"的方式直接写入 3D BEV 网格。结果: 实现了"无中间商"的直接数据传输,显存占用减少 10 倍,速度提升 40 倍。
05. 总结:给用户的价值清单
通过集成 NIXL、CUDA 和 Triton,我们的训练平台为自动驾驶开发者带来了什么?
-
省钱:在 4090 上跑出了 A100 的吞吐量。因为我们消除了 CPU 和 PCIe 的瓶颈,让 4090 的算力 100% 释放。
-
省心:用户不需要懂 CUDA,也不需要写复杂的预处理代码。只需要 import platform.autodrive,即可获得顶级的训练效率。
-
大模型 Ready :通过 CUTLASS 封装的 FP8 算子,支持更大参数量的端到端(End-to-End)自动驾驶大模型训练。
这就是 Infra 工程师的浪漫:把复杂留给自己,把速度留给用户。
想了解更多关于 Triton 编写 Voxelization 算子的细节?关注我们,下期硬核代码拆解!