《LangGraph 实战:基于 LangGraph 实现结构化输出与智能 Router 路由代理》
1 导语
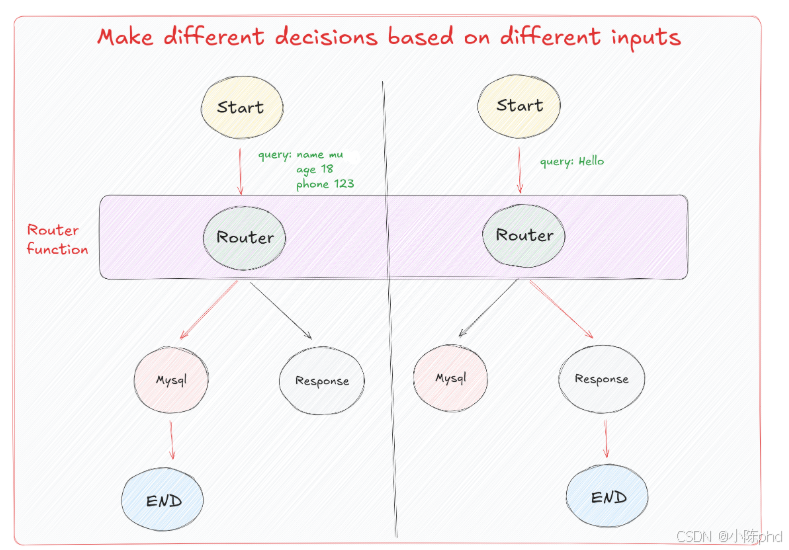
通常情况下,Agent能够处理多种格式的输入数据,并通过内置的路由逻辑确定具体执行的操作流程。如图所示,Agent的起始节点(Start)接收输入信息,这些输入可能包含结构化查询(如"name: muyu, age: 18, phone: 123")或简单对话内容(如"Hello")。系统会根据输入类型,通过Router函数进行智能路由,将不同请求分发至对应的处理流程。
本文将指导你实现一个"对话+信息提取"的双节点工作流。你将掌握如何运用LangGraph框架来实现结构化输出和智能路由代理功能。通过本项目的实践,你将具备构建智能代理应用的能力。一般来说,Agent是可以接收各种形式的输入,并通过预设的路由逻辑来确定执行的具体操作。如图所示,Agent的开始节点(Start)接收输入数据,这些输入可以是查询请求(例如"name: muyu, age: 18, phone: 123"或"Hello")。根据输入的不同,流程通过Router函数进行决策,将不同的输入引导到正确的处理流程。
本文将指导你实现一个"对话+信息提取"的双节点工作流。你将掌握如何运用LangGraph框架来实现结构化输出和智能路由代理功能。通过本项目的实践,你将具备构建智能代理应用的能力。
2 技术栈清单
- Python == 3.11.14
- langgraph == 1.0.5
- langchain-openai == 1.1.7
- langchain-core == 1.2.7
- python-dotenv == 1.2.1
3 项目核心原理
这里的核心是Router function ,它根据输入数据的结构和内容,动态地决定下一步应该执行的节点。例如,对于具体的查询请求,Router决定需要访问数据库(Mysql节点),而对于简单的问候(如"Hello"),则直接返回一个响应(Response节点)。每个决策路径最终都指向一个结束节点(End)。所以我们要明确的是,在构建实际的Agent时,Router fuction的定义才是最关键且最重要的。我们需要在这个函数中,基于特定的一些格式或者标识来区分该执行哪一条分支的逻辑。而 对于消息的传递,大模型往往是通过结构化输出,引导其在响应的过程中应遵循哪种模式来工作,就类似于工具调用过程。Router就很好的利用到了这个特性,通过结构化输出的特性来控制接下来的分支路径。
这里我们先来了解一下什么是结构化输出。在LangGraph中,实现结构化输出可以通过以下三种有效方式完成:
- 提示工程:指示大模型以特定格式做出回应。
- 输出解析器:采用后处理的方法从大模型的响应中提取结构化数据。
- 工具调用:利用一些内置工具调用功能来生成结构化输出。
4 实战步骤
4.1 环境准备
首先配置 .env 环境变量,确保通义千问 API 接入正常,并安装依赖。
bash
# 安装核心依赖包
pip install langgraph==1.0.5 langchain-openai==1.1.7 python-dotenv==1.2.1
4.2 代码实现
4.2.1 提示工程
python
import getpass
import os
from pyexpat import model
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
load_dotenv()
key=os.getenv("DASHSCOPE_API_KEY")
base_url=os.getenv("DASHSCOPE_API_BASE")
llm = ChatOpenAI(model="qwen-plus",api_key=key,base_url=base_url,temperature=0,)
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json`",
),
("human", "{query}"),
]
)
chain = prompt | llm
ans = chain.invoke({"query": "我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111"})
直接通过提示工程让大模型生成特定格式的输出虽然是可行的,但这种方法在复杂的Agent构建流程中非常并不稳定。一个进阶的优化方法是:引入后处理步骤,通过输出解析器来格式化大模型生成的响应。
4.2.2 提示工程 + 输出解析器
python
from langchain_core.messages import AIMessage
import json
import re
from typing import List
def extract_json(message: AIMessage) -> List[dict]:
"""Extracts JSON content from a string where JSON is embedded between \`\`\`json and \`\`\` tags.
Parameters:
text (str): The text containing the JSON content.
Returns:
list: A list of extracted JSON strings.
"""
text = message.content
# 定义正则表达式模式来匹配JSON块
pattern = r"\`\`\`json(.*?)\`\`\`"
# 在字符串中查找模式的所有非重叠匹配
matches = re.findall(pattern, text, re.DOTALL)
# 返回匹配的JSON字符串列表,去掉任何开头或结尾的空格
try:
return [json.loads(match.strip()) for match in matches]
except Exception:
raise ValueError(f"Failed to parse: {message}")
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json`",
),
("human", "{query}"),
]
)
chain = prompt | llm | extract_json
ans = chain.invoke({"query": "我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111"})
从结果可以明显看出,通过定制化的输出解析器得到的结果会更加的符合预期,而接下来我们要说的是,在LangGraph中我们更常用的,且效果更好的是,直接使用其内置的工具方法:.with_structured_output()。
这个方法通过接受一个定义了所需输出属性的名称、类型和描述的模式作为输入,进而生成一个类似模型的 Runnable。不同于常规模型输出字符串或消息,这个 Runnable 输出一个与输入模式相匹配的对象。可以通过几种方式指定这种架构,包括 TypedDict 类、JSON Schema 或 Pydantic 类。如果采用 TypedDict 或 JSON Schema,Runnable 将输出一个字典;若使用 Pydantic 类,则输出一个 Pydantic 对象。我们可以依次的来实践一下。
4.2.3 with_structured_output()方法
4.2.3.1 使用Pydantic做结构化输出
使用Pydantic去限定输出格式,可以确保所有通过此模型处理的数据都会符合指定的结构和数据类型,从而减少数据处理中的错误并增加代码的健壊性。此外,Pydantic的验证系统还会自动确保所有字段都符合预定义的格式,如果输入数据不符合预期,则会抛出错误。比如下面是一个用Pydantic定义用户信息模型的示例:
python
from typing import Optional
from pydantic import BaseModel, Field
# 定义 Pydantic 模型
class UserInfo(BaseModel):
"""Extracted user information, such as name, age, email, and phone number, if relevant."""
name: str = Field(description="The name of the user")
age: Optional[int] = Field(description="The age of the user")
email: str = Field(description="The email address of the user")
phone: Optional[str] = Field(description="The phone number of the user") 在这个UserInfo模型中:
- name(必需): 存储用户的名字。
- age(可选): 存储用户的年龄,这是一个可选字段。
- email(必需): 存储用户的电子邮件地址。
- phone(可选): 存储用户的电话号码,这也是一个可选字段。
对于.with_structured_output()方法,如果我们希望模型返回一个Pydantic对象,只需要传入所需的Pydantic类即可,即UserInfo,代码如下所示:
python
import getpass
import os
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="qwen-plus", api_key=key,base_url=base_url,temperature=0,)
structured_llm = llm.with_structured_output(UserInfo)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111")
print(extracted_user_info) 它返回的是一个
它返回的是一个UserInfo的Pytantic对象,每个字段中则填充了在原始非结构化文本中提取出来的结构化信息。经过这样的格式化输出呢,对于Router function中,我们就可以通过类似这样的伪代码去继续路由分支的选择,比如:
python
# isinstance 函数用于判断一个对象是否是一个已知的类型,或者是该类型的子类的实例
if isinstance(extracted_user_info, UserInfo):
print("执行节点A的逻辑")
else:
print("执行节点B的逻辑") 这就是结构化输出对于LangGraph中路由函数逻辑判断的意义所在。除此之外,还有TypedDict 和 JSON Schema能够做到相同的效果,下面我们依次对这两种模式进行尝试。
4.2.3.2 使用TypedDict做结构化输出
python
from typing import Optional
from typing_extensions import Annotated, TypedDict
# 定义 TypedDict 模型
class UserInfo(TypedDict):
"""Extracted user information from text"""
name: Annotated[str, ..., "The user's name"]
age: Annotated[Optional[int], None, "The user's age"]
email: Annotated[str, ..., "The user's email address"]
phone: Annotated[Optional[str], None, "The user's phone number"]
structured_llm = llm.with_structured_output(UserInfo)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111")
extracted_user_info
使用 TypedDict 创建的"对象"实际上是一个字典。它没有Pydantic模型那样的方法和属性,因此功能相对简单。TypedDict 主要用于静态类型检查,但它不会在运行时进行类型检查,但搭配着LangGraph中已实现的基本验证机制,也是一种不错的方法。
4.2.3.3 Json Schema
对于Json Schema格式大家应该最为熟悉,不需要导入或类,可以直接通过字典的形式清楚地准确记录每个参数,但代价是代码会更加冗长。如下所示user_info 的 JSON Schema,用于描述用户信息的结构,包括姓名、年龄、邮箱地址和电话号码。
python
# 定义 JSON Schema
json_schema = {
"title": "user_info",
"description": "Extracted user information",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The user's name",
},
"age": {
"type": "integer",
"description": "The user's age",
"default": None,
},
"email": {
"type": "string",
"description": "The user's email address",
},
"phone": {
"type": "string",
"description": "The user's phone number",
"default": None,
},
},
"required": ["name", "email"],
}
structured_llm = llm.with_structured_output(json_schema)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111")
4.3 结合结构化输出构建路由图
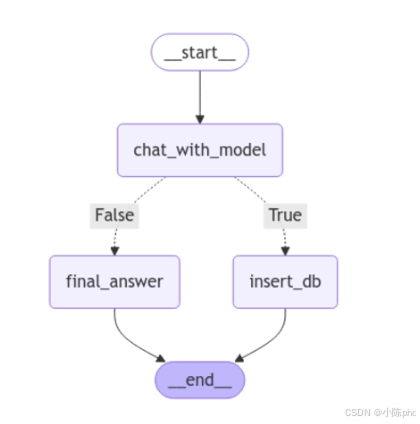
三种不同的结构化输出方法,我们更常使用的是用Pydantic来处理路由决策。在这种策略下,我们可以通过定义一个包含Union类型属性的父模型来灵活地从多种模式中选择适当的路由分支。例如,如果我们想根据输出决定是查询数据库还是直接回答问题,可以创建一个统一的模型来封装可能的输出类型。代码如下所示:
python
from typing import Union, Optional
from pydantic import BaseModel, Field
# 定义数据库插入的用户信息模型
class UserInfo(BaseModel):
"""Extracted user information, such as name, age, email, and phone number, if relevant."""
name: str = Field(description="The name of the user")
age: Optional[int] = Field(description="The age of the user")
email: str = Field(description="The email address of the user")
phone: Optional[str] = Field(description="The phone number of the user")
# 定义正常生成模型回复的模型
class ConversationalResponse(BaseModel):
"""Respond to the user's query in a conversational manner. Be kind and helpful."""
response: str = Field(description="A conversational response to the user's query")
# 定义最终响应模型,可以是用户信息或一般响应
class FinalResponse(BaseModel):
final_output: Union[UserInfo, ConversationalResponse]
structured_llm = llm.with_structured_output(FinalResponse) 这个扩展后的代码将用于提取和存储用户的基本信息,包括姓名、年龄、电子邮件地址和电话号码的UserInfo模型与用于生成面向用户的交流响应的ConversationalResponse模型统一的放在了FinalResponse模型中,使用Union类型来支持灵活的输出选项。final_output属性可以是UserInfo类型,也可以是ConversationalResponse类型,这使得系统可以根据不同的业务逻辑和用户输入决定输出的具体形式。例如,在用户请求个人数据时可以返回UserInfo,而在普通查询时则提供ConversationalResponse。
python
# 从非结构化文本中提取用户信息或进行一般对话响应
# 从非结构化文本中提取用户信息或进行一般对话响应
extracted_user_info = structured_llm.invoke("你好")
extracted_user_info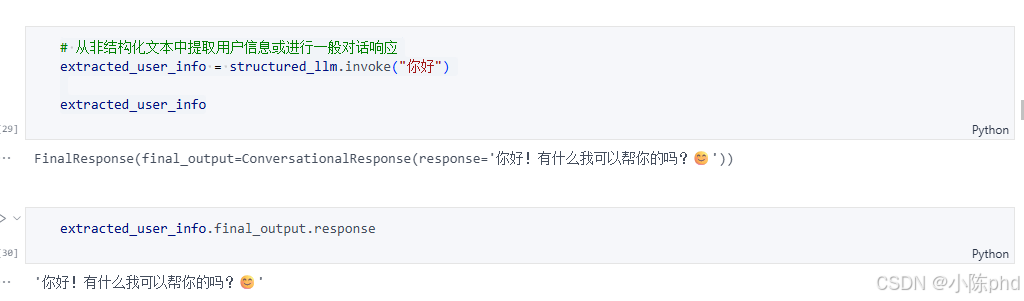
python
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫奥特曼,今年38岁,邮箱地址是aoteman#qq.com,电话是1211111111")
extracted_user_info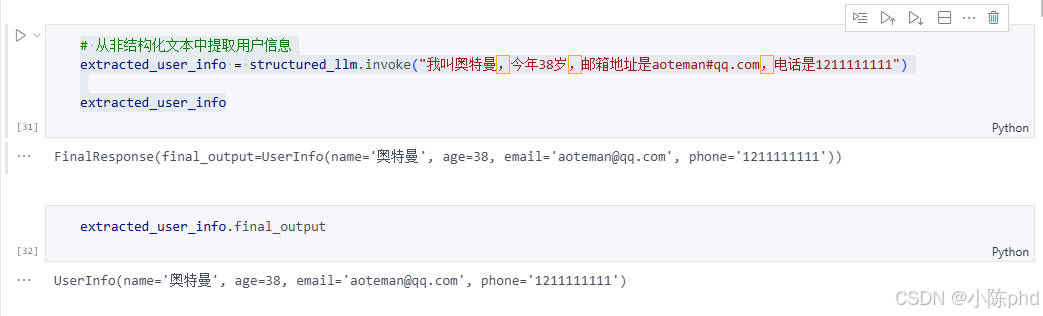
5 踩坑记录
5.1 节点返回值格式错误
- 错误现象 :
TypeError: 'AIMessage' object is not iterable - 根因分析 :由于定义了
operator.add,Reducer 要求返回的对象必须是可迭代的(即列表)。 - 解决方案 :亲测有效 的办法是确保返回值为
{"messages": [response]},必须带上班括号。
5.2 环境变量未生效
- 错误现象:API Key 缺失报错。
- 根因分析 :
load_dotenv()未在ChatOpenAI实例化前调用。 - 解决方案:将加载逻辑置于脚本最顶层。
5.3 提取指令被忽略
- 错误现象:模型没有输出 JSON,而是继续闲聊。
- 根因分析:SystemMessage 权重不够,或被之前的对话上下文干扰。
- 解决方案 :在提取节点中重置消息上下文,仅传递提取指令和目标文本。
6 总结与扩展
本文展示了 LangGraph 如何通过结构化输出与智能 Router 路由代理
欢迎评论区留言讨论核心主题相关的问题~