一、简介
本文以多层感知机MLP在CIFAR-10上进行图像分类为例,详细阐述了Fedavg这一经典联邦学习算法的应用,为各位读者打开初步学习联邦学习的大门。
 (Fedavg算法伪代码)
(Fedavg算法伪代码)
在联邦学习中,Server 不训练模型,只做调度与聚合;Client 不共享数据,只做本地训练。
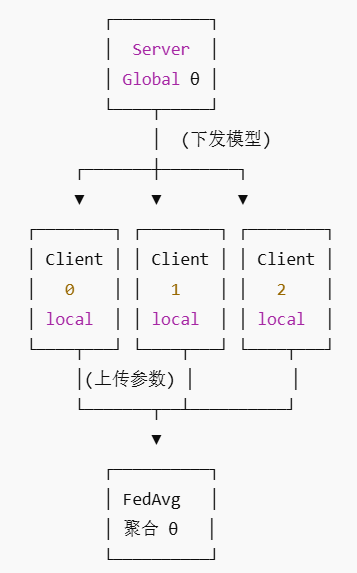
(上图为联邦聚合算法Fedavg的整体训练流程)
因为联邦学习是分布式的机器学习算法,所以在本文在模拟时按照多文件的代码结构梳理,读者想要复现的话请按照下面的项目格式进行整理,简单易上手,将下面的代码按照以下结构进行梳理后直接按照项目启动的说明就可以运行了。
fedavg_cifar10/
├── README.md
├── run.py # 主入口
├── server.py # 联邦服务器
├── client.py # 客户端逻辑
├── fedavg.py # FedAvg 聚合
├── model.py # MLP 模型
├── data.py # CIFAR-10 数据 + 客户端划分
├── utils.py # 评估工具
二、项目启动
1️⃣ 创建 Conda 环境
conda create -n fedavg-demo python=3.9 -y
conda activate fedavg-demo2️⃣ 安装 PyTorch
pip install torch torchvision torchaudio
3️⃣ 安装其余依赖
pip install numpy tqdm
4️⃣启动训练
python run.py
第一次运行的时候会首先下载数据集,大概要20-30mins左右,大家耐心等待就好啦~

最后应该会输出类似的内容:
===== Round 0 =====
Global Accuracy after round 0: 0.312
===== Round 1 =====
Global Accuracy after round 1: 0.418
...
三、项目说明
下面对每个模块做详细解读,想要直接运行的朋友可以直接复制粘贴:
1️⃣ model.py ------ 模型定义("被联邦的对象")
python
# model.py
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(32 * 32 * 3, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1) # flatten
return self.net(x)-
CIFAR-10 输入:
32×32×3 -
全是
Linear→ FedAvg 非常直观
2️⃣ data.py ------ CIFAR-10 + 客户端数据划分(IID)
python
# data.py
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
def load_cifar10():
transform = transforms.Compose([
transforms.ToTensor()
])
train_set = datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
test_set = datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
return train_set, test_set
def split_dataset(dataset, num_clients):
"""IID 划分"""
num_items = len(dataset) // num_clients
indices = torch.randperm(len(dataset))
client_subsets = []
for i in range(num_clients):
subset_idx = indices[i * num_items:(i + 1) * num_items]
client_subsets.append(Subset(dataset, subset_idx))
return client_subsets
def get_dataloader(dataset, batch_size=64, shuffle=True):
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)3️⃣ client.py ------ 客户端本地训练(关键)
python
# client.py
import torch
from model import MLP
def local_train(
client_id,
global_state_dict,
train_loader,
device,
local_epochs=1,
lr=1e-2
):
model = MLP().to(device)
model.load_state_dict(global_state_dict)
model.train()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
total_samples = 0
for _ in range(local_epochs):
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
loss = criterion(model(x), y)
loss.backward()
optimizer.step()
total_samples += x.size(0)
return {
"state_dict": model.state_dict(),
"num_samples": total_samples
}这一步就是在模拟真实联邦客户端,每个客户端client 不知道别的 client,客户端client之间 只看到 服务器端聚合后分发下来的全局模型global model,客户端client 只上传参数,不上传数据。
4️⃣ fedavg.py ------ FedAvg 代码实现
python
# fedavg.py
import torch
def fedavg(client_results):
total_samples = sum(r["num_samples"] for r in client_results)
global_state = {}
for key in client_results[0]["state_dict"].keys():
global_state[key] = sum(
r["state_dict"][key] * (r["num_samples"] / total_samples)
for r in client_results
)
return global_state上述代码的作用如下:
-
遍历每一个参数(weight / bias)
-
按客户端样本数加权
-
做逐元素平均
5️⃣ utils.py ------ 测试准确率
python
# utils.py
import torch
def evaluate(model, dataloader, device):
model.eval()
correct, total = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
preds = model(x).argmax(dim=1)
correct += (preds == y).sum().item()
total += y.size(0)
return correct / total6️⃣ server.py ------ 联邦服务器(调度核心)
python
# server.py
import copy
import torch
from model import MLP
from client import local_train
from fedavg import fedavg
class FedAvgServer:
def __init__(self, client_loaders, test_loader, device):
self.client_loaders = client_loaders
self.test_loader = test_loader
self.device = device
self.global_model = MLP().to(device)
def run_round(self, round_id):
print(f"\n===== Round {round_id} =====")
global_state = copy.deepcopy(self.global_model.state_dict())
client_results = []
for cid, loader in enumerate(self.client_loaders):
result = local_train(
cid, global_state, loader, self.device
)
client_results.append(result)
new_state = fedavg(client_results)
self.global_model.load_state_dict(new_state)
def train(self, rounds):
from utils import evaluate
for r in range(rounds):
self.run_round(r)
acc = evaluate(self.global_model, self.test_loader, self.device)
print(f"Global Accuracy after round {r}: {acc:.4f}")我们上面说过,服务器不训练模型,只做模型的调度和聚合。server端只干三件事:下发模型、收集客户端参数和调用Fedavg进行聚合。
7️⃣ run.py ------ 一键启动
python
# run.py
import torch
from data import load_cifar10, split_dataset, get_dataloader
from server import FedAvgServer
def main():
device = "cuda" if torch.cuda.is_available() else "cpu"
num_clients = 3 # 改成 6 试试
rounds = 10
train_set, test_set = load_cifar10()
client_datasets = split_dataset(train_set, num_clients)
client_loaders = [
get_dataloader(ds, batch_size=64)
for ds in client_datasets
]
test_loader = get_dataloader(test_set, batch_size=256, shuffle=False)
server = FedAvgServer(client_loaders, test_loader, device)
server.train(rounds)
if __name__ == "__main__":
main()所有的联邦变量都将在这里控制:客户端数量、通信轮数、batch size和CPU或者GPU的设备。