开篇介绍:
hello 大家,显而易见,我们这一篇博客是对上一篇博客的收尾,因为我们上一篇博客其实并没有对类和对象完成收尾,还剩下一些知识点,所以,我们将在这篇博客中,完成对这些知识点的讲解。
OK,话不多说大家,我们直接开始。
static成员:
1. 静态成员变量的定义与初始化
用static修饰的成员变量称为静态成员变量 ,其核心特性是:必须在类外进行初始化。
-
原因:静态成员变量属于类本身(而非某个对象),类的声明仅用于描述成员的存在,不分配内存;而初始化需要实际分配内存并设置初始值,因此必须在类外(其实也就是全局中)(通常是.cpp 文件中)单独完成。
-
语法示例:
class Test { public: static int count; // 类内声明(仅说明存在) }; int Test::count = 0; // 类外初始化(分配内存并赋值) //此时在外面就不用加static,直接类型就行
2. 静态成员变量的共享性与存储位置
静态成员变量为所有类对象所共享,不属于某个具体对象,其存储位置也与普通成员不同:
- 共享性:无论创建多少个类对象,静态成员变量只有一份内存副本。例如,若
Test类有静态成员count,则Test t1, t2;中t1.count和t2.count指向同一块内存,修改其中一个会影响所有对象。 - 存储位置:普通成员变量存储在对象内部(栈 / 堆中,随对象创建 / 销毁),而静态成员变量存储在静态区(程序启动时分配,结束时释放),生命周期与程序一致。
3. 静态成员函数的本质与特性
用static修饰的成员函数称为静态成员函数 ,其最核心的特点是:没有this指针。
this指针的作用:非静态成员函数默认隐含一个this指针,指向调用该函数的对象,用于访问当前对象的非静态成员(如this->x访问当前对象的x成员)。- 静态成员函数的特殊性:由于属于类本身(而非对象),调用时无需关联具体对象,因此没有
this指针。
4. 静态成员函数的访问规则
静态成员函数的访问范围受限于 "是否依赖this指针":
- 可以访问其他静态成员(静态成员变量 / 静态成员函数):因为静态成员也属于类,无需
this指针即可定位(直接通过类域访问)。 - 不能访问非静态成员(非静态成员变量 / 非静态成员函数):因为非静态成员属于具体对象,需要通过
this指针定位,而静态成员函数没有this指针,无法确定访问哪个对象的成员。
5. 非静态成员函数对静态成员的访问
非静态成员函数(有this指针)可以自由访问所有静态成员(变量和函数),也可以访问非静态成员:
-
原因:非静态成员函数既可以通过
this指针访问当前对象的非静态成员,也可以直接访问属于类的静态成员(无需依赖对象)。 -
示例:
class Test { private: int x; // 非静态成员变量 static int y; // 静态成员变量 public: void func() { // 非静态成员函数 x = 1; // 访问非静态成员(通过this->x) y = 2; // 访问静态成员(直接访问类的成员) } };
6. 静态成员的访问方式
静态成员属于类域,突破类域访问的方式有两种:
- 通过类名访问 :
类名::静态成员(推荐,不依赖对象,更直观)。示例:Test::count = 1; Test::staticFunc(); - 通过对象访问 :
对象.静态成员(本质仍是访问类的静态成员,与对象本身无关)。示例:Test t; t.count = 1; t.staticFunc(); - 类名访问(推荐) :班级的 "总人数" 是整个班级的属性 (不是某个同学的)。比如 "
班级::总人数 = 50;",直接通过 "班级"(类)操作总人数,不用依赖具体同学(对象),逻辑上最直观 ------ 因为 "总人数" 属于班级整体。 - 对象访问 :假设选 "同学小明" 来操作总人数,写成 "
小明.总人数 = 50;"。虽然代码能运行,但本质上 "总人数" 不是小明个人的属性(比如小明的身高、成绩才是个人属性),只是借 "小明" 这个对象去修改班级的总人数。所以这种方式能生效,但逻辑上不如 "类名访问" 直接。
总结一下就是,当我们使用静态成员函数去访问类中的静态成员变量时,我们是可以不用创建类变量,直接使用类名字::静态成员函数名来访问的,,即无对象调用,即:
sum::sumstaticfunc();而想要通过非静态成员函数去访问类中的静态成员变量时,就不能像上面那样子了,就得去创建一个类变量,然后通过这个变量去访问静态成员变量,即有对象调用,即:
sum s;
s.sumstaticfumn();7. 访问限定符对静态成员的限制
静态成员虽然属于类,但仍受public、protected、private访问限定符约束:
-
public静态成员:可在类外直接通过类名或对象访问。 -
private/protected静态成员:类外无法直接访问,需通过类内的public成员函数(静态或非静态)间接访问。 -
示例:
class Test { private: static int secret; // private静态成员 public: static int getSecret() { return secret; } // public静态函数,间接访问 }; // 类外: Test::secret = 1; // 错误(private不可直接访问) int val = Test::getSecret(); // 正确(通过public函数间接访问)
8. 静态成员变量不能在声明处指定缺省值
静态成员变量的声明位置(类内)不能用缺省值初始化(如static int x = 0;是错误的),原因是:
- 缺省值的设计初衷是为构造函数初始化列表服务的,用于对象创建时初始化其非静态成员(非静态成员属于对象,随对象构造而初始化),说白了就是,静态成员变量是不走类中的初始化列表的。
- 静态成员变量不属于任何对象,不参与对象的构造过程(与构造函数无关),因此不能在声明处使用缺省值,必须在类外单独初始化。
示例代码:
class example
{
public:
example()
//也不能在类的初始化列表去对静态成员变量进行定义初始化
//因为它并不存储在类中,而是存储在静态区中
:mval(10)
{
}
static void aprint()//静态类内成员函数是可以直接访问静态成员变量的,但是它不能直接访问其他非静态成员变量,因为它没有this指针
{
cout << ma << endl;
//cout << mval << endl; //非静态成员引用必须与特定对象相对
}
void operator++()
{
++ma;
}
private:
static int ma;//注意,由于是静态成员变量,所以也不能给缺省值
int mval;
};
//得在类外,也就是在全局中去进行静态成员变量的初始化
//但是由于是类的静态成员变量,所以也得申明是在哪一个类中
int example::ma = 10;//此时不必再有static,只需要类型
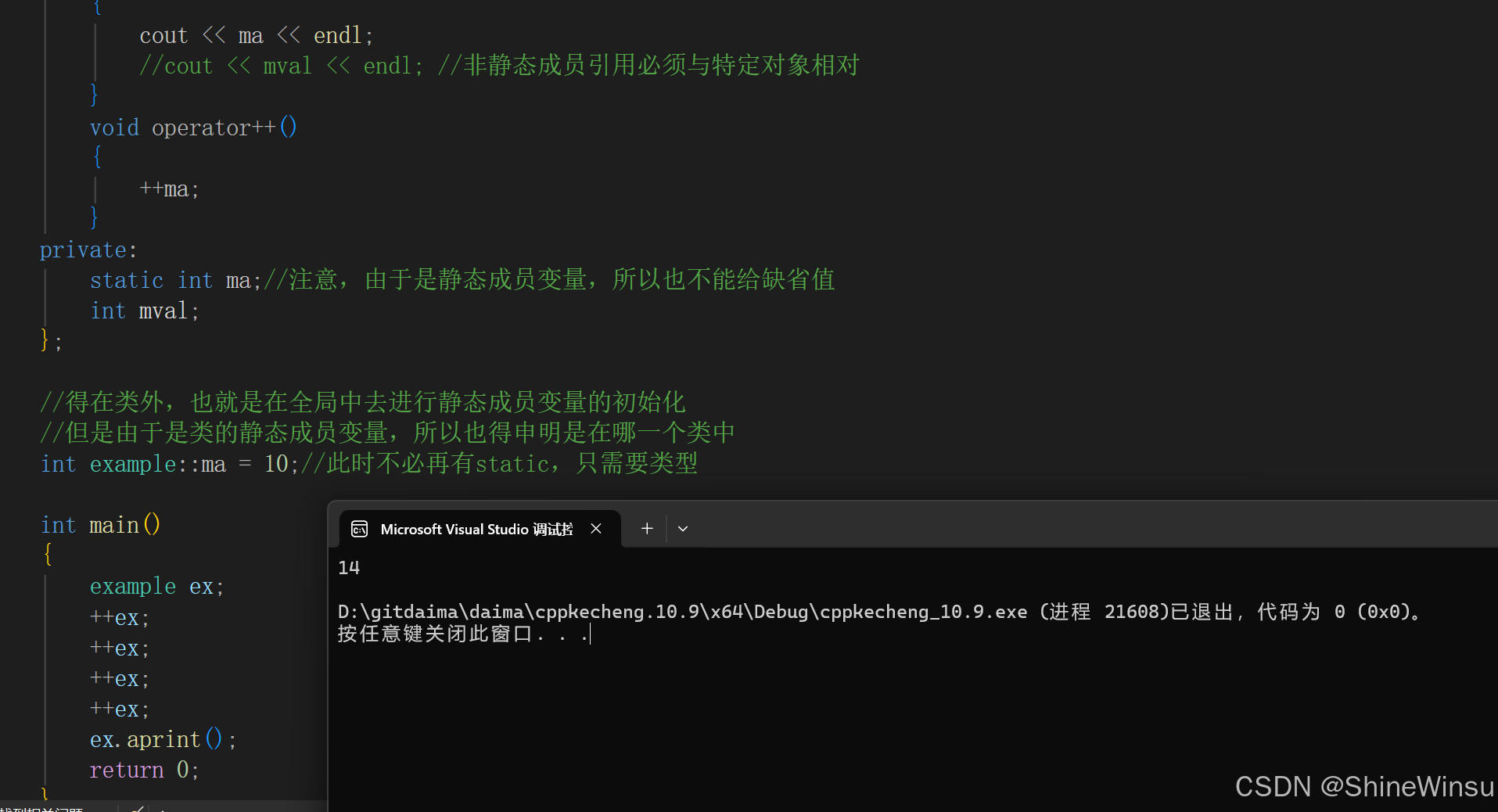
int main()
{
example ex;
++ex;
++ex;
++ex;
++ex;
ex.aprint();
return 0;
}
例题:
那么这道题要求很多,其实就是让我们使用静态的方法去解决问题。
那么我们有什么方法呢?其实可以这样,我们创建一个sum的类,然后这个类中存放两个成员变量,mi和mret,mi负责每次加1,从1到2,从2到3......直到n,而mret的作用就是每次加mi,然后累计,最后mret的值就是从1到n的和,那么大家注意,这两个变量得是静态的,为什么呢?因为题目是要求相加的,上面也说了,要是累计的结果,而只有全局变量或者静态变量才能做到这一点,又由于我们是在类中,所以就得用类的静态成员变量。
然后具体如何操作呢?那么就得用到sum类的构造函数了,我们要solution类中创建一个sum类型的arr数组,数组长度为n,那么为什么要这么做呢?
创建长度为n的Sum数组a[n]时,会调用n次Sum的构造函数,这是为什么呢?
1. 数组的本质:"多个独立对象的连续集合"
数组a[n]表示连续存储的n个Sum类型对象 。每个数组元素(如a[0]、a[1]...a[n-1])都是一个独立的Sum对象,彼此内存独立、逻辑独立。
2. 类对象的 "构造时机":创建时必须调用构造函数
C++ 中,类对象在 "创建瞬间" 会自动调用构造函数 (用于初始化对象的成员、执行构造逻辑)。无论是单个对象(如Sum s;)还是数组中的对象,只要是 "新创建的类对象",就会触发构造函数。
3. 数组元素的构造:每个元素都要 "单独构造"
当创建数组Sum a[n];时,编译器会执行以下步骤:
- 为
n个Sum对象分配连续的内存空间(数组的 "连续存储" 特性); - 对每个内存位置上的元素,逐个调用
Sum的构造函数进行初始化。
例如,若n=3,则:
- 构造
a[0]→ 调用 1 次Sum的构造函数; - 构造
a[1]→ 调用第 2 次Sum的构造函数; - 构造
a[2]→ 调用第 3 次Sum的构造函数;总共调用3次(即n次)。
4. 依赖 "默认构造函数" 的隐含条件
如果类没有显式定义构造函数,C++ 会生成默认构造函数 (无参构造函数)。数组初始化时,会自动调用这个默认构造函数。在之前的 "累加求和" 场景中,Sum类有默认构造函数(或用户定义的空构造函数),因此每个数组元素都能通过构造函数执行 "累加逻辑"。
核心结论
数组的每个元素都是独立的类对象,而 "类对象创建必须调用构造函数",因此n个元素会触发n次构造函数调用。这是 C++ 保证 "每个类对象都被正确初始化" 的基本规则。
所以这就是我们要创建创建长度为n的Sum数组a[n]。
然后呢,由于会调用n次的sum类中的构造函数,所以我们就可以在这个构造函数里面动手脚了,就是在这个构造函数里面去让mi++,同时mret=mret+mi;为什么呢?首先因为是它们两个都是静态成员变量,所以每次相加后的值都会保留下来,不会被销毁,又因为创建长度为n的Sum数组a[n]时,会调用n次Sum的构造函数,那么这就说明可以让构造函数里面的 mi++,mret=mret+mi运行n次,那么如此一来,不就实现了题目的要求了。
但是仅仅这样子还不够,我们还得想办法去获取mret的值,那么我们要怎么获取呢?其实可以依靠sum类中的成员函数,我们可以设置一个返回mret值的成员函数,然后在solution类中调用这个函数就可以了,这个思路是绝对可行的。
那么问题来了,我们要用什么静态成员函数还是非静态成员函数呢?根据上面说的,其实答案显而易见,就是使用静态成员函数,因为它是无对象调用,所以,我们的解题代码也就出来了:
class Sum {
public:
// 构造函数:每次创建Sum对象时,完成"累加"和"递增"
Sum() {
_ret += _i; // 把当前的_i加到总和_ret里
_i++; // _i自增,为下一次累加做准备
}
// 静态成员函数:获取最终的累加结果
static int GetRet() {
return _ret;
}
private:
static int _i; // 记录"当前要加的数"(从1开始)
static int _ret; // 记录"累加的总和"
};
// 类外初始化静态成员(必须步骤!)
int Sum::_i = 1;
int Sum::_ret = 0;
class Solution {
public:
int Sum_Solution(int n) {
Sum a[n]; // 创建n个Sum对象 → 调用n次构造函数
return Sum::GetRet(); // 返回1+2+...+n的和
}
};还是比较简单的。
友元:
友元是 C++ 中用于突破类的封装性 (访问限定符限制)的机制,分为友元函数 和友元类,以下是详细解析:
1. 友元的声明方式
友元需在类的内部 声明,声明时在函数 / 类的前面加 friend 关键字:
class MyClass {
// 友元函数声明
friend void friendFunc(MyClass& obj);
// 友元类声明
friend class FriendClass;
};这个我们在上上篇博客中讲流插入输出运算符重载就有讲到过,所以大家也应该已经很熟悉了。
2. 友元函数的特性
友元函数是外部函数(不是类的成员函数),但能访问类的私有 / 保护成员,核心特点:
-
不是类的成员函数 :友元函数的定义在类外,无需加
类名::作用域(就是类似普通定义在全局的函数一样),调用方式和普通函数一致(如friendFunc(obj);)。但它能直接访问类的private/protected成员。 -
声明位置不受访问限定符限制 :类的
public/private/protected段都可声明友元函数,效果完全相同(因为友元是类 "主动授予" 的权限,与声明位置的访问级别无关)。 -
可作为多个类的友元:一个函数能同时被多个类声明为友元,从而访问多个类的私有 / 保护成员。例如:
class A { friend void func(); }; class B { friend void func(); }; void func() { /* 可访问A和B的私有成员 */ }
3. 友元类的特性
若类 A 声明类 B 为友元类,则 B 的所有成员函数 都能访问 A 的私有 / 保护成员,核心特点:
-
友元类的所有成员都是友元 :
B是A的友元类 →B的public/private/protected成员函数,都能直接访问A的私有成员。 -
单向性(无交换性) :
A是B的友元 ≠B是A的友元。例如:class A { friend class B; }; // B能访问A的私有成员 class B { /* 未声明A为友元 */ }; // A不能访问B的私有成员 -
不可传递性 :
A是B的友元,B是C的友元 →A不是C的友元(友元关系无法 "传递")。
4. 友元的优缺点
-
优点:在特殊场景下简化操作,比如:
- 运算符重载(如输出流重载
ostream& operator<<(...)需访问类的私有成员,常声明为友元); - 两个类深度耦合时,用友元避免频繁调用 getter/setter,提高代码简洁性。
- 运算符重载(如输出流重载
-
缺点 :破坏了类的封装性 (私有成员被外部直接访问),增加了代码的耦合度 (类与友元的依赖更强),因此不宜滥用,仅在权衡后确有必要时使用。
总结:友元是 "权衡封装与便利" 的妥协机制,需谨慎使用以维持代码的封装性
示例代码:
示例 1:友元函数(普通友元 + 运算符重载友元)
友元函数不是类的成员,但能访问类的私有 / 保护成员,且可在类内任意位置声明。
#include <iostream>
#include <string>
using namespace std;
// 提前声明类(供友元函数参数使用)
class Student;
// 1. 普通友元函数:声明(可在类外先声明,也可直接在类内声明)
void printStudentDetail(const Student& s);
class Student {
private:
string _name; // 私有成员
int _age; // 私有成员
// 友元函数声明:在private段声明,仍能生效(不受访问限定符限制)
friend void printStudentDetail(const Student& s);
// 2. 运算符重载友元:常见场景(cout输出对象需访问私有成员)
friend ostream& operator<<(ostream& out, const Student& s);
public:
// 构造函数
Student(string name, int age) : _name(name), _age(age) {}
};
// 普通友元函数:定义(类外实现,无需加Student::)
void printStudentDetail(const Student& s) {
// 直接访问Student的私有成员_name和_age
cout << "友元函数打印:姓名=" << s._name << ",年龄=" << s._age << endl;
}
// 运算符重载友元:定义(访问私有成员拼接输出)
ostream& operator<<(ostream& out, const Student& s) {
out << "运算符重载打印:姓名=" << s._name << ",年龄=" << s._age;
return out; // 支持链式调用(如cout << s1 << s2)
}
// 测试友元函数
int main() {
Student s("张三", 18);
printStudentDetail(s); // 调用普通友元函数
cout << s << endl; // 调用运算符重载友元函数(等价于operator<<(cout, s))
return 0;
}运行结果:
友元函数打印:姓名=张三,年龄=18
运算符重载打印:姓名=张三,年龄=18示例 2:友元类(单向性 + 全成员访问)
友元类的所有成员函数都能访问目标类的私有成员,但关系是单向的(A 是 B 的友元≠B 是 A 的友元)。
#include <iostream>
using namespace std;
// 目标类:Teacher(声明Student为友元类)
class Teacher {
private:
string _course; // 私有成员:教授课程
int _salary; // 私有成员:薪资
// 声明Student为友元类:Student的所有成员函数都能访问Teacher的私有成员
friend class Student;
public:
Teacher(string course, int salary) : _course(course), _salary(salary) {}
};
// 友元类:Student(能访问Teacher的私有成员)
class Student {
public:
// Student的成员函数1:访问Teacher的私有成员
void checkTeacherCourse(const Teacher& t) {
cout << "学生查看老师课程:" << t._course << endl; // 直接访问私有成员_course
}
// Student的成员函数2:访问Teacher的另一个私有成员
void guessTeacherSalary(const Teacher& t) {
cout << "学生猜测老师薪资:" << t._salary << "元" << endl; // 直接访问私有成员_salary
}
};
// 测试友元类的单向性
int main() {
Teacher t("C++编程", 8000);
Student s;
// 1. Student(友元类)能访问Teacher的私有成员:正常运行
s.checkTeacherCourse(t); // 输出:学生查看老师课程:C++编程
s.guessTeacherSalary(t); // 输出:学生猜测老师薪资:8000元
// 2. Teacher不能访问Student的私有成员(单向性):
// 若Student有私有成员,Teacher的成员函数尝试访问会编译报错
return 0;
}示例 3:友元关系的不可传递性
若 A 是 B 的友元,B 是 C 的友元,A≠C 的友元(关系无法传递)。
#include <iostream>
using namespace std;
// 三层类:ClassMonitor(班长)→ Teacher(老师)→ Student(学生)
class Student {
private:
string _name;
// 声明Teacher为友元类:Teacher能访问Student的私有成员
friend class Teacher;
public:
Student(string name) : _name(name) {}
};
class Teacher {
private:
int _id;
// 声明ClassMonitor为友元类:ClassMonitor能访问Teacher的私有成员
friend class ClassMonitor;
public:
// Teacher(友元)能访问Student的私有成员
void printStudentName(const Student& s) {
cout << "老师打印学生姓名:" << s._name << endl; // 正常访问
}
};
class ClassMonitor {
public:
// ClassMonitor(友元)能访问Teacher的私有成员
void printTeacherId(const Teacher& t) {
cout << "班长打印老师工号:" << t._id << endl; // 正常访问
}
// 尝试访问Student的私有成员(测试不可传递性)
void tryPrintStudentName(const Student& s) {
// 错误:ClassMonitor不是Student的友元,即使Teacher是Student的友元
// cout << "班长尝试打印学生姓名:" << s._name << endl; // 编译报错!
}
};
// 测试不可传递性
int main() {
Student s("李四");
Teacher t; t._id = 1001; // ClassMonitor能访问Teacher的私有成员,这里直接赋值(仅演示)
ClassMonitor cm;
t.printStudentName(s); // 正常:Teacher是Student的友元
cm.printTeacherId(t); // 正常:ClassMonitor是Teacher的友元
// cm.tryPrintStudentName(s); // 编译报错:友元关系不可传递
return 0;
}核心特性对应代码总结
| 友元特性 | 对应示例位置 | 代码关键表现 |
|---|---|---|
| 友元函数访问私有成员 | 示例 1 的 printStudentDetail | 直接访问 s._name、s._age |
| 友元声明不受访问限定符 | 示例 1 的 friend 在 private 段 | 仍能正常调用友元函数 |
| 友元类全成员访问 | 示例 2 的 Student 类成员函数 | 两个函数都能访问 Teacher 私有成员 |
| 友元关系单向性 | 示例 2 的 Teacher→Student | Teacher 不能访问 Student 私有成员 |
| 友元关系不可传递 | 示例 3 的 ClassMonitor→Student | 编译报错,无法访问 s._name |
还是很简单的。
内部类:
在 C++ 中,内部类(也称嵌套类,nested class) 是指定义在另一个类(外部类)内部的类。它并非外部类的 "附属成员",而是具备独立性的类,仅受外部类的 "类域" 和 "访问限定符" 约束。以下从术语澄清、核心特性、访问细节、特殊场景(静态内部类)及标准库应用等方面,进行全面且细致的解析。
一、术语澄清:内部类 = 嵌套类
C++ 标准中并无 "内部类" 的官方术语,其正式名称是 嵌套类(nested class)------ 即 "定义在另一个类(外围类,enclosing class)内部的类"。我们常说的 "内部类" 是嵌套类的通俗叫法,二者含义完全一致,下文统一使用 "内部类" 以贴合日常表述。
二、核心特性:独立性与约束性并存
内部类的本质是 "独立的类 + 受外部类的双重约束",这是理解它的关键,具体表现为:
1. 独立性:内部类是独立的类,与外部类无 "包含关系"
内部类仅 "定义位置在外部类内部",但自身是完全独立的类,不依赖外部类存在,也不被外部类对象 "包含":
-
外部类对象不存储内部类成员 :外部类对象的内存大小,仅由外部类自身的成员(非静态成员、虚函数表指针等)决定,与内部类无关。示例:
#include <iostream> using namespace std; class Outer { // 外部类 public: class Inner { // 内部类 private: int _inner_val; // 内部类私有成员 }; private: int _outer_val; // 外部类私有成员(占4字节) }; int main() { // 外部类对象大小 = 自身成员大小(_outer_val占4字节),与Inner无关 cout << "sizeof(Outer) = " << sizeof(Outer) << endl; // 输出:4 // 内部类对象大小 = 自身成员大小(_inner_val占4字节) cout << "sizeof(Outer::Inner) = " << sizeof(Outer::Inner) << endl; // 输出:4 return 0; } -
创建内部类对象无需外部类对象 :即使不创建外部类对象,也能通过 "
外部类名::内部类名" 直接创建内部类对象。示例:int main() { // 正确:直接创建内部类对象,无需先创建Outer对象 Outer::Inner in_obj; return 0; }
2. 约束性:受外部类的 "类域" 和 "访问限定符" 限制
内部类的独立性并非无边界,它受外部类的两个核心约束:
(1)类域约束:必须通过 "外部类::内部类" 访问
内部类的作用域被限定在外部类的 "类域" 中,无法直接用内部类名访问 ,必须通过 "外部类名::内部类名" 指定类域,否则编译器会报错(认为找不到该类)。示例:
int main() {
// 错误:未指定类域,编译器无法识别Inner
// Inner in_err;
// 正确:通过"Outer::"指定类域,编译器能找到Inner
Outer::Inner in_ok;
return 0;
}(2)访问限定符约束:外部类的访问限定符控制内部类的 "可见性"
内部类在外部类中的定义位置(public/private/protected),决定了 "外部类之外的代码" 是否能访问该内部类:
| 内部类定义位置 | 外部类之外的代码是否可访问 | 适用场景 |
|---|---|---|
public |
可访问(通过 "Outer::Inner") | 内部类需被外部类之外的代码有限使用(如工具类) |
private |
不可访问(仅外部类内部可用) | 内部类是外部类的 "专属工具",不对外暴露 |
protected |
不可访问(仅外部类及子类内部可用) | 内部类需被外部类的子类复用 |
示例:private 内部类的限制(仅外部类内部可用)
class Outer {
private:
// 内部类定义在private区域:仅Outer内部可访问
class Inner {
public:
void inner_func() {
cout << "Inner's function" << endl;
}
};
public:
// 外部类内部:可正常创建Inner对象并调用成员
void outer_func() {
Inner in;
in.inner_func(); // 正确:输出"Inner's function"
}
};
int main() {
Outer out;
out.outer_func(); // 正确:通过外部类成员间接使用Inner
// 错误:Inner定义在Outer的private区域,外部无法访问
// Outer::Inner in_err;
return 0;
}三、访问细节:内部类与外部类的双向访问规则
内部类与外部类的访问权限是 "非对称" 的 ------ 内部类默认是外部类的友元,但外部类不是内部类的友元,具体规则如下:
1. 内部类访问外部类成员:默认是友元,可访问私有成员
C++ 规定:内部类默认是其外部类的友元类 。这意味着内部类的所有成员函数,都能直接访问外部类的 private/protected 成员(无需显式声明 friend)。
但注意:内部类访问外部类的 "非静态成员" 时,必须通过外部类对象(因为非静态成员属于对象,需绑定具体实例);访问 "静态成员" 时,无需外部类对象(静态成员属于类本身)。
示例:内部类访问外部类的静态与非静态成员
class Outer {
private:
int _outer_nonstatic = 10; // 非静态私有成员(属于对象)
static int _outer_static; // 静态私有成员(属于类)
public:
class Inner { // 内部类(默认是Outer的友元)
public:
// 访问外部类非静态成员:需传入外部类对象
void access_nonstatic(Outer& out_obj) {
// 正确:通过外部类对象访问非静态私有成员
cout << "Inner access Outer's nonstatic: " << out_obj._outer_nonstatic << endl;
}
// 访问外部类静态成员:无需对象,直接通过类域访问
void access_static() {
// 正确:通过"Outer::"访问静态私有成员
cout << "Inner access Outer's static: " << Outer::_outer_static << endl;
}
};
};
// 类外初始化外部类的静态成员
int Outer::_outer_static = 20;
int main() {
Outer out;
Outer::Inner in;
in.access_nonstatic(out); // 输出:Inner access Outer's nonstatic: 10
in.access_static(); // 输出:Inner access Outer's static: 20
return 0;
}2. 外部类访问内部类成员:需显式声明友元
外部类不是 内部类的友元,因此无法直接访问内部类的 private/protected 成员。若需访问,必须在内部类中显式声明外部类为友元 (friend class 外部类名;)。
示例:外部类访问内部类私有成员(需显式友元)
class Outer {
public:
class Inner {
// 显式声明Outer为友元:允许Outer访问Inner的私有成员
friend class Outer;
private:
int _inner_private = 30; // 内部类私有成员
};
// 外部类访问内部类私有成员
void access_inner_private(Inner& in_obj) {
// 正确:显式友元后,可直接访问Inner的私有成员
cout << "Outer access Inner's private: " << in_obj._inner_private << endl;
}
};
int main() {
Outer out;
Outer::Inner in;
out.access_inner_private(in); // 输出:Outer access Inner's private: 30
return 0;
}四、特殊场景:静态内部类
内部类可以被 static 修饰,称为静态内部类 。它与普通内部类的核心区别是:更强调与外部类的 "类级关联",且不隐含对外部类对象的依赖(但普通内部类本身也不依赖外部类对象,静态修饰更多是语义层面的明确)。
静态内部类的特性:
- 与普通内部类一样,独立于外部类,不被外部类对象包含;
- 创建时仍需通过 "
外部类::内部类"(static不改变类域约束); - 语义上更适合作为 "外部类的工具类"(如封装与外部类相关的静态逻辑)。
示例:静态内部类的使用
class MathUtil { // 外部类:数学工具类
public:
// 静态内部类:封装"整数相关的工具逻辑"
static class IntUtil {
public:
// 静态成员函数:判断是否为偶数(与外部类MathUtil语义关联)
static bool is_even(int num) {
return num % 2 == 0;
}
};
};
int main() {
// 调用静态内部类的静态成员函数:需指定两层类域
bool res = MathUtil::IntUtil::is_even(4);
cout << "4 is even? " << (res ? "Yes" : "No") << endl; // 输出:Yes
return 0;
}例题二重奏:
那么上面的那道例题也是能用内部类去解决的:
class Solution {
// 内部类:用于通过构造函数累加求和
class Sum {
public:
// 构造函数:每次创建对象时完成累加操作
Sum() {
_ret += _i;
++_i;
}
};
// 静态成员变量:用于记录当前累加值和累加结果
static int _i;
static int _ret;
public:
// 计算1到n的和
int Sum_Solution(int n) {
// 创建n个Sum对象,触发n次构造函数完成累加
Sum arr[n];
return _ret;
}
};
// 静态成员变量类外初始化
int Solution::_i = 1;
int Solution::_ret = 0;这么做我们就可以避免还要去加一个获取ret值的函数,因为sum是solution的内部类,所以solution的成员函数可以直接访问sum类的成员变量,管你三七二十一,我直接进入。
匿名对象:
在 C++ 中,匿名对象是一种特殊的对象形式,它没有明确的对象名称,仅在创建时使用一次,随后便会销毁。下面从定义、特性、使用场景和注意事项四个方面详细解析:
一、匿名对象与有名对象的定义对比
1. 有名对象
通过 类型 对象名(实参) 形式定义,有明确的标识符(对象名),可以被多次引用:
class Person {
public:
Person(string name) : _name(name) {}
void print() { cout << "Name: " << _name << endl; }
private:
string _name;
};
// 有名对象:有标识符"p",可重复使用
Person p("张三");
p.print(); // 多次使用对象名调用成员函数
p.print(); 2. 匿名对象
通过 类型(实参) 形式定义,没有对象名,只能在定义的当前行使用:
// 匿名对象:无标识符,直接通过类名+构造参数创建
Person("李四").print(); // 仅在当前行有效二、匿名对象的核心特性
1. 生命周期极短:仅在当前行有效
匿名对象的生命周期仅限于定义它的那一行代码,行执行结束后会立即调用析构函数销毁,这是其最核心的特性:
class Test {
public:
Test() { cout << "构造函数" << endl; }
~Test() { cout << "析构函数" << endl; }
};
int main() {
cout << "开始" << endl;
Test(); // 匿名对象:构造后立即销毁
cout << "结束" << endl;
return 0;
}输出结果:
开始
构造函数
析构函数
结束(可见匿名对象的析构在当前行内完成,不会延续到后续代码)
2. 只能在定义行使用,无法被二次引用
由于没有对象名,匿名对象无法被后续代码引用,只能在创建的同时调用成员函数或作为参数传递:
// 正确:创建匿名对象的同时调用成员函数
Person("王五").print();
// 错误:无法通过对象名引用匿名对象(根本没有对象名)
// Person("赵六");
// p.print(); // 编译报错:未定义标识符"p"三、匿名对象的典型使用场景
匿名对象的设计初衷是简化 "临时使用一次" 的对象操作,常见场景包括:
1. 临时调用类的成员函数(无需复用对象)
当只需调用一次类的成员函数,且后续不再使用该对象时,用匿名对象可省去定义对象名的步骤:
// 传统方式:定义有名对象(略显冗余)
Person temp("临时用户");
temp.print();
// 简化方式:直接用匿名对象
Person("临时用户").print(); 2. 作为函数参数传递(避免创建中间变量)
当函数需要类对象作为参数时,可直接传递匿名对象,减少中间变量的定义:
// 函数声明:接收Person对象作为参数
void func(Person p) {
p.print();
}
// 调用方式1:先定义有名对象再传递(多一步定义)
Person p("参数1");
func(p);
// 调用方式2:直接传递匿名对象(更简洁)
func(Person("参数2")); 3. 作为函数返回值(临时承载返回结果)
函数返回类对象时,匿名对象可作为临时载体,无需显式定义局部变量:
// 返回Person对象的函数
Person createPerson(string name) {
// 直接返回匿名对象(无需定义局部变量)
return Person(name);
}
int main() {
// 接收返回的匿名对象(可直接使用或赋值给有名对象)
Person p = createPerson("返回对象");
return 0;
}四、注意事项
-
避免无意义的匿名对象 单独创建匿名对象而不使用(如
Person("无效对象");)是合法的,但没有实际意义,会触发构造和析构却无任何操作,属于代码冗余。 -
匿名对象的赋值行为若将匿名对象赋值给有名对象,匿名对象会先被创建,赋值完成后立即销毁:
Person p = Person("赋值测试"); // 执行过程: // 1. 创建匿名对象 Person("赋值测试") // 2. 调用拷贝构造(或移动构造)将匿名对象赋值给p // 3. 匿名对象销毁 -
与右值的关系 匿名对象属于右值(无法被取地址),因此不能绑定到非 const 的左值引用:
// 错误:非const左值引用不能绑定匿名对象(右值) // Person& ref = Person("测试"); // 正确:const左值引用可绑定右值 const Person& ref = Person("测试");
示例代码:
class add
{
public:
add(int a=1,int b=1)
:ma(a)
,mb(b)
{ }
~add()
{
ma = 0;
mb = 0;
}
void addprint()
{
cout << ma + mb << endl;
}
private:
int ma;
int mb;
};
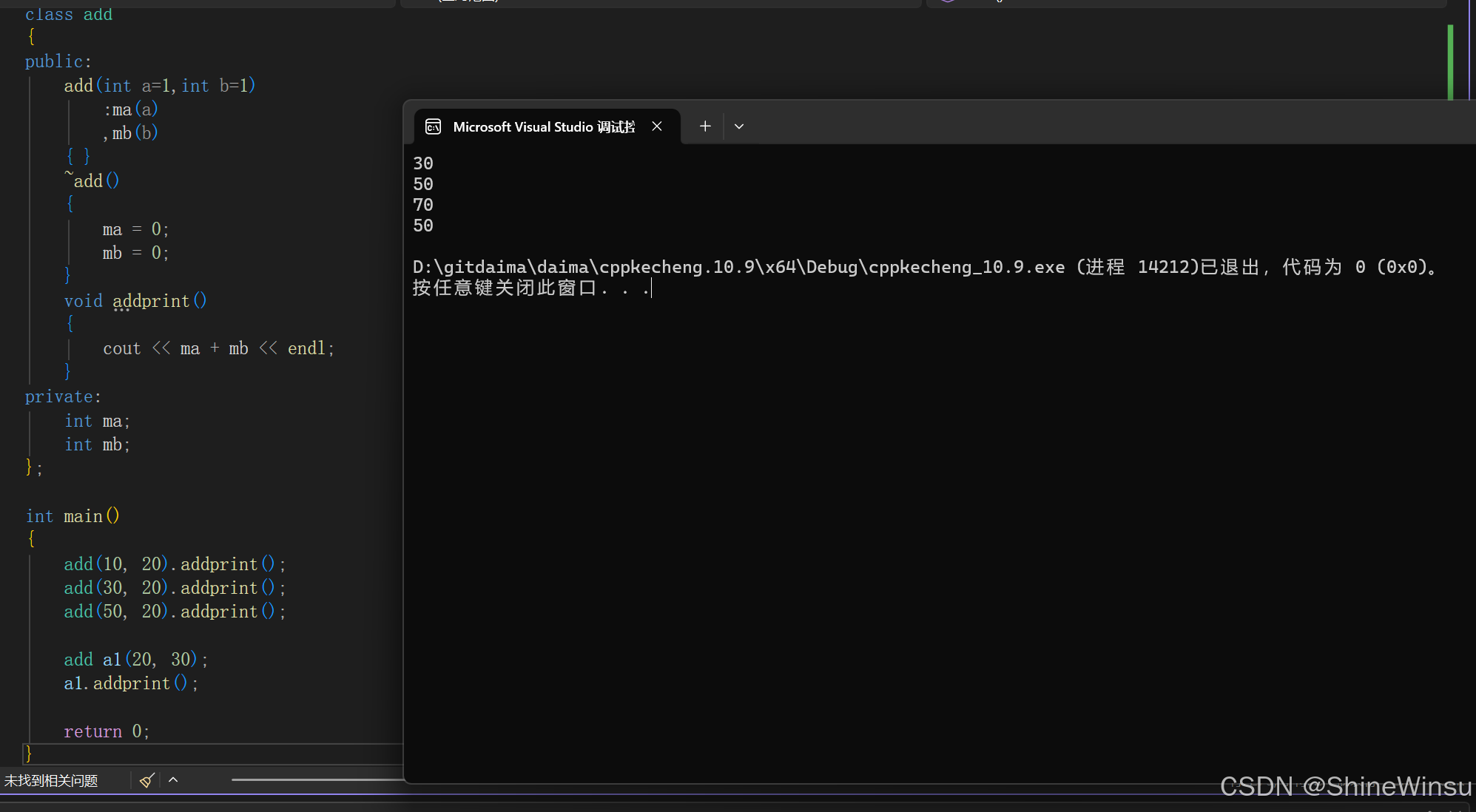
int main()
{
//匿名对象,随用随弃
add(10, 20).addprint();
add(30, 20).addprint();
add(50, 20).addprint();
//有名对象
add a1(20, 30);
a1.addprint();
return 0;
}
总结
匿名对象是 C++ 中 "即用即弃" 的轻量型对象,核心价值在于简化临时对象的使用,减少不必要的对象名定义。其生命周期仅为当前行的特性,既保证了使用的便捷性,又避免了资源的长期占用,是提升代码简洁性的有效工具。
对象拷贝时的编译器优化:
在 C++ 中,对象的 "拷贝"(如传参、返回值传递时调用拷贝构造函数)会带来额外的性能开销。现代编译器会通过拷贝省略(Copy Elision) 技术,在不影响程序正确性的前提下,主动减少甚至消除这些冗余拷贝,其中最典型的是 返回值优化(Return Value Optimization, RVO) 和 具名返回值优化(Named Return Value Optimization, NRVO)。以下从优化原理、场景、编译器行为及验证方式展开详细解析:
一、核心概念:为什么需要拷贝优化?
先明确 "冗余拷贝" 的来源 ------ 当对象通过值传递 (传参、返回值)时,C++ 标准原本要求生成 "临时对象" 并调用拷贝构造函数,但这些临时对象往往仅作为 "传递载体",使用后立即销毁,属于纯粹的性能浪费。
示例:未优化时的冗余拷贝
假设定义一个带构造、拷贝构造、析构函数的类,观察未优化时的拷贝行为:
#include <iostream>
using namespace std;
class Test {
public:
// 普通构造函数
Test(int val = 0) : _val(val) {
cout << "普通构造:" << this << " (val=" << _val << ")\n";
}
// 拷贝构造函数(值传递时调用)
Test(const Test& other) : _val(other._val) {
cout << "拷贝构造:" << this << " <- " << &other << "\n";
}
// 析构函数
~Test() {
cout << "析构:" << this << "\n";
}
private:
int _val;
};
// 函数1:返回匿名对象
Test createTest1() {
return Test(10); // 返回匿名对象(理论上需拷贝到临时对象)
}
// 函数2:返回具名对象
Test createTest2() {
Test t(20); // 具名对象
return t; // 理论上需拷贝t到临时对象
}
int main() {
cout << "--- 调用createTest1() ---\n";
Test t1 = createTest1(); // 接收返回值(理论上需拷贝临时对象到t1)
cout << "\n--- 调用createTest2() ---\n";
Test t2 = createTest2();
cout << "\nmain结束\n";
return 0;
}未优化时的理论执行流程(实际编译器默认会优化):
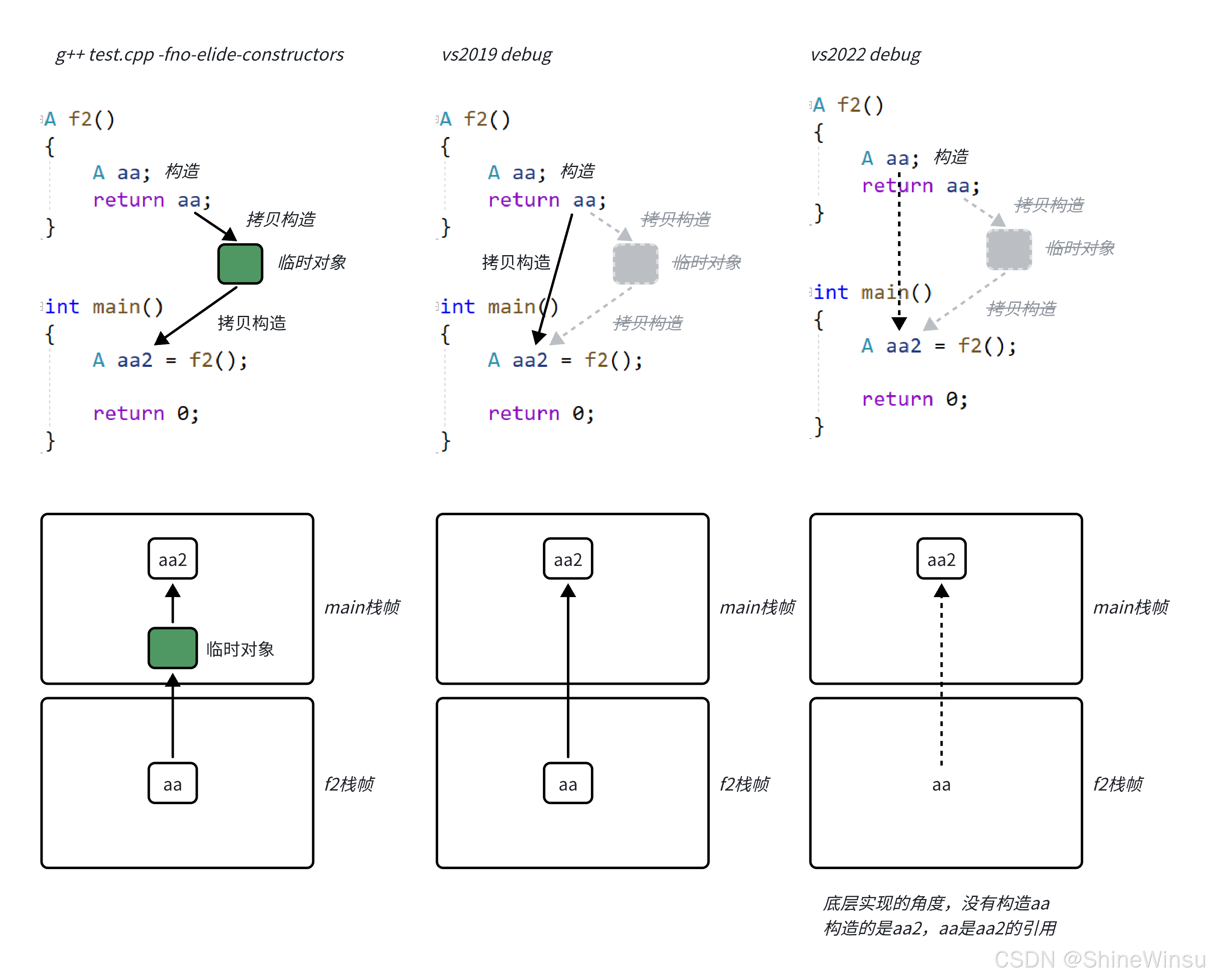
-
createTest1()调用:- 1.1 执行
Test(10):调用普通构造(创建匿名对象 A); - 1.2 返回匿名对象:调用拷贝构造(将 A 拷贝到临时对象 B);
- 1.3 匿名对象 A 销毁;
- 1.4 赋值给
t1:调用拷贝构造(将临时对象 B 拷贝到t1); - 1.5 临时对象 B 销毁。
- 1.1 执行
-
createTest2()调用:- 2.1 执行
Test t(20):调用普通构造(创建具名对象 C); - 2.2 返回
t:调用拷贝构造(将 C 拷贝到临时对象 D); - 2.3 具名对象 C 销毁;
- 2.4 赋值给
t2:调用拷贝构造(将临时对象 D 拷贝到t2); - 2.5 临时对象 D 销毁。
- 2.1 执行
理论上会有 4 次拷贝构造,但现代编译器会通过优化消除这些冗余拷贝,实际执行流程会大幅简化。
二、编译器的核心优化:拷贝省略(Copy Elision)
C++ 标准从 C++98 开始允许编译器进行 "拷贝省略",C++17 进一步将部分场景(如返回匿名对象)的优化强制化 (即编译器必须执行,不再是 "可选")。核心优化逻辑是:直接在 "目标内存地址" 创建对象,跳过中间临时对象的拷贝。
1. 两种典型优化场景
(1)返回值优化(RVO):返回匿名对象
当函数返回匿名对象 (如 return Test(10);)时,编译器会直接在 "函数调用者接收对象的内存地址"(如 t1 的地址)创建对象,完全跳过临时对象和拷贝构造。
优化后的 createTest1() 执行流程:
- 直接在
t1的内存地址调用普通构造(Test(10)); - 无临时对象,无拷贝构造,仅 1 次普通构造 + 1 次析构(
main结束时t1销毁)。
(2)具名返回值优化(NRVO):返回具名对象
当函数返回具名对象 (如 return t;,且 t 是函数内定义的局部对象)时,编译器会分析代码逻辑,若 t 仅用于返回且无其他修改,会直接在 "接收对象的内存地址" 创建 t,跳过拷贝。
优化后的 createTest2() 执行流程:
- 直接在
t2的内存地址调用普通构造(Test t(20)); - 无临时对象,无拷贝构造,仅 1 次普通构造 + 1 次析构(
main结束时t2销毁)。
2. 编译器优化的 "灵活性":标准未严格限定
C++ 标准仅规定 "允许编译器在不影响正确性的前提下省略拷贝",但未严格规定优化的具体范围和条件,因此不同编译器(GCC、Clang、MSVC)的优化策略存在差异:
- 主流编译器(GCC 8+、Clang 6+、MSVC 2019+):默认会对 "单个表达式内的连续拷贝" 进行合并优化(如返回值 + 赋值的连续拷贝);
- 激进优化(部分新版本编译器):甚至会跨语句、跨表达式优化(如函数内多次修改具名对象后返回,仍能识别并优化);
- 旧编译器或低优化级别 :可能仅支持 RVO,不支持 NRVO,或需要手动开启优化(如
-O2级别)。
三、如何验证优化效果?(关闭优化对比)
为了观察 "优化前" 和 "优化后" 的差异,我们可以通过编译器选项关闭拷贝优化,强制执行标准规定的拷贝流程。以 Linux 下的 GCC 编译器为例:
1. 关键编译选项:-fno-elideconstructors
- 默认情况:GCC 会自动开启拷贝优化(RVO/NRVO);
-fno-elideconstructors:关闭所有拷贝省略优化,强制调用拷贝构造函数(便于观察理论上的拷贝行为)。
2. 实际验证步骤
步骤 1:保存代码到 test.cpp
将上文的 Test 类代码保存为 test.cpp。
步骤 2:默认优化编译运行(开启优化)
g++ test.cpp -o test_opt # 默认开启优化(-O0 级别也会优化RVO)
./test_opt开启优化后的输出(GCC 11.4 示例):
--- 调用createTest1() ---
普通构造:0x7ffd8b7e3aac (val=10) # 直接在t1地址构造,无拷贝
--- 调用createTest2() ---
普通构造:0x7ffd8b7e3aa8 (val=20) # 直接在t2地址构造,无拷贝
main结束
析构:0x7ffd8b7e3aa8 # t2销毁
析构:0x7ffd8b7e3aac # t1销毁结论:仅 2 次普通构造,0 次拷贝构造(优化生效,消除所有冗余拷贝)。
步骤 3:关闭优化编译运行
g++ test.cpp -o test_no_opt -fno-elideconstructors # 关闭优化
./test_no_opt关闭优化后的输出(GCC 11.4 示例):
--- 调用createTest1() ---
普通构造:0x7ffc5e7a69f4 (val=10) # 匿名对象A
拷贝构造:0x7ffc5e7a6a00 <- 0x7ffc5e7a69f4 # A拷贝到临时对象B
析构:0x7ffc5e7a69f4 # A销毁
拷贝构造:0x7ffc5e7a6a04 <- 0x7ffc5e7a6a00 # B拷贝到t1
析构:0x7ffc5e7a6a00 # B销毁
--- 调用createTest2() ---
普通构造:0x7ffc5e7a69f8 (val=20) # 具名对象C
拷贝构造:0x7ffc5e7a6a08 <- 0x7ffc5e7a69f8 # C拷贝到临时对象D
析构:0x7ffc5e7a69f8 # C销毁
拷贝构造:0x7ffc5e7a6a0c <- 0x7ffc5e7a6a08 # D拷贝到t2
析构:0x7ffc5e7a6a08 # D销毁
main结束
析构:0x7ffc5e7a6a0c # t2销毁
析构:0x7ffc5e7a6a04 # t1销毁结论:4 次拷贝构造(与理论流程一致,冗余拷贝全部显现)。
四、优化的限制:哪些情况无法优化?
编译器并非能优化所有拷贝场景,以下情况通常无法省略拷贝:
-
函数返回前对象被修改或分支不同:
Test createTest3(bool flag) { Test t1(30), t2(40); if (flag) return t1; // 分支返回不同对象,无法确定提前构造位置 else return t2; }此时编译器无法提前判断返回哪个对象,只能在返回时拷贝。
-
返回对象是函数参数或全局对象:
Test createTest4(Test t) { return t; // t是函数参数,已在调用者栈帧创建,返回时需拷贝 } -
显式调用拷贝构造函数:
Test t1(50); Test t2 = Test(t1); // 显式创建临时对象,部分编译器可能不优化
示例代码:
#include <iostream>
using namespace std;
class A
{
public:
// 构造函数
A(int a = 0)
: _a1(a)
{
cout << "A(int a)" << endl;
}
// 拷贝构造函数
A(const A& aa)
: _a1(aa._a1)
{
cout << "A(const A& aa)" << endl;
}
// 赋值运算符重载
A& operator=(const A& aa)
{
cout << "A& operator=(const A& aa)" << endl;
if (this != &aa)
{
_a1 = aa._a1;
}
return *this;
}
// 析构函数
~A()
{
cout << "~A()" << endl;
}
private:
int _a1 = 1;
};
// 传值传参
void f1(A aa)
{
}
// 传值返回
A f2()
{
A aa;
return aa;
}
int main()
{
// 传值传参:构造+拷贝构造
A aa1;
f1(aa1);
cout << endl;
// 隐式类型转换:连续构造+拷贝构造->优化为直接构造
f1(1);
// 显式构造:连续构造+拷贝构造->优化为一个构造
f1(A(2));
cout << endl;
cout << "***********************************************" << endl;
// 传值返回(无优化情况:构造局部对象+拷贝构造临时对象)
// 部分编译器会优化为直接构造(如vs2022 debug)
f2();
cout << endl;
// 返回值接收:连续拷贝构造+拷贝构造->优化为一个拷贝构造
// 部分编译器会优化为直接构造(如vs2022 debug)
A aa2 = f2();
cout << endl;
// 赋值操作:构造+拷贝构造+赋值重载(通常无法优化)
// 部分编译器会优化中间临时对象(如vs2022 debug)
aa1 = f2();
cout << endl;
return 0;
}核心测试点说明:
| 测试场景 | 关键观察点(无优化时) | 编译器优化后行为(如 VS2022 Debug) |
|---|---|---|
f1(aa1)(传已存在对象) |
构造(aa1)→ 拷贝构造(形参)→ 2 次析构 | 无优化(传值必须拷贝) |
f1(1)(传字面量) |
隐式构造(临时对象)→ 拷贝构造 → 2 次析构 | 直接构造(省略临时对象拷贝),仅 1 次构造 |
f1(A(2))(传匿名对象) |
构造(匿名对象)→ 拷贝构造 → 2 次析构 | 直接构造(匿名对象与形参绑定),仅 1 次构造 |
f2()(无接收返回值) |
构造(aa)→ 拷贝构造(临时对象)→ 2 次析构 | 直接构造(临时对象),仅 1 次构造 |
A aa2 = f2()(接收返回值) |
构造(aa)→ 2 次拷贝构造 → 3 次析构 | 直接构造(aa2),仅 1 次构造 |
aa1 = f2()(赋值接收) |
构造(aa)→ 拷贝构造(临时对象)→ 赋值 → 3 次析构 | 保留赋值操作,仅省略 aa→临时对象的拷贝 |
五、总结
- 优化本质:编译器通过 "直接在目标地址创建对象",消除传参 / 返回值过程中的临时对象和拷贝构造,提升性能;
- 标准与编译器:C++17 强制部分优化(如返回匿名对象),主流编译器默认开启优化,优化范围因编译器版本而异;
- 验证方式 :Linux 下用
g++ -fno-elideconstructors关闭优化,对比观察拷贝行为; - 开发者建议:无需刻意规避 "可能触发拷贝" 的写法(如返回具名对象),现代编译器会自动优化;若需兼容旧编译器,可优先返回匿名对象(RVO 兼容性更好)。
这个其实不怎么重要,我们做个了解就行。
结语:以细节筑根基,以实践启新程 ------ 类与对象的收尾与前行
当我们敲下最后一行代码,看着编译器顺利通过,看着 "1+2+...+n" 的结果正确输出,看着友元、内部类、匿名对象在场景中各司其职时,这趟 "类与对象收尾之旅" 也终于抵达终点。回顾这段旅程,我们没有追逐新奇的语法糖,而是沉下心打磨那些容易被忽略却至关重要的细节 ------ 从静态成员的类外初始化,到友元打破封装的 "权衡艺术",再到内部类的独立性与约束性,每一个知识点都像一块精密的零件,共同拼凑出 C++ 面向对象编程的完整图景。
或许在学习之初,我们会困惑 "为什么静态成员不能在类内初始化",会纠结 "友元会不会破坏封装",会疑惑 "内部类和外部类到底是什么关系"。这些疑问就像迷雾,让我们在面向对象的世界里举棋不定。但当我们带着这些困惑拆解代码、调试运行、对比优化后会发现:C++ 的每一条规则都不是凭空而来,背后都藏着对 "效率" 与 "逻辑" 的深度考量。
静态成员的类外初始化,看似是 "多此一举" 的规定,实则是因为它属于 "类本身" 而非某个具体对象。类的声明仅用于描述成员的存在,就像一份设计图纸,不负责分配实际的建筑材料;而初始化需要分配内存并设置初始值,相当于根据图纸搭建实体结构,必须在类外(通常是.cpp 文件中)单独完成。试想,如果允许静态成员在类内初始化,当多个文件包含该类的头文件时,会导致静态成员被重复定义,引发编译冲突 ------ 这条规则从根源上避免了这种问题,保证了程序的链接正确性。
友元的存在,常常让我们担心 "破坏封装"。毕竟面向对象的核心思想之一就是 "数据隐藏",而友元却能直接访问类的私有成员,仿佛在严密的防护墙上开了一扇门。但仔细思考就会发现,这扇 "门" 并非随意开设,而是为了在 "绝对封装" 和 "实际便利" 间找到平衡。比如我们之前学习的流插入运算符重载(ostream& operator<<),如果不将其声明为类的友元,它就无法访问类的私有成员,也就无法实现 "cout << 对象" 这种直观的输出方式;再比如两个深度耦合的类,若通过友元直接访问必要的私有成员,能避免频繁调用 getter/setter 带来的冗余代码,让程序更简洁高效。友元不是对封装的否定,而是对封装的 "灵活补充"------ 它让我们在坚守封装原则的同时,不必为了形式上的 "纯粹" 而牺牲代码的实用性。
内部类的设计,则像是为紧密关联的逻辑打造了一个 "专属容器"。当 A 类的实现主要是为 B 类服务,比如vector的迭代器类(vector<T>::iterator)仅用于遍历vector,将 A 类设计为 B 类的内部类,既能避免全局命名空间的污染,又能通过访问限定符控制 A 类的可见性。如果将 A 类定义在 B 类的private区域,它就成为 B 类的 "专属工具",外部代码无法直接访问,保证了逻辑的封闭性;若定义在public区域,则能有限度地对外开放,满足特定场景的使用需求。更重要的是,内部类默认是外部类的友元,这让它能轻松访问外部类的私有成员,却又保持自身的内存独立性 ------ 外部类对象的大小与内部类无关,内部类的创建也无需依赖外部类对象,这种 "关联而不依附" 的关系,让代码结构既紧凑又灵活。
就像我们在 "求 1+2+...+n" 的例题中看到的那样:静态成员_i记录当前要累加的数字,_ret存储累加的总和,二者的共享性保证了多次构造调用后状态不会丢失;内部类Sum通过构造函数触发累加操作,每创建一个Sum对象,_i自增、_ret累加,无需额外调用函数;而如果用匿名对象来临时触发构造,还能进一步简化代码。这些知识点不再是孤立的概念,而是像齿轮一样协同工作,共同实现解题逻辑。当我们用 "创建 n 个对象触发 n 次构造" 的思路解决问题时,其实是将 "类的生命周期""静态成员的共享性""数组初始化规则" 等知识点融会贯通的过程 ------ 这种 "从知识点到解决方案" 的跨越,远比单纯记住语法更有价值,因为它教会我们的不是 "怎么写",而是 "为什么这么写"。
我们还探讨了编译器背后的 "隐形手"------ 拷贝优化。在 C++ 中,对象的拷贝(如传参、返回值传递)会调用拷贝构造函数,产生额外的性能开销。如果不了解编译器的优化机制,我们可能会写出看似 "低效" 的代码,却不知道编译器早已帮我们消除了冗余拷贝。当我们用g++ test.cpp -fno-elideconstructors关闭优化,看着屏幕上密密麻麻的 "拷贝构造""析构" 输出,再对比默认优化后的简洁结果,会突然明白:现代 C++ 的高效,不仅源于我们写出的代码,更源于编译器对冗余操作的 "智能裁剪"。
返回值优化(RVO)让函数返回匿名对象时,直接在调用者的内存地址创建对象,跳过中间临时对象的拷贝;具名返回值优化(NRVO)则对函数内的具名对象同样生效,只要对象仅用于返回且无复杂分支,编译器就能实现 "零拷贝"。但这并不意味着我们可以完全依赖编译器 "兜底",相反,理解优化的原理能让我们写出更适配优化的代码 ------ 比如知道返回匿名对象比返回具名对象更易触发 RVO,知道分支返回不同对象会导致优化失效,知道显式调用拷贝构造函数可能阻碍优化。这些细节就像 "编译器的语言",让我们能与编译器 "对话",在追求性能时更有方向。
在学习过程中,我们也不断修正着对某些概念的认知偏差。曾经以为匿名对象是 "没用的临时变量",直到发现它在临时调用成员函数、传递函数参数时能省去定义对象名的步骤,让代码更简洁;曾经以为内部类是 "外部类的附属品",直到看到sizeof(Outer)与内部类无关,才明白它是完全独立的类,只是 "借居" 在外部类的类域中;曾经以为静态成员函数 "只能访问静态成员" 是一种限制,直到需要不创建对象就操作类级数据时,才体会到这种 "无对象调用" 的便利。这些认知的修正过程,正是我们对 C++ 理解不断深化的证明 ------ 从 "知其然" 到 "知其所以然",从 "记住语法" 到 "理解逻辑",这才是编程学习的核心。
当然,面向对象编程的学习从未真正结束。这篇博客的收尾,不是终点,而是新的起点。当我们未来面对更复杂的项目时,今天学到的细节都会成为我们的 "底气"。比如设计一个自定义容器类时,我们会用内部类实现迭代器,利用内部类的友元特性访问容器的私有数据;比如开发一个工具库时,我们会谨慎使用友元,让跨类协作既高效又不破坏封装;比如优化性能敏感的代码时,我们会考虑拷贝优化的影响,写出更适配编译器的实现。
C++ 的魅力就在于此:它不提供 "一键式" 的解决方案,而是要求我们理解每一个选择背后的逻辑,在权衡中找到最适合场景的实现方式。它不像某些语言那样 "保姆式" 地屏蔽底层细节,而是将控制权交给开发者,让我们既能深入底层优化性能,又能构建高层抽象模型。这种 "灵活与严谨并存" 的特性,正是 C++ 能在系统开发、游戏引擎、高性能计算等领域长期立足的原因。
最后,想对每一位学习者说:学习编程就像搭建一座大厦,语法是砖瓦,细节是钢筋,实践是水泥。我们今天打磨的静态成员、友元、内部类,还有对拷贝优化的理解,就是大厦的钢筋 ------ 它们藏在代码深处,不显眼,却决定着大厦的稳固程度。或许在未来的某一天,当你面对一个棘手的 bug,调试了半天发现是静态成员未在类外初始化;当你需要优化一段卡顿的代码,想起可以通过返回匿名对象触发 RVO;当你设计一个复杂的类结构,用内部类实现了逻辑的封闭性时,会突然想起今天学到的某个细节,想起 "哦,原来当时那个知识点是为了解决这个问题"。
那些曾经让我们困惑的细节,那些反复调试才理解的逻辑,最终都会内化为我们的编程思维,成为我们解决问题的 "武器"。编程学习没有捷径,每一个知识点的掌握,每一次 bug 的解决,每一次代码的优化,都是在为我们的 "编程大厦" 添砖加瓦。
愿我们都能带着这份对细节的敬畏,继续在 C++ 的世界里探索 ------ 不急于求成,不畏惧复杂,在拆解问题、编写代码、调试优化的过程中,不断提升自己的编程思维与实践能力。下一段旅程,我们或许会遇见继承、多态、模板,会接触到更复杂的设计模式,会面对更具挑战性的项目,但只要我们保持这份 "刨根问底" 的态度,保持 "动手实践" 的习惯,就一定能在面向对象编程的道路上走得更远、更稳。
代码不止,探索不息。每一行代码都是我们与计算机的对话,每一次调试都是我们与问题的博弈,每一次优化都是我们对效率的追求。让我们带着这份热爱与坚持,在编程的世界里继续前行,期待在下一段旅程中,遇见更优秀的自己,写出更精彩的代码。我们下一段旅程再见!
时间会淡化一切。