目录
-
-
- [一、 出发点与研究背景 (Motivation & Background)](#一、 出发点与研究背景 (Motivation & Background))
-
- [1. 残差连接:深度学习的"定海神针"及其局限](#1. 残差连接:深度学习的“定海神针”及其局限)
- [2. 超连接(Hyper-Connections, HC)的尝试与崩塌](#2. 超连接(Hyper-Connections, HC)的尝试与崩塌)
- [二、 方法论 (Methodology): 流形约束](#二、 方法论 (Methodology): 流形约束)
-
- [1. 核心思想:投影到双随机流形](#1. 核心思想:投影到双随机流形)
- [2. 为什么选择双随机流形?](#2. 为什么选择双随机流形?)
- [3. 算法实现:Sinkhorn-Knopp 投影](#3. 算法实现:Sinkhorn-Knopp 投影)
- [三、 工作过程与工程实现 (Infrastructure Optimization)](#三、 工作过程与工程实现 (Infrastructure Optimization))
-
- [1. 挑战:显存墙与计算碎片化](#1. 挑战:显存墙与计算碎片化)
- [2. 解决方案一:基于 TileLang 的算子融合 (Kernel Fusion)](#2. 解决方案一:基于 TileLang 的算子融合 (Kernel Fusion))
- [3. 解决方案二:极致的重计算策略 (Recomputing / Gradient Checkpointing)](#3. 解决方案二:极致的重计算策略 (Recomputing / Gradient Checkpointing))
- [4. 解决方案三:DualPipe 通信重叠 (Communication Overlap)](#4. 解决方案三:DualPipe 通信重叠 (Communication Overlap))
- [四、 主要贡献 (Contributions)](#四、 主要贡献 (Contributions))
-
- [1. 理论贡献:重新定义了"稳定的超连接"](#1. 理论贡献:重新定义了“稳定的超连接”)
- [2. 系统贡献:定义了大模型算子优化的新标准](#2. 系统贡献:定义了大模型算子优化的新标准)
- [3. 实证贡献:性能与扩展性的双重验证](#3. 实证贡献:性能与扩展性的双重验证)
- [五、 总结与展望 (Conclusion & Outlook)](#五、 总结与展望 (Conclusion & Outlook))
-
- [1. 总结](#1. 总结)
- [2. 展望](#2. 展望)
-
这篇由 DeepSeek-AI 团队于 2025 年末发布的论文 《mHC: Manifold-Constrained Hyper-Connections》(mHC:流形约束的超连接),是对现代深度神经网络(特别是大语言模型)底层宏观架构设计的一次极其深入且具有高度工程实用价值的探索。
该论文针对近年来旨在扩展模型宽度与拓扑复杂度的"超连接"(Hyper-Connections, HC)技术,指出了其在大规模训练中存在的致命不稳定性问题,并提出了一套基于双随机矩阵流形(Birkhoff Polytope)理论的约束框架,配合深度的底层系统优化,成功在保留 HC 性能优势的同时恢复了残差网络的训练稳定性。
一、 出发点与研究背景 (Motivation & Background)
1. 残差连接:深度学习的"定海神针"及其局限
自 ResNet (He et al., 2016) 问世以来,残差连接(Residual Connection)一直是深度学习领域的统治性范式。其核心公式 x l + 1 = x l + F ( x l ) x_{l+1} = x_l + F(x_l) xl+1=xl+F(xl) 极其简洁,但蕴含了深刻的数学原理:恒等映射(Identity Mapping)。
- 信号传播: 在前向传播中,信号可以通过恒等路径无损地传递到深层。
- 梯度流: 在反向传播中,梯度可以直接跨层回传,避免了梯度消失或爆炸。
这种特性是 Transformer 架构(LLM 的基石)能够扩展到上百层、万亿参数规模的根本保障。
然而,随着模型规模的不断扩大,研究者开始思考:标准的残差连接是否限制了层与层之间的信息交互能力? 传统的残差流是一个单一的通道,宽度固定为 C C C(隐层维度)。这可能成为了信息流动的瓶颈。
2. 超连接(Hyper-Connections, HC)的尝试与崩塌
为了突破这一瓶颈,近期学术界(如 Zhu et al., 2024)提出了"超连接"(HC)。HC 的核心思想是将残差流的宽度从 C C C 扩展到 n × C n \times C n×C(例如 n = 4 n=4 n=4),并引入了三个可学习的动态矩阵来管理这一宽流:
- H p r e H_{pre} Hpre (Read-in): 从宽残差流中聚合信息输入到当前层。
- H p o s t H_{post} Hpost (Write-out): 将当前层计算结果写入宽残差流。
- H r e s H_{res} Hres (Route): 在宽残差流内部进行通道间的信息混合与路由。
HC 通过增加拓扑复杂度而非单纯增加计算单元(FLOPs),在理论上极大地提升了模型的表达能力。
但在实践中,DeepSeek 团队发现 HC 存在两个致命缺陷,使其无法真正应用于大规模基础模型(Foundation Models)的预训练:
-
破坏恒等映射,导致训练崩溃(Instability):
标准的残差连接保证了 x L = x l + ∑ F i x_L = x_l + \sum F_i xL=xl+∑Fi。但在 HC 中,跨层的信号传播变成了连乘形式: x L ≈ ( ∏ H r e s ) x l x_L \approx (\prod H_{res}) x_l xL≈(∏Hres)xl。
由于原始 HC 中的 H r e s H_{res} Hres 是无约束的(Unconstrained),其特征值可能大于 1 或小于 1。
- 信号爆炸: 当层数加深,连乘效应会导致信号幅度指数级增长(论文中观测到 Amax 增益高达 3000 倍)。
- 信号消失: 或者导致信号衰减至零。
这种数值不稳定性在大规模训练(Scale-up)时是不可接受的,会导致 Loss 剧烈震荡甚至发散。
-
巨大的显存访问开销(IO Overhead):
将残差流拓宽 n n n 倍,意味着显存的读写量(Memory Access)也增加了 n n n 倍。在现代 GPU 架构中,计算往往不是瓶颈,显存带宽(HBM Bandwidth) 才是。未经优化的 HC 会导致训练速度严重下降,使得其理论上的性能提升被硬件效率的损耗所抵消。
因此,本论文的出发点非常明确: 如何设计一种机制,既能享受 HC 带来的宽流信息交互能力,又能从数学上强制恢复"恒等映射"的稳定性,并通过系统工程解决显存墙问题?
二、 方法论 (Methodology): 流形约束
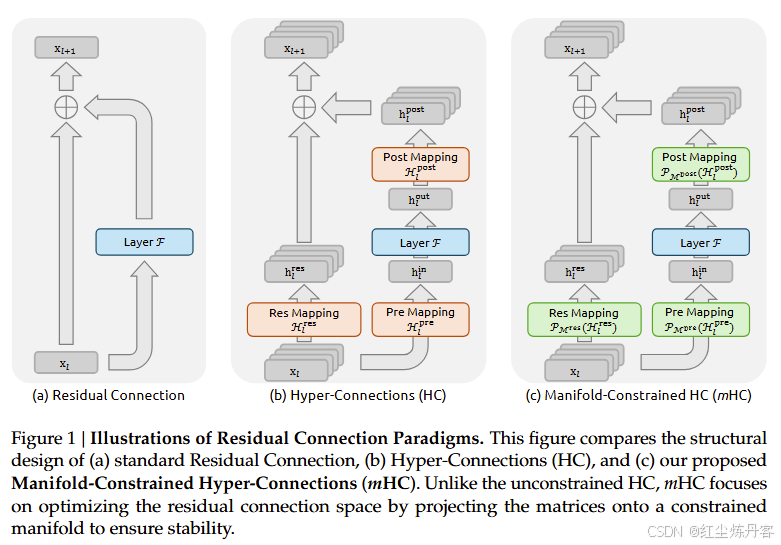
DeepSeek 团队提出的 mHC (Manifold-Constrained Hyper-Connections) 并非简单的修补,而是引入了严格的数学几何约束。
1. 核心思想:投影到双随机流形
为了解决 H r e s H_{res} Hres 连乘导致的信号失控,论文提出将 H r e s H_{res} Hres 限制在双随机矩阵(Doubly Stochastic Matrices) 构成的流形上。这个流形在几何上被称为 Birkhoff Polytope。
双随机矩阵的定义:
一个方阵 M ∈ R n × n M \in \mathbb{R}^{n \times n} M∈Rn×n 是双随机的,当且仅当:
- 所有元素非负: M i j ≥ 0 M_{ij} \ge 0 Mij≥0。
- 每一行的和为 1: ∑ j M i j = 1 \sum_j M_{ij} = 1 ∑jMij=1。
- 每一列的和为 1: ∑ i M i j = 1 \sum_i M_{ij} = 1 ∑iMij=1。
2. 为什么选择双随机流形?
论文深刻论证了该流形具备三个对深度网络至关重要的数学性质:
-
性质一:范数保持(Norm Preservation)
根据 Birkhoff-von Neumann 定理,双随机矩阵是置换矩阵的凸组合。其谱范数(最大奇异值)严格受限于 1。
这意味着:信号经过 H r e s H_{res} Hres 变换后,其能量(范数)永远不会被放大。 这从根本上根除了梯度爆炸的物理基础。
-
性质二:组合封闭性(Compositional Closure)
这是最关键的一点。两个双随机矩阵的乘积,依然是双随机矩阵。
这意味着:无论网络堆叠多少层,跨越任意深度 L L L 的复合映射 ∏ i = 1 L H r e s ( i ) \prod_{i=1}^L H_{res}^{(i)} ∏i=1LHres(i) 依然停留在双随机流形上。这保证了网络深度的全局稳定性,而不仅仅是局部稳定性。
-
性质三:凸组合意义(Convex Combination)
y = H r e s x y = H_{res} x y=Hresx 的运算实质上是对输入特征流进行了加权平均(混合)。它在混合信息的同时,保持了特征分布的均值(Mean)和方差(Variance)的相对稳定,使得信号表现得像"恒等映射"的变体------即统计意义上的恒等映射。
3. 算法实现:Sinkhorn-Knopp 投影
为了将神经网络输出的任意动态矩阵 H ~ r e s \tilde{H}_{res} H~res 实时投影到这个流形上,论文采用了经典的 Sinkhorn-Knopp 算法:
- 非负化: 首先通过指数函数处理原始输出: M ( 0 ) = exp ( H ~ r e s ) M^{(0)} = \exp(\tilde{H}_{res}) M(0)=exp(H~res),保证元素非负。
- 迭代归一化: 交替对矩阵进行行归一化和列归一化。
- 行归一化: M ← M ⊘ ( row_sum ( M ) ⋅ 1 T ) M \leftarrow M \oslash (\text{row\_sum}(M) \cdot \mathbf{1}^T) M←M⊘(row_sum(M)⋅1T)
- 列归一化: M ← M ⊘ ( 1 ⋅ col_sum ( M ) T ) M \leftarrow M \oslash (\mathbf{1} \cdot \text{col\_sum}(M)^T) M←M⊘(1⋅col_sum(M)T)
- 收敛: 论文指出,在大约 20 次迭代后,矩阵将高精度地收敛到双随机矩阵。
此外,对于输入映射 H p r e H_{pre} Hpre 和输出映射 H p o s t H_{post} Hpost,论文也设计了配套的 Sigmoid 门控机制和缩放因子,确保进入和离开残差流的信号能量也是受控的。
三、 工作过程与工程实现 (Infrastructure Optimization)
这篇论文的独特之处在于它不仅是算法研究,更是一份**高性能计算(HPC)**的工程实践报告。DeepSeek 团队针对 mHC 带来的硬件挑战,在 CUDA/Triton 层面进行了极致优化。
1. 挑战:显存墙与计算碎片化
引入 mHC 后,每个 Transformer 层多了大量的矩阵运算。
- n = 4 n=4 n=4 时,残差流数据量是原来的 4 倍。
- H r e s H_{res} Hres 的计算涉及 Sinkhorn 迭代,包含大量的除法和指数运算,如果直接用 PyTorch 实现,会产生大量的 Kernel Launch 开销和显存读写。
2. 解决方案一:基于 TileLang 的算子融合 (Kernel Fusion)
团队使用了自研或优化的编译器工具 TileLang(Wang et al., 2025),开发了定制化的 mHC 算子:
- 全流程融合: 将 RMSNorm、线性投影生成 H ~ \tilde{H} H~、以及 Sinkhorn-Knopp 的 20 次迭代全部融合进同一个 Kernel 。这意味着数据一旦从 HBM(高带宽显存)读入片上 SRAM,就在片上完成所有计算,直到输出最终的 H r e s H_{res} Hres。
- 消除中间读写: 这种融合避免了存储 Sinkhorn 迭代过程中的 20 个中间矩阵,极大地节省了显存带宽。
3. 解决方案二:极致的重计算策略 (Recomputing / Gradient Checkpointing)
由于 n n n 倍宽度的残差流极其占用显存,无法保存所有前向传播的激活值(Activation)用于反向传播。
- 传统做法: 保存每一层的输入。这对于 mHC 来说依然太占显存。
- mHC 策略: 采用分块重计算。不保存每一层的输入,而是每隔 k k k 层保存一次。在反向传播时,利用保存的状态重新计算中间层的 mHC 算子。
- 定制化反向 Kernel: 为了支持高效重计算,团队甚至手写了 Sinkhorn 的反向传播 Kernel,使其能够在不存储前向中间变量的情况下,通过重新执行迭代来计算梯度。
4. 解决方案三:DualPipe 通信重叠 (Communication Overlap)
DeepSeek-V3 采用了 DualPipe 流水线并行策略。mHC 的引入增加了跨节点通信的负载(需要传输更宽的残差流)。
- 调度优化: 团队调整了流水线调度表。利用 Transformer 中 MLP 和 Attention 计算的时间窗口,异步进行 mHC 的数据通信。
- 掩盖延迟: 通过精细的计算-通信流水线编排,使得 mHC 带来的额外通信时间几乎完全被计算时间掩盖(Overlap),实现了"免费"的通信。
最终工程结果: 在 n = 4 n=4 n=4 的配置下,相比于标准 Baseline,mHC 仅增加了 6.7% 的端到端训练时间。考虑到其带来的性能提升,这是极具性价比的。
四、 主要贡献 (Contributions)
这篇论文的贡献是多维度的,涵盖了理论、系统和应用:
1. 理论贡献:重新定义了"稳定的超连接"
- 诊断了病因: 明确指出了无约束超连接在深层网络中破坏 Identity Mapping、导致信号幅度失控是训练不稳定的根本原因。
- 提出了药方: 首次将 Birkhoff Polytope(双随机流形)引入大模型架构设计,证明了流形约束是解决深层网络信号传播问题的有效数学工具。这为后续研究"如何设计复杂的残差结构"提供了理论范式。
2. 系统贡献:定义了大模型算子优化的新标准
- 展示了在极致算力需求下,算法设计必须与底层硬件特性(Memory Hierarchy, Bandwidth)相结合。
- 开源或详细披露了基于 TileLang 的算子融合方案和 Sinkhorn 高效实现,为社区解决"内存受限算子"提供了参考范例。
- 证明了通过工程优化,拓扑复杂的网络结构完全可以在不显著增加训练时长的前提下落地。
3. 实证贡献:性能与扩展性的双重验证
- Scaling Law 验证: 在 3B、9B、27B 三个量级上,mHC 始终保持优于 Baseline 的 Loss 曲线,且优势随着计算量(FLOPs)的增加而稳固存在。
- 下游任务提升: 在 GSM8K(数学)、DROP(逻辑推理)、BBH(复杂指令)等高难度 Benchmark 上,mHC 相比标准模型和原始 HC 均有显著提升(例如 BBH 提升 2.1%)。这表明更复杂的残差流确实有助于模型进行更深层的逻辑推理。
- 稳定性实证: 训练曲线显示,mHC 彻底消除了原始 HC 出现的 Loss 尖峰(Spikes)和梯度范数震荡,实现了如 ResNet 般丝滑的训练过程。
五、 总结与展望 (Conclusion & Outlook)
1. 总结
mHC 是 DeepSeek 团队在探索大模型架构极限 过程中的产物。它挑战了沿用多年的"标准残差连接",提出了一种更"宽"、更灵活但又数学上严谨受控的信息通路。
这篇论文的价值在于它完美地平衡了**"表达能力的自由度"(通过超连接)与"训练过程的稳定性"**(通过流形约束)。它告诉我们:在大模型设计中,我们既需要增加复杂度来提升智能,又需要引入强数学约束来驾驭这种复杂度。
2. 展望
论文在最后指出了几个极具潜力的发展方向,这可能预示着下一代大模型(Next-Gen Foundation Models)的演进路径:
-
流形约束的泛化 (Generalization of Manifold Constraints):
目前使用的是双随机矩阵流形。未来是否可以探索其他黎曼流形?例如正交群(Orthogonal Group)或辛群(Symplectic Group)?不同的几何流形可能赋予模型不同的特性(如更好的长期记忆、旋转不变性等)。
-
拓扑架构设计的复兴 (Renaissance of Topological Architecture):
在 Transformer 结构趋于同质化(大家都在用 LLaMA 架构)的今天,mHC 可能会重新点燃学术界对宏观拓扑结构的研究热情。除了宽度扩展,是否还有其他维度的连接方式(如分形连接、动态路由连接)可以通过流形约束变得可用?
-
作为基础模型的标准组件:
鉴于 mHC 在推理和数学任务上的优异表现,它极有可能成为未来万亿参数级模型的标准配置。DeepSeek 团队明确表示,mHC 是一个灵活且实用的扩展,这意味着我们可能会在 DeepSeek 的下一代旗舰模型(如 DeepSeek-V4)中看到这一技术的全面应用。