1)先把三个概念讲明白:epoch / step / batch
batch(批大小)
一次喂给模型多少张图片。
比如 batch=128,意思是一次看 128 张图。
step(也叫 iteration,迭代步)
模型看一次 batch 并更新一次参数,算 1 step。
所以:
1 step = 看一个 batch + 反向传播更新一次参数
epoch
模型把整个训练集完整看一遍,算 1 epoch。
如果训练集有 50,000 张图,batch=128:
一次看 128 张,需要多少次才能看完全部?
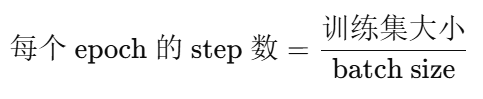
2)为什么小数据集 epoch 会很大?
因为小数据集每个 epoch 的 step 很少!
例子:CIFAR-10
-
训练集:50,000
-
batch=128
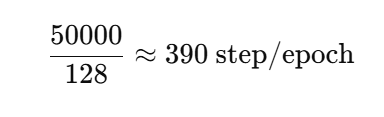
也就是说:
CIFAR 训练 1 epoch
模型只更新 390 次参数
训练 300 epoch 呢?
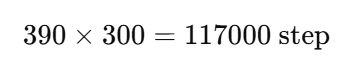
300 epoch 也才更新 11.7 万次
3)对比:ImageNet 为什么 epoch 不需要那么大?
ImageNet
-
训练集:1,280,000
-
batch=1024
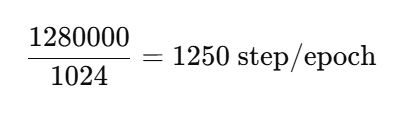
也就是说:
ImageNet 训练 1 epoch
模型更新 1250 次参数
训练 100 epoch:
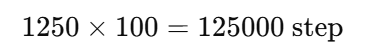
100 epoch 就更新 12.5 万次
4)所以核心原因是:大家真正关心的是 "更新了多少次参数"
训练的"强度"主要由 step 数决定,而不是 epoch 数。
因为模型学习靠的是:
每一次更新参数(step)
而不是 "你看了几遍数据"(epoch)
5)为什么很多人会误会 "小数据集训练 300 epoch 很夸张"?
因为直觉上会觉得:
"300 epoch = 把数据看了 300 遍 = 肯定过拟合爆炸"
但其实真正发生的是:
-
CIFAR 每遍就 390 step
-
ImageNet 每遍 1250 step
所以:
CIFAR 的 300 epoch ≈ ImageNet 的 100 epoch
从"更新次数"上差不多
6)举一个更生活的比喻(很直观)
把训练想成"刷题",参数更新想成"改错一次"。
CIFAR:题库很小
你题库只有 50 道题(小数据集),每天刷完一遍很快
你可能需要刷 300 天 才练够手感
ImageNet:题库很大
你题库有 1280 道题(大数据集),刷一遍就很累
刷 100 天 就已经练了很多东西了
所以:
"刷几遍"不重要
"总共练了多少次/改了多少次错"才重要
7)更关键的:训练效果还和学习率策略有关
原文提到:
更关键的是 总迭代步数 / 学习率轨迹
这句话非常对。
因为深度学习里通常会做:
-
前期大学习率:走得快
-
后期学习率衰减:慢慢精修
所以哪怕 step 一样,如果学习率安排不同,效果也会差很大。
例如两种训练:
A:10万 step + 学习率慢慢降
训练通常更稳,效果更好
B:10万 step + 学习率一直很大
可能震荡、学不好
总结 :为什么小数据集反而经常用更长 epoch?
因为:
-
小数据集每个 epoch step 少
-
大 epoch 只是为了凑够足够的 总 step 数(参数更新次数)
-
训练强度主要看 step 和学习率策略,不看 epoch 表面数字