布隆过滤器:
常用场景:
布隆过滤器的常用场景一般是需要判断某一个元素是否存在于一个集合中。他是redis的一种数据结构,但是它和 Redis 内置的 String、Hash、List、Set、ZSet 等"基础数据结构"不是同一类东西。它是通过RBloomFilter进行创建。它可以判断某个元素一定不存在或者可能存在---判断不存在则一定不存在,判断存在则可能不存在。这一特性可以提升很多唯一性判断问题的性能。
判断原理:
布隆过滤器是由一个位数组和一组哈希函数组成。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。哈希函数的个数和设置的误判率有关,错误率越低,位数组越长,布隆过滤器的内存占用越大,散列 Hash 函数越多,计算耗时较长。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
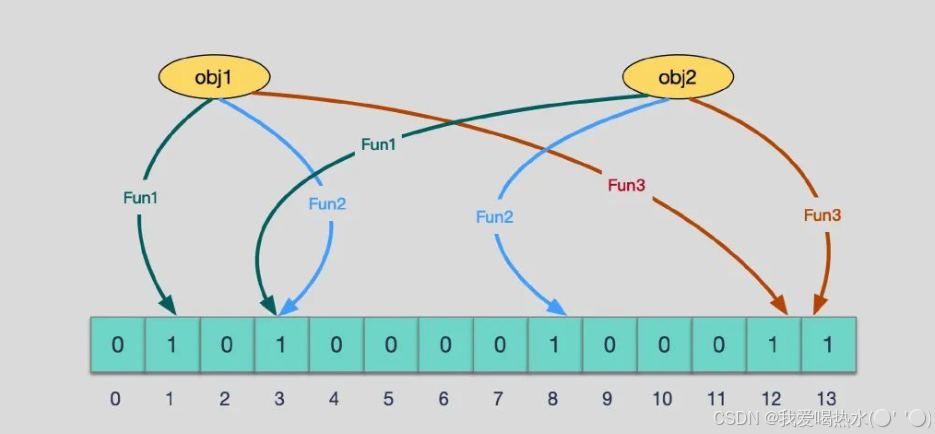
优缺点:
优点:
● 高效地判断一个元素是否属于一个大规模集合。
● 节省内存。(不直接存储元素,是通过位数组进行计算判断的)
缺点:
● 可能存在一定的误判(判断不存在则一定不存在,判断存在可能不存在)
使用流程:
1、引入 Redisson(Redis客户端) 依赖
java
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>2、配置Redis参数---application.yaml
java
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: 1234563、设置布隆过滤器配置类
java
@Bean
public RBloomFilter<String> userRegisterCachePenetrationBloomFilter(RedissonClient redissonClient) {
// 1. 获取分布式布隆过滤器实例
RBloomFilter<String> cachePenetrationBloomFilter = redissonClient.getBloomFilter("userRegisterCachePenetrationBloomFilter");
// 2. 初始化布隆过滤器(预期1亿元素,0.1%误判率)
cachePenetrationBloomFilter.tryInit(100000000L, 0.001);
// 3. 返回过滤器实例,注册为Spring Bean
return cachePenetrationBloomFilter;
}4、代码中使用---直接注入:
java
private final RBloomFilter<String> rBloomFilter;使用布隆过滤器的风险与解决方案:
布隆过滤器的拦截能力仅覆盖 "针对已存在数据的查询请求":当请求查询的是已存入布隆过滤器的存量数据时,可被有效拦截;而当攻击者针对某一不存在的目标数据(如未注册的用户名、未生成的短链接码),在极短时间(毫秒级)内发起海量恶意查询请求时,这类请求无法被布隆过滤器识别和拦截,会全部穿透至数据库层。此类海量请求会造成数据库的访问 QPS 骤增,资源占用率瞬间达到瓶颈,最终可能导致数据库服务过载宕机,引发整个业务链路的瘫痪。解决恶意请求的问题,加分布式锁,为每一个未注册的数据加一个分布式锁。但是如果恶意请求全部是使用不存在的数据发起请求,则是防不胜防,只能通过风控系统进行限流保障系统安全。
为何不使用set结构:
有人说为什么不使用Redis中的Set 结构来进行判断是否已经存在,如果使用set结构,那就要持久化存储所有元素,会需要消耗大量的内存,如果是使用的布隆过滤器就不用存储全部的数据,只是根据哈希函数进行映射,对内存要求远低于set结构。
分布式锁和布隆过滤器实现唯一性约束:
分布式锁是具有看门狗机制的,众多请求中只放一个请求访问数据库来保证数据库数据的唯一性约束。但是使用分布式锁实现唯一性的话就会让系统成为串行系统,会影响系统的吞吐量,如果使用布隆过滤器则是并行系统,性能上是优于分布式锁的,大概评估布隆过滤器是分布式锁的 6 倍性能。
布隆过滤器严重缺点:
存入布隆过滤器的数据是无法删除的,如果非要删除,已经删除的短链接我们可以加一层 Set 缓存,彻底删除的数据可以加入到这个 Set 集合中。如果判断在布隆过滤器中存在,需要再去判断是否在 Set 集合,如果set中存在就证明短链接可用,可以进行新增使用。优点是可以满足删除短链接后的复用问题,缺点是需要进行多次网络查询,以及删除要维护多个数据。也可以使用新出的布谷鸟过滤器,但是布谷鸟过于复杂,代码维护成本高。