让时序开发更可控:金仓时序 DB 的易用性实践与平台化路径
对开发者来说,一套时序数据库"好不好用",很少是看宣传页上堆了多少特性,更直接的感受往往只有三件事:接得进、跑得稳、扩得开 。这篇文章站在一线开发和架构落地的视角,围绕金仓时序数据库的易用性和二次开发生态,梳理了一条从 0 到 1 的实践路径,中间配好了完整的 SQL 示例和操作截图,方便你直接照着落地。
想了解更多产品和方案细节,也可以随时去金仓数据库官网看看:https://www.kingbase.com.cn/

文章目录
- [让时序开发更可控:金仓时序 DB 的易用性实践与平台化路径](#让时序开发更可控:金仓时序 DB 的易用性实践与平台化路径)
-
- [1. 开发者真正关心的"易用性",到底是哪些点?](#1. 开发者真正关心的“易用性”,到底是哪些点?)
- [2. 一条开发者友好的落地链路:从接入到看板再到运维闭环](#2. 一条开发者友好的落地链路:从接入到看板再到运维闭环)
- [3. 从 0 到 1:开发侧最小可行集(SQL 先跑通)](#3. 从 0 到 1:开发侧最小可行集(SQL 先跑通))
-
- [3.1 三张核心表:明细 + 聚合 + 事件](#3.1 三张核心表:明细 + 聚合 + 事件)
- [3.2 写入侧的两个"反直觉"点:幂等与质量位](#3.2 写入侧的两个“反直觉”点:幂等与质量位)
- [3.3 Windows 本地用 ksql 跑通示例:连接、建表、插数](#3.3 Windows 本地用 ksql 跑通示例:连接、建表、插数)
-
- [Step 1:打开 ksql 并连接到本地实例](#Step 1:打开 ksql 并连接到本地实例)
- [Step 2:一键初始化可跑数据集](#Step 2:一键初始化可跑数据集)
- [Step 3:用同一份数据跑三类查询](#Step 3:用同一份数据跑三类查询)
- [Step 4:退出 ksql](#Step 4:退出 ksql)
- [4. 开发者最常写的三类 SQL:回放、聚合、告警](#4. 开发者最常写的三类 SQL:回放、聚合、告警)
-
- [4.1 时间窗回放(排障必备)](#4.1 时间窗回放(排障必备))
- [4.2 时间窗聚合(看板主力)](#4.2 时间窗聚合(看板主力))
- [4.3 连续告警(避免抖动误报)](#4.3 连续告警(避免抖动误报))
- [5. 二次开发:怎么把"能用的数据库"搭成"好用的平台"](#5. 二次开发:怎么把“能用的数据库”搭成“好用的平台”)
-
- [5.1 接入与驱动:先把"连接"做成标准能力](#5.1 接入与驱动:先把“连接”做成标准能力)
- [5.2 SDK 的最小集合:别一上来做"大而全"](#5.2 SDK 的最小集合:别一上来做“大而全”)
- [5.3 模板库:把 SQL 变成"产品能力",不是"个人手艺"](#5.3 模板库:把 SQL 变成“产品能力”,不是“个人手艺”)
- [6. 工具链与生态:把"评估---迁移---开发---运维"串起来](#6. 工具链与生态:把“评估—迁移—开发—运维”串起来)
- [7. 让平台长期跑稳:开发者也必须关心的运维指标](#7. 让平台长期跑稳:开发者也必须关心的运维指标)
- 结语:真正的易用性,是让开发者把时间花在业务上
告别时序开发反复踩坑:把金仓时序数据库用顺、用稳、用成平台
1. 开发者真正关心的"易用性",到底是哪些点?
很多团队在做时序项目时,会有一种熟悉的落差感:系统勉强能跑,但一到开发联调、交付验收,就开始各种疲于奔命。站在开发者的角度,"易用"通常不是一句口号,而是落在下面这些非常具体的点上:
- 接入简单:标准接口、驱动齐全,业务系统改动可控
- 模型清晰:明细、聚合、事件三类表一上来就能对齐业务
- SQL 可复用:时间窗、聚合、补齐、告警这些逻辑能沉淀为模板
- 运维可控:分区、清理、回补、备份恢复能自动化,问题可定位
- 平台可扩展:能从"单项目"演进为"多业务域平台",二次开发能接得住
把这些点串起来看,其实所谓"易用性",说白了就是开发体验 + 交付效率 + 长期可维护性三件事能不能同时站得住。
2. 一条开发者友好的落地链路:从接入到看板再到运维闭环
要把时序平台做成"开发可控"的形态,只盯着某一层做优化是不够的,比较靠谱的做法是先把整体链路拆开看:接入层、数据层、查询层、运维层,各自承担清晰的职责。
接入层
采集端/网关/消息队列
写入适配
批量/幂等/质量位
数据层
金仓时序存储与索引
查询层
模板SQL/聚合层/回放
运维层
分区生命周期/备份恢复/监控
业务服务
告警/报表/看板
写代码时,最怕每个系统都要重新摸索一遍:接入怎么做、模型怎么建、SQL 怎么写、数据怎么养。按上面的方式拆完之后,有一个立竿见影的好处------每一层都可以逐步沉淀成可复用的组件,后面再做二次开发,就不会越做越"散装"。
3. 从 0 到 1:开发侧最小可行集(SQL 先跑通)
3.1 三张核心表:明细 + 聚合 + 事件
先把模型收一收,平台就不容易一上来就失控成"大而全工程"。实践下来,下面这三类表,基本能覆盖大多数典型场景:
- 明细表:承载原始点位,负责追溯与回放
- 聚合表:承载分钟/小时指标,负责看板与大多数报表
- 事件表:承载告警/工况事件,负责定位入口与关联分析
明细表(示例)
sql
CREATE TABLE telemetry_points (
ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
value DOUBLE PRECISION NOT NULL,
quality INTEGER DEFAULT 0,
PRIMARY KEY (ts, device_id, metric)
);索引的设计建议一开始就围绕"设备 + 指标 + 时间窗"这条主查询路径来固定,别等到线上慢查询堆出来再回头补。
sql
CREATE INDEX idx_tp_device_metric_ts ON telemetry_points (device_id, metric, ts);分区(示例思路)
时序数据是天然按时间往前滚的,分区大多数情况下按天/周/月切就足够;如果你的业务维度比较稳定、又经常作为过滤条件出现,也可以考虑"时间 + 业务维度"的联合切分方式,来进一步压缩扫描范围、减轻热点。
聚合表(示例:分钟级)
sql
CREATE TABLE telemetry_1m (
bucket_start TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
avg_value DOUBLE PRECISION NOT NULL,
min_value DOUBLE PRECISION NOT NULL,
max_value DOUBLE PRECISION NOT NULL,
cnt BIGINT NOT NULL,
PRIMARY KEY (bucket_start, device_id, metric)
);事件表(示例)
sql
CREATE TABLE telemetry_events (
event_ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
event_type VARCHAR(64) NOT NULL,
severity INTEGER NOT NULL,
message VARCHAR(256),
PRIMARY KEY (event_ts, device_id, event_type)
);3.2 写入侧的两个"反直觉"点:幂等与质量位
在真实环境里,写入链路里最常见的问题,往往不是"写不进去",而是"重复、乱序、补传一大堆"。想让系统一开始就站得稳,建议在建模阶段就给自己留出足够的"控制面":
- 幂等键 :设备重试、网关补传时,用
event_id去重 - 质量位 :用
quality标记正常/补传/估算/无效,避免告警口径乱
sql
CREATE TABLE telemetry_points_ingest (
event_id VARCHAR(128) NOT NULL,
ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
value DOUBLE PRECISION NOT NULL,
quality INTEGER DEFAULT 0,
PRIMARY KEY (event_id)
);这样设计有两个立刻能感受到的好处:一是写入服务可以大胆做重试和补传,而不用担心"多次落库";二是后续做聚合回补、数据修正时,有清晰的依据可循。
3.3 Windows 本地用 ksql 跑通示例:连接、建表、插数
下面这一小节,就是专门为"本地演示 + 截图"准备的操作脚本:我们在 Windows 本地的金仓数据库实例上,通过 ksql 命令行把示例从建表到出结果完整跑一遍。
Step 1:打开 ksql 并连接到本地实例
- 打开 PowerShell
- 确保
ksql.exe所在目录已加入 PATH(也可以直接进入安装目录的bin目录再执行) - 执行连接命令(把主机、端口、用户名、数据库名替换成你本机实际值)
bash
ksql -h 127.0.0.1 -p 54322 -U SYSTEM -d TEST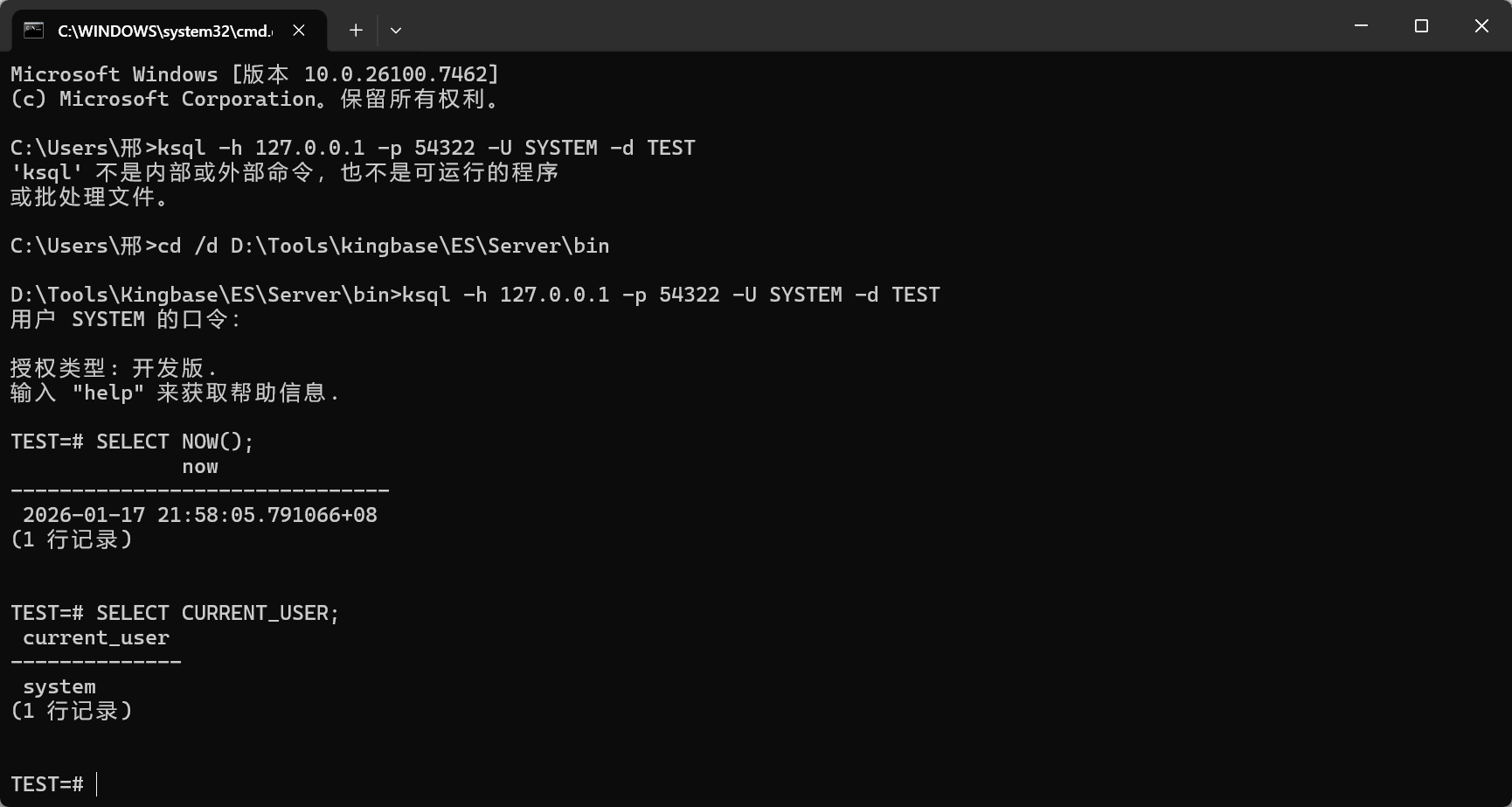
Step 2:一键初始化可跑数据集
sql
DROP TABLE IF EXISTS telemetry_points_ingest;
DROP TABLE IF EXISTS telemetry_events;
DROP TABLE IF EXISTS telemetry_1m;
DROP TABLE IF EXISTS telemetry_points;
CREATE TABLE telemetry_points (
ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
value DOUBLE PRECISION NOT NULL,
quality INTEGER NOT NULL DEFAULT 0,
PRIMARY KEY (ts, device_id, metric)
);
CREATE INDEX idx_tp_device_metric_ts ON telemetry_points (device_id, metric, ts);
CREATE TABLE telemetry_1m (
bucket_start TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
avg_value DOUBLE PRECISION NOT NULL,
min_value DOUBLE PRECISION NOT NULL,
max_value DOUBLE PRECISION NOT NULL,
cnt BIGINT NOT NULL,
PRIMARY KEY (bucket_start, device_id, metric)
);
CREATE TABLE telemetry_events (
event_ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
event_type VARCHAR(64) NOT NULL,
severity INTEGER NOT NULL,
message VARCHAR(256),
PRIMARY KEY (event_ts, device_id, event_type)
);
CREATE TABLE telemetry_points_ingest (
event_id VARCHAR(128) NOT NULL,
ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
value DOUBLE PRECISION NOT NULL,
quality INTEGER NOT NULL DEFAULT 0,
PRIMARY KEY (event_id)
);
INSERT INTO telemetry_points (ts, device_id, metric, value, quality) VALUES
('2025-01-01 00:00:00', 'D-10086', 'temperature', 75.0, 0),
('2025-01-01 00:01:00', 'D-10086', 'temperature', 76.0, 0),
('2025-01-01 00:02:00', 'D-10086', 'temperature', 79.0, 0),
('2025-01-01 00:03:00', 'D-10086', 'temperature', 81.0, 0),
('2025-01-01 00:04:00', 'D-10086', 'temperature', 82.0, 0),
('2025-01-01 00:05:00', 'D-10086', 'temperature', 83.0, 0),
('2025-01-01 00:06:00', 'D-10086', 'temperature', 84.0, 0),
('2025-01-01 00:07:00', 'D-10086', 'temperature', 85.0, 0),
('2025-01-01 00:08:00', 'D-10086', 'temperature', 86.0, 0),
('2025-01-01 00:09:00', 'D-10086', 'temperature', 78.0, 0);
COMMIT;
sql
SELECT COUNT(*) AS rows_cnt
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature';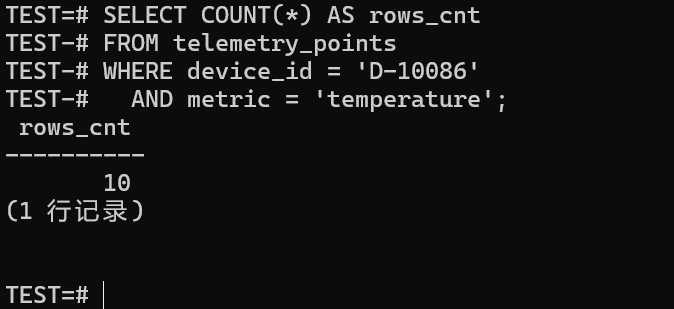
Step 3:用同一份数据跑三类查询
回放(按时间排序):
sql
SELECT ts, value, quality
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-01 00:10:00'
ORDER BY ts;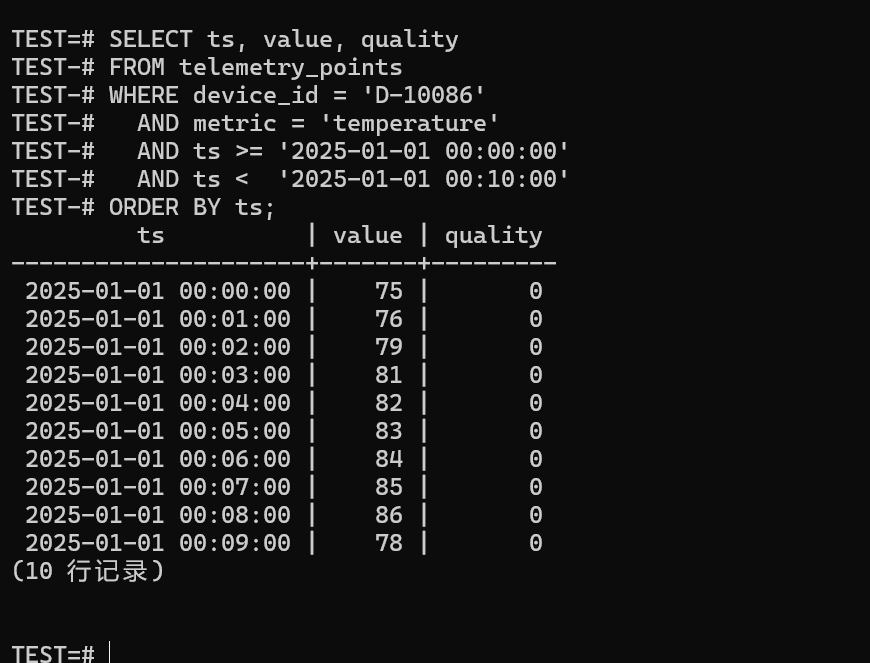
聚合(分钟粒度,看板最常用的那一类):
sql
SELECT
DATE_TRUNC('minute', ts) AS bucket_start,
AVG(value) AS avg_value,
MIN(value) AS min_value,
MAX(value) AS max_value,
COUNT(*) AS cnt
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-01 00:10:00'
GROUP BY DATE_TRUNC('minute', ts)
ORDER BY bucket_start;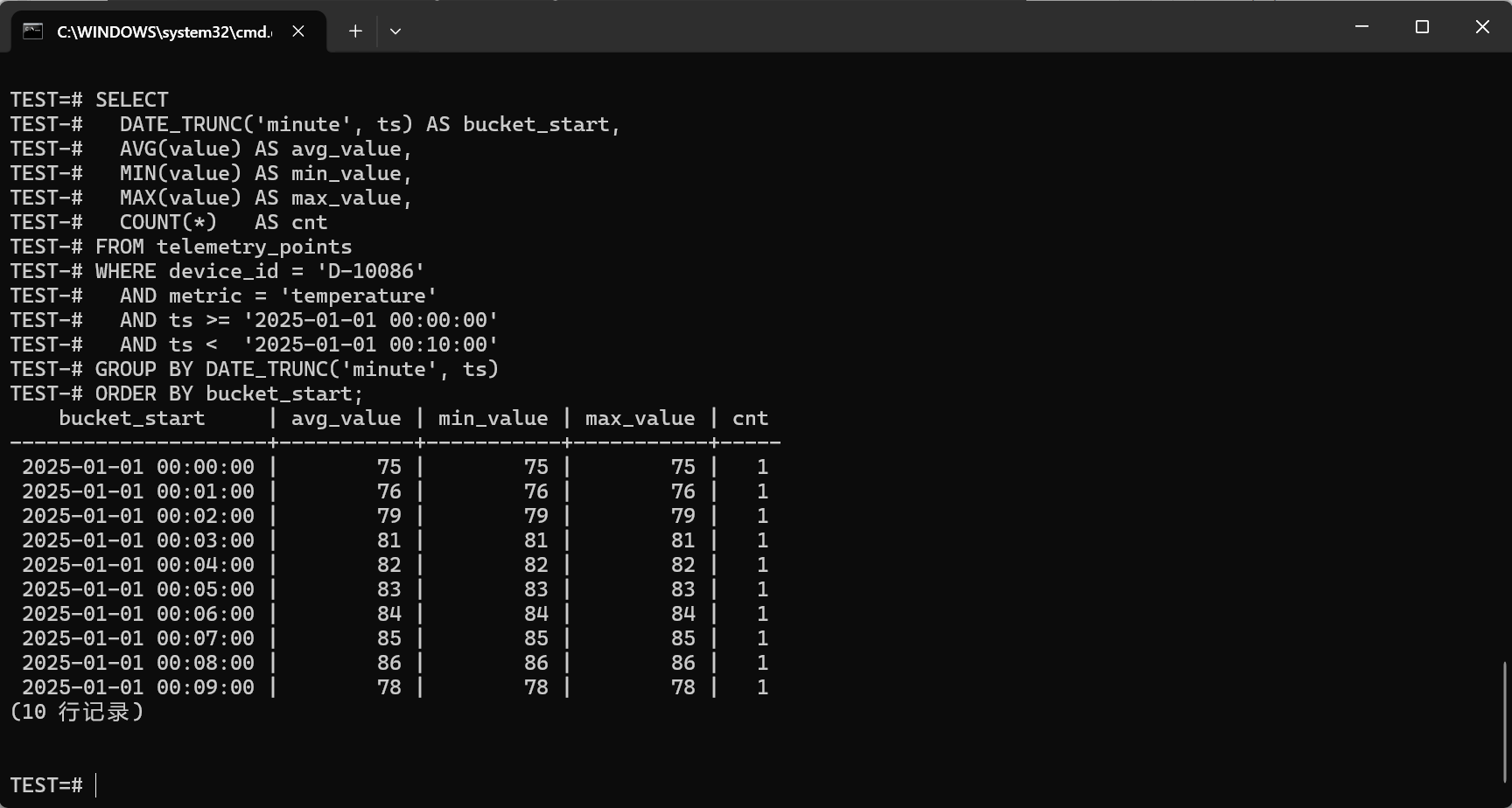
连续告警(示例口径:分钟均值连续 5 分钟 >= 80):
sql
WITH m1 AS (
SELECT DATE_TRUNC('minute', ts) AS minute_ts, AVG(value) AS avg_value
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-01 00:10:00'
GROUP BY DATE_TRUNC('minute', ts)
),
flag AS (
SELECT minute_ts, avg_value, CASE WHEN avg_value >= 80 THEN 1 ELSE 0 END AS over_th
FROM m1
),
grp AS (
SELECT *,
SUM(CASE WHEN over_th = 0 THEN 1 ELSE 0 END) OVER (ORDER BY minute_ts) AS grp_id
FROM flag
)
SELECT MIN(minute_ts) AS start_ts, MAX(minute_ts) AS end_ts, COUNT(*) AS minutes
FROM grp
WHERE over_th = 1
GROUP BY grp_id
HAVING COUNT(*) >= 5
ORDER BY start_ts;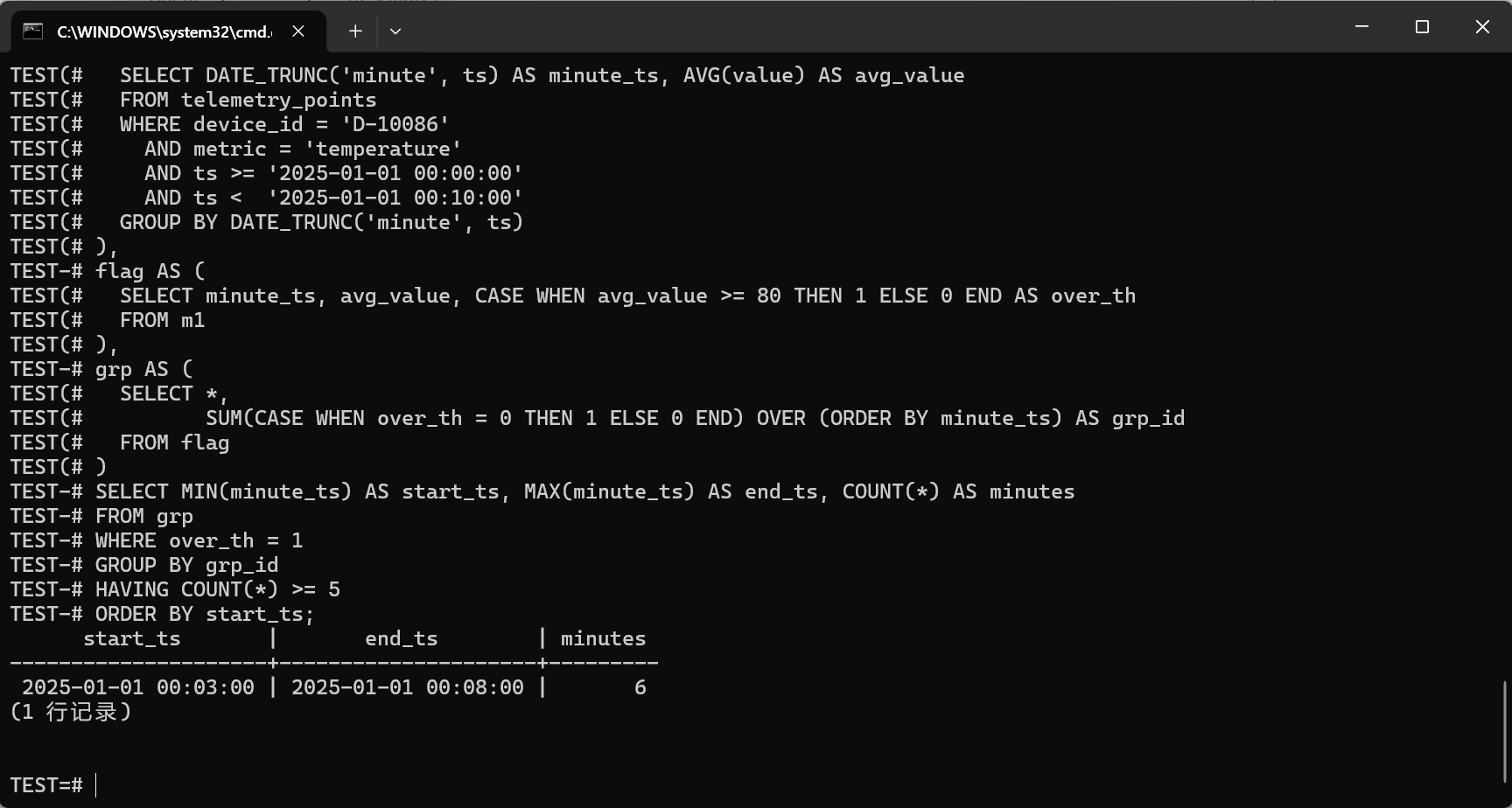
Step 4:退出 ksql
sql
\q4. 开发者最常写的三类 SQL:回放、聚合、告警
如果你希望团队在协作时少争论"到底该怎么查",比较理想的方式,是把下面这三类 SQL 直接沉淀成"模板库",由数据服务统一对外提供。
4.1 时间窗回放(排障必备)
sql
SELECT ts, value
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-02 00:00:00'
ORDER BY ts;4.2 时间窗聚合(看板主力)
sql
SELECT
DATE_TRUNC('minute', ts) AS bucket_start,
AVG(value) AS avg_value,
MIN(value) AS min_value,
MAX(value) AS max_value,
COUNT(*) AS cnt
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-01 06:00:00'
GROUP BY DATE_TRUNC('minute', ts)
ORDER BY bucket_start;4.3 连续告警(避免抖动误报)
sql
WITH m1 AS (
SELECT DATE_TRUNC('minute', ts) AS minute_ts, AVG(value) AS avg_value
FROM telemetry_points
WHERE device_id = 'D-10086'
AND metric = 'temperature'
AND ts >= '2025-01-01 00:00:00'
AND ts < '2025-01-01 06:00:00'
GROUP BY DATE_TRUNC('minute', ts)
),
flag AS (
SELECT minute_ts, avg_value, CASE WHEN avg_value >= 80 THEN 1 ELSE 0 END AS over_th
FROM m1
),
grp AS (
SELECT *,
SUM(CASE WHEN over_th = 0 THEN 1 ELSE 0 END) OVER (ORDER BY minute_ts) AS grp_id
FROM flag
)
SELECT MIN(minute_ts) AS start_ts, MAX(minute_ts) AS end_ts, COUNT(*) AS minutes
FROM grp
WHERE over_th = 1
GROUP BY grp_id
HAVING COUNT(*) >= 5
ORDER BY start_ts;等你把这些查询都固定成模板之后,会有一个很明显的感觉:开发体验的关键从来不在于"某条 SQL 写得有多花",而在于这些查询能不能被"固化为稳定的模块",让团队反复复用、让压测可回归、让指标口径不再飘来飘去。
5. 二次开发:怎么把"能用的数据库"搭成"好用的平台"
在很多项目里,"数据库能用"到"平台好用"之间,其实隔着一整套二次开发生态。这里的核心目标,是把底层数据库能力封装成开发者随取随用的"产品化能力"。比较落地的做法,是按下面三层来搭:
数据库层
金仓时序底座
数据服务层
写入/查询/聚合/回补
开发者体验层
SDK/组件/模板/文档
业务应用
看板/告警/报表/排障
5.1 接入与驱动:先把"连接"做成标准能力
开发者最怕遇到的是:每接一个系统,都要重新研究一套连接方式。要把这块统一起来,比较简单粗暴、但行之有效的方式,就是把接入能力收敛成两大类:
- 面向服务端应用:用标准数据库驱动接入(Java、.NET、Python 等常见语言都能走统一方式)
- 面向数据平台/工具:用标准接口接入 BI、ETL、可视化平台
金仓官网对外资料中提到,其配套组件覆盖迁移、开发管理、集中运维等工具,同时也提供相关驱动与配套文件下载渠道,方便在开发和交付阶段统一接入方式,少踩一些重复的坑。
5.2 SDK 的最小集合:别一上来做"大而全"
内部 SDK 一开始就想"全家桶",往往做着做着就失控了。更推荐的路径,是优先把最有价值、最常用的那一小撮能力落下来------通常只要先把下面四件事做好,就能解决 80% 的工程问题:
writePoints(points[]):批量写入,内置幂等与重试queryRange(device, metric, start, end):回放查询模板化queryAgg(device, metric, start, end, bucket):聚合查询模板化backfillAgg(window):聚合回补(处理迟到/补传)
Java(JDBC)伪代码示例:批量写入
java
String sql = "INSERT INTO telemetry_points_ingest(event_id, ts, device_id, metric, value, quality) VALUES (?, ?, ?, ?, ?, ?)";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
for (Point p : points) {
ps.setString(1, p.eventId());
ps.setTimestamp(2, p.ts());
ps.setString(3, p.deviceId());
ps.setString(4, p.metric());
ps.setDouble(5, p.value());
ps.setInt(6, p.quality());
ps.addBatch();
}
ps.executeBatch();
}这里真正重要的,不是这段代码本身写得多漂亮,而是把"幂等键、批量、重试"这些容易被忽略、又非常关键的工程动作统一收进 SDK,让业务方只需要关心"写什么数据",而不用每个项目都重新想一遍"该怎么写"。
5.3 模板库:把 SQL 变成"产品能力",不是"个人手艺"
从平台角度看,SQL 一旦多起来,如果没有分层管理,很快就会变成"谁写的谁知道"。比较实用的做法是,把 SQL 模板按三类管理:
- 固定模板:回放、聚合、连续告警这些通用能力
- 行业模板:电力、制造、交通等行业的常见指标与口径
- 项目模板:某个项目的特定维度与业务规则
同时给每条模板补上"版本号 + 参数声明 + 口径说明",后面做回归验证、做跨项目复用的时候,会省掉大量对齐口径、解释背景的时间。
6. 工具链与生态:把"评估---迁移---开发---运维"串起来
时序项目最怕的,就是在开发阶段一切顺利,上线之后却频繁被迁移、运维、性能分析、故障定位这些事情拖住脚步。
金仓官网公开信息中提到,其配套工具组件体系覆盖迁移评估、数据迁移、开发管理与集中运维等环节(例如 KDTS、KDMS、KStudio、KOPS 等)。这些能力对于搭建"可持续交付"的二次开发生态非常关键------你既可以把流程固化下来,也可以把经验沉淀成工具和标准化交付件。
从开发者视角给一点小建议:不要把这些工具当成"可有可无的附件",而是要主动把它们纳入平台工程的一部分,一开始就设计在流程里。
7. 让平台长期跑稳:开发者也必须关心的运维指标
如果你希望整个平台和二次开发生态越跑越稳,越跑越容易扩展,比较明智的做法是在开发阶段就把下面这些指标采集起来,而不是等出问题以后再补。
- 写入延迟:入口堆积、批量失败率、重试次数
- 查询延迟:P50/P95、慢查询 TOP、超时比例
- 存储增长:日增量、分区数量、冷热数据占比
- 生命周期动作:分区创建/清理/归档是否成功、耗时是否可预测
- 恢复演练:备份可用性、恢复耗时、演练频率
这些指标并不是给运维额外增加的"负担",而是平台能否朝规模化演进的一条底线。
结语:真正的易用性,是让开发者把时间花在业务上
从开发者视角看,金仓时序数据库的价值远不止"能承载时序数据"这么简单,更重要的是它可以成为你把时序能力工程化的底座:模型可以收敛,SQL 可以模板化,写入可以标准化,运维可以闭环,生态可以逐步搭起来。
如果你正准备把时序能力从"单个项目里的能力"升级成"对内对外复用的平台能力",不妨沿着"最小可行集 + 组件化演进 + 工具链固化"这条路线往前走------越早统一接入方式和口径,后面每扩一条业务线,心里就越有底。
参考资料
- 金仓时序数据库(官方资料):https://www.kdocs.cn/l/ctYp7fWoLYCV
- 金仓数据库官网:https://www.kingbase.com.cn/
想了解更多产品和方案,可以直接去金仓数据库官网逛一逛:https://www.kingbase.com.cn/
👉 金仓数据库官方博客站 :https://kingbase.com.cn/explore
如果你想继续深挖,这里有不少专家文章、原理拆解和最佳实践,可以按场景、按行业挑着看。